728x90
728x90
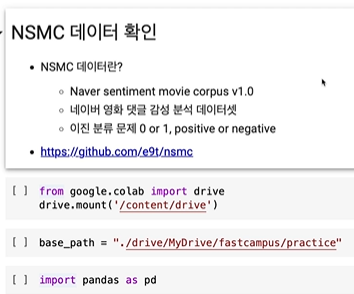
이전까지 이해가 안되었던 부분이기 때문에 실습을 잘 보도록... 하겠습니다...
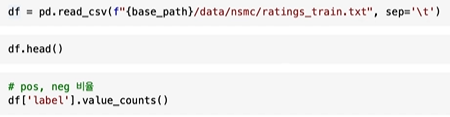
긍정 부정의 비율도 1대 1이었다.
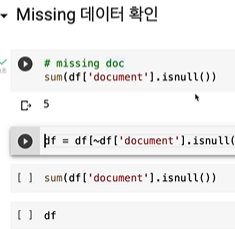
비어있는 5개는 제거했다.

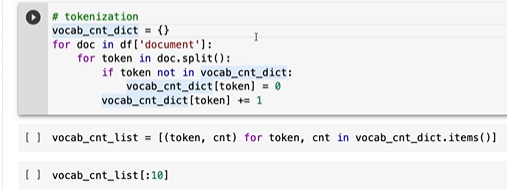
첫번째 줄은 띄어쓰기 기준으로 토큰을 나누는 것이다.
유니크한 토큰들이 약 36만개가 나온다 -> 토큰 임베딩 테이블의 크기가 너무 커진다.
많이 사용되는 단어들을 남김으로 써 중요도를 따질 수 있다.
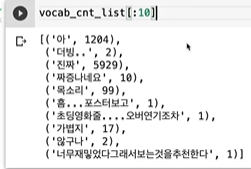

많이 나온 순서대로 정렬한다.
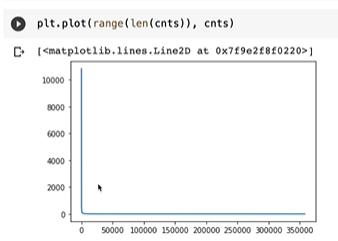

평균적으로 3번 나온다.

3개이상은 42635개이므로 이정도면 판단할 수 있다고 생각할 수 있다.

우리가 30만개의 단어를 무엇인지도 모르게 사용하게 된다. -> UNK
사각형 모향을 맞추기 위한 -> PAD


문장 하나를 받으면 숫자로 바꿔주는 것을 만든다.
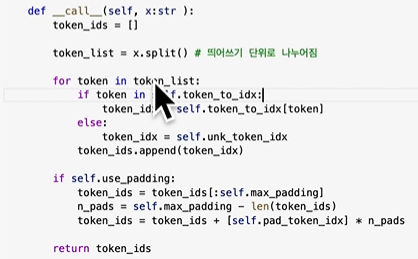
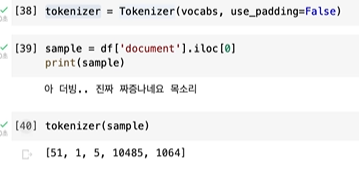
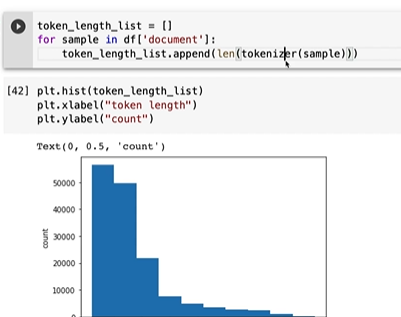
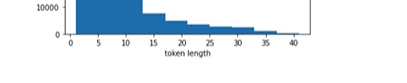

맥스패딩이 50개까지면 충문하다.

그럼 이렇게 된다.
빈 부분은 전부 패딩으로 0이 되게 된다.
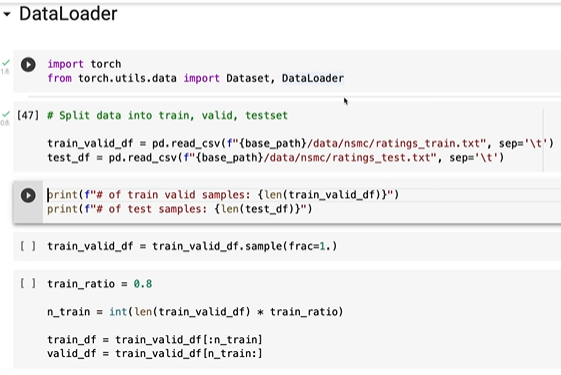
TRAIN과 VALIDATION을 0.8 대 0.2로 나눈다.
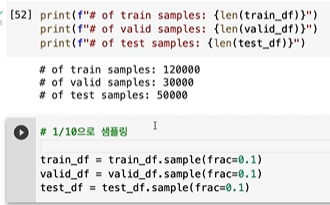
일단 너무 많기 때문에 10프로로 줄인다.
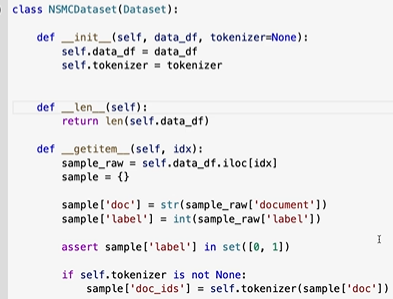







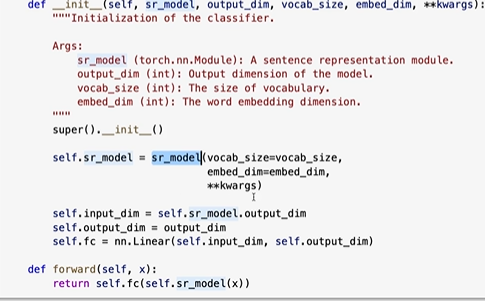
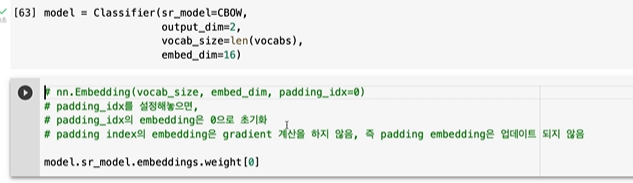



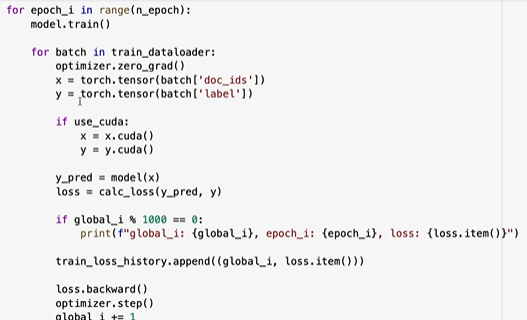
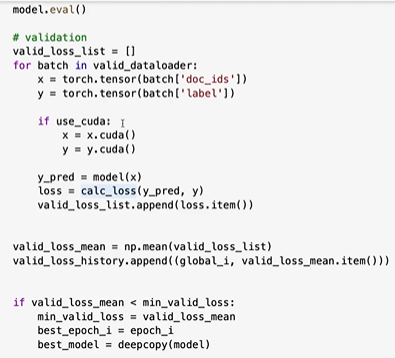
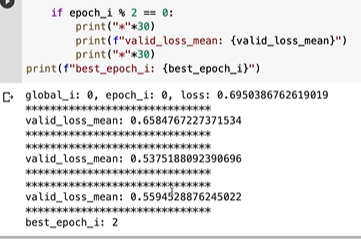



제대로 확인하려면 좀 더 에폭이 컸어야 했다.

에폭을 늘리니 VALIDATION이 오히려 늘었다.
728x90
'인공지능 > 자연어 처리' 카테고리의 다른 글
| 자연어 처리 -CNN을 사용한 실습, self- attention 실습 (1) | 2024.02.15 |
|---|---|
| 자연어 처리 - RN 실습 (0) | 2024.02.13 |
| 자연어 처리 - self attention으로 문장 표현하기 (0) | 2024.02.06 |
| 자연어 처리 - CNN, RNN으로 문장 표현하기 (0) | 2024.02.06 |
| 자연어 처리 - RN로 문장 표현하기 (0) | 2024.02.05 |