
이전엔 단순히 encoding만 했다면 이후로는 embedding으로 진행하였다.
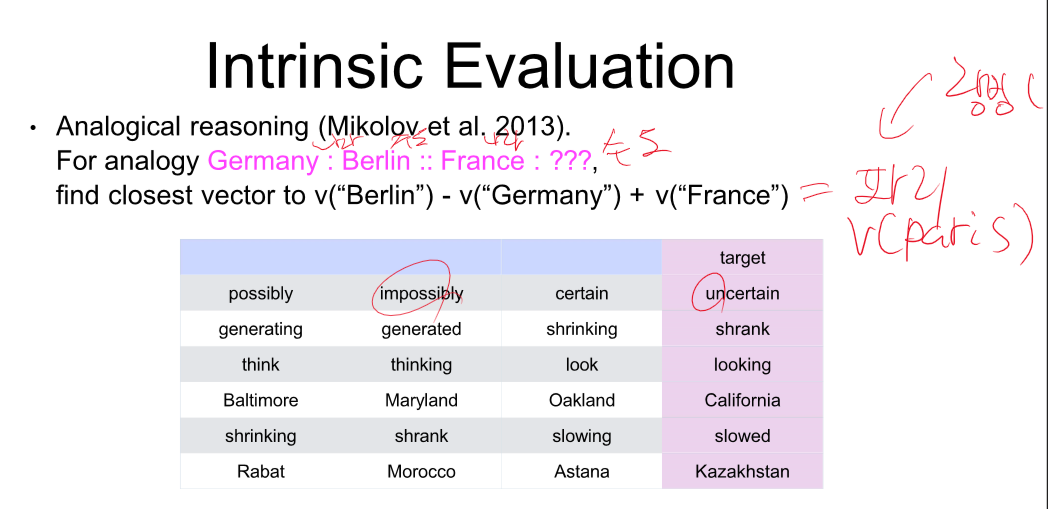
주변 단어를 통해 문맥을 얻을 수 있다.
비슷한 문맥 - 비슷한 벡터
representation = 컴퓨터가 이해할 수 있는 표현 == 백터
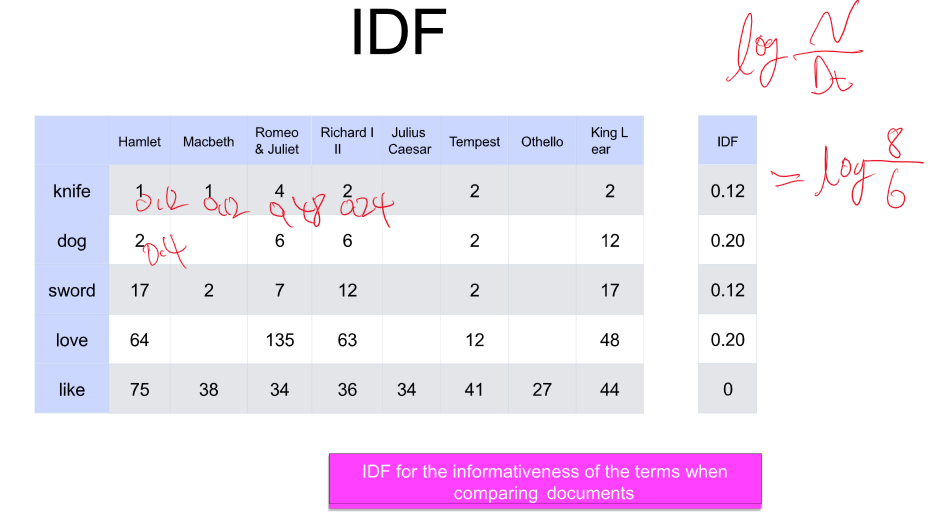
TD - 특정 문장에 단어가 등장 횟수
유사도는 이렇게 구할 수 있다.
문서가 많아질수록, 단어가 많아질 수록 효율이 떨어진다.

모든 문서에서 많이 나온다 - 가중치가 낮다 -> 일부 문서에서만 나온다 - 가중치가 높다.

TF - 얼마나 나오는지 센다
DF - 총 문서에서 얼마나 나왔냐







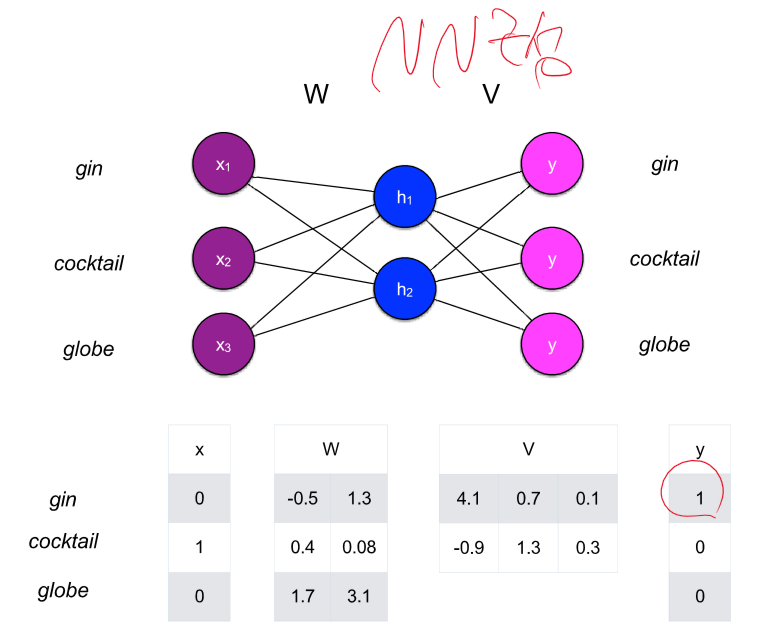
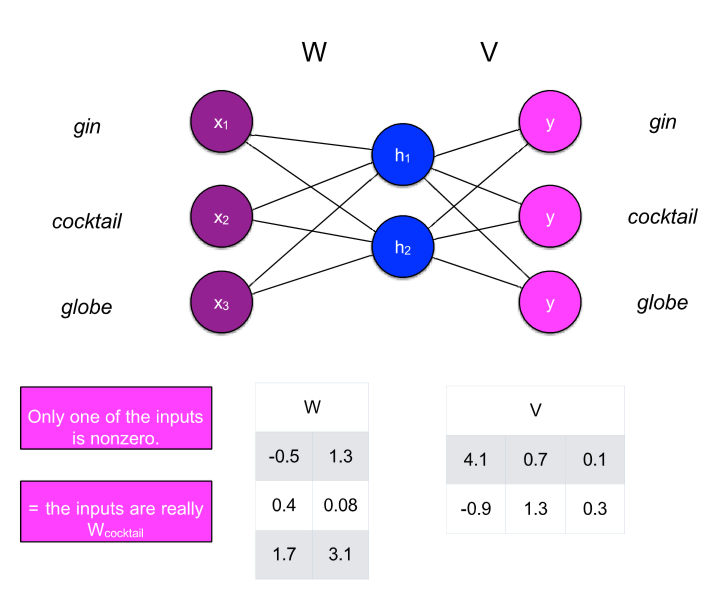
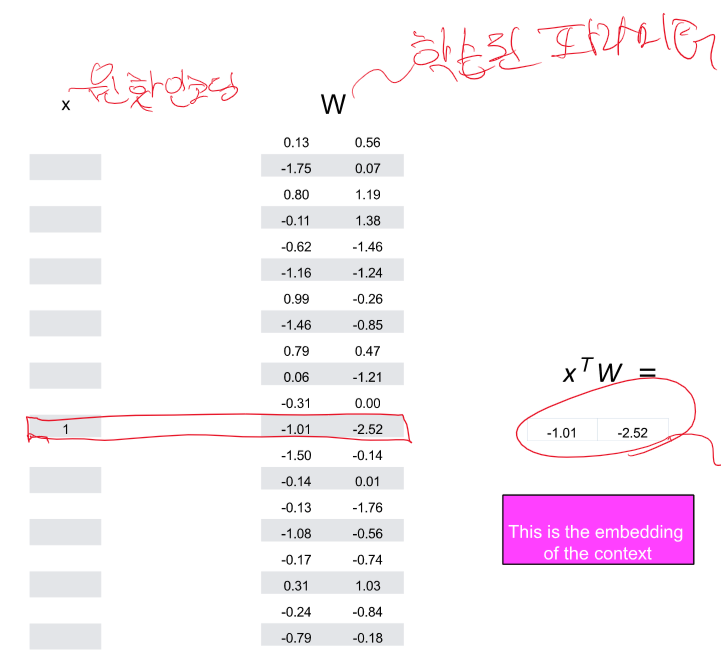
이것이 word2Vec 방식이다. 파라미터를 embedding으로 사용하는 것이다.


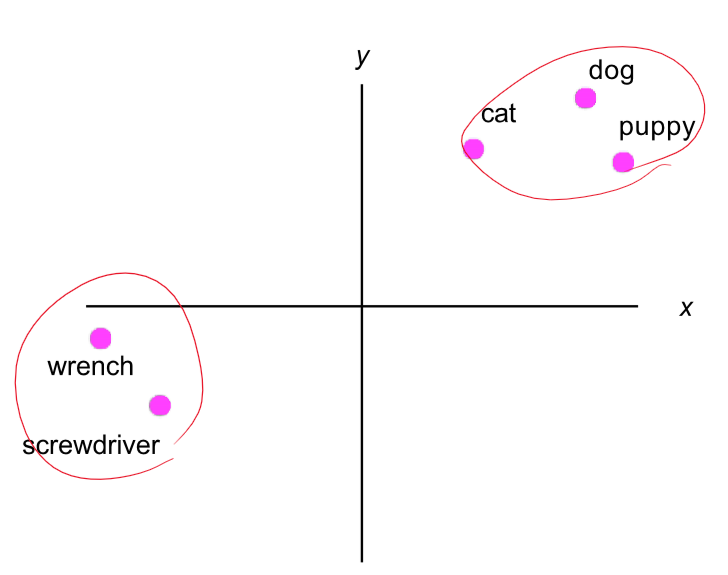
이러한 형태가 나온다.





그럼 word2vec는 수 많은 문장에서 얻어낸 단어들을 원핫 인 코딩 한 후 문장에 구멍을 뚫어서 뚫은 단어의 정답을 그 주변 단어로 하고 학습시킨 뒤 그 내부 파라미터를 백터로 사용하는 거야?
네, 맞습니다. Word2Vec는 대량의 텍스트 데이터에서 단어의 의미를 벡터 형태로 표현하는 데 사용되는 모델입니다. 이 모델의 핵심 아이디어는 비슷한 문맥에서 나타나는 단어들은 비슷한 의미를 가질 가능성이 높다는 점을 기반으로 합니다.
Word2Vec에는 두 가지 주요 아키텍처가 있습니다: Continuous Bag of Words (CBOW)와 Skip-Gram입니다. CBOW는 문장에서 주변 단어들을 사용하여 특정 단어를 예측하는 반면, Skip-Gram은 한 단어에서 주변 단어들을 예측합니다. 두 모델 모두 비슷한 방식으로 학습됩니다.
1. 문장에서 단어를 원-핫 인코딩으로 변환합니다. 이는 단어가 벡터 공간에서 고유한 위치를 갖도록 합니다.
2. Word2Vec 모델을 사용하여, CBOW의 경우 주변 단어들로부터 중심 단어를 예측하거나, Skip-Gram의 경우 중심 단어로부터 주변 단어들을 예측합니다.
3. 이 과정에서 모델의 내부 파라미터가 학습됩니다. 이 파라미터들은 최종적으로 각 단어의 벡터 표현으로 사용됩니다.
Word2Vec 모델 학습이 완료되면, 각 단어는 벡터 공간에서 의미론적으로 비슷한 단어들과 가까이 위치하게 됩니다. 예를 들어, "왕"과 "여왕"은 벡터 공간에서 서로 가까운 위치에 있을 것이며, 이러한 벡터 표현은 단어 간의 의미적 유사성을 포착하는 데 사용될 수 있습니다.
Word2Vec으로 생성된 단어 벡터는 다양한 자연어 처리 작업에 활용될 수 있으며, 문장이나 문서의 의미를 분석하는 데 유용한 도구가 됩니다.



'인공지능 > 자연어 처리' 카테고리의 다른 글
| 자연어 처리 5강 - Deep Learning Recap 1 (0) | 2024.04.12 |
|---|---|
| 자연어 처리 정리 - 4강 word embedding 2 (0) | 2024.04.12 |
| 자연어 처리 정리 - 2강 Text mining (0) | 2024.04.12 |
| 자연어 처리 Python 실습 - 한국어 관계 추출 (0) | 2024.04.11 |
| 자연어 처리 python 실습 - 한국어 자연어 추론 Task 실습 (1) | 2024.04.11 |