https://arxiv.org/abs/2006.16668
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
Neural network scaling has been critical for improving the model quality in many real-world machine learning applications with vast amounts of training data and compute. Although this trend of scaling is affirmed to be a sure-fire approach for better model
arxiv.org



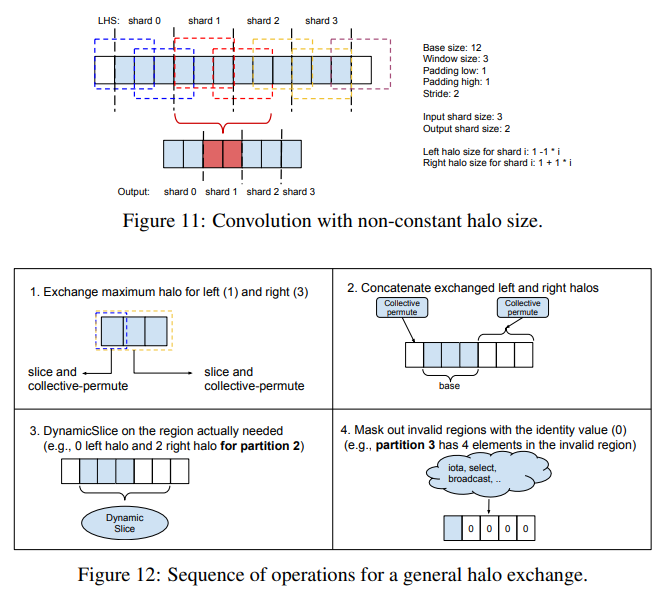

이 논문은 대규모 신경망을 효율적으로 확장하기 위해 GShard라는 모듈을 제안합니다. GShard는 조건부 계산(conditional computation)과 자동 분할(sharding)을 사용하여 모델을 효율적으로 병렬화하고, 6000억 개 이상의 매개변수를 갖는 다국어 신경 기계 번역 모델을 TPU 클러스터에서 효과적으로 학습할 수 있도록 설계되었습니다. 주요 연구 목표는 대규모 모델의 계산 효율성을 높이고, 여러 언어 간 번역 품질을 개선하는 데 있습니다.
- 문제 정의
- 대규모 모델 학습의 어려움: 모델 크기를 키우는 것은 품질 향상에 기여하지만, 계산 비용, 메모리 한계, 그리고 효율적인 병렬화의 어려움 등 여러 문제를 동반합니다.
- 효율성 문제: 기존의 병렬화 방식은 GPU나 TPU 같은 장치에서 효율적으로 활용하기 어렵고, 모델이 커질수록 계산 시간도 기하급수적으로 증가하는 경향이 있습니다.
- 목적
- 효율적 병렬화: GShard는 모델을 효율적으로 분할하여 계산이 병목현상을 일으키지 않도록 설계되었습니다. 특히 다국어 번역 모델의 품질을 높이면서도 계산 비용을 낮추는 것이 목적입니다.
- 자동 분할과 조건부 계산: TPU 클러스터에서 2048개의 TPU를 활용해 6000억 개의 매개변수를 가진 모델을 학습하는 것을 목표로 합니다.
- 제안된 방법
- 조건부 계산(Conditional Computation): 이 방법은 MoE(Mixture-of-Experts) 레이어를 활용하여 입력마다 다른 부분만 활성화되도록 함으로써 효율을 극대화합니다. 토큰마다 활성화된 전문가(expert)만 사용하여 계산 부담을 줄입니다.
- 자동 분할(Automatic Sharding): XLA 컴파일러의 확장 기능을 통해 모델을 여러 TPU에 걸쳐 자동으로 분할합니다. 모델을 하나의 대형 장치에서 실행하는 것처럼 구성하고, XLA가 분할과 통신을 자동으로 처리하여 실행 효율성을 극대화합니다.
- SPMD(Single Program Multiple Data): 단일 프로그램이 여러 장치에서 동시에 실행되도록 하여 복잡성을 줄이고, 각 장치의 메모리 사용량과 계산 속도를 효율적으로 관리합니다.
- 실험 결과
- 번역 품질: GShard로 학습된 다국어 번역 모델은 기존의 단일 언어 번역 모델보다 BLEU 점수가 더 높았습니다. 특히, 다수의 언어에서 데이터가 적은 경우에서도 높은 성능을 보였습니다.
- 계산 효율성: 6000억 개의 매개변수를 가진 모델을 2048개의 TPU v3 클러스터에서 4일간 학습하여 우수한 번역 성능을 달성했습니다. 이러한 모델은 TPU 코어-연도 측정치로 계산 비용이 기존보다 훨씬 적게 듭니다.
- 시간 효율성: 모델의 크기를 16배 확장할 때 계산 시간은 1.7배 증가에 그쳤습니다.
- 한계점 및 제약
- 분할 구현의 복잡성: 자동 분할 방식은 장점이 많지만 모든 신경망 구조에 쉽게 적용할 수 있는 것은 아니며, 모델에 따라 추가적인 수정과 설계가 필요할 수 있습니다.
- 메모리 제한: TPU에서 GShard가 메모리 효율성을 크게 개선했지만, 여전히 메모리 한계가 존재하여, 더 큰 모델에서는 추가적인 최적화가 필요할 수 있습니다.
- 초기 설정 및 튜닝의 어려움: GShard의 설정은 자동화되어 있지만 최적의 설정을 찾기 위해서는 추가적인 실험과 조정이 필요합니다.
이 논문은 대규모 모델의 효율적 학습에 관한 중요한 연구로, 특히 다국어 번역에서 GShard를 통한 조건부 계산과 자동 분할이 높은 품질과 효율성을 달성하는 데 기여하고 있음을 보여줍니다. 이를 통해 대규모 모델 학습의 병목을 줄이면서도 효율성을 유지하는 방안을 제공합니다.
기존 병렬화 방식이 무엇이었는데 GPU나 TPU에서 효율적으로 활용하기 어려웠는지 설명해줘
기존 병렬화 방식에는 주로 데이터 병렬화(data parallelism)와 모델 병렬화(model parallelism)의 두 가지 주요 접근법이 있었습니다. 하지만 이 방식들은 GPU나 TPU와 같은 장치에서 대규모 모델을 효율적으로 활용하기에 여러 제약이 있었습니다.
- 데이터 병렬화(Data Parallelism)
- 데이터 병렬화는 동일한 모델을 여러 장치에 복제하여 각 장치가 다른 데이터 배치를 독립적으로 처리하도록 하는 방식입니다. 각 장치는 동일한 모델 복사본을 사용하고, 계산이 완료된 후에 모델의 가중치를 동기화합니다.
- 제약 사항: 데이터 병렬화는 장치 간 동기화가 필수적이기 때문에 큰 통신 비용이 발생합니다. 특히 모델 크기가 커질수록 가중치 동기화 시간이 증가하여 효율이 크게 떨어집니다. 또한, 각 장치에 모델 전체를 복제해야 하므로 대규모 모델에서는 메모리 한계로 인해 실행이 어려워집니다.
- 모델 병렬화(Model Parallelism)
- 모델 병렬화는 모델을 여러 장치에 걸쳐 분할하고, 각 장치가 모델의 특정 부분을 담당하여 계층 단위로 계산을 수행하는 방식입니다. 예를 들어, 네트워크의 한 계층을 한 장치에서 계산하고 결과를 다음 장치로 전달하는 형태입니다.
- 제약 사항: 모델 병렬화는 네트워크의 구조에 따라 장치 간의 순차적 계산 의존성(sequential dependency)이 발생하기 때문에 장치가 대기하는 시간이 많아지고, 자원을 충분히 활용하지 못하게 됩니다. 특히, 깊이가 깊은 모델에서는 모델 병렬화가 병목현상을 일으켜 계산 속도가 느려질 수 있습니다.
- 슈퍼-선형 비용 증가(Super-linear Scaling Cost)
- 모델 크기를 단순히 늘리는 경우, 계산 시간과 장치의 메모리 사용량이 선형 또는 초선형적으로 증가합니다. 예를 들어, 모델의 깊이나 폭을 늘리면 계산 비용과 학습 시간이 급격히 증가합니다. 이를 해결하려면 레이어의 가중치나 계산을 여러 장치에 나눠야 하지만, 이 경우 통신 오버헤드와 장치 간의 비효율적 자원 사용이 발생하게 됩니다.
- 기존 프레임워크의 지원 부족
- 텐서플로우(TensorFlow)나 파이토치(PyTorch)와 같은 기존 딥러닝 프레임워크에서는 기본적인 그래프 분할 방식의 모델 병렬화만 지원하며, 이는 비효율적인 자원 활용으로 이어질 수 있습니다. 따라서 대규모 모델을 효과적으로 학습하기 위해서는 엔지니어가 많은 시간을 투자해 모델 코드를 특수 프레임워크로 이식하거나 최적화를 추가해야 하는 어려움이 있었습니다.
GShard와의 비교
GShard는 이러한 문제를 해결하기 위해 조건부 계산(conditional computation)과 자동 분할(automatic sharding)을 결합하여 모델을 TPU 클러스터에서 효율적으로 병렬화합니다. 각 입력마다 필요한 부분만 활성화하여 계산을 줄이고, XLA 컴파일러 확장을 통해 모델의 특정 텐서를 자동으로 분할 및 병렬 처리할 수 있도록 하여, 기존의 데이터 및 모델 병렬화의 비효율성을 줄였습니다.
그럼 자동 분할과, 조건부 계산이 어떻게 일어나는지, SPMD에 대해 자세하게 논문을 기반으로 설명하고, 이 논문이 주장하는 것에 대해 타당한지 말해줘
자동 분할 (Automatic Sharding)
자동 분할은 GShard의 핵심 기능으로, 모델을 여러 TPU 장치에 자동으로 나누어 병렬 계산을 수행하는 방식을 의미합니다. GShard는 XLA(Accelerated Linear Algebra) 컴파일러를 확장하여, 개발자가 모델을 거대한 단일 장치에서 실행하는 것처럼 코드를 작성할 수 있도록 하고, XLA 컴파일러가 이를 여러 장치에 나누어 실행할 수 있게 합니다. GShard의 자동 분할 과정은 다음과 같이 이루어집니다:
- 텐서 주석(annotation): 모델에서 병렬화할 특정 텐서에 대해 '복제(replicate)'나 '분할(split)' 등의 주석을 달아 자동 분할이 일어날 부분을 지정합니다. 예를 들어, GShard는 주어진 텐서가 전체 장치에서 복제되어야 할지, 특정 차원을 따라 분할되어야 할지를 지정해 개발자가 병렬화 방식을 조정할 수 있게 합니다.
- 연산 분할(Partitioning Operations): 주석을 기반으로 XLA 컴파일러는 해당 연산을 적절히 분할합니다. 예를 들어, 모델의 특정 연산을 다수의 장치에 걸쳐 분할하고 필요한 장치 간 통신을 추가하여 연산의 병렬 처리가 효율적으로 이루어지도록 합니다.
- 단일 프로그램 다중 데이터(Single Program Multiple Data, SPMD) 전략: GShard는 각 장치에서 단일 프로그램을 실행하는 SPMD 방식을 사용하여 연산을 병렬화합니다. SPMD 방식에서는 같은 프로그램이 여러 장치에서 동시 실행되며, 각 장치에 맞는 데이터 조각을 병렬로 처리하게 됩니다. 예를 들어, SPMD에서는 모델의 특정 레이어가 여러 장치에 분할되어 실행되며, 필요시 장치 간 데이터를 공유합니다.
조건부 계산 (Conditional Computation)
조건부 계산은 Mixture of Experts (MoE) 레이어를 사용하여, 입력 데이터의 특성에 따라 모델의 일부만 활성화시키는 방식입니다. 이 방식을 통해, 모든 레이어나 전문가가 항상 활성화되지 않고, 토큰마다 필요로 하는 전문가(expert)만 선택적으로 활성화되어 효율성을 극대화합니다.
- 토큰 선택과 라우팅: MoE 레이어는 입력되는 토큰을 각각의 전문가 중 몇 개로 라우팅하는 게이트(gate) 함수를 포함하고 있습니다. 이 게이트 함수는 각 토큰이 선택한 전문가에 따라 다른 전문가의 하위 네트워크를 활성화시켜 계산 부담을 줄입니다. 이 논문에서는 Top-k 게이트 방식을 통해, 각 토큰이 특정 전문가에만 할당되도록 하여 계산 비용을 줄이는 방식을 사용했습니다.
- 부하 균형 및 효율성: 게이트 함수는 토큰을 균등하게 분배하여 특정 전문가에 부하가 몰리지 않도록 합니다. 예를 들어, 특정 전문가에 지나치게 많은 토큰이 할당되지 않도록 전문가 용량(expert capacity)을 제한하고, 토큰이 라우팅될 수 있는 최대 전문가 수를 지정합니다.
- SPMD 기반 병렬 처리와 결합: MoE 레이어가 활성화되는 특정 토큰에 대해 해당 전문가만 계산을 수행하므로, 모든 장치에서 모든 전문가를 계산할 필요가 없습니다. 이로 인해 모델의 계산 비용이 절감되며, 계산 시간도 줄어들게 됩니다.
SPMD (Single Program Multiple Data)
SPMD는 GShard에서 사용된 병렬화 전략으로, 동일한 프로그램을 여러 장치에서 실행하면서 각 장치에 다른 데이터 조각을 처리하도록 하는 방식입니다. GShard에서 SPMD는 다음과 같은 방식을 통해 구현됩니다.
- 연산 분할 및 데이터 할당: XLA 컴파일러는 모델의 연산을 여러 장치에 분할하여 분산시키고, 특정 차원으로 나뉜 데이터를 해당 장치에 할당합니다. 예를 들어, 어텐션 레이어에서는 배치 차원으로 나누어 연산이 각 장치에서 독립적으로 수행되도록 합니다.
- Cross-Device Communication: 연산이 특정 장치에서만 수행될 경우 해당 장치에서의 데이터 조각만 처리되기 때문에, 일부 연산 결과는 다른 장치와 공유해야 합니다. 이를 위해 XLA는 AllReduce나 AllGather와 같은 장치 간 통신 연산을 통해 데이터를 결합하거나 재배치합니다.
- SPMD를 통한 통합 프로그램: 여러 장치에서 동일한 프로그램이 실행되므로, 각 장치는 SPMD에 의해 전체 그래프의 일부를 독립적으로 수행할 수 있습니다. XLA 컴파일러는 이러한 병렬화 처리를 지원하며, 컴파일 시간이 장치 수에 따라 선형적으로 증가하지 않아 대규모 장치에서도 효율적인 학습이 가능해집니다.
논문의 주장에 대한 타당성 평가
논문에서 주장하는 GShard의 효율적인 대규모 병렬화는 이론적으로 타당하며, 실제로도 효과적인 방식임을 다양한 실험 결과로 입증하고 있습니다.
- 효율성 향상: 자동 분할과 조건부 계산을 통해 기존의 데이터 병렬화나 모델 병렬화에서 겪었던 통신 비용 문제를 완화하고, TPU에서 수백억 개 이상의 매개변수를 효율적으로 학습할 수 있는 기반을 마련했습니다. TPU 코어-연도 관점에서 GShard 모델은 대형 모델의 학습을 위한 비용 효율성을 극대화하였음을 실험에서 증명했습니다.
- 확장성: SPMD 기반 자동 분할은 장치 수가 늘어나도 컴파일 시간 증가를 최소화하며, 병렬화된 연산이 각 장치에서 효율적으로 이루어지도록 합니다. 논문에서는 장치 수가 16배로 증가해도 계산 시간은 1.7배 정도만 증가함을 실험적으로 보여주어, 이 방식이 확장 가능한 솔루션임을 뒷받침합니다.
- 고품질 모델 성능: 조건부 계산을 통해 다국어 번역 성능을 높였고, 기존 단일 언어 번역 모델보다 우수한 BLEU 점수를 기록했습니다. 이로 인해 대규모 모델의 품질을 유지하면서도 학습 비용을 절감할 수 있음을 입증했습니다.
결론
GShard의 자동 분할과 조건부 계산은 대규모 모델을 TPU 클러스터에서 효율적으로 병렬화하는 데 매우 타당한 방법이며, 실험 결과 역시 이를 뒷받침합니다. SPMD 전략은 장치 간 동기화 및 통신 비용을 줄이는 데 큰 도움이 되며, 다국어 번역 모델을 포함한 여러 AI 응용에서 대규모 모델의 품질과 학습 효율을 동시에 달성할 수 있는 잠재력을 보여줍니다.
그럼 여기서 일정 전문가만 활성화하는 방식을 사용한다면 학습이 엄청 오래 걸릴 것 같은데 auxiliary loss같은 건 없었어?
네, 이 논문에서는 전문가가 고르게 학습되도록 auxiliary loss를 추가하여 부하 불균형 문제를 해결했습니다. 조건부 계산을 통해 일부 전문가만 활성화되기 때문에, 특정 전문가에 부하가 집중될 수 있는 문제가 발생할 수 있습니다. 이에 따라 GShard에서는 Auxiliary Loss를 도입하여 학습 중 전문가들이 고르게 활성화되도록 유도합니다.
Auxiliary Loss의 주요 역할과 설계
- 부하 균형(Balanced Load):
- 각 토큰이 특정 전문가에 할당될 때, 일부 전문가에게 부하가 집중되는 현상이 발생할 수 있습니다. 이러한 부하 불균형은 일부 전문가가 과부하되어 학습이 불안정해지고, 다른 전문가가 충분히 학습되지 않는 문제를 초래합니다.
- Auxiliary Loss는 전문가들이 균등하게 활성화되도록 유도하여 부하를 고르게 분배합니다. 이를 통해 모든 전문가가 학습 데이터에 노출될 수 있도록 하여 모델의 일반화 성능을 높입니다.
- 효율적인 병렬 처리(Parallel Efficiency):
- 학습 배치(batch) 내의 각 토큰은 두 개의 전문가에만 할당되며, 각 전문가의 용량(capacity)은 제한됩니다. Auxiliary Loss는 이 용량 제한을 준수하면서 전문가 간 부하 균형을 유지하도록 유도합니다.
- 각 전문가에 할당된 토큰의 비율을 최소화하는 방식으로 부하 균형을 맞추고, 학습에서의 효율을 유지합니다.
- 수학적 표현:
- Auxiliary Loss는 전문가마다 부하를 정규화하여, 부하가 고르게 분포되도록 합니다. 구체적으로, 각 전문가에 대한 평균 게이트 값 me를 사용하여, Mean Square Error 형태로 부하를 최소화하도록 설정합니다. 이를 통해 전문가 간의 부하 균형을 최적화합니다.
- 불균형 처리와 예외 처리:
- 토큰이 특정 전문가에 과도하게 할당되는 상황을 막기 위해, 선택한 전문가가 용량을 초과하면 해당 토큰은 다음 레이어로 전달됩니다. 이로써 토큰이 전문가를 고르게 활용할 수 있도록 제약을 둡니다.
Auxiliary Loss의 효과
Auxiliary Loss는 다중 전문가 모델에서 발생할 수 있는 불균형 문제를 완화하면서도, 각 전문가가 고르게 학습될 수 있도록 하여 모델의 학습 효율과 일반화 성능을 높이는 역할을 합니다. 이 논문에서 Auxiliary Loss를 통해 토큰이 고르게 전문가에게 분배됨으로써 모델의 수렴 속도와 전문가들의 학습 질을 유지할 수 있었습니다.