https://arxiv.org/abs/2406.12846
DrVideo: Document Retrieval Based Long Video Understanding
Most of the existing methods for video understanding primarily focus on videos only lasting tens of seconds, with limited exploration of techniques for handling long videos. The increased number of frames in long videos poses two main challenges: difficult
arxiv.org
요약
기존 영상 이해 모델은 짧은 영상에 최적화되어 긴 영상에서 핵심 정보 탐색의 어려움과 장기 추론 곤란이라는 문제가 발생함. DrVideo는 긴 비디오를 긴 텍스트 문서로 변환하여 검색을 통해 핵심 프레임을 선택하고, 반복적인 정보 증강과 판단을 통해 최종 추론을 진행하여 전략적으로 긴 영상을 잘 이해하였다.
강점
1. 기존의 비디오 시퀀스 처리 문제가 아닌 텍스트 기반 문서 이해 문제로 재 정의하여 참신한 접근을 보여줌
2. 프레임 변환, 검색, 증강, 에이전트 루프, CoT 추론이라는 모듈화된 구성으로 재현성, 타당성을 높임
3. 학습 없이 작동하는 구조이며, 저 사양에서도 구동가능한 산업적/ 실용적 가치가 큼
약점
1. 검색, 증강, 에이전트 루프, CoT는 이미 존재하는 기술로 단순한 조합으로 여겨질 수 있음
2. 반복 증강이 지나쳐지면 LLM이 불필요한 정보에 의해 틀린 추론을 진행할 수 있는데 그 것에 대한 필터링 여부가 없음.
3. VLM 캡션 품질에 민감하게 반응할 것인데 이에 대한 보완 전략이 충분히 논의되지 않음.
개선 가능점
1. 정보 증강 방식에 Refine, Feedback 과정을 통해 길어지는 노이즈 제거를 통해 정보의 질과 양을 균형으로 자동으로 조절
2. VLM 캡션이 부정확할 경우 Reasoning에 영향을 줄 수 있으므로 검증 모듈을 활용해 첫 캡션에도 품질을 올리는 과정을 진행하여 성능 향상
3. 지금은 개별 프레임 정보가 독립적으로 나열되어 있어 시간적 맥락이나 사건 흐름을 LLM이 추론하는데 한계가 있음. 프레임 간 종속적으로 엮어서 QA 성능을 올리는 프레임 워크 발전
| 모듈 | 설명 |
| ① Video-Document Conversion | 각 프레임/클립을 LLaVA-NeXT 등 VLM을 이용해 텍스트 설명으로 변환 (SVt) |
| ② Document Retrieval | 질문 Q와 문서 내 각 SVt의 임베딩 유사도 기반 top-K 프레임 선택 |
| ③ Document Augmentation | top-K 프레임에 대해 Caption + VQA 정보 추가 (LVt′) |
| ④ Multi-Stage Agent Loop | - Planning Agent: 정보 sufficiency 판단 - Interaction Agent: 부족한 정보 찾고 증강 유형 결정 (caption or VQA)반복 수행 |
| ⑤ Answering Module | 최종 문서를 바탕으로 Chain-of-Thought 방식으로 응답 생성 |

| 🔎 문제 정의 | 기존 영상 이해 모델은 수십 초 내외의 짧은 영상에 최적화됨. 긴 영상(3~60분 이상)은 🔸핵심 정보 탐색 어려움, 🔸장기 추론 곤란이라는 두 가지 문제 발생 |
| 🎯 제안 개요 | DrVideo는 긴 비디오를 긴 텍스트 문서로 변환하여, LLM의 언어 추론 능력을 활용하는 문서 검색 기반 장기 비디오 이해 프레임워크 |
| 🧠 핵심 아이디어 | 비디오를 프레임 단위로 caption화 → 문서로 구성 → 질의와 관련된 핵심 프레임 검색 → 반복적인 정보 증강과 판단을 통해 최종 추론 수행 |
| 📐 아키텍처 구성 | 1. Video-Document Conversion (VLM으로 프레임 → caption) 2. Document Retrieval (질문과 관련된 top-K 프레임 선택) 3. Document Augmentation (caption + VQA 형태 정보 추가) 4. Multi-Stage Agent Loop (planning + interaction agent로 반복 검색) 5. Answering Module (Chain-of-Thought 기반 최종 예측) |
| 🔄 Agent 구조 | - Planning Agent: 현재 문서가 충분한지 판단 - Interaction Agent: 부족할 경우 필요한 프레임과 증강 방식 지정 (A: caption / B: VQA) → 이 루프 반복 후 최종 답변 도출 |
| 📊 실험 성능 (SOTA 초과) | EgoSchema (3분): 66.4% (기존 VideoAgent 대비 +3.6%) MovieChat-1K (10분): Global 93.1%, Breakpoint 56.4% (기존 대비 +24.8%) Video-MME (avg 44분): w/o subs 51.7%, w/ subs 71.7% (GPT-4o, Gemini Flash 능가) |
| 🔍 Ablation 인사이트 | - Retrieval, Agent, CoT 모두 성능 향상에 기여 - 프레임 수 늘릴수록 오히려 성능 하락 (과적재) - Caption/VQA 정보 모두 병행해야 효과적 |
| ⚠️ 한계점 | - LLM의 입력 길이 제한으로 매우 긴 영상 처리에 제약 - 프레임 수 증가시 정보 노이즈 증가 가능성 - VLM의 caption 정확도에 성능이 좌우됨 - zero-shot 구조로 학습 기반 도메인 특화에 한계 |
| 🌟 주요 기여 | ✅ 비디오 → 문서로 전환하여 LLM 최적 활용 ✅ Agent 기반 반복 탐색 구조 설계 ✅ caption + VQA 증강 조합을 통한 정보 정밀화 ✅ CoT로 투명한 추론 추적 가능 ✅ RTX 4090에서 재현 가능한 실용적 프레임워크 제시 |
| 🧪 모델 구성 | - VLM: LaViLa (clip 기반), LLaVA-NeXT (frame 기반) - LLM: GPT-3.5, GPT-4, DeepSeek V2.5 (agent 및 답변에 사용) |
| 🧰 적용 가능성 | - 영상 QA, 코칭 분석, 라이프로그 해석, 감정 분석 등 시간 축 reasoning이 중요한 도메인에 적용 가능 |
| 🧩 총평 | 단순한 요약형 모델과 달리 질문 기반 의미적 정보 선별 + 증강 + 추론을 통합한 장기 영상 이해 프레임워크. 영상 데이터를 NLP로 끌어와 처리하는 전략적 접근법의 대표 사례 |
DrVideo는 긴 비디오의 이해를 ‘문서 검색 기반’ 문제로 변환하여 LLM의 언어 추론 능력을 최대한 활용하는 혁신적인 프레임워크입니다.
🔍 연구 문제
| 항목 | 설명 |
| 🔧 문제점 | 대부분의 비디오 이해 모델은 수십 초 길이의 짧은 영상에만 집중. 긴 영상(수 분~수십 분 이상)은 다음 두 가지 도전 과제 발생: ① 핵심 정보의 위치 식별 어려움 ② 장기적 추론 능력 부족 |
| 🎯 해결 목표 | LLM의 장기 언어 추론 능력을 활용하여 긴 비디오의 내용을 효율적으로 이해하고, 질의에 답변할 수 있는 핵심 정보를 정제하는 방법 고안 |
🧠 핵심 아이디어
- 영상 → 문서 변환: 긴 비디오를 프레임 단위로 자르고, 각 프레임을 자연어 설명으로 변환하여 "초기 문서" 생성
- 문서 검색 기반 키 프레임 식별: 질문과 문서의 임베딩 유사도 기반으로 상위 K개 프레임 선택
- 정보 증강: 선택된 키 프레임에 대해 Caption, VQA 기반 설명 추가
- 다단계 에이전트 루프: 정보가 충분하지 않다고 판단되면, 추가적인 프레임을 찾아서 반복적으로 정보 보강
- 최종 예측: 충분한 정보가 모이면, Chain-of-Thought 기반의 답변 생성
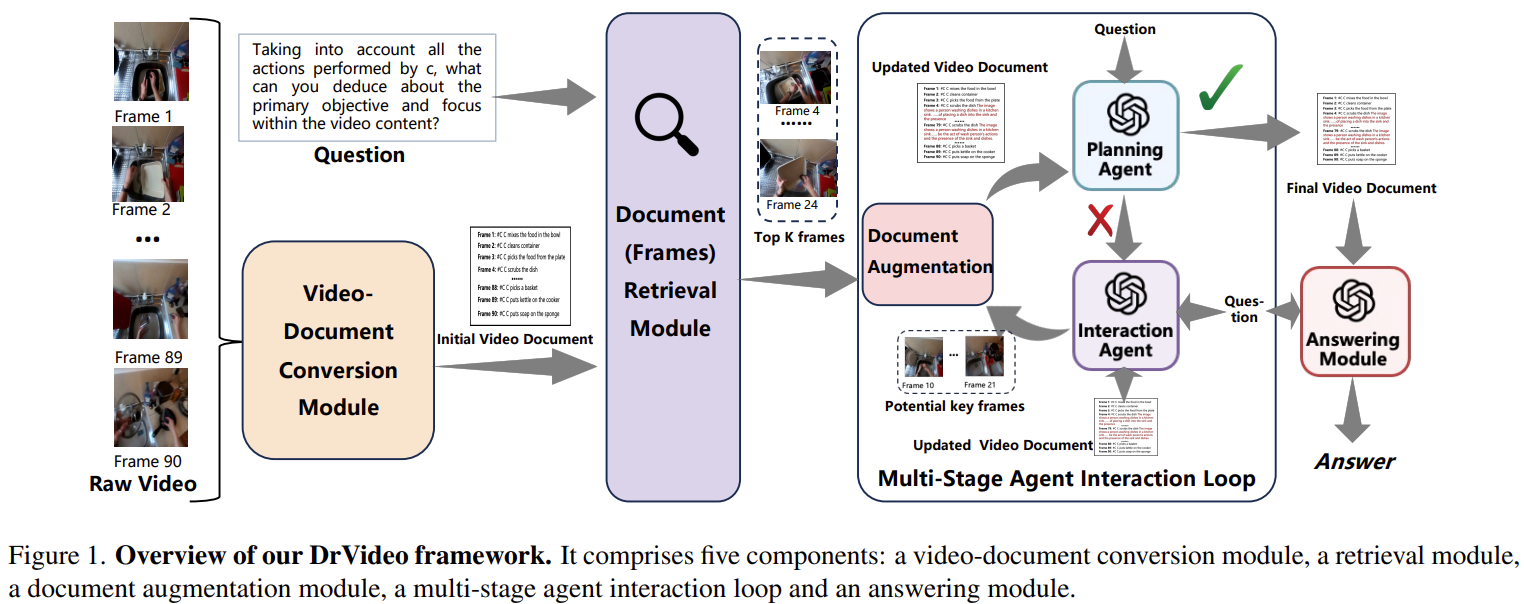
🧩 전체 아키텍처 구성 (Fig. 1)
| 모듈 | 설명 |
| ① Video-Document Conversion | 각 프레임/클립을 LLaVA-NeXT 등 VLM을 이용해 텍스트 설명으로 변환 (SVt) |
| ② Document Retrieval | 질문 Q와 문서 내 각 SVt의 임베딩 유사도 기반 top-K 프레임 선택 |
| ③ Document Augmentation | top-K 프레임에 대해 Caption + VQA 정보 추가 (LVt′) |
| ④ Multi-Stage Agent Loop | - Planning Agent: 정보 sufficiency 판단 - Interaction Agent: 부족한 정보 찾고 증강 유형 결정 (caption or VQA)반복 수행 |
| ⑤ Answering Module | 최종 문서를 바탕으로 Chain-of-Thought 방식으로 응답 생성 |
🧪 실험 및 결과
📊 사용 데이터셋
| 데이터 셋 | 특징 |
| EgoSchema | 3분짜리 비디오 5,000개 + 선택형 질문 (평균 90프레임) |
| MovieChat-1K | 영화/TV 쇼 10분짜리 비디오 1,000개 (Global / Breakpoint 모드) |
| Video-MME | 평균 44분짜리 장기 영상 포함 (30~60분) |
🏆 주요 성능 비교
✅ EgoSchema (Table 1)
| 모델 | Acc. (%) |
| VideoAgent (GPT-4) | 60.2 |
| DrVideo (GPT-3.5) | 62.6 |
| DrVideo (GPT-4) | 66.4 |
✅ MovieChat-1K (Table 2)
| 모델 | Global (%) | Breakpoint (%) |
| VideoAgent | 65.4 | 31.6 |
| DrVideo | 93.1 | 56.4 |
✅ Video-MME (Table 3, w/o subs)
| 모델 | Acc. (%) |
| Claude 3.5 | 51.2 |
| GPT-4o | 65.3 |
| DrVideo | 51.7 (w/o subs) 71.7 (w/ subs) |
🔬 주요 구성 요소 성능 분석 (Ablation, Table 4–7)
| 구성 | 정확도 (%) |
| 모든 구성 포함 (기본) | 62.6 |
| Retrieval 모듈 제외 | 59.4 |
| Agent Loop 제외 | 60.6 |
| CoT 제외 | 62.2 |
→ Retrieval과 Agent Loop가 성능 향상에 핵심 기여
| VLM 종류 | 정확도 (%) |
| LaViLa (clip 기반) | 62.6 |
| LLaVA-NeXT | 61.2 |
| BLIP-2 | 59.6 |
| LLM 종류 | 정확도 (%) |
| GPT-4 | 66.4 |
| GPT-3.5 | 62.6 |
| DeepSeek | 61.2 |
| Mistral | 47.6 |
🧭 결론 및 한계
💡 기여 요약
| 🧠 핵심 전략 | 긴 영상 이해를 문서 검색 + 증강 + 추론 문제로 변환 |
| 🧩 설계 장점 | 영상 전체를 처리하지 않고 핵심 프레임만 증강하여 LLM 입력 최적화 |
| 📈 성능 기여 | 다양한 데이터셋에서 기존 VideoAgent, LLoVi 대비 평균 3~24% 성능 향상 |
⚠️ 한계
- 최대 입력 토큰 수에 따라 처리 가능한 비디오 길이에 제한 있음
- 정보 증강 시 불필요한 내용이 포함되면 오히려 성능 저하 가능
- VLM/LLM의 품질에 크게 의존
✅ 한눈에 정리된 표
| 🔧 문제 | 긴 영상에서 핵심 정보를 찾고 장기 추론하기 어려움 |
| 💡 제안 | 문서 검색 + 증강 기반 영상 이해 프레임워크 DrVideo |
| 🧱 구성 | Video-to-Text 변환 → 문서 검색 → 증강 → 다단계 Agent → CoT 기반 답변 |
| 🔍 장점 | LLM 추론 능력 활용, 정보 손실 최소화, 확장성 우수 |
| 📊 성능 | EgoSchema: 66.4%, MovieChat-1K: 93.1%, Video-MME(w/ subs): 71.7% |
| ⚠️ 한계 | LLM/VLM 의존성, 길이 제한, 정보 과적재 가능성 |
🔍 DrVideo 관련 연구 분류
| 범주 | 주요 내용 |
| 1. Long Video Understanding | 긴 시간의 영상에 대한 정보 추출 및 추론을 다룸 |
| 2. LLM 기반 비디오 질의응답 (Video-QA) | 비디오의 텍스트/비주얼 내용을 바탕으로 LLM이 질문에 답변 |
| 3. LLM 기반 멀티모달 에이전트 (LLM Agents) | LLM이 모듈간 인터랙션 및 추론에 에이전트처럼 작동 |
| 4. 비디오 → 문서 변환 방식 | 영상을 클립/프레임 단위로 자르고, 텍스트로 변환 후 NLP 방식 적용 |
| 5. 문서 검색 기반 정보 회수 (Document Retrieval) | 질문과 관련된 정보를 텍스트 문서 내에서 검색, 정제하여 사용 |
| 6. 정보 증강 및 CoT 추론 | 문서의 부족한 정보 보완 → 체인 오브 사고 (CoT)로 추론 |
| 7. 프레임 선택 및 샘플링 전략 | 영상에서 핵심 프레임을 선택해 압축 표현 구성 |
📚 주요 관련 논문 요약
1. LLoVi (2023, arXiv:2312.17235)
- 방법: 영상 → 클립으로 나눈 후 간단한 캡션 생성 → 요약 후 질문에 답변
- 한계: 핵심 정보 누락, 상세 정보 부족
- DrVideo와 차이: 문서 증강 및 Agent Loop 부재 → 질문 관련 세부 추출 불가능
2. VideoAgent (2024, arXiv:2403.10517)
- 방법: LLM이 프레임을 찾아내고 CLIP 기반 이미지-텍스트 유사도로 프레임 회수
- 한계: CLIP 기반 coarse-to-fine 방식의 한계, 문서 전체 파악 부족
- DrVideo와 차이: 정형화된 retrieval + document augmentation loop로 정밀한 추론
3. MovieChat / MovieChat+ (2023–2024)
- 방법: Sparse memory를 유지하며 문맥 추론, 질문 관련 segment에 집중
- 한계: 시나리오 기반 QA만 가능, 장기 reasoning 어려움
- DrVideo와 차이: 프레임 기반 문서화 + 에이전트 기반 iterative 증강을 통해 더 강한 추론 가능
4. S4ND / ViS4mer / S5 (2023)
- 방법: Structured State Space (S4) 기반 비디오 시퀀스 모델링
- 한계: 비디오 직접 처리 방식으로 학습 비용 큼, zero-shot 어려움
- DrVideo와 차이: S4는 구조 기반 모델 설계, DrVideo는 LLM-friendly 방식으로 간접 이해
5. GPT-Video-LLM (MM-VID) (2023)
- 방법: GPT-4V 기반으로 비디오를 이해하며, 명시적 샘플링 없이 전체 내용을 요약
- 한계: 고가의 프로프라이어터리 모델 의존, 공개 재현 어려움
- DrVideo와 차이: 오픈 소스 VLM + 모듈화된 증강 방식으로 재현 가능성 강조
🧩 DrVideo의 차별점 요약
| 항목 | 기존 연구 | DrVideo |
| 프레임 선택 | 샘플링 또는 CLIP 유사도 | 질문 기반 문서 임베딩 유사도 |
| 문서 증강 | 없음 또는 요약 중심 | Caption + VQA 병렬 증강 |
| 정보 탐색 | 단순 self-loop 또는 정해진 프레임 | 에이전트 기반 인터랙션 반복 (Planning + Interaction) |
| 추론 방식 | 직접 요약 → 답변 | CoT 기반 문서 최적화 후 답변 |
| 확장성 | 영상 길이 제약 많음 | 문서 기반 전환으로 상대적 확장 용이 |
| 재현 가능성 | 낮음 (대부분 클로즈드 모델 사용) | GPT-3.5 + LLaVA 기반으로 연구자 친화적 설계 |
📌 마무리
DrVideo는 기존 LLM 기반 비디오 이해 모델의 한계를 다음과 같이 보완합니다:
- 단순 캡션 요약 → 정보 검색 + 증강 + 에이전트 협업으로 진화
- 영상 문제를 문서 문제로 재정의함으로써 LLM의 강점을 최대 활용
- 재현 가능성과 학습 효율을 모두 고려한 모듈 설계
논문《DrVideo: Document Retrieval Based Long Video Understanding》의 방법론은 긴 비디오를 효과적으로 이해하기 위해 LLM 기반 문서 검색/증강/추론 시스템으로 변환하는 것입니다. 기존 방식과의 차별점은, 비디오 자체를 직접 다루는 대신, 비디오를 텍스트 문서로 변환하여 LLM의 언어 이해 능력을 활용한다는 데 있습니다.
🧠 DrVideo 전체 구조 요약 (Fig.1 기반)
DrVideo는 총 5개 모듈로 구성되어 있습니다:
1. Video-Document Conversion
2. Document Retrieval
3. Document Augmentation
4. Multi-Stage Agent Interaction Loop
5. Answering Module
1️⃣ Video-Document Conversion (비디오 → 텍스트 문서 변환)
- 입력: 긴 비디오 (예: 3분짜리 영상 = 90프레임)
- 출력: 프레임별 간략한 텍스트 설명을 묶은 “초기 문서” (Doc_init)
- 사용 모델: LaViLa (clip 기반), LLaVA-NeXT (frame 기반) 등 VLM 사용
🧾 예시:
| Frame 1 | 한 여성이 펜을 들고 있음 |
| Frame 2 | 사람이 카드를 확인하고 있음 |
| Frame 3 | 카드가 열리고 있음 |
| ... | ... |
2️⃣ Document Retrieval (문서 내 핵심 프레임 추출)
- 목표: 질문 Q와 관련된 텍스트 설명(프레임)을 찾음
- 방법: 질문과 각 프레임 설명을 OpenAI Embedding 모델을 사용해 벡터화 → 코사인 유사도로 가장 관련 높은 상위 K개 프레임 선택
📌 예시 질문:
"C는 무엇을 하고 있었는가?"
→ 질문 벡터와 90개 프레임 설명 벡터 비교 → 상위 5개 프레임 선택 (예: Frame 15, 24, 59, 84, 86)
3️⃣ Document Augmentation (핵심 프레임 정보 보강)
- 목표: 선택된 프레임들의 정보를 Caption + VQA 형태로 정밀 보강
- 방법: 각 프레임에 대해 아래 두 유형 중 적절한 프롬프트를 사용하여 VLM에 요청
| 정보 | 타입 설명 |
| A (Caption) | 해당 이미지에 대한 상세 설명 요청 |
| B (VQA) | 질문에 대한 응답 요청 |
🎯 예시:
- Frame 15: A타입 → "책상에 앉아 컴퓨터를 사용하는 사람이 보입니다. 마우스를 움직이고 있습니다."
- Frame 24: B타입 → "질문: C는 무엇을 하고 있었는가?" → "C는 작업 공간을 정리하고 컴퓨터를 시작하려는 중입니다."
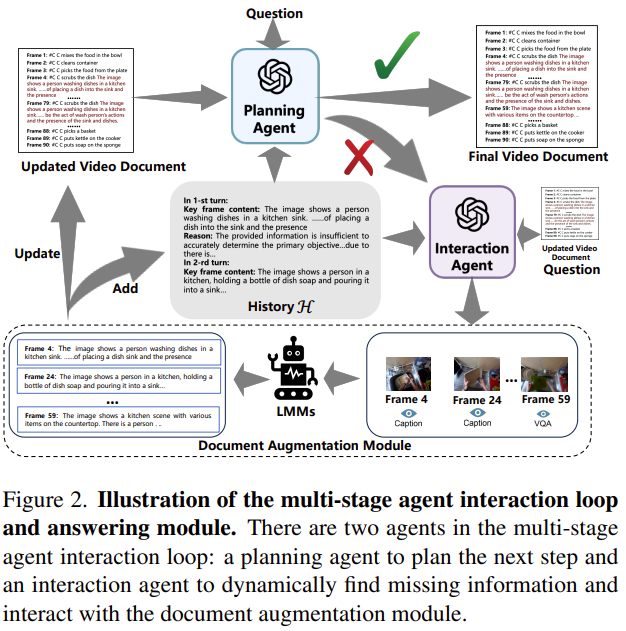
4️⃣ Multi-Stage Agent Interaction Loop (다단계 에이전트 정보 탐색 반복)
이 모듈이 DrVideo의 핵심 차별화 포인트입니다.
| 역할 | 설명 |
| Planning Agent | 지금까지 수집한 정보가 질문을 답하는 데 충분한지 판단 |
| Interaction Agent | 부족한 경우 어떤 프레임에서 어떤 정보가 필요한지 판단하여 요청 |
🔁 이 과정을 반복하여 문서 정보 품질을 높임 (예: 최대 2~3회 반복)
📦 예시:
- Planning Agent: "아직 정보 부족함. C가 어떤 작업을 했는지 추가 프레임 필요."
- Interaction Agent: "Frame 4, 14, 19에 VQA 타입 정보 요청 필요"
- Augmentation 수행 → 문서 업데이트 → 재판단
5️⃣ Answering Module (최종 예측)
- 입력: 최종 업데이트된 비디오 문서 + 질문
- 방법: GPT 기반 LLM이 Chain-of-Thought(CoT) 방식으로 추론
- 출력: 선택지 중 정답 + 신뢰도(1~3) + 한 줄 설명
🧾 예시:
질문: "C의 전반적인 목표는 무엇인가?"
- 답변: A (작업 공간을 설정하고 컴퓨터로 작업 시작)
- Confidence: 3
- 설명: “프레임 15, 59, 84에서 C가 노트북을 세팅하고 키보드를 조작하는 모습이 확인됨”
📌 요약 알고리즘 (Pseudocode 참고)
Doc_init = video_to_text(V, frame_caption_model)
topK = retrieve_top_frames(Doc_init, question_embedding)
for frame in topK:
Doc_aug = augment_frame_info(frame, type='caption or VQA')
while not planning_agent(Doc_aug).is_sufficient():
missing_frames = interaction_agent(Doc_aug).find_missing()
for frame in missing_frames:
Doc_aug = augment_frame_info(frame)
final_answer = answer_module(Doc_aug, question)
🔬 이 방식의 장점
| 기존 방식 | DrVideo |
| 영상 자체를 CLIP 등으로 직접 처리 | 텍스트 문서로 변환하여 LLM이 쉽게 처리 |
| 단순 캡션 → 요약 → 답변 | 핵심 프레임 탐색 + 증강 → 반복적 판단 후 추론 |
| Key 정보 누락 많음 | Retrieval + Agent로 누락 정보 보완 |
| LLM의 reasoning 능력 활용 부족 | CoT로 명시적 추론 과정 가시화 |
🧠 전문가 인사이트 요약
DrVideo는 영상 이해 문제를 NLP 문제로 변환하여, 정보 회수(Retrieval) + 증강(Augmentation) + 반복적 판단(Planning & Interaction Agents) + CoT 기반 추론으로 이어지는 LLM 최적화 파이프라인을 구축했습니다.
이는 단지 모델 성능을 높인 것을 넘어, 영상 AI와 언어 모델의 접점을 구조화된 방식으로 다룬 강력한 설계 방식이라 볼 수 있습니다.
다음은 논문 "DrVideo: Document Retrieval Based Long Video Understanding"의 결과, 결론, 한계점, 기여를 종합적으로 정리한 내용입니다.
✅ 1. 주요 실험 결과 요약 (Main Results)
DrVideo는 세 개의 대표적인 장기 영상 QA 벤치마크에서 기존 SOTA (state-of-the-art) 방법들을 압도하는 성능을 보였습니다.
| 데이터 셋 | 특징 | 성능 비교 |
| EgoSchema | 3분짜리 egocentric 비디오 + 선택형 문제 (500개 subset) | DrVideo (GPT-4): 66.4% 기존 최고 (VideoAgent): 62.8% |
| MovieChat-1K | 영화/TV쇼 10분 영상 (Global / Breakpoint 모드) | Global: 93.1% 기존 최고 (VideoAgent): 65.4% Breakpoint: 56.4% (기존 31.6%) |
| Video-MME (long) | 평균 44분짜리 비디오, subtitle + 멀티모달 질의 포함 | DrVideo: 51.7% (no subtitles)71.7% (w/ subtitles) → GPT-4o, Gemini Flash, Claude 3.5보다 높음 |
🔍 Ablation 분석 요약:
| 기본 (RM+Agent+CoT) | 62.6% |
| Agent loop 제거 | 60.6% |
| Retrieval 제거 | 59.4% |
| CoT 제거 | 62.2% |
| Caption만 | 60.4% |
| VQA만 | 61.8% |
🧠 2. 결론 (Conclusion)
- DrVideo는 장기 영상 이해를 문서 기반 추론 문제로 전환하는 프레임워크로서, 기존의 단순 프레임 샘플링이나 요약 방식의 한계를 극복함.
- 에이전트 기반 반복 인터랙션과 정보 증강 설계를 통해 질문과 관련된 핵심 정보만을 선택적으로 정제하고, Chain-of-Thought 방식으로 LLM의 추론을 강화함.
- 다양한 데이터셋에서 기존 LLM + Video 모델보다 높은 정확도와 적은 반복 횟수로 정답에 도달하는 효율성을 보임.
- 특히 subtitles와 결합 시 강력한 성능을 나타내어, 멀티모달 정보 통합 방식의 가능성을 시사함.
⚠️ 3. 한계점 (Limitations)
| 🔸 LLM 토큰 길이 제한 | 문서 기반 처리 방식이기 때문에 최종 생성된 문서 길이가 LLM의 token limit을 초과하면 성능 하락 가능. (긴 비디오 예: 10시간 이상) |
| 🔸 정보 과적재 위험 | 너무 많은 프레임을 증강하거나 반복적으로 추가할 경우, LLM에 노이즈 정보가 포함되어 오히려 성능 저하 발생 (반복 횟수 2회 초과 시 정확도 감소) |
| 🔸 VLM 품질 의존 | Caption/VQA 정보를 생성하는 VLM (예: LaViLa, LLaVA-NeXT)의 품질에 매우 민감. 잘못된 caption이 누적되면 판단 오류 발생 |
| 🔸 학습 불가능 (Training-free) | 현재는 파인튜닝 없이 작동하는 구조지만, 도메인 특화 문제나 추론 구조 학습은 어려움 |
🌟 4. 기여 (Contributions)
| 🧠 문제 재정의 | 장기 비디오 이해를 영상 자체의 시퀀스 모델링이 아닌 텍스트 문서 기반 LLM reasoning 문제로 변환 |
| 🔍 검색 기반 추론 | 질문과 연관된 프레임을 유사도 기반 검색 + 증강하여 핵심 정보만 선별, 압축 |
| 🧩 다단계 Agent 설계 | Planning Agent + Interaction Agent로 구성된 루프를 통해 필요한 정보만 점진적으로 탐색 |
| 🔗 Chain-of-Thought 결합 | CoT 기반 reasoning을 마지막 단계에 적용하여 투명하고 해석 가능한 추론 과정 제공 |
| 🧪 우수한 성능 및 효율 | 여러 벤치마크에서 SOTA 초과, 적은 에이전트 반복 횟수로 효율성 + 정밀성 확보 |
| 🛠️ 재현성 강조 | GPT-3.5 + LLaVA 기반으로 구성되어 연구자 친화적이며 RTX 4090에서도 재현 가능 |
📌 핵심 요약 표
| 📍 문제 정의 | 긴 비디오에서 핵심 정보 추출 및 질문 응답 |
| 🛠️ 제안 기법 | 문서 검색 기반 프레임워크 + 에이전트 루프 + CoT |
| 📊 성능 | EgoSchema, MovieChat-1K, Video-MME에서 기존 방법 대비 최고 성능 |
| 🧠 기여 | 비디오 이해를 텍스트 기반 reasoning 문제로 재정의한 첫 모델 |
| ⚠️ 한계 | 토큰 길이, VLM 품질, 반복 과적재, 학습 불가능 |
| 💡 의의 | 단순 캡션-요약 방식을 넘어서 LLM reasoning 능력 최대 활용한 구조적 장기 영상 이해 방식 제안 |
필요하시면 해당 내용을 기반으로 논문 발표용 슬라이드 / 요약 포스터 형태로도 재구성해 드릴 수 있습니다.
'인공지능 > 논문 리뷰 or 진행' 카테고리의 다른 글
| Context Generation 후 Answer Generation! - Generate rather than Retrieve: Large Language Models are Strong Context Generators (3) | 2025.06.30 |
|---|---|
| Critic-V: VLM Critics Help Catch VLM Errors in Multimodal Reasoning (2) | 2025.06.17 |
| UltraTool, Open Grounded Planning 정리 (0) | 2025.06.09 |
| Few-shot 관련 논문 (0) | 2025.05.31 |
| 데이터 기반 질환 예측 논문 정리 - 3 (3) | 2025.05.29 |