6주차 - 딥러닝
1차시 - 심층 신경망, 딥러닝 개요
퍼셉트론 이론 문제
1. 역전파 알고리즘은 layer가 많을 수록 기울기 정보가 사라진다.(나중에 skip connection으로 해결)
2. 학습 데이터에 대해 오차가 감소하지만 실제 데이터에서는 오히려 오차가 증가하는 과적합 문제(validation을 통해 확인하자)
3. 문제 규모가 커질 때 마다 나타나는 높은 시간 복잡도와 컴퓨터 성능의 한계(병렬 처리)
ResNet의 ImagNet 우승으로 딥러닝 기술이 발전하게 되었다.
여기서 MLP = Multi-Layer Perceptron
기울기 소실은 ReLU를 통해 해결
과적합은 Dropout을 통해 해결
심층 신경망(DNN)과 딥러닝(Deep Learning)의 배경
심층 신경망 : 여러 개의 은닉층을 가진 신경망 계열의 모델
딥러닝 : 심층신경망을 학습하는 다양한 방법
빅데이터 특징 추출 및 학습에 매우 뛰어나 좋은 겅과를 보이고 있다.
Drop out - 일정 확률로 노드를 무작위 선택하여 앞뒤로 연결된 가중치 연결선은 없는 것으로 간주하고 학습
MLP는 Feed Forward Neural Network, Fully Connected Neural Network, Deep Neural Network로 발전하였고, 같은 노드들 끼리 연결되어 있지 않지만, 이전과 다음 노드들은 완전하게 연결되어있다.
Deep Neural Network + Machind Learning = Deep Learning
| 머신러닝 | 딥러닝 | |
| 데이터 크기 | 적은 데이터 집합에 좋은 결과 | 매우 큰 데이터 집합에 좋은 결과 |
| 처리하는 컴퓨터 | 학습 시간이 짧아 일반 컴퓨터 | 매우 오래 걸리므로 강력한 컴퓨터 |
| 특징 추출의 방법 | 최상의 결과를 위해 여러 가지 특징 추출과 분류 방법 시도, 사람이 시도 | 특징 추출과 분류가 자동적으로 처리 가능 |
| 처리 시간 | 몇 분에서 몇 시간 정도 | 경우에 따라 몇 주 까지도 걸린다. |
| 알고리즘의 종류 | 다양하고 많다. | 현재는 적으나 많이 개발중이다. |
딥러닝의 단점은 성능 증가 시 원인 파악이 어렵다
추출한 feature가 뭔지도 모르고, 분류가 어떻게 되는지 확인하기 어렵기 때문이다.
2차시 - 심층 신경망, 딥러닝 개념
딥러닝의 정확도가 높은 이유는 인식의 해상도가 언어의 해상도보다 크기 때문이다.
내가 이미지를 보고 사과라고 인식했을 때 모든 것을 언어로 표현할 수 없다는 것이다.
데이터 학습을 통해 Layer 별 다양한 표현을 포착하고 추상화 하여 특정 분야에선 사람도 이긴다.
input -> Simple features -> Additional layers of more Abstract features -> mapping for features -> output
심층 신경망은 많은 simple Feature로 특징을 표현하는데 전체적으로 보면 입력 데이터의 복잡한 특징들을 잘 추출하여 학습할 수 있다.
은닉층이 많을수록 다양한 표현을 포착 가능해 수준을 높일 수 있다.
다양한 구조의 깊은 인공 신경망
Fully-connected / Undirected : DNN, RBM(Restricted Boltzmann Networks), DBN(Deep Belief Networks)
Convolution : LeNet, GoogleNet, AlexNet, VGGNet, ResNet - 이미지 특징 추출에 최적화 되어 공간적인 상관관계 추출
Recurrent : LSTM, GRU, SRU - 과거의 데이터가 현재에 영향을 줘 자연어 처리에 사용
Activation Function : ReLU, Leaky ReLU, Maxout
Regularization : L1 L2, Early stopping, Dropout
Optimization : SGD, AdaGrad, RMSprop, Adam
3차시 - CNN, RNN
합성곱 신경망 CNN은 다차원 데이터를 학습하기 위한 인공신경망으로 이미지와 같은 공간적 상관관계(주변 픽셀과의 관계성)를 찾는다.
Convolution - Local 특징 추출, Shared Weights(전체 영상에 동일한 필터를 적옹하여 연산하여 객체의 크기나 위치의 변화에 무관하다.)
Feed Forward Neural Network는 1차원 데이터만 받을 수 있기 때문에 3차원 이미지 데이터를 벡터화 해서 1차원으로 바꿔야 되기 때문에 공간정보가 소실된다.
Fully Connected layer - 특징을 통한 분류
RNN은 Sequence data(시계열 데이터로 구성 요소가 순차적으로 발생하거나 구성 요소간에 순서가 존재하여 이전 값들이 현재 값에 영향을 준다.)
분류, 예측 시 현재 시점의 값, 이전 시점의 값 고려가 필요하다. -> 순환 신경망은 과거의 출력 데이터를 참조하여 예측한다.
입력과 출력의 형태는 다양하다.
RNN과 CNN을 결합하여 사진 상황을 글로 설명할 수 있다.
7주차 - 딥러닝
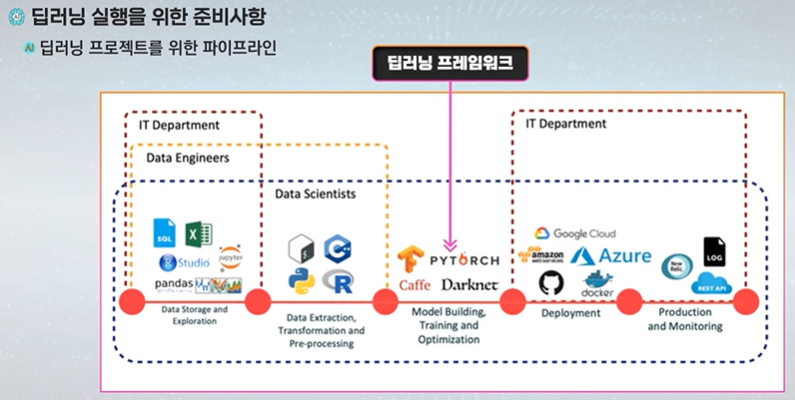
1차시 - 딥러닝 프레임워크
딥러닝은 미래를 선도할 혁신 기술로 GPU 기반의 병렬 처리를 포함하여 컴퓨팅 기술의 발달과 빅데이터, 알고리즘의 개발로 발전하게 되었다.
데이터는 정형 데이터(행과 열로 이루어진 숫자, 문자), 비정형 데이터(이미지, 문장, 영상 등)가 있다.
준비 사항 - 개인 PC, 클라우드 형태, 고성능 서버
언어 - 파이썬, c++
IDE (통합개발환경) - PyCharm, Visual Studio Code
공통된 개발자 툴을 하나의 GUI로 결합하는 애플리케이션
설정 프로세스의 일환으로 여러 유틸리티를 수동으로 설정하고 통합할 필요가 없으므로 새로운 어플리케이션 프로그래밍을 신속하게 시작 가능
클라우드 형태로 딥러닝을 실행 가능하다!
고성능 GPU 서버로도 나눠쓰는 형태로 가능하다
파이썬은 플랫폼에 독립적이고, 인터프리터식이며, 객체 지향적이고, 동적 타이핑 대화형 언어인 고급 프로그래밍 언어이다.
텐서 플로우 = 딥러닝 프레임워크= 딥러닝 라이브러리 로 패키기자 라이브러리 형태로 구현되어 있다. - 파이썬이 선호된다.
아나콘다 = 파이썬 + 주요 패키지
딥러닝 프레임 워크 = 딥러닝 알고리즘 실행, 개발에 필요한 연산 및 함수를 제공하고, GPU가속 및 분산 병렬 학습기능을 제공하며 Open Source software이다. = 빠르고 손쉽게 딥러닝 사용을 가능하게 한다.
그 중 텐서 플로우는 데이터 플로우 그래프를 사용하여 수치 연산을 하는 오픈 소스 라이브러리로 GPU 가속 및 분산 병렬 학습 기능을 제공한다. 유연한 아키 텍처로 구성되어 코드 수정 없이 데스크탑, 서버 혹은 모바일 디바이스에서 CPU나 GPU를 사용하여 연산을 구동하고, 구글에 의해 개발
Data flow graph - 노드 (수치 연산), 엣지(노드 사이를 이동하는 다차원 데이터 배열 = 텐서)
넘파이 - 텐서 연산에서 사실상 표준 API 역할
판다스 - 강력하고 유연한 데이터 프레임을 활용할 수 있다.
사이킷 런 - 머신러닝에 필요한 많은 기능과 함수가 있는 패키지 이다.
ONNX - 다음 프레임 워크간 호환 지원
2차시 - 범용적 AI, 강화학습, 강건한 딥러닝 모델
2020년의 주요 연구 동향 - 범욕적 AI, 강화 학습, 강건한 딥러닝 모델, 설명가능 AI, 딥러닝 자동화, 생성 모델, 딥러닝 모델 경량화
범용적 AI - A문제를 해결하면서 얻은 지식과 경험을 B문제에 적용하는 것
전이학습이 현실적 어려움을 해결해준다. - 기존 학습된 모델에 적합하게 미세 조정하여 다른 task에 사용한다.
전이학습 - 대규모 데이터셋으로 훈련된 기존 네트워크 불러오기 -> 앞쪽을 그대로 사용 -> 뒤쪽은 내가 원하는 출력을 낼 수 있도록 네트워크 구성 -> 두 네트워크가 잘 맞물리게끔 미세조정하기
많은 수의 데이터가 없어도 좋은 결과를 낼 수 있다.
강화학습 - 행동의 시행착오를 통한 학습 == 보상을 많이 얻으려고 한다.
딥러닝 알고리즘 연구 동향
Decision Making 및 Conrtol 문제 해결에 적합 : 단순 분류가 아닌 연속적인 의사결정 및 그에 따른 실행 판단 ex) 로보틱스, 자율주행차
기존 딥러닝 알고리즘 개선에 활용 : 지도 학습으로 학습된 모델 정확도를 개선하기 위해 추가적 강화학습
강건한 딥러닝 모델의 필요성 : 적대적 공격 - 악의적으로 활용될 가능성 있다.
Adversarial Training + Denoiser로 강건 모델 진화, 발전 중이다. - noise를 넣어서 학습시키거나 noise 제거 or noise 패턴 검출하여 제거한다.
3차시 - 설명 가능 AI, 딥러닝 자동화, 생성 모델, 모델 경량화
딥러닝의 뛰어난 성능, 다양한 응용, 한계 발생에 따라 설명가능한 인공지능이 대두되어 인공지능의 내부 경정 과정을 사용자가 이해하는 것이 필요해졌다.
기존 인공지능 - 주어진 데이터를 학습 후 새로운 데이터에 대해 분류 및 예측하지만 결과에 대해 설명이 힘들다
XAI - 기존 인공지능 결과에 대해 설명하거나 모델의 의사결정 과정 및 결과를 사용자 레벨에서 설명한다.
필요성 : AI의 판단 결과에 대한 인간의 신뢰 - 의료, 국방, 법률, 금융
결과에 대한 가중치들을 계속 더하여 히트맵을 찾을 수 있다.
딥러닝 자동화 = Meta Learning - 학습하는 법을 학습하는 것이다.
기존 지식을 통해 소수 데이터만 있더라도 잘 학습
생성 모델 GAN : 경쟁하는 판별자와 생성자 - 범죄에 악용 우려, 게임, 패션 광고에서 활용
리얼/ 페이크 이미지를 구별 못 하는 상태에 도달하면 가상 인물을 생성한다
모델 경량화 - 저전력, 저사양 기기에서도 딥러닝 알고리즘과 모델 구조 = 경량화 모델 제안
기존 클라우드 기반의 학습된 모델을 경량 장치에 내장하기 위한 필수 기술이다.
지연 시간 감소, 개인 정보 보호, 네트워크 트래픽 감소

정확도 손실 없이 신경망 크기를 줄여 속도를 높이고, 메모리 사용량을 줄인다.
9주차 -
1차시 - 데이터 사이언스 개요, 활용 분야
빅데이터 - 분산컴퓨팅, 기계학습, 데이터마이닝, 대용량 데이터프로세싱을 함께 다루는 기술, 플랫폼, 방식
데이터 사이언스!
대량의 데이터를 처리하는 여러 학문 분야가 관련된 학문
엄청난 양의 데이터를 수집, 저장, 분석, 처리
데이터 다루는 방법론, 프로세스, 알고리즘, 시스템
업무를 효율적으로 관리하고 분석하는 학문적 바탕
데이터에 대한 직관력을 획득할 수 있게 해주는 학문 분야
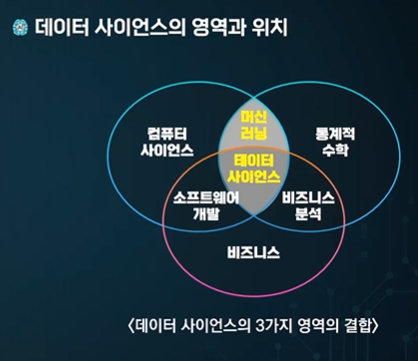
통계 + 과학적 방법 + AI + 데이터 분석 = 데이터 가치 추출
추세를 보여준다. = 기업의 제품 및 서비스 생산에 혁신적 통찰력을 제공한다.
데이터 사이언티스트 = 데이터 사이언스를 실천하는 사람
데이터 준비 -> 결과 분석 (데이터 사이언티스트) -> 통찰력 획득
"데이터 해석"이 사회의 혁신적인 이점을 가져온다.
데이터 사이언스의 활용 분야
의미있는 패턴 찾아 통찰력을 획득하고, 분석하고 활용하기
통계학, 데이터 분석, 머신러닝 등 방법론을 사용
사용성, 중요성이 높아지는 이유 - 처리 속도가 빠르고 널리 보급된 컴퓨터 기술, 인터넷을 통한 풍부한 데이터, 인공지능의 머신러닝으로 빠르고 편리하게 구현
응용 분야 - 경영, 인공지능, 사회학, 의학, 생물학, 인문학 등 응용 분야와 폭이 점차 넓어지고 있다.
비지니스 분석과 활용 - 의사 결정의 향상, 경영상의 문제 개선, 미래에 대한 예측, 경영 목표 개선, 새로운 기회 창출, 위험 평가 향상
데이터 사이언스의 기술 학문으로부터 비롯된 데이터 기반 의사결정
데이터 사이언스에 필요한 지식과 기술
컴퓨터 사이언스, 인공지능, 통계학의 방법론
인터넷으로 데이터를 효율적으로 수집하는 컴퓨터 지식
대규모 데이터를 다루는 프로그래밍 기술
데이터 분석 과정에서 필요한 통계 처리 기초 지식
분류와 클러스터링 등 머신러닝 관련 지식과 기술
데이터를 분석한 결과를 시각화할 수 이쓴ㄴ 기술
데이터 사이언스 관련 직업 - 상당한 수준의 전문성이 필요하다.
데이터 사이언티스트 - 과거 분석과 미래 예측에 쓰일 수 있는 패턴을 찾아냄, 데이터 수집, 분석, 결과 보고 등 업무
임무
데이터 분석 전략 개발
분석용 데이터 준비
데이터 탐색
분석 및 시각화
Python과 R 프로그래밍 언어를 사요하여 데이터로 모델 구축
어플리케이션에 모델 배포
문제에 맞는 모델링 후 통계학, 시뮬레이션, 머신러닝 기술을 적절하게 좋바하여 실제로 구현하는 능력
광고분야
데이터 분석가 : 연령, 성별, 지역 등 식별화 할 수 있는 정보들을 바탕으로 상호연관관게 파악
머신러닝 개발자 : 관계있는 변수들을 Tensorflow에 얹어서 그 변수들과 매칭율이 높은 유저에게 적절한 광고 노출 시스템 개발
역량
데이터 분석가, 개발자의 역량
변수가 될 가능성이 있는 데이터 가공 능력
다양한 테스트를 통해 적절한 변수 발견
데이터 사이언스와 AI
인공지능 기술은 전통적인 통계학을 바탕으로 한다.
데이터 기반으로 추론 및 검증하고, 결과를 예측한다.
AI 이전에는 빅데이터 분석, 데이터 마이닝 등 활용한다.
"데이터 사이언스의 인공지능은 데이터 사이언스에 기반하고 있다."
AI 전문가, AI 과학자
데이터 사이언스 학문분야 내부에 ㅜ이치
머신러닝, 딥러닝을 사용하여 복잡한 추론 및 예측, 검증을 가능하게 한다.
데이터 사이언스 기반, SOTA 문제해결에 포커스 - 최근에 엄청난 성과
데이터 사이언스에 포함되지만 더 인공지능에 초점을 맞춘 전문가
2차시 - 데이터 수집, 관리, 분석
데이터 사이언스 6단계 작업의 흐름
문제 정의 -> 데이터 수집 -> 데이터 관리 -> 탐색적 분석 -> 최종 분석 -> 보고
1단계 문제 정의 - 문제 정의를 위한 목표 설정과 배경 파악
명확한 문제 정의와 목표값 설정
새로운 구상을 위한 수요자나 의뢰자 요구 확인
중요성이 매우 크며 정의(추상적인 아이디어의 구체화)가 정확하지 않으면 잘못된 결과를 초래한다.(잘하면 효율적인 워크플로우 가능)
2단계 데이터 수집
데이터들을 데이터베이스나 웹 사이트로부터 수집
각종 매체를 이용한 시장 유용성 조사
설정된 목표값에 부합하는 데이터들을 수집
인터넷에서 다양한 출처(검색, 데이터베이스 등)로부터 수많은 데이터를 찾고, 오프라인에선 센서를 통해 직접 데이터를 수집한다.
효율적인 데이터 수집을 위해 어떻게 수집할지, 어떤 데이터가 필요하고 어떤 처리 과정을 가지는지, 개선점이 무엇인지, 중요한 요소가 무엇인지 고민해야 한다.
3단계 데이터 관리
데이터를 적절하게 저장 및 관리
수집된 데이터를 저장하고, 체계화된 데이터는 데이터베이스 형태로 저장하고, 섞여있는 데이터는 필요한 데이터만 따로 분리하고 만약을 위해 백업하기
4단계 탐색적 분석 - Visualization = 분석한 결과를 빠르게 이해할 수 있다.(모델: 특징 표현. 도구 : 상관관계, 막대 그래프, 히스토그램)
데이터로부터 패턴을 찾아내고, 탐색적 분석 수행, 결과를 시각화
데이터로부터 패턴을 찾아내고, 탐색적 분석을 수행하며, 분류나 클러스터링을 통해 특정 패턴을 찾아내 분석한다.
전통적인 통계 방식 분석이나 머신러닝 기법을 적용하고, 필요한 경우 다양한 방식의 분석 기법 적용 가능하다.
5단계 최종 분석
비즈니스 질문에 대해 최종적으로 데이터 분석
정확한 결과를 위해 예측 모델을 미세 조정하기도 한다.
탐색적 분석 단계 과정을 체크 리스트로 최종 점검하고, 문제 정의에서의 목표 부합 여부를 최종으로 분석하여 결과를 확인한다.
6단계 보고
최종 분석의 결과를 바탕으로 보고 문서를 만든다.
결과를 팀이나 의뢰인에게 보고하고 필요한 결정 권고한다.
시각화된 보고서를 통해 모두에게 보고하고 필요한 결정 권고한다.
데이터 분석 단계 - 분류와 클러스터링
데이터 수집, 분석 및 클러스터링, 저장 및 관리, 지도학습
데이터 사이언스에서 활용되는 분류 - 개인별 선호 예측, 컴퓨터 비전, 유전자 데이터 인식
머신러닝, 딥러닝에서 활용되는 분류의 예와 유사하다. - 머신러닝과 딥러닝도 데이터 사이언스에 포함되어 있다.
클러스터링 응용의 예 - 지진 연구, 그룹화, 피자집 위치 지정, 응급실과 약국 위치 선정
3차시 - 빅데이터와 데이터 마이닝
빅데이터 개요
데이터 : 4차 산업 혁명의 쌀
빅데이터 : 다양한 데이터를 많이 모아 놓은 것
빅데이터란 엄청난 양의 데이터 집합으로부터 가치 있는 정보를 효율적으로 추출하고 결과를 분석하는 최신 기술
포드는 센서를 통해 주행 습관을 수집해 needs를 신제품에 반영하고 있다.
빅데이터 : 정형화 + 비정형 데이터
저장, 분석, 인터넷 등 다양한 기술과 연관성을 가진다.
엄청난 양의 정보를 분석하여 의미 있는 결론을 도출한다.(유전자 정보, 시설물 정보, 주거 및 가족 정보, 기후 환경 정보, CCTV 정보, 범죄 발생 정보, 소셜 미디어 정보, 교통 정보)
빅데이터의 문제점
사생활 침해와 보안 측면의 문제점
수집과 분석 시 개인의 민감한 정보에 주의
정보 제공에 동의하면 추천 정확도는 향상되겠지만 개인 정보가 노출될 우려가 있다.
빅데이터 시장의 규모 - 국내는 14억 달러
빅데이터를 위해 엄청난 양의 데이터 저장 장치가 필요하다.
빅데이터의 특징 3V
큰 데이터 부피 + 빠른 변화 속도 + 다양한 속성 = 효과적인 결과물 창출
빅데이터 기술의 6가지 요소
1. 크기
2. 다양성
3. 속도
4. 진실성 : 의사 결정이나 활동의 배경을 고려하여 이용됨으로써 신뢰성을 높임
5. 시각화
6. 가치 : 비지니스에 실현될 궁극적 가치에 중점을 둔다.
빅데이터 활용 과정
기업의 비즈니스 요구사항 확인
문제 정의
필요한 빅데이터를 검색하여 수집
수집한 데이터를 적절한 형태로 가공
처리된 데이터 분석 및 시각화

데이터 마이닝(데이터 사이언스의 하위 분야) = 빅데이터의 등장으로 적용 범위가 확대되었다.
데이터로부터 통계적 규칙이나 패턴을 찾아내는 과정
통계학, 인공지능, 머신러닝 등의 기법을 활용
컴퓨터 사이언스와 통계학의 학제 간 연구 분야
데이터로부터 지식을 발견하는 분석 과정
데이터 마이닝 주요 업무
데이터로부터 정보를 추출하는 일
감춰진 패턴을 발견해 내는 일
예측 모델을 개발하는 일
통계학 - 한정된 개수의 데이터를 추정 또는 검정
데이터 마이닝 - 대규모 데이터를 분석하여 정보 추출, 기업 경영 활동용 분석이 많다, 다양한 산업 분야에 적용되는 표준화 처리 과정 제시
데이터 마이닝 활용 분야
데이터 마이닝을 이용하는 기업 관련 업무
생산 과정에서 불량률을 줄이는 품질 관리 분야
패턴 인식 기법을 적용한 의료 진단 분야
고객의 신용을 평가하는 금융 관리 분야
데이터 사이언스의 현재
인터넷 발달과 함께 데이터 규모가 날로 커지는 추세이다.
음성, 영상, 동영상 등 비정형의 멀티 미디어 데이터가 급증
데이터 사이언스의 기법도 다양해졌다.
머신러닝을 이용한 인공지능적인 기법을 적용하였다.
10주차 -
1차시 - 인공지능 기술의 미래와 윤리
특이점 - 기술적 특이점 or 특이점 그 자체 = 지능의 폭발 발생
인공지능이 새로운 문명을 만드는 가설적 미래 시점
인공지능 기술이 인간 능력을 뛰어 넘어 새 문명을 만드는 시점
미래학자들은 인공지능이 통제 불가능한 수준 발달 예상
지능의 폭발 - 특이점 가설의 대표적인 예로 인공지능이 발전하여 인간의 지능을 뛰어넘는 기점
강한 인공지능 이상의 슈퍼 인공지능이 출현하는 시기이다.
약한 인공지능(자율 주행) -> 강한 인공지능(인간 수준) -> 슈퍼 인공지능
무어의 법칙 - 컴퓨터 속도는 2년마다 2배씩 빨라진다. -> 인공지능도 적용
이로운 기계 = 인간 선호의 실현 최대화 + 선호에 대해 확실히 알지 못함 + 정보의 궁극적 원천은 인간의 행동 = 이타성의 원칙 + 겸손의 원칙 + 인간 관찰의 법
2차시 - 인공지능 윤리 이슈
인공지능의 필요성 : 인공지능과 관련된 다양한 문제들은 사람이 인공지능을 어떻게 만들고 사용하는가에 따라 결정된다. -> 개발자, 사용자 모두 인공지능 윤리 문제를 충분히 고려해야 한다.
인공지능 윤리 이슈 : 성차별, 다양한 혐오 발언 학습, 트롤리 딜레마, 딥페이크 기술, 뉴럴링크
인공지능 윤리
인공지능 개발자들을 제어하는 규칙들과 기준들
연구 대상자들이 지켜야 할 기본적인 윤리
연구 과정이나 내용을 조작하지 않을 윤리
사회적 문제의 가능성을 교려하며 연구할 윤리
예측되는 결과들의 윤리적 문제 여부 판단
예방적 차원에서의 윤리 의식 함양
3차시 - 인공지능 윤리의 중요성과 원칙
인공지능 윤리
인공지능 관련 이해관계자들이 준수해야 할 보편적 사회 규범 및 관련 기술
카카오 - 알고리즘 기술이 인간의 도덕적 가치와 윤리관념에 부합, 궁극적으로는 인간의 삶의 효율성을 높일 수 있어야 한다.
이실로마 원칙 - AI 개발의 목적, 윤리와 가치, 중기 이슈 등에 대해 개발자들이 지켜야하는 준칙
우리가 인공지능을 개발할 때 무엇을 지켜야 하며, 왜 지켜야 하는지, 인공지능에 대한 각국의 법안과 윤리 수칙에 대한 제정
연구 문제 - 5가지
1. 연구 목적은 유익한 지능을 만드는 것이어야 한다.
2. 유익한 사용을 보장하기 위한 연구 자금 동반
3. AI 연구자 및 정책 임안자 간 교류 필요
4. 협력, 신뢰, 투명성의 연구 문화 육성
5. AI 시스템 개발팀은 적극적으로 협력해야 한다.
윤리와 가치 -13가지 (개인 정보 보호, 프로세스 존중 및 개선 등등)
장기적 문제 - 5가지(AI 역량의 주의, 계획과 위험 관리, 안전 관리 및 통제 대상, 초지능의 공공성)
유네스코 인공지능 윤리 권고 - 세계적 AI 표준
선언 < 윤리 권고 < 협약
데이터 보호 강화, 사회적 점수 평가 및 대량 감시 금지, 모니터링 및 평가 지원, 환경 보호
'인공지능 > 공부' 카테고리의 다른 글
| 인공지능과 빅데이터 11 ~ 15주차 정리 (0) | 2024.06.20 |
|---|---|
| LSTM, GRU 연산 정리하기 (0) | 2024.06.18 |
| 생성형 인공지능 입문 기말고사 간단 정리 (1) | 2024.06.16 |
| 생성형 인공지능 기말고사 대비 문제만들기 (2) | 2024.06.15 |
| 딥러닝 개론 14장 강화학습 (1) | 2024.06.15 |