728x90
728x90

from google.colab import drive, files
import pandas as pd
from keras.datasets.mnist import load_data
from keras.models import Sequential, Model
from keras.layers import Dense, Input ,Flatten, Dropout, Conv2D, MaxPooling2D
from keras.utils import plot_model, to_categorical
from keras.regularizers import l2
from sklearn.model_selection import train_test_split
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf각종 라이브러리 임포트 해줍니다.
이전에 있던 코드를 재활용하느라 Conv까지 존재하는데 필요 없어보이는건 지우셔도 됩니다.
Uploaded = files.upload()
df_train = pd.read_csv('train_data.csv')
df_test = pd.read_csv('test_data.csv')데이터 집어넣기 - 과제 1
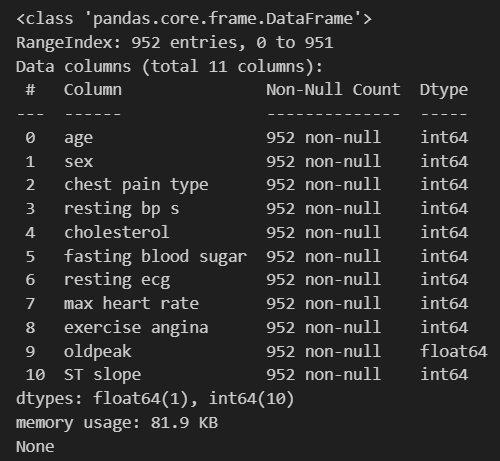
print(df_train.drop('target', axis=1).info())라벨을 제거한 information 출력하기
df_train = df_train.sample(frac=1)
df_test = df_test.sample(frac=1)
traindata = df_train.values
testdata = df_test.values
X_train = traindata[:,0:11]
Y_train = traindata[:,11]
X_test = testdata[:,0:11]
Y_test = testdata[:,11]데이터를 나눠줍니다.
input = Input(shape = (11))
x = Dense(32, activation = 'relu')(input)
x = Dense(64, activation = 'relu')(x)
#x = Dense(64, activation = 'relu')(x)
x = Dense(32, activation = 'relu')(x)
output = Dense(1, activation = 'sigmoid')(x)
model = Model(inputs = input, outputs = output)
model.compile(optimizer = tf.keras.optimizers.Adam(learning_rate = 0.01), loss = 'binary_crossentropy', metrics = ['accuracy'])
hist = model.fit(X_train, Y_train, epochs = 50, batch_size = 10, validation_split = 0.2)파라미터나 레이어는 다양하게 변경해보시면 되빈다.
학습은 금방 끝납니다.
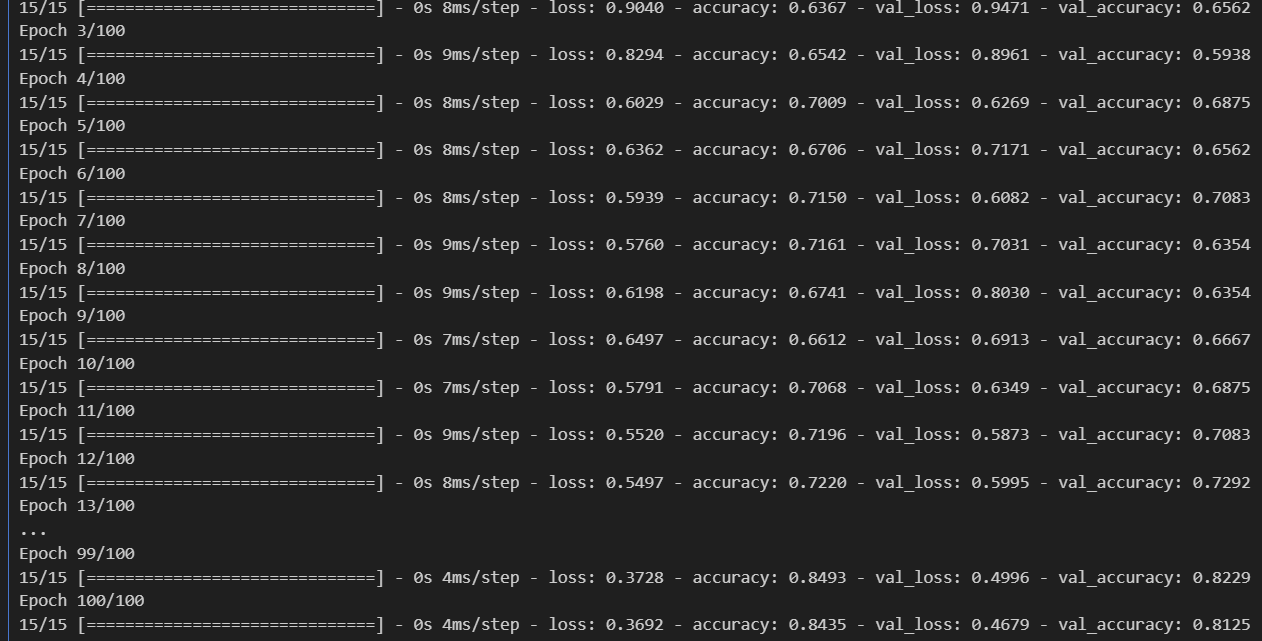
validation을 보고 얼마나 학습되었는지 확인할 수 있습니다. - 과제 3
model.evaluate(X_test,Y_test)
plt.plot(hist.history['loss'],label='loss')
plt.plot(hist.history['val_loss'],label='val_loss')
plt.legend()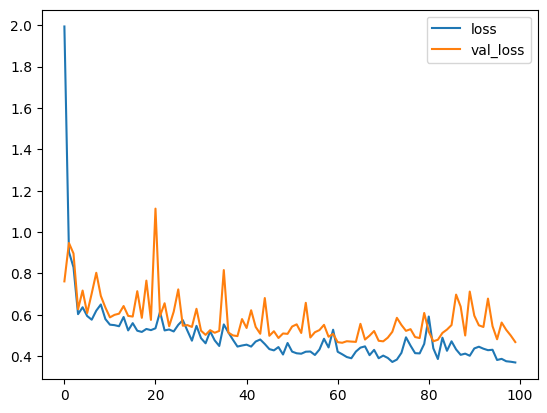
있으면 보기 좋으니까.....

정확도도 0.75보다 높네요 - 과제 4
728x90
'인공지능 > 공부' 카테고리의 다른 글
| 모두를 위한 머신러닝 - 14주차 퀴즈 (1) | 2024.06.03 |
|---|---|
| 모두를 위한 머신러닝 - 14주차 이상 데이터 검출 (0) | 2024.06.03 |
| 생성형 인공지능 입문 - 13주차 퀴즈 (0) | 2024.05.28 |
| 생성형 인공지능 입문 13주차 - Transformer 기반 action 생성 (1) | 2024.05.27 |
| 모두를 위한 머신러닝 13주차 퀴즈 (0) | 2024.05.27 |