https://arxiv.org/abs/2401.17167
Planning, Creation, Usage: Benchmarking LLMs for Comprehensive Tool Utilization in Real-World Complex Scenarios
The recent trend of using Large Language Models (LLMs) as tool agents in real-world applications underscores the necessity for comprehensive evaluations of their capabilities, particularly in complex scenarios involving planning, creating, and using tools.
arxiv.org
기존 벤치마크는 단순 도구 호출에만 초점을 맞추고 있어 실제 시나리오의 복잡성, 단계적 문제 해결 능력을 반영하지 못한다!
=> 도구 계획하는 단계를 통해 목표를 분해하고, 자연어 기반의 계획 수립을 진행하여 복잡한 요청을 다 단계로 분해할 수 있는지 확인한다.
목적
복잡한 목표를 논리적 순서로 분해
각 단계에서 어떤 작업이 필요한지 명시
도구 호출의 의존 관꼐와 선행 정보 획득 요구사항을 구조적으로 정리
사용자 요청을 다단계(sub-task)로 분해
각 단계에서 필요한 작업을 자연어로 명시
도구 호출 간 의존관계 및 정보 흐름을 구조화
선행 작업 → 후속 작업의 논리적 연결성을 확인

도메인 22개

🛠️ UltraTool 구축 과정
- Query 수집
- 실제 사용 시나리오 기반 고난이도 질의 수집 (도메인 전문가 협력) (Query 작성 기준 : 현실성, 복잡성, 다양성)
- GPT-4로 질의 일반화 및 복잡화 진행
- Solution Annotation
- Plan Annotation : GPT-4를 사용한 다단계 계획(트리 구조) 수립
- Tool Creation, Plan Refinement : 기존 도구 부족 시 도구 생성, 기존 계획 정제
- Tool Calling Message Annotation : JSON 기반 도구 호출 메시지 주석 달기
- Tool MMerge : 유사 도구 병합, 중복 제거, 2032개의 독립 도구 정의 완료
- Manual Refinement
- 전문가 6인이 수작업으로 계획 구조 및 도구 호출 보완, 오류 제거
평가는 LLM as Judge 방식
| 평가 항목 | 정의 |
| Accuracy | 사용자의 목표와 계획의 정합성 |
| Completeness | 질의에서 요구된 모든 제약/정보 반영 여부 |
| Executability | 각 단계가 실제로 실행 가능한지 |
| Syntactic Soundness | 문법적 완전성, 자연스러움 |
| Structural Rationality | 단계 간 계층 구조 및 순서의 논리성 |
| Efficiency | 과도한 단계 없이 필요한 최소 작업으로 구성되었는지 |
| 모델 | Planning (전체 점수) | Accuracy | Completeness | Executability | Syntactic | Structure | Efficiency |
| GPT-4 | 76.39 | 79.56 | 77.53 | 78.31 | 81.21 | 78.19 | 78.60 |
| Qwen-72B | 73.40 | 78.28 | 74.25 | 76.23 | 80.83 | 75.70 | 77.30 |
| GPT-3.5 | 69.50 | 76.43 | 70.26 | 73.14 | 80.94 | 72.26 | 75.10 |
| Mistral-7B | 66.18 | 73.00 | 68.50 | 70.77 | 81.48 | 70.07 | 69.68 |
| Vicuna-13B | 65.72 | 73.19 | 68.08 | 70.64 | 81.68 | 69.98 | 70.89 |
| LLaMA2-7B | 46.44 | 51.35 | 47.61 | 50.66 | 72.52 | 50.79 | 50.39 |

Step에 해당하는 것이 Planning 단계다
🧭 UltraTool의 Planning 단계를 통한 LLM의 Agentic 능력 평가
1. 📌 측정하려는 능력 (What to Measure)
LLM의 Planning 능력:
복잡한 목표에 대해 도구에 의존하지 않고 자연어 기반의 멀티스텝 계획을 수립하는 능력
| 세부 측정 능력 | 설명 |
| 🧠 과제 이해력 | 사용자 질의의 목적, 제약 조건, 필요한 정보 요소를 이해하는 능력 |
| 🪜 목표 분해 능력 | 전체 과제를 논리적이고 실행 가능한 서브태스크로 분해하는 능력 |
| 🧩 구조 설계 능력 | 계층적/트리 구조의 작업 흐름을 구성하는 능력 |
| 🔁 논리적 연결성 | 선후 관계, 의존성, 순차성 등을 적절히 반영하는 능력 |
| 📏 간결성과 효율성 | 불필요한 단계를 제거하고, 최소한의 스텝으로 효과적 계획을 수립하는 능력 |
이러한 능력은 LLM이 autonomous agent로서 복합적 문제를 자체 구조화하여 해결할 수 있는가를 측정하는 핵심 요소입니다.
2. 🧪 측정 방법 (How to Measure)
UltraTool은 GPT-4 기반 LLM-as-Judge를 활용하여 아래 6가지 평가 항목을 기준으로 점수를 부여함
| 평가 항목 | 측정 기준 | 역할 |
| Accuracy | 사용자 요구와 계획의 정합성 | 목표 파악 정확성 |
| Completeness | 요구된 모든 작업 포함 여부 | 과제 범위 이해도 |
| Executability | 각 스텝이 실행 가능 여부 | 현실 적용 가능성 |
| Syntactic Soundness | 문법/자연어 품질 | 자연스러운 표현력 |
| Structural Rationality | 계층 구조 및 흐름의 논리성 | 작업 조직 능력 |
| Efficiency | 과도한 반복 없이 구성 | 전략적 간결성 |
- 채점 기준: 각 항목별 1~10점
- 평가 방식: GPT-4가 Reference Plan과 예측 계획을 비교해 항목별로 점수 부여
- Human 평가와 0.8 이상의 상관관계를 보이며, 객관적 자동 평가 신뢰 확보
3. 🔍 UltraTool의 차별성 (What Makes It Unique)
| 항목 | 기존 벤치마크 | UltraTool |
| Planning 평가 | ❌ 없음 or 간접적 | ✅ 명시적 Planning 평가 존재 |
| 도구 종속 여부 | 도구 세트 기반 질의 생성 → 계획 왜곡 발생 | 도구와 무관한 순수 질의 기반 계획 수립 |
| 계층적 계획 평가 | 대부분 단일 스텝 | ✅ 트리 구조 기반 계획 수립 평가 |
| 다차원 평가 | 단일 정확도 중심 | ✅ 6가지 항목 기반 다면적 평가 |
| 현실성 | 시뮬레이션 질의 위주 | ✅ 실제 사용자 질의 + 전문가 작성 |
| 자율성 평가 | Tool API를 얼마나 잘 호출하는가에 국한 | ✅ 복잡 목표를 스스로 구조화하는 능력 평가 |
➡️ 따라서, UltraTool은 “문제 해결을 위한 사전 전략 구성 능력”을 독립적으로 측정한다는 점에서 기존의 도구 호출 중심 평가와 본질적으로 다름
4. 🎯 도전성 (Challenges)
| 측면 | 도전 요소 |
| ⚙️ 계획 수립의 자유도 | 정답이 여러 개 존재할 수 있음 (non-determinism) |
| 🔀 작업 의존성 파악 | 단순 분해가 아닌 의존 관계 기반 분해 필요 |
| 🧱 구조 설계 능력 | depth, branching 구조를 논리적으로 설계해야 함 |
| 🔄 반복 제거와 효율성 | 불필요한 중복 스텝을 줄이며도 충분히 완전한 계획을 구성해야 함 |
| ✍️ 표현 일관성 | 명확한 자연어 문장으로 표현하는 능력도 중요 (계획 품질과 직결) |
✅ 결론: Agentic Planning 능력 측정의 정당성과 활용
UltraTool의 Planning 평가는 LLM이 다음을 수행할 수 있는지를 측정합니다:
“외부 도구 없이도 복잡한 사용자 문제를 인식하고, 이를 논리적으로 나누어 스스로 해결 전략을 설계할 수 있는가?”
이는 Agentic AI가 갖추어야 할*자기주도 문제 해결력(Self-structured reasoning capability)의 핵심입니다.
UltraTool은 이 능력을 도구 호출 능력과 독립적으로 분리하여 직접적으로 평가할 수 있다는 점에서 학술적 가치가 높습니다.
https://arxiv.org/abs/2406.02903
Open Grounded Planning: Challenges and Benchmark Construction
The emergence of large language models (LLMs) has increasingly drawn attention to the use of LLMs for human-like planning. Existing work on LLM-based planning either focuses on leveraging the inherent language generation capabilities of LLMs to produce fre
arxiv.org
기존 LLM기반 Planning은 자연어 기반 자유로운 계획 혹은 제한된 도구 환경에서의 플레닝에 집중되어 실제 실행 가능한 계획이 되지 못한다.
Open Grounded Planning은 실행 가능한 액션 집합 내에서만 계획을 생성하고, 방대한 도메인의 방대한 액션 집합을 대상으로 한다.
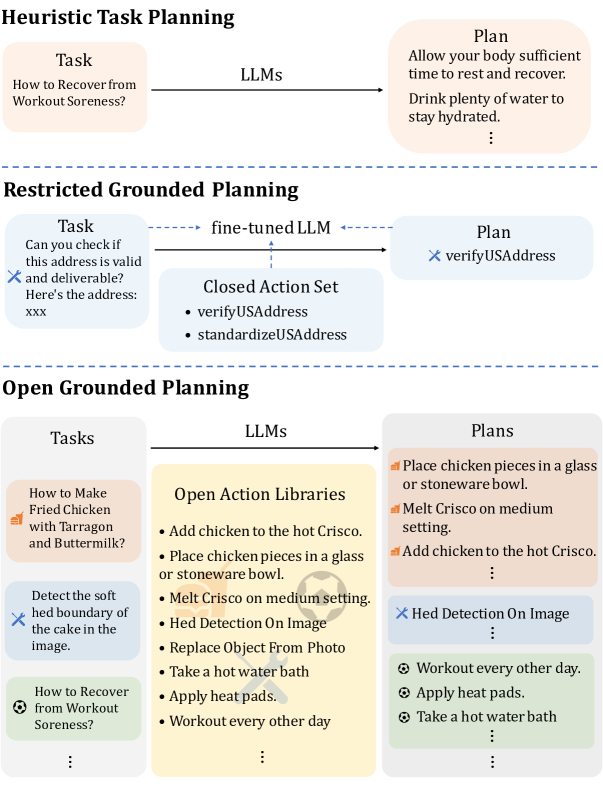

일상 데이터 셋 wikiHow - 도메인 내 근거 기반 계획 역량 평가 - 매우 광범위한 범위를 포괄 = 행동 세트가 더 복잡함
로봇 관련 데이터 세트를 활용해 도메인 외 근거 기반 계획에 대한 다양한 모델과 방법론의 일반화를 평가
Tool엔 매개변수 없이 설명과 이름만 있다.
평가 방법
| 항목 | 설명 |
| ✅ Executability | 생성된 모든 단계가 액션 집합 내에 포함되는 비율 |
| 🧠 Quality | 계획의 완전성, 실행 가능성, 과업 관련성 기준으로 평가 (ChatGPT 사용, 위치 bias/길이 bias 보정) |
| 📊 Pass Rate | Executability × Quality로 최종 평가 |
🔍 제안 방법들 (총 5가지)
| 방법 | 설명 |
| 1. Task-Retrieve | Task 이름 기반으로 관련 액션을 검색 후, LLM이 선택 및 순서 조정 |
| 2. Plan-Retrieve | 초안 계획 생성 → 이를 기반으로 관련 액션 검색 및 최종 계획 생성 |
| 3. Step-wise Select | 매 스텝마다 후보 액션 검색 → 하나 선택 (ReAct 방식 유사) |
| 4. DFS | Step-wise 방식에서 선택 실패 시 백트래킹 |
| 5. Retrieve and Rewrite (제안) | 전체 계획 초안 생성 후, 액션 집합에 맞춰 점진적 수정 (삭제/교체/삽입 포함) |
인 도메인 Wiki
| 모델 / 방법 | Task-Retrieve | Plan-Retrieve | Step-wise | Select DFS | Retrieve & Rewrite | 최고 성능 |
| 🔹 GPT-3.5 (API) | 42.65 | 41.78 | 19.82 | 50.17 | 54.60 | ✅ Rewrite |
| 🔸 Vicuna-7B (Open) | 24.97 | 28.74 | 9.03 | 7.03 | 28.17 | ✅ Rewrite |
| 🟢 LLaMA-2-7B (SFT) | 47.37 | 57.70 | 24.22 | 53.04 | 60.51 | ✅ Rewrite |
아웃 도메인 Tools, Robot
| 모델 / 방법 | Task-Retrieve | Plan-Retrieve | Step-wise | Select DFS | Retrieve & Rewrite | 최고 성능 |
| 🔹 GPT-3.5 | 25.23 | 31.65 | 26.79 | 24.92 | 37.87 | ✅ Rewrite |
| 🔸 Vicuna-7B | 15.61 | 12.63 | 10.41 | 11.01 | 17.83 | ✅ Rewrite |
| 🟢 LLaMA-2-7B (SFT) | 39.05 | 38.46 | 29.82 | 16.37 | 44.74 | ✅ Rewrite |
🧠 논문이 평가하는 LLM의 Agentic 능력
| 평가 능력 | 설명 |
| 1. 실행 가능한 계획 생성 (Grounded Planning) | 주어진 액션 라이브러리 내에서만 계획을 세워야 하며, 자연어로만 구성된 자유로운 설명은 허용되지 않음. 즉, 계획의 각 스텝이 실행 가능한 도구/API/로봇 액션이어야 함. |
| 2. 개방형 문제 해결 능력 (Open Domain Generalization) | 사전 정의된 좁은 도메인 대신, 다양한 실생활, 도구 사용, 로봇 환경 등 도메인 불특정 과제에 대해 계획을 생성하는 능력 |
| 3. 전역적 사고 + 단계별 조정 (Global + Local Planning) | 전반적인 계획 구조를 구성한 뒤, 세부 단계에서의 정확한 선택/수정을 통해 계획의 완성도를 높이는 능력 |
🧪 평가 방법
📏 평가 기준 (질적 기준 + 수치화)
| 항목 | 내용 | 구현 방식 |
| Executability | 생성된 모든 스텝이 액션 집합 내에 포함되는가? | 후보 액션 집합과 대조하여 자동 판별 |
| Plan Quality | 다음 세 가지 세부 기준에 따라 평가: 1. Completeness: 누락 없이 전개됨? 2. Feasibility: 실행 가능한가? 3. Relevance: 과업 목표에 적절한가? |
ChatGPT를 통해 생성된 계획과 정답 계획(golden plan)을 비교 평가 |
| Pass Rate | 실행 가능성과 품질을 종합한 최종 점수 | Executability × Quality로 계산됨 |
⚙️ 자동 평가 방식의 보정
- 위치 편향(position bias) 방지: 평가 대상 순서 바꿔가며 평균
- 길이 편향(length bias) 방지: 불필요한 단계는 감점
- ChatGPT 평가 신뢰성: 휴먼 평가와 80.76% 상관관계 (Spearman)로 검증
📈 이 벤치마크를 통해 얻을 수 있는 것
| 항목 | 설명 |
| 🔍 LLM의 진짜 ‘계획 능력’ 진단 | 단순히 자연어로 "그럴듯한 설명"이 아니라 정확한 도구 호출 기반 계획을 생성할 수 있는지를 측정 |
| 🌐 도메인 일반화 능력 확인 | 훈련된 도메인(wikiHow) 외에 도구(API-Bank, ToolAlpaca 등)나 로봇(SayCan, VirtualHome) 시나리오에서도 계획 능력을 전이할 수 있는지 확인 |
| 🔄 단계적 reasoning vs 전역 planning trade-off 분석 | Step-wise, DFS, Retrieve-and-Rewrite 등 다양한 계획 생성 방식의 강점과 한계를 실험적으로 비교 가능 |
| 📊 SFT vs GPT-3.5 등 모델 성능 비교 | 일반 사전학습 모델, 파인튜닝 모델 간의 계획 능력 차이를 정량적으로 비교할 수 있음 |
| 🚧 현행 모델 한계 도출 | hallucination, 실행 불가능 스텝, 반복 등 실제 에이전트 적용 시 발생할 수 있는 구조적 오류 유형 파악 가능 |
평가 항목
평가 방법
얻을 수 있는 것?
'인공지능 > 논문 리뷰 or 진행' 카테고리의 다른 글
| Critic-V: VLM Critics Help Catch VLM Errors in Multimodal Reasoning (2) | 2025.06.17 |
|---|---|
| DrVideo: Document Retrieval Based Long Video Understanding 논문 리뷰 (6) | 2025.06.10 |
| Few-shot 관련 논문 (0) | 2025.05.31 |
| 데이터 기반 질환 예측 논문 정리 - 3 (3) | 2025.05.29 |
| 데이터 기반 질환 예측 논문 정리 - 2 (1) | 2025.05.26 |