https://arxiv.org/abs/2305.10601
Tree of Thoughts: Deliberate Problem Solving with Large Language Models
Language models are increasingly being deployed for general problem solving across a wide range of tasks, but are still confined to token-level, left-to-right decision-making processes during inference. This means they can fall short in tasks that require
arxiv.org
Few-Shot -> CoT -> SC-CoT -> ToT에 이르는 논문입니다.
2025.02.05 - [인공지능/논문 리뷰 or 진행] - Language Models are Few-Shot Learners - 논문 리뷰
Language Models are Few-Shot Learners - 논문 리뷰
https://arxiv.org/abs/2005.14165 Language Models are Few-Shot LearnersRecent work has demonstrated substantial gains on many NLP tasks and benchmarks by pre-training on a large corpus of text followed by fine-tuning on a specific task. While typically tas
yoonschallenge.tistory.com
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models - 논문 리뷰
https://arxiv.org/abs/2201.11903 Chain-of-Thought Prompting Elicits Reasoning in Large Language ModelsWe explore how generating a chain of thought -- a series of intermediate reasoning steps -- significantly improves the ability of large language models t
yoonschallenge.tistory.com
Self-Consistency Improves Chain of Thought Reasoning in Language Models
https://arxiv.org/abs/2203.11171 Self-Consistency Improves Chain of Thought Reasoning in Language ModelsChain-of-thought prompting combined with pre-trained large language models has achieved encouraging results on complex reasoning tasks. In this paper,
yoonschallenge.tistory.com
프롬프트의 기본이 부족하다고 느껴 정리를 하다 보니 조금씩은 이해가 되는 느낌입니다.

ToT에서는 생각을 이렇게 분리해내는 것이 중요하다.
분해한 생각에서 다시 여러 방향을 생각하고, 상태를 평가하며 검색도 진행해야 한다.
이러한 4단계가 매끄럽게 진행되어야 ToT는 성공적으로 이루어질 수 있다.

적절하게 너무 크지도, 작지도 않게 문제를 단계적으로 나누어 풀어야 합니다.
여기서 생각의 가지를 만드는 법은 독립적, 순차적으로 나누어서 생성하고, 만들어진 가지들은 상태 평가를 통해 계속 이어집니다. 그리고 BFS혹은 DFS 방식을 선택하여 진행하게 됩니다.

24게임의 결과로 보아 ToT가 가장 우수한 것을 볼 수 있습니다.
또한 CoT에서는 많은 오류가 나는 것도 볼 수 있다.
이렇듯 ToT는 수 많은 장점을 가지고 있습니다.
다음번에는 ToT의 코드를 확인하고, 다양한 연구 방법으로 생각해봐야겠네요
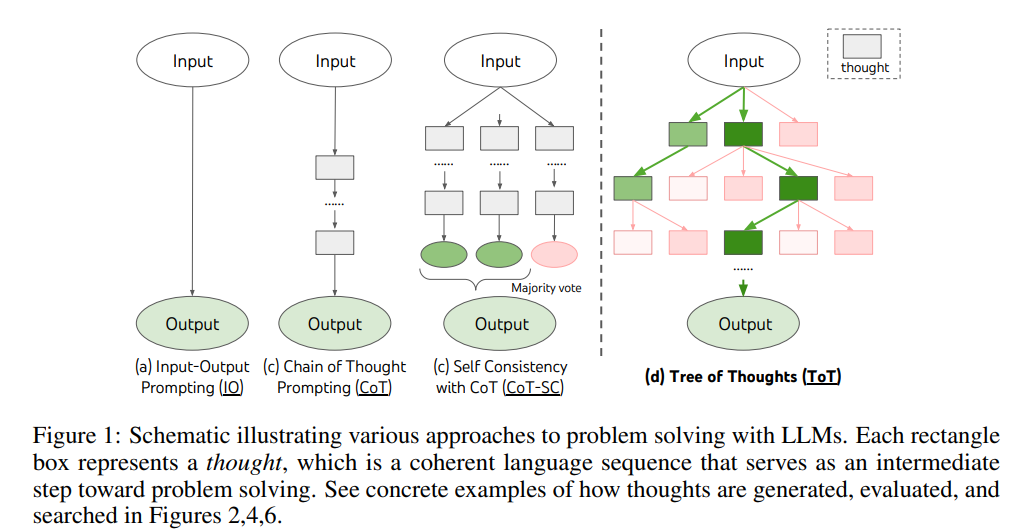
| 📖 연구 목표 | 기존 LLM(대형 언어 모델)의 토큰 단위 좌우 예측 방식의 한계를 극복하여, 탐색·전략적 사고가 가능한 문제 해결 구조를 도입 | CoT(Chain of Thought) 방식은 단계별 사고를 제공하지만, 탐색·백트래킹이 불가능 |
| 🔍 ToT 개념 | LLM을 트리 기반 탐색 구조로 변환하여, 여러 경로를 탐색하며 최적의 문제 해결 방안을 선택 | 게임 "24 만들기"에서 다양한 수식 조합을 평가하고 최적의 해를 선택 |
| 🧩 기존 방식과 비교 | IO Prompting (입력-출력 직접 매핑), CoT (단일 경로 사고), CoT-SC (다양한 사고 경로 후 다수결) | CoT-SC는 다양한 사고 과정 중 가장 빈도 높은 답을 선택, ToT는 다양한 경로를 평가 후 최적 경로 선택 |
| 🌳 ToT의 4단계 | (1) 사고 단계 분해 → (2) 사고 생성 → (3) 상태 평가 → (4) 탐색 알고리즘 선택 | 창의적 글쓰기에서는 문단별 사고 단계, 수학 문제에서는 수식별 사고 단계 |
| 1️⃣ 사고 단계 분해 (Thought Decomposition) | 문제를 해결하기 위한 단계별 사고(thought) 구성 | 창의적 글쓰기: 문단 단위 / 게임 "24 만들기": 연산 단계별 |
| 2️⃣ 사고 생성기 (Thought Generator, G) | 다음 사고 단계에서 가능한 선택지를 생성 | i.i.d. 샘플링: 독립적 선택지 제공 (창의적 문제 적합) / 순차적 샘플링: 문맥 유지하며 선택지 제공 (수학 문제 적합) |
| 3️⃣ 상태 평가 (State Evaluator, V) | 생성된 사고를 평가하여 최적의 경로를 선택 | 수치 평가 (Value Scoring): "이 연산이 24를 만들기에 적절한가?" / 투표 (Voting): "이 문장이 가장 자연스러운가?" |
| 4️⃣ 탐색 알고리즘 (Search Algorithm) | BFS(너비 우선 탐색) 또는 DFS(깊이 우선 탐색)로 문제 해결 과정 최적화 | BFS: 다양한 가능성을 먼저 탐색 (창의적 문제 적합) / DFS: 특정 경로를 깊이 탐색 (논리적 문제 적합) |
| 🆚 i.i.d. 샘플링 vs. 순차적 샘플링 | i.i.d. 샘플링: 여러 개의 독립적 사고를 한 번에 생성 (창의적 문제) 순차적 샘플링: 특정 경로를 따라가며 여러 개의 선택지를 생성 (논리적 문제) |
i.i.d. 샘플링: 다양한 문장을 시작으로 창의적 글쓰기 / 순차적 샘플링: "24 만들기"에서 단계별 연산 선택 |
| 🆚 ToT vs. BFS/DFS | ToT의 사고 생성 방식과 BFS/DFS는 탐색 전략이 다름 | BFS/DFS는 탐색 방식, ToT의 샘플링(i.i.d./순차적)은 사고 생성 방식 |
| 🔬 실험 결과 | Game of 24: GPT-4 + CoT (4%) → ToT (74%) 창의적 글쓰기: ToT 사용 시 일관성 증가 (GPT-4 평가 7.56점) 크로스워드 퍼즐: 단어 정답률 60% |
ToT는 CoT 대비 문제 해결 성능 대폭 향상 |
| 📌 최종 결론 | ToT는 기존 LLM 방식(CoT)보다 더 나은 탐색 및 의사결정 능력을 제공하며, 다양한 문제 해결에 적용 가능 | 창의적 문제, 수학 문제, 크로스워드 등 다양한 분야에 적용 가능 |
1. 연구 배경 및 문제 정의
현재 대형 언어 모델(LLM)은 다양한 문제 해결 능력을 갖추고 있지만, 여전히 토큰 단위의 좌에서 우 방향의 결정 방식에 의존하고 있다. 이러한 방식은 탐색(exploration), 전략적 예측(planning), 초기 결정의 중요성 고려 등의 요소가 필요한 문제에서는 한계를 드러낸다.
연구진은 이러한 한계를 극복하기 위해 "Tree of Thoughts (ToT)" 프레임워크를 제안했다. 이는 기존의 Chain of Thought (CoT) 방식보다 일반화된 형태로, LLM이 스스로 여러 경로를 탐색, 자신의 선택을 평가, 전략적으로 앞을 내다보거나 되돌아가는(backtracking) 기능을 수행할 수 있도록 한다.
2. 기존 접근법 및 한계
기존 LLM 기반 문제 해결 방식은 다음과 같은 방법으로 수행된다:
(1) IO Prompting (입력-출력 방식)
- 단순히 입력을 받아 출력을 생성하는 방식.
- 맥락적 추론이 필요한 문제에는 한계가 있음.
(2) Chain of Thought (CoT)
- 중간 사고 과정(thought)을 명시적으로 생성하여 복잡한 문제를 해결.
- 그러나 한 번 선택한 사고 경로에서 벗어날 수 없으며, 잘못된 경로를 수정할 수 있는 능력이 부족함.
(3) Self-Consistency with CoT (CoT-SC)
- 여러 개의 CoT 샘플을 생성한 후, 다수결을 통해 최적의 답을 선택.
- 하지만 중간 사고 단계에서 대안적 선택지를 고려하는 기능은 부족함.
3. Tree of Thoughts (ToT) 프레임워크
ToT는 LLM을 활용한 문제 해결을 트리 탐색(tree search) 방식으로 확장한다.
(1) 트리 구조의 개념
- 각 노드는 현재까지의 부분적인 해결 상태(state) 를 나타냄.
- 브랜치는 새로운 사고 단계(thought)를 나타내며, 문제 해결 방향성을 제시.
- 각 단계에서 LLM은 여러 가지 대안적인 사고(thoughts) 를 생성하고 평가하여, 최적의 경로를 선택.
(2) 주요 구성 요소
- 사고 단계 분해 (Thought Decomposition)
- 문제에 따라 적절한 중간 사고 단위를 정의.
- 예를 들어, 수학 문제는 수식 단위, 글쓰기는 문단 단위로 설정.
- 사고 생성기 (Thought Generator, G)
- LLM을 사용하여 다음 단계에서 가능한 k개의 후보 사고를 생성.
- 독립적으로 샘플링하거나, 연속적으로 제안할 수 있음.
- 상태 평가 (State Evaluator, V)
- 생성된 사고를 평가하여 문제 해결에 유용한지 판단.
- LLM이 자체적으로 평가하거나, 후보들 중에서 투표(voting) 방식으로 최선의 사고를 선택.
- 탐색 알고리즘 (Search Algorithm)
- BFS (너비 우선 탐색): 일정한 너비(b)를 유지하며 여러 가지 경로를 탐색. (e.g., Game of 24, Creative Writing)
- DFS (깊이 우선 탐색): 가장 유망한 경로를 우선 탐색하며, 해결이 어려울 경우 백트래킹. (e.g., Mini Crosswords)
4. 실험 및 성능 평가
ToT의 효과를 검증하기 위해 세 가지 어려운 과제를 설정하였다.
(1) Game of 24 (수학적 문제 해결)
- 주어진 4개의 숫자로 24를 만드는 연산을 찾는 문제.
- GPT-4를 사용한 CoT는 성공률 4%에 불과했으나, ToT는 74%의 성공률을 기록.
| 방법 | 성공률 |
| IO Prompting | 7.3% |
| CoT Prompting | 4.0% |
| CoT-SC (k=100) | 9.0% |
| ToT (b=1) | 45% |
| ToT (b=5) | 74% |
| IO + Refine (k=10) | 27% |
| IO (best of 100) | 33% |
| CoT (best of 100) | 49% |
→ 결과: ToT는 기존 방법 대비 압도적인 성능 향상!
(2) Creative Writing (창의적 글쓰기)
- 4개의 랜덤 문장이 주어지면, 이를 문단 구조로 자연스럽게 연결하는 글을 작성하는 문제.
- GPT-4를 활용하여 글의 일관성을 평가하는 자동 점수(GPT-4 Score) 와 사람의 주관적 평가(human preference test) 를 활용하여 비교.
| 방법 | 평균 GPT-4 Score |
| IO Prompting | 6.19 |
| CoT Prompting | 6.93 |
| ToT | 7.56 |
| IO + Refine | 7.67 |
| ToT + Refine | 7.91 |
- 인간 평가에서도 41%의 경우 ToT를 선호, 21%는 CoT를 선호, 38%는 비슷하다고 응답.
→ 결과: ToT가 가장 높은 일관성을 보이며, CoT 대비 창의적인 글쓰기에서 우수한 성능을 발휘.
(3) Mini Crosswords (미니 크로스워드 퍼즐)
- 5x5 크로스워드 퍼즐을 푸는 문제.
- 단어 제약을 고려하여 DFS 방식으로 탐색 수행.
| 방법 | 글자 정답률(%) | 단어 정답률(%( | 퍼즐 완전 해결(%) |
| IO Prompting | 38.7 | 14 | 0 |
| CoT Prompting | 40.6 | 15.6 | 1 |
| ToT | 78 | 60 | 20 |
| ToT (best state 선택) | 82.4 | 67.5 | 35 |
| ToT (pruning 제거) | 65.4 | 41.5 | 5 |
| ToT (백트래킹 제거) | 54.6 | 20 | 5 |
→ 결과: ToT는 단어 정답률에서 4배 이상의 성능 향상을 보이며, CoT 대비 큰 개선 효과를 보임.
5. 결론 및 미래 연구 방향
(1) 연구 결론
- 기존의 CoT 방식이 단순한 연속적 사고 전개에 그쳤다면, ToT는 보다 구조적이고 체계적인 문제 해결이 가능하도록 한다.
- BFS 및 DFS를 적용하여 탐색 및 평가를 결합한 방식으로 다양한 문제에 적용할 수 있다.
(2) 향후 연구 방향
- 더 복잡한 문제 적용
- ToT는 상대적으로 간단한 문제에서 강력한 성능을 보였으므로, 향후 코딩 문제, 로봇 제어, 데이터 분석 등 실용적인 문제에 적용 가능.
- LLM 학습에 활용
- ToT 방식을 활용하여 모델 학습 과정 자체를 최적화할 가능성 탐색.
- 비용 효율성 개선
- 현재 ToT는 일반 CoT보다 연산량이 많음. 효율적인 탐색 전략을 통해 비용 절감 연구 필요.
6. 최종 평가
Tree of Thoughts(ToT)는 기존 CoT 방식의 단점을 보완하여 대형 언어 모델의 문제 해결 능력을 크게 향상시키는 혁신적인 접근법이다. 앞으로 AI 에이전트 개발 및 다양한 실세계 문제 해결에 매우 유용할 것으로 기대된다.
Tree of Thoughts (ToT)의 4단계
ToT는 LLM을 활용한 문제 해결 방식을 트리 탐색(tree search) 방식으로 확장하는 프레임워크다. 이를 구현하는 과정에서 LLM이 스스로 여러 경로를 탐색, 자신의 선택을 평가, 전략적으로 앞을 내다보거나 되돌아가는(backtracking) 기능을 수행할 수 있도록 한다.
이를 위해 ToT는 네 가지 핵심 과정을 포함한다:
- 사고 단계 분해 (Thought Decomposition)
- 사고 생성기 (Thought Generator, G)
- 상태 평가 (State Evaluator, V)
- 탐색 알고리즘 (Search Algorithm)
1. 사고 단계 분해 (Thought Decomposition)
✔ 어떤 방식으로 문제를 해결할지 결정하는 단계
- 문제를 여러 개의 사고(thought) 단계로 나누어 해결.
- 각 사고 단계는 적절한 크기여야 함:
- 너무 작으면 (ex: 단일 토큰) 의미 있는 평가가 어려움.
- 너무 크면 (ex: 전체 문단) 탐색이 비효율적임.
🔹 예시: 게임 "24 만들기"
👉 입력: 4, 9, 10, 13 (연산을 이용해 24 만들기)
👉 사고 단계 예시:
- 첫 번째 연산: 13 - 9 = 4 (남은 숫자: 4, 4, 10)
- 두 번째 연산: 10 - 4 = 6 (남은 숫자: 4, 6)
- 세 번째 연산: 4 × 6 = 24 🎯 (성공)
🔹 예시: 창의적 글쓰기(Creative Writing)
👉 입력: 4개의 랜덤 문장을 포함하는 이야기 작성
👉 사고 단계 예시:
- 첫 번째 문단의 주제 설정
- 두 번째 문단에서 이야기 전개
- 세 번째 문단에서 갈등 생성
- 네 번째 문단에서 결론 맺기
2. 사고 생성기 (Thought Generator, G)
✔ 다음 사고(thought) 단계에서 가능한 선택지를 생성하는 과정
- 한 번에 여러 개의 대안을 만들고 탐색함.
- 2가지 방법이 있음:
- 독립적(i.i.d.) 샘플링: 다양한 가능성을 제공 (창의적 문제에 적합)
- 순차적(propose prompt) 샘플링: 단계별로 제안하며 탐색 (수학 문제, 크로스워드에 적합)
🔹 예시: "24 만들기"
👉 가능한 사고 후보들:
- (13 - 9) = 4 or (10 - 4) = 6
- 4 × 6 = 24 or 4 + 6 = 10
👉 LLM은 여러 후보를 생성한 후, 최적의 것을 선택해 진행!
3. 상태 평가 (State Evaluator, V)
✔ 생성된 사고(thought)가 좋은 선택인지 판단하는 과정
- "이 상태가 문제 해결에 얼마나 유용한가?"를 평가
- 평가 방식 2가지:
- 수치 평가(value scoring): 각 상태에 점수를 부여
- 투표(voting): 여러 개의 대안을 비교하여 최적의 것 선택
🔹 예시: "24 만들기"에서 상태 평가
👉 현재 상태: 13 - 9 = 4 (남은 숫자: 4, 4, 10)
👉 평가 방식:
- ✔ "4와 10은 곱하면 24에 가까우니 유망하다" → 높은 점수
- ❌ "4와 4는 연산이 제한적이므로 가능성이 낮다" → 낮은 점수
LLM이 이러한 상태 평가를 수행하여 "좋은 경로"를 선택하도록 한다.
4. 탐색 알고리즘 (Search Algorithm)
✔ LLM이 어떤 방식으로 문제를 탐색할지 결정하는 과정
- 트리 탐색 방식 적용:
- BFS (너비 우선 탐색)
- DFS (깊이 우선 탐색)
🔹 예시: BFS vs DFS 비교
(1) BFS (너비 우선 탐색)
- 여러 가지 사고 경로를 동시에 탐색.
- 적절한 선택을 남기고 나머지는 가지치기.
- 사용 예시: 창의적 글쓰기, 24 만들기 (초기 선택 중요)
(2) DFS (깊이 우선 탐색)
- 한 가지 경로를 끝까지 탐색 후, 실패하면 되돌아가서 다른 경로 탐색.
- 사용 예시: 크로스워드 퍼즐 (단어를 하나씩 채워나가며 검토)
🎯 ToT의 4단계 요약
| 단계 | 설명 | 예시 |
| 1. 사고 단계 분해 | 문제를 여러 사고 단계로 나눔 | "24 만들기"에서 수식을 단계별로 분해 |
| 2. 사고 생성 | 가능한 여러 개의 사고(생각) 후보 생성 | (13-9), (10-4) 같은 연산을 여러 개 생성 |
| 3. 상태 평가 | 생성된 사고가 좋은지 평가 | "이 연산이 24를 만들기 좋은지?" 점수 부여 |
| 4. 탐색 알고리즘 | BFS 또는 DFS를 사용하여 탐색 | BFS(여러 대안 평가), DFS(깊게 탐색) |
🔥 ToT의 강점
- 보다 체계적인 문제 해결 가능
- 단순한 좌우 방향 생성 방식이 아닌, 탐색 + 평가 + 수정 가능
- 다양한 문제 유형에 적용 가능
- 수학 문제, 창의적 글쓰기, 크로스워드 등
- CoT보다 강력한 의사결정 능력 제공
- ToT는 잘못된 사고 경로를 수정 가능
- LLM의 한계를 보완하여 "계획 + 평가" 수행 가능
💡 결론
기존의 Chain of Thought (CoT) 방식이 단순한 연속적 사고 전개에 그쳤다면,
Tree of Thoughts (ToT)는 여러 사고 경로를 탐색하고 평가하며 최적의 결정을 내릴 수 있도록 한다.
이를 통해 LLM이 단순한 연산 모델을 넘어, 스스로 탐색하고 전략적으로 판단하는 AI 시스템으로 발전할 수 있다! 🚀
ToT의 2단계: 사고 생성기 (Thought Generator)
ToT의 사고 생성기(Thought Generator, GG)는 주어진 문제 상태에서 다음 사고(thought) 단계를 생성하는 역할을 한다.
즉, LLM이 다음 단계를 결정하기 전에 여러 개의 대안을 생성하는 과정이다.
이를 위해 두 가지 방법을 사용한다:
- 독립적(i.i.d.) 샘플링 – 다양한 후보를 랜덤하게 생성
- 순차적(Propose Prompt) 샘플링 – 하나의 문맥 안에서 여러 대안을 생성
1. 독립적(i.i.d.) 샘플링 (Independent and Identically Distributed Sampling)
- 기본 개념:
- 동일한 입력에서 여러 개의 사고(thoughts)를 독립적으로 생성한다.
- 같은 맥락에서 랜덤하게 여러 사고를 샘플링하여 다양성을 확보.
- 주로 창의적 문제(Creative Writing)에서 효과적이다.
- 수식 표현:
- 즉, 동일한 입력 x 와 이전 사고 단계 z1,…,zi에 대해 k개의 샘플을 독립적으로 생성.

🔹 예시: 창의적 글쓰기 (Creative Writing)
👉 입력: "이야기의 마지막 문장이 주어졌을 때, 문맥이 자연스러운 4개의 문단을 작성하라."
👉 샘플링된 사고 후보들 (5개 샘플, k=5):
- "이야기의 배경을 설명하는 문단을 먼저 작성하자."
- "주인공이 문제를 마주하는 장면부터 시작하는 것이 좋겠다."
- "대화를 먼저 삽입하여 분위기를 형성하는 것이 자연스럽다."
- "시간 순서대로 사건을 정리하는 것이 가장 이해하기 쉽다."
- "반전 요소를 넣기 위해 결론부터 제시하고 거꾸로 설명해보자."
👉 특징:
- 하나의 프롬프트에서 여러 가지 가능성을 독립적으로 샘플링하여 생성.
- CoT 방식과 유사하지만, 여러 개의 사고를 동시에 탐색할 수 있다는 점이 다름.
- 랜덤성이 많아 다양성을 확보하는 데 유리함.
2. 순차적(Propose Prompt) 샘플링
- 기본 개념:
- LLM이 특정 문맥을 유지하며 순차적으로 여러 개의 사고를 제안한다.
- 같은 문맥에서 서로 다른 여러 개의 가능성을 한 번에 생성하는 방식.
- "24 만들기"와 같은 논리적 사고가 필요한 문제에서 유리함.
- 수식 표현:
- 즉, 하나의 프롬프트에서 여러 사고를 동시에 생성.

🔹 예시: "24 만들기" (Game of 24)
👉 입력: 4개의 숫자 (4, 9, 10, 13) 를 이용해 24를 만들어라.
👉 순차적 사고 생성 (3개의 연산 조합을 생성, k=3):
- "(13 - 9) = 4" 또는 "(10 - 4) = 6"
- "(10 - 4) × 4 = 24" 또는 "4 × 6 = 24"
- "(13 - 9) + 10 = 14" (실패)"
👉 특징:
- 한 번의 프롬프트에서 여러 개의 사고(thoughts)를 동시에 생성.
- i.i.d. 샘플링과 다르게, 문맥을 공유하면서 서로 다른 대안을 생성.
- 중복을 줄이고, 연산 과정이 제한적인 문제(수학, 크로스워드)에서 효과적.
🔎 i.i.d. 샘플링 vs. 순차적 샘플링 비교
| 방법 | 특징 | 적용 사례 | 장점 | 단점 |
| i.i.d. 샘플링 | 독립적으로 여러 사고를 생성 | 창의적 글쓰기 | 다양한 해결책을 탐색 가능 | 중복 가능성이 높음 |
| 순차적 샘플링 | 하나의 문맥 내에서 여러 사고를 생성 | 수학 문제, 크로스워드 | 중복을 줄이고 체계적인 탐색 가능 | 탐색 공간이 제한될 수 있음 |
🔍 ToT 사고 생성기의 핵심 정리
- i.i.d. 샘플링: 같은 입력에서 랜덤하게 여러 개의 사고를 생성 (창의적 문제에 적합).
- 순차적 샘플링: 같은 문맥 안에서 여러 개의 대안을 제안 (논리적 문제에 적합).
- 문제 유형에 따라 적절한 방식을 선택하여 LLM이 여러 대안을 생성하고 최적의 경로를 탐색할 수 있도록 함. 🚀
🔹 i.i.d. 샘플링 vs. 순차적 샘플링의 차이
- i.i.d. 샘플링: 하나의 입력에 대해 독립적으로 k개의 선택지를 생성.
- 순차적 샘플링: 하나의 입력에서 k단계(step)까지 진행한 여러 개의 경로를 생성.
🔎 i.i.d. 샘플링 (Independent Sampling)
- 각 선택지는 서로 독립적이며, 동일한 입력에서 여러 개의 가능성을 탐색.
- 즉, "다음 스텝을 어떻게 진행할지"에 대한 여러 개의 개별적인 제안을 만듦.
- 예를 들어, 하나의 프롬프트를 넣으면 k개의 독립적인 사고(thought)를 생성.
✅ 예제 1: 창의적 글쓰기 (Creative Writing)
👉 입력 (Prompt): "이야기의 첫 문장을 만들어라."
👉 출력 (5개 샘플, k=5):
- "어느 날, 그는 깊은 숲 속에서 길을 잃었다."
- "도시는 어둠에 휩싸였고, 빛 하나 없는 밤이었다."
- "비가 추적추적 내리던 어느 날, 나는 그를 처음 만났다."
- "미래의 세계는 우리가 상상했던 것과는 전혀 달랐다."
- "모든 것이 끝났다고 생각한 순간, 문이 열렸다."
🔹 특징:
- 각 문장이 독립적이므로 문맥을 공유하지 않음.
- 단순히 여러 개의 시작점을 제공하여 다양성을 높임.
- LLM이 창의성을 발휘하기 좋음.
🔎 순차적 샘플링 (Propose Sampling)
- 한 번의 프롬프트에서 여러 단계를 진행한 샘플을 생성.
- 즉, "이전 단계까지 진행한 상태"를 공유하면서 여러 개의 가능성을 탐색.
- 이전 사고(thought)들을 기반으로 다음 단계를 생성하는 방식.
✅ 예제 2: "24 만들기" (Game of 24)
👉 입력 (Prompt): "4, 9, 10, 13을 이용해 24를 만들어라."
👉 출력 (3개 샘플, k=3) (순차적으로 연산 진행):
- (13 - 9) = 4 → (10 - 4) = 6 → 4 × 6 = 24 ✅
- (10 - 4) = 6 → (13 - 9) = 4 → 6 × 4 = 24 ✅
- (13 - 10) = 3 → (9 - 3) = 6 → 6 × 4 = 24 ✅
🔹 특징:
- 첫 번째 연산이 끝난 상태에서 다음 단계를 고려하여 사고를 생성.
- i.i.d. 방식과 다르게, 각 선택지가 "이전 스텝의 문맥"을 유지하며 진행.
- 탐색 공간을 줄이고 중복을 방지하는 데 효과적.
🔥 두 방식의 차이 정리
| i.i.d 샘플링 | 순차적 샘플링 | |
| 방식 | 하나의 입력에서 k개의 독립적인 선택지 생성 | 하나의 입력에서 k단계 진행한 여러 개의 경로 생성 |
| 선택지 간 관계 | 서로 독립적 | 이전 스텝의 문맥을 공유 |
| 장점 | 창의적인 문제 해결 가능 (다양한 아이디어 탐색) | 논리적 문제 해결 가능 (문맥 유지, 중복 방지) |
| 적용 예시 | 창의적 글쓰기, 스토리 생성 | 수학 문제 해결, 크로스워드 풀이 |
🛠️ 최종 결론
- i.i.d. 샘플링은 한 입력에 대해 여러 개의 시작점을 주는 것.
- 순차적 샘플링은 k 단계까지 진행한 여러 개의 경로를 생성하는 것.
- 즉, i.i.d.는 "한 스텝의 다양한 가능성", 순차적 샘플링은 "여러 스텝을 포함한 경로"를 선택지로 제공.
✅ 직관적인 비유
- i.i.d. 샘플링 = "맛집을 검색할 때, 여러 개의 레스토랑 후보를 한 번에 추천받는 것"
- 순차적 샘플링 = "길을 찾을 때, 한 번에 여러 개의 경로를 제안받는 것"
🚀 ToT에서는 문제 유형에 맞게 두 방식을 적절히 선택해서 사용하면 된다! 🚀
아주 날카로운 질문입니다! i.i.d. 샘플링이 BFS이고, 순차적 샘플링이 DFS처럼 보이지만, 실제로는 다소 차이가 있습니다. 🚀
🔎 i.i.d. 샘플링 vs. BFS, 순차적 샘플링 vs. DFS
| i.i.d 샘플링 | 순차적 샘플링 | BFS | DFS | |
| 샘플링 방식 | 독립적인 여러 개의 생각(thought)을 한 번에 생성 | 한 경로에서 여러 스텝을 진행한 후, 여러 개의 대안을 생성 | 여러 개의 노드를 동시에 확장 | 한 경로를 깊이 탐색한 후, 다른 경로를 탐색 |
| 각 스텝 간 관계 | 서로 독립적 | 문맥을 공유하며 순차적으로 생성 | 넓은 범위를 탐색하며 병렬적으로 진행 | 특정 경로를 따라가며 깊이 탐색 |
| 탐색 전략 | 다양성 확보 (여러 아이디어 탐색) | 논리적 진행 (이전 생각을 기반으로 발전) | 여러 가능한 상태를 한꺼번에 탐색 | 하나의 가능성을 끝까지 진행 후 되돌아옴 |
| 적용 예시 | 창의적 글쓰기, 아이디어 생성 | 수학 문제 풀이, 크로스워드 퍼즐 | 게임의 가능한 모든 움직음을 고려 (e.g., 체스) | 미로 탐색, 퍼즐 풀이 |
🛠️ 왜 i.i.d. ≠ BFS이고, 순차적 샘플링 ≠ DFS인가?
- BFS는 트리의 노드를 확장하며 동시에 탐색하지만, i.i.d. 샘플링은 각 단계에서 독립적인 선택지를 생성할 뿐이다.
- BFS는 한 레벨의 모든 노드를 확장한 후, 다음 레벨로 넘어감.
- i.i.d. 샘플링은 "하나의 입력에 대한 여러 아이디어를 독립적으로 샘플링"하는 것일 뿐, 상태를 유지하며 깊게 탐색하지 않는다.
- DFS는 하나의 경로를 끝까지 탐색한 후 백트래킹(backtracking)하지만, 순차적 샘플링은 여러 개의 경로를 생성하고 평가할 뿐이다.
- DFS는 하나의 경로를 따라 내려가면서 깊이 탐색하고, 목표에 도달하지 못하면 다른 경로로 되돌아가 다시 탐색.
- 순차적 샘플링은 특정 문맥에서 여러 개의 가능성을 탐색하지만, 완전히 깊게 탐색하지 않고 병렬적인 대안을 생성할 수 있다.
🔍 i.i.d. 샘플링과 BFS의 차이
✅ 예제 1: 창의적 글쓰기 (Creative Writing)
- i.i.d. 샘플링
- "이야기의 첫 문장을 만들어라."
- 5개의 독립적인 문장을 생성
- (각 문장은 서로 관계 없음)
- BFS
- "이야기의 첫 문장을 만든 후, 그 다음 문장을 여러 개 만들고, 그다음 문장을 또 여러 개 만들면서 탐색"
- (각 문장이 연결됨 → 하나의 스토리를 만들어가는 방식)
🔹 차이점
- i.i.d. 샘플링은 한 번의 스텝에서 여러 개의 가능성을 독립적으로 생성.
- BFS는 여러 개의 가능성을 동시에 확장하며, 문맥을 공유.
🔍 순차적 샘플링과 DFS의 차이
✅ 예제 2: "24 만들기" (Game of 24)
- 순차적 샘플링
- (13 - 9) = 4 → (10 - 4) = 6 → (4 × 6) = 24
- (10 - 4) = 6 → (13 - 9) = 4 → (6 × 4) = 24
- 여러 개의 계산 경로를 동시에 생성하여 평가
- DFS
- (13 - 9) = 4 → (10 - 4) = 6 → (4 × 6) = 24 ✅
- (실패 시 백트래킹하여 다른 경로 탐색)
🔹 차이점
- 순차적 샘플링은 한 번의 프롬프트에서 여러 개의 가능한 계산 과정을 병렬적으로 생성.
- DFS는 하나의 경로를 끝까지 탐색한 후, 실패하면 백트래킹.
🎯 결론: i.i.d. ≠ BFS, 순차적 샘플링 ≠ DFS
- i.i.d. 샘플링은 BFS처럼 "넓은 범위의 가능성"을 탐색하지만, BFS처럼 상태를 유지하며 점진적으로 탐색하지 않음.
- 순차적 샘플링은 DFS처럼 "논리적으로 진행"하지만, DFS처럼 한 경로를 끝까지 따라가고 백트래킹하지 않음.
- BFS/DFS는 트리 탐색 전략이고, i.i.d./순차적 샘플링은 LLM이 생각을 생성하는 방식이다.
→ 즉, BFS/DFS는 전체 탐색 전략이고, i.i.d./순차적 샘플링은 개별 사고(thoughts)를 생성하는 방법이다.
🚀 결론: BFS/DFS는 탐색 방식이고, i.i.d. & 순차적 샘플링은 개별적인 사고 생성 방식이다. 🚀