import matplotlib.pyplot as plt
plt.rc('font', family='NanumBarunGothic')
from google.colab import drive
drive.mount('/content/drive')
base_path = "./drive/MyDrive/fastcampus/practice"
import pandas as pd
df = pd.read_csv(f"{base_path}/data/nsmc/ratings_train.txt", sep='\t')
# pos, neg 비율
df['label'].value_counts()
# missing doc
sum(df['document'].isnull())
df = df[~df['document'].isnull()]
sum(df['document'].isnull())
df['document'].iloc[0].split()
# tokenization
vocab = set()
for doc in df['document']:
for token in doc.split():
vocab.add(token)
len(vocab) # 너무 많다
# tokenization
vocab_cnt_dict = {}
for doc in df['document']:
for token in doc.split():
if token not in vocab_cnt_dict:
vocab_cnt_dict[token] = 0
vocab_cnt_dict[token] += 1
vocab_cnt_list = [(token, cnt) for token, cnt in vocab_cnt_dict.items()]
top_vocabs = sorted(vocab_cnt_list, key=lambda tup:tup[1], reverse=True)
import matplotlib.pyplot as plt
import numpy as np
cnts = [cnt for _, cnt in top_vocabs]
plt.plot(range(len(cnts)), cnts)
np.mean(cnts)
sum(np.array(cnts) > 2) # count가 3개 이상인 vocab의 수
n_vocab = sum(np.array(cnts) > 2)
top_vocabs_truncated = top_vocabs[:n_vocab]
vocabs = [token for token, _ in top_vocabs_truncated]
unk_token = '[UNK]'
unk_token in vocabs
pad_token = '[PAD]'
pad_token in vocabs
vocabs.insert(0, unk_token)
vocabs.insert(0, pad_token)
idx_to_token = vocabs
token_to_idx = {token: i for i, token in enumerate(idx_to_token)}
class Tokenizer:
def __init__(self, vocabs, use_padding=True, max_padding=64, pad_token='[PAD]', unk_token='[UNK]'):
self.idx_to_token = vocabs
self.token_to_idx = {token: i for i, token in enumerate(self.idx_to_token)}
self.use_padding = use_padding
self.max_padding = max_padding
self.pad_token = pad_token
self.unk_token = unk_token
self.unk_token_idx = self.token_to_idx[self.unk_token]
self.pad_token_idx = self.token_to_idx[self.pad_token]
def __call__(self, x):
token_ids = []
token_list = x.split()
for token in token_list:
if token in self.token_to_idx:
token_idx = self.token_to_idx[token]
else:
token_idx = self.unk_token_idx
token_ids.append(token_idx)
if self.use_padding:
token_ids = token_ids[:self.max_padding]
n_pads = self.max_padding - len(token_ids)
token_ids = token_ids + [self.pad_token_idx] * n_pads
return token_ids
tokenizer = Tokenizer(vocabs, use_padding=False)
sample = df['document'].iloc[0]
print(sample)
token_length_list = []
for sample in df['document']:
token_length_list.append(len(tokenizer(sample)))
# 시각화
plt.hist(token_length_list)
plt.xlabel("token length")
plt.ylabel("count")
tokenizer = Tokenizer(vocabs, use_padding=True, max_padding=50, pad_token='[PAD]', unk_token='[UNK]')
# data loader
import torch
from torch.utils.data import Dataset, DataLoader
# Split data into train, valid, testset
train_valid_df = pd.read_csv(f"{base_path}/data/nsmc/ratings_train.txt", sep='\t')
test_df = pd.read_csv(f"{base_path}/data/nsmc/ratings_test.txt", sep='\t')
print(f"# of train valid samples: {len(train_valid_df)}")
print(f"# of test samples: {len(test_df)}")
train_valid_df = train_valid_df.sample(frac=1.)
train_ratio = 0.8
n_train = int(len(train_valid_df) * train_ratio)
train_df = train_valid_df[:n_train]
valid_df = train_valid_df[n_train:]
print(f"# of train samples: {len(train_df)}")
print(f"# of train samples: {len(valid_df)}")
print(f"# of test samples: {len(test_df)}")
# 1/10으로 샘플링
train_df = train_df.sample(frac=0.1)
valid_df = valid_df.sample(frac=0.1)
test_df = test_df.sample(frac=0.1)
class NSMCDataset(Dataset):
def __init__(self, data_df, tokenizer=None):
self.data_df = data_df
self.tokenizer = tokenizer
def __len__(self):
return len(self.data_df)
def __getitem__(self, idx):
sample_raw = self.data_df.iloc[idx]
sample = {}
sample['doc'] = str(sample_raw['document'])
sample['label'] = int(sample_raw['label'])
assert sample['label'] in set([0, 1])
if self.tokenizer is not None:
sample['doc_ids'] = self.tokenizer(sample['doc'])
return sample
def collate_fn(batch):
keys = [key for key in batch[0].keys()]
data = {key: [] for key in keys}
for item in batch:
for key in keys:
data[key].append(item[key])
return data
train_dataset = NSMCDataset(data_df=train_df, tokenizer=tokenizer)
valid_dataset = NSMCDataset(data_df=valid_df, tokenizer=tokenizer)
test_dataset = NSMCDataset(data_df=test_df, tokenizer=tokenizer)
# 학습 데이터셋은 shuffle을 해줘야함
train_dataloader= DataLoader(train_dataset,
batch_size=64,
collate_fn=collate_fn,
shuffle=True)
valid_dataloader= DataLoader(valid_dataset,
batch_size=64,
collate_fn=collate_fn,
shuffle=False)
test_dataloader= DataLoader(test_dataset,
batch_size=64,
collate_fn=collate_fn,
shuffle=False)
sample = next(iter(test_dataloader))이전에 사용했던 전처리 작업은 동일하다.
import torch
import torch.nn as nn
import torch.nn.functional as F
class SentenceCNN(nn.Module):
def __init__(self,
vocab_size,
embed_dim,
word_win_size=[3, 5, 7]):
"""
Args:
vocab_size (int): size of vocabulary.
embed_dim (int): dimension of embedding.
word_win_size (list): n-gram filter size, optional
"""
super().__init__()
self.vocab_size = vocab_size
self.embed_dim = embed_dim
self.word_win_size = word_win_size
self.conv_list = nn.ModuleList(
[nn.Conv2d(1, 1, kernel_size=(w, embed_dim))
for w in self.word_win_size])
self.embeddings = nn.Embedding(vocab_size,
embed_dim,
padding_idx=0)
self.output_dim = len(self.word_win_size)
def forward(self, X):
"""Feed-forward CNN.
Args:
X (torch.Tensor): inputs, shape of (batch_size, seq_len).
Returns:
torch.tensor, Sentence representation.
"""
batch_size, seq_len = X.size()
X = self.embeddings(X) # batch_size x seq_len x embed_dim
X = X.view(batch_size, 1, seq_len, self.embed_dim) # batch_size x channel(1) x seq_len(H) x embed_dim(W)
C = [F.relu(conv(X)) for conv in self.conv_list]
C_hat = torch.stack([F.max_pool2d(
c, c.size()[2:]).squeeze()
for c in C], dim=1)
return C_hat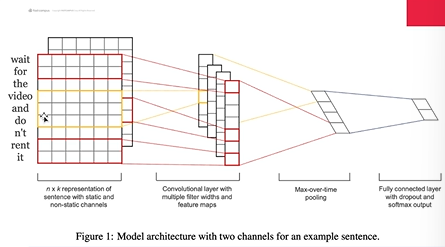
이 코드에 대한 설명
[
이 코드는 PyTorch를 활용한 CNN 기반의 자연어 처리(NLP) 모델로, 주요 구성 요소와 차원 변환에 대해 설명하겠습니다.
1. **클래스 정의 및 초기화**:
- `SentenceCNN` 클래스는 `nn.Module`을 상속받아 정의됩니다.
- `vocab_size`, `embed_dim`, `word_win_size`라는 매개변수를 입력받습니다.
- `self.embeddings`: 단어 임베딩을 위한 레이어로, 단어의 인덱스를 임베딩 벡터로 변환합니다.
- `self.conv_list`: 여러 크기의 커널을 가진 1차원 컨볼루션 레이어들의 리스트를 생성합니다.
2. **forward 메소드**:
- 입력 텐서 `X`의 차원은 `[batch_size, seq_len]`입니다.
- `self.embeddings(X)`: 임베딩 레이어를 통해 `X`를 임베딩 벡터로 변환합니다. 차원이 `[batch_size, seq_len, embed_dim]`이 됩니다.
- `X.view(...)`: 임베딩된 텐서를 4차원 텐서로 재구성하여 컨볼루션 연산을 수행할 수 있도록 합니다. 차원이 `[batch_size, 1, seq_len, embed_dim]`이 됩니다.
- `self.conv_list`: 각 컨볼루션 레이어를 순회하면서 텐서에 적용합니다. ReLU 활성화 함수를 적용한 후, 결과를 리스트 `C`에 저장합니다.
- `torch.stack(...)`: 각 컨볼루션 레이어의 출력을 최대 풀링 연산을 통해 축소하고, 이 결과들을 차원 1에 따라 쌓아 최종 출력 `C_hat`을 생성합니다. 차원은 `[batch_size, len(self.word_win_size), 1, 1]`이 됩니다.
3. **backward 메소드**:
- 이 코드에는 `backward` 메소드가 명시적으로 정의되어 있지 않습니다. PyTorch의 `nn.Module`은 자동 미분 기능을 지원하므로, 모델의 파라미터에 대한 손실 함수의 그래디언트를 자동으로 계산할 수 있습니다.
- 학습 과정에서 손실(loss)을 계산하고 `loss.backward()`를 호출하면, 이 클래스의 각 파라미터에 대한 그래디언트가 자동으로 계산됩니다.
**총평**: 이 모델은 다양한 크기의 커널을 가진 1D 컨볼루션 레이어를 통해 텍스트 데이터에서 특징을 추출하고, 추출된 특징을 바탕으로 NLP 작업을 수행할 수 있습니다. Embedding, Convolution, ReLU, MaxPooling 연산을 통해 입력 문장을 고차원 특징 공간으로 변환하며, 이러한 특징은 다운스트림 NLP 작업(분류, 감정 분석 등)에 사용될 수 있습니다.
]
[이 코드는 간단히 말해서 텍스트 데이터를 처리하는 데 사용되는 CNN(합성곱 신경망) 기반의 모델입니다. 여기서는 문장을 어떻게 다루는지에 대해 쉽게 설명해 보겠습니다:
단어 임베딩: 먼저, 모델은 문장을 이루는 각 단어를 벡터로 변환합니다. 이렇게 하면, 각 단어는 숫자의 배열로 표현됩니다. 예를 들어 "고양이는 귀엽다"라는 문장이 있다면, 각 단어 "고양이는", "귀엽다"는 특정 숫자 배열로 변환됩니다.
CNN 레이어: 변환된 단어 벡터들을 CNN 레이어에 통과시킵니다. CNN 레이어는 문장의 특징을 파악하기 위해 여러 크기의 필터(윈도우)를 사용합니다. 이렇게 하면, 문장의 다양한 부분(단어 조합)에서 특징을 추출할 수 있습니다.
풀링 연산: CNN 레이어의 출력을 풀링 연산을 통해 간소화합니다. 이 과정에서 문장의 중요한 정보만을 남기고 나머지는 버립니다.
결과: 마지막으로, 이 모든 과정을 거친 결과는 문장의 의미를 나타내는 벡터로 변환됩니다. 이 벡터는 텍스트를 분류하거나, 감정을 분석하는 데 사용될 수 있습니다.
간단히 말해서, 이 모델은 문장을 숫자의 배열로 변환하고, 이 배열을 CNN을 통해 처리하여 문장의 의미를 파악하는 데 사용됩니다.]
학습과 평가하는 코드
class Classifier(nn.Module):
"""A classifier, arbitary graph, on the top of sentence representation.
Attributes:
sr_model: A sentence representation module.
input_dim: Input dimension of the classifier. Input_dim is set with sr_model output.
output_dim: Output dimension of the model.
"""
def __init__(self, sr_model, output_dim, vocab_size, embed_dim, **kwargs):
"""Initialization of the classifier.
Args:
sr_model (torch.nn.Module): A sentence representation module.
output_dim (int): Output dimension of the model.
vocab_size (int): The size of vocabulary.
embed_dim (int): The word embedding dimension.
"""
super().__init__()
self.sr_model = sr_model(vocab_size=vocab_size,
embed_dim=embed_dim,
**kwargs)
self.input_dim = self.sr_model.output_dim
self.output_dim = output_dim
self.fc = nn.Linear(self.input_dim, self.output_dim)
def forward(self, x):
return self.fc(self.sr_model(x))
model = Classifier(sr_model=SelfAttention,
output_dim=2,
vocab_size=len(vocabs),
embed_dim=16)
# nn.Embedding(vocab_size, embed_dim, padding_idx=0)
# padding_idx를 설정해놓으면,
# padding_idx의 embedding은 0으로 초기화
# padding index의 embedding은 gradient 계산을 하지 않음, 즉 padding embedding은 업데이트 되지 않음
model.sr_model.embeddings.weight[0]
use_cuda = True and torch.cuda.is_available()
if use_cuda:
model.cuda()
import torch.optim as optim
import numpy as np
from copy import deepcopy
optimizer = optim.Adam(params=model.parameters(), lr=0.01)
calc_loss = nn.CrossEntropyLoss()
n_epoch = 5
global_i = 0
valid_loss_history = [] # [(global_i, valid_loss), ...]
train_loss_history = [] # [(global_i, train_loss), ...]
min_valid_loss = 9e+9
best_model = None
best_epoch_i = None
for epoch_i in range(n_epoch):
model.train()
for batch in train_dataloader:
optimizer.zero_grad()
x = torch.tensor(batch['doc_ids'])
y = torch.tensor(batch['label'])
if use_cuda:
x = x.cuda()
y = y.cuda()
y_pred = model(x)
loss = calc_loss(y_pred, y)
if global_i % 1000 == 0:
print(f"global_i: {global_i}, epoch_i: {epoch_i}, loss: {loss.item()}")
train_loss_history.append((global_i, loss.item()))
loss.backward()
optimizer.step()
global_i += 1
# validation
model.eval()
valid_loss_list = []
for batch in valid_dataloader:
x = torch.tensor(batch['doc_ids'])
y = torch.tensor(batch['label'])
if use_cuda:
x = x.cuda()
y = y.cuda()
y_pred = model(x)
loss = calc_loss(y_pred, y)
valid_loss_list.append(loss.item())
valid_loss_mean = np.mean(valid_loss_list)
valid_loss_history.append((global_i, valid_loss_mean.item()))
if valid_loss_mean < min_valid_loss:
min_valid_loss = valid_loss_mean
best_epoch_i = epoch_i
best_model = deepcopy(model)
if epoch_i % 1 == 0:
print("*"*30)
print(f"valid_loss_mean: {valid_loss_mean}")
print("*"*30)
print(f"best_epoch_i: {best_epoch_i}, best_global_i: {global_i}")
# 학습곡선 그리기
def calc_moving_average(arr, win_size=100):
new_arr = []
win = []
for i, val in enumerate(arr):
win.append(val)
if len(win) > win_size:
win.pop(0)
new_arr.append(np.mean(win))
return np.array(new_arr)
valid_loss_history = np.array(valid_loss_history)
train_loss_history = np.array(train_loss_history)
plt.figure(figsize=(12,8))
plt.plot(train_loss_history[:,0],
calc_moving_average(train_loss_history[:,1]), color='blue')
plt.plot(valid_loss_history[:,0],
valid_loss_history[:,1], color='red')
plt.xlabel("step")
plt.ylabel("loss")
#평가
from tqdm.auto import tqdm
model = best_model
model.eval()
total = 0
correct = 0
for batch in tqdm(test_dataloader,
total=len(test_dataloader.dataset)//test_dataloader.batch_size):
x = torch.tensor(batch['doc_ids'])
y = torch.tensor(batch['label'])
if use_cuda:
x = x.cuda()
y = y.cuda()
y_pred = model(x)
curr_correct = y_pred.argmax(dim=1) == y
total += len(curr_correct)
correct += sum(curr_correct)
print(f"test accuracy: {correct/total}")
self-attention
전처리는 또 똑같다.
일단 한글 오류 해결
# Matplotlib 한글 깨짐 해결
# 1. 이 코드 실행
# !sudo apt-get install -y fonts-nanum
# !sudo fc-cache -fv
# !rm ~/.cache/matplotlib -rf
# 2. 런타임 재시작
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
class SelfAttention(nn.Module):
def __init__(self,
vocab_size,
embed_dim):
"""
Args:
vocab_size (int): size of vocabulary.
embed_dim (int): dimension of embedding.
"""
super().__init__()
self.vocab_size = vocab_size
self.embed_dim = embed_dim
self.output_dim = embed_dim
self.embeddings = nn.Embedding(vocab_size, embed_dim, padding_idx=0)
self.q_linear = nn.Linear(embed_dim, embed_dim)
self.k_linear = nn.Linear(embed_dim, embed_dim)
self.v_linear = nn.Linear(embed_dim, embed_dim)
def forward(self, X, return_attention_score=False):
"""Feed-forward Self attention.
Args:
X (torch.Tensor): inputs, shape of (batch_size, seq_len).
Returns:
torch.tensor, Sentence representation.
"""
batch_size, seq_len = X.size()
X = self.embeddings(X) # batch size x seq_len x embed_dim
q, k, v = self.q_linear(X), self.k_linear(X), self.v_linear(X) # batch_size x seq_len x embed_dim
attention_score_raw = q @ k.transpose(-2,-1) / math.sqrt(self.embed_dim) # batch_size x seq_len x seq_len
attention_score = torch.softmax(attention_score_raw, dim=2) # batch_size x seq_len x seq_len
weighted_sum = attention_score @ v # batch_size x seq_len x dim
context = torch.mean(weighted_sum, dim=1) # self attention된 임베딩들을 average
if return_attention_score:
return context, attention_score
return context[이 코드는 자기 주의 메커니즘(Self-Attention)을 사용하여 문장을 표현하는 PyTorch 모델의 클래스 정의입니다. 이 모델은 텍스트 데이터를 처리하는 데 사용되며, 각 단어가 문장 전체에서 어떻게 상호 작용하는지를 학습합니다.
클래스 정의 (SelfAttention):
vocab_size: 어휘 사전의 크기를 나타냅니다. 즉, 모델이 인식할 수 있는 고유한 단어의 수입니다.
embed_dim: 임베딩 벡터의 차원입니다. 각 단어가 임베딩되어 나타내는 벡터의 크기입니다.
q_linear, k_linear, v_linear: 이 세 개의 선형 레이어는 쿼리(query), 키(key), 값(value) 벡터를 생성하기 위해 사용됩니다. 자기 주의 계산에 필요한 세 가지 주요 구성 요소입니다.
forward 메서드:
X: 입력 데이터. batch_size는 한 번에 처리하는 문장의 수, seq_len은 각 문장의 단어 수입니다.
X = self.embeddings(X): 각 단어를 임베딩 벡터로 변환합니다.
q, k, v: 쿼리, 키, 값 벡터를 생성합니다. 이들은 각각 입력 X를 변환한 것입니다.
attention_score_raw: 쿼리와 키의 내적(dot product)을 통해 주의 점수(raw attention scores)를 계산합니다. 이 점수는 각 단어가 다른 단어와 얼마나 연관되어 있는지 나타냅니다.
attention_score: softmax 함수를 적용하여 주의 점수를 정규화합니다. 이렇게 하면 각 단어가 다른 단어와 얼마나 연관되어 있는지를 나타내는 확률 분포가 생성됩니다.
weighted_sum: 주의 점수와 값 벡터의 가중합을 계산하여 문장의 새로운 표현을 생성합니다.
context: 문장의 최종적인 표현을 얻기 위해 가중합 벡터들의 평균을 취합니다. 이 표현은 문장의 모든 단어에 걸쳐 정보를 집약한 것입니다.
자기 주의 메커니즘은 단어 간의 관계를 파악하여 문장의 의미를 더 잘 이해하는 데 도움을 줍니다. 이 모델은 자연어 처리 태스크에서 맥락을 더 잘 파악하고자 할 때 유용합니다.]
[입력 차원과 임베딩:
입력 (X): [batch_size, seq_len] 차원을 가집니다. 예를 들어, 32개의 문장이 있고 각 문장에 단어가 10개씩 있다면, X의 차원은 [32, 10]이 됩니다.
임베딩 후 (X = self.embeddings(X)): 각 단어가 임베딩 벡터로 변환됩니다. 임베딩 차원이 64라면, 새로운 차원은 [32, 10, 64]가 됩니다. 즉, 각 단어는 64차원의 벡터로 표현됩니다.
쿼리(Query), 키(Key), 값(Value) 계산:
q, k, v = self.q_linear(X), self.k_linear(X), self.v_linear(X): 여기서 X는 [32, 10, 64] 차원입니다. 세 개의 선형 변환을 적용하면 쿼리, 키, 값 모두 같은 [32, 10, 64] 차원을 갖게 됩니다.
주의 점수 계산 (Attention Score Calculation):
attention_score_raw = q @ k.transpose(-2,-1) / math.sqrt(self.embed_dim):
k.transpose(-2,-1)는 k를 전치(transpose)하여 [32, 64, 10] 차원으로 만듭니다.
쿼리(q)와 전치된 키(k)의 내적을 계산하면, 결과는 [32, 10, 10] 차원이 됩니다. 이는 각 단어가 문장 내의 다른 모든 단어와 어떻게 연관되어 있는지를 나타내는 점수입니다.
sqrt(self.embed_dim)으로 나누는 것은 값을 정규화하여 계산 안정성을 높이기 위함입니다.
주의 점수 정규화:
attention_score = torch.softmax(attention_score_raw, dim=2):
softmax 함수는 주의 점수를 확률 분포로 변환합니다. 결과적으로 차원은 [32, 10, 10]으로 유지됩니다.
가중합 계산 (Weighted Sum Calculation):
weighted_sum = attention_score @ v:
여기서 v는 [32, 10, 64] 차원이고, attention_score는 [32, 10, 10] 차원입니다.
이 두 행렬의 행렬곱을 계산하면 최종적인 차원은 [32, 10, 64]가 됩니다. 이는 각 단어가 문장 내 다른 단어들과의 관계를 고려한 새로운 표현입니다.
문장의 최종 표현:
context = torch.mean(weighted_sum, dim=1):
여기서 weighted_sum의 차원 [32, 10, 64]에서 평균을 취하여 각 문장의 대표적인 벡터를 얻습니다.
결과적으로 context의 차원은 [32, 64]가 됩니다. 이는 각 문장을 대표하는 64차원 벡터입니다.
이 과정은 각 단어가 문장 내에서 다른 단어와 어떻게 상호작용하는지를 모델링하고, 이를 통해 문장의 의미를 보다 풍부하게 표현할 수 있도록 합니다.]
마지막으로 시각화
sample = df['document'].iloc[14]
print(sample)
tokenizer.use_padding = False
token_ids = tokenizer(sample)
token_ids
token_list = [idx_to_token[token_idx] for token_idx in token_ids]
list(zip(token_list, token_ids))
# Attention score 계산
_, attention_score = model.sr_model(torch.tensor([token_ids]), return_attention_score=True)
attention_score.shape # batch_size, seq, seq
attention_score_np = attention_score.squeeze(0).detach().numpy()
import seaborn as sns
plt.figure(figsize=(12,8))
attn_vis = sns.heatmap(attention_score_np, xticklabels=token_list, yticklabels=token_list)
_ = attn_vis.set_xticklabels(attn_vis.get_xticklabels(), rotation=45)
'인공지능 > 자연어 처리' 카테고리의 다른 글
| 자연어 처리 - Autoregressive language modeling (0) | 2024.02.15 |
|---|---|
| 자연어 처리 - 문장의 그럴듯함을 측정하는 방법 (0) | 2024.02.15 |
| 자연어 처리 - RN 실습 (0) | 2024.02.13 |
| 자연어 처리 - CBOW 실습 (0) | 2024.02.13 |
| 자연어 처리 - self attention으로 문장 표현하기 (0) | 2024.02.06 |