728x90
728x90
목표 - 수집한 자연어 코퍼스를 정제하는 과정 및 정규화 과정에 대해 이해할 수 있다.

정규화 - 대문자 -> 소문자, 다양한 이모지 통일 등
노이즈 - 판단 필요하다! -> 완벽하게 없애는 것은 힘들기 때문에 합의점이 필요하다.
분포가 너무 적은 것들은 제거도 한다.
쓰임이 없는 단어, 비효율적인 단어들
모델의 응답시간도 단축 가능하다.
정보량이 많지 않다. -> 무언가를 분류하는데 도움이 되지 않는다.
없다면 pip nltk로 설치도 필요하다.
대명사, 관사들이 들어있다.
내가 필요하다고 생각하다면 리스트에서 제거해주면 된다.
단어가 많이 줄어든 것을 볼 수 있다.
조사는 붙어있는데 어떻게 제거할까?

특수 문자중에서도 웃음과 같은 것은 긍정으로 볼 수 있지 않나...?
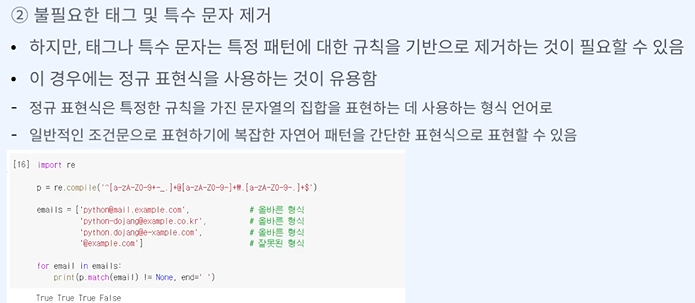

빈도에 따라 중요성도 생각해 볼 수 있다.




모델은 숫자에 의해 판단한다!


불필요한 단어를 없앤다 -> 효율성 증가!!



과거형도 현재형으로 !

최근에 자주 사용되지는 않는다.




728x90
'인공지능 > 자연어 처리' 카테고리의 다른 글
| 한국어 데이터 전처리 - 서브워드 토큰화 (BPE 활용) (0) | 2024.03.02 |
|---|---|
| 한국어 데이터 전처리 - 토큰화 Tokenization (0) | 2024.03.02 |
| 한국어 데이터 전처리 - 자연어 코퍼스 수집 (0) | 2024.03.02 |
| 자연어 처리 살펴보기 - Google colab 환경에서 Huggingface 기초 실습 (0) | 2024.03.02 |
| 자연어 처리 살펴보기 - 프레임워크 소개 (0) | 2024.03.02 |