1차시 - 영상 생성 동작 및 데모

잠복 - latent
VAE + U-net(노이즈 제거에 좋다) + BERT
QKV가 트랜스포머 기반이라는 것을 포현해준다. - 트랜스포머 기반으로 한 u-net
Conditioning에 언어 모델이 들어간다. BERT,GPT 등등...
모델 로드하는 과정이다.
프롬포트를 바꾸면 계속 다른 사진이 나온다.

리소스 문제가 있긴 하지만 그래도 퀄리티가 매우 좋아졌다.
2차시 - 영상 생성 동작 2 DALL E


제로샷 러닝, 생성 - 한 번도 보여주지 않았다.
원샷 - 한 번은 샘플을 보여준다.
학습에는 엄청난 양의 데이터를 사용했다.

한 번도 본적 없는 텍스트에 대해서도 이미지를 생성한다.

파라미터가 너무 많다.
256 * 256 을 32*32로 여러개 이미지 토큰(패치)으로 나눈다.



coco - 이미지 넷과 비슷한 데이터 셋이다.

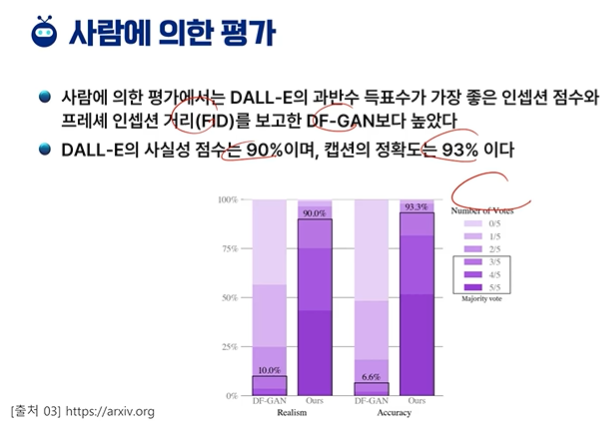


3차시 - DALL-E 2 소개


CLIP의 Latent 벡터를 이용한다.

CLIP - 이미지 생성의 학습 효과도 좋고, 퀄리티도 좋아진다.
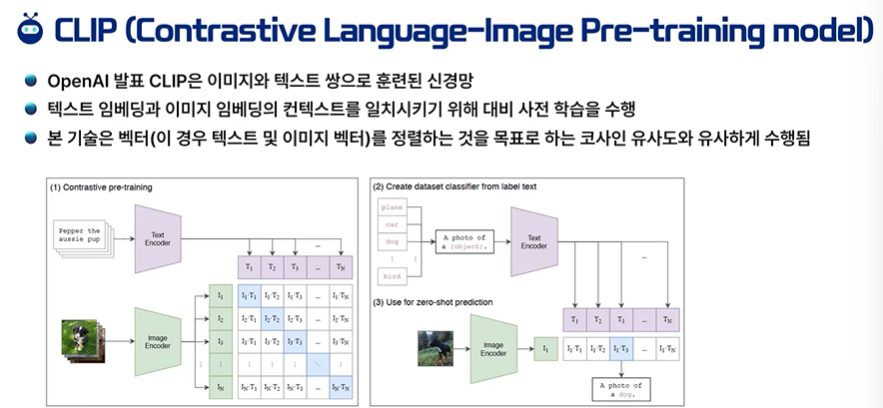
text와 이미지의 연관성을 가져온다.

생성형 AI 류에서 open ai의 영향력이 엄청 크다.

클립 + 프라이어 = 달리 2

다양성이 많이 높아졌다.
CLIP - 텍스트, 이미지 쌍의 데이터가 많이 사용되었다. == 다양한 종류의 그림을 그릴 수 있다.



4차시 - 달리 응용 사례




원하는 프린팅도 그려준다.



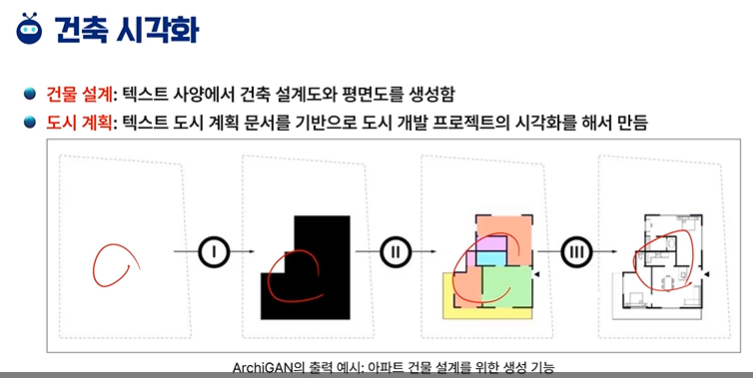

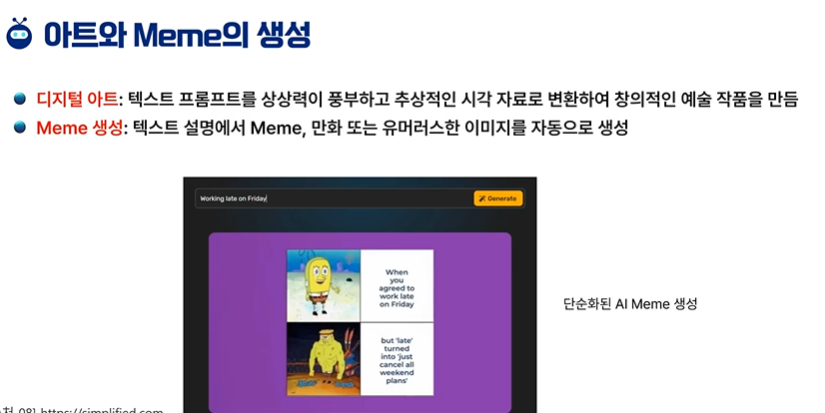


5차시 - 생성 모델의 확장성


계산 제약 조건(CPU, GPU)에 따라 모델을 조절할 수 있다.


시간과 GPU사용량은 더 늘 순 있지만 크기를 늘릴 수 있다.

적은 리소스만으로도 어떻게든 만들 수 있다.


시간이 지날수록 점점 개선된다.
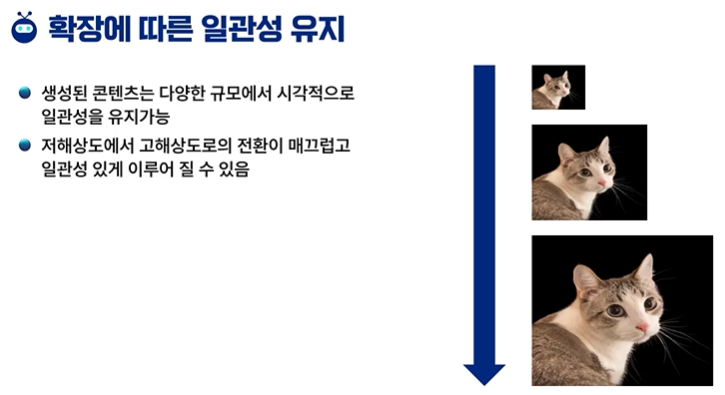
작은 것도 나름대로의 성질은 유지한다.

창의성이 중요하다.



Scalable Diffusion Models with Transformers (DiT)
확산 모델에 트랜스포머 백본. JAX로 구현됨. Arxiv Github Project Page Abstract 확산 모델에서 일반적으로 사용되는 U-Net 백본을 잠재 패치에서 작동하는 트랜스포머로 대체한다. 트랜스포머의 깊이/폭
ostin.tistory.com
Scalable Diffusion Models with Transformers 논문 리뷰입니다.
'인공지능 > 공부' 카테고리의 다른 글
| 모두를 위한 머신러닝 13주차 - 차원줄이기 (0) | 2024.05.27 |
|---|---|
| 생성형 인공지능 입문 - 12주차 퀴즈 (1) | 2024.05.20 |
| 모두를 위한 머신러닝 과제2 - k means 진행, 계산 (0) | 2024.05.20 |
| 모두를 위한 머신러닝 12주차 퀴즈 (0) | 2024.05.20 |
| 모두를 위한 머신러닝 12주차 클러스터링 (0) | 2024.05.20 |