https://arxiv.org/abs/2012.03411
MLS: A Large-Scale Multilingual Dataset for Speech Research
This paper introduces Multilingual LibriSpeech (MLS) dataset, a large multilingual corpus suitable for speech research. The dataset is derived from read audiobooks from LibriVox and consists of 8 languages, including about 44.5K hours of English and a tota
arxiv.org
기존 ASR 연구는 대규모 음석, 텍스트 병렬 데이터가 핵심ㄷ이지만 영어 한 언어에 한정 된 데이터도 있고, 다국어 ASR 데이터는 대부분 규모가 작았음
MLS = 44.5K 영어 + 6k 독, 네덜란드, 스페인, 프랑스, 포루투갈, 이탈리아, 폴란드 등
LibriVox 오디오북을 다운로드 후 오디오 파일을 (10 ~ 20초) 자름
자른 오디오에 대해 4-gram LM + Beam search로 자동 전사
영어는 기존 모델 재사용
텍스트 데이터를 받아서 위에서 만든 가짜 라벨과, 책의 TF-IDF 유사도를 통해 후보 문서를 선택하고, 최고의 매칭을 찾아서 후처리 진행
오류율은 table 3와 같음


모델 구조
- 입력 feature 생성 - Log-Mel Filterbank
- 1D CNN -> stride3을 통해 시간축 1/3
- 36 Layer Tasnformer Encoder (768 차원)
- Encoder 출력 -> Linear Layer -> grapheme logit (문자 집합)
- CTC Loss로 학습
grapheme logit - character 단위 출력의 점수
5-gram -> 단순히 character 단위 출력 점수만 보는 것이 아닌 이전 단어를 통해 더 가능성있는 단어를 골라줌
🎧 음성: “the quick brown fox”
CTC greedy 결과:
"teh quik brwn foks"Beam search 후보들:
1) the quick brown fox
2) teh quik brown fox
3) the quik brwn fox
4) teh quick brown foks
...5-gram LM의 점수:
P("the quick") = 매우 높음
P("teh quick") = 매우 낮음
P("quik brown") = 낮음
P("brown fox") = 매우 높음➡ 최종 선택:
“the quick brown fox”
구분 핵심 정리
| 문제 상황 | - ASR 연구는 대규모 음성–텍스트 병렬 데이터가 필수적 - LibriSpeech는 영어만 지원, 다국어 ASR에는 부족 - 기존 다국어 코퍼스는 규모가 작거나, 품질이 낮거나, 공개 라이선스 문제가 있음 → 대규모·고품질·공개 라이선스 기반의 다국어 음성 데이터셋 부재 |
| 연구 목표 | - LibriVox 기반의 대규모 다국어 읽기 음성 데이터셋(MLS) 구축 - 언어별 LM과 Baseline ASR 모델 제공 - 공개/표준화된 multilingual ASR·TTS 연구 기반 구축 |
| 데이터 규모 | - 총 50K+ 시간 - 영어 44.5K h, 기타 7개 언어 합계 6K h 지원 언어 8개: EN, DE, NL, FR, ES, IT, PT, PL |
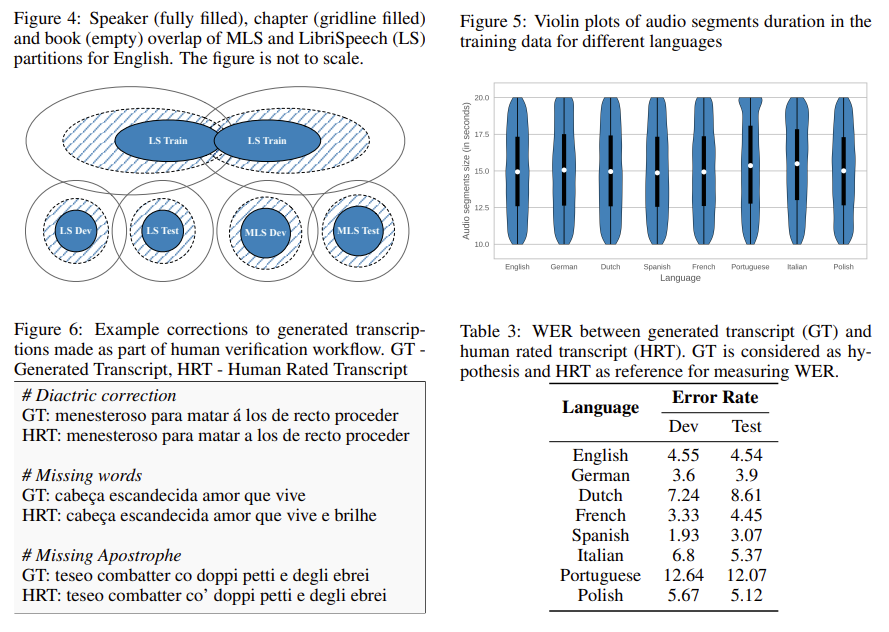
| 데이터 생성 파이프라인 | ① LibriVox 오디오 수집 (API + 수동 보정) ② 오디오 세그멘테이션: 10–20초, TDS-ASG 모델로 silence 기반 분할 ③ Pseudo label 생성: TDS 모델 + 4-gram LM beam search ④ 텍스트 소스 수집: Gutenberg/Archive 등 + PDF/HTML 파싱 ⑤ 텍스트 정규화: NFKC, hyphen 제거, emoji 제거, 언어별 unicode 필터링 ⑥ Transcript Retrieval: TF-IDF(bigram) 문서 검색 + Smith-Waterman alignment ⑦ 숫자/하이픈/아포스트로피 후처리 (pseudo label 기반 대체) ⑧ Train/Dev/Test Split: 화자 불겹침, 성별 균형 ⑨ Dev/Test human verification (명백한 오류만 수정) |
| 데이터 품질 | - Dev/Test는 사람이 검증하여 WER 대폭 개선 - GT vs Human WER (Dev): EN 4.55%, ES 1.93%, PL 5.67% 등 → 높은 정확도의 평가 세트 확보 |
| 언어모델 (LM) | - Gutenberg 기반 LM 텍스트 정제 후 3-gram/5-gram LM 생성 - KenLM 사용 - LM OOV가 성능에 영향 → PL은 13.39%로 가장 높음 |
| ASR 모델 구조 | 모델: Transformer Encoder 기반 CTC 구조 - 입력: 80-dim Log-Mel Filterbank - Frontend: 1D Conv(kernel=7, stride=3, GLU) - Encoder: 36-layer Transformer, 4-head, d=768, FFN=3072 - Output: grapheme linear → CTC - 정규화: dropout, layerdrop, SpecAugment - Loss: CTC |
| 학습 설정 | - Optimizer: Adagrad - Learning rate: dev WER plateau 시 factor 2 decay - Augmentation: SpecAugment (10 time mask, 2 freq mask) - Token set: 언어별 grapheme |
| Decoding 방식 | - Viterbi(greedy) - ZeroLM (beam search without LM) - 5-gram LM decoding (성능 최적) |
| 실험 결과 (WER) | 5-gram LM이 모든 언어에서 WER 개선 (PL 제외) - EN: 6.99 → 5.88 - FR: 6.88 → 5.58 - IT: 12.35 → 10.54 - PT: 21.70 → 19.49 |
| LibriSpeech 비교 | MLS 44.5K h로 학습한 모델은 LibriSpeech dev/test에서도 성능 향상 - LS baseline test-other: 7.1 - MLS 기반 모델 test-other: 3.97 |
| 결과 요약 | - MLS는 대규모 supervised data 덕분에 기존 LibriSpeech만 사용한 모델보다 성능이 절반 수준으로 감소 - 다국어 ASR 학습에도 매우 강력한 성능 제공 |
| 기여(Contribution) | 1) 대규모·다국어 공개 음성 데이터셋 제공 2) 자동·반자동 Transcript Retrieval pipeline 제안 3) Human-verified Dev/Test 공개 → 안정적 평가 가능 4) 3-gram/5-gram LM 및 Baseline ASR 모델 제공 5) 대규모 supervised 학습의 효과를 정량적으로 입증 |
| 한계(Limitations) | - 읽기 음성(read speech)에 한정 → conversational domain엔 약함 - pseudo label 품질이 alignment 정확도에 영향 - 숫자/아포스트로피 처리 규칙은 완벽하지 않음 - 언어별 데이터 편차 큼 (EN 압도적 편중) - 어떤 언어는 LM OOV가 높아 decoding 성능 제한 |
| 적용 가능 분야 | - 대규모 multilingual ASR 학습 - LibriTTS 확장 → multilingual TTS - self-supervised pretraining의 supervision 비교 실험 - cross-lingual transfer 연구 |
아래는 MLS (Multilingual LibriSpeech) 논문 전체를 기반으로 한 체계적·전문적 한국어 요약입니다.
핵심 문제 → 방법론 → 데이터 구성 → 모델·실험 결과 → 기여와 한계까지 AI 음성 연구자가 바로 활용할 수 있도록 구조화했습니다.
(모든 내용은 업로드된 원문을 기반으로 작성했습니다. )
📌 MLS: A Large-Scale Multilingual Dataset for Speech Research — 논문 요약
1. 연구 문제 및 배경
ASR(Automatic Speech Recognition) 연구는 대규모 음성-텍스트 병렬 데이터가 핵심이지만,
- LibriSpeech는 영어 한 언어에 한정됨.
- 기존 다국어 ASR 데이터는 대부분
- 규모가 작거나(low-resource),
- 도메인이 제한적이거나(전화 음성),
- 공개 라이선스가 불명확함.
➡️ 대규모·다국어·공개 라이선스 기반 ASR 데이터의 부재가 연구 발전을 제한함.
이 논문의 목표:
📍 읽기 음성 기반의 대규모 다국어 음성 데이터셋(MLS) 구축
📍 ASR/TTS 연구에 자유롭게 활용하도록 공개
2. MLS 데이터셋 개요
🌍 포함된 언어 8개
- 영어: 44.5K 시간
- 독일어, 네덜란드어, 스페인어, 프랑스어, 포르투갈어, 이탈리아어, 폴란드어: 총 6K 시간
→ 전체 50K+ 시간 규모의 세계 최대급 다국어 음성 데이터셋
→ LibriVox 오디오북 기반 (원문은 Gutenberg 등에서 확보)
3. 데이터 구축 파이프라인 (방법론)
논문은 MLS 구축 과정을 세밀한 자동·반자동 파이프라인으로 구성함.
Step 1. LibriVox 오디오북 다운로드
- LibriVox API 사용
- 48kHz → 16kHz 다운샘플링
- 텍스트 출처(Gutenberg, Archive, CCEL 등) 자동·수동 수집
(특히 다국어 텍스트는 자동화 어려워 수동 보정 포함)
Step 2. 오디오 세그멘테이션 (10–20초)
문제: 오디오북 파일은 몇 시간씩 매우 김 → ASR 학습 불가능
배경 모델: TDS(Time-Depth Separable) 기반 ASG(CTC보다 지연이 적음) 모델 사용
- Viterbi alignment로 음소/단어 타임스탬프 추출
- 10–20초 구간 내 최장 silence를 기준으로 자름
- silence가 없으면 20초에서 강제 절단
→ 모든 샘플이 10–20초로 정규화 (그림 1 참고)
Step 3. Pseudo Label 생성
- 세그먼트된 오디오에 대해
4-gram LM + beam search로 자동 전사 생성 - 영어는 기존 LibriSpeech 기반 모델 재사용
Step 4. 텍스트 소스 수집 및 정규화
문제:
- PDF/EPUB, HTML 등 포맷 다양
- 페이지 번호, 전자책 특유의 하이픈, 다양한 구두점 문제
해결:
- NFKC 정규화
- 불필요한 문자, 기호 제거
- “line hyphenation” 제거
- 언어별 유니코드 필터링 적용
Step 5. Transcript Retrieval (정확한 문장 매칭)
🔍 핵심 알고리즘
- 원본 책 텍스트를 1250 단어 문서로 슬라이딩 윈도우 구성
- pseudo label과 TF-IDF(bigram) 유사도로 후보 문서 선택
- Smith-Waterman alignment로 최고의 매칭 subsequence 찾기
- 후보 중 pseudo-label과의 WER > 40%면 제거
Step 6. 난이도 높은 후처리
특히 중요했던 부분:
① 숫자 처리
“401” → “four hundred one” vs “four-oh-one” 등 다양
→ pseudo-label과 alignment하여 pseudo-label 단어로 대체 (그림 2)
② 하이픈/아포스트로피 문제
텍스트는 많지만 실제 발화에는 없는 경우 다수 → 휴리스틱 적용 (그림 3)
Step 7. Train/Dev/Test Split
원칙
- 화자 불겹침
- 성별·길이 균형 맞춤
- 난이도 확보
또한 영어는 LibriSpeech와 dev/test 겹치지 않도록 설계 (그림 4)
Step 8. Human Verification (검증 중요 포인트)
Dev/Test는 전문 청취자가 다음만 수정:
- 명백한 표기 오류
- 누락 단어
- 잘못된 악센트/아포스트로피
(그림 6 예시)
GT vs Human transcript WER (dev 기준):
- 영어: 4.55%
- 스페인어: 1.93%
- 포르투갈어: 12.64%
→ 전체적으로 높은 품질의 테스트셋 확보 (표 3)
4. 언어모델(Language Model) 구성
각 언어별:
- Gutenberg 기반 텍스트 수십만–수백만 문장
- 정규화 후 3-gram, 5-gram LM 학습
- KenLM 사용 (표 4, 5)
특징:
- 폴란드는 데이터 부족으로 OOV → WER 악화
5. Baseline ASR 모델 및 실험 결과
Acoustic Model 구조
- Conv(1D, kernel 7, stride 3 + GLU)
- 36-layer Transformer encoder
- d_model = 768
- FFN = 3072
- 4-head attention
- SpecAugment 적용
- CTC Loss
- Adagrad optimizer
WER 결과 (표 6)
Decoding 방식별 (Viterbi → Zero LM → 5-gram LM):
언어 Viterbi(test) 5-gram LM(test)| English | 6.99 | 5.88 |
| German | 6.93 | 6.49 |
| French | 6.88 | 5.58 |
| Italian | 12.35 | 10.54 |
| Portuguese | 21.70 | 19.49 |
→ 모든 언어에서 5-gram LM가 성능 향상 (폴란드 제외)
→ 폴란드 OOV 13% 영향
LibriSpeech와 비교 (표 7)
LibriSpeech(960h) vs MLS(44.5K h)로 학습된 동일 모델 비교:
모델 test-other| LibriSpeech | 7.1 |
| MLS | 3.97 |
→ 데이터가 커질수록 성능이 40~50% 수준으로 대폭 향상됨
6. 결론 및 기여
🔑 주요 기여
- 최대 규모의 공개 다국어 읽기 음성 데이터셋 (50K+ h)
- 정교한 자동 레이블링 + alignment 기반 transcript 복원 기법 제안
- 언어모델(3-gram/5-gram)과 baseline ASR 모델 모두 제공
- Human-verified Dev/Test 제공 → 평가 신뢰성 확보
- ASR뿐 아니라 다국어 TTS 연구의 기반 제공
7. 한계 및 논문에서 언급된 문제점
- 일부 언어(폴란드어 등)의 OOV·데이터 부족 문제
- 읽기 음성(read speech)에만 한정 → 대화체 다양성 부족
- Alignment 품질이 pseudo label 품질에 의존
- 숫자/하이픈 처리 휴리스틱은 완벽하지 않음
- LibriVox 기반이라 도메인 편향 존재 (문어체 문학 텍스트 중심)
8. 요약 표 (연구자가 다시 참고할 수 있도록)
항목 내용| 문제 | 다국어 ASR/TTS 연구용 대규모 공개 데이터 부족 |
| 데이터 | 8개 언어, 총 50K+ 시간 (영어 44.5K) |
| 파이프라인 | 다운로드 → 세그멘테이션 → pseudo-label → 텍스트 수집 → alignment → 후처리 → split → human verification |
| 모델 | 36-layer Transformer encoder + CTC |
| LM | 언어별 Gutenberg 기반 3/5-gram KenLM |
| 성능 | 모든 언어에서 LM decoding 적용 시 WER 감소 |
| LibriSpeech 비교 | MLS 기반 모델은 LS test-other에서 3.97까지 감소 |
| 기여 | 대규모 공개 다국어 데이터셋 + LM + baseline 제공 |
| 한계 | 언어 간 데이터 편차, pseudo label 기반 오류, read-speech 한정 |
필요하면 아래도 추가로 정리해드릴 수 있어요:
- 연구에 활용하기 위한 데이터 로딩/전처리 코드 템플릿
- MLS를 활용한 multilingual ASR 실험 설계 가이드
- Conformer/W2V2/Whisper 기반 fine-tuning 전략
원하시는 방향이 있나요?
아래는 MLS 논문에서 구축한 데이터(MLS Dataset)를 가지고 실제 ASR 모델을 학습하는 전체 과정을, 논문 내용을 기반으로 구체적으로, 단계별로, 연구자가 바로 구현할 수 있는 수준으로 상세히 설명한 것입니다.
(모든 내용은 업로드된 원문인 MLS: A Large-Scale Multilingual Dataset for Speech Research.pdf에서 직접 추출·정리함 )
📌 MLS 데이터로 ASR 모델을 학습하는 전체 파이프라인 (논문 기반 상세 설명)
논문은 MLS 데이터를 활용했을 때 어떤 모델 구조로, 어떤 입력 특징(Log-Mel Filterbank)으로, **어떤 학습 설정(optimizer, LR schedule, augment)**으로 학습하는지를 매우 구체적으로 제시한다.
아래 설명은 논문 순서를 넘어서, 연구자가 실제로 학습 코드를 짤 수 있을 정도로 재구성한 형태이다.
1. 입력 특징 (Input Feature) 생성 과정
✔️ 입력: 16kHz mono audio
MLS의 모든 오디오는 다운로드 이후 16kHz로 resample 되어 있다.
→ 이는 wav2letter++에서 기본 입력 주파수이기도 함.
✔️ 특징 추출: 80-channel Log-Mel Filterbank
논문에서는 모든 ASR 모델에서 80 dim log-mel filterbank를 사용한다.
Sample rate: 16 kHz
FFT window: (기본 wav2letter 설정, 약 25ms)
Hop size: 약 10ms
Mel bins: 80
Mean/variance normalization: 적용
즉 입력은 대략 다음 shape을 가진다:
Input: [TimeFrames, 80]
이는 Conformer나 Transformer Encoder에 입력되기 전, Conv-frontend를 통과한다.
2. 모델 구조 (Acoustic Model Architecture)
논문에서 사용하는 AM(acoustic model)은 다음과 같은 매우 강력한 Transformer Encoder 기반이다.
✔️ 1단계: Convolutional Frontend
1D Conv(kernel 7, stride 3) → GLU → Dropout
- stride 3을 사용하면 시간축 길이가 1/3로 줄어든다.
- Transformer의 계산량 감소 & receptive field 증가.
✔️ 2단계: 36-layer Transformer Encoder
- 레이어 수: 36
- 헤드 수: 4
- d_model = 768
- FFN dimension = 3072
- Dropout on:
- Self-attention
- Feed-forward (FFN)
- LayerDrop 적용 (Transformer 레이어 전체를 랜덤하게 drop)
- 모델 deepness를 유지하면서 regularization 효과를 부여
✔️ 3단계: Output Linear (CTC Classifier)
- Transformer encoder의 출력 → Linear layer → grapheme logits
- Token set: 각 언어의 grapheme(문자) 집합
- 예: 영어는 소문자 알파벳+기본 문자들
✔️ 학습 Loss: CTC (Connectionist Temporal Classification)
ASG 대신 segmentation에만 ASG를 쓰고, 학습은 모두 CTC로 진행한다.
3. 학습 설정 (Training Configuration)
✔️ Optimizer
Optimizer: Adagrad
Adagrad를 사용한 이유:
- Transformer 기반 ASR 모델에서 안정적
- learning rate decay가 잘 작동함
✔️ Learning Rate Schedule
논문 방식:
validation WER가 plateau에 도달할 때마다 LR을 2배 감소
즉, early stopping 기반의 adaptive decay 방식.
✔️ Regularization 기법
1) Dropout
- Conv layer 이후 dropout
- 각 Transformer layer의 attention·FFN dropout
2) LayerDrop
- Transformer layer 전체를 drop하는 structured dropout
→ 매우 deep한 모델(36 layers)의 overfitting을 방지
3) SpecAugment
SpecAugment는 논문에서 매우 강력하게 사용됨.
SpecAugment 설정:
- Frequency mask: 2개
- Time mask: 10개
- Time mask ratio: p = 0.1
- Max freq mask width: 30 bins
- Max time mask width: 30 frames
- Time warping: 사용하지 않음
4. 디코딩 전략 (Inference)
모델 학습 이후, WER을 계산하기 위해 3가지 디코딩 방법을 사용:
✔️ 1) Viterbi (no LM, greedy)
- 가장 단순: 성능 낮지만 baseline으로 필요
✔️ 2) ZeroLM (beam-search, LM 없이)
- LM 없이 beam search만 사용
✔️ 3) 5-gram LM decoding (추천)
- 각 언어별로 논문이 함께 제공하는 KenLM 5-gram 사용
- decoder hyperparameter는 dev set WER을 기준으로 튜닝
5. 데이터 활용 방식 (Training / Validation 구성)
✔️ Train/Dev/Test Split 특징
- 화자 불겹침
- 성별 균형 유지
- dev/test는 human verified transcript 보정
→ 품질 매우 높음 (표 3에서 dev WER 1.9%~12%)
6. 전체 학습 밀도 요약 (논문에서 실제 한 학습)
✔️ Step-by-step 요약
1단계. 데이터 준비
- MLS 오디오(.flac) 로드
- 80 Mel Filterbank 생성
- grapheme 단위 라벨 불러오기
2단계. 모델 초기화
- Conv Frontend → 36L Transformer Encoder → Linear Output
- grapheme vocabulary size로 classifier 구성
3단계. 학습 Loop
각 epoch마다:
- 배치 로드
- SpecAugment 적용
- Conv + Transformer forward
- CTC loss 계산
- Adagrad + learning rate scheduling
- WER(dev) 계산 → plateau 시 LR 감소
4단계. 디코딩
Dev/Test에 대해:
- Viterbi
- ZeroLM beam search
- 5-gram LM beam search
WER 계산
5단계. 모델 성능 비교
논문 결과에서:
언어 Viterbi(test) 5-gram LM(test)| English | 6.99 | 5.88 |
| French | 6.88 | 5.58 |
| Italian | 12.35 | 10.54 |
| Portuguese | 21.70 | 19.49 |
LM 디코딩이 필수적으로 성능 향상을 이끈다.
7. 연구자가 이해해야 할 핵심 포인트 요약
🔑 1. MLS는 read-speech 기반으로 매우 노이즈가 적음
→ Transformer 기반 End-to-end CTC 모델에 최적화된 환경
🔑 2. 학습 구조는 "Conv Frontend + Deep Transformer Encoder + CTC"
→ Whisper 이전 ASR 트렌드의 정석 구조
🔑 3. SpecAugment와 LayerDrop이 매우 중요한 regularization 역할
🔑 4. LM 디코딩이 성능을 크게 끌어올린다
→ 특히 폴란드어처럼 OOV가 큰 언어는 성능이 떨어짐
🔑 5. large-scale supervised training 후 LibriSpeech에서도 성능이 향상됨
(LS training 960h vs MLS 44.5K h 비교)
필요하신 추가 분석도 제공 가능합니다
예를 들어:
- Colab/PyTorch로 MLS ASR 학습 스크립트 템플릿
- 위 모델을 Conformer로 교체한 modern ASR pipeline 구성
- MLS 기반 multilingual ASR 연구 방향 추천
- Whisper/Wav2Vec2와의 성능 비교 분석
원하시면 다음 단계로 이어서 설명해드릴게요!