728x90
728x90

강의 목표 : 웹 상에 공개된 한국어 자연어 코퍼스들을 소개하고 활용하는 방법들을 이해할 수 있다.



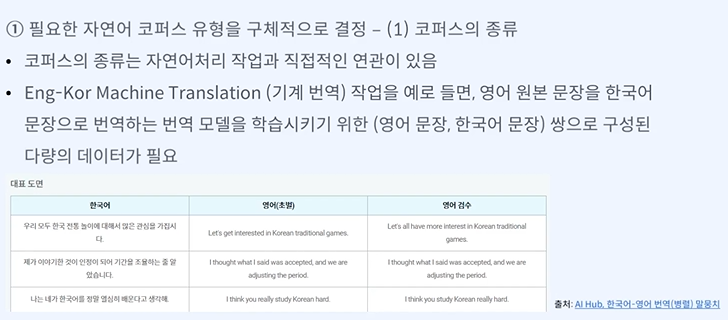

내가 필요한 데이터의 종류를 잘 찾아야 한다.

어느 정도의 코퍼스를 수집해야 할까?
무한히 많은 코퍼스가 항상 좋은 것도 아니다.

번역 모델 - 모델 구조에 2만개의 학습 데이터를 넣었을 때 잘 된다는 논문을 보고 2만개라고 정할 수 있다.


레이블 - 데이터의 패턴

모델이 커지면 커질수록 데이터 필요 커짐
쉬운 작업에 큰 모델은 필요 없다!


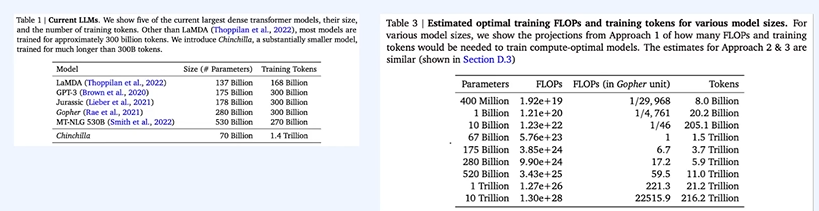
데이터에 비해 모델이 너무 크다! 모델이 크려면 학습 데이터도 많아야 한다.




23년 현재의 어뷰징 컨텐츠를 거르고 싶은데 20년도 어뷰징 관련 데이터라면 지금 어뷰징은 못 잡을 확률이 크다.
데이터 분석 과정이 필수다.



중립적인 의견은 표출하지 않아 편향적인 데이터가 많다.


최근의 일을 다뤄준다!


내가 만든다? -> 리소스 과다 필요



트롤러들이 존재하기도 한다!

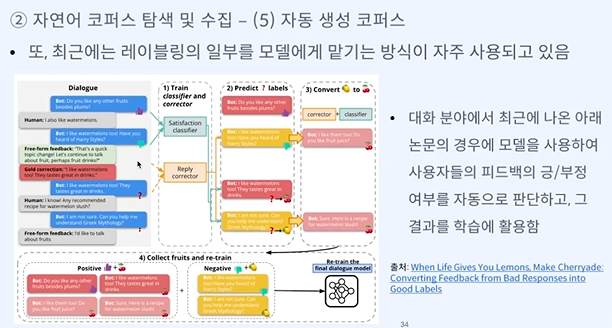
자동 생성 코퍼스가 있다면 이미 내가 만드려는 모델이 있는거 아닌가...?


원본문장 -> 소스문장으로 번역하는 모델을 만들 때 소스문장이 더 많다면 소스문장을 원본 문장으로 번역한 것을 다시 학습에 사용하기

728x90
'인공지능 > 자연어 처리' 카테고리의 다른 글
| 한국어 데이터 전처리 - 토큰화 Tokenization (0) | 2024.03.02 |
|---|---|
| 한국어 데이터 전처리 - 정제(Cleaning) 및 정규화(Normalization) (0) | 2024.03.02 |
| 자연어 처리 살펴보기 - Google colab 환경에서 Huggingface 기초 실습 (0) | 2024.03.02 |
| 자연어 처리 살펴보기 - 프레임워크 소개 (0) | 2024.03.02 |
| 자연어 처리 진행 순서 2 - 모델링, 모델 학습 및 평가 (0) | 2024.03.02 |