https://arxiv.org/abs/2505.15778
Soft Thinking: Unlocking the Reasoning Potential of LLMs in Continuous Concept Space
Human cognition typically involves thinking through abstract, fluid concepts rather than strictly using discrete linguistic tokens. Current reasoning models, however, are constrained to reasoning within the boundaries of human language, processing discrete
arxiv.org
예전부터 생각만 하던 분야라서....
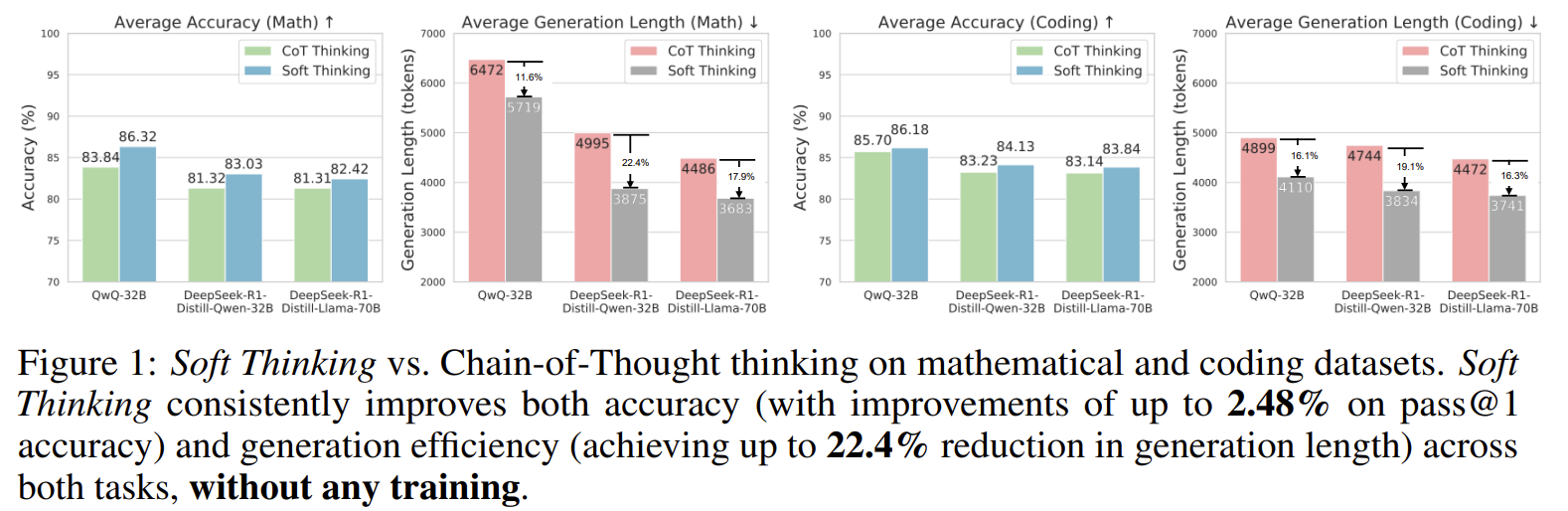
CoT 대비 정확도와 길이 등 모두 나아지는 것을 볼 수 있다.
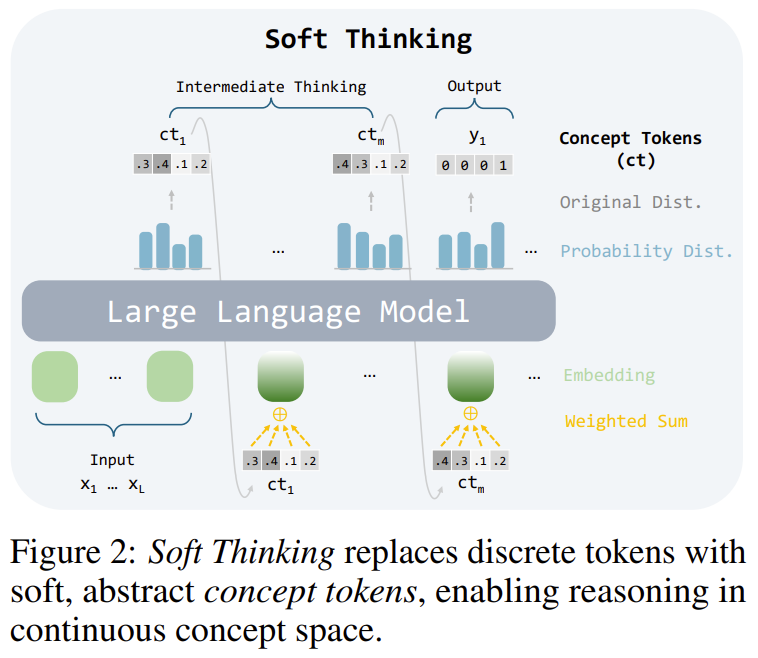
가장 간단하게 표현해준다.
결국 출력되는 확률 분포를 통해 입력되는 토큰을 하나만 하는 것이 아닌 여러 토큰의 분포를 가중하여 넣어준다!
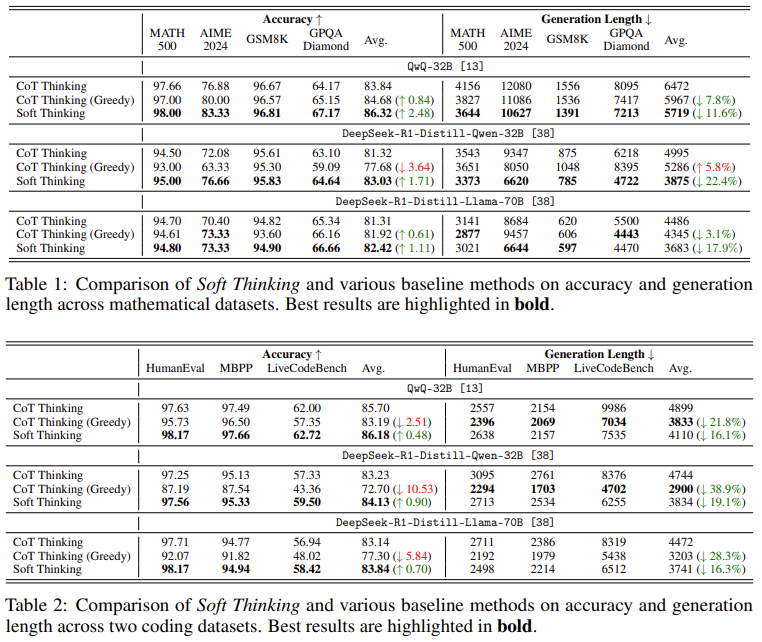
결과도 ㄱㅊ
근데 학습 안하고 이렇게 되는게 맞나...?

이 것만 봐선 엄청 괜찮은 결과가 나타난다.

근데 그리디랑 너무 비슷한 출력이 나와서 이건 좀 봐봐야 겠네요
| 문제 상황 | - 기존 Chain-of-Thought(CoT)는 이산 토큰(discrete tokens) 기반 → 매 step에서 가장 높은 확률의 토큰만 선택하여 하나의 reasoning path에만 의존. - 토큰 분포 전체의 정보가 손실되어 추상적 개념 표현 부족, 추론 과정 좁아짐. - 잘못된 토큰 선택 시 되돌릴 수 없는 path collapse 발생. - 성능을 높이려면 CoT를 길게 생성해야 하므로 토큰 비용·추론 시간 증가. - 연속 공간에서 추론하지 못해 모델의 reasoning 잠재력이 제한됨. |
| 방법론 | Soft Thinking: training-free continuous reasoning 1) Concept Token: LLM의 출력 확률 분포 p 자체를 thinking token으로 사용 (샘플링하지 않음). 2) Continuous Concept Space: p를 토큰 임베딩 E 위에서 확률 가중합하여 연속 임베딩 e~ 생성 → 기존 디코딩에 입력. 3) Soft Thinking Loop: thinking 단계에서 매 step 연속 임베딩을 입력으로 사용하여 여러 reasoning path의 “soft superposition”을 형성. 4) Cold Stop: 엔트로피 기반 종료 규칙(H(p) < τ가 k번 지속)으로 OOD collapse/반복 방지. 5) Answer 단계: thinking 종료 후에는 기존 CoT처럼 discrete token 생성. → 모델 파라미터 업데이트(학습) 없이 inference rule만 바꿔 reasoning 성능 향상. |
| 실험 | Models: QwQ-32B, DeepSeek-R1-Distill-Qwen-32B, DeepSeek-R1-Distill-Llama-70B (모두 최초 학습된 checkpoint 그대로 사용). Datasets: • Math: GSM8K, Math500, AIME 2024, GPQA-Diamond • Code: HumanEval, MBPP, LiveCodeBench Baselines: – Standard CoT(temperature 0.6, 16-sample Pass@1) – Greedy CoT(temperature 0) – Soft Thinking(ours) Hyperparameters: – top-n ∈ {5,10,15,20,30} (모델별 최적 값 선택) – Cold Stop: τ ∈ {0.01~0.2}, k ∈ {128~1024} Metrics: Pass@1, 전체/정답 케이스 토큰 길이 |
| 결과 | 정확도 향상: - Math: QwQ-32B 기준 Standard CoT 대비 +2.48pt, DeepSeek 계열도 +1~2pt. - Code: HumanEval/MBPP/LCBench 전반에서 +0.5~1pt. 토큰 효율성 개선: - 수학: –11% ~ –22% - 코드: –16% ~ –19% Ablation: - COCONUT-style 평균 임베딩은 collapse (성능 0, 길이 max). - Soft Thinking without Cold Stop: collapse 빈도 증가, 길이 비효율적. - Soft Thinking + Cold Stop이 가장 높은 정확도 & 최적의 길이. 정성적 결과: - reasoning 구조 동일 유지하면서 CoT보다 훨씬 간결한 토큰 사용. - 분포 시각화: “탐색 단계(soft)” + “계산 단계(sharp)” 분리 명확. |
| 기여 | 1) 새로운 reasoning 패러다임 제안: discrete token space → continuous concept space로 확장. 2) 완전 training-free 방법: 기존 LLM을 그대로 사용해 성능 향상 가능. 3) 정확도 상승 + 토큰 감소라는 최초의 동시 달성: reasoning cost-effective 제어 가능. 4) 이론적 정당화: Soft Thinking이 path-summation의 선형 근사임을 수학적으로 분석. 5) 일반성 높은 방법: Qwen/LLaMA/RL-distilled 모델 모두에서 효과적. 6) 간단한 엔지니어링: inference-time 변경만으로 재현 가능(SGLang 구현). |
| 한계 | - concept embedding은 모델이 학습 중 본 적 없는 OOD 연속 입력 → collapse 가능성. - Cold Stop은 heuristic 기반이며 최적화된 학습 기반 방법이 아님. - top-n·τ·k 등의 하이퍼파라미터가 휴리스틱 선택에 의존. - thinking 단계만 continuous space로 확장하며, answer 단계는 여전히 discrete. - continuous concept space에 최적화된 학습 기반(bi-modal training) 연구 필요. - 높은 차원의 convex combination이 항상 semantically meaningful한지는 보장되지 않음. |
이 논문은 **“Soft Thinking: 연속 개념 공간(continuous concept space)에서의 추론”**을 제안하는 논문입니다. 아래에서 문제–방법–이론–실험–기여–한계를 체계적으로 정리하겠습니다.
1. 이 논문이 해결하려는 문제
(1) 기존 CoT 추론의 한계
- 언어 토큰에 갇힌 추론
- 현재 LLM의 Chain-of-Thought(CoT)는
→ 매 step마다 하나의 discrete 토큰을 샘플링해 자연어로 추론 과정을 풀어 쓰는 방식. - 즉, 모델은 항상 고정된 토큰 집합(Vocabulary)의 one-hot 토큰만을 다룸.
- 하지만 인간 인지는 단어 자체보다 추상적 개념 수준에서 비언어적 연상·추론을 한다는 신경과학 근거들이 있음.
- 현재 LLM의 Chain-of-Thought(CoT)는
- 단일 경로(single path) 추론
- 매 step에서 하나의 토큰만 선택 → 그 순간 나머지 잠재적인 추론 경로의 확률 질량은 모두 버려짐.
- 수학/코드처럼 난이도 높은 문제에서
- 초반에 잘못된 토큰을 선택하면
- 잘못된 추론 경로에 끝까지 갇히고, 토큰을 많이 소비하면서도 정답에 도달하지 못함.
- 효율성 문제
- 추론 성능을 높이기 위해 CoT 길이(생성 토큰 길이)를 늘리면 성능은 오르지만
→ 계산 비용과 토큰 비용이 크게 증가 (inference-time scaling law). - greedy CoT는 토큰 수를 줄이지만, 성능이 크게 떨어지는 trade-off가 존재.
- 추론 성능을 높이기 위해 CoT 길이(생성 토큰 길이)를 늘리면 성능은 오르지만
요약하면:
- (1) 이산 언어 토큰에 갇혀 추상적 개념을 풍부하게 표현·조작하지 못하고,
- (2) 매 step 하나의 토큰만 선택해 하나의 추론 경로에만 commit,
- (3) 그래서 성능과 토큰 효율성의 trade-off가 강하게 존재한다는 점을 문제로 본다.
2. 핵심 아이디어: Soft Thinking & Continuous Concept Space
이 논문의 핵심은 **“토큰을 하나 뽑지 말고, 분포 전체를 ‘개념 토큰(concept token)’으로 유지한 채 연속 공간에서 추론하자”**입니다.
2.1 Concept Token 정의
- LLM이 어떤 step에서 출력하는 **logits → softmax → 분포 p ∈ Δ_{|V|-1}**를 그대로 사용.
- 정의 1 (Concept Token)
- 해당 step의 어휘 전체에 대한 확률 분포 p 자체를 concept token ct라고 정의:
[
ct := p \in \Delta_{|V|-1}
]
- 해당 step의 어휘 전체에 대한 확률 분포 p 자체를 concept token ct라고 정의:
- 기존 CoT는 argmax(또는 sampling)으로 분포를 하나의 token id로 collapse했다면,
Soft Thinking은 분포 전체를 보존한다는 점이 핵심.
2.2 Continuous Concept Space 정의
- 임베딩 행렬: (E \in \mathbb{R}^{|V|\times d}), k번째 토큰 임베딩 (e^{(k)} = E[k]).
- 정의 2 (Continuous Concept Space)
- 모든 토큰 임베딩의 **확률 가중합(convex combination)**으로 정의:
[
\mathcal{C} = \left{\sum_{k=1}^{|V|} \alpha_k e^{(k)} ; : ; \alpha \in \Delta_{|V|-1} \right} \subset \mathbb{R}^d
]
- 모든 토큰 임베딩의 **확률 가중합(convex combination)**으로 정의:
- 즉,
- 기존: “의미 공간 = d차원 실수 벡터 공간”
- 여기서 제안: “연속 개념 공간 = 모든 토큰 임베딩의 convex hull”
3. Soft Thinking 알고리즘 (추론 과정 step-by-step)
Soft Thinking은 기존 CoT 파이프라인의 “중간 생각 단계(think 단계)”만 바꿉니다. 정답 출력 단계(answer 단계)는 기존처럼 discrete 토큰을 생성합니다.
3.1 기존 CoT 추론 (Preliminary)
- 입력: (x_{1:L}) (문제 텍스트)
- 생각 단계(think tokens) 길이 m, 답변 단계(answer tokens) 길이 n.
- 생각 단계(standard CoT)
- step i에서:
[
t_i \sim p_i = \text{LLM}(e(x_{1:L}), e(t_{1:i-1})) \in \Delta_{|V|-1}
] - 여기서 토큰 id (t_i) 하나를 샘플링.
- ⟨/think⟩ 토큰이 나올 때까지 반복.
- step i에서:
- 답변 단계(standard)
- step j에서:
[
y_j \sim q_j = \text{LLM}(e(x_{1:L}), e(t_{1:m}), e(y_{1:j-1}))
] - 여기서도 discrete 토큰 y_j를 샘플링.
- step j에서:
3.2 Soft Thinking: 중간 생각 단계만 연속 공간으로 변경
Soft Thinking에서는 생각 단계에서만 아래처럼 동작합니다.
Step 1: 개념 토큰 얻기
- 중간 step에서 LLM이 출력한 분포:
[
p \in \Delta_{|V|-1}
] - 이것을 그대로 concept token (ct := p)로 사용.
Step 2: 개념 토큰을 임베딩으로 변환
- 다음 step의 입력 임베딩을 아래처럼 확률 가중합으로 계산:
[
\tilde{e}{\text{next}} = \sum{k=1}^{|V|} ct[k]; e^{(k)}
] - 구현에서는 연산량을 줄이기 위해
- top-k / top-p 필터링 후
- 상위 n개 토큰만 사용해 확률 재정규화 후 가중합 (복잡도 O(n·d)).
Step 3: 이 임베딩을 다음 step 입력으로 사용
- 다음 LLM 호출 시, 입력 시퀀스의 마지막 위치에 **이 연속 임베딩 (\tilde{e}_{\text{next}})**를 붙여서 forward.
- 이 과정이 반복되면서, 모델은
- 각 step에서 여러 가능성을 합성한 추상적 개념을 입력으로 사용
- “여러 reasoning path의 soft한 superposition”을 따라 추론을 진행.
Step 4: 생각 종료 조건 & 답변 모드 전환
- 개념 토큰 p에서 **가장 확률 높은 토큰이 ⟨/think⟩**이면 생각 단계 종료.
- 그 이후부터는 기존 CoT와 동일하게,
→ discrete 토큰을 하나씩 샘플링하며 최종 답변 y_1:n을 생성.
4. Cold Stop: OOD로 인한 collapse 방지 + 효율 향상
연속 개념 임베딩은 **훈련 시 보지 못한 입력(OOD)**이기 때문에,
LLM이 **반복/붕괴(repetition collapse)**에 빠질 수 있습니다. 이를 막기 위해 entropy 기반의 Cold Stop을 도입합니다.
4.1 엔트로피 기반 종료 규칙
- 각 step에서 concept token p에 대해 엔트로피 계산:
[
H(p) = -\sum_{k} p[k]\log p[k]
] - 직관:
- 낮은 엔트로피 → 확률 분포가 sharp → 모델이 매우 확신(“cold”)
- 높은 엔트로피 → 모델이 아직 불확실 (“hot”)
4.2 Cold Stop 알고리즘
- 하이퍼파라미터:
- 엔트로피 threshold: τ
- 연속 step 수: k
- 규칙:
- 만약 (H(p) < \tau) 이면, “low-entropy 카운터”를 +1,
아니면 카운터를 0으로 reset. - 카운터가 k에 도달하면
- 강제로 ⟨/think⟩ 토큰을 삽입하고
→ 생각 단계를 종료, 답변 단계로 전환.
- 강제로 ⟨/think⟩ 토큰을 삽입하고
- 만약 (H(p) < \tau) 이면, “low-entropy 카운터”를 +1,
4.3 효과
- 장점
- OOD 입력으로 인한 무한 반복, collapse를 크게 줄여줌.
- 과도하게 길어진 reasoning chain을 잘라내 토큰 효율을 개선.
- 실험에서는 Cold Stop이 정답 수를 늘리면서도,
전체 평균 토큰 길이를 줄이는 효과가 있음을 보임(§4.5, Table 3).
5. 이론적 분석 요약
논문은 Soft Thinking이 정확한 “경로 합(path-summation)”을 근사하는 방식임을 1차 선형화 관점에서 설명합니다.
5.1 정답 확률의 정확한 경로 전개
- 길이 m의 생각 토큰 t_{1:m}을 모두 marginalize:
[
p(y|x) = \sum_{t_1}!p(t_1|x)\sum_{t_2}!p(t_2|x,t_1)\cdots\sum_{t_m}!p(t_m|x,t_{1:m-1})p(y|x,t_{1:m})
] - 이는 지수적으로 많은 경로를 정확히 합산하는 형태.
5.2 1차 선형화 + 기대값으로 치환
- t_1을 one-hot 벡터로 보고, 그에 대한 기대값이 바로 concept token ct_1:
[
ct_1 = \mathbb{E}[t_1] = \sum_{t_1} p(t_1|x) t_1 = p(\cdot | x)
] - p(y|x,t_1)를 ct_1 주위에서 선형 근사하면:
[
p(y|x) \approx p(y | x, ct_1)
] - 이후 step들에 대해서도 같은 논리를 재귀적으로 적용:
[
p(y|x,ct_1) \approx p(y|x,ct_1,ct_2) \approx \cdots \approx p(y|x,ct_1,\dots,ct_m)
] - 결론:
- Soft Thinking은 각 step에서 분포의 기대값을 쓰는 선형 근사를 통해
원래의 지수적 path-summation을 단일 forward로 근사하는 역할을 한다. - 반면 standard CoT는 각 합을 한 개의 샘플로 대체해서 나머지 경로의 확률 질량을 모두 버리는 방식.
- Soft Thinking은 각 step에서 분포의 기대값을 쓰는 선형 근사를 통해
6. 실험 설정
6.1 벤치마크 데이터셋
- 수학 (총 4개)
- Math500: MATH dataset에서 500개 문제 추출.
- AIME 2024: American Invitational Mathematics Examination 2024 기출.
- GSM8K: 초등 수학 word problem 1,319개.
- GPQA-Diamond: 고난도 graduate-level Q&A subset.
- 코딩 (총 3개)
- HumanEval
- MBPP
- LiveCodeBench: 컨탐 없는 동적 코드 평가; 2024/08–2025/01 구간의 279 문제 사용.
6.2 모델
- QwQ-32B (Qwen 계열, RL로 학습)
- DeepSeek-R1-Distill-Qwen-32B
- DeepSeek-R1-Distill-Llama-70B
→ 서로 다른 아키텍처(Qwen, LLaMA), 크기(32B, 70B), 학습 파이프라인(RL, distillation)에 대해 일반성을 확인.
6.3 비교 Baseline
- Standard CoT Thinking: temperature 0.6, top-k=30, top-p=0.95, 16 샘플 → Pass@1 계산.
- Standard Greedy CoT: temperature=0, single sample.
6.4 Soft Thinking 하이퍼파라미터
- max generation length: 32,768
- Soft Thinking에서:
- concept token 구축시 top-n (n ∈ {5,10,15,20,30})
- Cold Stop:
- entropy threshold τ ∈ {0.01, 0.05, 0.1, 0.2}
- length threshold k ∈ {128, 256, 512, 1024}
- 최적 조합:
- QwQ-32B: n=15
- DeepSeek-R1 계열: n=10
7. 주요 결과
7.1 수학 벤치마크 (Table 1, Page 7)
- QwQ-32B (Math)
- Avg Pass@1:
- CoT: 83.84
- Greedy CoT: 84.68 (+0.84)
- Soft Thinking: 86.32 (+2.48)
- Avg generation length:
- CoT: 6472
- Greedy CoT: 5967 (–7.8%)
- Soft Thinking: 5719 (–11.6%)
- Avg Pass@1:
- DeepSeek-R1-Distill-Qwen-32B (Math)
- Avg Pass@1:
- CoT: 81.32
- Greedy CoT: 77.68 (↓)
- Soft Thinking: 83.03 (+1.71)
- Avg length:
- CoT: 4995
- Greedy CoT: 5286 (↑)
- Soft Thinking: 3875 (–22.4%)
- Avg Pass@1:
- DeepSeek-R1-Distill-Llama-70B (Math)
- Avg Pass@1:
- CoT: 81.31
- Greedy CoT: 81.92
- Soft Thinking: 82.42 (+1.11)
- Avg length:
- CoT: 4486
- Greedy CoT: 4345
- Soft Thinking: 3683 (–17.9%)
- Avg Pass@1:
7.2 코딩 벤치마크 (Table 2, Page 7)
- QwQ-32B (Code)
- Avg Pass@1:
- CoT: 85.70
- Greedy CoT: 83.19 (↓ 2.51)
- Soft: 86.18 (+0.48)
- Avg length:
- CoT: 4899
- Greedy CoT: 3833 (–21.8%)
- Soft: 4110 (–16.1%)
- Avg Pass@1:
- DeepSeek-R1-Distill-Qwen-32B (Code)
- Avg Pass@1:
- CoT: 83.23
- Greedy CoT: 72.70 (↓ 10.53)
- Soft: 84.13 (+0.90)
- Avg length:
- CoT: 4744
- Greedy CoT: 2900 (–38.9%)
- Soft: 3834 (–19.1%)
- Avg Pass@1:
- DeepSeek-R1-Distill-Llama-70B (Code)
- Avg Pass@1:
- CoT: 83.14
- Greedy CoT: 77.30
- Soft: 83.84 (+0.70)
- Avg length:
- CoT: 4472
- Greedy CoT: 3203
- Soft: 3741 (–16.3%)
- Avg Pass@1:
핵심:
- 모든 모델·모든 데이터셋에서 Pass@1 향상
- 동시에 토큰 수 11–22% 수준 감소
8. Ablation: Concept Token 전략 & Cold Stop 효과
8.1 Concept Token 전략 비교 (Table 3, Page 9)
AIME 2024, LiveCodeBench에서 QwQ-32B 사용.
- COCONUT-TF (training-free COCONUT: 이전 hidden state를 그대로 embedding으로 사용)
- Accuracy: 0.0 / 0.0
- Length: 항상 max length(32,768)까지 반복 → 완전히 collapse.
- Average Embedding (top-5 단순 평균)
- Accuracy: AIME 6.66, LiveCodeBench 7.49
- Generation length(전체): 30k 토큰 이상 → 매우 비효율.
- Soft Thinking w/o Cold Stop
- AIME: 73.33, LiveCodeBench: 56.98
- Generation length(전체): 12,991 / 13,705
- Correct에 대한 평균 길이: 9,457 / 6,877
- Soft Thinking w/ Cold Stop
- AIME: 83.33, LiveCodeBench: 62.72
- Generation length(전체): 11,445 / 12,537 (더 짧음)
- Correct 길이: 10,627 / 7,535 (조금 길어짐)
해석:
- Cold Stop이 없으면:
- 맞힌 문제에서는 짧지만,
- 틀린 문제에서 OOD collapse가 발생해 전체 평균 길이를 크게 키움.
- Cold Stop을 켜면:
- collapse를 잘라내 전체 평균 길이를 줄이면서
- 어려운 문제(긴 reasoning 필요)를 더 많이 풀어 정답 수가 증가.
- 또한 COCONUT처럼 “hidden state = embedding”을 그대로 쓰는 방식은
대형 모델에서는 공간 mismatch로 사실상 동작하지 않음을 실험적으로 보여줌.
9. 질적 분석 (Qualitative)
9.1 텍스트 비교 (Figure 3, Page 8)
- 예시 문제: 43 × 34
- 둘 다 정답 1,462에 도달.
- Standard CoT: 157 tokens
- Soft Thinking: 96 tokens
- Soft Thinking이 논리 구조는 유지하면서도 훨씬 간결한 설명을 생성함.
(중복된 수식 설명, 불필요한 부연이 줄어듦)
9.2 확률 분포 시각화 (Figure 4, Page 9)
- 각 step에서 top-k 토큰과 확률을 시각화.
- 관찰:
- “탐색 구간”(예: 1–3, 13–14, 18–20 step): 토큰 분포가 비교적 평평 → 여러 경로를 동시에 고려.
- 정확 계산 구간: 숫자/연산 토큰은 거의 one-hot 분포 → 수치 계산은 명확하게 결정.
- 예를 들어 36–37 step에서 “4로 곱할까, 30으로 곱할까” 두 옵션을 비교하면서 점차 4에 확신을 싣고, 42 step에서 실제로 “by 4”를 선택.
- 요약:
Soft Thinking은 문장 구조/전략에 대해서는 다양한 경로를 soft하게 탐색하면서,
수학적 계산 자체는 sharp한 분포로 수행해 유연성과 정확성을 동시에 달성.
10. 논문의 기여와 한계 정리 표
마지막으로, 나중에 다시 볼 수 있도록 한 페이지 표로 정리합니다.
항목 내용| 문제 상황 | LLM의 CoT 추론이 이산 자연어 토큰에 묶여 있고, 매 step 하나의 토큰만 선택하여 단일 경로로만 추론 → 추상적 개념 표현이 제한되고, 잘못된 경로에 빠지면 토큰 낭비 및 성능 저하. CoT 길이를 늘리면 성능은 오르지만 비용·토큰 수가 크게 증가. |
| 핵심 아이디어 | (1) LLM이 각 step에서 출력하는 전체 확률 분포 p를 **concept token(ct)**으로 간주. (2) 임베딩 공간에서는 모든 토큰 임베딩의 확률 가중합 (\tilde e = \sum p[k]e^{(k)})을 사용해 **continuous concept space(토큰 임베딩 convex hull)**에서 추론. (3) 생각 단계만 이러한 연속 임베딩으로 진행하고, 정답 단계는 기존 토큰 기반 디코딩 유지. (4) 엔트로피 기반 Cold Stop으로 OOD collapse 방지 및 토큰 효율 개선. |
| 방법론 – 추론 알고리즘 | ① 입력 x를 받고, 생각 단계에서 LLM이 출력한 분포 p를 그대로 concept token ct로 사용. ② top-k/top-p 필터 후 상위 n개의 토큰 임베딩을 p로 가중합해 연속 개념 임베딩 (\tilde e) 계산. ③ 이 임베딩을 다음 step의 입력 마지막에 삽입해 forward. ④ 최상위 토큰이 ⟨/think⟩일 때 생각 종료 → 답변 단계로 전환. ⑤ 답변 단계에서는 기존 CoT처럼 discrete 토큰 y_j를 하나씩 생성. ⑥ 매 step 엔트로피 H(p)를 측정해 τ 이하가 k번 연속되면 Cold Stop으로 ⟨/think⟩ 강제 삽입. |
| 이론 분석 | 정답 확률 (p(y |
| 실험 설정 – 데이터 | 수학: Math500, AIME 2024, GSM8K, GPQA-Diamond. 코딩: HumanEval, MBPP, LiveCodeBench(2024/08–2025/01 279문제). |
| 실험 설정 – 모델 | QwQ-32B(RL 기반 수학 강화), DeepSeek-R1-Distill-Qwen-32B, DeepSeek-R1-Distill-Llama-70B(대형 distillation 모델). 모두 기존 공개 checkpoint 사용, 추가 학습 없음(훈련 불요). |
| 평가 지표 | Pass@1 (16 샘플 또는 1 샘플에서 정답 비율), generation length (정답에 도달한 케이스 기준 토큰 수, 전체 평균 토큰 수 모두 분석). |
| 주요 결과 – 정확도 | 모든 모델·벤치마크에서 Soft Thinking이 CoT 대비 Pass@1 증가. 예: QwQ-32B 수학 평균 83.84 → 86.32(+2.48), AIME2024에서 +6.45pt. 코드에서도 평균 +0.48~0.90pt 개선. |
| 주요 결과 – 토큰 효율 | 수학: QwQ-32B –11.6%, DeepSeek-Qwen-32B –22.4%, DeepSeek-Llama-70B –17.9%. 코드: –16.1%, –19.1%, –16.3%. Greedy CoT도 토큰은 줄지만, 정확도는 크게 하락하는 반면, Soft Thinking은 정확도와 효율성을 동시에 개선. |
| Ablation – Concept Token 전략 | COCONUT-TF(이전 hidden state를 그대로 embedding으로 사용)는 대형 모델에서 완전 실패(정확도 0, max length). 단순 average embedding도 성능이 낮고 길이가 매우 길다. 반면 Soft Thinking(확률 가중합) + Cold Stop은 정확도와 길이를 동시에 크게 개선. |
| Ablation – Cold Stop | Soft Thinking without Cold Stop은 정답 케이스에서는 짧지만, collapse로 인해 전체 평균 길이가 길어짐. Cold Stop을 켤 경우 collapse를 방지해 전체 평균 길이를 줄이면서, 더 어려운 문제까지 풀어 정답 수 증가. |
| 정성적 분석 | 예시(43×34)에서 Soft Thinking은 CoT와 같은 정답에 도달하지만 설명이 157 → 96 토큰으로 더 간결. 분포 시각화에서 텍스트 구조 단계는 분포가 넓고, 숫자 계산 단계는 거의 one-hot → “경로 탐색(soft) + 숫자 계산(sharp)”의 분리된 역할이 관찰됨. |
| 주요 기여 | 1) 연속 개념 공간에서의 추론(Soft Thinking): 토큰 분포를 concept token으로 보고 임베딩 convex combination으로 추론하는 새로운 패러다임 제안. 2) 훈련 불요(training-free): 어떤 LLM에도 CoT pipeline에 쉽게 plug-in 가능. 3) 성능·효율 동시 개선: 수학/코드 벤치마크에서 Pass@1과 토큰 수 모두 개선. 4) 이론적 정당화: path-summation에 대한 선형 근사 관점으로 Soft Thinking의 의미를 해석. 5) 실용 구현: SGLang 엔진에 soft-thinking 모드, weighted embedding, entropy-based Cold Stop를 실제로 구현해 고속 추론 가능. |
| 한계 및 향후 과제 | 1) 현재 LLM은 **concept token(연속 mixture embedding)**을 학습 중에 본 적이 없어, Soft Thinking은 본질적으로 OOD 입력에 해당 → collapse 가능성 존재, Cold Stop은 완화책일 뿐 근본 해결은 아님. 2) concept token의 최적 구성(top-n, τ, k 등)은 여전히 휴리스틱. 3) training-free라서, 장기적으로는 concept token을 고려하는 **학습 기반 방법(Soft Thinking-aware pretraining/fine-tuning)**이 필요. 4) 현재는 생각 단계에만 적용되므로, 답변 단계까지 연속 개념 공간을 확장하는 방향도 연구 여지가 있음. |
추가로, 이 논문을 실제 코드/실험에 적용해 보고 싶다면:
- SGLang과 유사하게
- decoder 출력 logits → softmax → 분포 p
- top-n / top-p 필터 후 임베딩 가중합 (\tilde e) 계산
- generation loop에서 input_ids 대신 inputs_embeds를 업데이트하는 방식으로
**“think 단계용 generation 루프”**를 별도로 구성하면, 바로 실험 가능할 것입니다.
원하면, 지금 사용하는 Llama/Qwen 기반 코드에 맞춰 Soft Thinking + Cold Stop용 generation 루프/샘플러 pseudo-code를 단계별로 짜서 정리해 드리겠습니다.
이 논문에서는 별도의 학습(gradient update)이 없습니다.
Soft Thinking 자체는 완전히 “추론(inference)-only”, training-free 방법입니다.
그래서 “이 논문이 어떤 식으로 모델을 학습시켰는가?”라고 물으면, 답은
✔ 기존에 이미 학습된 reasoning LLM(QwQ, DeepSeek-R1 계열)을 그대로 가져와서,
그 위에 Soft Thinking이라는 새로운 디코딩/추론 규칙만 얹어서 평가했다.
입니다.
그럼에도 불구하고, “학습”이라는 관점에서 정리해볼 수 있는 부분들을 단계적으로 나눠 설명하면 다음과 같습니다.
1. 이 논문 안에서의 학습: 없다 (Training-free)
1.1 Soft Thinking 자체는 완전히 결정적(decision rule)인 추론 규칙
Soft Thinking에서 새로 정의한 것들은 전부 결정적 수식/알고리즘입니다.
- 개념 토큰(concept token)
[
ct_i = p_i \in \Delta_{|V|-1}
]- i번째 step에서 LLM이 뱉는 확률 분포 p_i를 그대로 ct_i로 사용 (softmax 결과 그 자체).
- 별도의 파라미터 없음, 학습 없음.
- 연속 개념 임베딩(continuous concept embedding)
[
\tilde e_i = \sum_{k=1}^{|V|} ct_i[k] , e^{(k)}
]- 임베딩 행렬 (E)는 원래 LLM의 embedding layer.
- Soft Thinking은 그냥 이 E 위에서 확률 가중합을 계산할 뿐, E 자체는 업데이트하지 않음.
- Cold Stop 규칙
- 엔트로피 (H(p) = -\sum p \log p)가 threshold τ 아래로 k번 연속 떨어지면 ⟨/think⟩ 강제 삽입.
- 역시 고정된 수식 + 수치 threshold, gradient 기반 최적화 없음.
요약:
Soft Thinking은 기존 LLM의 파라미터를 단 1 step도 업데이트하지 않고,
출력 분포를 어떻게 다음 step 임베딩으로 넣을지에 대한 새로운 디코딩 규칙만 정의합니다.
2. 사용한 LLM들의 학습(= 이 논문 밖에서 이미 수행된 학습)
이 논문이 직접 학습한 것은 없지만, 사용한 모델들은 모두 “reasoning에 특화되도록” 사전에 학습되어 있습니다.
논문에서는 그 과정을 요약만 하고, 자세한 내용은 각 원 논문(QwQ, DeepSeek-R1 등)에 위임합니다.
2.1 QwQ-32B
- Qwen 계열 기반의 32B parameter “reasoning LLM”
- 원 논문에 따르면 (간단히 요약하면)
- 기본 언어모델 사전학습(Pretraining)
- 웹 텍스트/코드 등 대규모 데이터로 causal LM 학습.
- 지도 미세조정(SFT)
- GSM8K, MATH 등 수학/코딩/추론 데이터로 step-by-step CoT 답안을 학습.
- 강화학습(RL, GRPO 등)
- 모델이 생성한 답변에 대해 정답 여부 + 형식 등을 보상으로 해 policy 개선.
- 기본 언어모델 사전학습(Pretraining)
- 이 논문에서는 QwQ-32B를 “미리 학습된 reasoning용 LLM”으로서 그대로 로드만 하고,
- Soft Thinking / greedy CoT / standard CoT 등 서로 다른 디코딩 규칙만 비교합니다.
- QwQ 파라미터에 대한 추가 학습은 전혀 하지 않습니다.
2.2 DeepSeek-R1-Distill-Qwen-32B / DeepSeek-R1-Distill-Llama-70B
- DeepSeek-R1: 대형 RL 기반 reasoning 모델(teacher).
- Distill-Qwen-32B / Distill-Llama-70B:
- teacher의 출력을 따라가도록 knowledge distillation으로 학습된 student 모델들.
- 학습 구성(원 논문 기준 요약):
- teacher 모델(RL로 강화된 reasoning LM)을 먼저 만든 뒤,
- student 모델(Qwen-32B, Llama-70B)을 teacher의 응답에 맞추도록 지도 학습(SFT/diff distillation).
- 이 논문에서는 역시 이들 Distill 모델을 그대로 가져와:
- “기존 CoT 디코딩 vs Soft Thinking 디코딩”으로만 비교.
- Distill 모델에 대한 추가 fine-tuning이나 RL은 전혀 하지 않습니다.
즉, 이 논문이 하는 일은 “새로운 학습 기법을 제안하는 것”이 아니라,
이미 학습된 reasoning LLM 위에서 추론 규칙을 바꾸면 성능·효율이 어떻게 달라지는지를 분석하는 것입니다.
3. 하이퍼파라미터 선택 방식 (일종의 “튜닝”)
학습은 없지만, Soft Thinking에 필요한 하이퍼파라미터는 실험을 통해 선택합니다. 이는 gradient 기반 학습이 아니라 grid search / validation 기반 선택입니다.
3.1 Concept Token 구성: top-n
- 개념 임베딩 계산 시,
- 전체 vocab(|V|)를 다 쓰면 계산량이 너무 크므로,
- top-n 토큰만 남기고 확률 재정규화 후 가중합.
- n 값 후보: {5, 10, 15, 20, 30}
- 각 모델·데이터셋에서 몇 개의 validation/개발 문제를 사용해
- Pass@1 + 길이 trade-off를 보고 적당한 n 선택.
- 결과:
- QwQ-32B: n=15가 best
- DeepSeek-R1-Distill 계열: n=10이 best
→ 이것은 “어떤 n이 좋더라” 수준의 실험적 선택이지,
모델 파라미터를 업데이트하는 학습은 아닙니다.
3.2 Cold Stop: 엔트로피 threshold τ, 연속 길이 k
- 후보:
- τ ∈ {0.01, 0.05, 0.1, 0.2}
- k ∈ {128, 256, 512, 1024}
- 역시 개발셋 몇 개를 기준으로
- collapse를 줄이면서,
- 정답률과 평균 길이의 균형이 좋은 조합을 선택.
이런 튜닝은 “model-free policy search”에 더 가깝고,
우리가 흔히 말하는 “모델 파라미터 θ를 gradient로 업데이트하는 학습”과는 다릅니다.
4. 구현 관점에서의 “학습 아닌 최적화”
논문 말미에서 Soft Thinking을 SGLang 엔진에 구현했다고 밝힙니다.
- 구현 내용:
- 기존 sampling loop에서
- logits → softmax → concept token(p)
- top-n 필터 후 embedding weighted sum
- 이를 다음 step의 inputs_embeds에 삽입
- Cold Stop 로직 추가
- 기존 sampling loop에서
- 이 과정은 코드 레벨에서는 “최적화/엔지니어링 작업”이지,
- 모델의 weights를 바꾸는 의미에서의 학습은 전혀 하지 않습니다.
5. 정리: 이 논문의 “학습 방법”을 한 줄로 쓰면
- 이 논문은 새로운 학습 알고리즘을 제안하지 않는다.
- 대신, 이미 학습된 reasoning LLM(QwQ·DeepSeek-R1-distill)에 대해
- 중간 추론 단계에서 토큰 분포 전체를 개념 토큰으로 보고,
- 임베딩 convex combination을 사용하는 **새로운 추론 규칙(Soft Thinking)**과
- 엔트로피 기반 종료 규칙(Cold Stop)을 붙여서
- 추론 성능과 토큰 효율을 동시에 개선했음을 실험으로 보인다.
만약 “그렇다면 Soft Thinking을 학습과 연계해서 써보려면 어떻게 해야 할까?”가 궁금하다면,
- (1) concept token을 입력으로 받도록 LLM을 재학습하는 방법
- (2) pretraining 단계에서부터 continuous concept space에 노출시키는 방법
- (3) Soft Thinking-aware RL (예: reward가 concept space trajectory까지 반영되도록)
같은 방향으로 **“Soft Thinking-aware pretraining/fine-tuning 스킴”**을 설계하는 아이디어도 같이 정리해 줄 수 있습니다.
이 논문에서는 별도의 학습(gradient update)이 없습니다.
Soft Thinking 자체는 완전히 “추론(inference)-only”, training-free 방법입니다.
그래서 “이 논문이 어떤 식으로 모델을 학습시켰는가?”라고 물으면, 답은
✔ 기존에 이미 학습된 reasoning LLM(QwQ, DeepSeek-R1 계열)을 그대로 가져와서,
그 위에 Soft Thinking이라는 새로운 디코딩/추론 규칙만 얹어서 평가했다.
입니다.
그럼에도 불구하고, “학습”이라는 관점에서 정리해볼 수 있는 부분들을 단계적으로 나눠 설명하면 다음과 같습니다.
1. 이 논문 안에서의 학습: 없다 (Training-free)
1.1 Soft Thinking 자체는 완전히 결정적(decision rule)인 추론 규칙
Soft Thinking에서 새로 정의한 것들은 전부 결정적 수식/알고리즘입니다.
- 개념 토큰(concept token)
[
ct_i = p_i \in \Delta_{|V|-1}
]- i번째 step에서 LLM이 뱉는 확률 분포 p_i를 그대로 ct_i로 사용 (softmax 결과 그 자체).
- 별도의 파라미터 없음, 학습 없음.
- 연속 개념 임베딩(continuous concept embedding)
[
\tilde e_i = \sum_{k=1}^{|V|} ct_i[k] , e^{(k)}
]- 임베딩 행렬 (E)는 원래 LLM의 embedding layer.
- Soft Thinking은 그냥 이 E 위에서 확률 가중합을 계산할 뿐, E 자체는 업데이트하지 않음.
- Cold Stop 규칙
- 엔트로피 (H(p) = -\sum p \log p)가 threshold τ 아래로 k번 연속 떨어지면 ⟨/think⟩ 강제 삽입.
- 역시 고정된 수식 + 수치 threshold, gradient 기반 최적화 없음.
요약:
Soft Thinking은 기존 LLM의 파라미터를 단 1 step도 업데이트하지 않고,
출력 분포를 어떻게 다음 step 임베딩으로 넣을지에 대한 새로운 디코딩 규칙만 정의합니다.
2. 사용한 LLM들의 학습(= 이 논문 밖에서 이미 수행된 학습)
이 논문이 직접 학습한 것은 없지만, 사용한 모델들은 모두 “reasoning에 특화되도록” 사전에 학습되어 있습니다.
논문에서는 그 과정을 요약만 하고, 자세한 내용은 각 원 논문(QwQ, DeepSeek-R1 등)에 위임합니다.
2.1 QwQ-32B
- Qwen 계열 기반의 32B parameter “reasoning LLM”
- 원 논문에 따르면 (간단히 요약하면)
- 기본 언어모델 사전학습(Pretraining)
- 웹 텍스트/코드 등 대규모 데이터로 causal LM 학습.
- 지도 미세조정(SFT)
- GSM8K, MATH 등 수학/코딩/추론 데이터로 step-by-step CoT 답안을 학습.
- 강화학습(RL, GRPO 등)
- 모델이 생성한 답변에 대해 정답 여부 + 형식 등을 보상으로 해 policy 개선.
- 기본 언어모델 사전학습(Pretraining)
- 이 논문에서는 QwQ-32B를 “미리 학습된 reasoning용 LLM”으로서 그대로 로드만 하고,
- Soft Thinking / greedy CoT / standard CoT 등 서로 다른 디코딩 규칙만 비교합니다.
- QwQ 파라미터에 대한 추가 학습은 전혀 하지 않습니다.
2.2 DeepSeek-R1-Distill-Qwen-32B / DeepSeek-R1-Distill-Llama-70B
- DeepSeek-R1: 대형 RL 기반 reasoning 모델(teacher).
- Distill-Qwen-32B / Distill-Llama-70B:
- teacher의 출력을 따라가도록 knowledge distillation으로 학습된 student 모델들.
- 학습 구성(원 논문 기준 요약):
- teacher 모델(RL로 강화된 reasoning LM)을 먼저 만든 뒤,
- student 모델(Qwen-32B, Llama-70B)을 teacher의 응답에 맞추도록 지도 학습(SFT/diff distillation).
- 이 논문에서는 역시 이들 Distill 모델을 그대로 가져와:
- “기존 CoT 디코딩 vs Soft Thinking 디코딩”으로만 비교.
- Distill 모델에 대한 추가 fine-tuning이나 RL은 전혀 하지 않습니다.
즉, 이 논문이 하는 일은 “새로운 학습 기법을 제안하는 것”이 아니라,
이미 학습된 reasoning LLM 위에서 추론 규칙을 바꾸면 성능·효율이 어떻게 달라지는지를 분석하는 것입니다.
3. 하이퍼파라미터 선택 방식 (일종의 “튜닝”)
학습은 없지만, Soft Thinking에 필요한 하이퍼파라미터는 실험을 통해 선택합니다. 이는 gradient 기반 학습이 아니라 grid search / validation 기반 선택입니다.
3.1 Concept Token 구성: top-n
- 개념 임베딩 계산 시,
- 전체 vocab(|V|)를 다 쓰면 계산량이 너무 크므로,
- top-n 토큰만 남기고 확률 재정규화 후 가중합.
- n 값 후보: {5, 10, 15, 20, 30}
- 각 모델·데이터셋에서 몇 개의 validation/개발 문제를 사용해
- Pass@1 + 길이 trade-off를 보고 적당한 n 선택.
- 결과:
- QwQ-32B: n=15가 best
- DeepSeek-R1-Distill 계열: n=10이 best
→ 이것은 “어떤 n이 좋더라” 수준의 실험적 선택이지,
모델 파라미터를 업데이트하는 학습은 아닙니다.
3.2 Cold Stop: 엔트로피 threshold τ, 연속 길이 k
- 후보:
- τ ∈ {0.01, 0.05, 0.1, 0.2}
- k ∈ {128, 256, 512, 1024}
- 역시 개발셋 몇 개를 기준으로
- collapse를 줄이면서,
- 정답률과 평균 길이의 균형이 좋은 조합을 선택.
이런 튜닝은 “model-free policy search”에 더 가깝고,
우리가 흔히 말하는 “모델 파라미터 θ를 gradient로 업데이트하는 학습”과는 다릅니다.
4. 구현 관점에서의 “학습 아닌 최적화”
논문 말미에서 Soft Thinking을 SGLang 엔진에 구현했다고 밝힙니다.
- 구현 내용:
- 기존 sampling loop에서
- logits → softmax → concept token(p)
- top-n 필터 후 embedding weighted sum
- 이를 다음 step의 inputs_embeds에 삽입
- Cold Stop 로직 추가
- 기존 sampling loop에서
- 이 과정은 코드 레벨에서는 “최적화/엔지니어링 작업”이지,
- 모델의 weights를 바꾸는 의미에서의 학습은 전혀 하지 않습니다.
5. 정리: 이 논문의 “학습 방법”을 한 줄로 쓰면
- 이 논문은 새로운 학습 알고리즘을 제안하지 않는다.
- 대신, 이미 학습된 reasoning LLM(QwQ·DeepSeek-R1-distill)에 대해
- 중간 추론 단계에서 토큰 분포 전체를 개념 토큰으로 보고,
- 임베딩 convex combination을 사용하는 **새로운 추론 규칙(Soft Thinking)**과
- 엔트로피 기반 종료 규칙(Cold Stop)을 붙여서
- 추론 성능과 토큰 효율을 동시에 개선했음을 실험으로 보인다.
만약 “그렇다면 Soft Thinking을 학습과 연계해서 써보려면 어떻게 해야 할까?”가 궁금하다면,
- (1) concept token을 입력으로 받도록 LLM을 재학습하는 방법
- (2) pretraining 단계에서부터 continuous concept space에 노출시키는 방법
- (3) Soft Thinking-aware RL (예: reward가 concept space trajectory까지 반영되도록)
같은 방향으로 **“Soft Thinking-aware pretraining/fine-tuning 스킴”**을 설계하는 아이디어도 같이 정리해 줄 수 있습니다.
좋습니다. 최근 Soft Thinking: Unlocking the Reasoning Potential of LLMs in Continuous Concept Space (이하 Soft Thinking) 와 유사한 맥락에서 나온 연구들, 그리고 Soft Thinking이 갖는 장단점과 다른 접근들과의 차이를 아래처럼 정리했습니다.
✅ 주요 관련 연구 & 방법론들
방법론 / 연구 핵심 아이디어 / 접근 방식| Training Large Language Models to Reason in a Continuous Latent Space (일명 “COCONUT / continuous latent reasoning”) | LLM이 discrete token 생성 대신, latent/hidden-state (representation) 공간에서 reasoning chain을 형성하도록 학습/추론하는 방법. 즉, reasoning을 토큰화된 자연어가 아닌 연속 잠재 표현(latent vectors)의 흐름으로 수행. (DSBA) |
| SynAdapt: Learning Adaptive Reasoning in Large Language Models via Synthetic Continuous Chain-of-Thought (2025) | continuous-CoT (continuous chain-of-thought, CCoT)를 학습 타겟으로 삼아 LLM을 fine-tuning함. synthetic continuous reasoning trace를 생성하여, discrete reasoning보다 효율성과 정확성의 균형을 맞추려는 시도. (arXiv) |
| (전통적) Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (CoT) + Self-Consistency Improves Chain of Thought Reasoning in Language Models (Self-Consistency) 등 | 복잡한 추론 문제에 대해 “중간 사고 과정(rationale, reasoning chain)”을 자연어로 생성하게 하는 prompting 방식. 여러 경로를 샘플링하고 최종 답변 일관성(consistency)을 기준으로 선택하는 방식으로 정확성 개선. (Spring Lab) |
| (또 다른 trend) Program-of-Thought Prompting (PoT) | 단순 자연어 reasoning 대신, 중간 단계를 코드 또는 실행 가능한 프로그램으로 생성하고 실제 연산을 외부 도구(예: 파이썬 실행기)에 맡기는 접근. 복잡한 수학/계산 작업에서 계산 오류를 줄이고 정확성을 확보. (위키백과) |
⚖️ Soft Thinking vs 관련 접근 — 장단점 & 차이점
Soft Thinking의 강점
- Training-free: 별도의 fine-tuning이나 gradient update 없이, 기존 LLM 위에서 바로 적용 가능. 즉, 이미 학습된 모델에 “추론 룰만 바꾸는” 방식. (arXiv)
- 추론 경로의 soft 병렬 탐색: discrete token 하나를 고르는 대신, vocabulary 전체에 대한 확률 분포를 유지하면서 연속 임베딩(“concept token”)을 다음 입력으로 사용하는 덕분에, 여러 가능한 reasoning path들을 soft하게 동시에 고려. 이론적으로는 path-summation의 근사. (OpenReview)
- 효율성과 성능의 양립: 논문에서 수학/코드 벤치마크에서 기존 CoT 대비 accuracy 향상 + 토큰 수/연산량 감소. (arXiv)
- 언어의 한계 극복 가능성: discrete token이라는 언어 단위의 제약을 넘어서, 더 풍부하고 추상적인 개념 표현이 가능하다는 인지적 직관을 컴퓨터 모델에 반영. (arXiv)
Soft Thinking의 한계 및 위험점
- OOD (Out-Of-Distribution) / 안정성 문제: concept token, 즉 “확률 가중합 임베딩”은 모델이 학습 시 보지 못한 형태의 입력이므로, 반복 generation 중 embedding이 붕괴하거나 degenerate된 벡터로 치우칠 가능성 있음. 논문에서는 이를 막기 위해 “entropy-based Cold Stop” 규칙을 도입. (arXiv)
- 근본적으로 근사에 의존: Soft Thinking은 discrete path-summation을 “연속 공간에서의 expectation + 선형 근사”로 바꾸는 것. 하지만 reasoning 과정이 본래 비선형일 경우(예: branching, symbolic manipulation, discrete combinatorial steps)엔 approximation error가 클 수 있음.
- 개념의 해석성 / 설명성 문제: discrete CoT은 사람이 읽을 수 있는 reasoning chain(rationale)을 제공하지만, Soft Thinking에서 중간 thought은 사실상 “벡터의 흐름”이기 때문에 사람이 중간 reasoning을 이해하거나 점검하기 어렵다.
- 복잡한 제어/튜닝 필요: top-n token 수, entropy threshold, Cold Stop step 수 등 hyperparameter가 많아 튜닝이 필요하며, 이는 작업마다 재조정이 필요할 수 있다.
🔄 비교: Soft Thinking vs Other Methods (COCONUT, SynAdapt, CoT/PoT 등)
관점 Soft Thinking Continuous-latent reasoning (예: COCONUT) / 학습-기반 CCoT (예: SynAdapt) Discrete CoT / Self-Consistency / PoT| 추론 공간 | 연속 concept embedding space (probability-weighted embedding convex hull) | Latent state / hidden-state space (hidden vectors) | Discrete natural language tokens (or code tokens) |
| 학습 필요성 | 없음 — training-free | 보통은 fine-tuning / 학습이 포함됨 (latent reasoning 학습) | 없음 (prompting만) 또는 SFT / RL fine-tuning (reasoning-specialized LLMs) |
| 추론 경로 탐색 방식 | Soft 병렬 + expectation (근사) | 병렬 latent path, implicit / learned | 샘플링 기반 경로 탐색 (Self-Consistency) / deterministic code generation (PoT) |
| 해석성 / 설명성 | 낮음 — 중간 벡터는 사람이 읽기 어려움 | 낮음 — latent representation은 opaque | 높음 — 사람/툴이 읽고 검토 가능한 자연어 (또는 코드) |
| 효율성 (토큰/연산) | 상대적으로 높음 — 토큰 생성 절감, embedding 연산 중심 (arXiv) | 매우 높을 가능성 — token generation 거의 없음, latent forward 중심 (DSBA) | 상대적으로 낮음 — 많은 token 생성 필요, 특히 복잡한 reasoning chain에서는 더 많음 |
| 안정성 / 일반성 | hyperparameter 민감 + OOD 취약 가능성 존재 | 학습 안정성 / generalization 문제 — latent reasoning이 학습된 분포 밖에서 얼마나 견고한지 의문 | 상대적으로 견고, 익숙한 token 기반 logic / 코드 기반 절차 사용 가능 |
🎯 나의 연구 관점에서 참고할 점 & 가능성
당신이 지금 “LLM robustness, adversarial perturbation, hybrid embedding + generation, security/attack 저항성” 등에 관심이 있으므로, Soft Thinking 또는 continuous-latent reasoning 계열은 다음과 같은 연구 가능성과 도전점을 던집니다:
- 추론 경로의 은닉화(hidden reasoning path): Soft Thinking의 경우, 중간 reasoning이 vector로 남기 때문에 adversarial injection (예: prompt injection, token-level perturbation) 공격이 탐지/변형하기 어려울 수 있습니다. 즉, chain-of-thought처럼 사람이 볼 수 있는 “이중화된 reasoning trace”가 없기 때문에, 보안/프라이버시 측면에서 새로운 리스크 + 기회를 동시에 만듭니다.
- 토큰-레벨 공격보다 embedding-level 공격 탐지 어려움: adversarial token perturbation이 아닌, embedding space에서의 subtle perturbation이나 distributional shift가 attack vector가 될 수 있으며 — 모델이 훈련된 분포에 없는 concept embedding에 대해 어떻게 반응할지가 중요합니다.
- 효율-안정성-정밀성 trade-off 연구: Soft Thinking은 효율과 성능 양립을 목표하지만, 근사에 기반해 있으므로 특정 태스크(예: 심볼릭, 논리, 기호 조작)에선 한계가 있을 수 있습니다. 이를 보완하려면 continuous reasoning-aware fine-tuning, hybrid discrete + continuous reasoning, 또는 mixed 방식(coarse reasoning in latent + discrete final answer) 같은 연구가 유망합니다.
- 설명 가능성(explainability) / 투명성 이슈: embedding 수준의 reasoning은 사람이 직관적으로 검토/이해하기 어렵기 때문에, model introspection, representation analysis, 또는 latent reasoning trace를 human-interpretable form으로 변환하는 연구가 중요합니다.
✅ 요약
- Soft Thinking은 discrete token 기반 reasoning의 제약(한 경로 선택, 비효율성, 표현력 제한)을 continuous embedding space + soft-path summation이라는 혁신적인 방식으로 해결하려는 training-free 추론 규칙.
- 이와 유사하지만 “latent reasoning을 학습(fine-tuning) / representation-level reasoning chain 생성”을 목표로 한 연구들 (예: COCONUT, SynAdapt) 이 존재하며, 이들은 token-generation 비용을 더욱 줄이고 효율성을 높이는 방향을 지향.
- 반면, 전통적인 CoT, Self-Consistency, PoT 등은 여전히 “사람/툴이 읽을 수 있는 reasoning trace”를 제공하고, 안정성과 해석성 측면에서 강점.
- Soft Thinking 및 continuous reasoning은 당신이 관심 가진 “robustness, adversarial-aware LLM, embedding-based attacks/defenses, 효율-보안 균형” 관점에서 매우 흥미로운 출발점이 될 수 있으며 — 다만 해석성, 안정성, 근사 오차 등에 대한 심층 연구가 필요합니다.
원한다면, 최근 1–2년 내에 나온 논문들 중 Soft Thinking / continuous reasoning / hybrid reasoning 계열을 포함한 **최신 연구 목록(with major 결과 + 벤치마크)**를 뽑아서 같이 정리해줄게요.
아주 핵심을 정확하게 짚었어.
Soft Thinking에서 어떤 hidden state를 재조정하느냐는 논문의 방법론을 이해하는 데 결정적인 포인트다.
논문의 본문과 수식 구조를 기반으로 결론부터 말하면:
✅ **Soft Thinking은 “출력단의 hidden state”가 아니라
“입력단의 embedding layer를 지난 hidden state(=입력 임베딩)”를 재조정한다.**
즉, **LLM 내부의 hidden state(hᵢ)**를 수정하는 것이 아니라
다음 토큰 step의 입력을 연속 임베딩으로 바꿔서 넣는 방식이다.
📌 1. Soft Thinking이 재조정하는 대상은 “입력 임베딩(inputs_embeds)”
논문에서 Continuous Concept Embedding을 정의할 때:
[
\tilde e_i = \sum_{k=1}^{|V|} p_i[k] \cdot e^{(k)}
]
여기서 e^(k)는 **토큰 임베딩(embedding layer의 lookup 결과)**이다.
따라서 Soft Thinking은:
- LLM의 출력 logits → softmax → 확률 분포 pᵢ
- pᵢ를 embedding matrix E 위에서 convex combination
- 입력 embedding을 새로 만들어서 다음 step 입력으로 넣는다
즉, LLM은 다음과 같이 동작하게 됨:
previous_inputs_embeds → LLM → logits → p
↓
weighted embedding (continuous)
↓
next_inputs_embeds (재조정된 입력) → LLM
여기서 재조정되는 것은 입력으로 들어가는 임베딩이다.
📌 2. “출력단 hidden state”는 건드리지 않는다
LLM의 마지막 레이어(hidden state hᵢ)에서 우리는 logits만 가져온다:
[
p_i = \text{softmax}(W \cdot h_i)
]
그리고 hᵢ 자체는 변하지 않는다.
즉:
- last hidden state(hᵢ)
- attention stack 내부의 hidden state들
이 부분은 전혀 수정되지 않음.
Soft Thinking이 하는 일은:
✔ 출력단의 hᵢ에서 pᵢ를 계산하고
✔ pᵢ로부터 새로운 입력 embeddings을 만들고
✔ 이것을 다음 step의 inputs_embeds로 넣는 것
📌 3. Soft Thinking의 진짜 구조
아키텍처 관점에서 보면 다음과 같다.
기존 CoT:
tokens → embedding → transformer → logits → argmax → next token
Soft Thinking:
tokens → embedding → transformer → logits → softmax → pᵢ
↓
continuous embedding = Σ pᵢ[k] e(k)
↓
next_inputs_embeds = concat(…, continuous embedding)
↓
embedding bypass → transformer → next logits
여기서 체크할 점:
■ continuous embedding은 embedding layer의 output 공간에 존재
→ 즉, "입력단 hidden state"와 동일한 공간
→ LLM의 내부 hidden state와는 다른 레벨
■ LLM 내부 hidden state는 변경되지 않음
→ 수정되는 것은 “다음 step의 input embedding”만
📌 4. 왜 입력단 임베딩을 건드리는 방식인지?
1) LLM 내부 hidden state를 바꾸는 것은 구조적·수치적으로 불안정
- transformer 내부의 hidden state는 레이어마다 정규화·attention 등 구조적 흐름이 있음
- 중간 레이어 hidden state를 직접 재조정하면 모델이 쉽게 collapse하거나 divergence
2) 반대로 입력 임베딩은 “LLM이 자연스럽게 처리”하도록 할 수 있음
- token embedding matrix는 본래 모델이 처리하도록 학습된 공간
- convex combination으로 초기 입력을 주는 것은 가장 안정적
📌 5. 논문에서도 명시적으로 “inputs_embeds” 방식임
수식과 알고리즘 설명에서 Soft Thinking이 사용하는 공간은 다음과 같음:
- 임베딩 공간(embedding space, continuous concept space)
- **토큰 임베딩 e^(k)**의 convex 조합
- 개념 임베딩 (\tilde e_i)는 LLM의 embedding layer output과 동일한 공간에 있음
즉, LLM forward의 첫 번째 레이어 입력을 바꾸는 것임.
📌 최종 결론
✔ Soft Thinking은 “출력 logits으로 embedding을 재조정한다"
✔ 재조정되는 것은 LLM 입력단의 임베딩(outputs of embedding layer)
✔ LLM 내부의 hidden state는 전혀 건드리지 않는다
✔ continuous concept embedding은 다음 step의 inputs_embeds 역할
원하면 이 구조를 바탕으로
- 당신의 Hybrid Encoder-Decoder 모델에서 Soft Thinking을 적용하는 코드
- “입력 embedding 기반 generation loop” 템플릿
- transformers 기반 구현
까지 정확하게 만들어줄게.
'인공지능 > 논문 리뷰 or 진행' 카테고리의 다른 글
| Privacy AI 관련 조사 1 (0) | 2025.12.02 |
|---|---|
| ACL 2025 - Pretraining Context Compressor for Large Language Models with Embedding-Based Memory (0) | 2025.12.01 |
| Jasper-Token-Compression-600M Technical Report (0) | 2025.11.28 |
| WaterMax: breaking the LLM watermark detectability-robustness-quality trade-off (0) | 2025.11.25 |
| Watermark under Fire: A Robustness Evaluation of LLM Watermarking (0) | 2025.11.25 |