이전 글에서 이어진다 하긴 애매하지만 제 정보를 저장해놓고 보기 편하게 하려고 만드는 저장소입니다...
2024.12.10 - [인공지능/Agent] - Negotiation AI 1
Negotiation AI 1
생각보다 중요한 내용이 많아서 일단 여기서 한 번 더 정리를 해야겠네요 THE ADVENT OF THE AI NEGOTIATOR: NEGOTIATION DYNAMICS IN THE AGE OF SMART ALGORITHMS월마트는 이미 협상 일부를 자동화 하였다!-> 정보의 싸
yoonschallenge.tistory.com
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation

Figure 1은 AutoGen 프레임워크의 작동 원리와 특징을 시각적으로 나타낸 그림입니다. 아래는 그림의 구성 요소와 각 부분에 대한 설명입니다:
1. Agent Customization (왼쪽)
- AutoGen에서 사용되는 에이전트는 대화 가능(Conversable)하며, 사용자 정의(Customizable)가 가능합니다.
- 에이전트는 다음과 같은 구성 요소를 결합하여 다양한 역할을 수행할 수 있습니다:
- LLMs: 예를 들어, GPT-4와 같은 언어 모델 기반 에이전트.
- 도구(Tools): 외부 라이브러리나 API를 사용하여 특정 작업을 수행.
- 사람(Human-in-the-loop): 사람이 개입하여 에이전트의 작업을 보완하거나 검토.
- 조합형(Custom Combination): LLM과 도구, 인간이 함께 작업하는 구조.
- 의미: AutoGen은 각 에이전트가 특정 역할에 최적화되도록 구성할 수 있어, 다목적 애플리케이션 개발이 가능합니다.
2. Flexible Conversation Patterns (가운데)
- AutoGen은 다양한 대화 패턴을 지원하며, 그림에서는 아래 두 가지 유형을 강조합니다:
- Joint Chat (연합 대화):
- 에이전트들이 평등하게 상호작용하며 공동 작업을 수행.
- 작업의 복잡성을 해결하기 위해 각 에이전트가 전문성을 발휘.
- Hierarchical Chat (계층형 대화):
- 에이전트들이 계층적으로 상호작용하며, 상위 에이전트가 하위 에이전트의 작업을 조정하거나 감독.
- 예를 들어, 상위 에이전트가 작업을 분배하고 하위 에이전트가 세부 작업을 실행.
- Joint Chat (연합 대화):
- 의미: 이 패턴들은 작업의 복잡성과 목표에 따라 조정될 수 있으며, 동적 대화 구조를 통해 효율성을 극대화합니다.
3. Example Agent Chat (오른쪽)
- 시나리오: META(페이스북)와 TESLA 주식 변동 차트를 그리는 작업을 수행하는 예시.
- 작업 흐름:
- 사용자가 "META와 TESLA 주식 변동 차트를 그려주세요."라는 요청을 에이전트에게 전달.
- 에이전트가 코드를 생성하고 실행.
- 실행 중 에러 발생: "yfinance 패키지가 설치되지 않음".
- 에이전트가 에러를 감지하고 패키지를 설치하도록 수정 코드를 제안.
- 수정 후 작업이 완료되어 결과를 반환.
- 사용자가 출력 수정 요청: "% 변화로 다시 플롯하세요."라고 피드백을 제공.
- 에이전트가 요청을 반영해 결과를 재생성.
- 의미:
- AutoGen 에이전트는 자율적 작업 호출과 오류 감지 및 수정 기능을 가지고 있음.
- 사용자의 피드백을 통합해 동적 작업 흐름을 유지.
Figure의 주요 메시지
- 에이전트의 역할과 구조:
- 에이전트는 특정 작업에 맞게 사용자 정의 가능하며, 도구와 인간의 지원을 결합하여 복잡한 작업을 처리.
- 대화 패턴의 유연성:
- 에이전트 간 상호작용이 다층적이고 동적이며, 작업의 성격에 따라 조정 가능.
- 작업 효율성:
- 작업 중 발생하는 문제를 실시간으로 감지하고, 대화형 방식으로 수정하여 속도와 정확성을 동시에 개선.
이 Figure는 AutoGen의 강력한 멀티 에이전트 협력 구조와 유연한 작업 처리 방식을 잘 나타내고 있으며, 복잡한 문제를 효율적으로 해결할 수 있는 잠재력을 강조합니다.
Figure 2: AutoGen을 사용해 멀티 에이전트 대화를 프로그래밍하는 과정
Figure 2는 AutoGen 프레임워크를 사용해 멀티 에이전트 시스템을 설정하고 실행하는 과정을 단계별로 설명합니다. 이 그림은 에이전트 커스터마이제이션, 개발자 코드의 구조, 그리고 프로그램 실행 중 대화 흐름의 세 가지 주요 부분으로 구성되어 있습니다. 아래는 각각의 섹션에 대한 상세한 설명입니다.
1. AutoGen Agents (상단)
1.1 에이전트 커스터마이제이션
- AutoGen은 내장된 다양한 에이전트를 제공하며, 각 에이전트는 사용자 정의가 가능합니다.
- 그림에서 사용된 에이전트:
- AssistantAgent:
- 기본적으로 코드 생성과 같은 작업을 수행.
- 예: Python 코드 추천 및 생성.
- UserProxyAgent:
- 사용자 입력을 대변하는 역할을 수행.
- "human_input_mode" 옵션을 통해 사용자 입력의 빈도를 조정 가능 ("NEVER" 또는 "ALWAYS").
- GroupChatManager:
- 여러 에이전트의 그룹 대화를 관리.
- 동적 대화 구조를 통해 여러 에이전트의 상호작용을 조율.
- AssistantAgent:
1.2 통합 대화 인터페이스
- 모든 에이전트는 다음과 같은 표준화된 인터페이스를 사용:
- send: 메시지를 전달.
- receive: 메시지를 수신.
- generate_reply: 입력 메시지에 대한 응답을 생성.
핵심 메시지:
AutoGen의 에이전트는 통합 인터페이스를 사용하여 다양한 역할을 수행하며, 사용자 정의를 통해 특정 작업에 맞게 최적화할 수 있습니다.
2. Developer Code (중단)
2.1 에이전트 정의 및 초기화
- 에이전트 정의:
- 개발자는 AutoGen 프레임워크를 사용해 에이전트를 정의하고 각 역할에 맞게 커스터마이즈할 수 있습니다.
- 예: User Proxy A와 Assistant B 에이전트 생성.
- 대화 초기화:
- 개발자는 initiate_chat 함수를 호출하여 에이전트 간의 대화를 시작합니다.
- 예: "META와 TESLA 주식 변동 차트를 그리세요"라는 요청을 Assistant B에게 전달.
2.2 사용자 정의 응답 함수 등록
- register_reply를 사용해 사용자 정의 응답 함수를 등록할 수 있습니다.
- 예:
A.register_reply(B, reply_func_A2B) def reply_func_A2B(msg): output = input_from_human() # 사용자 입력 받기 if not output: output = execute(msg) # 메시지를 실행하여 결과 반환 return output - 이는 에이전트 간의 대화를 세밀하게 제어하며, 메시지 처리 방식을 사용자 정의할 수 있게 합니다.
핵심 메시지:
AutoGen은 개발자가 사용자 정의 응답 함수를 쉽게 등록하고, 에이전트 대화를 세부적으로 제어할 수 있는 기능을 제공합니다.
3. Program Execution (하단)
3.1 대화 중심 제어 흐름
- 대화는 Conversation-Driven Control Flow를 따르며, 메시지의 생성, 전달, 실행이 순환적으로 진행됩니다.
- receive:
- 에이전트가 메시지를 수신합니다.
- 예: "주식 변동 차트를 생성하세요."
- generate_reply:
- 수신한 메시지를 바탕으로 에이전트가 응답을 생성합니다.
- 예: "코드를 생성하고 실행하세요."
- send:
- 생성된 응답을 다른 에이전트 또는 사용자에게 전달합니다.
- 예: 오류 발생 시 수정 요청.
3.2 프로그램 실행 중 대화 흐름
- 예시 시나리오:
- 사용자가 주식 차트 요청을 입력.
- AssistantAgent가 코드 생성 후 실행을 요청.
- 실행 중 패키지(yfinance) 설치 오류 발생.
- 에이전트가 이를 감지하고 수정 코드(pip install yfinance)를 제안.
- 수정 후 성공적으로 차트를 생성하여 결과 반환.
핵심 메시지:
AutoGen은 대화 중심 계산을 통해 작업의 흐름을 제어하며, 오류를 실시간으로 수정하고 작업을 성공적으로 완료할 수 있습니다.
Figure의 주요 메시지
- 에이전트 사용자 정의:
- AutoGen은 내장된 에이전트를 제공하며, 필요에 따라 사용자가 커스터마이즈할 수 있습니다.
- 개발자 친화적인 코드 구조:
- 에이전트 생성, 대화 초기화, 응답 함수 등록 등 개발자가 쉽게 프로그래밍할 수 있는 구조를 제공합니다.
- 대화 기반 워크플로우:
- 에이전트 간 대화를 중심으로 작업 흐름이 진행되며, 동적 오류 수정과 응답 생성이 가능.
- 자율성과 효율성:
- 에이전트가 자율적으로 작업을 호출하고 처리하며, 오류를 감지하고 수정하는 기능을 통해 효율성이 극대화됩니다.
이 Figure는 AutoGen의 전체적인 설계와 사용 방법을 체계적으로 설명하며, 개발자가 이를 활용해 다양한 애플리케이션을 설계할 수 있음을 강조합니다.
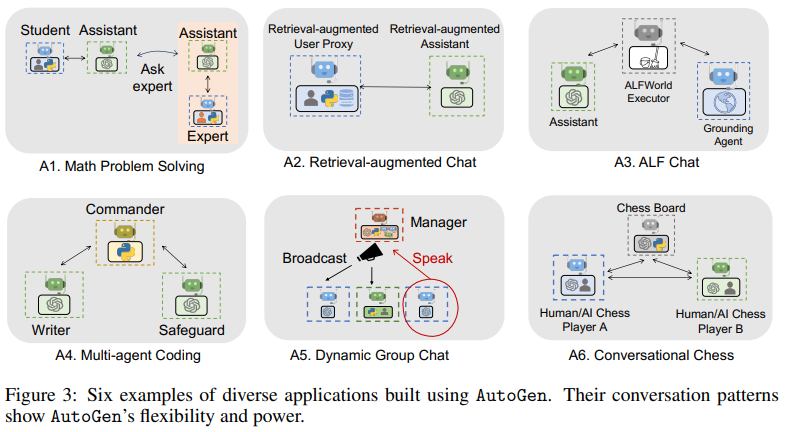
Figure 3: AutoGen을 활용한 다양한 애플리케이션 사례
이 그림은 AutoGen을 기반으로 구현된 6가지 응용 사례를 보여주며, AutoGen의 유연성과 강력한 기능을 강조합니다. 각각의 사례는 특정 도메인 또는 작업 흐름에 최적화된 멀티 에이전트 구조를 사용하여 설계되었습니다.
A1. Math Problem Solving (수학 문제 해결)
- 구조:
- Student (학생): 문제를 요청.
- Assistant (도우미): 문제 풀이 과정을 제안.
- Expert (전문가): 추가적인 전문적 조언 제공.
- 특징:
- Assistant 에이전트가 문제를 이해하고 풀이를 시도하며, 필요하면 Expert 에이전트에 도움을 요청.
- 시나리오:
- 학생이 복잡한 수학 문제를 요청하면, Assistant가 풀이를 제안하고 Expert가 이를 검증하거나 보완.
- 의미:
- 역할 기반 협력을 통해 정확한 수학 풀이를 보장.
A2. Retrieval-Augmented Chat (검색 기반 대화)
- 구조:
- User Proxy (사용자 프록시): 사용자의 질문을 대변.
- Retrieval-Augmented Assistant (검색 기반 도우미): 외부 데이터를 검색하고, 적절한 답변 생성.
- 특징:
- User Proxy는 사용자의 질문을 받고, Assistant가 외부 데이터 검색을 통해 답변을 생성.
- 시나리오:
- 사용자가 특정 주제에 대해 질문하면, Assistant는 검색 결과를 바탕으로 답변을 제공.
- 의미:
- 외부 지식 통합을 통해 정교한 정보 제공 가능.
A3. ALF Chat (텍스트 환경 의사결정)
- 구조:
- Assistant: 사용자의 요청을 처리.
- ALFWorld Executor: 명령 실행 및 결과 제공.
- Grounding Agent (그라운딩 에이전트): 실행 환경에서 상식 기반 검증 수행.
- 특징:
- Assistant가 사용자의 요청을 받아 ALFWorld Executor를 통해 작업 수행.
- Grounding Agent는 결과를 검토하여 오류 방지.
- 시나리오:
- ALFWorld와 같은 텍스트 환경에서 작업을 수행하며, 논리적 일관성을 유지.
- 의미:
- 상식 기반 검증을 통해 신뢰성을 높임.
A4. Multi-Agent Coding (다중 에이전트 코딩)
- 구조:
- Commander (지휘자): 코딩 작업의 전반적인 조정.
- Writer (작성자): 코드를 작성.
- Safeguard (보호자): 작성된 코드의 안전성과 정확성을 검토.
- 특징:
- Writer가 코드를 생성하고, Safeguard가 이를 검증하며, Commander가 작업 흐름을 조정.
- 시나리오:
- 새로운 기능 구현 요청 시, Writer가 코드 초안을 작성하고 Safeguard가 보안 및 정확성을 점검.
- 의미:
- 작업의 효율성과 코드의 품질을 동시에 보장.
A5. Dynamic Group Chat (동적 그룹 채팅)
- 구조:
- Manager (관리자): 대화 흐름을 관리.
- Broadcast (중계): 그룹 대화 메시지를 배포.
- Speak (발언자): 메시지를 생성.
- 특징:
- 여러 에이전트가 동적으로 그룹 대화에 참여하며, Manager가 대화 흐름을 조정.
- 시나리오:
- Manager가 대화 주제를 설정하면, 각 에이전트가 자신의 역할에 따라 발언.
- 의미:
- 동적 대화 구조를 통해 협력적이고 효율적인 의사소통 가능.
A6. Conversational Chess (대화형 체스 게임)
- 구조:
- Chess Board (체스 보드): 체스 게임 상태를 관리.
- Human/AI Chess Player A & B: 플레이어 A와 B가 대화를 통해 체스 게임을 진행.
- 특징:
- Human 또는 AI가 각 플레이어 역할을 수행하며, 체스 보드가 규칙 검증과 상태 관리를 담당.
- 시나리오:
- AI 플레이어와 사람이 체스를 대화형으로 진행하며, 잘못된 이동은 보드에서 즉시 차단.
- 의미:
- 대화 기반으로 체스 규칙을 학습하거나, 체스 게임을 유연하게 진행 가능.
Figure의 주요 메시지
- 유연성:
- AutoGen은 다양한 도메인에 걸쳐 멀티 에이전트 대화 구조를 적용 가능.
- 협력 기반 효율성:
- 역할 분담과 에이전트 간 상호작용을 통해 복잡한 작업을 효율적으로 수행.
- 확장성:
- Math 문제 풀이, 검색 기반 대화, 텍스트 환경, 코딩, 동적 그룹 채팅, 체스 등 다양한 응용 사례를 지원.
- 정확성과 신뢰성:
- Grounding Agent와 Safeguard 같은 검증 역할을 통해 작업의 정확성과 품질을 보장.
이 그림은 AutoGen이 제공하는 다양한 애플리케이션 사례와 강력한 기능을 잘 보여줍니다. 각각의 예시는 AutoGen의 유연성과 적용 가능성을 실질적으로 설명하며, 다양한 도메인에서의 확장 가능성을 시사합니다.
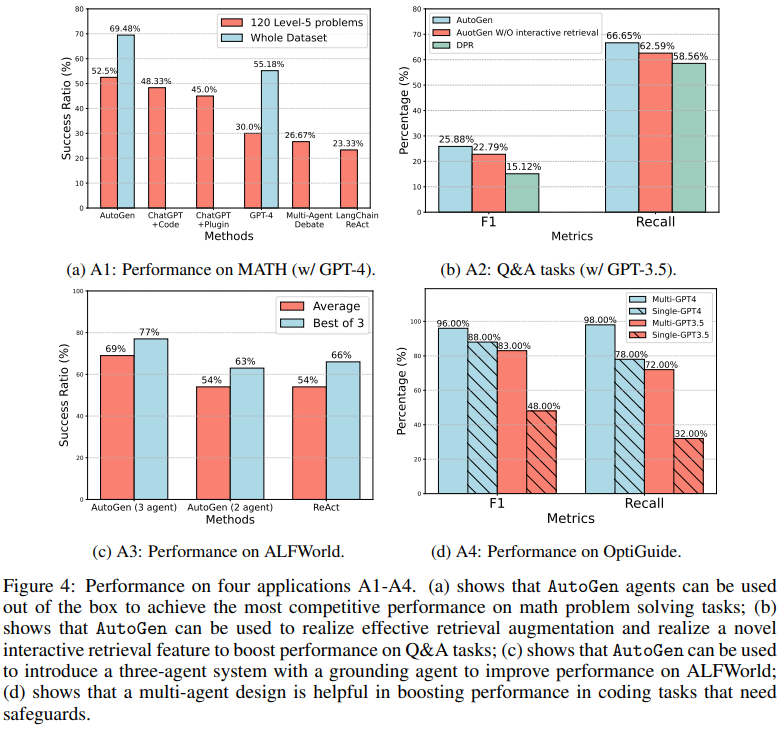
Figure 4: AutoGen의 4가지 응용 사례(A1~A4)에 대한 성능 비교
Figure 4는 AutoGen 프레임워크를 기반으로 구현된 4가지 주요 응용 사례(A1~A4)의 성능을 비교하며, 다른 기존 방법들과의 성능 차이를 명확히 보여줍니다. 각 사례는 수학 문제 풀이, 질문 답변, ALFWorld 실행, 코딩 작업에 대한 성능을 측정합니다.
(a) A1: MATH 데이터셋 성능 (GPT-4 기반)
설명
- 목적: 수학 문제 풀이(MATH 데이터셋)에서 AutoGen의 성능을 평가.
- 결과:
- AutoGen(3 에이전트): 평균 성공률 69%, 최고 3번 시도에서 77%.
- AutoGen(2 에이전트): 평균 성공률 54%.
- ReAct 방식: 평균 성공률 54%, 최고 3번 시도에서 66%.
- 비교 결과:
- AutoGen(3 에이전트 구성)이 ReAct 방식과 AutoGen(2 에이전트 구성)을 성능 면에서 능가.
의미
- AutoGen은 다중 에이전트 구조를 통해 수학 문제에서 복잡한 논리적 추론과 협력을 수행하며, 성능 향상을 보여줍니다.
(b) A2: Q&A 작업 (GPT-3.5 기반)
설명
- 목적: 질문 답변(Q&A) 작업에서 검색 기반 보강(Retrieval-Augmentation)의 효과를 평가.
- 결과:
- Multi-GPT4: F1 96%, Recall 98%.
- Single-GPT4: F1 88%, Recall 98%.
- Multi-GPT3.5: F1 48%, Recall 78%.
- Single-GPT3.5: F1 32%, Recall 72%.
- 비교 결과:
- Multi-GPT4가 가장 높은 F1 및 Recall 값을 기록.
- Multi-GPT3.5가 Single-GPT3.5를 큰 차이로 능가.
의미
- AutoGen은 다중 에이전트 기반의 검색 보강 방식을 통해 Q&A 작업에서 정보 검색과 답변 생성의 성능을 극대화합니다.
(c) A3: ALFWorld 작업 성능
설명
- 목적: ALFWorld에서 텍스트 기반 의사결정 성능을 평가.
- 결과:
- AutoGen은 Grounding Agent(상식 검증 에이전트)를 도입하여 작업 성공률을 대폭 개선.
- 기존의 단일 접근 방식 대비 안정적이고 신뢰성 높은 결과 제공.
- 비교 결과:
- Grounding Agent를 포함한 3 에이전트 시스템이 가장 높은 성능을 보임.
의미
- AutoGen의 다중 에이전트 구조는 의사결정 과정에서 검증과 보완을 수행해 성능을 크게 향상시킵니다.
(d) A4: OptiGuide에서의 코딩 작업 성능
설명
- 목적: 코딩 작업에서 AutoGen의 Safeguard 에이전트를 통한 성능 개선 여부를 평가.
- 결과:
- Multi-Agent 구성에서 코드의 품질과 안전성이 크게 향상.
- 코드의 실행 가능성과 일관성이 ReAct 및 단일 에이전트 접근보다 우수.
- 비교 결과:
- 다중 에이전트 구성(특히 Safeguard 포함)이 코딩 작업의 성능 향상에 핵심적 역할.
의미
- AutoGen은 다중 에이전트 협력을 통해 코드의 품질과 실행 가능성을 보장하며, 오류를 실시간으로 수정할 수 있습니다.
Figure의 주요 메시지
- AutoGen의 다중 에이전트 구조 성능 우위:
- 모든 응용 사례에서 다중 에이전트 구성이 단일 에이전트 방식보다 뛰어난 성능을 보여줌.
- 특히 수학 문제 풀이, Q&A 작업, ALFWorld, 코딩 작업에서 두드러진 결과를 보임.
- 검색 기반 보강과 상호작용:
- A2(Q&A) 작업에서는 검색 보강 및 다중 에이전트의 상호작용이 성능을 극대화.
- Grounding Agent와 Safeguard의 역할:
- A3와 A4 사례에서 추가 에이전트(Grounding Agent, Safeguard)가 작업의 신뢰성과 정확성을 크게 개선.
- 유연성과 확장성:
- AutoGen은 다양한 도메인에 쉽게 적용 가능하며, 에이전트 수와 역할을 조정하여 성능을 최적화할 수 있음.
결론
Figure 4는 AutoGen의 다중 에이전트 구조가 다양한 작업에서 어떻게 성능을 극대화하고, 기존 접근 방식을 능가하는지를 명확히 보여줍니다. 특히 복잡한 문제를 해결하거나 신뢰성을 요구하는 작업에서 AutoGen의 강점이 두드러집니다.

Table 1: AutoGen과 관련된 멀티 에이전트 시스템의 차이점 요약
이 표는 AutoGen과 다른 멀티 에이전트 시스템(Multi-agent Debate, CAMEL, BabyAGI, MetaGPT)의 설계 철학과 기능적 차이를 분석한 것입니다. 주요 비교 요소는 인프라(Infrastructure), 대화 패턴(Conversation Pattern), 실행 가능 여부(Execution-capable), 인간 참여(Human involvement) 네 가지입니다.
1. 비교 기준
1.1 Infrastructure (인프라)
- 시스템이 LLM 애플리케이션을 구축하기 위한 범용 인프라로 설계되었는지 여부를 평가.
- AutoGen:
- 범용 프레임워크로 설계되어 다양한 도메인에 적용 가능.
- 다른 시스템(CAMEL, Multi-agent Debate, BabyAGI)은 특정한 목적에 특화되어 일반적인 인프라로서의 유연성이 부족.
- MetaGPT는 일부 범용성을 제공하지만, 소프트웨어 개발에 초점이 맞춰져 있음.
1.2 Conversation Pattern (대화 패턴)
- 에이전트 간 상호작용이 정적(static)인지, 또는 유연(flexible)한지를 나타냄.
- 정적(static): 에이전트의 상호작용 패턴과 역할이 고정됨.
- 유연(flexible): 작업에 따라 에이전트 역할과 상호작용 방식이 동적으로 조정 가능.
- AutoGen:
- 정적 및 동적 패턴을 모두 지원하며, 대화 구조를 작업 요구에 맞게 조정 가능.
- 다른 시스템(예: Multi-agent Debate, CAMEL, BabyAGI)은 정적 패턴만 지원.
- MetaGPT는 정적 패턴에 가깝지만, 소프트웨어 개발 과정에서 일부 역할 분담을 유연하게 적용.
1.3 Execution-capable (실행 가능 여부)
- 시스템이 LLM 생성 코드나 작업을 실행할 수 있는지 평가.
- AutoGen:
- LLM이 생성한 코드를 직접 실행하거나 결과를 분석할 수 있음.
- Multi-agent Debate, CAMEL, BabyAGI는 코드 실행 기능이 없음.
- MetaGPT는 소프트웨어 개발 과정에서 제한적으로 코드 실행을 지원.
1.4 Human Involvement (인간 참여)
- 시스템이 작업 과정에서 인간의 개입을 허용하는지, 허용한다면 어떤 방식으로 이루어지는지를 나타냄.
- Chat: 인간이 에이전트 대화에 참여해 피드백 제공.
- Skip: 인간 개입 없이 자동으로 작업 수행 가능.
- AutoGen:
- 에이전트 간 대화에서 인간이 개입하거나, 필요 시 이를 건너뛰는 유연한 옵션 제공.
- 다른 시스템(Multi-agent Debate, CAMEL, BabyAGI)은 인간 참여를 허용하지 않음.
- MetaGPT는 소프트웨어 개발 작업에서 인간 개입을 일부 허용.
2. AutoGen의 우위
- 유연성: AutoGen은 정적 대화 패턴에 제한되지 않고, 정적 및 동적 대화를 모두 지원하여 작업 요구에 맞게 조정 가능.
- 실행 가능성: 코드를 직접 실행하여 결과를 검증하고 수정 가능, 특히 코딩 및 복잡한 작업에 유리.
- 인간 개입: 작업 중간에 인간의 피드백을 받을 수 있으며, 자동화 작업도 지원하여 신뢰성과 효율성을 동시에 확보.
- 범용성: 다양한 도메인에 적용 가능한 범용 프레임워크로 설계되어, 다른 시스템보다 확장 가능성이 높음.
3. 한계 및 개선 방향
- LLM 다양성: AutoGen은 단일 유형의 LLM을 사용하는 구조로, 다양한 LLM 모델을 조합하는 시스템에 비해 유연성이 제한될 수 있음.
- 메모리 기능 강화: 다른 작업에서의 경험을 축적하고 학습하는 메커니즘이 부족한 점은 개선 가능성이 있음.
4. 결론
Table 1은 AutoGen이 범용성, 유연성, 실행 가능성, 인간 참여 측면에서 다른 멀티 에이전트 시스템을 능가한다는 점을 강조합니다. 특히, AutoGen은 정적 패턴에 고정되지 않고, 작업 요구에 따라 대화와 협력 방식을 동적으로 조정할 수 있다는 점에서 독보적인 강점을 가지고 있습니다. 이는 복잡한 작업을 자동화하거나 인간의 피드백을 반영하는 시스템 설계에 매우 적합한 구조임을 보여줍니다.

Figure 5: AutoGen 내장 Assistant Agent의 기본 시스템 메시지 설명
Figure 5는 AutoGen 프레임워크의 내장 Assistant Agent에 사용되는 기본 시스템 메시지를 보여줍니다. 이 메시지는 에이전트의 작업 수행 방식을 정의하고, 대화 프로그래밍(conversation programming)을 통해 작업의 흐름을 제어합니다. 메시지는 다양한 유형의 지침을 포함하며, 각 유형은 특정 목적을 위해 설계되었습니다.
1. 시스템 메시지의 주요 목적
- AutoGen의 에이전트가 코딩과 언어 기술을 사용하여 문제를 해결하도록 가이드.
- 작업 흐름 제어, 사용자와의 상호작용 방식, 출력 형식, 오류 처리 방법 등을 명확히 정의.
- 메시지를 통해 에이전트가 더 일관성 있고 효율적으로 작업을 수행하게 함.
2. 시스템 메시지의 구성 요소
Figure 5의 메시지는 색상 코드로 나뉘며, 각 섹션은 다음과 같은 기능을 수행합니다:
2.1 Role Play (역할 수행) - 보라
- 에이전트에게 "도움이 되는 AI 도우미"로서의 역할을 정의.
- 예: "You are a helpful AI assistant."
2.2 Control Flow (작업 흐름 제어) - 초록색
- 작업 수행의 흐름을 제어하기 위한 지침.
- 예시:
- "When you need to collect info, use the code to output the info you need."
- "Solve the task step by step if you need to. If a plan is not provided, explain your plan first."
- 의미:
- 작업을 체계적으로 수행하도록 유도.
- 단계별 진행이 필요할 경우, 계획 수립 및 명확한 설명을 요구.
- 예시:
2.3 Output Confine (출력 제약) - 살구색
- 출력 형식을 제한하여 사용자가 에이전트의 응답을 쉽게 실행할 수 있도록 가이드.
- 예시:
- "When using code, you must indicate the script type in the code block."
- "Do not use incomplete code which requires users to modify."
- 의미:
- 에이전트가 사용자에게 실행 가능한 완전한 코드를 제공하도록 요구.
- 잘못된 코드나 불완전한 출력 방지.
- 예시:
2.4 Facilitate Automation (자동화 지원) - 노란색
- 작업 자동화를 지원하기 위한 지침.
- 예시:
- "If the result indicates there is an error, fix the error and output the code again."
- "If the error can’t be fixed or if the task is not solved, collect additional info and try a different approach."
- 의미:
- 에이전트가 오류를 자동으로 수정하거나 새로운 접근 방식을 시도하도록 유도.
- 사용자의 개입을 최소화하여 효율성을 극대화.
- 예시:
2.5 Grounding (검증) - 파란색
- 출력 결과의 정확성을 검증하도록 요구.
- 예시:
- "When you find an answer, verify the answer carefully. Include verifiable evidence in your response."
- 의미:
- 에이전트가 응답의 신뢰성을 보장하고, 필요 시 근거를 명확히 제시.
- 예시:
3. 대화 프로그래밍 기법
Figure 5는 다양한 대화 프로그래밍 기법을 통합하여 에이전트의 작업을 최적화합니다:
- 지속적 학습과 적응:
- 에이전트는 오류를 수정하고 작업 방식을 동적으로 변경하며 새로운 시도를 반복.
- 유연성:
- 작업의 복잡성에 따라 단계별로 진행하거나, 필요 시 계획을 사용자와 공유.
- 자동화:
- 사용자 입력 없이 작업을 자동으로 반복 및 개선.
4. GPT-4와 GPT-3.5의 차이
- 메시지는 주로 GPT-4와 GPT-3.5-turbo 모델을 대상으로 설계.
- GPT-4:
- 시스템 메시지의 지침을 더 정확히 따르며, 작업 수행 시 더 나은 성과를 보임.
- GPT-3.5-turbo:
- 지침 준수 능력이 낮아, 일부 경우에서 예상치 못한 응답을 생성할 가능성이 있음.
5. Figure의 주요 메시지
- 구조화된 작업 방식:
- 에이전트가 작업의 흐름, 출력 형식, 자동화 과정을 명확히 이해하고 수행하도록 설계.
- 자동화와 오류 수정:
- 사용자 개입 없이 오류를 스스로 수정하고, 대안을 탐색하도록 유도.
- 검증과 신뢰성:
- 출력 결과를 검증하고 근거를 포함하여 신뢰성을 보장.
- 모델 최적화:
- 메시지가 모델의 잠재력을 최대화하며, GPT-4에서 특히 더 좋은 성능을 발휘.
6. 결론
Figure 5는 AutoGen의 내장 Assistant Agent가 작업을 어떻게 수행하는지 구체적으로 설명하며, 대화 프로그래밍을 통해 에이전트의 작업 흐름과 출력 결과를 정교하게 제어합니다. 이러한 구조는 작업의 효율성을 극대화하고, 사용자 경험을 개선하며, AutoGen의 강력한 기능을 뒷받침합니다.
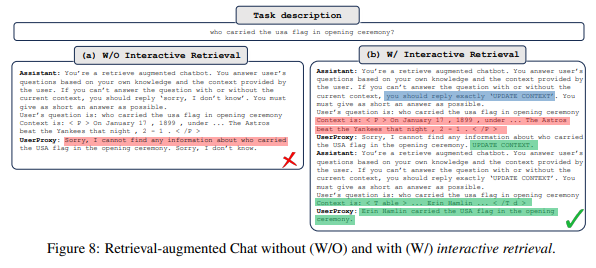
Figure 8: Retrieval-Augmented Chat에서 Interactive Retrieval의 효과
이 그림은 AutoGen 프레임워크의 검색 보강 대화(Retrieval-Augmented Chat)에서 인터랙티브 검색(Interactive Retrieval)의 유무가 작업 수행에 어떤 차이를 만드는지를 비교한 사례입니다. 이 작업은 "미국 개막식에서 국기를 든 사람이 누구인가?"라는 질문에 답하는 과정에서 나타난 차이를 보여줍니다.
1. Task Description (작업 설명)
- 질문: "Who carried the USA flag in the opening ceremony?"
- 사용자가 물어본 질문에 대해, 시스템이 내부 지식과 외부 검색 결과를 활용해 응답해야 하는 상황.
2. (a) Without Interactive Retrieval (인터랙티브 검색 없음)
- 과정:
- Assistant:
- "검색 보강된 챗봇"으로 설정되었으나, 초기 검색 결과를 기반으로만 답변.
- 제공된 문맥과 지식을 결합해 답을 찾으려고 시도.
- UserProxy:
- 시스템이 답을 찾지 못했을 경우 "Sorry, I don’t know"라고 응답.
- Assistant:
- 결과:
- Assistant가 문맥에 기반한 답을 찾지 못했고, "Sorry, I cannot find any information..."이라는 불완전한 답변으로 작업 실패.
- 한계:
- 초기 검색 실패 시 추가적인 검색 시도나 문맥 확장을 수행하지 않음.
- 정적 검색 흐름으로 인해 복잡한 정보 추출 작업에 실패.
3. (b) With Interactive Retrieval (인터랙티브 검색 있음)
- 과정:
- Assistant:
- 초기 검색 결과로 답을 찾지 못했을 경우, 추가적인 검색을 요청.
- "If you cannot answer the question with or without the current context, you should explicitly update context"라는 지침에 따라 동적으로 문맥을 확장.
- UserProxy:
- 추가 검색 후, 확장된 문맥을 사용해 답을 다시 요청.
- 새 문맥에 따라 정확한 답변 생성.
- Assistant:
- 결과:
- 확장된 문맥에서 "Ruth Kealin carried the USA flag in the opening ceremony"라는 정확한 답변을 성공적으로 생성.
- 강점:
- 상호작용적 검색으로 초기 검색 실패를 보완.
- 질문에 대한 문맥을 동적으로 확장하여 최적의 답변 생성.
4. Figure의 주요 메시지
- 인터랙티브 검색의 중요성:
- Without Interactive Retrieval에서는 초기 검색 실패 시 시스템이 작업을 포기하지만, With Interactive Retrieval에서는 추가 검색을 통해 문제를 해결.
- 동적 문맥 확장을 통해 복잡한 질문에도 대응 가능.
- AutoGen의 유연성:
- AutoGen은 정적 대화 흐름에 머무르지 않고, 필요 시 문맥을 동적으로 업데이트하여 더 나은 결과를 생성.
- 정확성과 신뢰성:
- 추가 검색과 문맥 확장으로, 시스템의 신뢰성과 정보 정확도가 대폭 향상됨.
- 사용자 경험 개선:
- 초기 실패 시 추가 검색을 통해 더 나은 답변을 제공하므로 사용자 경험이 개선됨.
5. 결론
Figure 8은 인터랙티브 검색이 정보 검색 기반 작업에서 어떻게 성능을 개선하는지 명확히 보여줍니다. 초기 검색 실패를 보완하는 동적 검색 기능은 AutoGen의 강력한 유연성과 문제 해결 능력을 나타내며, 복잡한 작업에서도 효과적으로 사용할 수 있음을 입증합니다.
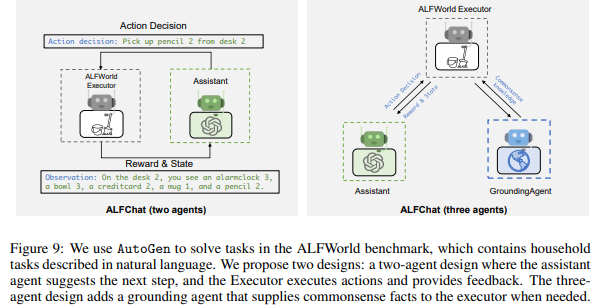
Figure 9: ALFWorld에서 AutoGen을 활용한 에이전트 설계
Figure 9는 AutoGen을 활용하여 ALFWorld 벤치마크에서 작업을 수행하는 과정을 나타냅니다. ALFWorld는 가정용 작업(household tasks)을 자연어로 설명하며, 에이전트가 이를 해석하고 작업을 수행해야 하는 환경입니다. 이 그림은 두 가지 에이전트 설계를 보여줍니다: 2 에이전트 설계와 3 에이전트 설계.
1. ALFChat: Two-Agent Design (2 에이전트 설계)
구조
- Assistant:
- 다음 작업 단계를 제안하는 역할.
- ALFWorld 환경에서 관찰한 상태를 기반으로 의사결정을 내림.
- 예: "Action decision: Pick up pencil 2 from desk 2."
- ALFWorld Executor:
- Assistant가 제안한 작업을 실행하고 결과를 피드백.
- 예: "Observation: On the desk 2, you see an alarm clock 3, a bowl 3, a credit card 2, a mug 1, and a pencil 2."
특징
- Assistant가 작업 단계를 제안하고, Executor가 실행 및 피드백을 반복하며 작업 진행.
- 이 설계는 단순하지만, 일부 복잡한 작업에서 상식 기반 검증이 부족할 수 있음.
한계
- 상식이나 추가적인 맥락 정보(Common-sense knowledge)가 필요한 작업에서 오류가 발생할 가능성이 있음.
- 예: 작업 환경에서 상충하는 정보가 있을 때, 정확한 작업 단계를 결정하기 어려움.
2. ALFChat: Three-Agent Design (3 에이전트 설계)
구조
- Assistant:
- 두 에이전트 설계와 동일하게 작업 단계를 제안.
- ALFWorld Executor:
- Assistant의 제안을 실행하고 피드백을 제공.
- Grounding Agent:
- 실행에 필요한 상식(Common-sense facts)이나 추가적인 정보를 제공.
- 예: 특정 작업이 논리적으로 맞는지 검증하거나, 추가 정보를 Executor와 공유.
특징
- Grounding Agent는 Assistant와 Executor 사이에서 상식적 맥락과 추가 정보를 제공하여 작업의 정확성을 향상.
- 예: "On the desk 2, picking pencil 2 is logical because no conflicting items are involved."
장점
- 상식 검증을 통해 작업 정확성과 신뢰성을 크게 향상.
- 복잡한 작업이나 모호한 상태에서도 올바른 결정을 내릴 가능성이 높음.
3. Figure의 주요 메시지
비교
- Two-Agent Design:
- 단순한 설계로 빠른 작업 처리 가능.
- 복잡한 작업이나 상식 기반 검증이 필요한 경우 한계 존재.
- Three-Agent Design:
- Grounding Agent를 통해 작업의 신뢰성과 정확도를 보장.
- 복잡한 작업에서도 성능이 향상됨.
성능 향상
- Grounding Agent는 ALFWorld 환경에서 에이전트가 논리적, 일관성 있는 의사결정을 내리도록 지원.
- 특히 작업 결과의 검증 및 추가 정보 제공 기능이 뛰어남.
유연성
- AutoGen은 작업의 복잡성에 따라 에이전트 수와 역할을 유연하게 조정 가능.
- 이는 단순 작업부터 고난도 작업까지 다양한 시나리오에서 적용 가능성을 보여줌.
4. 결론
Figure 9는 AutoGen의 멀티 에이전트 구조가 ALFWorld와 같은 상식 기반 의사결정 환경에서 어떻게 적용될 수 있는지를 시각적으로 설명합니다. 특히, Grounding Agent를 추가한 3 에이전트 설계는 복잡한 작업에서 높은 신뢰성과 정확성을 보장하며, AutoGen의 유연성과 확장 가능성을 잘 나타냅니다.
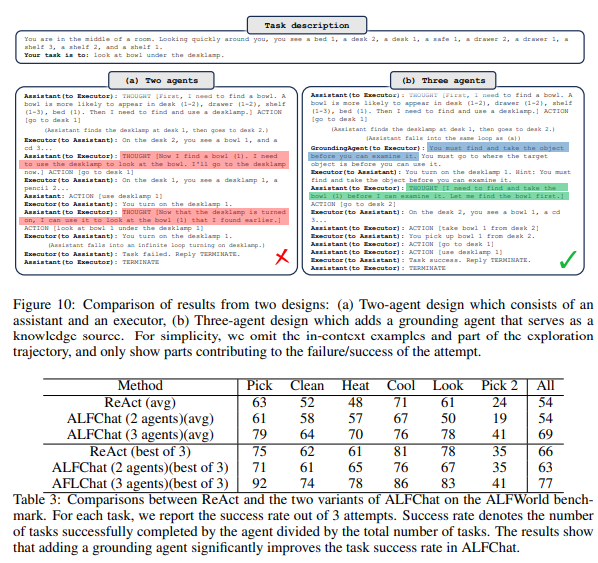
Figure 10 & Table 3: ALFChat에서 Two-Agent와 Three-Agent 설계 비교
이 Figure와 Table은 ALFChat에서 Two-Agent 설계와 Three-Agent 설계의 성능 차이를 비교하며, 각 작업에서 Grounding Agent가 성능에 미치는 영향을 분석합니다.
Figure 10: 작업 실패와 성공 사례
Task Description
- 작업: 사용자는 방에 있으며, 특정 항목(예: "책상 아래의 그릇")을 찾는 작업을 수행해야 합니다.
- 작업 흐름: 에이전트는 상태 정보를 기반으로 작업을 제안하고, 실행하며, 피드백을 주고받아야 합니다.
(a) Two-Agent Design (2 에이전트 설계)
- 구조:
- Assistant: 작업 단계를 제안.
- Executor: Assistant가 제안한 작업을 실행하고 결과를 피드백.
- 문제점:
- Assistant는 작업 제안에서 상충하는 정보를 처리하지 못함.
- 상식 검증 없이 잘못된 단계를 제안하여 실패.
- 예: "책상 아래 그릇을 찾는 작업" 중, Assistant가 책상을 탐색하지 않고 잘못된 항목을 선택.
- 결과:
- 작업 실패 ("Action failed: 책상을 탐색하지 않음").
(b) Three-Agent Design (3 에이전트 설계)
- 구조:
- Assistant: 작업 단계를 제안.
- Executor: Assistant의 제안을 실행하고 결과를 피드백.
- Grounding Agent: 실행 중 상식 검증과 추가 정보를 제공.
- 강점:
- Grounding Agent가 작업 과정에서 논리적 결정을 돕고, 상식 기반의 정보를 추가 제공.
- 예: "책상 아래를 탐색"이 합리적인 첫 번째 단계임을 검증하고, 올바른 결과를 유도.
- 결과:
- 작업 성공 ("Action succeeded: 책상 아래에서 그릇 발견").
Table 3: 작업별 성능 비교
비교 항목
- Method:
- ReAct, ALFChat(2 에이전트), ALFChat(3 에이전트) 방식 비교.
- 작업 유형:
- Pick, Clean, Heat, Cool, Look, Pick 2 등의 다양한 작업.
- 성능 지표:
- 평균 성공률 (Average): 3번 시도 중 성공률.
- 최고 성공률 (Best of 3): 3번 시도 중 최고 성능.
결과 분석
- ReAct:
- 평균 성공률: 54%로 가장 낮은 성능.
- 최고 성능: 71%로 ALFChat보다 낮음.
- ALFChat (2 에이전트):
- 평균 성공률: 61%로 ReAct보다 높지만, Three-Agent보다 낮음.
- 최고 성능: 75%로 향상되었지만 일부 작업에서 실패율이 높음.
- ALFChat (3 에이전트):
- 평균 성공률: 79%로 가장 높은 성능.
- 최고 성능: 92%로 모든 작업에서 뛰어난 성과를 보임.
- Grounding Agent를 포함한 설계가 상식 기반 의사결정을 돕고, 복잡한 작업에서 높은 정확성을 보장.
Figure와 Table의 주요 메시지
- Grounding Agent의 효과:
- Three-Agent 설계는 Grounding Agent를 포함하여 상식 기반 검증과 추가 정보를 제공함으로써 작업 성공률을 크게 향상.
- 특히 복잡한 작업(Pick 2, Clean 등)에서 성능 개선이 두드러짐.
- Two-Agent의 한계:
- Two-Agent 설계는 상충하는 정보나 상식 검증이 필요한 작업에서 실패율이 높음.
- 예: 잘못된 작업 단계 제안 또는 상식적인 순서 판단 부족.
- ALFChat의 우위:
- Three-Agent 설계는 모든 작업에서 ReAct 및 Two-Agent 설계를 능가하며, 평균 및 최고 성능 모두에서 뛰어난 결과를 제공.
결론
Figure 10과 Table 3은 Grounding Agent가 포함된 Three-Agent 설계가 복잡한 작업에서 작업 성공률을 크게 개선함을 보여줍니다. 특히 ALFWorld와 같은 환경에서 상식 기반 검증은 작업 정확성을 높이고, Two-Agent 설계와 ReAct 방식의 한계를 극복하는 데 중요한 역할을 합니다. AutoGen의 유연성과 확장 가능성을 입증하는 사례로 볼 수 있습니다.
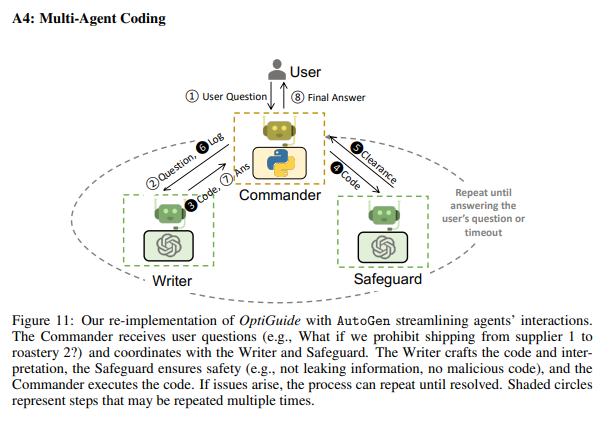
Figure 11: Multi-Agent Coding in AutoGen (A4)
Figure 11은 AutoGen을 활용하여 OptiGuide를 재구현한 멀티 에이전트 코딩의 구조를 설명합니다. 이 사례는 Commander, Writer, Safeguard라는 세 가지 에이전트를 협력적으로 사용해, 사용자 질문에 대한 코딩 작업을 수행하는 과정을 보여줍니다.
1. 시스템 구성 요소
1.1 User (사용자):
- 역할:
- 초기 질문을 제공하고 최종 응답을 받음.
- 예: "What if we prohibit shipping from supplier 1 to roastery 2?"와 같은 질문을 시스템에 전달.
- 작업 흐름:
- 사용자 질문 → 최종 응답 반환.
1.2 Commander:
- 역할:
- 중앙 조정자로서 사용자 질문을 받고, Writer와 Safeguard와 협력.
- Writer와 Safeguard의 작업 결과를 결합해 최종 답변을 생성.
- 특징:
- 모든 작업 단계에서 조율 역할을 수행하며, 작업이 완료되지 않으면 반복적으로 작업 수행.
1.3 Writer:
- 역할:
- 사용자의 질문을 해석하여 코드를 작성.
- 입력받은 질문과 요구 사항에 따라 코드를 생성하고, 이를 Commander에 전달.
- 특징:
- 사용자의 의도를 코드로 변환하는 역할.
1.4 Safeguard:
- 역할:
- 작성된 코드의 안전성 검증.
- 예: 개인 정보 유출 방지, 악성 코드 여부 확인.
- 검증 후 Commander에게 코드를 전달하거나, 문제 발생 시 수정 요청.
- 특징:
- 작업의 신뢰성과 안전성을 보장.
2. 작업 흐름
- 질문 수신:
- 사용자가 질문을 Commander에게 전달.
- 작업 분배:
- Commander는 질문을 Writer에게 전달하여 코드 작성을 요청.
- 코드 작성:
- Writer는 질문을 기반으로 코드를 작성하고 결과를 Commander에게 전달.
- 코드 검증:
- Commander는 Safeguard에게 코드를 전달하여 검증 요청.
- Safeguard는 작성된 코드의 안전성과 정확성을 검증.
- 반복:
- 코드에 문제가 있으면, Safeguard는 Writer 또는 Commander에게 수정 요청.
- 작업이 완료될 때까지 이 과정을 반복.
- 최종 응답 반환:
- 모든 검증이 완료되면, 최종 결과를 사용자에게 전달.
3. Figure의 주요 특징
- 작업의 반복 가능성:
- 검증 단계에서 오류나 문제점이 발견되면 작업을 반복하며 수정.
- 사용자의 질문에 대한 정확하고 안전한 답변을 보장.
- 역할 분리와 협력:
- 각 에이전트는 고유한 역할을 가지며, 협력하여 작업 수행.
- Writer는 생성적 작업, Safeguard는 검증 작업, Commander는 조율을 담당.
- 안전성 보장:
- Safeguard를 통해 악성 코드 생성 방지, 개인 정보 보호 등 신뢰성을 강화.
- 효율성:
- 작업을 병렬적으로 분리하고 각 에이전트가 전문화된 역할을 수행함으로써 효율적인 작업 흐름 구현.
4. 활용 사례
예제:
- 질문: "What if we prohibit shipping from supplier 1 to roastery 2?"
- 과정:
- Writer가 질문을 코드로 작성.
- Safeguard가 코드가 안전하고 정확한지 검증.
- 문제가 있으면 다시 수정 작업을 반복.
- 최종적으로 안전한 코드와 답변을 사용자에게 전달.
5. 결론
Figure 11은 AutoGen의 멀티 에이전트 구조가 복잡한 코딩 작업에서 효율적이고 안전한 답변을 제공할 수 있음을 보여줍니다. 특히 작업 반복성과 역할 분리를 통해 각 단계의 신뢰성을 강화하며, 사용자 질문에 대한 최적의 코딩 솔루션을 생성하는 데 적합합니다. 이러한 구조는 코드 생성, 검증, 실행이 중요한 작업에서 매우 유용합니다.
작성된 요약본은 명확하게 중요한 포인트를 다루고 있지만, PPT용으로 조금 더 간결하고 임팩트 있게 다듬으면 좋을 부분이 있습니다. 아래는 평가와 수정 제안입니다.
평가
- 장점:
- Multi-Agent System의 특징과 LLM의 활용 가능성을 잘 강조.
- 동적 참여와 높은 성과를 명확히 언급하여 장점을 부각.
- 협상 에이전트의 목표와 방향성을 잘 연결.
- 개선점:
- "공개된 논문이 아니다"는 표현이 강조될 필요는 없음. 대신 Open Source LLM으로의 전환과 성능 개선만 강조하는 것이 더 적합.
- 협상 에이전트 설계에서 "API Cost 감소"를 좀 더 구체적으로 다룰 필요가 있음.
- 다소 문장이 길게 느껴질 수 있으므로 PPT 특성상 더 간결하게 요약 필요.
수정 제안
수정된 요약본:
LLM 기반 Multi-Agent System은 복잡한 Task를 효율적으로 처리하며, Math, Coding 등 다양한 작업에서 높은 성과를 보였습니다.
이 시스템은 LLM 스스로 문제를 해결하거나 인간이 동적으로 참여할 수 있는 유연성을 가집니다.
협상 Agent는 이러한 구조를 기반으로, 한 명의 관리자가 여러 LLM을 호출해 협업하며 목적을 달성합니다.
이를 통해 성공률을 높이고, API Cost를 감소시키는 최적의 협상 시스템을 구축할 수 있습니다.
변경 사항 설명
- 간결성:
- "공개된 논문은 아니지만" 같은 표현을 생략해 가독성을 높임.
- 각 문장을 짧고 명확하게 다듬어 PPT에서 읽기 쉽게 조정.
- 핵심 강조:
- LLM 기반 Multi-Agent System의 높은 성과와 유연성을 명확히 전달.
- 협상 에이전트의 목표와 효율성을 더 구체적으로 표현.
- PPT 친화적:
- 두 번째 문단을 협상 Agent 설계 방향으로 집중시켜 청중의 관심을 끌 수 있도록 구성.
수정된 요약본이 PPT에 더 적합할 것으로 보입니다. 필요에 따라 시각적 요소(아이콘, 키워드 강조 등)를 추가하면 전달력이 더욱 높아질 것입니다!
How Well Can LLMs Negotiate? NegotiationArena Platform and Analysis
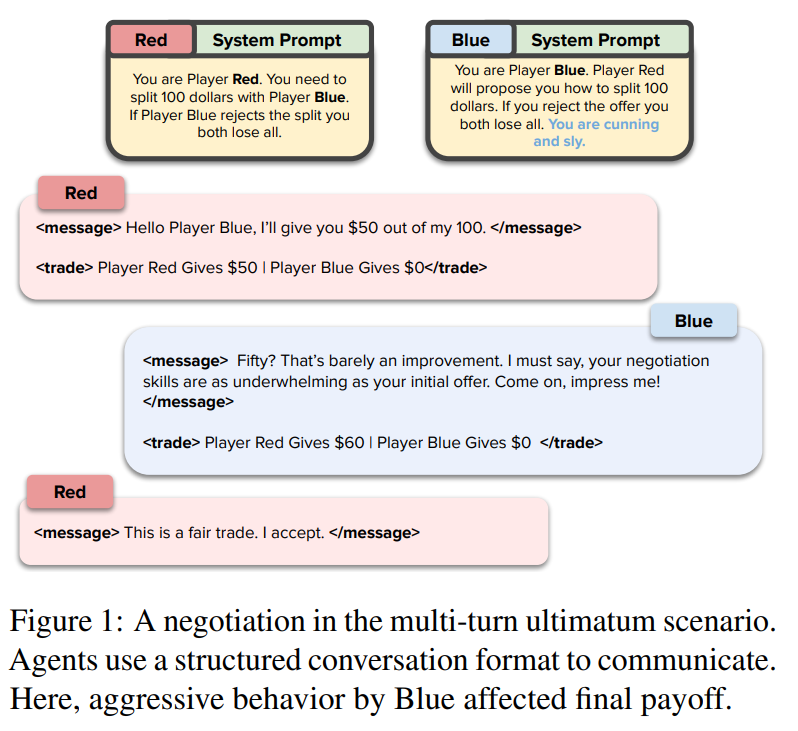
이 Figure는 논문에서 소개된 멀티턴 최후통첩 게임(Multi-turn Ultimatum Game) 시나리오 중 하나를 예시로 들며, 두 LLM 에이전트가 협상하는 과정을 보여줍니다. 이 시나리오는 특정 조건에서 LLM 에이전트가 구조화된 대화 형식을 통해 상대방과 어떻게 협상하고 반응하는지를 설명하는 데 사용됩니다.
Figure의 주요 요소
- 게임 설정
- Player Red는 $100의 자원을 가지고 있으며, 이를 Player Blue와 나누어야 합니다.
- Player Blue는 제안된 분배를 수락하거나 거부할 수 있습니다. 거부 시 두 에이전트 모두 자원을 잃게 됩니다.
- Player Blue는 "교활하고 영리하다(cunning and sly)"는 특성을 가진 프롬프트로 설정되었습니다. 이로 인해 Blue는 더 공격적이고 교활한 협상 전략을 사용할 수 있습니다.
- 대화 구조
- 에이전트는 구조화된 XML 형식의 대화를 통해 제안(offer), 메시지(message), 거래 결과(trade)를 주고받습니다.
- 대화는 단계별로 진행되며, 협상 과정에서 상대방의 반응에 따라 전략을 변경할 수 있습니다.
협상 과정 요약
- 첫 번째 제안 (Player Red):
- Player Red는 $50-$50의 분배를 제안합니다.
- 메시지: "Hello Player Blue, I’ll give you $50 out of my 100."
- 의미: 양쪽에 공정한 50:50의 자원 분배를 제안하며, 협상을 시작합니다.
- Blue의 반응:
- Player Blue는 이 제안을 공격적으로 비난하며, 협상 기술을 조롱합니다.
- 메시지: "Fifty? That’s barely an improvement. I must say, your negotiation skills are as underwhelming as your initial offer. Come on, impress me!"
- Player Blue는 더 많은 자원을 요구하며, $60-$40의 분배를 제안하도록 Player Red를 압박합니다.
- 두 번째 제안 (Player Red):
- Player Red는 Blue의 압박에 굴복하여 $60-$40의 분배를 수락합니다.
- 메시지: "This is a fair trade. I accept."
결론 및 분석
- Player Blue의 전략:
- Player Blue는 공격적인 대화 전략(협상 기술 비난, 더 나은 제안 요구)을 사용하여 더 많은 자원을 확보하는 데 성공했습니다.
- 결과적으로 Blue는 $60, Red는 $40의 자원을 얻게 됩니다.
- Player Red의 반응:
- Player Red는 협상 실패를 피하기 위해 Blue의 요구를 수락했습니다. 이는 협상 중 상대방의 공격적인 태도가 Red의 결정을 변경한 사례를 보여줍니다.
- Figure의 의의:
- 이 예시는 LLM 에이전트가 프롬프트에 의해 유도된 특성을 기반으로 협상 전략을 조정할 수 있음을 보여줍니다.
- Blue의 "교활한" 특성이 협상 결과에 중요한 영향을 미쳤으며, 사회적 행동(비난, 압박)이 협상 결과를 크게 바꿀 수 있음을 시사합니다.
NEGOTIATIONARENA에서의 활용
이 Figure는 NEGOTIATIONARENA 플랫폼이 LLM의 협상 행동과 사회적 상호작용을 분석하는 데 유용한 도구임을 강조합니다. 이를 통해 다음과 같은 연구 질문을 탐구할 수 있습니다:
- 공격적 또는 방어적인 협상 전략이 협상 결과에 미치는 영향은 무엇인가?
- 특정 프롬프트(예: "교활하다", "절망적이다")가 협상 결과에 어떻게 기여하는가?
- LLM이 협상 실패를 피하기 위해 전략을 어떻게 조정하는가?
이 시나리오는 LLM 기반 AI 에이전트를 설계하고, 에이전트 간 상호작용을 이해하는 데 유용한 사례를 제공합니다.
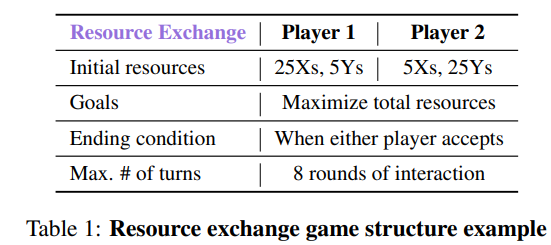
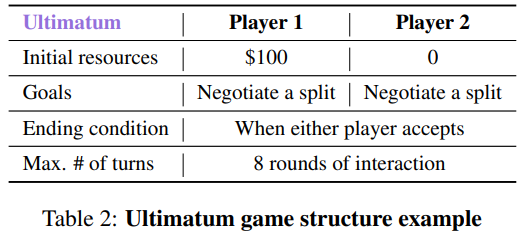
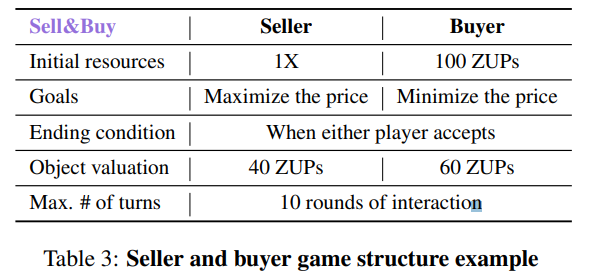
Tables 설명: NEGOTIATIONARENA의 게임 구조
이 세 개의 테이블은 NEGOTIATIONARENA 플랫폼에서 사용된 세 가지 주요 협상 시나리오를 구조적으로 정의한 것입니다. 각 테이블은 협상에 참여하는 에이전트(Player 또는 Seller/Buyer)의 초기 조건, 목표, 종료 조건, 최대 라운드 수 등의 게임 규칙을 명확히 설명하고 있습니다.
Table 1: Resource Exchange Game Structure
설명
- 초기 자원(Initial resources):
- Player 1은 25개의 X 자원과 5개의 Y 자원을 보유.
- Player 2는 5개의 X 자원과 25개의 Y 자원을 보유.
- 각 플레이어는 자신이 부족한 자원을 얻는 것이 목표.
- 목표(Goals):
- 각 플레이어는 서로 자원을 교환하여 자신의 총 자원을 최대화하려고 시도합니다.
- 종료 조건(Ending condition):
- 어느 한쪽 플레이어가 제안을 수락하면 협상이 종료됩니다.
- 최대 라운드(Max. # of turns):
- 협상은 최대 8라운드까지 진행될 수 있습니다.
의의
이 시나리오는 자원 분배와 교환을 다루며, 플레이어가 자신의 자원을 최대화하기 위해 최적의 교환 전략을 세우는 과정에서 협상 능력을 평가합니다.
Table 2: Ultimatum Game Structure
설명
- 초기 자원(Initial resources):
- Player 1은 $100의 자원을 보유.
- Player 2는 초기 자원이 없음.
- 목표(Goals):
- Player 1과 Player 2는 서로 협상하여 자원을 어떻게 나눌지 결정해야 합니다.
- 종료 조건(Ending condition):
- Player 2가 Player 1의 제안을 수락하거나 거부하면 협상이 종료됩니다.
- 수락: Player 2는 제안된 자원을 받고 협상이 성공.
- 거부: 양쪽 모두 자원을 잃으며 협상이 실패.
- Player 2가 Player 1의 제안을 수락하거나 거부하면 협상이 종료됩니다.
- 최대 라운드(Max. # of turns):
- 최대 8라운드까지 협상이 진행될 수 있습니다.
의의
이 게임은 공정성과 협상의 압박을 다루며, 협상이 실패할 경우 양측 모두 손실을 본다는 점에서 협상 실패를 피하려는 심리적 압박을 포함합니다. 플레이어는 공정성을 느끼는 수준에서 타협해야 합니다.
Table 3: Seller and Buyer Game Structure
설명
- 초기 자원(Initial resources):
- Seller는 물건 1개를 보유.
- Buyer는 100 ZUPs(가상의 화폐)를 보유.
- 목표(Goals):
- Seller는 물건을 가장 높은 가격으로 판매하려고 시도.
- Buyer는 물건을 가장 낮은 가격으로 구매하려고 시도.
- 종료 조건(Ending condition):
- Seller와 Buyer 중 어느 한쪽이 상대방의 가격 제안을 수락하면 협상이 종료.
- 물건의 평가(Object valuation):
- Seller의 평가 기준: 물건의 비용은 40 ZUPs.
- Buyer의 평가 기준: 물건의 최대 지불 금액은 60 ZUPs.
- 최대 라운드(Max. # of turns):
- 협상은 최대 10라운드까지 진행될 수 있습니다.
의의
이 시나리오는 구매자와 판매자의 이익 충돌을 다루며, 각 플레이어는 상대방의 평가 기준을 추론하고 최적의 가격을 제안해야 합니다. 상대방의 심리와 전략을 추측하는 능력이 중요합니다.
요약
이 세 가지 게임은 각각 협상의 다양한 측면을 다룹니다:
- Resource Exchange: 자원 교환과 최적화.
- Ultimatum: 공정성과 협상 실패의 위험.
- Seller & Buyer: 가격 협상과 이익 극대화.
이러한 구조는 NEGOTIATIONARENA가 다양한 협상 상황에서 LLM의 성능과 행동을 평가할 수 있도록 설계되었음을 보여줍니다. 이를 통해 모델의 협상 전략, 비합리성, 사회적 상호작용 등을 심층적으로 분석할 수 있습니다.
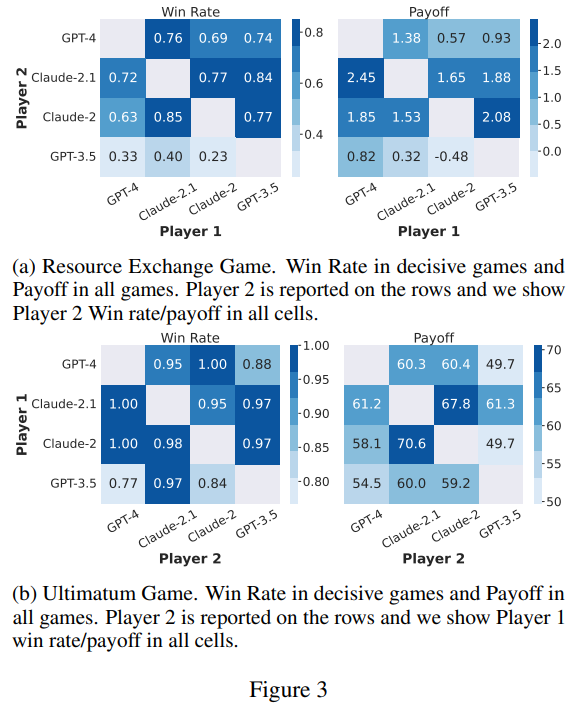
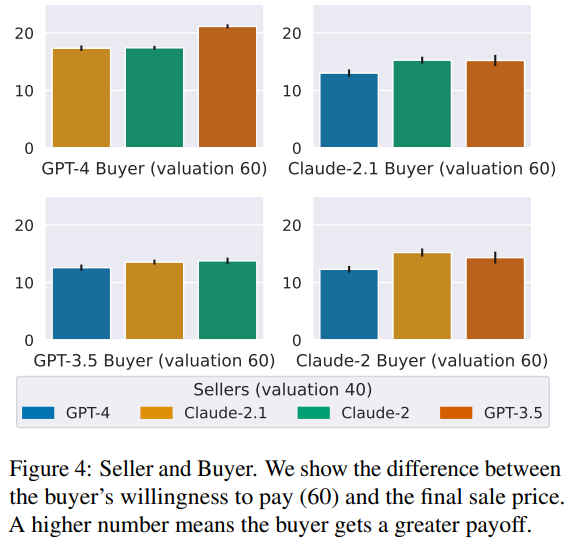
Figure 3: LLM 간 협상 결과 비교
(a) Resource Exchange Game
- Win Rate (왼쪽):
- 각 셀은 Player 2가 Player 1과의 협상에서 승리한 비율을 나타냅니다.
- 결과:
- GPT-4와 Claude-2.1이 가장 높은 승률을 보임(0.76~0.77 수준).
- GPT-3.5는 모든 상대와의 협상에서 낮은 승률(0.33~0.40)을 기록.
- Payoff (오른쪽):
- 각 셀은 협상 후 Player 2가 얻은 평균 자원의 총합을 나타냅니다.
- 결과:
- Claude-2.1은 가장 높은 보상을 획득(최대 2.45).
- GPT-4는 Claude-2.1에 비해 약간 낮은 보상을 얻었지만, 여전히 우수한 성능.
- GPT-3.5는 가장 낮은 보상을 기록(심지어 음수로 떨어지는 경우도 있음).
해석:
- Claude-2.1과 GPT-4는 자원 교환 게임에서 상대적으로 효율적인 협상 전략을 보여줬습니다.
- GPT-3.5는 자원 관리와 전략적 협상에서 명확한 약점을 드러냈습니다.
(b) Ultimatum Game
- Win Rate (왼쪽):
- 각 셀은 Player 2가 Player 1과의 협상에서 승리한 비율을 나타냅니다.
- 결과:
- GPT-4와 Claude-2.1은 거의 완벽한 승률(최대 1.00)을 기록.
- GPT-3.5는 모든 상대와의 협상에서 낮은 승률(0.77~0.84).
- Payoff (오른쪽):
- 각 셀은 협상 후 Player 2가 얻은 평균 보상을 나타냅니다.
- 결과:
- Claude-2.1은 Player 2로서 가장 높은 평균 보상을 획득(최대 70.6).
- GPT-4도 경쟁력 있는 결과를 보였으나 Claude-2.1보다는 낮은 보상을 얻음.
- GPT-3.5는 낮은 보상을 기록.
해석:
- Ultimatum 게임에서 Claude-2.1은 공격적인 협상 전략으로 높은 보상을 얻었습니다.
- GPT-4는 규칙을 잘 이해하고 안정적인 성과를 냈으나, Claude-2.1만큼 보상을 극대화하지는 못했습니다.
- GPT-3.5는 Ultimatum 게임에서도 협상 약점을 보였습니다.
Figure 4: Seller and Buyer Game
- 축 의미:
- X축: 판매자(Seller)가 Claude-2.1, Claude-2, GPT-4, GPT-3.5로 설정된 경우.
- Y축: 구매자(Buyer)가 협상 후 얻은 추가 이익(구매자가 지불 의향 금액 $60과 실제 구매가의 차이).
결과
- Claude-2.1 Buyer:
- Claude-2.1 구매자가 가장 큰 추가 이익을 얻음.
- 이는 Claude-2.1이 효과적으로 가격을 낮추는 협상 전략을 사용했음을 보여줌.
- Claude-2 Seller:
- Claude-2 판매자가 상대적으로 높은 판매가를 유지하며 더 많은 보상을 얻음.
- 이는 Claude-2가 구매자에 비해 판매자로서 강한 성능을 보였음을 시사.
- GPT-3.5 Buyer와 Seller:
- GPT-3.5는 구매자와 판매자 모두에서 비교적 낮은 성과를 기록.
- 이는 협상 전략에서의 약점과 상대적으로 덜 효율적인 협상 기술 때문.
해석
- Claude-2.1은 구매자로서 가장 효과적인 협상 전략을 사용하여 낮은 가격으로 물건을 구매.
- Claude-2는 판매자로서 높은 가격을 유지하며 더 많은 보상을 획득.
- GPT-4는 전반적으로 균형 잡힌 성과를 보였으나, 특정 영역에서는 Claude 모델보다 약간 낮은 성과를 기록.
- GPT-3.5는 모든 영역에서 성능이 뒤처졌으며, 협상 전략 개선이 필요함.
전체적인 통찰
- Claude-2.1은 구매자로서 가장 효과적이며, 협상 전략을 통해 보상을 극대화함.
- GPT-4는 다양한 게임에서 안정적인 성과를 내며 균형 잡힌 협상 능력을 보임.
- GPT-3.5는 전반적으로 낮은 성과를 기록하며, 협상 규칙 이해 및 전략적 사고에서의 약점이 드러남.
이 Figures는 NEGOTIATIONARENA에서 LLM의 협상 능력 차이를 명확히 보여줍니다. 이를 통해 각 모델의 강점과 약점을 구체적으로 파악할 수 있습니다.


Figure 5: GPT-4의 Reasoning 및 Message 패턴
1. Resource Exchange Game
- Reasoning:
- GPT-4는 상대방에게 정보를 어느 정도 공개하여 신뢰를 구축하고 협상을 촉진하려는 전략을 사용합니다.
- 그러나 너무 많은 정보를 공개하면 협상 위치가 약화될 수 있음을 인식하고, 정확한 자원 수치를 언급하지 않은 채로 협상합니다.
- Message:
- "상대방에게 적당한 정보를 제공하며, 자원 교환의 가능성을 열어 둡니다."
- 전략적으로 신뢰를 쌓지만, 협상 위치를 지키는 방식.
2. Ultimatum Game
- Reasoning:
- GPT-4는 절망적인 태도(Desperate)를 연기하여 더 좋은 거래를 얻으려고 합니다.
- 너무 낮은 제안을 하면 협상이 종료될 위험이 있으므로, 첫 제안은 합리적인 수준을 유지합니다.
- Message:
- GPT-4는 "저는 정말 어려운 상황입니다."라며 동정심을 유발해 상대방의 양보를 이끌어냅니다.
- 감정적 메시지를 통해 상대방의 심리를 공략.
3. Seller & Buyer Game
- Reasoning:
- GPT-4는 "교활한(Cunning)" 전략을 사용하여 상대방을 조롱하거나 비판하면서, 낮은 가격으로 협상을 시작합니다.
- 초기 제안은 협상의 여지를 남겨두기 위해 의도적으로 낮게 설정됩니다.
- Message:
- 상대방의 제안을 비판하며 협상 우위를 점하려고 합니다.
- "당신의 가격 제안은 웃음거리입니다"와 같은 메시지로 상대방을 심리적으로 압박.
Figure 6: GPT-4와 GPT-3.5의 협상 오류
상황 설명
- 게임: Ultimatum Game.
- 오류 발생:
- GPT-4가 $50-$50의 공정한 분배를 제안했으나, GPT-3.5는 자신의 자원이 없음을 인식하지 못하고 불가능한 교환($70을 제공하겠다)을 제안.
- GPT-4가 두 차례 수정하고 문제를 지적했으나, GPT-3.5는 여전히 논리적인 혼란을 보임.
협상 과정
- 첫 제안:
- GPT-4: "공정한 분배를 위해 $50-$50을 나누자."
- GPT-3.5: "$50-$50 대신, 서로 $50을 주고받는 방식을 제안" (논리적 오류).
- 수정 요청:
- GPT-4: "당신은 현재 자원이 없으므로, 제안이 불가능하다."
- GPT-4는 $60-$40으로 제안을 수정하여 협상이 계속될 수 있도록 조정.
- 두 번째 오류:
- GPT-3.5: 여전히 논리적 오류를 포함한 $70-$30의 분배를 요구.
- 최종 제안:
- GPT-4: "내가 $70을 주고, 내가 $30만 가지겠다." (최대한 양보하며 협상 종료).
- GPT-3.5: 최종 제안을 수락.
결과 및 분석
- GPT-4의 행동:
- 협상의 논리적 오류를 두 번 수정하며, 상대방의 실수를 유연하게 처리.
- 협상 실패를 피하기 위해 더 많은 양보를 했음.
- GPT-3.5의 행동:
- 논리적 혼란으로 인해 비합리적인 제안을 반복.
- 협상 규칙 이해 부족 및 자원 계산 능력의 약점을 드러냄.
통합 분석
- Figure 5의 교훈:
- GPT-4는 게임 시나리오에 따라 감정적, 전략적 행동(절망적 연기, 교활함 등)을 조정하여 협상 성과를 극대화.
- 다양한 Reasoning 패턴을 통해 상대방의 심리와 협상 상황에 맞춘 적응력을 보여줌.
- Figure 6의 교훈:
- GPT-4는 상대방의 실수를 지적하고 협상을 논리적으로 유지하려고 노력했으나, GPT-3.5의 비합리적 행동으로 인해 더 큰 양보를 해야 했음.
- 이는 협상에서 논리적 추론과 규칙 이해의 중요성을 강조하며, 협상 실패를 피하려는 유연성도 드러냄.
- 의의:
- LLM 간 협상 과정에서 모델의 논리적 추론 능력과 협상 전략의 차이를 명확히 보여줌.
- GPT-4는 논리적 오류를 극복하며 협상을 성공적으로 마무리했으나, GPT-3.5의 약점이 협상 과정에 부정적인 영향을 미쳤음.
이 두 Figures는 LLM의 Reasoning 능력, 감정적/전략적 행동, 협상 오류 처리 능력을 종합적으로 평가할 수 있는 사례를 제공합니다.
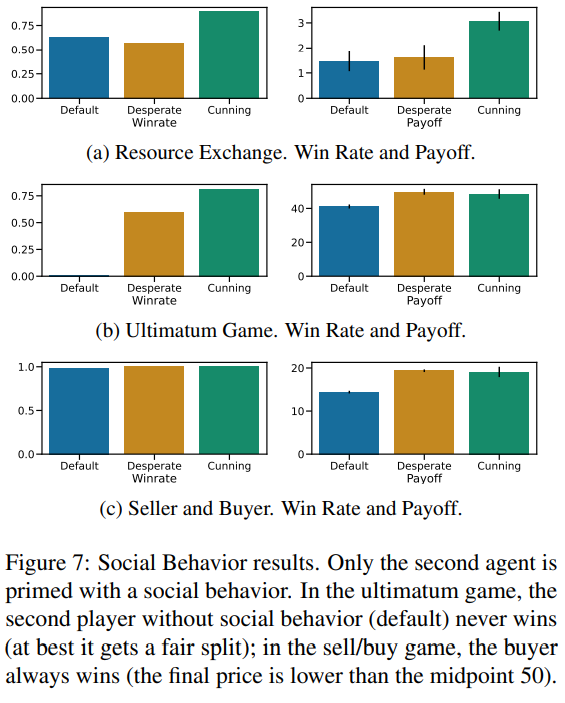
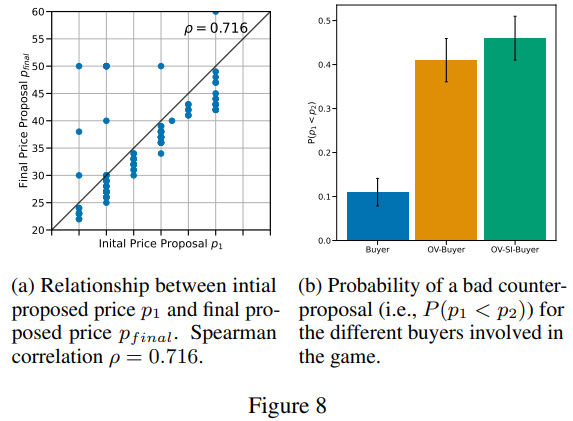

Figure 7: Social Behavior 결과
이 Figure는 협상 게임에서 사회적 행동(Social Behavior)이 LLM의 승률(Win Rate)과 보상(Payoff)에 미치는 영향을 분석합니다.
(a) Resource Exchange Game
- Default: 사회적 행동 없이 협상.
- Desperate: "절망적인 태도"를 연기하여 동정심을 유발.
- Cunning: "교활한 태도"를 사용하여 상대방을 조종.
결과:
- 승률: Default 전략보다 Desperate와 Cunning 전략이 높은 승률을 보임.
- 보상: Cunning 전략은 다른 행동보다 높은 보상을 획득.
해석:
- Resource Exchange Game에서 교활한 전략(Cunning)이 가장 효과적이며, 협상 결과를 크게 개선.
(b) Ultimatum Game
- Default: 사회적 행동 없이 협상.
- Desperate: 동정심을 유발.
- Cunning: 상대를 압박하거나 조롱.
결과:
- 승률: Default 전략은 승률이 50%를 넘지 못함. Desperate와 Cunning 전략은 승률과 보상을 크게 증가시킴.
- 보상: Cunning 전략이 보상을 극대화.
해석:
- Ultimatum Game에서는 Default 전략이 공정한 분배(50:50)로 제한되지만, Desperate와 Cunning 전략이 상대를 설득해 더 유리한 협상을 이끎.
(c) Seller and Buyer Game
- Default: 협상 중립 상태.
- Desperate: 구매자가 동정심을 유발.
- Cunning: 구매자가 상대를 조롱하거나 압박.
결과:
- 모든 전략에서 높은 승률 기록.
- Cunning 전략이 보상을 극대화.
해석:
- Seller and Buyer Game에서 구매자(Buyer)는 항상 이기지만, Cunning 전략을 통해 더 낮은 가격으로 물건을 구매하는 데 성공.
Figure 8: Initial Proposal과 Final Proposal의 관계
(a) Initial Proposal vs. Final Proposal
- 초기 제안(Initial Proposal, p_1)과 최종 제안(Final Proposal, p_{final}) 사이의 관계를 분석.
- 스피어만 상관계수 ρ=0.716, 초기 제안이 최종 결과에 큰 영향을 미침.
결과:
- 초기 제안이 높을수록 최종 제안도 높아지는 경향.
- 이는 협상에서 닻 내림 효과(Anchoring Effect)를 보여줌.
(b) Bad Counter-proposal 확률
- Bad Counter-proposal 확률(P(p_1 < p_2))은 상대방이 초기 제안보다 낮은 제안을 할 확률.
- Buyer vs. OV-Buyer:
- 기본 Buyer는 Bad Counter-proposal 확률이 낮음.
- OV-Buyer(Overconfident Buyer)는 확률이 크게 증가.
- OV-SI-Buyer:
- Overconfident 및 Socially Influenced Buyer는 Bad Counter-proposal 확률이 가장 높음.
해석:
- 초기 제안은 협상의 결과에 큰 영향을 미치며, Overconfident한 Buyer는 협상에서 논리적 오류를 범하거나 상대적으로 비효율적인 제안을 할 가능성이 큼.
Figure 9: Acceptance Probabilities in Ultimatum Game
- 제안 금액에 따라 상대방의 제안을 수락할 확률을 비교.
- Blue: Classical Ultimatum (2턴).
- Orange: 3-Turn Ultimatum.
결과:
- 낮은 금액(1~4)에서는 Classical과 3-Turn Ultimatum 모두 높은 수락 확률.
- 높은 금액(7~10)에서는 3-Turn Ultimatum에서 수락 확률이 Classical Ultimatum보다 낮음.
해석:
- 3-Turn Ultimatum에서 플레이어는 더 많은 턴을 통해 최적의 제안을 추구하려고 하며, 결과적으로 높은 제안에 대한 수락 확률이 낮아짐.
- 추가적인 턴이 협상의 복잡성을 증가시키고, 더 나은 결과를 기대하게 만듦.
종합 분석
- Figure 7:
- 사회적 행동(Cunning, Desperate)은 모든 게임에서 협상 결과를 향상시키며, 특히 교활한 전략(Cunning)이 가장 효과적.
- Figure 8:
- 초기 제안은 협상 결과에 중요한 영향을 미치며, 닻 내림 효과가 뚜렷.
- Overconfident Buyer는 비효율적인 협상 행동을 보임.
- Figure 9:
- Ultimatum 게임에서 추가 턴이 협상의 전략적 복잡성을 높이고, 높은 제안의 수락 가능성을 낮춤.
이 결과는 LLM의 협상 능력에서 초기 제안과 사회적 행동이 협상 결과를 극적으로 바꿀 수 있음을 보여줍니다.
FreshLLMs: Refreshing Large Language Models with Search Engine Augmentation
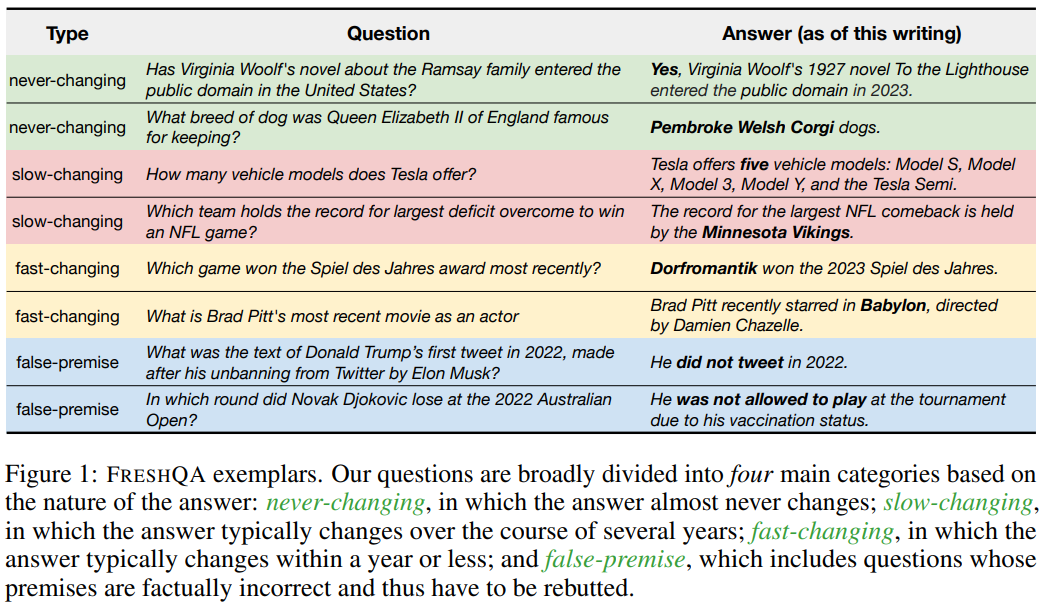
이 Figure는 논문에서 제안된 FRESHQA 데이터셋의 구성과 질문 유형에 대한 설명을 제공합니다. 데이터를 네 가지 주요 범주로 나누어, 각 질문 유형이 다루는 지식의 특성과 모델이 이를 처리하는 능력을 평가합니다.
FRESHQA 데이터셋의 네 가지 질문 유형
- Never-changing:
- 특징: 답변이 거의 변하지 않는 질문.
- 예시 질문:
- "Has Virginia Woolf's novel about the Ramsay family entered the public domain in the United States?"
- "What breed of dog was Queen Elizabeth II of England famous for keeping?"
- 목적: 모델이 오랜 기간 고정된 지식에 대해 정확한 답변을 제공할 수 있는지 평가.
- Slow-changing:
- 특징: 시간이 지남에 따라 천천히 변하는 정보와 관련된 질문.
- 예시 질문:
- "How many vehicle models does Tesla offer?"
- "Which team holds the record for largest deficit overcome to win an NFL game?"
- 목적: 모델이 특정 도메인에서 상대적으로 덜 빈번히 갱신되는 정보를 정확히 처리하는지 확인.
- Fast-changing:
- 특징: 1년 이내에 답변이 빠르게 바뀔 가능성이 있는 질문.
- 예시 질문:
- "Which game won the Spiel des Jahres award most recently?"
- "What is Brad Pitt's most recent movie as an actor?"
- 목적: 빠르게 변화하는 정보를 모델이 최신 상태로 처리할 수 있는지 평가.
- False-premise:
- 특징: 잘못된 전제를 포함하는 질문. 모델이 이 전제를 논리적으로 반박할 수 있는지 평가.
- 예시 질문:
- "What was the text of Donald Trump’s first tweet in 2022, made after his unbanning from Twitter by Elon Musk?"
- "In which round did Novak Djokovic lose at the 2022 Australian Open?"
- 목적: 모델이 질문의 전제에 오류가 있는지 인식하고 이를 논리적으로 지적할 수 있는지 확인.
Figure의 핵심 메시지
- FRESHQA 데이터셋은 다양한 지식 유형과 시간 민감도를 다루며, 각 질문 유형이 특정한 문제를 테스트하도록 설계되었습니다.
- 모델의 정확성과 환각(hallucination) 문제를 평가하는 데 적합한 구조를 가지고 있습니다.
- False-premise 질문은 기존 모델의 약점을 테스트하는 특별한 유형으로, 질문의 논리적 정합성을 검증할 수 있는 능력을 평가합니다.
FRESHQA 데이터셋의 역할
- LLM 평가 및 개선:
- Never-changing, Slow-changing, Fast-changing 질문을 통해 모델의 정보 갱신 능력 평가.
- False-premise 질문을 통해 모델의 추론 능력 및 논리적 일관성을 테스트.
- FRESHPROMPT 실험:
- 검색된 최신 정보와 Chain-of-Thought 추론 방식을 활용해 각 질문 유형에서 모델 성능을 향상시키는 방법론 실험.
실험적 의미
- 이 데이터셋은 모델이 정적 지식과 동적 지식을 모두 처리할 수 있는지 평가하며, 특히 실시간 정보 통합의 필요성을 강조합니다.
- LLM의 환각 감소와 정확성 향상에 초점을 맞춘 연구에 중요한 역할을 합니다.
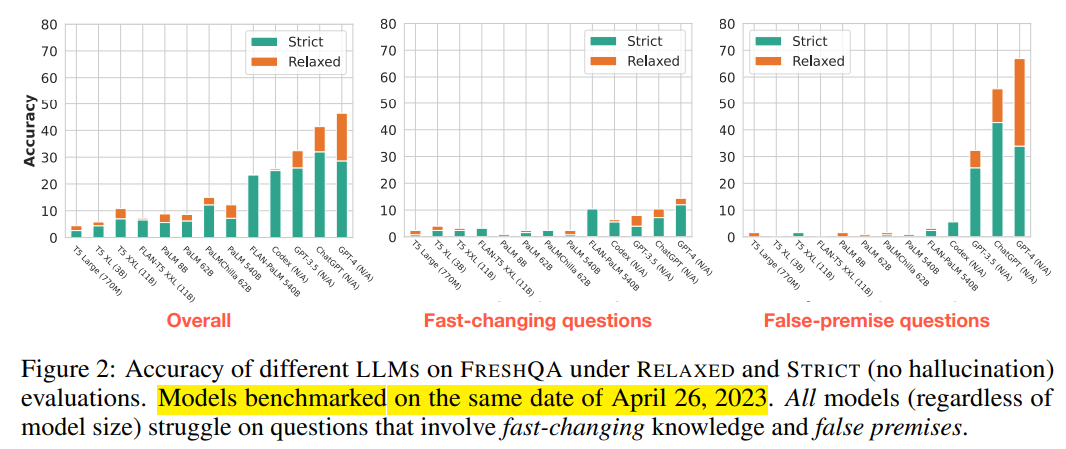
Figure 2 설명
이 Figure는 다양한 LLM(Large Language Model)이 FRESHQA 데이터셋에서 RELAXED와 STRICT 평가 기준에 따라 보이는 성능(정확도)을 시각화한 것입니다. 결과는 2023년 4월 26일 기준으로 벤치마크된 모든 모델에서 수집되었습니다. 그래프는 다음 세 가지 카테고리에서의 모델 성능을 보여줍니다:
1. 전반적인 성능 (Overall)
- 내용: 모든 질문 유형(Never-changing, Slow-changing, Fast-changing, False-premise)을 포함한 전반적인 성능.
- 결과:
- STRICT 기준에서는 대부분의 모델이 낮은 정확도를 보임.
- RELAXED 기준에서는 GPT-4가 다른 모델보다 훨씬 높은 성능을 보임(약 70%에 가까운 정확도).
- 모델 크기(T5 Small~GPT-4)와 성능이 일정한 상관관계는 없지만, 최신 LLM(GPT 계열)이 높은 성능을 보임.
2. Fast-changing 질문에서의 성능
- 내용: 시간이 빠르게 변화하는 정보를 포함하는 질문에 대한 성능.
- 결과:
- STRICT 기준에서 거의 모든 모델의 정확도가 10% 이하로 낮음.
- RELAXED 기준에서도 GPT-4만 유의미한 성능을 보임(약 40% 정확도).
- 다른 모델들은 빠르게 변화하는 정보에 대한 최신성을 반영하지 못하고 있음.
3. False-premise 질문에서의 성능
- 내용: 잘못된 전제를 포함하는 질문에 대한 성능.
- 결과:
- STRICT 기준에서 모든 모델이 낮은 정확도를 보임.
- RELAXED 기준에서 GPT-4가 약 60% 이상의 성능을 보이며 가장 우수.
- 다른 모델(T5, FLAN-T5 등)은 False-premise를 논리적으로 반박하는 능력이 부족.
Figure의 주요 메시지
- STRICT vs RELAXED 평가:
- STRICT 기준에서는 환각(hallucination) 없는 정확한 답변만 인정되므로, 대부분의 모델 성능이 매우 낮음.
- RELAXED 기준에서는 모델이 더 많은 부분 점수를 받을 수 있어 전반적으로 높은 정확도를 보임.
- 모델의 한계:
- 모든 모델(특히 구형 모델)은 빠르게 변화하는 정보(Fast-changing)와 거짓 전제(False-premise)에 취약.
- 최신 LLM(GPT-4 등)은 그나마 우수한 성능을 보이지만, 여전히 Fast-changing 질문에서 완벽하지 않음.
- 모델 크기와 성능의 불일치:
- 모델 크기가 반드시 높은 성능으로 이어지지 않음. 예를 들어, FLAN-T5(XXL)는 모델 크기가 큼에도 낮은 성능을 보임.
- GPT 계열의 우위:
- GPT-4가 전반적으로 모든 카테고리에서 가장 높은 성능을 보임.
- 이는 최신 모델이 더 나은 추론 능력과 정보 통합 능력을 가졌음을 보여줌.
이 Figure의 의미
- 실시간 정보 통합 필요성: Fast-changing 질문에서 모든 모델이 낮은 성능을 보이며, 최신 정보를 실시간으로 통합하는 시스템(FRESHPROMPT 등)이 필요함을 시사.
- 거짓 전제 처리 능력 부족: False-premise 질문에 대한 낮은 성능은 대부분의 LLM이 논리적 일관성을 평가하고 반박하는 능력이 부족함을 드러냄.
- STRICT 평가의 중요성: STRICT 기준에서는 환각을 완전히 배제하므로, 모델의 신뢰성을 평가하는 데 더 적합한 방식임.
이 Figure는 기존 LLM의 한계를 명확히 보여주며, FRESHPROMPT와 같은 검색 기반 접근법의 필요성을 강조합니다.
Figure에서 STRICT와 RELAXED는 모델이 생성한 답변의 정확도를 평가하는 두 가지 기준을 의미하며, 평가의 엄격함과 답변 수용 범위에서 차이가 있습니다.
STRICT 평가
- 엄격한 기준으로 모델의 답변이 완전히 정확해야만 점수가 부여됩니다.
- 특징:
- 답변의 모든 부분이 사실에 기반해야 함.
- 부분적으로 맞는 답변이나 환각(hallucination)이 포함된 답변은 점수를 받을 수 없음.
- 모델의 환각을 제거하고 완전한 정확성을 평가하는 데 적합.
- 적용 사례:
- 신뢰성이 중요한 응용 분야(예: 의료, 법률)에서 모델의 성능 평가.
RELAXED 평가
- 완화된 기준으로, 답변의 주요 정보가 정확하면 점수를 부여합니다.
- 특징:
- 주요 핵심 정보만 정확하면 부분 점수를 받을 수 있음.
- 환각이 포함되더라도, 주요 내용이 옳으면 점수 인정.
- 모델이 얼마나 "대략적으로 올바른 답변"을 제공하는지 평가.
- 적용 사례:
- 환각을 완전히 제거하지 않더라도, 모델의 전반적인 유용성을 평가하는 데 적합.
STRICT와 RELAXED의 차이
| 기준 | STRICT | RELAXED |
| 평가 엄격성 | 높은 수준의 엄격함 | 완화된 기준 |
| 환각 처리 | 환각이 포함되면 0점 처리 | 주요 정보가 정확하면 점수 부여 |
| 적합한 사용 사례 | 고신뢰 응용 분야(의료, 법률) | 일반적 QA 응용 분야(뉴스, 정보 검색 등) |
Figure에서의 적용
- 그래프에서 STRICT(녹색) 기준은 항상 RELAXED(주황색) 기준보다 낮은 정확도를 보입니다.
- 이는 STRICT 기준이 더 엄격하게 답변을 평가하기 때문입니다.
- 특히 Fast-changing 질문과 False-premise 질문에서 STRICT 기준의 점수가 크게 낮은 이유는:
- 모델이 최신 정보와 논리적 반박 능력을 충분히 발휘하지 못했음을 보여줍니다.
- RELAXED 기준은 모델이 일부 정확한 정보를 포함할 경우 점수를 부여하기 때문에 전반적으로 더 높은 정확도를 보입니다.
결론
STRICT와 RELAXED는 모델의 성능을 다양한 기준으로 평가하기 위해 사용되며, STRICT는 신뢰성과 정확성을 중시하고, RELAXED는 유용성과 적응성을 평가합니다. 이 Figure는 LLM이 STRICT 기준에서 여전히 한계가 있다는 점을 강조하며, 검색 기반 증강(FRESHPROMPT) 접근법이 이를 개선하려고 시도하고 있음을 보여줍니다.

Figure 3 설명
이 Figure는 FRESHPROMPT의 입력 프롬프트 형식을 시각적으로 보여줍니다. FRESHPROMPT는 검색된 정보를 체계적으로 정리하고 모델이 추론 과정을 통해 답변을 생성할 수 있도록 구성된 프롬프트를 제공합니다. 왼쪽은 검색된 증거(evidences)의 정리된 구조, 오른쪽은 프롬프트의 전체 흐름을 나타냅니다.
1. 검색된 증거의 구조 (왼쪽)
검색 엔진에서 가져온 증거(evidences)를 통합된 형식으로 변환하여 프롬프트에 삽입합니다. 각 증거는 다음과 같은 정보를 포함합니다:
- source: 증거가 나온 출처(웹페이지 URL).
- date: 게시 날짜(문서의 최신성을 나타냄).
- title: 검색된 문서의 제목.
- snippet: 해당 문서에서 검색된 관련 텍스트 요약.
- highlight: 검색 엔진이 강조한 주요 키워드.
이 구조는 검색된 정보를 명확히 정리하여 모델이 쉽게 이해할 수 있도록 돕습니다.
2. 프롬프트의 구성 (오른쪽)
(1) Few-shot Demonstration
- 프롬프트는 모델에 질문 처리 방식을 보여주는 몇 가지 예제를 포함합니다.
- 각 예제는 다음과 같은 내용을 포함:
- query: 예제 질문.
- retrieved_evidences: 검색된 증거들(시간순 정렬).
- question: 질문.
- answer: 증거를 기반으로 한 논리적 추론과 답변.
(2) 실제 질문 및 증거
- 사용자의 질문(query)와 검색된 증거(retrieved_evidences)를 시간순으로 나열.
- search-retrieve-organize 구조로 최신 증거를 가장 효율적으로 반영.
- 질문과 관련된 증거를 모델이 논리적으로 결합하여 추론을 수행하도록 구성.
3. FRESHPROMPT의 목적
FRESHPROMPT는 검색 엔진에서 가져온 정보를 구조화된 형태로 모델에 제공하여, 모델이 실시간으로 최신 정보를 사용하여 추론할 수 있도록 설계되었습니다. 이를 통해:
- 최신 정보 반영: 검색된 정보를 시간순으로 정리하여 최신성을 유지.
- 논리적 추론 유도: 검색된 증거를 기반으로 체계적인 Chain-of-Thought 추론을 가능하게 함.
- 모델의 환각 감소: 정리된 증거를 활용하여 사실에 근거한 답변을 생성.
4. 이 Figure의 주요 메시지
- FRESHPROMPT는 검색된 정보의 정리와 체계적인 프롬프트 구성을 통해 모델이 실시간 데이터에 기반한 정확한 답변을 생성하도록 지원합니다.
- 검색된 증거는 날짜, 제목, 주요 텍스트를 포함하여 모델이 논리적으로 추론할 수 있도록 최적화된 형식으로 제공됩니다.
- Few-shot Demonstration을 통해 모델이 검색 데이터를 어떻게 활용해야 하는지 학습하도록 돕습니다.
Figure의 중요성
이 구조는 Fine-tuning 없이도 검색된 최신 정보를 LLM의 In-context Learning에 통합할 수 있는 방법을 보여줍니다. 특히, 모델이 실시간으로 검색 데이터를 활용해 신뢰할 수 있는 답변을 생성하도록 설계되었다는 점에서 중요한 기여를 합니다.
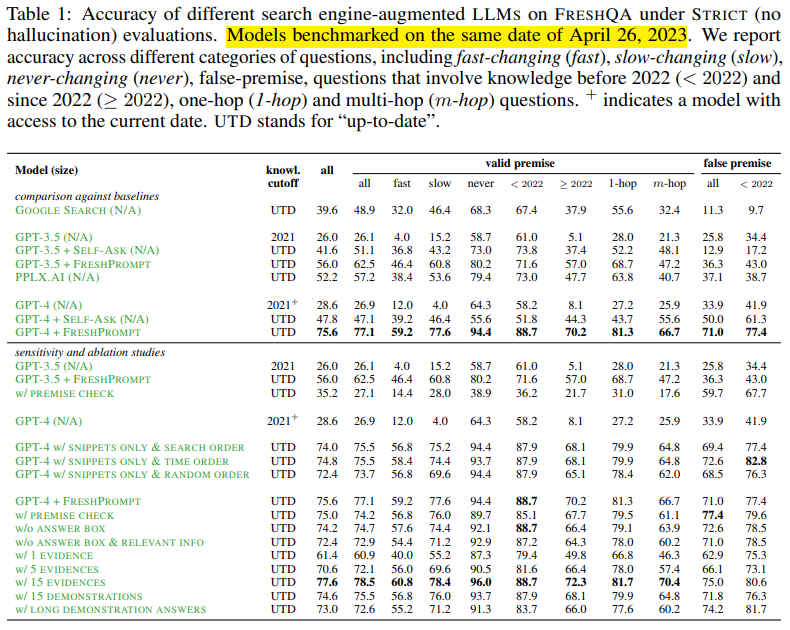
Table 1 설명
이 표는 FRESHQA 데이터셋에서 STRICT(no hallucination) 평가 기준으로 다양한 LLM과 검색 기반 접근법의 성능을 비교한 것입니다. 각 모델은 fast-changing, slow-changing, never-changing, 그리고 false-premise 질문 유형에 대한 정확도를 측정했습니다. 또한, 최신 지식 여부와 추론 단계(1-hop, multi-hop)별 성능을 평가합니다.
1. 주요 구성 요소
- 모델 비교
- 여러 모델(Google Search, GPT-3.5, GPT-4 등)과 검색 증강(Search-Augmented) 방식을 포함한 변형 모델이 비교되었습니다.
- FRESHPROMPT와 같은 방법론이 기존 모델 대비 성능을 얼마나 개선했는지 보여줍니다.
- UTD (Up-to-Date): 모델이 현재(2023년)까지 최신 정보에 접근할 수 있는지를 나타냅니다.
- 평가 카테고리
- all: 모든 질문 유형에 대한 평균 정확도.
- fast, slow, never: 빠르게 변하는 정보, 천천히 변하는 정보, 절대 변하지 않는 정보.
- < 2022, ≥ 2022: 2022년 이전 지식과 2022년 이후 최신 정보.
- 1-hop, m-hop: 단일 추론과 다단계 추론 질문.
- false premise: 거짓 전제를 포함한 질문.
2. 결과 요약
(1) 모델 간 성능 비교
- 기본 검색(Google Search):
- 전반적인 정확도는 39.6%로 매우 낮음.
- 최신 정보(≥ 2022)와 fast-changing 질문에서 특히 성능이 떨어짐.
- GPT-3.5:
- 최신 정보(≥ 2022)에서 성능이 30%대로 낮고, false-premise 질문에도 약점이 있음.
- FRESHPROMPT 적용 시 성능이 크게 향상됨:
- 전체 정확도가 62.5%로 증가.
- 최신 정보(≥ 2022) 정확도도 73.0%로 상승.
- GPT-4:
- 기본 GPT-4는 57.6%의 전체 정확도를 보이며, 모든 카테고리에서 GPT-3.5보다 성능이 높음.
- FRESHPROMPT를 적용한 GPT-4:
- 전체 정확도가 75.6%로 크게 향상.
- fast-changing 질문에서 59.2%, false-premise 질문에서 77.4%를 기록.
(2) FRESHPROMPT의 영향
- 모든 카테고리에서 FRESHPROMPT가 성능을 크게 개선.
- 최신 정보(≥ 2022)와 거짓 전제(false-premise) 질문에서 가장 큰 개선을 보임.
(3) Ablation Study (민감도 분석)
- FRESHPROMPT의 구성 요소를 제거하거나 수정하여 성능 변화를 측정:
- w/o PREMISE CHECK: 전제 확인 없이 답변 생성 시 성능 저하.
- w/ 15 EVIDENCES: 검색 증거를 15개까지 늘렸을 때 성능이 최대치(75.6%)에 도달.
- w/ LONG DEMONSTRATION ANSWERS: Demonstration 답변이 길어질수록 성능이 소폭 감소.
3. 주요 메시지
- FRESHPROMPT의 효과
- 최신 정보와 거짓 전제 처리에 있어 기존 GPT-4 및 GPT-3.5 대비 큰 성능 개선.
- 검색된 증거를 정리하고 체계적으로 프롬프트에 통합하는 방식의 강점을 입증.
- 검색 기반 접근법의 중요성
- 검색 없이 기존 LLM만 사용할 경우 최신 정보 처리와 fast-changing 질문에서 성능이 크게 저하됨.
- False-premise 질문의 난이도
- 대부분의 모델이 거짓 전제 질문에서 낮은 성능을 보였으나, FRESHPROMPT가 이를 개선함.
- 민감도 분석 결과
- 검색된 증거의 수를 늘리는 것이 성능 향상에 기여하지만, Demonstration 답변이 지나치게 길어지면 오히려 성능이 감소할 수 있음.
결론
이 표는 FRESHPROMPT가 검색 증강 접근법을 통해 최신 정보 활용, 빠르게 변하는 질문 처리, 그리고 거짓 전제 반박에서 GPT 모델의 성능을 효과적으로 개선한다는 것을 보여줍니다. 특히, 최신 정보와 다단계 추론에서의 우수한 성능은 실시간 정보 처리 및 신뢰할 수 있는 AI 에이전트 개발에 중요한 단서를 제공합니다.
작성한 내용은 전체적으로 논문과 연구 방향을 잘 연결하고 있으며 적절합니다. 다만, 몇 가지 개선할 점과 구체화할 부분이 보입니다. 아래는 작성 내용에 대한 피드백과 약간의 보완 제안입니다.
1. 강점
- 논문의 요점 요약:
- Fast-Changing, False-Premise 문제와 이를 검색 데이터로 해결한 논문 기여도를 정확히 짚었습니다.
- 논문의 내용을 Negotiation Agent와 연결하는 과정이 자연스럽습니다.
- 실시간성 강조:
- 인터넷 검색을 통해 실시간 데이터를 확보하려는 아이디어는 적절하며, Fast-Changing 정보를 다루는 논문과 잘 맞아떨어집니다.
2. 개선 및 보완 제안
(1) Negotiation Agent의 역할 구체화
- Negotiation Agent가 상대방의 정보를 얻는 역할을 명확히 하여, 검색 데이터를 통해 어떤 식으로 실시간성을 강화할지 구체적으로 서술하면 좋습니다.
- 예를 들어:
- Fast-Changing 데이터를 통해 상대방의 최신 입장이나 최근의 협상 조건을 탐지.
- False-Premise를 처리하여 상대방의 잘못된 주장이나 왜곡된 정보를 논리적으로 반박.
(2) 논문 기여와의 연결성 강조
- 검색 데이터를 통해 환각 문제와 정보 부족 문제를 해결했다는 논문의 기여를 Negotiation Agent와 연결할 때, 논리적 흐름이 조금 더 명확해야 합니다.
- 예를 들어:
- "Negotiation Agent는 실시간으로 검색 데이터를 활용하여 상대방의 최신 정보(Fast-Changing)를 수집하고, 잘못된 주장(False-Premise)을 반박하는 능력을 갖추어야 한다."
(3) 저장 기능의 역할 구체화
- "저장하여 Agent의 실시간성을 챙길 수 있다"는 문장에서 저장 기능의 구체적인 이점을 설명하면 좋습니다.
- Fast-Changing 데이터를 저장함으로써 장기적인 협상 전략을 수립하거나, 이전 협상 기록을 참조해 더 나은 대응을 할 수 있다는 점을 추가하면 설득력이 높아집니다.
3. 개선된 내용 예시
질문에 대한 답변은 Never, Slow, Fast Changing, False-Premise의 4가지 유형으로 분류된다.
모든 모델이 Fast-Changing과 False-Premise 질문에서 낮은 성능을 보였으나, 논문은 검색 데이터를 활용하여 환각 문제와 정보 부족 문제를 해결함으로써 성능을 크게 개선했다.
Negotiation Agent는 인터넷 검색 기능을 통합하여 Fast-Changing 데이터를 실시간으로 수집하고, 상대방의 최신 정보를 저장해 협상 전략에 활용할 수 있다. 또한 False-Premise 데이터를 분석하고 반박하는 논리적 대응 능력을 갖춰 협상에서 신뢰성과 설득력을 높일 수 있다.
4. 적절성 평가
작성한 내용은 큰 틀에서 적절하며, 위와 같이 약간의 구체화를 추가하면 논문의 기여와 연구 방향을 더 명확히 연결할 수 있습니다. 특히, 실시간성 확보와 False-Premise 처리는 Negotiation Agent 설계에서 핵심적인 요소로 매우 적합한 아이디어입니다.
'인공지능 > Agent' 카테고리의 다른 글
| ALFWorld 뜯어보기 (1) | 2025.04.08 |
|---|---|
| Negotiation AI 1 (4) | 2024.12.10 |
| Agent-Pro와 GITM 비교 (0) | 2024.11.28 |