https://aclanthology.org/2025.acl-long.1394/
Pretraining Context Compressor for Large Language Models with Embedding-Based Memory
Yuhong Dai, Jianxun Lian, Yitian Huang, Wei Zhang, Mingyang Zhou, Mingqi Wu, Xing Xie, Hao Liao. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025.
aclanthology.org
긴 컨텍스트 처리하는데 드는 비용과 메모리 사용량이 매우 큼! => LLM 구조는 그대로 유지하며 긴 컨텍스트를 효율적으로 압축해 downstream LLM에게 제공할 수 있는 독립형 모듈이 필요
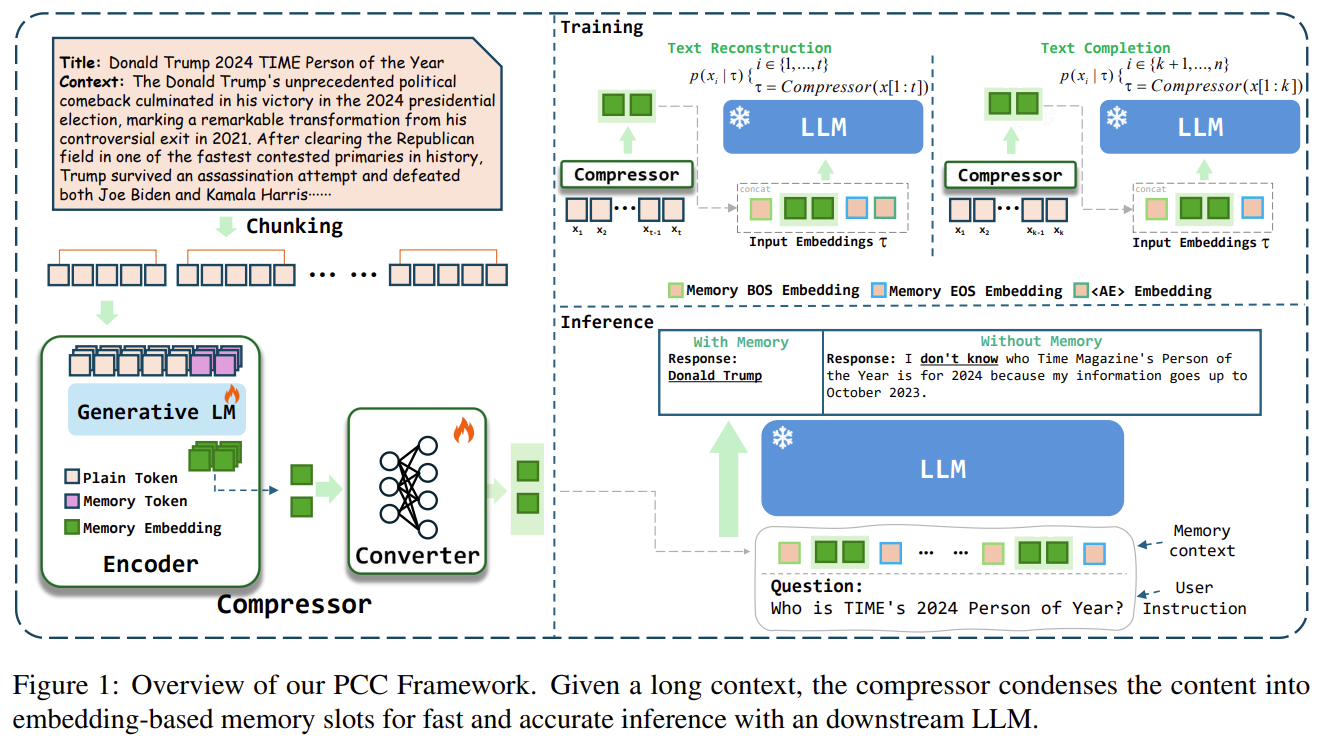
여기서도 문구 압축하고 재건하는 과정이 있네요
Long context -> Chunking -> Compressor(memory encoder -> converter) -> Inference

Pre-trained를 위해선 범용 웹 데이터가 필요합니다 ㅎㅎ
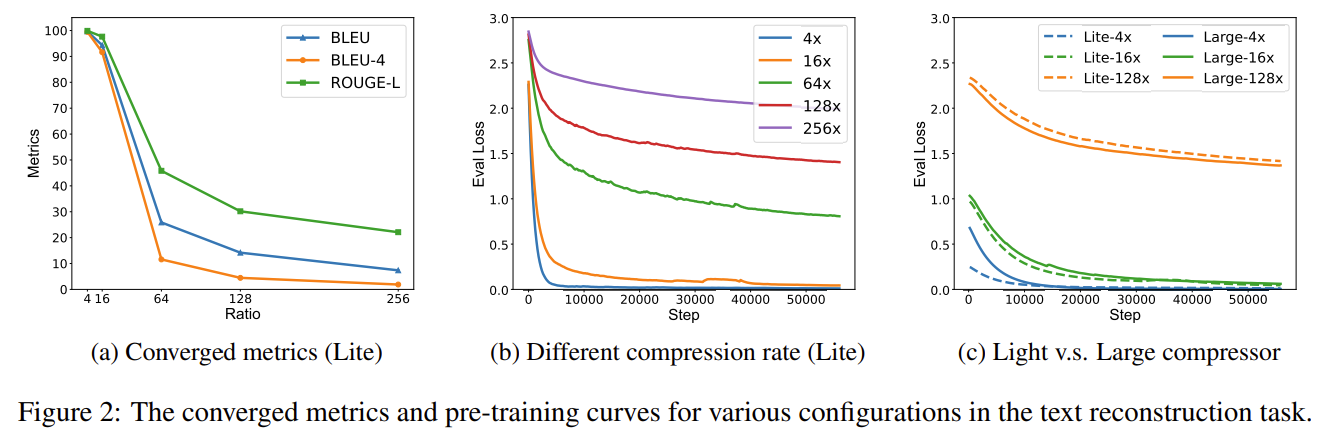
압축률이 증가할 수록 품질은 급격하게 떨어진다!
BUT 16은 확실하게 괜찮네요
Compresso의 영향도 확실히 있는데 그건 뭐 어쩔 수 없으니....
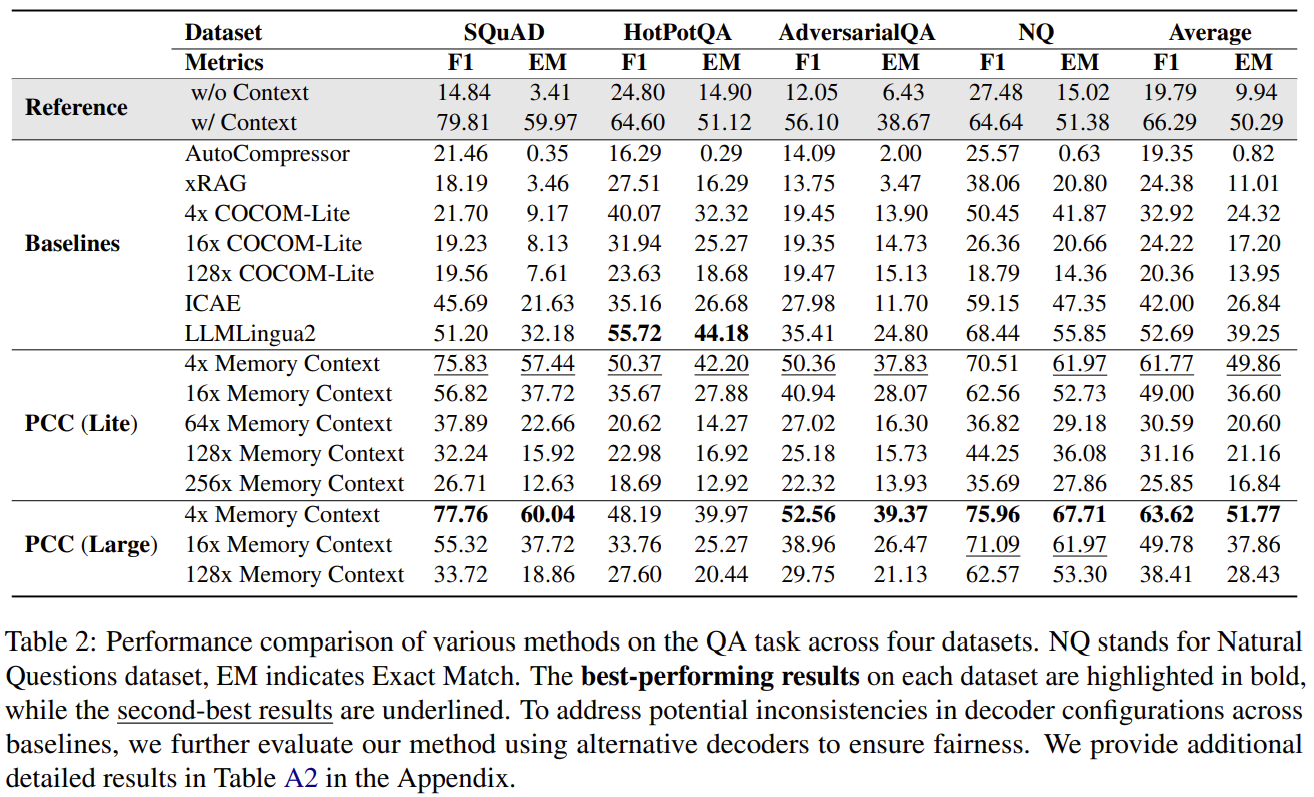
기존 베이스라인에 비해 높은 성능을 내는 것을 볼 수 있다.
LLMLingua2 - 중요하지 않은 토큰을 제거하는 방식
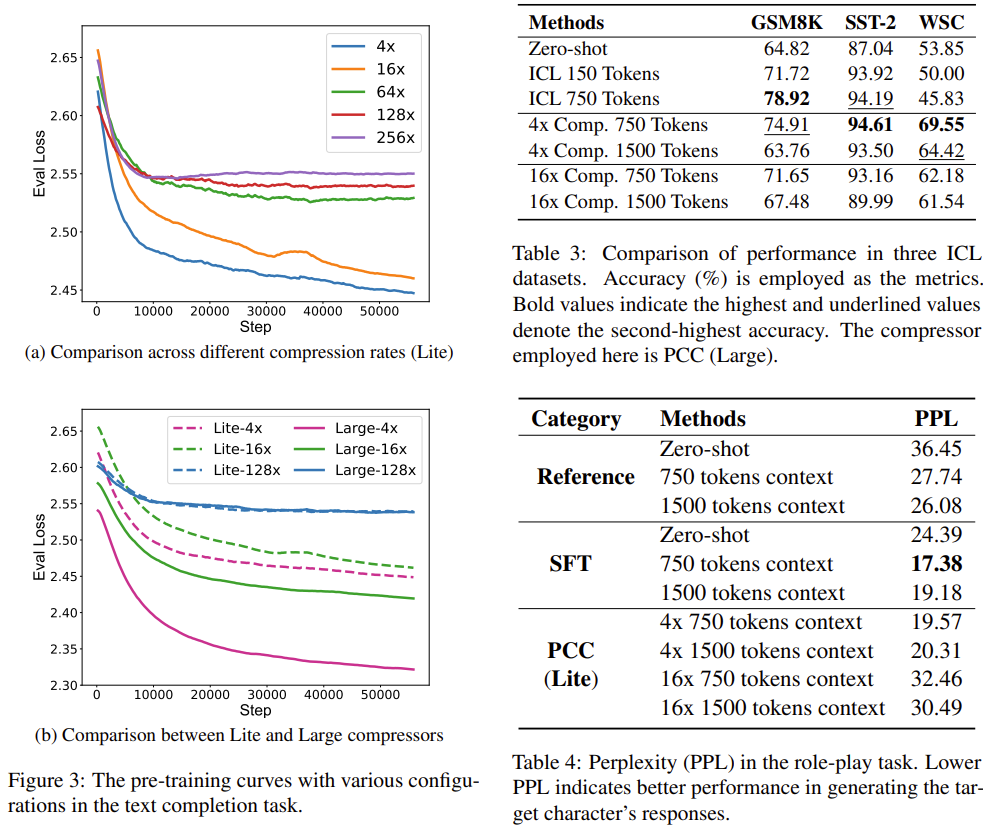
| 문제 상황 | • LLM의 긴 컨텍스트 처리 비용이 O(n²)로 폭증하여 RAG / ICL / Role-playing 등에서 비효율 • LLM 구조를 수정하지 않고 “외부에서 컨텍스트를 압축해 넣는 방식”이 필요함 • 기존 explicit 압축(LLMLingua)과 implicit 압축(COCOM/ICAE)은 정보 손실·범용성 부족 |
| 핵심 아이디어 / 방법론 | 1) Decoupled Compressor-LLM Framework - LLM은 완전 freeze, Compressor만 학습 - Memory Encoder + Converter 구조로 어떤 LLM에도 Memory slot을 연결 가능 2) Memory Encoder - GPT2-Large(Lite), Llama-3-8B(Large) 기반 decoder-only 구조 - 입력 끝에 <mem_i> 토큰 삽입→해당 hidden state를 memory slot로 사용 3) Memory Converter - 2-layer MLP + RMSNorm + GELU - Memory embedding → Target LLM embedding space로 정렬 4) 두 가지 Pretraining Objective (1) Text Reconstruction (Auto-Encoding): memory로 원문 전체 복원 (2) Text Completion (Auto-Regressive): memory + prefix로 뒷부분 생성 → 두 loss를 λ=0.5로 결합 5) Two-Stage Pretraining • Stage1: 짧은 문장(128 tokens), 4× 압축, 32M tokens (warm-up) • Stage2: 긴 문장(256 tokens), 5B tokens, reconstruction+completion 동시 학습 |
| 학습 데이터 | Pretraining: FineWeb 5B tokens - Stage1: 19M 샘플 중 32M tokens 사용 - Stage2: 전체 5B tokens Fine-tuning: - SQuAD (QA domain) → 86,821 train / 5,928 test - GSM8K (ICL reasoning) → 6,725 train / 748 test - HPD (Role-playing) → 987 train / 110 test |
| 실험 구조 | 1) Pretraining Analysis: 압축률(4×, 16×, 64×, 128×, 256×)별 reconstruction quality, convergence 2) RAG-based QA: SQuAD / HotPotQA / AdversarialQA / NQ 3) In-Context Learning: GSM8K / SST-2 / WSC 4) Role-playing: Harry Potter Dialogue 5) Generalization across LLMs: Llama-3-8B, Mistral-7B, Qwen2.5-7B, Phi-3.5 |
| 주요 결과 | Reconstruction • 4×, 16×: BLEU ≈ 100, 98 → 원문 복원 가능 • 64×↑: 정보 손실 심각, 복원 불가 RAG QA • Full context F1=66.29 • PCC Large 4×: F1=63.62 (~96%) • Baseline(LLMLingua2=52.69, ICAE=42.00, COCOM<40) 대비 압도적 성능 ICL • 4× compression이 explicit 750-token ICL보다 성능 우수 • WSC에서 최고 성능 기록(69.55) Role-playing • 4× compression이 few-shot role-play보다 낮은 perplexity 다양한 LLM에서 Generalization • Mistral / Qwen / Phi에서도 4× memory가 모두 성능 개선을 만듦 |
| 핵심 기 | 1) 범용 Universal Compressor 제안 — 어떤 LLM 앞에도 memory를 prepend해 사용 가능 2) Dual-objective Pretraining (Reconstruction+Completion)의 필요성 실증 3) Compress ratio에 대한 정량적 가이드 제시 — 4× / 16×가 최적 4) Implicit compression 연구의 새로운 스탠더드를 제시 5) 다양한 task와 여러 LLM에서 generalize되는 최초의 범용 implicit compressor |
| 한계 | • Pretraining이 매우 compute-heavy: 현재 8B 모델까지 실험 • 256× 같은 extreme compression은 정보 손실로 성능 저하 • 모든 segment를 동일 압축률로 처리 → 향후에는 adaptive compression 필요 • Downstream adaptation 시 encoder+converter 일부는 fine-tuning 필요(완전 freeze 불가) |
| PCC Lite (GPT2-Large 기반) 특징 | • 모델이 작아 cost-efficient • 4× 압축에서는 Large와 거의 동일한 downstream 성능 • 16× 이상에서는 Large 대비 reconstruction/QA 성능 조금씩 떨어짐 • 실제 deployment 시 가장 practical한 선택 (메모리·비용 대비 성능 비율이 높음) |
| 실험에서 드러난 핵심 포인트 요약 | • Reconstruction quality가 downstream QA 성능과 1:1로 연동됨 • Memory slot은 단순 summary가 아니라 “LLM이 바로 읽을 수 있는 latent context representation”이어야 함 • 4×=full-context 대체 수준 / 16×=효율·성능 균형 / 64×↑=정보 부족 • Compressor 크기보다 압축률이 더 큰 영향 |
아래는 “Pretraining Context Compressor for Large Language Models with Embedding-Based Memory” 논문을 기반으로, 연구자로서 바로 실험·모델링에 활용할 수 있도록 문제 상황 → 방법론 → 실험 → 결과 → 기여 → 한계까지 체계적으로 정리한 전문 요약입니다.
(모든 내용은 업로드된 PDF 기반으로 작성함)
📌 논문 요약
Pretraining Context Compressor for Large Language Models with Embedding-Based Memory (PCC)
ACL 2025 Long Paper
1. 문제 상황 (Problem)
LLM이 긴 컨텍스트를 처리하는 데 필요한 비용과 메모리 사용량이 매우 크다.
특히:
- Self-attention 특성상 O(n²) 비용 증가 → 긴 문서 RAG, ICL, 대화 기록 등에서 비효율
- Edge device·저사양 GPU에서는 긴 컨텍스트 inference가 어려움
- 기존 long-context 확장 방식은 LLM 구조를 바꾸거나 재훈련이 필요함
따라서 “LLM 구조는 그대로 유지하면서, 긴 컨텍스트를 효율적으로 압축해 downstream LLM에게 제공할 수 있는 독립형 모듈”이 필요했다.
2. 핵심 아이디어 (Contribution Summary)
논문이 제안한 **PCC(Pretraining Context Compressor)**는:
✔ LLM 바깥에서 동작하는 독립형 compressor
- Original context → 소수의 dense memory slots
- Memory slots만 downstream LLM 입력 앞에 붙여 넣으면 됨
- LLM 자체는 freeze, 구조 수정 없음
✔ 두 가지 사전학습 목표를 결합
- Auto-Encoding (Text Reconstruction)
- Auto-Regressive Completion (Next-token prediction)
→ 압축된 memory가 기억 + 추론 지원을 함께 수행하도록 설계
✔ Converter 모듈로 다양한 LLM과 호환
- Memory encoder output → target LLM embedding space로 정렬
- 2-layer MLP + RMSNorm
✔ 4× 또는 16× 압축이 가장 실용적
- 4×: 원문과 거의 동일한 정보 유지
- 16×: 속도 개선 + 정확도 유지
- 64× 이상: 급격한 정보 손실
3. 방법론 (Methodology)
📌 전체 구조 (Fig. 1 기반 설명, p.3)
Context → Memory Encoder → Memory Slots → Converter → LLM
3.1 Memory Encoder
- GPT2-Large 또는 Llama3-8B 기반의 decoder-only transformer
- 입력 뒤에 <mem_1> … <mem_m> 토큰을 추가
- 마지막 layer에서 해당 토큰의 hidden state를 memory embedding으로 사용
3.2 Memory Converter
- Memory dims → LLM embedding dims
- 2-layer MLP, RMSNorm + GELU
- LLM tokenizer/embedding과 분리된 범용 모듈
3.3 Pretraining Objective
1) Text Completion (Auto-Regressive)
[
L_{TC} = -\frac{1}{n-k} \sum_{i=k+1}^{n} \log p(x_i | h_e, x_{k:i-1})
]
2) Text Reconstruction (Auto-Encoding)
- <AE> 토큰을 사용해 문장 전체 재구성
[
L_{TR} = -\frac{1}{n} \sum \log p(x_i | h_e, , x_{1:i-1})
]
3) Combined Loss
[
L = \lambda L_{TC} + (1-\lambda)L_{TR} \quad (\lambda = 0.5)
]
3.4 Pretraining Strategy
- Stage 1: 짧은 문장(128 tokens), 4x 압축, reconstruction 중심 (32M tokens)
- Stage 2: 긴 문장(256 tokens), 5B tokens, completion + reconstruction
4. 실험 구성 (Experiments)
📌 Pretraining 모델
- PCC Lite: GPT2-Large 기반
- PCC Large: Llama-3-8B 기반 (LoRA r=64)
- LLM Decoder (Frozen): Llama-3-8B-Instruct
📌 Downstream Task
- RAG QA (SQuAD, HotPotQA, AdvQA, NQ)
- In-Context Learning (GSM8K, SST-2, WSC)
- Role-Playing (Harry Potter Dialogue)
- LLM generalization: Mistral, Qwen2.5, Phi-3.5 등 다양한 LLM과 호환성 테스트
5. 주요 결과 (Results)
5.1 Pretraining
- 4x / 16x Reconstruction BLEU는 거의 perfect
- 4x: BLEU ≈ 100
- 16x: BLEU ≈ 98.8
- 64x 이상: reconstruction 급격히 품질 저하
Fig. 2 & Fig. 3 (p.5–7) 핵심 관찰
- Compression rate↑ → convergence difficulty↑
- Completion task는 모델 capacity 영향이 큼
- Pretraining이 없으면 QA 성능 직격타 (계산적 2~3배 하락)
5.2 RAG QA (Table 2, p. 6)
Llama3-8B 기준 Average F1
Method Avg F1| Full context | 66.29 |
| PCC Large 4x | 63.62 |
| PCC Lite 4x | 61.77 |
| LLMLingua2 | 52.69 |
| ICAE | 42.00 |
| COCOM 4x | 32.92 |
| AutoCompressor | 19.35 |
→ PCC Large 4x가 거의 full-context에 근접한 최고 성능
5.3 In-Context Learning (Table 3)
4x compression은 explicit 750-token ICL보다 더 잘 나옴
- GSM8K: 4x 750 tokens → 74.91
- ICL 750 tokens → 78.92 (약간 낮지만 비슷)
- WSC: 4x 750 tokens → 69.55 (최고 성능)
5.4 Role-Playing (Table 4)
- 4x compression이 explicit 750 token prompt보다 더 낮은 perplexity
- 16x는 zero-shot 보다는 좋고 few-shot보다는 떨어짐
5.5 다른 LLM과의 호환성 (Table 5)
- Mistral7B / Qwen2.5 / Phi3.5 모두에서 4x 압축 시 성능 상승
→ PCC는 “범용 Memory Compressor” 역할 가능
6. 기여 (Contributions)
- Decoupled universal compressor
- LLM 구조 수정 없이 컨텍스트 메모리 생성
- Dual-objective pretraining (Reconstruction + Completion)
- Memory가 기억 + 생성 모두 지원
- Comprehensive study
- Compression rate
- Model size
- Memory boundary token
- Pretraining ablation
- 4×, 16×가 앞으로 compression 표준값이 될 근거 제시
- 8개 데이터셋, 3개 도메인에서 SOTA baseline 초월
7. 한계 (Limitations)
논문 p.10–11 기반:
- 큰 모델(70B) 이상 compressor 실험 불가
- 256× 압축에서 정보 손실 문제 해결 어려움
- 모든 segment를 동일 비율로 압축하는 것은 suboptimal
- 미래 연구: adaptive compression rate
- 다양한 LLM에 연결하려면
- converter + encoder 모두 살짝 fine-tuning 필요
- 이상적으론 converter만 tuning하는 방향이 필요
8. 전체 내용을 한눈에 보는 요약표
항목 내용| 문제 | 긴 컨텍스트 처리 시 비용·메모리 폭증, LLM 구조 수정이 필요함 |
| 목표 | LLM을 freeze한 상태에서 범용 memory 기반 context compressor 개발 |
| 방법론 | Memory encoder + converter / dual pretraining (reconstruction + completion) |
| Pretraining | 5B tokens, 두 단계 학습, Llama3-8B를 decoder로 freeze |
| Compression Rate | 4×·16× 최적 / 64×↑는 정보 손실 |
| 실험 | RAG QA, ICL, role-playing, multi-LLM generalization |
| 결과 | 대부분 task에서 4× compression은 full-context에 매우 근접한 성능 |
| 기여 | Universal, decoupled, pretrained memory compressor의 가능성 제시 |
| 한계 | 고압축(256×)의 정보 손실, segment-adaptive compression 미탐구 |
필요하시면,
- 전체 그림 기반의 시각적 구조 정리
- 코드 수준에서 compressor 구현 설명
- HEGA/Hybrid EncDec 모델에 memory compressor 적용 전략
도 이어서 정리해 드릴게요.
'인공지능 > 논문 리뷰 or 진행' 카테고리의 다른 글
| Privacy AI 관련 조사 2 (1) | 2025.12.02 |
|---|---|
| Privacy AI 관련 조사 1 (0) | 2025.12.02 |
| Soft Thinking: Unlocking the Reasoning Potential of LLMs in Continuous Concept Space (0) | 2025.12.01 |
| Jasper-Token-Compression-600M Technical Report (0) | 2025.11.28 |
| WaterMax: breaking the LLM watermark detectability-robustness-quality trade-off (0) | 2025.11.25 |