https://arxiv.org/abs/2510.23274
Privacy-Preserving Semantic Communication over Wiretap Channels with Learnable Differential Privacy
While semantic communication (SemCom) improves transmission efficiency by focusing on task-relevant information, it also raises critical privacy concerns. Many existing secure SemCom approaches rely on restrictive or impractical assumptions, such as favora
arxiv.org
Privacy-Preserving Semantic Communication over Wiretap Channels with Learnable Differential Privacy
vision 쪽입니다.
이 쪽은 자세히 모르겠어서 요약 표 정도만...
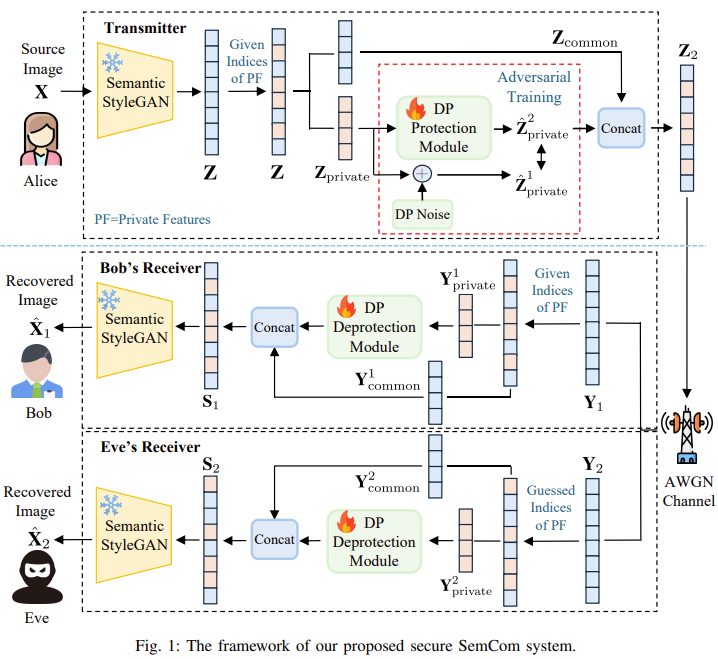
Bob - 합법 수신자 = 정보를 정상적으로 복원해야 한다. == 품질을 최대한 높게 유지하는 것
Eve - 공격자 = 통신 채널에 접속해 복원하려고 시도 == 복원하지 못하도록 해야 함
Alice - 메세지 보내는 사람

| 문제 상황 | • SemCom은 “중요한 의미 정보(semantic)”만 압축해 보내는데, 얼굴 같은 경우 신원정보(ID)가 가장 중요한 semantic이라 자연스럽게 그대로 전송됨. • 채널 상황이 Bob과 Eve에게 거의 동일(SNR≈SNR)한 경우, Eve도 거의 같은 품질로 얼굴을 복원할 수 있음 → 심각한 프라이버시 침해. • 기존 보안 방식 문제점: – 암호화: 연산·지연 많아서 SemCom의 장점과 충돌 – 물리 계층 보안: “Bob 채널이 더 좋다”는 비현실적 가정 필요 – Adversarial 보안: Eve 모델 구조를 안다는 강한 가정 요구 – 전통적 DP: noise가 비가역적이라 Bob도 복원 품질이 심하게 저하됨 |
| 핵심 아이디어(방법론) | 1) 얼굴을 의미 단위 latent로 분해 (GAN inversion + Semantic StyleGAN) • 얼굴 latent를 “신원 관련 부분(Z_private)”과 “덜 민감한 부분(Z_common)”으로 분리 2) Z_private에만 ‘Learnable DP Noise’ 삽입 • 진짜 Laplace DP 노이즈는 참고용(target)으로만 사용 • Protection Module이 DP 노이즈처럼 보이지만 Bob이 지울 수 있는 패턴을 학습 • Adversarial training으로 “진짜 DP 분포와 구분되지 않게” 만듦 3) Bob만 Deprotection Module로 노이즈 제거 • Bob은 어떤 latent가 private인지 알고 있음(아주 작은 사전 공유 정보) • Eve는 이 위치를 모르거나 잘못된 위치로 복원해 얼굴 형태가 깨짐 4) Privacy 수준(ε) 조절 가능 • ε↓ → 강한 보호(엄청난 노이즈) / ε↑ → 약한 보호(높은 품질) • 시스템이 사용자 선택에 따라 보안–품질 트레이드오프를 조절 |
| 실험 설정 | • 데이터: CelebAMask-HQ (얼굴 이미지 30k) • 모델: Pretrained Semantic StyleGAN (generator+inverter 겸용) • latent 차원: 28 × 512, 그중 일부를 private로 설정 • 채널 조건: AWGN wiretap, Bob=SNR=Eve (가장 어려운 조건) • 평가 지표: – LPIPS: 시각적 유사도 (낮을수록 원본과 유사) – FPPSR: “얼굴이 다른 사람으로 보이는 비율” (Eve는 높을수록 좋음) • 비교 baseline: – 아무 보호 없음 (Direct SemCom) – 전통적 DP (latent에 실제 Laplace DP 노이즈 추가) |
| 결과 (정량/정성) | 1) Bob은 거의 원본 수준 품질 유지 • ε ≥ 200에서 LPIPS ≈ 무보호 전송과 거의 동일 • 얼굴 ID 보존율도 거의 유지됨 2) Eve는 ID 복원 거의 불가능 • 모든 ε, 모든 SNR에서 Eve의 FPPSR ≈ 0.9~1.0 (거의 항상 “다른 사람”으로 보임) • 시각적 결과: 얼굴 형태 왜곡, ID 불일치, 혹은 의미만 남고 다른 사람 얼굴 생성 3) 전통적 DP 대비 개선 • 같은 ε 기준 Bob 품질이 훨씬 더 좋고(Eve와 격차 증가) • 수치는 Bob 기준 LPIPS 약 0.06–0.29 향상, FPPSR 0.10–0.86 감소 (→ ID 정확히 복원됨) |
| 기여 요약 | ✔ SemCom에서 실제 적용 가능한 “역복원 가능한” DP 기반 보안 구조 제안 ✔ latent 공간에서 “필요한 부분만 selective 보호” (ID 관련된 잠복 벡터만 노이즈) ✔ 정량적으로 조절 가능한 privacy budget ε 도입 (세기 조절 가능) ✔ adversarial training 사용해 DP와 유사하지만 invertible한 노이즈를 학습 ✔ Eve가 구조·보호 존재를 알아도 복원이 어려운 stronger threat model까지 검증 |
| 한계 | • ε가 매우 작을 때(강한 보호) 시각적으로 너무 noisy해서 “자연스럽지만 다른 사람처럼 보이는 얼굴 생성”은 아직 미흡 • 얼굴 이미지 + StyleGAN에만 특화 → 일반 이미지, 텍스트, 멀티모달 SemCom으로 확장 필요 • semantic jamming(악의적으로 의미를 깨뜨리는 공격)에 대한 방어는 고려하지 않음 • 민감한 latent index를 Bob과 사전 공유해야 하는 최소한의 부하 존재 |
| 핵심 한줄 | “프라이버시 민감한 의미 정보(latent 일부)에만 learnable DP 노이즈를 넣고 Bob만 복원할 수 있도록 해, Bob은 고품질로 유지하면서 Eve는 신원 정보를 절대 알아볼 수 없게 하는 새로운 SemCom 보안 구조” |
이 논문 내용부터 정리해볼게.
1. 한 줄 요약
Semantic StyleGAN 기반의 얼굴 SemCom 시스템에서 잠복 표현(latent code)의 “프라이버시 민감 부분”만 선택적으로 DP 노이즈(패턴을 학습한 노이즈)로 보호하고, 합법 수신자만 이 노이즈 패턴을 제거하도록 학습함으로써, Bob은 고품질 복원을 유지하면서 Eve는 얼굴을 거의 알아볼 수 없게 만드는 DP 기반 보안 SemCom 프레임워크.
2. 문제 설정 (Problem)
2.1 배경
- SemCom은 비트 정확도 대신 과제 관련 의미(semantic)만 전송하여 효율을 올리지만,
- 채널 부호/중복을 줄이고,
- semantic 상 중요한 정보(예: 얼굴 ID, 프라이버시 정보)를 그대로 보내기 때문에
→ 도청자(Eve)에게 더 취약해지는 역설적인 상황이 생김.
- 기존 보안 SemCom 접근의 한계:
- Adversarial training 기반: Eve 모델 구조/파라미터를 알고 있다는 비현실적 가정, 명시적 security level 제어 어려움.
- 암호화 기반: 키 관리/계산량이 커서 SemCom의 “가벼움·저지연”과 상충.
- 물리계층 기반(인공 잡음, jamming): 보통 Bob 채널 우위, shared knowledge 등 강한 가정 + 정량적/가시적인 privacy level 제어가 어려움.
2.2 이 논문이 다루는 핵심 문제
- Wiretap 채널에서 Bob과 Eve의 SNR이 거의 같은 “가장 어려운” 상황(Comparable-SNR) 가정.
- 어떤 키 교환 없이,
- 프라이버시 민감한 semantic 정보만 선택적으로 보호하고,
- DP(Differential Privacy)를 이용해 privacy level(ε)을 명시적으로 조절 가능하면서도,
- Bob은 이미지 품질과 얼굴 ID 유지를 극대화하고, Eve는 얼굴 ID를 재구성하지 못하게 만드는 SemCom 시스템 설계.
3. 방법론: Step-by-step
3.1 전체 시스템 구조 (Fig.1 기반)
엔티티:
- Alice(송신자), Bob(합법 수신자), Eve(도청자).
- 전송 대상: 얼굴 이미지 (X) (예: CelebAMask-HQ 얼굴).
전송 파이프라인:
- Semantic StyleGAN 기반 GAN inversion으로 입력 얼굴 (X)를 잠복 표현 Z로 인코딩
[
Z = f_{\text{inv}}(X)
]- Z는 여러 개의 disentangled latent code로 구성 (얼굴의 각 부분/속성: 눈, 코, 입, 텍스처 등).
- Z를 두 부분으로 분리:
- Z_private: 프라이버시 민감한 latent (identity 관련 공유 코드 + 특정 로컬 코드들).
- Z_common: 상대적으로 민감하지 않은 latent.
[
Z = [Z_{\text{private}}, Z_{\text{common}}]
]
- NN-based DP Protection Module으로 Z_private만 보호:
- 보호 후 잠복 표현:
[
\hat{Z}{2,\text{private}} = f{\text{protection}}(Z_{\text{private}}; \theta_{\text{prot}})
] - 전송용 전체 semantic:
[
Z_2 = [\hat{Z}{2,\text{private}}, Z{\text{common}}]
]
- 보호 후 잠복 표현:
- 전송:
- 전력 제약 P에 맞게 정규화 후, 실수 2개씩 묶어 복소 벡터 ( \tilde{Z}_2 ) 생성.
- AWGN wiretap 채널:
[
Y_1 = \tilde{Z}_2 + n_1,\quad Y_2 = \tilde{Z}_2 + n_2
]- SNR_leg = SNR_eve (가장 어려운 비교 조건).
- Bob 측:
- Bob은 어떤 latent index가 private인지 미리 알고 있음 (사전에 한 번 공유, 키 교환 X).
- 수신 벡터 (Y_1)를 다시 실수 latent로 복원 후,
- Y₁_private, Y₁_common으로 분할.
- Y₁_private → DP Deprotection Module:
[
\hat{Y}{1,\text{private}} = f{\text{deprot}}(Y_{1,\text{private}}; \theta_{\text{deprot}}^1)
] - 합치기: ( S_1 = [\hat{Y}{1,\text{private}}, Y{1,\text{common}}] )
- Semantic StyleGAN generator (f_{\text{gen}})으로 얼굴 복원:
[
\hat{X}1 = f{\text{gen}}(S_1)
]
- Eve 측 (두 시나리오):
- Basic Eve: 보호가 있는지 모름 → (Y_2) 전체를 바로 (f_{\text{gen}})에 넣어 복원:
[
\hat{X}2 = f{\text{gen}}(Y_2)
] - Stronger Eve:
- 보호가 있다는 사실과 deprotection 네트워크 아키텍처는 알고 있지만,
- 어떤 index가 private인지 모름,
- Bob의 deprotection 파라미터는 모름.
- 임의로 private index를 추측해 Y₂_private, Y₂_common으로 나눈 뒤,
[
\hat{Y}{2,\text{private}} = g{\text{deprot}}(Y_{2,\text{private}}; \theta_{\text{deprot}}^2)
]
[
S_2 = [\hat{Y}{2,\text{private}}, Y{2,\text{common}}]
]
[
\hat{X}2 = f{\text{gen}}(S_2)
]
- 보호가 있다는 사실과 deprotection 네트워크 아키텍처는 알고 있지만,
- Basic Eve: 보호가 있는지 모름 → (Y_2) 전체를 바로 (f_{\text{gen}})에 넣어 복원:
3.2 Semantic StyleGAN 기반 인코더/디코더 (Fig.2)
- Semantic StyleGAN[37]을 encoder/decoder 모두로 사용:
- Forward (generator): shared 코드 (C_{\text{base}}) + H개의 local 코드 (C_1,…,C_H)를 받아,
- 각 local generator가 semantic 영역별 feature map & pseudo-depth map 생성,
- depth map → coarse segmentation mask m,
- 모든 feature map을 mask로 fuse → aggregated feature fm,
- render network로 최종 이미지 (\hat{X}) 출력.
- Reverse (GAN inversion):
- 주어진 X에 대해 latent Z를 최적화:
[
\min_Z \text{MSE}(X, f_{\text{gen}}(Z))
] - 고정된 횟수의 gradient descent로 수행.
- 주어진 X에 대해 latent Z를 최적화:
- Forward (generator): shared 코드 (C_{\text{base}}) + H개의 local 코드 (C_1,…,C_H)를 받아,
→ 즉, 한 개의 bidirectional StyleGAN으로 의미 disentanglement + 복원을 동시에 수행.
3.3 NN-based DP Protection / Deprotection
3.3.1 Genuine DP 노이즈 & 중간 변수 ( \hat{Z}_{1,\text{private}} )
- 정통 DP 메커니즘:
- Laplace 메커니즘 사용:
[
n_{\text{dp}} \sim \text{Lap}\Big(0,\frac{\Delta f}{\epsilon}\Big)
] - private latent에 직접 적용하면 비가역성(Non-invertibility) 때문에 Bob도 심각하게 열화됨.
- Laplace 메커니즘 사용:
- 이 논문에서는 이를 “지도 신호”로만 사용:
- 중간 latent:
[
\hat{Z}{1,\text{private}} = Z{\text{private}} + n_{\text{dp}}
] - 이는 학습 시에만 사용되는 target style이고 전송되지는 않음.
- 중간 latent:
3.3.2 Adversarial Training (Fig.3)
- DP Protection Module G(·) vs Discriminator D(·):
- D: “이 latent가 genuine DP 노이즈가 더해진 것((\hat{Z}{1,\text{private}}))인지, G가 만든 것((\hat{Z}{2,\text{private}}))인지” 이진 분류.
- G: 자신의 출력((\hat{Z}_{2,\text{private}}))이 통계적으로 genuine DP 노이즈 결과와 구분되지 않도록 학습.
- Loss:
- Discriminator:
[
L_D = -\mathbb{E}[\log D(\hat{Z}_1)] - \mathbb{E}[\log(1 - D(\hat{Z}_2))]
] - Generator(Protection module):
[
L_G = \mathbb{E}[\log(1 - D(\hat{Z}_2))]
]
- Discriminator:
3.3.3 Network 구조 (Fig.4)
- Protection / Deprotection 모듈 모두 동일한 아주 단순한 구조:
- 입력: (Z_{\text{private}} \in \mathbb{R}^{m \times 512})
- Vectorization: (\mathbb{R}^{512m})
- Fully-connected layer 1개
- 다시 (\mathbb{R}^{m \times 512})로 reshape
- Bob/Eve deprotection도 같은 구조를 사용하되 파라미터만 다름.
3.4 Sensitivity (\Delta f) 계산 (DP 스케일링)
- 여기서 sensitivity는 “Semantic StyleGAN inversion 후 latent space에서 서로 다른 두 이미지 간 최대 L2 거리”로 정의:
[
\Delta f = \sup_{I_1, I_2 \in \mathcal{D}} |f_{\text{inv}}(I_1) - f_{\text{inv}}(I_2)|_2
] - 모든 이미지쌍을 다 보는 것은 cost 크고, outlier 문제 있음 → clipping 기반 근사:
- 전체 데이터 latent element들에 대해 0.5% quantile a, 99.5% quantile b 계산.
- [a,b] 밖은 a 또는 b로 잘라냄.
- 한 이미지 latent의 element 수가 n이라면:
[
\Delta f = \sqrt{(b-a)^2 \cdot n}
]
- 실험에서 (\Delta f = 351.88)로 사용.
3.5 Training Strategy
3.5.1 Basic Eavesdropper 세팅
- 학습 대상:
- Legitimate network: DP protection + Bob deprotection module.
- Discriminator.
- 손실:
- Discriminator: 위의 (L_D).
- Legitimate network:
[
L^{(2)} = \text{MSE}(Z, S_1) + \lambda \cdot \mathbb{E}[\log(1 - D(\hat{Z}_2))]
]- 첫 항: Bob이 재구성한 latent (S_1)가 원래 Z와 가까워지도록 (복원 품질).
- 둘째 항: protection이 genuine DP 노이즈와 분포상 유사하도록 (privacy).
- (\lambda = 10^{-3}).
3.5.2 Stronger Eavesdropper 세팅
- Eve가 보호 존재 + deprotection 구조는 알지만 index/파라미터는 모른다고 가정.
- Training을 두 단계로 나눔:
- 1단계: Basic eavesdropper 세팅과 동일하게 legitimate network + D 학습.
- 2단계: Legitimate network 고정, Eve의 deprotection만 학습:
[
L = \text{MSE}(Z, S_2)
]
- 즉, 실제 공격자처럼 사후적으로 Eve가 최선의 복원기를 학습하는 상황을 시뮬레이션.
4. 실험 설정
4.1 데이터 & 모델
- 데이터: CelebAMask-HQ, 30,000 얼굴 이미지.
- 28,000 train / 2,000 test.
- 1024×1024 원본 → 512×512로 리사이즈.
- Pre-trained Semantic StyleGAN[37] 사용, inversion 및 생성 모두 동일 네트워크.
4.2 Latent 구조 & private 코드
- 각 이미지 latent dimension: 28 × 512
- 첫 2개 latent: shared 코드 (C_{\text{base}}) (얼굴 전체 구조).
- 나머지 26개는 shape + texture local codes → H = (28-2)/2 = 13 그룹.
- Basic Eve 실험:
- Private latent: shared 두 개 + 4~7번째 코드.
- Stronger Eve 실험:
- Bob: shared + 4~13번째 latent를 private로 보호.
- Eve: shared + 6~7번째를 private라 “추측”. 오차가 Eve 성능에 불리하게 작용.
4.3 Privacy Budget & 채널 SNR
- Privacy budget (\epsilon \in {1,5,10,30,100,200,300,500,800,2000}).
- 채널 SNR: {0, 5, 10, 15, 20} dB, Bob/Eve 동일 SNR.
4.4 Baselines
- Direct Transmission without Protection:
- Z를 그대로 채널로 보내고 Bob/Eve 모두 StyleGAN으로 복원.
- Bob/Eve 성능이 동일 → privacy 전혀 없음.
- Traditional DP Protection[31]:
- private latent에 그대로 Laplace DP 노이즈를 더함.
- 수신 측에서 독립적인 NN으로 노이즈 제거를 시도.
- genuine DP 보장은 있지만 비가역성 때문에 Bob 성능도 크게 열화되는 것이 단점.
5. 평가 지표
- LPIPS (Learned Perceptual Image Patch Similarity) – AlexNet 기반:
- 낮을수록 원본과 시각적으로 유사.
- Bob: 낮을수록 좋음 (품질).
- Eve: 높을수록 좋음 (보안).
- FPPSR (Face Privacy Protection Success Rate):
- ArcFace 인식 시스템을 사용해 두 얼굴이 “같은 사람”인지 확인.
- score < 0.31이면 “다른 사람”으로 간주.
- FPPSR = “원본과 다른 사람으로 인식된 복원 얼굴 비율”.
- Bob: FPPSR 낮을수록 좋음 (ID 유지).
- Eve: FPPSR 높을수록 좋음 (ID 보호).
6. 주요 실험 결과
6.1 Basic Eavesdropper – ε 변화 (SNR=20dB)
- LPIPS (Fig.5):
- Direct (no protection) 기준 LPIPS ≈ 0.112.
- Bob:
- ε=1에서 0.120 → ε ≥ 200에서 0.113으로 거의 baseline 수준.
- Eve:
- ε=1에서 0.386 (심각한 왜곡),
- ε=2000에서도 약 0.230으로 여전히 Bob보다 훨씬 큼.
- FPPSR (Fig.6):
- Bob: 0.140(ε=1) → 0.112(ε=2000) ≈ baseline 0.088에 근접.
- Eve: ε 전 구간에서 1.0 → 0.96 정도로 매우 높음
⇒ Eve가 복원한 얼굴은 거의 항상 “다른 사람”으로 인식.
- 시각적 분석 (Fig.9, 10):
- Bob: ε가 작아도 semantic 일관성이 높고, ε ≥ 100에서 원본과 거의 동일.
- Eve: ε가 작을 때는 완전히 붕괴된 노이즈 이미지, ε가 커져도 원본과 다른 ID의 얼굴로 보임.
6.2 Basic Eavesdropper – SNR 변화 (ε=100)
- LPIPS (Fig.7):
- Bob: 모든 SNR에서 Direct baseline과 거의 동일, SNR↑ → LPIPS↓.
- Eve: 모든 SNR에서 Bob보다 훨씬 높은 LPIPS 유지.
- FPPSR (Fig.8):
- Bob: SNR↑ → FPPSR baseline 수준으로 감소.
- Eve: 모든 SNR에서 FPPSR=1.0
⇒ Eve는 채널이 좋아져도 ID를 알아낼 수 없음.
6.3 Stronger Eavesdropper – ε 변화 (SNR=20dB)
- Eve가 보호 존재와 deprotection 구조를 알고, 자신의 deprotection을 학습한 경우(Fig.11, 12):
- LPIPS:
- Bob: 0.127(ε=1) → 0.114(ε=2000), baseline(0.112)에 매우 근접.
- Eve: 0.334(ε=1) → 0.197(ε=2000)
→ 여전히 Bob보다 상당히 높음 (perceptual 차이 큼).
- FPPSR:
- Bob: 0.310→0.180, baseline 0.088에 접근.
- Eve: 1.0→0.84 여전히 매우 높음 ⇒ ID 보호 유지.
6.4 Stronger Eavesdropper – SNR 변화 (ε=100)
- LPIPS (Fig.13):
- Bob: 0dB에서 0.196 → 20dB에서 0.121.
- Eve: 0dB에서 0.278 → 20dB에서 0.210 – 항상 Bob보다 훨씬 큼.
- FPPSR (Fig.14):
- Bob: 0.802 → 0.239 (SNR ↑).
- Eve: 0.999 → 0.862, 계속 매우 높음.
6.5 Traditional DP vs Proposed (Basic Eve, SNR=20dB)
- Traditional DP Protection[31]과 비교 (Fig.15, 16):
- Traditional DP의 문제:
- genuine DP Laplace 노이즈를 직접 latent에 더해버려서,
- Bob의 de-noising NN도 노이즈를 제대로 되돌리기 어렵고,
- low ε에서는 Bob/Eve 모두 성능 나쁨,
- high ε에서는 Eve도 좋은 성능 → privacy도 무너짐.
- 제안 방법:
- learnable pattern DP를 사용하여,
- Bob: 항상 Traditional DP보다 LPIPS/FPPSR 측면에서 더 좋은 품질,
- Eve: 동일 ε에서 더 높은 LPIPS, 더 높은 FPPSR로 privacy 더 강함.
- 논문 요약 수치: 동일 보안 수준에서 기존 DP 대비
- Bob 기준 LPIPS 0.06–0.29 개선,
- FPPSR 0.10–0.86 개선.
- learnable pattern DP를 사용하여,
7. 이 논문의 핵심 기여
- Comparable-SNR wiretap SemCom에서의 DP 기반 보안 프레임워크 제안
- Bob/Eve 채널 품질이 비슷한 가장 어려운 상황에서,
- 키 교환 없이 사전 공유된 “private latent index”만으로 fine-grained 보호.
- GAN inversion 기반 “부분 latent 보호”
- Semantic StyleGAN으로 얼굴 이미지를 disentangled latent로 분해하고,
- ID 관련 코드들만 선택적 보호 → 불필요한 정보는 손대지 않아 품질 유지.
- Learnable DP Noise + NN-based deprotection
- Genuine DP Laplace 노이즈를 “지도 분포”로 사용하고,
- Adversarial training으로 DP와 분포는 비슷하지만 Bob이 invert 가능한 노이즈 패턴을 학습.
- privacy budget ε에 따라 노이즈 강도를 조정 → 명시적 privacy-utility trade-off 제어.
- Basic/Stronger Eve 두 환경에서의 평가
- Eve가 구조/보호 여부를 아는 강한 위협 모델에서도,
- Bob과 Eve 사이에 안정적인 성능 격차 확보.
- 기존 DP 기반 방법 대비 우월한 성능
- 기존 latent-space DP보다 **Bob 품질↑, Eve 보안↑**를 동시에 달성.
8. 한계 및 향후 연구 방향
논문에서 명시한 한계/미래 과제:
- 저 ε에서의 시각적 자연성
- 지금 접근은 ε가 아주 작을 때 Eve 이미지는 완전히 붕괴된 “노이즈”에 가까움.
- 향후에는 **“자연스럽지만 가짜인 얼굴”**을 생성해 더 교묘한 미스리딩(misleading)을 유도하는 방향 제안.
- Semantic Jamming 대응 미비
- 현재는 eavesdropping에 초점, **semantic jamming(공격자가 의미를 망가뜨리는 노이즈를 넣는 공격)**에 대한 방어는 미고려.
- 향후 anti-jamming 전략 결합으로 SemCom의 robustness 강화 필요.
- 얼굴 이미지(Semantic StyleGAN) 특화
- CelebAMask-HQ + 얼굴용 StyleGAN에 최적화된 구조라,
- 텍스트, 일반 이미지, 멀티모달 환경으로의 확장성이 과제로 남음.
9. 한눈에 보는 요약 표
항목 내용| 문제 설정 | Wiretap 채널에서 Bob/Eve SNR이 비슷한 상황에서 얼굴 ID 등 프라이버시 정보만 선택적으로 보호하면서 SemCom 품질을 유지하는 방법 설계 |
| 데이터/모델 | CelebAMask-HQ (30k 얼굴, 512×512), Semantic StyleGAN(bidirectional) + Simple FC Protection/Deprotection 모듈 |
| 표현 방식 | GAN inversion으로 28×512 latent 추출 → shared(2개) + local(shape/texture, 26개)로 분해, 일부 index를 private latent로 지정 |
| 보안 메커니즘 | private latent에만 learnable DP 노이즈 추가 (Laplace(Δf/ε)를 지도 신호로 사용하는 adversarial training), Bob만 해당 패턴을 제거하는 deprotection 학습 |
| DP 설정 | Sensitivity Δf≈351.88, ε∈{1,…,2000}; clipping(0.5–99.5%)으로 Δf 근사, ε로 노이즈 강도를 제어 |
| 채널 모델 | 복소 AWGN wiretap 채널, SNR={0,5,10,15,20}dB, Bob/Eve 동일 SNR (가장 어려운 조건) |
| 평가 지표 | LPIPS (시각적 유사도, 낮을수록 좋음), FPPSR (얼굴 ID 보호 성공률, Bob↓ Eve↑가 이상적) |
| Baselines | (1) Direct Transmission w/o protection (SemCom만, 보안 없음) (2) Traditional DP Protection: latent에 직접 Laplace DP 노이즈 + de-noising NN |
| 주요 결과 – Basic Eve | ε↑ 시 Bob LPIPS/FPPSR은 Direct에 근접, Eve는 모든 ε에서 LPIPS≫Bob, FPPSR≈1로 ID 복원 실패. SNR↑에도 Eve는 여전히 ID 인식 실패 |
| 주요 결과 – Stronger Eve | Eve가 보호 존재를 알고 deprotection을 학습해도, Bob과 Eve 사이에 LPIPS/FPPSR 격차 유지 → 비교적 강한 위협 모델에서도 privacy 확보 |
| 기존 DP 대비 장점 | 같은 ε에서 Bob 기준 LPIPS 0.06–0.29 개선, FPPSR 0.10–0.86 개선. Traditional DP는 low ε에서 Bob도 망가지고 high ε에서 Eve도 복원 잘하는 문제가 있음 |
| 핵심 기여 | (1) GAN inversion 기반 fine-grained latent 보호 (2) learnable DP 노이즈 패턴 + NN deprotection (3) ε로 보안 레벨 명시적 제어 (4) stronger Eve 환경까지 실험 |
| 한계/미래 연구 | (1) 낮은 ε에서 자연스러운 “가짜 얼굴” 생성으로 더욱 정교한 mislead (2) semantic jamming에 대한 robust anti-jamming 전략 결합 (3) 얼굴 외 multimodal/일반 이미지 SemCom으로 확장 필요 |
혹시 다음 단계로,
- 네가 관심 있는 워터마킹/프라이버시 연구 방향과 어떻게 연결할 수 있을지,
- 또는 이 구조를 텍스트 SemCom/LLM latent space에 이식하는 아이디어도 정리해볼까?
https://aclanthology.org/2024.acl-long.230/
Transferable Embedding Inversion Attack: Uncovering Privacy Risks in Text Embeddings without Model Queries
Yu-Hsiang Huang, Yuche Tsai, Hsiang Hsiao, Hong-Yi Lin, Shou-De Lin. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024.
aclanthology.org
Transferable Embedding Inversion Attack: Uncovering Privacy Risks in Text Embeddings without Model Queries
기존 연구는 Embedding 모델을 가지고 있을 때 그 embedding으로부터 원문을 복구해낸다.
그러나 이 논문에서는 embedding 모델이 없고, embedding 벡터의 일부와 텍스트 원문 일부만을 우연히 획득한 상황을 가정한다.
즉 벡터 DB 유출 상황을 가정

유출된 Text, Embedding 쌍 DL만으로 Encoder를 모방하는 Surrogate encoder를 만든다.
처음에는 MSE를 통해 모방하도록 한다.
코사인 유사도 또한 비슷하도록 진행한다. = 공간 정보도 유사하게 만들어준다.
판별기를 통해 만들어진 임베딩인지, 진짜 임베딩인지도 학습을 진행한다.
그 후 임베딩으로 문장 생성하는 학습도 진행
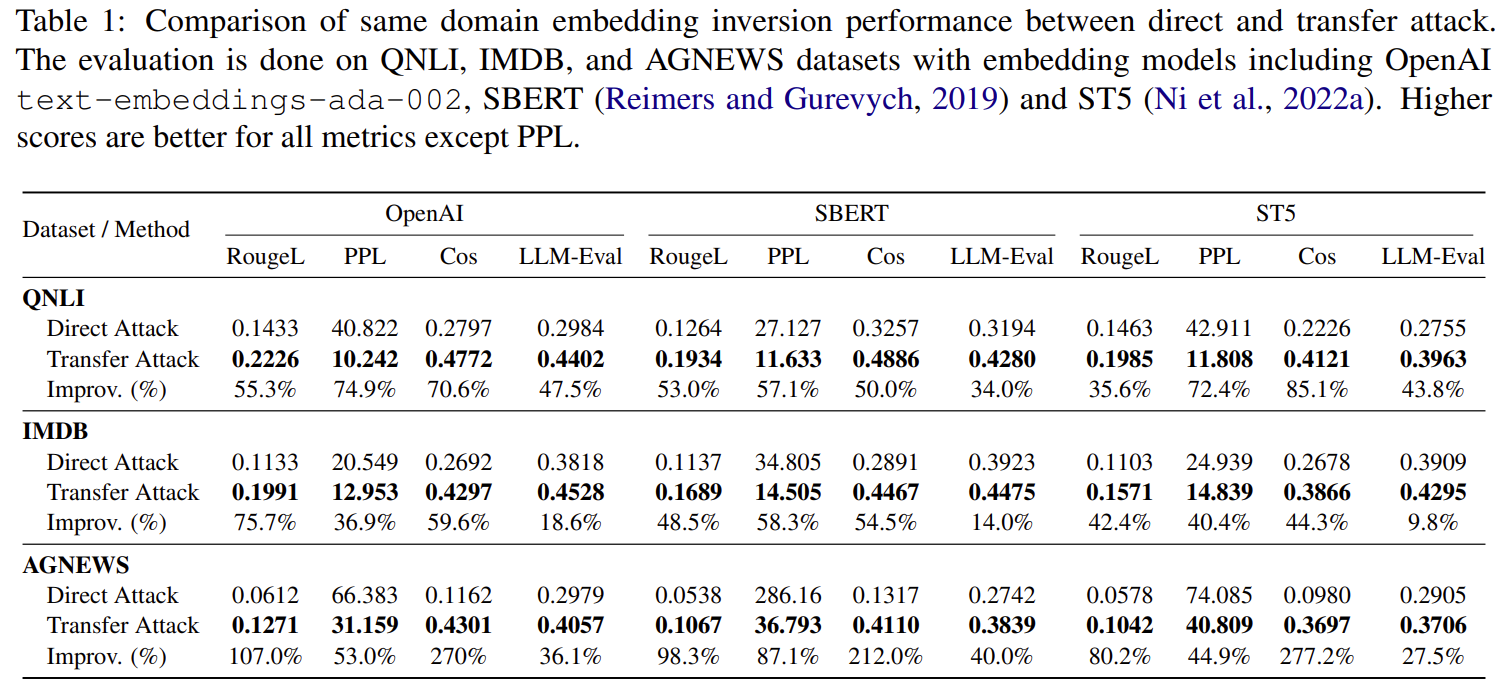
기존 방법에 비해 뛰어난 복구율을 보여준다.
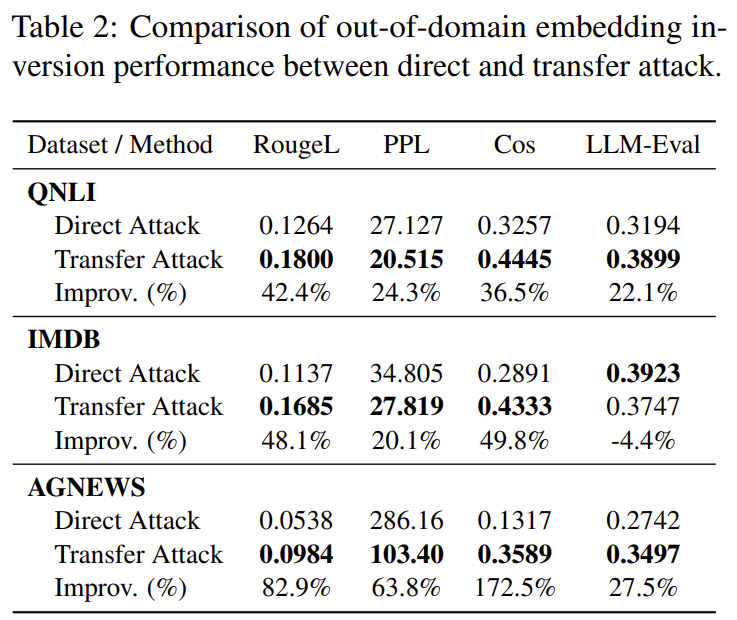
20k 정도면 할만하다는 건데....


복구가 잘 된 것을 볼 수 있다.
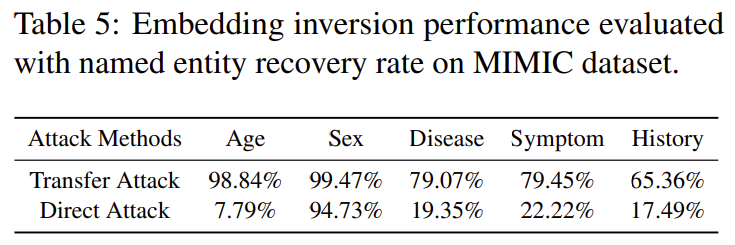
embedding 하나만으로도 환자의 나이 성별 질병 증상 과거 이력이 모두 복원됨
이 논문이 좀 중요할 듯
| 문제 상황 | - RAG/Vector DB 시스템은 텍스트를 embedding 형태로 저장하며 “embedding만으론 원문 복원이 불가능하다”고 가정함 - 기존 embedding inversion 연구는 모델 쿼리 가능, 또는 모델 구조 일부 접근 가능이라는 비현실적 조건 필요 - 실제 유출 사고는 embedding만 노출되고, 모델은 완전히 black-box(쿼리 불가)인 경우가 일반적 - 본 논문은 “쿼리 없이 embedding만 가지고도 원문 복원이 가능한가?”라는 현실적 위협 모델을 해결 |
| 방법론 (전체 파이프라인) | 1) Encoder Stealing (Surrogate Encoder φ̂) - 유출 데이터 DL = {(문장 x, embedding φ(x))}만으로 victim encoder φ를 모방 - Surrogate encoder(GTR-T5 등) + Adapter 사용 - Loss ① L_intra: EP vs ES 직접 정렬 (MSE) - Loss ② L_inter: 문서 간 pairwise cosine similarity 구조 정렬 2) Adversarial Threat Transferability - External dataset DS로 surrogate embedding ET 생성 - Discriminator C가 EP(진짜) vs ET(surrogate)를 구분 - Surrogate encoder는 두 분포가 구분되지 않도록 adversarial 학습 (L_adv) 3) Embedding-to-Text Inversion - GPT Decoder(DialoGPT-small) 사용 - embedding을 hidden state로 넣고 teacher forcing LM loss (L_LM)로 문장 복원 훈련 최종 Loss Lfinal=LLM+Lintra+Linter+LadvL_{final} = L_{LM} + L_{intra} + L_{inter} + L_{adv} |
| 학습에 사용된 데이터 | Leaked Dataset DL (유출 데이터) - QNLI (8K) - IMDB (8K) - AGNews (8K) External Dataset DS - 동일 domain 데이터 (in-domain) - PersonaChat (out-of-domain) |
| 평가에 사용된 Embedding 모델 (Victim) | - OpenAI text-embedding-ada-002 - SBERT - Sentence-T5(ST5) |
| 평가 메트릭 | Rouge-L – 복원 문장 vs 원문 n-gram 중첩 Perplexity(PPL) – 생성 문장의 언어모델 자연스러움 Cosine Similarity – SBERT embedding 공간에서 의미적 유사도 LLM-Eval – ChatGPT 기반 semantic 평가 (0~1) |
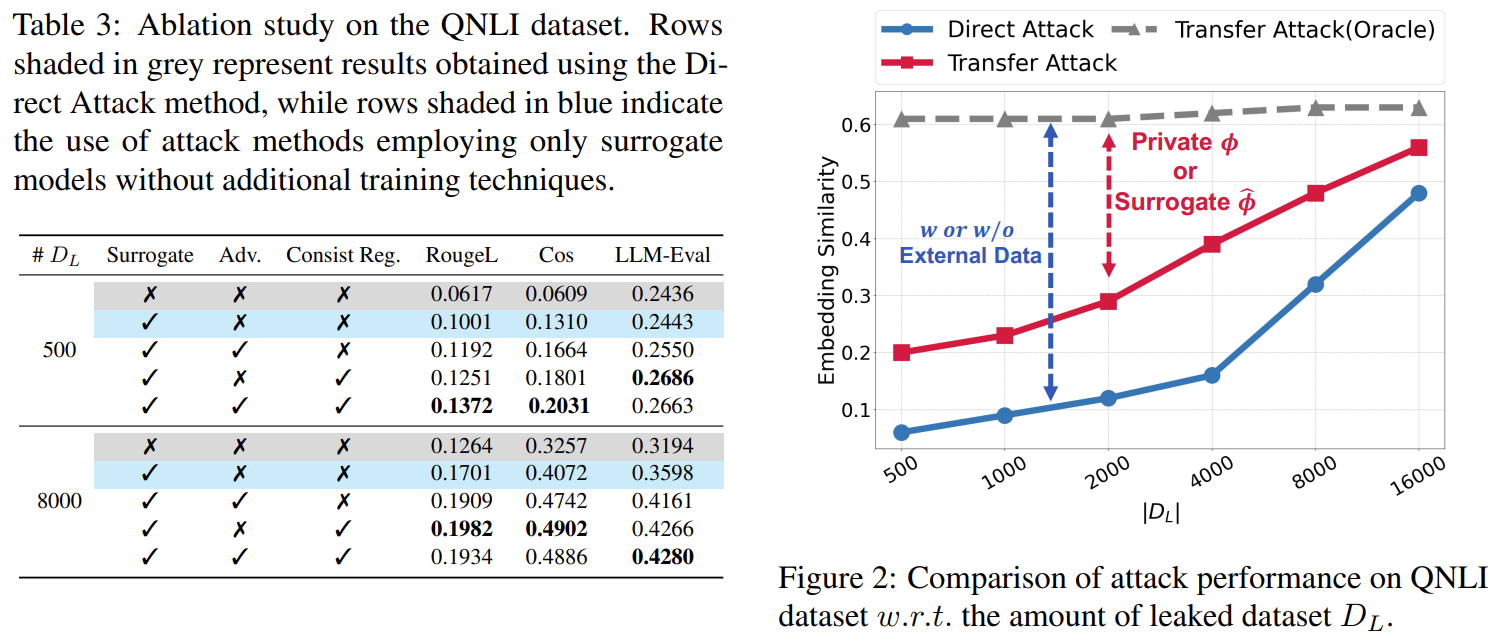
| 주요 실험 구성 | - 비교 baseline: Direct Attack (Li et al., 2023) — surrogate 없이 유출 embedding만으로 GPT decoder를 학습 - In-domain vs Out-of-domain 전이 성능 비교 - Ablation: surrogate, consistency reg., adversarial training 각각의 효과 검증 - Surrogate encoder 종류 변경(OpenAI/SBERT/ST5) 시 성능 변화 분석 - Leaked dataset 크기 변화 (500~16K) 영향 분석 - 의료 데이터(MIMIC-III) case study (privacy leakage 검증) |
| 주요 결과 | 1) Direct Attack 대비 Transfer Attack 큰 향상 - Rouge-L: 최대 +100% 증가 - Cosine similarity: 최대 +270% 증가 - 특히 OpenAI embedding에서 향상 폭 큼 2) Out-of-domain 데이터(예: PersonaChat)로도 공격 가능 - domain이 달라도 성능 감소는 10~15% 수준 → 공격자 domain 몰라도 공격 가능 3) Surrogate encoder 종류에 거의 영향 없음 - victim encoder를 몰라도 공격 가능 4) 유출 데이터 2K~8K만 있어도 높은 복원율 - 8K이면 victim encoder의 70% 이상 모방 5) MIMIC-III 의료 데이터에서 심각한 개인정보 유출 확인 - Age: 98.8% 복원 - Sex: 99.5% 복원 - Disease/Symptom: 79% 복원 |
| 기여 | - 모델 쿼리 불가 상황에서도 embedding inversion이 가능함을 최초로 입증 - Encoder stealing + adversarial alignment라는 새로운 공격 프레임워크 제안 - 다양한 embedding 모델(OpenAI 포함)에서 안정적 공격 성공 - Out-of-domain 데이터만으로도 복원이 가능함을 실증 → 공격 난이도 매우 낮음 - 실제 의료 데이터로 민감 정보(age, sex, disease 등)가 embedding에서 쉽게 복원됨을 입증 - Vector DB 기반 RAG 시스템의 심각한 privacy risk 경고 |
| 한 | - 긴 문장(예: AGNews)은 복원 성능이 저하됨 (embedding 하나로 표현하기 때문) - Decoder(GPT) 기반이므로 hallucination 발생 가능성 있음 - 매우 긴 문단 단위의 inversion은 여전히 어려움 - embedding 모델의 구조까지 완전 복제하는 것은 어려움 |
| 한 줄 요약 | “유출된 embedding만으로도 원문을 복원할 수 있으며, 모델 쿼리조차 필요 없다. Surrogate encoder + adversarial alignment + GPT decoder를 결합한 Transfer Attack은 현실적 환경에서 강한 privacy 위협을 입증한다.” |
아래는 논문 전체 내용을 기반으로,
AI 연구자가 바로 실험·리뷰·재현에 활용할 수 있도록 문제 상황–방법론–실험–결과–기여–한계까지 한 번에 파악 가능한 구조적 요약이다.
요약에는 본문 텍스트 + Figure 1(모델 구조), Table 1–5(성능 비교, MIMIC 사례), Figure 2–4(분석) 내용을 모두 통합했다.
📌 논문 요약: Transferable Embedding Inversion Attack (ACL 2024)
“모델 쿼리 없이(text embedding만으로) 원본 텍스트를 재구성하는 최초의 Transfer Attack”
1. 문제 상황 (What Problem It Solves)
현대 LLM/RAG 시스템은 문서 전체를 vector DB에 embedding 형태로 저장한다.
하지만 많은 서비스는 다음 주장으로 유저를 안심시킨다:
“Embedding은 역추적이 불가능하므로 원문 유출 위험이 없다.”
이 논문은 이 전제를 정면으로 반박하며, 다음과 같은 현실적 공격 시나리오를 제시한다:
● 기존 연구의 비현실적 가정
- 공격자가 embedding 모델에 무제한 query 가능
- 혹은 모델 가중치 일부를 알고 있음
● 본 논문의 현실적 위협 모델
- 공격자는 embedding 벡터 일부 + 해당 텍스트 원문 일부만을 우연히 획득(데이터 유출)
- embedding 모델에 절대 query 불가
- 모델 구조·파라미터 모두 불명 (진짜 black-box)
즉, 실제 벡터 DB 유출 상황을 가정하고,
“embedding만 보고 사용자가 입력한 원래 문장을 얼마나 복원할 수 있는가?”
라는 문제를 다룬다.
2. 핵심 아이디어 (Method: Transferable Inversion Attack)
논문 Figure 1(페이지 3)의 전체 구조에 기반해 설명한다.
공격은 3단계로 이루어진다:
STEP 1 — Encoder Stealing (Surrogate Encoder 학습)
유출된 (text, embedding) 쌍 DL만을 이용해
“victim encoder φ를 모방하는 surrogate encoder φ̂ 생성”
구성:
- Surrogate Encoder: 공개된 Sentence encoder (예: GTR-T5, SBERT 등)
- Adapter: Linear layer (dimension mismatch 해결 + 미세 조정 역할)
Loss 1. Intra-consistency (embedding 직접 정렬)
[
L_{intra} = MSE(\phi(x),\ \hat\phi(x))
]
Loss 2. Inter-consistency (pairwise similarity 보존)
같은 batch 내부 문서들의 코사인 유사도 행렬이
victim φ와 surrogate φ̂에서 같아지도록 학습
이는 단순 벡터 매칭이 아니라,
문서 간 의미적 거리 구조까지 복원하도록 압력을 준다.
STEP 2 — Adversarial Threat Transferability
Surrogate φ̂는 victim과 완전히 동일하지 않다.
→ GPT decoder는 φ̂ embedding에 최적화됨
→ 실제 φ embedding에선 성능 저하 발생
이를 해결하기 위해 도메인 분류기 C 를 이용:
- C: embedding이 surrogate(ET) 인지 victim(EP) 인지 구분
- φ̂: C를 속이도록 adversarial 학습 → 두 embedding 분포를 정렬
[
L_{adv} = \min_{\hat\phi}\max_C
\left[\log C(E_P) + \log(1 - C(E_T))\right]
]
STEP 3 — Embedding-to-Text Reconstruction
여기서는 기존 inversion 연구들과 동일하게,
- Decoder: DialoGPT-small
- Input: reconstructed embedding
- Loss: standard LM teacher forcing (Eq.2)
최종 objective:
[
L_{final} = L_{LM} + L_{surrogate} + L_{adv}
]
3. 실험 (Datasets, Models, Setup)
Victim Embedding Models
- OpenAI text-embedding-ada-002
- SBERT
- Sentence-T5 (ST5)
Leaked Dataset DL (유출 데이터)
각 8K 샘플 사용
(QNLI / IMDB / AGNews)
External Dataset DS
- In-domain: 동일 분포 사용
- Out-of-domain: PersonaChat (chit-chat)
Evaluation Metrics
- Rouge-L
- Perplexity
- Cosine similarity (SBERT embedding)
- LLM-Eval (ChatGPT를 이용한 semantic score)
4. 주요 결과 (Results)
✔ 1) Transfer Attack은 Direct Attack보다 40–50% 이상 향상
(Table 1, page 5)
특히 embedding cosine similarity는 최대 +270% 증가.
예: QNLI + OpenAI embedding
Attack Rouge-L Cosine| Direct | 0.143 | 0.279 |
| Transfer | 0.223 | 0.477 |
→ 모델 쿼리가 없어도, 원문 문장 대부분을 복원할 수 있음.
✔ 2) Out-of-domain 데이터로도 공격 가능
(Table 2, page 5)
즉, 유출 데이터와 전혀 다른 외부 데이터로 surrogate를 훈련해도 여전히 inversion 성공.
→ 공격자가 domain knowledge를 몰라도 공격 가능
✔ 3) 얼마나 DL이 필요할까? (Figure 2–3)
- 약 2K 샘플이면 φ̂가 φ의 약 50% 기능을 복제
- 8K 샘플이면 70% 이상 복제
- 16K면 사실상 upper bound(oracle)에 근접
✔ 4) Surrogate Encoder 선택은 성능에 거의 영향 없음
(Figure 4)
즉, 공격자는 victim encoder 종류를 몰라도 된다.
✔ 5) MIMIC-III 의료 데이터에서 강력한 개인정보 유출 확인
(Table 4–5, page 7–8)
Named Entity Recovery Rate (NER-based)
Entity Transfer Direct| Age | 98.8% | 7.8% |
| Sex | 99.5% | 94.7% |
| Disease | 79.1% | 19.3% |
| Symptom | 79.5% | 22.2% |
| History | 65.3% | 17.5% |
→ 단순 embedding 하나만 주어져도
환자의 나이·성별·질병·증상이 거의 모두 복원됨.
5. 논문의 기여 (Contributions)
✔ 1) 모델 쿼리 없이 embedding inversion을 최초로 가능한 형태로 제시
→ 현실적인 벡터 DB 유출 시나리오 대응
✔ 2) Encoder stealing + adversarial transfer 구조 제안
→ victim embedding 분포를 surrogate로 효과적으로 근사
✔ 3) 다양한 embedding 모델(OpenAI 포함)에서 일관된 공격 성공
→ 실서비스 embedding도 안전하지 않음
✔ 4) 의료 데이터 MIMIC-III 사례로 실제 privacy risk 증명
→ 매우 민감한 정보까지 복원 가능함
6. 한계점 (Limitations)
논문에서 직접 밝힌 내용 포함.
1) 긴 문장 복원 성능이 떨어짐
- AGNews (sentence 길이가 가장 길음)에서 Rouge-L/PPL 성능 하락
- 긴 입력을 하나의 fixed embedding으로 표현하는 구조적 한계
2) embedding dimension / 구조가 복잡할수록 완전 정밀 복원은 어려움
- 특히 문장의 구조적 정보까지 완벽히 반영되지는 않음
3) GPT decoder 기반이므로 hallucination 가능
- 특히 Direct Attack보다 줄었지만 여전히 존재
7. 한눈에 보는 논문 요약 표
항목 내용| 문제 | embedding만 유출되어도 원문 텍스트를 복원할 수 있는가? (모델 쿼리 불가) |
| 접근 | Surrogate encoder를 학습해 victim encoder를 모방하고, adversarial 방식으로 embedding 분포 정렬 후 GPT decoder로 inversion |
| 구성요소 | Intra-consistency + Inter-consistency + Adversarial training + LM reconstruction |
| 데이터 | QNLI, IMDB, AGNews (DL=8K), PersonaChat(DS) |
| Victim Models | OpenAI ada-002, SBERT, Sentence-T5 |
| 결과 | Direct 대비 Rouge-L +40~100%, Cosine +50~270% 개선 |
| Case Study | MIMIC-III에서 개인정보(NER) Recovery: Age 98.8%, Sex 99.5% 등 |
| 기여 | 모델 쿼리 없는 embedding inversion attack 최초 제안 및 강력한 privacy risk 실증 |
| 한계 | 긴 문장 복원 취약, decoder hallucination, embedding 구조 의존 |
필요하면 다음도 추가로 정리해줄 수 있어:
✅ Figure 1 구조를 그림 기반으로 더 자세히 해석
✅ Ablation (Table 3)만 따로 분석
✅ Code 재현을 위한 pseudo-code 제공
✅ 본 논문을 기존 embedding inversion 연구와 비교 정리
✅ “RAG 시스템에서 privacy-safe embedding 설계” 방향 제안
원하는 방식 알려줘!
아래 설명은 Figure 1 전체를 기준으로,
논문이 제안한 Transferable Embedding Inversion Attack이 실제로 어떻게 작동하는지 “처음 보는 사람도 이해할 수 있게” 단계별로 풀어쓴 것이다.
특히 사용자가 “기존 inversion 연구에서 decoder가 뭘 하는지, teacher forcing이 뭔지 잘 모르겠다”라고 말한 부분을 고려하여 기초부터 차근차근 설명한다.
🔎 그림(Figure 1) 기반 방법론 전체 구조 설명
Figure는 2개의 큰 블록으로 구성된다.
1. 전체 목표: Embedding → Text 복원(inversion)
원래 텍스트 x가 embedding 모델 φ에 의해
[
\mathbf{e} = \phi(x)
]
로 변환되어 벡터DB에 저장되어 있다고 가정한다.
공격자는 이 embedding만 가지고 원래 문장을 재구성하고 싶다.
문제는…
- embedding을 만든 진짜 모델 φ를 알 수 없음
- 심지어 쿼리도 불가능
- 오직 일부 (문장, embedding) 유출 데이터만 가짐
그래서 이 논문은 사기꾼 encoder(surrogate encoder) φ̂ 를 만들어 내고,
이를 이용하여 GPT decoder로 문장을 복원하는 전략을 사용한다.
2. 왼쪽 블록: Encoder Stealing (Surrogate Encoder 학습)
이 단계의 목표는:
“유출된 소량의 (문장, embedding)만 가지고
진짜 embedding 모델 φ를 모방하는 모델 φ̂를 만든다.”
즉, 진짜 embedding 모델을 훔치는 단계.
2-1. 입력: 유출된 Private Documents (Dₚ)
- 유출 데이터:
(문장 x, 진짜 embedding EP = φ(x)) - Surrogate encoder φ̂(x) → ES 라는 embedding을 생성한다.
그리고 진짜 embedding EP와 surrogate embedding ES 간의 차이를 최소화하는 것이 목표이다.
2-2. Intra-sample Regularization (L_intra)
“각 문장에서 나온 embedding을 직접 1:1로 맞추기”
그림 상단의 p₁→s₁, p₂→s₂ 이런 구조가 그것이다.
- pᵢ = 진짜 embedding (private)
- sᵢ = surrogate embedding
Loss:
[
L_{\text{intra}} = MSE(E_P, E_S)
]
즉,
- “이 문장을 넣었을 때 나오는 embedding이 비슷해야 한다”
- 개별 샘플 수준(l1 alignment)
2-3. Inter-sample Regularization (L_inter)
“문서들 사이의 의미적 관계(코사인 유사도 구조)를 맞추기”
그림 하단의 pairwise similarity matrix 부분.
예)
- 진짜 embedding에서는 문서1과 문서3이 비슷함 (회색/녹색칸)
- surrogate embedding에서도 동일한 문서 간 관계를 유지해야 한다.
Loss:
[
L_{\text{inter}} = || Q_P - Q_S ||_F^2
]
이게 중요한 이유:
- 단순히 점만 맞추는 것이 아니라
embedding 공간의 구조 전체를 모방하게 해 준다. - 소량의 유출 데이터만 있을 때도 모델을 더 정확하게 흉내낼 수 있음.
3. 오른쪽 블록: Threat Model Transferability (Adversarial Alignment)
Encoder stealing이 끝나면 φ̂는 φ를 대충 비슷하게 흉내낸다.
하지만 여전히 완전히 동일하지 않다.
문제:
- GPT decoder는 surrogate embedding ES에서 훈련된다.
- 나중에 실제 embedding EP(진짜 DB에서 유출된 embedding)를 넣으면 mismatch 발생
이를 해결하기 위한 단계가 바로 Adversarial Threat Model Transfer이다.
3-1. 입력 데이터 2종류
- DP: Private (유출된 진짜 embedding EP)
- DS: External (surrogate embedding ET = φ̂(x_ext))
External dataset은 많은 양이 있을 수 있음 → 공격자가 인터넷에서 긁어온 외부 텍스트 등을 이용.
3-2. Discriminator C (판별기)
Discriminator C의 역할:
“이 embedding이 진짜 embedding EP인지, surrogate embedding ET인지 구별한다.”
Adversarial training에서는:
- Discriminator는 두 embedding을 최대한 구별하려고 노력
- Surrogate encoder φ̂는 구별되지 않도록 embedding을 생성하려고 노력
Loss:
[
L_{adv} = \min_{\hat\phi} \max_C
\left[ \log C(E_P) + \log (1 - C(E_T)) \right]
]
결과:
- Surrogate embedding distribution ≈ Private embedding distribution
- GPT decoder가 진짜 embedding을 넣어도 잘 동작하는 구조 확보
4. Embedding-to-Text Inversion (GPT Decoder로 문장 복원)
여기서 가장 질문이 많았던 부분을 자세히 설명한다.
⚠️ 흔히 하는 오해
“Decoder가 embedding을 어떻게 문장으로 바꾸지?”
실제 동작:
embedding → GPT decoder initial hidden state 로 투입된다.
- GPT decoder는 autoregressive LM
- 입력 embedding은 hidden state 초기값 또는 prefix embedding으로 주어진다.
- 그 이후 GPT는 “embedding을 설명하는 문장”을 생성하도록 학습됨.
4-1. Teacher Forcing (LM Loss, Eq.2)
Teacher forcing은 seq2seq, LM 학습에서 가장 표준적인 방식:
예:
원문 문장이
“The patient is a 63-year-old male.”
이면 학습할 때는:
<bos>, The → target=The
The, patient → target=patient
patient, is → target=is
...
즉,
현재까지 생성한 단어 + embedding을 기반으로 다음 단어를 예측하도록 강제.
Loss:
[
L_{LM} = - \sum_i \log P(w_i | \phi(x), w_0,...w_{i-1})
]
5. 모든 Loss를 합쳐서 Joint Training
최종 loss:
[
L_{final} = L_{LM} + L_{surrogate} + L_{adv}
]
- L_surrogate = L_intra + L_inter
- encoder stealing + adversarial alignment + decoder training을 동시에 수행
🔥 방법론 전체를 인간친화적으로 한 문장으로 요약
“유출된 embedding을 흉내내는 surrogate encoder를 만든 뒤,
이 embedding 분포를 adversarial하게 진짜 embedding과 같아지도록 정렬시키고,
GPT decoder로 embedding을 문장으로 복원하는 attack pipeline”
🔍 Figure 1을 기반으로 전체 흐름 요약
아래처럼 전체 플로우를 보면 그림의 각 요소가 정확히 이해된다.
① 유출 데이터 (Dₚ) → 진짜 embedding EP 추출
attack 대상이 되는 embedding.
② Surrogate encoder φ̂ + Adapter 학습
EP와 ES가 일치하도록
- L_intra: 1:1 vector alignment
- L_inter: 문서 간 유사도 구조 보존
③ 외부 데이터 (Dₛ)로 surrogate embedding ET 생성
④ Discriminator C가 EP vs ET를 구분하려고 함
Surrogate encoder는 이를 속이며 embedding 분포 정렬
→ L_adv
⑤ GPT decoder가 embedding만 보고 문장 복원 훈련
Teacher forcing 기반 LM loss
→ L_LM
⑥ 훈련이 끝나면
이제 공격자는 embedding만으로 문장을 재구성 가능.
만약 원한다면…
- Figure 1을 기반으로 “모델 forward 과정”을 pseudo-code로 정리
- Encoder stealing 부분만 더 깊게 분석
- Adversarial alignment가 왜 transferability를 올리는지 시각적으로 설명
- 기존 inversion attack 대비 차이점 비교표 작성
- 이 구조를 네가 실험할 때 어떻게 PyTorch로 구현해야 할지 코드 생성
어떤 포맷으로 더 보고 싶어?
https://arxiv.org/abs/2409.19134
Confidential Prompting: Privacy-preserving LLM Inference on Cloud
This paper introduces a vision of confidential prompting: securing user prompts from an untrusted, cloud-hosted large language model (LLM) while preserving model confidentiality, output invariance, and compute efficiency. As a first step toward this vision
arxiv.org
Confidential Prompting: Privacy-preserving LLM Inference on Cloud
괜찮은 방법인 줄 알았으나 kv cashe를 사용자가 연산하는 거라 이건 좀....
너무 느릴 것 같은데...
그리고 CVM이라는 구조 자체를 정확히 모르다보니 애매한게 있네요
배치 처리가 안되는 이 CVM.....
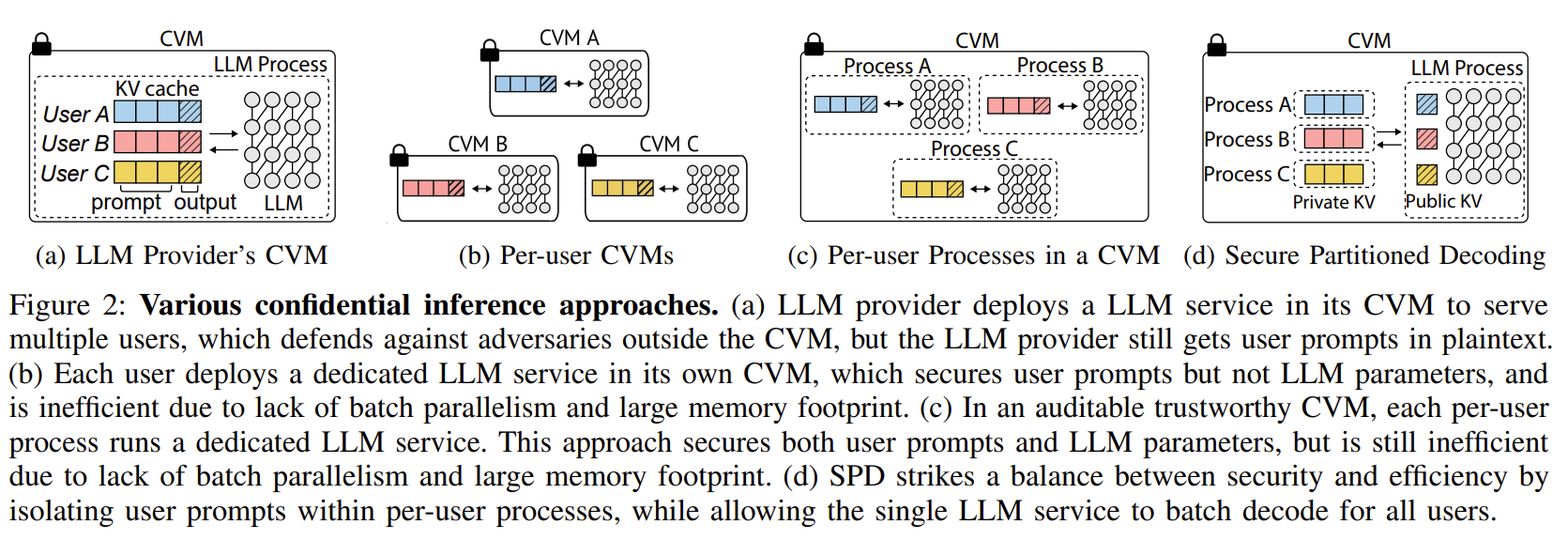
| 문제 상황 | • 클라우드 LLM 사용 시 프롬프트가 LLM provider·클라우드 provider에게 노출됨 → 개인정보, 의료·금융·기밀 문서 위험. • Confidential Computing(TEE/CVM)은 “클라우드 provider”는 막지만 LLM provider는 프롬프트를 그대로 볼 수 있음 (표준 confidential inference의 한계). • Per-user CVM 방식은 프라이버시는 지키지만 배치 처리 불가, GPU 메모리 낭비로 스케일 불가능. • HE/MPC/DP/Anonymization은 정확도 손실 또는 엄청난 계산량 문제. |
| 해결 목표 | (1) User Prompt Confidentiality (2) Model Confidentiality (LLM 파라미터 불노출) (3) Output Invariance (LLM 원본 출력과 100% 동일) (4) Compute Efficiency (multi-user batch 가능한 고성능) |
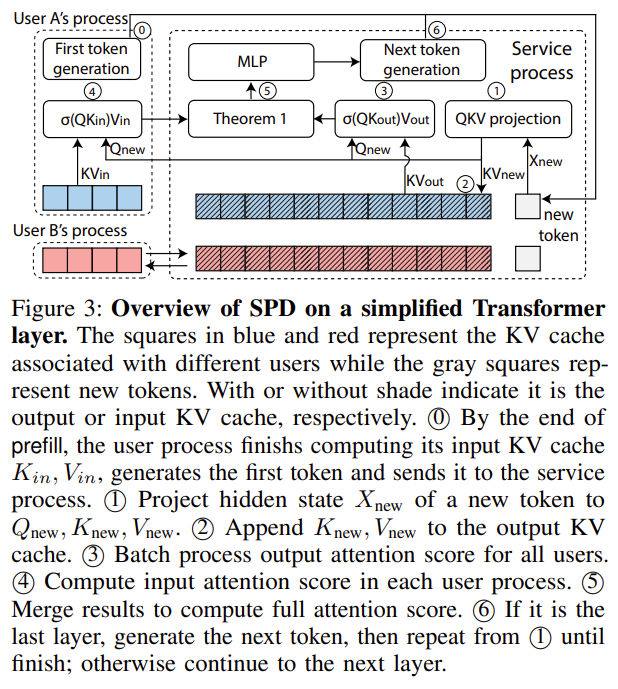
| 핵심 아이디어 | Secure Partitioned Decoding(SPD): Attention을 프롬프트 기반 부분과 출력 기반 부분으로 정확하게 분할 계산하여 합치는 수학적 기법. 1) Input KV Cache (K_in, V_in) → per-user process에서 생성 및 저장 (prefill). 2) Output KV Cache (K_out, V_out) → service process에서 관리 (decode). 3) per-user process: Q_new만 전달받아 A_in = softmax(QK_inᵀ)V_in 계산. 4) service process: A_out = softmax(QK_outᵀ)V_out 계산. 5) Theorem 1로 attention 완전 결합 → 원래 LLM과 동일한 attention 결과. → 프롬프트는 per-user process 밖으로 절대 나오지 않지만, decode는 고성능 batch 처리 가능. |
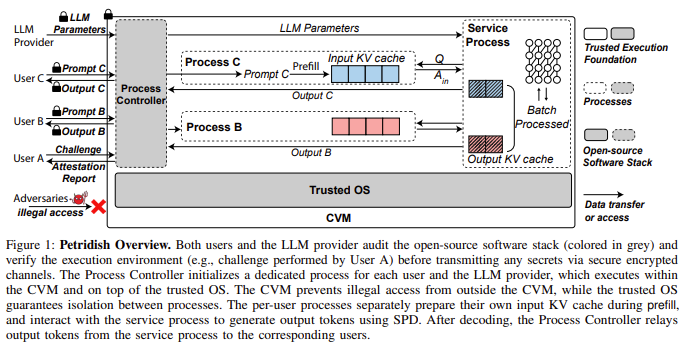
| 시스템 구조 | CVM 내부 구성: • Process Controller: secure channel 생성, 프로세스 생성, 네트워크 차단, output relay. • per-user process: 프롬프트 수신·prefill·A_in 계산. 네트워크 완전 격리. • service process: 모델 실행, output KV 관리, A_out와 토큰 생성 담당. • 오픈소스 software stack(Linux kernel, NVIDIA open driver, Controller 등): 사용자와 LLM provider가 audit 가능. • Remote Attestation로 CPU+GPU 환경 무결성 증명. |
| 평가 실험 환경 | • Azure NCCads H100 v5 CVM (AMD SEV-SNP + NVIDIA H100 GPU CC 활성화) • LLM 모델: Llama 3 (8B), Llama 3.2 (1B, 3B), Code Llama (7B, 13B, 34B). • 사용자 수: 1 ~ 32 concurrent users. • Input/Output 길이: 64 ~ 512 tokens. • Baseline: ① No-protection(LLM provider 신뢰) ② Full Isolation(per-user LLM instance) |
| 평가 메트릭 | • Latency per generated token (주요 메트릭) • End-to-end request latency • Scaling efficiency (사용자 수 증가 시) • Model size scaling(1B~34B) • Overhead breakdown (Q 전송, A_in/A_out 병합 비용 등) |
| 실험 결과 | • SPD(Petridish)는 per-user isolation 대비 최대 5× 낮은 latency 달성. (Fig.4) • 사용자 수 32명까지 scaling 시에도 성능 degradation 작음 (batch decode 때문에). • 모델 크기(1B→34B) 증가 시 full isolation은 폭증하지만 SPD는 증가폭이 매우 작음. (Fig.5) • input/output token 수가 증가해도 per-token latency는 거의 일정. (Fig.6) • GPU CC 환경에서 통신 오버헤드는 크지만 Blackwell TEE-IO에서는 대폭 개선 가능성. |
| 보안 분석 | • 사용자 프롬프트는 per-user process 메모리에서만 존재 → service process·LLM provider·클라우드 provider 모두 접근 불가. • A_in은 정보 손실 attention map → prompt stealing 공격이 실질적으로 실패함(Tan et al. empirically). • per-user process는 네트워크 차단 → 모델 파라미터 유출 불가. • process isolation + remote attestation으로 프롬프트·모델 모두 보호. |
| 논문 기여 | 1) Secure Partitioned Decoding(SPD) 최초 제안: attention을 완전 분할·병합하여 원본 모델 출력과 identical한 결과 생성. 2) Prompt confidentiality + Model confidentiality + Batch-efficient decoding을 동시에 달성한 첫 시스템. 3) CVM 내부의 auditable software stack 구조 제안. 4) 실제 구현 및 H100 CC 환경에서 대규모 실험. |
| 한계 | • 출력 토큰은 보호 대상이 아님 → LLM provider가 사용자의 output은 볼 수 있음. • CVM/OS/GPU driver 취약점 공격(TEE.fail 등)은 TCB 한계 → 외부 연구 필요. • GPU CC 통신 오버헤드가 매우 큼(특히 H100) → 향후 Blackwell GPU에서 해결 가능. • Prompt injection 공격은 Attention Tracker 같은 추가 기법과 결합 필요. |
아래는 업로드한 “Confidential Prompting: Privacy-preserving LLM Inference on Cloud” 논문을 기반으로 한 전문가용 요약입니다.
요약은 문제 상황 → 핵심 아이디어(SPD) → 시스템 구조(Petridish) → 방법론 단계별 정리 → 실험 → 결과 → 기여 → 한계 순으로 정리했습니다.
나중에 이 표만 보면 논문 내용을 완전히 복원할 수 있도록 구성했습니다.
(모든 내용은 논문 PDF 기반이며, 표기된 위치는 논문 페이지 기준입니다. )
📌 1. 논문 핵심 요약 (한 줄)
Petridish는 Confidential Computing과 Secure Partitioned Decoding(SPD)을 결합해, 클라우드에서 사용자 프롬프트를 LLM 제공자와 클라우드로부터 모두 보호하면서도 배치 효율을 유지하는 최초의 실용적 비밀 프롬프트 처리 시스템이다.
📌 2. 논문 전체 구조 요약 표
항목 내용| 문제 상황 | 클라우드 LLM 사용 시 LLM 제공자, 클라우드 제공자, 악의적 사용자가 사용자 프롬프트를 탈취할 위험 존재. 기존 confidential computing은 “클라우드 제공자”는 방어하지만 LLM 제공자는 그대로 프롬프트를 본다 → 완전 보호 불가능. |
| 기존 한계 | • Per-user CVM: 안전하지만 13B 모델 기준 GPU 하나당 3명만 서비스 가능 → 비효율적. • Confidential inference: LLM 제공자가 프롬프트를 그대로 봄. • HE/MPC/DP/Anon: 느리거나 정확도 손실 발생. |
| 목표 | (1) 프롬프트 비밀성 (2) 모델 기밀성 (3) 출력 불변성 (4) 높은 효율성 동시에 달성. |
| 핵심 기여 | Secure Partitioned Decoding(SPD): attention 계산을 input과 output으로 분리해, 사용자 프롬프트에서 생성된 KV cache는 per-user process에만 남기고, LLM service는 이를 볼 수 없음. |
| 시스템 | Petridish: CVM 내부에서 per-user process + LLM service process를 분리. Process Controller가 접근 제어·네트워크 제한·secure channel 관리 수행. (Fig. 1) |
| Prefill 단계 | 입력 프롬프트는 per-user process가 직접 prefill을 수행하여 input KV cache(K_in, V_in) 생성. LLM 모델 파라미터는 read-only로 공유되지만 외부로 유출 불가. |
| Decode 단계(SPD) | service process는 output KV만 가지고 attention 수행. input KV 부분은 per-user가 Ain = softmax(Q K_inᵀ) V_in 계산 → service process로 전송. service process는 output 부분 A_out 계산 후 Theorem 1 기반으로 두 attention을 병합. |
| 보안 근거 | • input attention score는 역으로 prompt 복원 불가 (information-losing map). • prompt stealing 공격에 대해 Tan et al.의 실험 기반 안정성 확보. • per-user 네트워크 완전 차단으로 LLM 파라미터 유출 방지. |
| 성능 | 8B 모델 기준: 기존 per-user isolation 대비 최대 5× 빠름. 32명 동시 요청에서도 batch-friendly. (Fig. 4–7) |
| 한계 | • “응답 내용”은 보호하지 못함 (LLM provider가 출력은 볼 수 있음). • CVM/OS/드라이버에 대한 공격은 TCB 한계 상 대응 어려움. |
| 적용 분야 | 의료·금융 기록 처리, 민감한 데이터 포함 대화형 시스템 등. |
📌 3. 방법론 – 그림 기반 상세 설명 (Fig.1, Fig.3)
🔷 3-1. Petridish 전체 구조 (Figure 1) 설명
(페이지 2)
그림의 구성 요소:
① Confidential VM (CVM)
- AMD SEV-SNP + NVIDIA GPU CC 기반 TEE.
- 클라우드 제공자가 CVM 내부 메모리 접근 불가.
② Trusted OS
- 프로세스 간 격리 보장.
- per-user process와 service process를 완전히 분리.
③ Process Controller
- 사용자·LLM 제공자와 Diffie-Hellman 기반 secure channel 생성.
- per-user process 초기화.
- 네트워크 namespace 격리로 per-user process 네트워크 완전 차단.
- LLM service process로부터 생성된 토큰을 사용자에게 relay.
④ Per-user Process
- 사용자 프롬프트를 받음.
- Prefill 단계에서 input KV cache(K_in, V_in) 생성 → 절대 외부 노출 안 됨.
- Decode 단계에서 attention 중 input 부분 Ain만 계산.
⑤ Service Process
- 모델 전체 파라미터 소유.
- 모든 사용자에 대한 출력 attention을 batch로 계산(A_out).
🔷 3-2. SPD 동작 (Figure 3)
(페이지 8)
그림은 Transformer layer의 attention 계산을 다음처럼 분리함:
(0) Prefill 종료
- per-user process가 input KV 생성(K_in, V_in).
- 첫 토큰을 service process에게 보냄.
(1) Service → Q,K,V 계산
X_new → Q_new, K_new, V_new
- 새로운 토큰에 대한 Q_new는 per-user로 전달.
(2) output KV cache 갱신
- service는 자기 internal KV cache(K_out, V_out)에만 접근 가능.
(3) A_out 계산 (service)
A_out = softmax(Q_new K_outᵀ) V_out
(4) A_in 계산 (per-user)
A_in = softmax(Q_new K_inᵀ) V_in
(5) Theorem 1에 따라 attention 병합
논문 Eq.(1) (페이지 8):
[
σ(QK^T)V =
\frac{γ_{in}}{γ_{in}+γ_{out}} σ(QK_{in}^T)V_{in} +
\frac{γ_{out}}{γ_{in}+γ_{out}} σ(QK_{out}^T)V_{out}
]
➡ 이 식 덕분에 attention은 완전히 동일한 결과를 유지(output invariance).
(6) 최종 토큰 생성
- service가 다음 토큰 생성 후 Controller로 전달.
📌 4. 실험 결과 (Fig.4–7)
(모든 그림은 페이지 11–12)
실험 항목 결과| 스케일(1–32 사용자) | Full isolation은 사용자 증가 시 급격히 악화. SPD는 거의 선형적으로 안정 유지. |
| 모델 크기(1B~34B) | 모델이 커질수록 full isolation은 폭증. SPD는 batch 효과로 증가폭 매우 작음. |
| input/output token 증가 | token 수가 512까지 증가해도 per-token latency 거의 일정. |
| 오버헤드 분석 | GPU CC 때문에 IPC 통신이 느려지지만, Blackwell TEE-IO에서는 largely 해결될 예정. |
결론: 배치 처리 + 프롬프트 기밀성을 동시에 만족하는 유일한 기법.
📌 5. 논문 기여 요약
(1) Secure Partitioned Decoding(SPD) 제안
- attention을 input과 output으로 정확하게 분리할 수 있음을 최초로 증명(Theorem 1).
(2) 사용자 프롬프트 완전 보호
- input KV cache를 per-user process 내부에만 저장 → LLM provider도 볼 수 없음.
(3) 모델 파라미터 보호
- per-user process는 read-only로만 접근하며 네트워크 차단 → 모델 추출 불가능.
(4) 배치 효율 유지
- output KV는 중앙 service process가 batch 처리함 → multi-user 속도 유지.
(5) output invariance
- SPD는 attention 계산을 정확히 복원하므로 모델 출력 100% 동일.
📌 6. 한계 및 향후 과제
한계 설명| 응답 데이터는 보호 불가 | per-user process에서 출력값은 Controller → 사용자로 가지만, LLM provider가 service process의 출력은 관찰 가능. |
| TCB 취약성 | CVM/OS/Nvidia Driver 공격 가능성 존재. |
| Prompt Leakage Injection 완전 방어 어려움 | Attention Tracker 같은 별도 탐지 기법과 결합 필요. |
| GPU CC 통신 오버헤드 | H100에서 큰 비용, Blackwell에서 개선 예정. |
📌 7. STEP-BY-STEP 흐름 요약
Step 1. CVM 초기화
- OS/Driver/Controller 모두 오픈소스 → 사용자와 LLM provider가 audit.
- Remote attestation으로 무결성 검증.
Step 2. secure channel 생성
- Diffie-Hellman으로 user ↔ Controller ↔ LLM provider 연결.
Step 3. Prefill (per-user process)
- prompt 입력 → input KV 생성(K_in, V_in).
- 첫 토큰만 service process에 전달.
Step 4. Decode (SPD)
- Q_new는 per-user process로 전달 → A_in 계산.
- service process는 A_out 계산.
- Theorem 1로 attention 합성.
Step 5. Response
- Controller가 모든 출력 토큰을 사용자에게 전달.
결과:
LLM provider도 prompt를 모른 채로 추론이 진행되며, 출력 품질 변화 없음.
📌 필요하다면 추가로 제공할 수 있습니다
- Figure별 해석 더 자세히
- SPD의 수학적 작동 방식 deeper dive
- Prompt leakage 공격 모델 정리
- 실용적 시스템 구성 흐름도
- 당신의 연구 아이디어와 연결하는 분석
필요한 부분을 말해줘.
논문의 방법론은 **“어떻게 클라우드에서 LLM을 돌리면서도 프롬프트는 절대 안 보이게 만들 것인가”**를 시스템·수학 두 층위에서 풀어낸 것이라 보면 됩니다.
아래에서는 (1) 기본 LLM 추론 구조 → (2) SPD 핵심 아이디어와 수식 → (3) Petridish 시스템 구조와 동작 프로토콜 순으로 정리하겠습니다.
1. 기본 전제: LLM 추론, KV 캐시, Prefill/Decode
1.1 GPT 계열 LLM의 self-attention 구조
- 입력 시퀀스 (X \in \mathbb{R}^{n \times d}) 에 대해 각 layer에서
[
Q = XW_Q,\quad K = XW_K,\quad V = XW_V
]
[
Y = \sigma(QK^\top)V
]
형태로 self-attention 수행. 여기서 (\sigma)는 softmax. - 마지막 layer 출력에서 logits → 다음 토큰 샘플링 → autoregressive generation.
1.2 KV 캐시와 Prefill / Decode 분리
- Prefill 단계: 전체 프롬프트 토큰을 한 번에 통과시켜 프롬프트에 대한 K, V 전체를 계산해서 KV cache로 저장.
- Decode 단계: 매 출력 토큰마다
- 새 토큰에 대한 (K_{new}, V_{new})만 추가 계산.
- 기존 KV cache는 재사용.
- 이 구조 덕분에 “프롬프트로부터 온 KV”와 “생성된 토큰에서 온 KV”를 분리해서 생각할 수 있게 됩니다. 이게 SPD의 출발점입니다.
2. Secure Partitioned Decoding(SPD)의 핵심 아이디어
2.1 위협 모델 기반 설계 목표
가정:
- LLM provider ≠ 사용자 이고 서로 신뢰하지 않는다.
- 둘 다 클라우드도 신뢰하지 않는다.
- 하지만 CPU/GPU TEE + guest OS + Process Controller(모두 오픈소스)는 신뢰한다고 가정.
따라서 달성해야 하는 것:
- 프롬프트 비밀성:
- LLM provider도, 클라우드 provider도 프롬프트를 못 본다.
- 모델 기밀성:
- 사용자는 LLM 파라미터를 빼갈 수 없다.
- Output invariance:
- 보안을 걸어도 LLM 출력은 “원래 LLM 그대로”여야 한다.
- Compute efficiency:
- per-user CVM처럼 batch 불가능한 구조는 안 된다.
2.2 KV cache를 두 부분으로 나누기
Decode에서는 한 시점의 attention 계산이
[
Q \in \mathbb{R}^d,\quad K \in \mathbb{R}^{\text{len} \times d},\quad V \in \mathbb{R}^{\text{len} \times d}
]
에 대해 이뤄집니다. 여기서 len = (프롬프트 길이 + 지금까지 생성된 토큰 수).
SPD는 이걸 다음처럼 쪼갭니다.
- 입력 프롬프트로부터 온 KV:
[
K_{in}, V_{in} \quad (\text{input KV cache})
]
→ 사용자 프로세스(per-user process) 안에서만 유지. - 지금까지 생성된 출력 토큰으로부터 온 KV:
[
K_{out}, V_{out} \quad (\text{output KV cache})
]
→ 서비스 프로세스(service process) 에서 관리.
즉, 전체 (K, V) 를
[
K = \text{concat}(K_{in}, K_{out}),\quad V = \text{concat}(V_{in}, V_{out})
]
으로 표현.
핵심 아이디어:
- 프롬프트에 해당하는 KV는 사용자 쪽에만 두고, LLM provider가 가진 서비스 프로세스는 절대 이 KV를 보지 않는다.
- 대신 attention 결과를 “input부분 + output부분”으로 나눠 계산한 뒤, 수학적으로 정확하게 합쳐준다.
3. SPD 수식 (Theorem 1) – 어떻게 합치길래 동일한 결과인가?
3.1 attention을 두 조각으로 나눔
일반적인 attention은
[
s = QK^\top \in \mathbb{R}^{\text{len}},\quad \gamma = \sum_i e^{s_i},\quad
\sigma(s)V = \sum_i \frac{e^{s_i}}{\gamma} V_i
]
이를 input/output으로 나누면:
- (K = [K_{in}; K_{out}],\ V = [V_{in}; V_{out}])
- (s = [s_{in}, s_{out}] = [QK_{in}^\top,\ QK_{out}^\top])
- softmax 분모도
[
\gamma = \sum_i e^{s_i} = \gamma_{in} + \gamma_{out}
]
각 부분에 대한 attention 결과:
[
\sigma(QK_{in}^\top)V_{in},\quad \sigma(QK_{out}^\top)V_{out}
]
Theorem 1 (논문 식 (1)):
[
\sigma(QK^\top)V =
\frac{\gamma_{in}}{\gamma_{in} + \gamma_{out}} \cdot \sigma(QK_{in}^\top)V_{in}
+
\frac{\gamma_{out}}{\gamma_{in} + \gamma_{out}} \cdot \sigma(QK_{out}^\top)V_{out}
]
→ 즉,
“전체 attention 결과 = (input 부분 attention) + (output 부분 attention) 의 가중 합”
(가중치는 각 부분의 softmax 분모 비율)
3.2 안전한 분할 계산 프로토콜
이 수식을 이용해, attention을 두 당사자가 나눠서 계산:
- 사용자 프로세스 (input KV를 가진 쪽):
- (K_{in}, V_{in})는 자신이 보관.
- 서비스로부터 새로운 토큰의 (Q_{new})만 받음.
- (A_{in} = \sigma(Q_{new}K_{in}^\top)V_{in}) 계산.
- (\gamma_{in} = \sum \exp(Q_{new}K_{in}^\top))도 계산.
- 이 두 값만 서비스 프로세스로 전달.
- 서비스 프로세스 (LLM provider 쪽):
- (K_{out}, V_{out})를 관리.
- 자신 쪽에서 (A_{out} = \sigma(Q_{new}K_{out}^\top)V_{out}), (\gamma_{out}) 계산.
- Theorem 1로 (A = \sigma(QK^\top)V)를 정확히 복원.
- 이 (A)로 MLP, 다음 layer, 다음 토큰 생성 진행.
이렇게 하면:
- 서비스 프로세스는 프롬프트 텍스트도, K_in/V_in도 모른다.
- 사용자 프로세스는 모델 파라미터를 보긴 하지만 read-only이고 네트워크 차단 때문에 유출할 수 없다.
- attention 결과는 원래 LLM과 완전히 동일 (output invariance).
3.3 수치 안정성 처리
softmax 분모 (\gamma_{in}, \gamma_{out}) 직접 계산은 overflow 문제.
그래서 online softmax 기법을 사용해 각 부분에서 max를 빼고 계산:
- (m_{in} = \max(QK_{in}^\top),\ m_{out} = \max(QK_{out}^\top))
- (\gamma_{in} = \sum \exp(QK_{in}^\top - m_{in})), (\gamma_{out})도 동일.
- 두 부분의 max 차이로 스케일링 factor (\alpha = e^{m_{out} - m_{in}}) 를 둬서 합칠 때 안정적으로 처리.
4. Petridish 시스템 레벨 방법론 (구체 동작 프로토콜)
이제 위의 SPD를 실제 클라우드 환경에서 어떻게 구현하는지가 Petridish의 시스템 방법론입니다. (Fig.1, §4 전반)
4.1 단계 0 – CVM 및 소프트웨어 스택 신뢰 구축
- 오픈소스 소프트웨어 스택
- Linux kernel, NVIDIA open GPU driver, PyTorch, Process Controller 등 CVM guest stack 전부 공개.
- 사용자와 LLM provider가 코드 레벨에서 audit 가능.
- 원격 attestation
- Process Controller가 GPU TEE(NVIDIA NRAS)·CPU TEE(AMD SEV-SNP) 양쪽 attestation을 수행.
- attestation report에 “GPU attestation token”의 해시까지 포함시켜 CPU/GPU 둘 다 검증.
- 참여자 측 검증
- 사용자·LLM provider는 로컬에서 빌드한 CVM 이미지의 hash와 attestation report의 hash를 비교 → 환경 무결성 확인.
4.2 단계 1 – Secure Channel 및 프로세스 초기화
- Diffie-Hellman 키 교환으로 secure channel 생성
- User ↔ Process Controller
- LLM Provider ↔ Process Controller
- Process Controller가 per-user process 생성
- 사용자마다 하나의 프로세스.
- 생성 시 clone의 CLONE_NEWNET flag로 각 프로세스를 독립 네임스페이스에 격리 → 네트워크 직접 사용 불가.
- LLM service process 생성
- LLM provider 측을 대표하는 프로세스.
- GPU 상에 모델 파라미터 로드.
4.3 단계 2 – 모델 파라미터 Read-only 공유
- LLM provider → Process Controller
- LLM 파라미터를 secure channel로 전송.
- 혹은 파라미터·바이너리를 CVM 이미지에 암호화된 형태로 넣어두고 runtime에 key만 전달하는 방식도 가능.
- Process Controller
- 파라미터를 CVM 내부에서 복호화 후 read-only in-memory file로 저장.
- 이 파일을 LLM service process와 모든 per-user process에 read-only로 매핑.
- GPU 메모리 공유
- PyTorch의 CUDA MemPool + cuMemCreate / cuMemExportToShareableHandle 사용해 파라미터용 GPU 메모리 생성.
- per-user process는 cuMemImportFromShareableHandle로 같은 파라미터 메모리 영역에 read-only 접근.
→ 결과적으로, 모든 프로세스가 하나의 파라미터 사본을 공유하면서 메모리 효율 유지 + 모델 수정/유출 방지.
4.4 단계 3 – Prefill (per-user process에서 수행)
- 사용자 → per-user process
- 사용자 프롬프트는 secure channel을 통해 Controller에 전달되고, 다시 IPC로 해당 per-user process에 전달.
- per-user process
- LLM forward를 돌려 **프롬프트 전체에 대한 K_in, V_in (input KV cache)**를 계산.
- 이 KV는 해당 프로세스의 메모리 안에만 존재, service process는 접근 불가.
- Prefill 마지막에서 첫 output 토큰을 생성하여 service process로 전달.
4.5 단계 4 – Decode (SPD 프로토콜 실행)
decode는 각 토큰마다 다음 루프를 돎 (Fig.3).
- 서비스 프로세스: Q,K,V 계산
- 새 토큰의 hidden state (X_{new})에서
[
Q_{new}, K_{new}, V_{new}
]
계산. - Q_new만 per-user process로 비동기 전송(GLOO backend 사용).
- 새 토큰의 hidden state (X_{new})에서
- 서비스 프로세스: output KV 업데이트
- K_new, V_new를 자신의 output KV cache (K_{out}, V_{out})에 append.
- 서비스 프로세스: A_out, γ_out 계산
- 모든 사용자에 대해 batch로
[
A_{out} = \sigma(Q_{new}K_{out}^\top)V_{out},\quad \gamma_{out}
]
계산.
- 모든 사용자에 대해 batch로
- per-user process: A_in, γ_in 계산
- 전달받은 Q_new와 자신의 (K_{in}, V_{in})로
[
A_{in} = \sigma(Q_{new}K_{in}^\top)V_{in},\quad \gamma_{in}
]
계산 후, 이 두 값만 서비스 프로세스로 다시 전송.
- 전달받은 Q_new와 자신의 (K_{in}, V_{in})로
- 서비스 프로세스: attention 병합 + 다음 토큰 생성
- Theorem 1에 따라
[
A = \frac{\gamma_{in}}{\gamma_{in} + \gamma_{out}} A_{in} + \frac{\gamma_{out}}{\gamma_{in} + \gamma_{out}} A_{out}
]
을 계산 → 원래 attention 결과와 동일. - 이후 MLP, 다음 layer 처리.
- 마지막 layer라면 logits → 다음 토큰 샘플링.
- 생성된 토큰은 Process Controller로 전달.
- Theorem 1에 따라
- 반복
- [EOS] 생성 시까지 1–5 반복.
여러 사용자가 있을 때는:
- per-user process → A_in 계산은 서로 독립적으로 진행되고,
- 서비스 프로세스 → A_out 계산은 output KV 전체에 대해 하나의 큰 batch로 수행하므로 GPU 효율이 유지됩니다.
4.6 단계 5 – 응답 전달 및 정보 흐름 제어
- Process Controller는 service process로부터 받은 토큰 시퀀스를 사용자에게 secure channel로 전달.
- per-user process는 사용자와 직접 네트워크 통신을 하지 못하게 설계되어, LLM 파라미터를 네트워크로 유출할 수 없음.
5. 방법론의 보안 관점 정리 (요약)
- 프롬프트 비밀성
- 프롬프트는 CVM 밖에서는 항상 암호화 상태.
- CVM 안에서도 per-user process 메모리 안에만 존재.
- service process는 A_in (attention 결과) + 출력 토큰만 본다.
- attention은 정보 손실 매핑이고, prompt stealing 공격이 실제 “in-the-wild 프롬프트”에서 거의 실패한다는 결과를 인용해 실증적 근거도 제시.
- 모델 기밀성
- per-user process는 파라미터를 read-only로만 볼 수 있고, 네트워크가 차단되어 있음.
- 응답 토큰 전달은 Controller가 수행하므로, per-user process가 “파라미터 코딩된 토큰 스트림”을 외부로 직접 쏘는 것도 불가능.
- 출력 불변성
- SPD는 attention을 수학적으로 동일하게 재구성.
- LLM 파라미터나 구조 변경, 재학습이 필요 없고 “pure runtime scheme”.
- 효율성
- 인코딩/HE/MPC 대신 원본 모델 그대로 사용.
- 서비스 프로세스에서 output KV에 대한 계산을 multi-user batch로 수행 → per-user CVM/프로세스 방식보다 latency가 훨씬 낮음(실험에서 최대 ~5×).
원하시면,
- SPD를 “secure two-party computation” 관점에서 더 수학적으로 풀어 설명하거나,
- 실제 PyTorch/Transformers 코드 레벨에서 어떤 식으로 monkey patching했는지(LLama attention 모듈)까지 구조를 풀어서 설명해 드릴 수 있습니다.
아주 정확한 질문이야.
“사용자 프롬프트가 LLM provider에게 전달되지 않는다면, 누가 Transformer를 한 번 돌려서(KV cache를 만들기 위해) prefill을 수행하느냐?”
이 부분이 Petridish 방법론에서 가장 핵심적이면서도 헷갈리기 쉬운 지점이다.
결론부터 말하면:
사용자가 Transformer를 1회 inference 하는 것이 아니라,
CVM 내부의 “per-user process”가 LLM 전체 파라미터를 사용해 프롬프트를 prefill한다.
이때도 프롬프트는 LLM provider에게 절대 넘어가지 않는다.
즉, Transformer 1회 추론(prefill)은 반드시 수행되지만, 그 수행 주체는 “사용자 PC”가 아니라 “CVM 내부의 per-user process”다.
아래에서 이를 구조적으로 매우 명확하게 설명해 줄게.
✔ 1. 사용자 PC가 Transformer를 돌리는 것이 아님
사용자는 단지 프롬프트 텍스트를 암호화된 채널로 CVM에 전달한다.
사용자 로컬 PC에서는 LLM을 돌리지 않는다.
기본 흐름은 다음과 같다:
사용자 →(암호화)→ Process Controller → per-user process
per-user process는 CVM 내부의 하나의 프로세스이며,
여기에 LLM 파라미터 전체를 read-only 형태로 로드하여 prefill을 실행할 수 있다.
LLM provider는 이 프로세스 내부의 메모리를 볼 수 없다.
✔ 2. 프롬프트는 per-user process 내부에서만 복호화됨
논문 4.1절(Setup)과 4.1.1 ~ 4.1.3에 따르면:
- 사용자 ↔ Process Controller 간 Diffie-Hellman secure channel 생성
- Process Controller가 프롬프트를 해당 사용자 프로세스(per-user process)로 IPC 전달
- 프롬프트는 CVM 밖으로 나간 적이 없으며, LLM provider도 절대 볼 수 없음
즉, 프롬프트는 per-user process 안에서만 평문 상태로 존재한다.
✔ 3. per-user process가 LLM 파라미터를 읽어서 prefill을 수행한다
논문 4.1.2 LLM Parameter Read-only Sharing 부분에 명시되어 있다:
- LLM provider가 모델 파라미터를 CVM으로 전달하면
- Process Controller가 이를 read-only 파일로 저장하고
- per-user process와 서비스 프로세스 모두에게 read-only 공유 권한을 준다
그리고 중요한 점:
per-user process는 “prefill 단계에서만” LLM 파라미터에 접근한다.
따라서,
- per-user process는 full LLM 모델을 사용해서 프롬프트 전체를 forward pass → input KV cache 생성
- 이때 사용자 PC가 모델을 실행하는 것이 아니라
CVM GPU 안에서 모델이 실행됨
✔ 4. 왜 안전한가? (Model Confidentiality 유지)
per-user process가 모델을 읽을 수 있는데 왜 모델이 유출되지 않는가?
논문은 다음 3가지 조치를 설명한다:
① 모델은 read-only 메모리로 매핑
→ 수정도 복사도 불가능.
② per-user process는 네트워크가 완전히 차단됨
→ 외부 네트워크로 모델을 송출할 수 없음.
③ 모든 출력 토큰은 Process Controller가 relay
→ per-user process가 사용자에게 직접 출력 메시지를 보낼 수 없음
→ (모델 파라미터를 몰래 "출력 토큰에 암호화해 보내기" 같은 공격 불가능)
즉, per-user process는 모델을 읽을 수 있지만 유출할 수 없다.
✔ 5. 그래서 KV 캐시는 이렇게 만들어진다
단계별 설명:
① 사용자가 prompt를 보냄
User →(Encrypted)→ Process Controller → per-user process
② per-user process는 LLM 파라미터를 read-only로 로드
- CUDA IPC로 GPU 메모리에서 모델 파라미터를 공유 받음 (copy 없음).
③ per-user process 내부에서 prompt를 Transformer에 넣음
prefill 수행 → input KV(K_in, V_in) 생성
이 KV는 per-user process의 private GPU 메모리/CPU 메모리 안에만 존재.
④ 첫 번째 생성 토큰만 서비스 프로세스로 보냄
per-user에는 네트워크가 없으므로:
per-user process →(IPC)→ Process Controller → service process
⑤ 이후 decode는 SPD로 분할 수행
- per-user: A_in = softmax(Q K_inᵀ) V_in
- service: A_out = softmax(Q K_outᵀ) V_out
- attention 합성은 서비스 프로세스가 수행
이 단계에서는 per-user가 더 이상 모델 파라미터를 보지 않는다.
✔ 6. 중요한 결론
❗(Q1) 사용자가 직접 Transformer inference를 하나요?
아닙니다.
prefill은 CVM 내부의 per-user process가 수행합니다.
❗(Q2) prompt는 누가 읽나요?
오직 per-user process만 읽습니다.
LLM provider는 읽지 못합니다.
❗(Q3) KV 캐시는 어떻게 만들죠?
- input KV(K_in, V_in): per-user process가 생성함 (prefill)
- output KV(K_out, V_out): service process가 생성함 (decode)
❗(Q4) 그래서 prefill은 완전 그대로 Transformer forward인가요?
네. 정확히 같은 forward이며, output invariance를 보장합니다.
SPD는 decode 단계에만 개입합니다.
✔ 7. 그림으로 간단 정리
[CVM 내부]
User Process (프롬프트 비공개)
- 모델 파라미터 read-only 접근
- Prefill 실행 → K_in, V_in 생성
- Decode에서 A_in 계산(Q만 받음)
Service Process (LLM provider 영역)
- 모델 전체 파라미터 소유
- Decode에서 K_out, V_out 관리
- A_out 계산 후 attention 합성
- 토큰 생성
Process Controller
- secure channel
- 네트워크 isolation
- 토큰 relay
✔ 8. 핵심 요약
사용자가 Transformer를 돌리는 것이 아니라,
CVM 내부의 per-user process가 프롬프트를 가지고 prefill을 수행한다.
이 과정에서 프롬프트는 오직 per-user process만 읽으며,
LLM provider에게는 절대 전달되지 않는다.
KV cache는 per-user가 input 부분을 만들고,
service process가 output 부분을 만들며,
attention은 SPD로 정확하게 결합된다.
원하면:
- 실제 메모리 구조(view)
- CUDA IPC 동작 방식
- prefill에서 발생하는 정확한 연산 경로
- per-user → Controller → service 간 IPC 데이터 흐름
- “prompt stealing” 공격이 왜 여기서는 실패하는지
까지 더 깊게 설명해 줄 수 있어.
아주 핵심을 정확하게 찌른 질문이야.
이를 완전히 이해하려면 **“CVM(Confidential VM)에 무엇이 들어가고, 누가 무엇을 볼 수 있으며, 프로세스들이 어떻게 격리되는지”**를 정확하게 정리해야 한다.
아래에서 단계별로 완전히 명확하게 설명할게.
🔥 1. 무엇이 CVM으로 들어가는가?
CVM 내부에는 다음 3가지가 존재한다:
① LLM 모델 파라미터 (LLM provider가 제공함)
- LLM provider가 암호화된 채널로 CVM 내부의 Process Controller에게 전달한다.
- CVM 내부에서 복호화되어 GPU 메모리에 올려진다.
- 단, read-only memory 형태로 per-user process·service process가 공유하여 사용할 뿐,
외부로 유출 불가능.
② Petridish Software Stack (Linux, NVIDIA open driver, Process Controller 등)
- 모두 오픈소스로 제공 → 사용자와 LLM provider 모두 소스 코드를 검증 가능.
③ per-user process + service process
- CVM 내부에서만 실행되며,
- processes 간 메모리는 OS가 강제 격리한다.
즉, LLM provider는 모델 파라미터를 CVM 안으로 넣어주지만,
CVM 내부 메모리를 다시 “볼 수 있는 권한”은 없다.
🔥 2. CVM에서 정확히 어떤 데이터가 전달되는가?
사용자가 CVM으로 전달하는 것은 프롬프트 전체 텍스트다.
하지만 중요한 점은:
프롬프트는 CVM 밖에서는 항상 암호화된 상태로만 이동한다.
즉:
사용자 →(암호화)→ Process Controller → per-user process(여기서만 복호화됨)
LLM provider는 이 통신 경로에 접근할 수 없다.
왜냐하면:
- CVM 내부의 네트워크 통신은 Process Controller가 직접 관리한다.
- per-user process는 네트워크가 완전히 차단됨(Linux network namespace).
- LLM provider는 service process만을 소유하지만, service process는 per-user process의 메모리를 볼 수 없다.
🔥 3. 왜 LLM provider는 프롬프트를 볼 수 없는가?
이게 가장 중요한 구조적 포인트다.
이유 1) LLM provider는 CVM 내부 메모리를 읽을 권한이 없다
CVM은 Confidential Computing 기반(AMD SEV-SNP, NVIDIA GPU CC).
즉:
- 클라우드 제공자도,
- LLM provider도,
- 외부 사용자도,
CVM 메모리 내용을 읽을 수 없다.
CVM은 “암호화된 VM”이라 생각하면 된다.
논문에서도 명시:
“CVM prevents illegal access from outside the CVM”
즉 LLM provider는 “모델 파라미터를 CVM 안으로 넣어줄 뿐, 내부를 다시 들여다볼 수는 없다”.
이유 2) per-user process의 메모리는 service process와도 격리됨
Linux kernel의 process isolation + namespace를 사용한다.
- service process(LLM 제공자 측)는
per-user process의 메모리에 접근할 수 없다. - per-user process가 가진 프롬프트 텍스트와 input KV cache는 완전히 private.
이유 3) LLM provider가 관찰하는 데이터는 딱 2개
- service process가 계산하는 output attention A_out
- 최종 output 토큰들
서비스 프로세스가 받는 정보는:
- Q_new (서비스가 계산한 것)
- per-user process가 보내는 A_in (attention 결과만)
여기엔 프롬프트 원문도, input K/V도 포함되지 않는다.
attention은 정보 손실 매핑이라 원문을 역추적하기 매우 어렵다고 논문에서 언급한다.
🔥 4. 그럼 CVM 안에서 어떻게 prefill이 가능한가?
정확히 이 구조가 설계의 핵심이다.
✔ 4.1 per-user process가 모델을 직접 사용하여 prefill 수행
- per-user process는 read-only 모델 파라미터에 접근 가능.
- 따라서 프롬프트를 LLM에 직접 통과시키며 input KV cache(K_in, V_in) 생성 가능.
즉, per-user process가 LLM을 “사용”할 수는 있지만
LLM을 외부로 빼내거나 유출할 수는 없다.
그 이유:
- 네트워크가 완전히 차단됨
- 메모리 mapping이 read-only
- 사용자에게 직접 데이터를 보낼 수 없음
- 출력은 Controller가 필터링하여 건네줌
✔ 4.2 그런데 모델 파라미터를 per-user process가 가져가면 위험하지 않나?
그럴 수 있지만, 다음 제약 때문에 유출 불가능하다:
- 외부 네트워크가 없음
→ 인터넷으로 모델을 보낼 방법이 없음. - process 간 통신은 Controller IPC만 가능
→ 임의 바이너리 전송 불가. - 출력 토큰은 per-user process가 직접 사용자에게 보내지 않음
→ Controller만 사용자와 talk 가능.
따라서 per-user process는 모델을 “볼 수는 있으나, 밖으로 유출할 수 없다”.
🔥 5. CV cache는 어떻게 유지되는가?
input KV cache (K_in, V_in)
- prefill 단계에서 per-user process가 직접 생성
- per-user process 내부에서만 저장
- service process는 절대 접근 불가
즉:
Input KV cache는 프롬프트와 함께 per-user process에 완전 고립된 상태로 존재한다.
output KV cache (K_out, V_out)
- decode 단계에서 service process가 생성
- 여러 사용자 output KV를 batch로 함께 관리
🔥 6. CVM 안에 모델이 존재해야 한다 = 맞는 말
사용자가 혼동하기 쉬운 포인트는 바로 이것:
CVM 내부에 LLM 모델 자체는 반드시 존재한다.
하지만 CVM 내부에서 실행되는 프로세스는 "외부로 유출할 수 없도록" 격리되어 있다.
즉:
- 모델이 CVM GPU 메모리에 올라가 있으므로
per-user process는 prefill을 수행할 수 있다. - 하지만 이 파라미터는:
- read-only
- CVM 외부 접근 불가
- 네트워크 차단
따라서 모델을 사용하지만 유출할 수는 없다.
🔥 7. 다시 정리
✔ 사용자 프롬프트는 왜 LLM provider가 볼 수 없는가?
- 프롬프트는 CVM 안에서만 복호화된다.
- CVM 메모리는 LLM provider가 접근할 수 없다.
- per-user process 메모리는 service process와도 격리된다.
✔ CVM은 어떻게 LLM 모델로 계산을 하는가?
- LLM provider가 모델 파라미터를 CVM 내부로 전달하지만,
그 후에는 CVM 내부에서만 사용될 뿐 외부에서 읽을 수 없다. - per-user process가 이 파라미터를 사용해 prefill을 수행한다.
✔ input KV cache를 per-user process가 유지할 수 있는 이유?
- per-user process가 프롬프트를 실제로 LLM에 넣어 inference 1회(prefill)를 수행하기 때문.
- 이 과정은 CVM 내부에서 안전하게 진행.
🔥 8. 아주 간단한 최종 요약
[CVM 안]
- LLM 모델 (provider 제공, CVM 내부에서만 존재)
- per-user process (프롬프트 받고 prefill로 input KV 생성)
- service process (output KV 생성 및 SPD 기반 decode)
- Process Controller (네트워크·정보 흐름 통제)
결론:
CVM 안에서는 모델도 프롬프트도 존재하지만,
어떤 외부 주체도(LLM provider 포함) CVM 내부 메모리를 볼 수 없다.
따라서 LLM provider는 프롬프트를 알 수 없다.
원하면 다음도 더 깊게 설명해줄 수 있어:
- “CVM 내부 구조를 그림으로 메모리 맵 형태로 설명”
- “process 간 통신 방식(IPC) 실제 구현 수준 설명”
- “왜 CVM이 LLM provider에게도 보이지 않는지(SEV-SNP·GPU CC 아키텍처 분석)”
- “input attention A_in이 prompt 복원이 불가능한 수학적 이유”
어떤 방식으로 더 파고들고 싶은지 알려줘!
'인공지능 > 논문 리뷰 or 진행' 카테고리의 다른 글
| Privacy AI 관련 조사 3 (0) | 2025.12.03 |
|---|---|
| Privacy AI 관련 조사 2 (1) | 2025.12.02 |
| ACL 2025 - Pretraining Context Compressor for Large Language Models with Embedding-Based Memory (0) | 2025.12.01 |
| Soft Thinking: Unlocking the Reasoning Potential of LLMs in Continuous Concept Space (0) | 2025.12.01 |
| Jasper-Token-Compression-600M Technical Report (0) | 2025.11.28 |