https://arxiv.org/abs/2306.04744
WOUAF: Weight Modulation for User Attribution and Fingerprinting in Text-to-Image Diffusion Models
The rapid advancement of generative models, facilitating the creation of hyper-realistic images from textual descriptions, has concurrently escalated critical societal concerns such as misinformation. Although providing some mitigation, traditional fingerp
arxiv.org
하필 vision을...
https://github.com/kylemin/WOUAF
GitHub - kylemin/WOUAF: WOUAF: Weight Modulation for User Attribution and Fingerprinting in Text-to-Image Diffusion Models (CVPR
WOUAF: Weight Modulation for User Attribution and Fingerprinting in Text-to-Image Diffusion Models (CVPR 2024) - kylemin/WOUAF
github.com
git도 다행히 존재합니다.

데이터 베이스에 사용자마다 고유한 지문 벡터를 생성해서 저장하여 누군지 찾을 수 있게 함
디코더 가중치에 이진 벡터를 채널별 스케일로 만들어 곱함 -> 사용자 별로 다른 가중치를 갖는 모델이 만들어짐
이제 Fingerprint Decoding network를 통해 지문 복원 가능

디코더만 학습해서 지문(유저 정보)이 숨겨진 이미지를 얻는다

이미지에 차이가 거의 없다.

| 문제 상황 | 공개 SD 계열은 사후(free-standing) 지문/워터마크 모듈을 코드 한 줄로 우회 가능 → 악용 시 사용자 귀속(Attribution)이 어려움. 배포자가 모델 자체에 사용자별 식별 신호를 넣어 책임 추적을 가능하게 하는 방법이 필요. |
| 핵심 아이디어 | 가중치 변조(weight modulation)로 디코더 D의 합성곱 가중치에 사용자 지문 ϕ에서 유도된 채널별 스케일 (u)를 곱해 지문 삽입: (W^{ϕ}_{i,j,k}=u_j ⋅ W_{i,j,k}). 변조는 디코더에만 적용(ϵθ 미변조). |
| 구성 요소 | (1) 지문 인코딩: ϕ → 매핑 네트워크 M + 층별 Affine (A_\ell) → (u). (2) 디코더 D(변조 대상). (3) 지문 복원기 F: ResNet-50, 이미지에서 ϕ 복구. |
| 학습 목표/손실 | ① 지문 복원 손실 (L_ϕ): F(D(ϕ,z))가 모든 비트를 맞히도록 전비트 BCE(ϕ는 학습 시 베르누이 샘플). ② 품질 보존 (L_{quality}): 원본-지문삽입 이미지 간 지각 거리 최소화. ③ 최종: (λ₁=λ₂=1). |
| 데이터 & 생성 설정 | 학습: MS-COCO Karpathy split 미세조정. 평가: COCO test + LAION-Aesthetics. 샘플러: Euler (T = 20), 기본 CFG=7.5(DDIM/스텝/CFG 변화는 부록). |
| 학습법/구현 포인트 | StyleGAN2-ADA의 weight-mod 설계 채택 매핑 M=FC 2층. 후처리 강건 훈련을 위해 Kornia로 미분가능 변환 구현(Stable Signature 비교 시도 동일 변환으로 교체). 세부 하이퍼파라미터는 부록. |
| 평가 지표/프로토콜 | Attribution Acc.(비트 일치율; 임계치 기반 판정), FID(품질), CLIP-score(텍스트-이미지 정합). 다양한 소스 이미지/생성 설정에 대해 일반화 확인. |
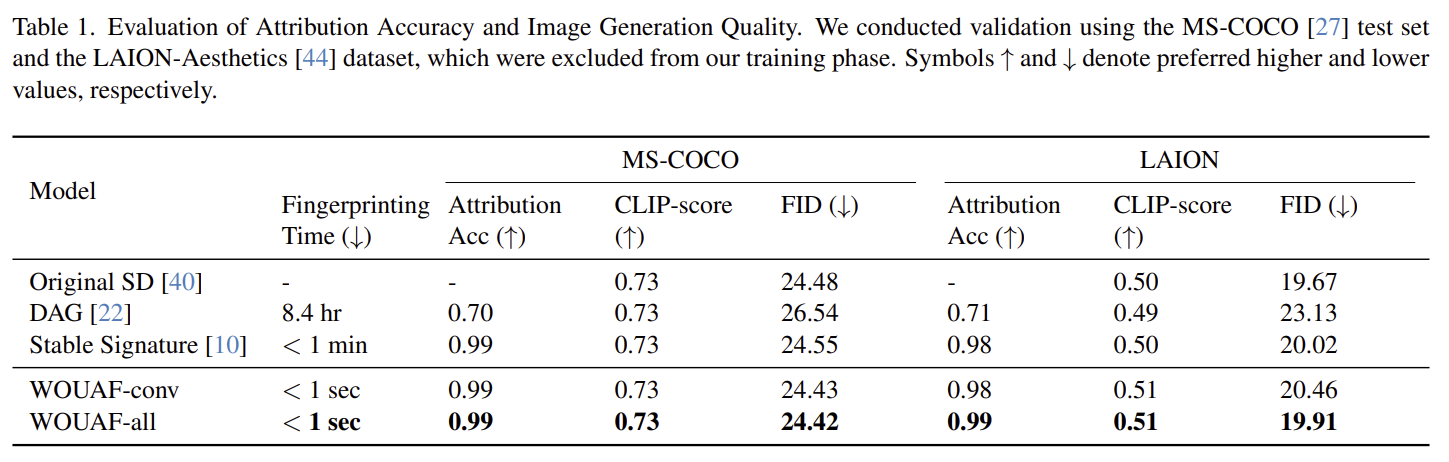
| 주요 결과(정량) | COCO/LAION에서 귀속 정확도 0.99, CLIP/FID 거의 동일. 지문 주입 시간 <1초(DAG 8.4h, Stable Signature <1m). (Table 1) |
| 강건성(후처리 내성) | JPEG/노이즈/블러/회전/크롭/밝기/지우개/복합 등 후처리 강건 훈련 시 기존법 대비 평균 ~11% 개선(요지·대조실험). CLIP/FID도 후처리 하에서 경쟁적. |
| 스케줄러/하이퍼 변화 | Euler/DDIM, 스텝·CFG 스윕에서도 0.99 유지 및 품질 안정 (Tables 4–5, Fig. 9–10). |
| 용량(사용자 수) | 지문 차원 (d_) 실험: 16/32/64에서 0.99, 128에서 소폭 하락 → (d_=32) 채택(이론상 (2^{32}) 사용자 이상). (Table 2) |
| 일반화 | ImageNet만으로 미세조정해도 COCO/LAION 평가에서 Acc 0.99 / 품질 유지 (Table 3). |
| 비교 기준(Baselines) | DAG, Stable Signature와 동일 프로토콜로 재평가(후처리 변환은 공정 비교 위해 동일화). WOUAF가 정확도/강건성/시간에서 우수·경쟁적. |
| 어블레이션(디자인 선택) | 디코더만 변조 vs ϵθ+디코더 동시 변조: 후자는 품질 크게 악화(Fig. 4), 정확도도 ~89%로 하락 → 디코더만 변조가 최적. |
| 공격/회피 분석 | ① 오토인코더 압축: 압축률↑ → 정확도 ~50%로 하락하지만 품질도 동반 악화(본질적 트레이드오프). ② 모델 정화(미세조정)도 정확도↓와 함께 FID 악화. ③ 풀-지식 공격자가 별도 모델로 생성한 이미지 5K를 넣어도 원 복원기는 랜덤 수준(회피). |
| 기여(요약) | (1) 배포자 지향 모델-내 지문 삽입(우회 곤란), (2) 0.99 정확도 & 품질 보존, (3) 후처리 강건성 향상, (4) <1초 지문 주입으로 대규모 사용자 확장성. |
| 한계 | 매우 강한 압축/정화로 정확도 저하 가능(단, 품질 희생 필요)·SD v2 기반 설정 중심 → 타 구조/해상도·타 모달 확장 필요(저자 언급). |
아래는 업로드하신 논문 **“WOUAF: Weight Modulation for User Attribution and Fingerprinting in Text-to-Image Diffusion Models”**의 핵심을, 실험에 바로 활용할 수 있도록 체계적으로 정리한 요약입니다. 모든 내용은 논문 근거에 기반합니다.
한눈에 보는 핵심 요약 (TL;DR)
- 문제: 공개 배포된 T2I 모델(Stable Diffusion 등)에서 사후 워터마크/지문 모듈은 쉽게 우회됨. 사용자를 식별(귀속)할 수 있는 우회 어려운 모델 지문 방식이 필요.
- 해결: **가중치 변조(weight modulation)**로 디코더(Decoder, D) 가중치만 사용자별 벡터(지문)로 스케일링하여 모델 자체에 지문을 삽입. 별도 모듈이 없어 우회가 어려움. 지문 복원용 ResNet-50 디코더(F)를 공동 학습하며 품질 보존 손실을 함께 사용.
- 성과: COCO/LAION에서 귀속 정확도 0.99를 달성하면서 CLIP/FID 품질 거의 유지, 지문 생성 시간 <1초(Stable Signature는 <1분, DAG는 8.4시간).
- 용량: 지문 차원 dϕ=32만으로 약 2^32(40억+) 사용자까지 확장 가능.
- 강건성: JPEG/노이즈/블러/회전/크롭/밝기/지우개/복합 등 8종 후처리에 평균적으로 기존법 대비 ~11% 개선(논문 요지).
- 중요 설계: 디코더만 미세조정해야 품질-귀속 균형이 좋음. 디퓨전 UNet(ϵθ)까지 함께 변조하면 FID 크게 악화, 귀속도 최대 89%에 그침.
1) 문제 정의
오픈소스 SD 계열은 별도 지문/워터마킹 모듈을 코드 한 줄로 비활성화 가능. 배포자 중심으로 모델을 사용자별로 변형해, 생성물에서 역으로 사용자 지문을 복원해 책임을 추적하는 방식이 요구된다.
2) 방법론 (Step-by-Step)
2.1 핵심 아이디어: “가중치 변조”
- 각 사용자 지문 ϕ(비트 벡터, 차원 dϕ)를 매핑 네트워크 M과 **층별 Affine(Al)**을 거쳐 출력 채널 스케일 u로 변환.
- 디코더 D의 합성곱 가중치 W에 곱연산 스케일링:
Wϕᵢⱼₖ = uⱼ · Wᵢⱼₖ. (출력 채널 j마다 스케일 uⱼ 적용) - 적용 범위는 디코더 D에 한정(ϵθ에는 적용하지 않음 → 품질 보존).
2.2 학습 목표(손실)
- 지문 복원 손실 Lϕ: F(D(ϕ, z))가 ϕ의 각 비트를 맞히도록 전비트 BCE.
Lϕ = 𝐸 [ Σᵢ ϕᵢ log σ(F(… )ᵢ) + (1−ϕᵢ) log(1−σ(F(… )ᵢ)) ] - 품질 보존 Lquality: 원본 x와 지문삽입 이미지 간 지각 거리(perceptual distance) 최소화.
- 최종 목적: min λ₁Lϕ + λ₂Lquality, (λ₁=λ₂=1)로 귀속과 품질 균형.
2.3 강건 학습(후처리 내성)
- 생성 이미지에 **무작위 후처리 T(·)**를 적용한 뒤 F가 ϕ를 복원하도록 Lrobust로 학습(수식 5).
(지우개, 회전, 가우시안 블러/노이즈, 크롭, 밝기, JPEG, 복합) 강도 범위를 명시적으로 샘플링.
2.4 구현·세팅
- 지문복원기 F: ResNet-50.
- 데이터·생성 설정: COCO Karpathy split 미세조정, 평가는 COCO/LAION, Euler T=20, CFG=7.5(DDIM/스텝·CFG 변화도 평가).
- 평가지표: 귀속 정확도(비트 일치율, 이항검정으로 유의성 p-value), CLIP-score, FID.
- 강건 후처리 구현: Kornia 사용(미분가능 변환).
- 하이퍼파라미터(부록): 매핑 차원 d_M=4·dϕ, 50K iters, batch 32, lr 1e-4, AdamW.
3) 실험 & 결과
3.1 메인 결과: 정확도·품질·시간
- Table 1 요지:
- WOUAF-conv / WOUAF-all: 귀속 0.99, CLIP/FID는 원본 SD와 유사.
- 지문 주입 시간: <1 sec(Stable Signature <1 min, DAG 8.4 hr).
- 베이스라인: DAG, Stable Signature 재현·비교.
- 정리: 지문 삽입이 빠르고(전달 시 1 fwd-pass), 품질 희생 없이 0.99 정확도.
3.2 지문 용량(dϕ)
- dϕ=16/32/64에서 정확도 0.99 유지, dϕ=128에서 소폭 하락. dϕ=32 채택 → 2^32명+.
3.3 생성 하이퍼파라미터 변화(Euler/DDIM, step/CFG)
- 다양한 step/CFG에서도 0.99 유지, CLIP/FID 변동 미미. (표 4·5)
3.4 다양한 출처·데이터 일반화
- ImageNet 단독 학습 후 COCO/LAION 평가에서도 0.99/품질 유지(표 3).
3.5 후처리 강건성
- 8종 후처리에 대해 대부분 시나리오에서 기존법(DAG/Stable Signature)보다 우수(그림 5), 논문 요지 기준 평균 ~11% 개선.
3.6 적대적 제거 시도
- 오토인코더 압축: 압축률↑ → 정확도 **무작위(≈50%)**로 하락하지만 이미지 품질도 함께 열화(트레이드오프).
- 모델 정화(미세조정), 가중치 가우시안 노이즈 주입: 귀속↓시키면 FID 악화. (그림 6, 16)
- 풀 지식 공격(모든 세부 알고 있는 내부자): 공격자 모델이 생성한 5K 이미지에 대해 원래 복원기는 ~0.5(랜덤) 수준으로만 반응 → 회피.
3.7 디코더만 미세조정해야 하는 이유
- ϵθ+ D 동시 변조는 품질 급락(FID 63.48, CLIP 0.68), 귀속도 최대 89%(그림 4, 11). D만 변조가 최적.
4) 기여·한계·결론
기여
- 배포자 중심 지문 삽입(모델 가중치 변조)로 우회 어려움. 2) 0.99 귀속·품질 보존. 3) 후처리 강건성(평균 ~11% 이점). 4) 공격/정화 시도에 대한 트레이드오프 분석을 제시.
한계
- 강한 압축/정화로 귀속을 낮출 수 있으나 품질 손상 동반(안정적 trade-off).
- SD v2-base(512p) 중심 평가 → 다른 구조/해상도로의 일반화는 추가 검증 필요(부록 명시).
- dϕ↑ 시 복원 난이도↑로 정확도 소폭 감소(128차원에서 하락).
결론
WOUAF는 모델 내부 가중치에 사용자별 지문을 주입해 책임 추적을 가능케 하고, 품질 저하 없이 0.99 정확도와 후처리 강건성을 달성했다. 향후 텍스트/오디오/비디오로의 확장을 제안.
5) 재현 체크리스트 (실험용 Step-by-Step)
- 데이터/모델: SD v2-base 준비, COCO(Karpathy)로 미세조정, 평가는 COCO/LAION.
- 지문 설정: dϕ=32 권장(약 40억 사용자), d_M=4·dϕ.
- 아키텍처: D의 모든/혹은 Conv 층에 스케일 곱(Wϕ= uⱼ·W); F=ResNet-50.
- 손실: Lϕ(BCE 전비트) + Lquality(Perceptual), λ₁=λ₂=1. 강건 버전은 Lrobust(무작위 T(·)).
- 학습: 50K iters / batch 32 / lr 1e-4 / AdamW, Kornia로 T(·) 미분가능 구현.
- 생성 설정: Euler T=20, CFG=7.5(DDIM/스텝/CFG 전 범위에서도 성능 유지 확인).
- 평가: (i) 귀속(비트 일치율 + 이항검정), (ii) CLIP/FID, (iii) 지문 주입 시간(전달 시 1 fwd-pass).
6) 한 장 표 (문제–방법–실험–결과–기여–한계)
항목 내용| 문제 | 사후 워터마크는 오픈소스에서 쉽게 우회 → 사용자 귀속 가능한 모델 지문 필요. |
| 핵심 아이디어 | 디코더 가중치 스케일링(Wϕ = uⱼ·W) 으로 모델 내부에 지문 삽입(UNet는 미변조). |
| 학습 목표 | Lϕ(BCE) + Lquality(Perceptual), λ₁=λ₂=1. 강건 버전 Lrobust로 T(·) 내성. |
| 구현 | F=ResNet-50, Kornia로 후처리 미분 구현, d_M=4·dϕ, 50K/bs32/lr1e-4/AdamW. |
| 데이터/세팅 | COCO 미세조정, COCO/LAION 평가, Euler T=20, CFG=7.5(DDIM/step/CFG 다양화 실험). |
| 지문 용량 | dϕ=16/32/64에서 0.99, dϕ=32 → 2^32 사용자. |
| 메인 결과 | 0.99 정확도, 품질 유지(CLIP/FID 차이 소), <1초 주입. |
| 강건성 | JPEG/노이즈/블러/회전/크롭/밝기/지우개/복합 내성, 평균 ~11% 개선(요지). |
| 비교·분석 | D만 변조가 최적(ϵθ+ D 동시 변조 시 품질 붕괴·귀속 89%). |
| 공격 내성 | 오토인코더/정화/가중치 노이즈 → 귀속↓와 함께 품질도 함께 악화(트레이드오프). |
| 기여 | 배포자 중심 지문 삽입, 고정확·품질 보존, 후처리 강건, 공격 시 트레이드오프 분석. |
| 한계/미래 | 강한 압축/정화에는 품질 희생 동반, SD v2-base 중심, 타 모달 확장 예정. |
필요하시면 위 표/요약을 바탕으로 재현용 코드 스켈레톤(학습 루프, 손실 계산, Kornia 후처리 파이프, D-modulation 유틸)을 만들어 드릴게요.
아래는 업로드하신 WOUAF 논문의 **방법론(Method)**을, 실험 재현과 코드 설계에 바로 쓰실 수 있도록 구성 요소→수식→학습 루프→배포/검증까지 단계별로 정리한 설명입니다. (각 진술은 논문 문장·수식에 근거해 인용합니다.)
1) 구성 요소 (What is trained?)
- 가중치 변조(Weight Modulation): 사용자 지문 ϕ로부터 각 **디코더(Decoder, D)**의 출력 채널별 스케일 u를 생성하고, 합성곱 가중치에 곱으로 주입
( W^{(\phi)}{i,j,k} = u_j \cdot W{i,j,k} ) (출력 채널 j에 대한 스케일)
→ 중요: SD의 디코더 D에만 변조를 적용(ϵθ까지 손대지 않음: 품질-귀속 균형 때문) - 매핑 네트워크 M & 층별 Affine (A_\ell): 이진 지문 ϕ → (FC-2층) → 층별 스케일 벡터 u 생성. 구현은 StyleGAN2-ADA의 weight mod 설계를 따른다고 명시.
- 지문 복원기 F: 생성된 이미지에서 ϕ를 회복하는 ResNet-50 회귀기/분류기(시그모이드) .
- 지문 차원 (d_\phi): 기본 (d_\phi=32). 정확도 0.99를 유지하면서 약 (2^{32}) 사용자까지 확장 가능. (16/32/64는 0.99, 128에서 약간 하락)
2) 수식과 목표 (What objective do we optimize?)
(a) 지문 복원 손실 (L_\phi)
ResNet-50 복원기 (F)가 이미지 (D(\phi, z))로부터 모든 비트를 맞히도록 하는 전비트 BCE:
[
L_\phi = \mathbb{E}{z=E(x),,\phi\sim\Phi}\ \sum{i=1}^{d_\phi}
\big[\phi_i \log \sigma(F(D(\phi,z))_i)
+(1-\phi_i)\log(1-\sigma(F(D(\phi,z))_i))\big]
]
(학습 중 ϕ는 베르누이 샘플; 배포 시엔 사용자별 ϕ_α를 고정해 디코더를 변조하여 전달)
(b) 품질 보존 손실 (L_{\text{quality}})
원본 x와 지문삽입 이미지 간 지각(perceptual) 거리 최소화:
[
L_{\text{quality}}=\mathbb{E}_{z=E(x),,\phi\sim\Phi}\big[\ell(x, D(\phi,z))\big],\ \ \ell:\ \text{perceptual distance}
]
(c) 최종 목적함수
[
\min_{A,M,D,F}\ \lambda_1 L_\phi+\lambda_2 L_{\text{quality}},\quad \lambda_1=\lambda_2=1
]
3) 강건 지문 학습(옵션) (Robust training against post-process)
실전 배포를 고려해, 후처리 (T(\cdot)) (JPEG/노이즈/블러/회전/크롭/밝기/지우개/복합)에도 지문 복원이 되도록 강건 손실 사용:
[
L_{\text{robust}}=\mathbb{E}\ \sum_{i=1}^{d_\phi}\big[\phi_i \log \sigma(F(T(D(\phi,z))i)) + (1-\phi_i)\log(1-\sigma(F(T(D(\phi,z))i))\big]
]
훈련 땐 (L\phi)를 (L{\text{robust}})로 대체하며, Kornia를 써서 미분가능 변환으로 구현(공정 비교 위해 Baseline의 후처리도 동일 스킴으로 교체). 각 변환의 강도 범위는 논문에 구간 지정(예: JPEG 50–90, 회전 −30–30°, 크롭 5–20% 등).
4) 학습·생성 세팅 (Repro tips)
- 데이터/스케줄러: MS-COCO Karpathy split로 미세조정, 평가엔 COCO/LAION. 생성은 Euler T=20, CFG=7.5(DDIM/스텝/CFG 전 범위 실험은 부록).
- 매핑 M: FC 2-층(StyleGAN2-ADA식 weight mod 설계 참고).
- 평가: 지문 비트 일치율과 이항검정 p-value로 유의성 판단(기본 (d_\phi=32)). 품질은 FID/CLIP.
5) 배포·검증 파이프라인 (How do you use it after training?)
- 배포자가 사용자별 이진 지문 ( \phi_\alpha)를 샘플링/할당 → 디코더 (D) 가중치를 (W^{(\phi_\alpha)})로 변조한 개인화 디코더 (D(\phi_\alpha,\cdot)) 를 사용자에게 전달(잠재 z만 입력 허용).
- 사용자가 생성한 이미지 (x_{\phi_\alpha})에 대해, 배포자는 복원기 (F(x_{\phi_\alpha})) 로 (\hat\phi) 추정 후 비트 일치율·이항검정으로 귀속을 판정(유의수준 0.05).
6) 왜 “디코더만” 변조하나? (Crucial design choice)
ϵθ(UNet 노이즈 예측기)까지 동시 변조하면 품질 급락(예: CLIP 0.68, FID 63.48)하며 귀속도 **최대 89%**에 그친다. 반면 디코더만 변조하면 품질을 유지하며 0.99에 근접한 귀속이 가능.
7) 학습 루프 요약 (Pseudo-code)
- 샘플 (x) → 인코더 (E)로 잠재 (z=E(x))
- 미니배치마다 (\phi \sim \text{Bernoulli}) (길이 (d_\phi))
- (u = A_\ell(M(\phi))) 생성 → 디코더 가중치를 (W^{(\phi)}=u\odot W)로 스케일(출력 채널별)
- (옵션) (x' = T(D(\phi,z))) / 아니면 (x' = D(\phi,z))
- 지문 복원 손실 (L_\phi) 또는 강건 손실 (L_{\text{robust}}) 계산, 품질 손실 (L_{\text{quality}}) 더해 업데이트(λ1=λ2=1)
- 반복. (평가 시 Euler/DDIM/CFG 전 범위에서도 성능 확인)
8) 한 줄 핵심
“사용자 지문 ϕ → (M, A_\ell) → 디코더 가중치의 채널별 스케일 u → (W^{(\phi)}=u\cdot W)로 변조 → 이미지 생성 → ResNet-50 (F)로 ϕ 복원.”
이때 (L_\phi + L_{\text{quality}})(옵션으로 (L_{\text{robust}}))로 학습하여 귀속 0.99와 품질 유지를 동시에 달성합니다.
원하시면 위 절차를 바로 돌릴 수 있도록 **PyTorch 스켈레톤(모듈 정의·가중치 변조 유틸·Kornia 강건 파이프·손실/평가 루틴)**까지 만들어 드릴게요.
좋아요! 이 그림은 WOUAF의 전체 파이프라인을 한 장으로 요약한 개요도입니다. 위(배포자)–아래(사용자) 두 영역으로 나뉘며, “모델 내부 지문”이 어떻게 주입·유통·검증되는지를 단계별로 보여줍니다.
그림 해설 (Step-by-Step)
- 지문 데이터베이스(Database) – 배포자 측(상단 파란 영역)
- 배포자는 사용자마다 고유한 이진 지문 벡터 ϕ를 생성해 DB에 저장합니다.
- 이 지문은 훗날 “이 이미지가 누구의 모델에서 생성됐는가?”를 판별하는 키가 됩니다.
- 지문 주입(⊗ 아이콘) – 모델 변조
- Stable Diffusion의 디코더(Decoder, D) 가중치에 대해, ϕ → (매핑 네트워크/층별 Affine) → 채널별 스케일 u를 만들어 가중치에 곱합니다.
- 이렇게 하면 사용자별로 서로 다른 가중치를 갖는 지문 내장형 SD가 만들어집니다(그림의 녹색/보라색 SD 박스).
- 포인트: UNet(ϵθ)는 건드리지 않고 디코더만 변조해 품질을 유지하면서 지문을 심습니다.
- 개인화 모델 배포 – End-Users(하단 살구색 영역)
- 각 사용자는 자신에게 할당된 지문이 주입된 SD 모델을 받습니다(녹색/보라색 상자).
- 사용자는 평소처럼 텍스트 프롬프트로 이미지를 생성하지만, 이미지에는 해당 지문이 은닉적으로 각인됩니다.
- 사용자 입장에서는 품질/속도 차이를 거의 체감하지 못합니다.
- 생성물(이미지) – 지문이 묻어난 결과
- 그림 속 생성 예시(인물, 일러스트 등)는 모두 모델 내부 지문이 스며든 출력입니다.
- 이는 픽셀 워터마크처럼 나중에 꺼버릴 수 있는 외부 모듈이 아니라, 모델 가중치 자체에 녹아 있어 우회가 어렵다는 게 핵심.
- 지문 복원기(Fingerprint Decoding Network) – 배포자 측 판독기
- 배포자는 별도로 학습해 둔 지문 복원 네트워크 F(논문에선 ResNet-50) 를 보유합니다.
- 문제가 되는 이미지가 접수되면, F가 이미지 → 지문 ϕ̂를 복원합니다.
- 데이터베이스 조회(Database Lookup) – 사용자 귀속(Attribution)
- 복원된 지문 ϕ̂를 DB에서 정확히 일치하는 사용자 지문 ϕ와 매칭합니다.
- 매칭이 성립하면 “이 이미지는 사용자 A의 모델에서 생성”되었다고 귀속합니다.
- 이 과정이 그림의 오른쪽 화살표(복원기 ↔ DB 조회)로 묘사되어 있습니다.
그림에서 읽을 수 있는 설계 포인트
- 모델-내 지문(Weight Modulation): 지문은 픽셀 후처리물이 아니라 모델 가중치의 함수입니다. 사용자가 코드를 조금 바꿔도 지문 모듈을 끄기 어렵습니다.
- 디코더만 변조: UNet까지 바꾸면 품질·안정성이 크게 떨어지므로, 디코더에 한정해 채널 스케일을 곱합니다.
- 복원기는 배포자 전용: 사용자는 복원 네트워크를 갖지 않으며, 배포자(감사자)가 사후 감사(auditing) 시에만 사용합니다.
- 확장성: 지문 차원(dϕ)을 적절히 잡으면 매우 많은 사용자를 커버할 수 있으며, 그림의 여러 색상의 SD 상자는 “사용자별로 서로 다른 지문이 주입된 개인화 모델”을 의미합니다.
한 줄 요약
배포자는 각 사용자에게 지문이 스며든 SD 디코더를 배포하고, 나중에 문제 발생 시 복원기(F)로 이미지에서 지문을 읽어 DB와 대조해 사용자를 특정(Attribution) 하는 구조를, 이 그림이 전체 흐름으로 보여줍니다.
'인공지능 > 논문 리뷰 or 진행' 카테고리의 다른 글
| Provable Robust Watermarking for AI-Generated Text (1) | 2025.10.27 |
|---|---|
| StegaStamp: Invisible Hyperlinks in Physical Photographs (0) | 2025.10.24 |
| BERTGEN: Multi-task Generation through BERT (0) | 2025.10.21 |
| REALM: Retrieval-Augmented Language Model Pre-Training (0) | 2025.10.20 |
| RELAM: LEARNING ANTICIPATION MODEL FOR REWARDING VISUAL ROBOTIC MANIPULATION (0) | 2025.10.19 |