
항상 어려웠던 이 부분...
https://www.youtube.com/watch?v=6s69XY025MU&t=1322s&pp=ygUWdHJhbnNmb3JtZXIsIGF0dGVudGlvbg%3D%3D
이 유튜브가 찐으로 잘 설명해줍니다...
컴퓨터가 어디에 attention을 주냐 안주냐에 관심! 누구한테 관심을 얼마만큼 주냐 => Self Attention
주어진 모델 - Head -> 모든 head를 다 더하면 multi head attention
RNN -> LSTM -> GRU -> Transformer
information retirval == 내가 query를 줬을 때 키 key 값이 있고, 그것에 대한 value를 찾겠다.
문장 내의 연관 관계를 따지는데 q,k,v를 통해 문장 내의 context가 자동으로 계산이 된다.
이미지일 경우 -> 고양이와 개의 관계 등이 계산된다.
셀프 어텐션(Self-Attention)은 입력 시퀀스 내의 각 요소가 서로 어떻게 상호작용하는지를 모델링하는 메커니즘입니다. 셀프 어텐션에서는 쿼리(Query), 키(Key), 밸류(Value) 모두 같은 입력 시퀀스에서 나옵니다. 이 점이 일반적인 어텐션 메커니즘과 다른 점입니다. 즉, 각 입력 요소는 쿼리, 키, 밸류의 세 가지 역할을 모두 수행합니다.
예시로, 문장 내 단어 간의 관계를 학습하는 경우를 생각해보겠습니다.
예시: "The cat sat on the mat"
- 쿼리(Query): 현재 관심을 가지고 있는 단어입니다. 예를 들어, "sat"이 쿼리가 될 수 있습니다.
- 키(Key): 쿼리와 비교 대상이 되는 다른 단어들입니다. 예를 들어, "The", "cat", "on", "the", "mat"이 키가 됩니다.
- 밸류(Value): 키와 연관된 정보로, 쿼리와의 관계를 통해 얻은 정보의 가중치를 결정하는 데 사용됩니다. 이 예시에서 밸류 역시 "The", "cat", "on", "the", "mat"의 정보가 됩니다.
셀프 어텐션의 과정은 다음과 같습니다:
- "sat"이 쿼리로 주어집니다.
- 쿼리("sat")는 문장의 모든 단어(키)와 비교됩니다. 이 때, 각 단어가 "sat"와 얼마나 관련이 있는지를 평가합니다.
- 평가된 관련도에 따라 각 밸류(문장의 모든 단어에 대한 정보)에 가중치를 부여합니다.
- 가중치가 부여된 밸류들을 합산하여, 새로운 문맥 벡터를 생성합니다. 이 벡터는 "sat"이라는 단어의 문맥을 포착한 정보를 담고 있습니다.
이 과정을 통해 모델은 "sat"이라는 단어가 문장 내에서 어떤 단어와 관련이 깊은지(예: "cat", "mat")를 학습할 수 있습니다. 셀프 어텐션은 이런 식으로 모든 단어에 대해 반복됩니다. 결과적으로, 모델은 문장 내의 모든 단어 간의 관계를 포괄적으로 이해할 수 있게 됩니다.
attention masking
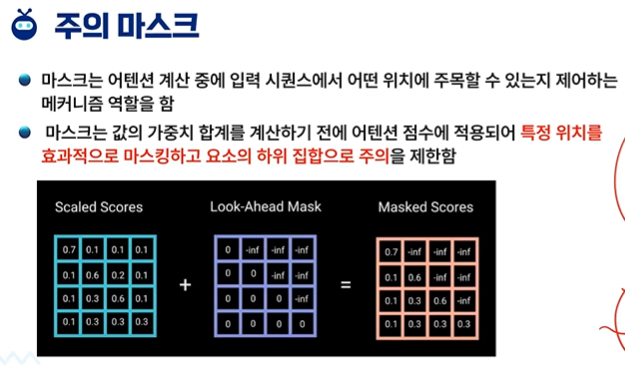
가려져있으면 유추를 할 수 있다.
한쪽만 하는 것이 아니라 랜덤으로도 가능하다.
GPT도 이러한 MASK 때문에 빈칸 채우기 문제를 잘 맞출 수 있게 되었다.

'인공지능 > 공부' 카테고리의 다른 글
| 생성형 인공지능 4주차 Transformer 4차시 - Multi-Head Attention 다중머리 주의 (0) | 2024.03.26 |
|---|---|
| 생성형 인공지능 4주차 Transformer 3차시 - Self-Attention 2 자기 주의 (0) | 2024.03.26 |
| 생성형 인공지능 4주차 Transformer 1차시 - 워드 임베딩 word embedding (1) | 2024.03.26 |
| 머신러닝 과제 1 (1) | 2024.03.26 |
| 머신러닝 퀴즈 4 (1) | 2024.03.25 |