728x90
728x90

아스키 코드로 바꾸면 안되나?

tokenization - 형태소 단위로 쪼갠다.
한글에선 띄어쓰기(공백)로 나누면 단어 단위라고 할 수 없다.

그럼 index가 엄청나게 많겠네...?
문장 => 숫자의 나열로 변환

token은 순서가 없다.

문장은 어떻게 표현할까? => 행렬형식으로 ?

이건 순서가 뭉게진다...


이러면 경우의 수가 어마무시하게 늘어날 것 같은데....?

라면 좋아 좋아 라면 싫어 알로에는 또 토큰 만들어서...?

말뭉치 = 텍스트들의 뭉치를 토큰화해서 두개씩 뭉쳐서 등록

조사의 숫자가 커서 중요해보인다. => 중요도를 고려한 표현!

중요도를 고려해 문장을 표현하는 방식!

천천히 보면 쉬운 수식이다. 중요한 토큰일 수록 높은 값을 가진다.
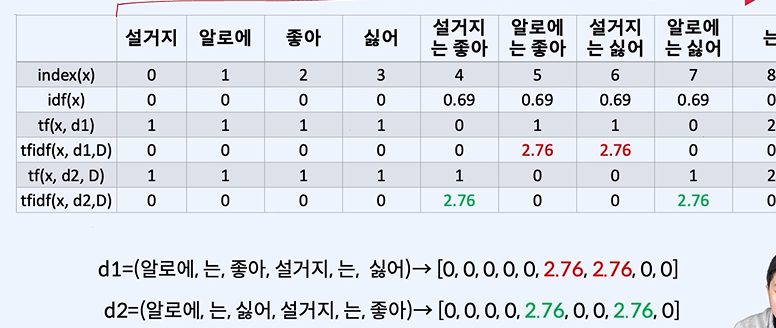
중요한 벡터만 남게 된다.

728x90
'인공지능 > 자연어 처리' 카테고리의 다른 글
| 자연어 처리 - RN로 문장 표현하기 (0) | 2024.02.05 |
|---|---|
| 자연어 처리 - CBOW으로 문장 표현하기 (1) | 2024.01.30 |
| 자연어 처리 - NN을 이용한 classification, regression 실습 (1) | 2024.01.25 |
| 자연어 처리 - Multi task learning (0) | 2024.01.25 |
| 자연어 처리 - Transformer (1) | 2024.01.21 |