https://arxiv.org/abs/2106.03484
BERTGEN: Multi-task Generation through BERT
We present BERTGEN, a novel generative, decoder-only model which extends BERT by fusing multimodal and multilingual pretrained models VL-BERT and M-BERT, respectively. BERTGEN is auto-regressively trained for language generation tasks, namely image caption
arxiv.org
MLM기반의 BERT로는 NLG Task에는 부적합하는 통념을 깨고, Decoder 생성기 처럼 확장해 멀티모달 task를 한번에 다루려는 시도로 진행하였다.

이미지 캡셔닝(IC), 멀티모달 번역(MMT), 텍스트 번역(MT) 모두 진행
Transformer 모델에 MLM 헤드를 달아서 학습 진행
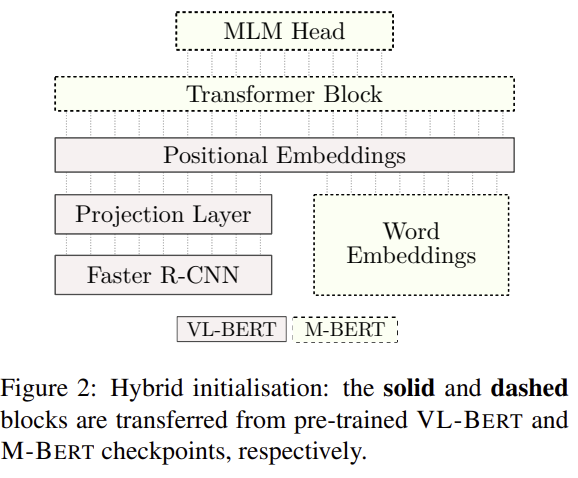
모델의 구조다.

생성을 진행할 수록 mask를 한 칸씩 옆으로 이동한다.
| 문제 상황 | BERT류(MLM)는 생성(NLG)에 부적합하다는 통념. 멀티모달(이미지↔텍스트)·다국어·다태스크를 하나의 모델로 처리하면서도 제로샷까지 노리는 단일 생성기 필요. |
| 방법론 | ① 단일 Transformer + MLM 헤드로 인코더/디코더 구분 없이 생성 수행(one-stream self-attention). ② 시퀀스 언롤링: 타깃 길이 n인 한 샘플을 n개의 미니샘플로 전개해 학습 진행 |
| 모델 구조 | Transformer 12-layer / 12-head, (d_{model}=768), (d_{ff}=3072) 파라미터 ≈89.3M(워드 임베딩 제외). 포지셔널 임베딩 학습 허용. |
| 입력 포맷 | 태스크별: MMT {x, v, y} / MT {x, y} / IC {v, y}. 모든 경우 맨 앞에 [LANG] 부착. 시각 RoI는 사전 추출(감지기 미세조정 없음). |
| 학습 목표(언롤링) | 각 샘플을 타깃 길이만큼 분해해 [MASK] 위치별 미니샘플로 CE(로그우도) 학습 → 코퍼스 × 평균 타깃 길이만큼 관측 증가(데이터 증강 효과) + 인코더/디코더 통합으로 파라미터 효율(ED 대비 절반 수준). |
| 디코딩 | 그리디: [MASK] 위치의 최빈 토큰을 삽입 → [MASK]를 오른쪽으로 이동 → [STOP] 예측 시 종료. (언롤링 구조상 빔서치는 재계산 비용이 커서 미사용) |
| 학습법(Optimizer/스케줄) | AdamW, lr=1.3e-5, warm-up 16k step, linear decay, weight decay=1e-4. 태스크를 섞어 멀티태스킹으로 공동 학습. |
| 학습 데이터셋(원본 → 언롤 후 예시 수) | IC: Flickr30k(IM→EN ~2.39M, IM→DE ~2.48M), Flickr8k-TASVIRET(IM→TR ~0.26M). MMT: Multi30k EN↔DE/FR(예: EN→DE ~0.58M). MT: IWSLT EN↔DE/FR, SETIMES/WMT EN↔TR(예: EN→TR ~8.40M). WMT’19 DE↔FR 뉴스는 제로샷 평가에 사용. (숫자는 언롤링 후 대략값) |
| 실험 설정 | 태스크 결합 멀티태스킹 학습(IC + MMT + MT). RoI 감지기 고정(사전 추출). 그리디 디코딩으로 통일. 학습 곡선/어블레이션으로 초기화 전략·멀티태스킹 이득 검증. |
| 주요 결과—IC | Flickr30k-EN: BLEU 27.0 / METEOR 23.2 / CIDEr 0.587(빔 써야 하는 강력 베이스라인과 대등/우위). COCO(카르파시): COCO 미학습으로 NBT 대비 METEOR −6.7이지만 합리적 성능. FR/DE/TR 제로샷 캡션 가능(참조 수 한계로 점수 보수적). |
| 주요 결과—MMT | Multi30k 2016: EN→DE BLEU 42.2 / METEOR 61.6, EN→FR 68.0 / 81.2 → RNN/Transformer MMT 및 단일태스크 NMT 초과. DE↔FR 제로샷도 강력. 이미지-문장 페어 셔플 시 성능 하락(EN→DE: BLEU −1.1/METEOR −0.9; EN→FR: −3.1/−2.3) → 비전 특징을 실제로 사용. |
| 주요 결과—MT | IWSLT/SETIMES 전반에서 FAIRSEQ 단일태스크 NMT 대비 동급~우위, 특히 METEOR 전 언어쌍 우세(예: EN→DE 27.8/48.4 vs 27.4/47.1). 학습 효율: 소수 패스에서 단일태스크 모델 추월. WMT’19 DE↔FR(뉴스) 제로샷: DE→FR 19.6/40.5, FR→DE 13.1/36.7. |
| 어블레이션 | 초기화: Hybrid(VL-BERT+mBERT) > Visual-only > Random. 멀티태스킹: 멀티태스크 > 단일태스크, 장기 학습에서도 카타스트로픽 포겟팅 없음. |
| 기여(요약) | 1) 단일 스트림 BERT-기반 생성기로 다국어×멀티모달×다태스크를 한 번에 처리. 2) 시퀀스 언롤링으로 데이터 증강·안정 학습·파라미터 효율 달성. 3) 하이브리드 초기화로 비전/다국어 유도편향 이식. 4) 제로샷 번역·캡션 일반화 실증. 5) 멀티태스킹/초기화 설계의 이득을 정량적 어블레이션으로 확인. |
| 한계(주의점) | • COCO 미학습으로 일부 도메인 격차(예: METEOR −6.7). • 그리디 디코딩(빔 미사용)으로 품질 상한 가능. • 언롤링 구조상 추론 재계산 비용↑(빔 느림). • RoI 감지기 미세조정 없음(비전표현 상한 가능). • 매우 최신 대규모 NMT/VLM SoTA를 반드시 추월하려는 세팅은 아님. • 리소스 요구(단일 32GB V100 기준 에폭 시간 큼; 혼합정밀/멀티GPU로 완화). |
| 재현·적용 팁 | • [LANG] 토큰 규칙을 유지하면 다태스크/다국어/제로샷 전이에 일관성. • 언롤링 배수(평균 타깃 길이)를 활용해 작은 코퍼스도 안정 학습. • 현대 백본으로 하이브리드 초기화 대체(예: 최신 VLM + mBERT/mT5) 시 추가 이득 여지. • 그리디 디코딩 품질 보강: 길이 보정, 반복 억제, lightweight re-ranker(후처리) 고려. |
아래 요약은 업로드하신 원문(BERTGEN: Multi-task Generation through BERT)만을 근거로 정리했습니다. 핵심 아이디어→방법→학습 설정→실험 결과→기여/한계 순으로 단계별로 설명하고, 마지막에 “한 장짜리 표”로 모두 압축했습니다.
한눈에 보는 핵심
- 문제의식: MLM 기반의 BERT류는 NLG(번역/생성)에 부적합하다는 통념을 깨고, **BERT를 단일 생성기(decoder-only처럼 동작)**로 확장해 텍스트·멀티모달·다국어를 멀티태스크로 한 번에 다루려는 시도.
- 핵심 아이디어:
- 하이브리드 초기화: VL-BERT(시각) + mBERT(다국어)의 가중치·임베딩·MLM 헤드 결합,
- **시퀀스 언롤링(sequence unrolling)**로 인코더/디코더 구분 없이 MLM 형식으로 오토리그레시브 생성,
- **타깃 언어 스페시파이어([DE] 등)**로 언어 전환,
- RoI 시각 특징(2048-d) + 위치 임베딩을 입력 스트림에 함께 넣는 단일 스트림 자기어텐션.
- 결과 요약: 이미지 캡셔닝·MMT·텍스트 번역에서 강력한 베이스라인 다수 초과. 제로샷(예: DE↔FR MMT/MT, FR 캡션)에서도 유의미한 성능. 멀티태스킹과 하이브리드 초기화의 이득이 어블레이션으로 확인됨.
방법(step-by-step)
1) 모델 구조(단일 Transformer로 생성과 인코딩 겸함)
- 단일 Transformer(12L, 12H, d_model=768, d_ff=3072) 위에 MLM 헤드를 얹고, 입력 스트림에 소스 토큰 x, 타깃 토큰 y(마스크), 시각 RoI 특징 v를 한 줄로 배치해 양방향 self-attention으로 인코딩/생성을 동시에 수행. 인코더/디코더 분리는 없음.
- 시퀀스 언롤링: 타깃 길이 n에 대해 n개의 독립 예시로 분해해 각각 log P(y_t | x, v, y_<t)를 최대화(MLM-like). 데이터 증강 효과(코퍼스 × 평균 타깃 길이). 파라미터 수는 인코더/디코더 절반 수준으로 효율적.
- 디코딩: test 시 그리디. 현재 [MASK] 위치의 최빈 토큰을 찍고 오른쪽으로 [MASK]를 한 칸 이동, [STOP] 예측 시 종료(beam 미사용: 재계산 비용 때문).
2) 하이브리드 초기화
- VL-BERT에서 비전 관련 블록과 mBERT에서 워드피스 임베딩(119k vocab), Transformer 가중치, MLM 헤드를 가져와 결합(Hybrid). 시각/다국어 **유도편향(inductive bias)**를 초기부터 주입. 어블레이션에서 Random < Visual-only < Hybrid 순으로 명확한 이득.
3) 입력 구성과 시각 임베딩
- 태스크별 입력:
- MT: {x, y}, MMT: {x, v, y}, IC: {v, y}.
- 타깃 언어 스페시파이어(예: [DE])를 시퀀스 맨 앞에 붙여 출력 언어 지정(태스크 불문 공통 규칙).
- 시각 RoI 특징: Faster R-CNN의 Bottom-Up/Top-Down으로 2048-d RoI 추출, 10~100개 선택, **기하 임베딩(박스 좌표 투영)**과 합산. 백본 감지기 파인튜닝은 하지 않음. 비시각 위치에는 풀-이미지 피처를 반복 삽입.
4) 학습 설정
- Optim/스케줄: AdamW, lr=1.3e-5, warmup 16k step, linear decay, weight decay=1e-4. 위치 임베딩은 학습 허용(사전학습 길이 밖 포지션 학습 필요). 파라미터≈89.3M(워드임베딩 제외). 단일 32GB V100 기준, 레퍼런스 태스크 기준 에폭당 약 2일(저자 코드 기준; 혼합정밀/멀티GPU 최적화로 더 단축 가능).
데이터셋 & 멀티태스킹 구성
- 태스크: 이미지 캡셔닝(IC), 멀티모달 번역(MMT), **텍스트 번역(MT)**를 동시에 멀티태스크로 학습.
- 주요 코퍼스 및 통계(언롤링 후 샘플 수):
- Flickr30k(IC EN/DE), Flickr8k-TASVIRET(IC TR), Multi30k(MMT EN↔DE/FR), IWSLT’14(MT EN↔DE/FR), SETIMES2/WMT(MT EN↔TR). 언롤링으로 수백 K~수백만 샘플로 증폭(예: Flickr30k IM→EN 2.39M, IM→DE 2.48M). 데이터 누수 방지 위해 TASVIRET는 새 스플릿 구성.
결과(핵심 수치)
1) 이미지 캡셔닝 (IC)
- Flickr30k-EN: BLEU 27.0 / METEOR 23.2 / CIDEr 0.587, Sentinel·NBT 등 강력 베이스라인과 대등~우위(상대는 beam 사용). COCO(카르파시 스플릿)에서는 COCO 미학습 탓에 NBT 대비 낮지만 합리적 범위(METEOR 20.4). 제로샷 FR/DE/TR 캡션도 유효한 기술 산출.
2) 멀티모달 번역 (MMT, Multi30k 2016 test)
- EN→DE: BLEU 42.2 / METEOR 61.6 (대조군 Transformer-MMT 및 RNN-MMT 초과, 대규모 비제한 MMT보다도 우수).
- EN→FR: BLEU 68.0 / METEOR 81.2(최상).
- 제로샷 DE→FR 64.1 METEOR, FR→DE 56.9 METEOR로 강력한 NMT/MMT를 상회.
- Adversarial 평가(이미지-문장 페어 셔플): EN→DE에서 BLEU −1.1 / METEOR −0.9, EN→FR에서 BLEU −3.1 / METEOR −2.3 하락 ⇒ 비전 특징을 무시하지 않음.
3) 텍스트 번역 (MT)
- IWSLT/SETIMES 전반에서 FAIRSEQ 단일 태스크 NMT와 동급~우위, 특히 METEOR 전 언어쌍 우세. 소수 패스만으로도 단일태스크 대비 빠르게 상회(학습 효율성).
- 제로샷 WMT’19 DE↔FR 뉴스: DE→FR METEOR 40.5, FR→DE 36.7. 해당 언어쌍으로 직접 학습한 공유태스크 최상위(MSRA)보단 낮지만, 제로샷임을 감안하면 고무적.
4) 어블레이션
- 초기화: Hybrid > Visual-only > Random(EN→DE-MMT 검증 BLEU).
- 멀티태스킹: 멀티태스크 > 단일태스크, 장기 학습에서도 카타스트로픽 포겟팅 없음.
이 논문의 기여
- 단일 스트림·단일 모듈로 다국어×멀티모달×다태스크 생성이 가능한 BERT 확장 생성기 제안(인코더/디코더 분리 없음).
- 하이브리드 초기화(VL-BERT + mBERT)로 멀티모달·다국어 유도편향 이식. 어블레이션으로 정량적 이득 확인.
- 시퀀스 언롤링으로 데이터 증강 및 파라미터 효율성(인코더/디코더 통합) 달성.
- 제로샷 생성 능력(언어쌍/캡션)과 멀티태스킹 일반화 확인.
한계 및 주의점
- COCO 미학습 상황에서 COCO 캡셔닝 SOTA 대비 격차(도메인·규모 차이).
- 그리디 디코딩만 사용(beam은 재계산 비용 큼) → 품질 상한선 제약 가능성.
- 시각 특징은 고정된 RoI 추출기에 의존(공동 미세조정 미수행). 더 강한 비전 백본/공동학습 시 추가 개선 여지.
연구 적용 팁
- HEGA/KURE 계열 멀티스테이지 실험에 적용 시:
- 언롤링式 MLM-생성을 라벨/교사 없이 대규모 멀티태스킹으로 섞어 제로샷 전이 확보.
- [LANG] 태그로 언어 지정 + 비전 RoI를 입력 스트림에 함께 투입하는 단일 모델 설계를 검토.
- 하이브리드 초기화를 현대 비전-언어·다국어 백본(예: 최신 VLM, mT5/mBERT-대체)으로 확장하면 추가 이득 기대.
한 장 요약표 (연구 재현용)
항목 내용| 문제 | MLM 사전학습(BERT)을 **생성(NLG)**으로 확장해 IC/MMT/MT를 단일 모델·멀티태스킹으로 해결 |
| 핵심 아이디어 | 하이브리드 초기화(VL-BERT + mBERT), 시퀀스 언롤링(MLM-like로 오토리그레시브), [LANG] 스펙으로 다국어, 단일 스트림 양방향 self-attn |
| 입력 | MT: {x,y} / MMT: {x,v,y} / IC: {v,y}; 시각은 2048-d RoI 10–100개 + 기하 임베딩(감지기 고정) |
| 모델/학습 | Transformer 12L/12H, d=768/3072; AdamW, lr=1.3e-5, warmup 16k, WD 1e-4; 그리디 디코딩; ≈89.3M params(임베딩 제외) |
| 데이터 | Flickr30k/8k-TASVIRET, Multi30k, IWSLT’14, SETIMES2/WMT; 언롤링으로 데이터량 수배 증가 |
| IC 성능 | Flickr30k-EN: BLEU 27.0 / METEOR 23.2 / CIDEr 0.587(Sentinel/NBT와 대등↑); FR/DE/TR 제로샷 가능 |
| MMT 성능 | EN→DE: BLEU 42.2 / METEOR 61.6, EN→FR: 68.0 / 81.2; DE↔FR 제로샷도 강함; 셔플 어택 시 성능 하락 → 비전 사용 근거 |
| MT 성능 | IWSLT/SETIMES에서 FAIRSEQ NMT와 동급~우위, METEOR 전쌍 우세, 학습 효율성 높음 |
| 어블레이션 | Hybrid 초기화가 최상; 멀티태스킹 > 단일태스킹, 망각 없음 |
| 기여 | 단일 생성기로 다국어×멀티모달×멀티태스크 통합, 제로샷 일반화, 파라미터 효율 |
| 한계 | COCO 미학습 성능 격차, 그리디 디코딩 한계, RoI 추출기 고정 |
(모든 내용은 업로드한 논문에 근거함)
다음 정리는 업로드하신 논문(BERTGEN: Multi-task Generation through BERT)의 “Related Work”과 본문 설명을 그대로 근거로 삼아, 주제별로 맥락과 차이를 정리한 것입니다. 필요에 따라 대표 인용을 덧붙였습니다.
범주별 관련 연구 맵
1) 멀티모달·다국어 프리트레이닝 계열
- 핵심 흐름: 대규모 MLM(BERT) 사전학습으로 유도편향을 얻고, 태스크별 파인튜닝으로 전이(Transfer)하는 표준 패러다임. 멀티모달 확장은 LXMERT, VL-BERT 등에서 MLM + (마스크드 리전·이미지-문장 매칭 등) 보조 과제를 결합해 시각·언어 공동표현을 학습. 음성까지 확장한 SpeechBERT도 존재. 다만 이 계열은 **NLU 중심(특히 영어 편중)**이었음.
- BERTGEN의 위치: VL-BERT(시각) + M-BERT(다국어)를 결합한 하이브리드 초기화로, **생성(NLG)**을 겨냥한 다국어×멀티모달 생성기를 구성(태스크 특화 NLU가 아님).
2) 생성(Seq2Seq) 프리트레이닝과 BERT 활용
- BERT를 MT에 쓰는 방식: (a) 인코더-디코더 초기화에 활용, (b) 지식 증류로 생성 태스크에 이식. 그러나 일반적으로 “MLM은 생성에 부적합”하다는 회의가 있었음.
- 전용 생성 프리트레이닝: MASS(ED 구조에서 MLM식 사전학습), UniLM(자기어텐션 마스킹으로 uni/bi/seq2seq 목적을 한 모델에 통합), UniLM-VL 확장(Conceptual Captions) 등이 있음. 공통점은 보통 태스크별 추가 파인튜닝이 필요하다는 점.
- BERTGEN의 차별성: 한 번의 학습으로 다태스크 생성 가능(추가 파인튜닝 비의존), 단일 생성기(인코더/디코더 분리 없음), 시퀀스 언롤링으로 데이터 증강+파라미터 효율(ED 절반 수준) 달성.
3) 멀티태스킹·제로샷과 언어 스페시파이어
- 멀티태스킹/멀티링구얼 NMT는 오래된 흐름(언어쌍을 태스크로 두고 다태스크 학습). Ha et al. 2016, Johnson et al. 2017이 제안한 타깃 언어 스페시파이어로 제로샷 번역이 가능해졌고, BERTGEN도 같은 아이디어를 채택([DE] 등).
- BERTGEN의 확장: 언어 다변화 + 시각 특징을 한 스트림에 투입해 다국어×멀티모달 제로샷 생성을 보임(예: DE↔FR, 제로샷 캡셔닝).
4) 단일 통합형 생성기와의 비교
- One-Model 계열(예: Kaiser et al. 2017)은 하나의 변환기 안에 **모달리티별 서브모듈(전용 인코더/디코더, I/O 믹서 등)**을 둠.
- BERTGEN의 차이: 태스크 전용 모듈 없이 완전 단일 스트림 구조로, 언어·시각·출력 모두를 공유 self-attention으로 처리.
핵심 비교 요약 (표)
범주 대표 예시 핵심 아이디어 한계/초점 BERTGEN이 취한 선택/차이| 멀티모달·다국어 프리트레이닝 | BERT/M-BERT, LXMERT, VL-BERT, SpeechBERT | MLM + 보조과제로 시각/음성 융합, 대규모 전이학습 | NLU 중심, 영어 편중 | VL-BERT+M-BERT 하이브리드 초기화로 NLG에 전용화 |
| BERT 활용 NLG | BERT 초기화 NMT, 증류 기반 생성 | BERT 지식을 생성기로 이식 | “MLM은 생성에 부적합” 논쟁 | 단일 생성기로 직접 생성, 추가 파인튜닝 의존↓ |
| 전용 생성 프리트레이닝 | MASS, UniLM, UniLM-VL | 마스킹·마스킹-스케줄링으로 uni/bi/seq2seq 목적 통합 | 보통 태스크별 파인튜닝 필요 | 한 번의 학습으로 다태스크 생성, 파라미터 효율↑ |
| 멀티태스킹·제로샷 | Ha’16, Johnson’17 | [LANG] 스페시파이어로 제로샷 번역 | 언어·모달리티 확장 제한 | [LANG] 유지 + 시각 RoI 결합으로 다모달 제로샷 |
| 단일 통합형 생성기 | Kaiser’17 | 단일 모델에 모달리티별 서브모듈 | 구조 복잡(전용 인코더/디코더 등) | 태스크 전용 모듈 없음, 완전 단일 스트림 self-attn |
한눈에 보는 “BERTGEN vs. 기존” 포인트
- NLG 직접화: “MLM→생성 부적합” 논지를 **단일 생성기(ED 분리 없음)**로 무력화.
- 하이브리드 초기화: **VL-BERT(시각) + M-BERT(다국어)**에서 가중치·임베딩·MLM 헤드 이식 → 멀티모달·다국어 유도편향을 초기에 주입.
- 시퀀스 언롤링: 한 예시를 타깃 길이만큼 언롤해 데이터 증강과 **파라미터 효율(ED 대비 약 절반)**을 동시에 달성.
- [LANG] 스펙 + 단일 스트림 self-attn: 언어 전환과 모달 융합을 태스크 불문 동일 규칙으로 처리 → 제로샷 번역·캡션까지 일반화.
메모(연구 적용 관점)
- KURE/HEGA류 파이프라인에서 “하이브리드 초기화 + 시퀀스 언롤링”은 라벨 재정의 없이 다태스크 신호를 크게 증폭시키는 실용 레시피로 읽힙니다(현대 백본으로 대체 가능).
원하시면, 위 표를 **BibTeX 포함 ‘Related Work’ 섹션 초안(영문/국문 병기)**으로 바로 정리해 드리겠습니다.
아래는 업로드하신 원문(BERTGEN: Multi-task Generation through BERT)의 “Method(§2)”를 토대로, 설계 → 입력/표현 → 학습목표(언롤링) → 어텐션 동작 → 디코딩 → 초기화 → 하이퍼파라미터/데이터 순서로 핵심만 깔끔하게 재구성한 설명입니다. 문장 끝의 표시는 모두 원문 근거입니다.
1) 모델 한 줄 요약
**인코더·디코더 분리 없이 ‘단일 Transformer+MLM 헤드’**로 텍스트·시각·다국어 입력을 한 스트림에서 처리하고, MLM 형식의 오토리그레시브 학습으로 캡셔닝/번역/MMT를 멀티태스크 한 번에 학습합니다.
2) 아키텍처(단일 스트림 Transformer)
- 본체: 12층 Transformer(12 heads), d_model=768, d_ff=3072 + MLM 헤드. 파라미터(워드임베딩 제외) ≈ 89.3M. 포지셔널 임베딩은 학습 허용.
- 스트림 구성: [LANG] 지정자 + 텍스트 토큰 + (있다면) RoI 시각 토큰들을 하나의 시퀀스로 넣고, 공유 self-attention으로 인코딩·생성을 동시에 수행. 테스트 시 예측 토큰을 시퀀스에 삽입하고 [MASK]를 한 칸 오른쪽으로 이동합니다.
3) 입력 구성 & 타깃 언어 지정
- 표기: 소스 문장 임베딩 x, 타깃 y, 시각 RoI 특징 v.
- MMT: {x, v, y}, MT: {x, y}, IC: {v, y}.
- 타깃 언어 스페시파이어: 입력 맨 앞에 [DE] 등 언어 토큰을 붙여 출력 언어를 명시(태스크 불문 동일 규칙).
4) 시각 임베딩(Visual embeddings)
- **RoI 특징(2048-d)**을 Bottom-Up/Top-Down 감지기로 사전 추출하고, 신뢰도에 따라 10–100개(k∈[10,100]) 선택. RoI 기하(박스 좌표) 임베딩과 합산하여 최종 시각 임베딩 구성. 감지기 자체는 미세조정하지 않음. 비시각 위치에는 풀-이미지 특징을 반복 삽입.
5) 학습목표: 시퀀스 언롤링(sequence unrolling) 기반 MLE
- 목표식(예: MMT):
[
\mathcal{L}^{(i)}=\sum_{t=1}^{n}\log P!\left(y^{(i)}{t}\mid x^{(i)};v^{(i)};y^{(i)}{<t}\right)
]
각 조건부 항을 하나의 독립 샘플로 보고 타깃 길이 (n) 만큼 언롤링하여 학습(한 에폭 동안 n배 관측). 결과적으로 데이터 증강 효과(평균 타깃 길이만큼 배수)와 **파라미터 효율(ED 절반 수준)**을 동시에 얻습니다.
6) Self-Attention의 동작(언롤링의 영향)
- 양방향(attend-all): 언롤된 하나의 예시 안에서 모든 위치가 서로를 주시(bi-directional).
- 재계산(re-compute): 각 언롤 사례가 독립 샘플이므로 초기 위치의 표현도 단계마다 다시 계산됩니다(전형적인 디코더 캐시와 다름).
- 귀납편향: 단일 스트림에서 입력/출력을 함께 인코딩해 진짜 멀티모달·다국어 공유 표현 공간을 유도.
7) 디코딩(추론)
- 그리디: [MASK] 위치의 최빈 토큰을 시퀀스에 삽입 → [MASK]를 오른쪽으로 한 칸 이동 → [STOP] 예측 시 종료.
- Beam을 쓰지 않는 이유: 언롤링으로 인해 단계마다 self-attention 표현을 재계산해야 하므로 빔 탐색이 느려짐.
8) 하이브리드 초기화(VL-BERT + M-BERT)
- 전이 구성: VL-BERT 체크포인트를 기반으로, 워드 임베딩/Transformer 가중치/MLM 헤드는 M-BERT로 초기화(WordPiece 119K, 104개 언어). 이로써 시각+다국어 유도편향을 동시에 주입합니다(그림 2).
9) 학습 스케줄 & 용량(재현 지표)
- 옵티마이저/스케줄: AdamW, lr=1.3×10⁻⁵, warm-up 16K 스텝, 이후 linear decay, weight decay=1e−4. 포지셔널 임베딩 업데이트 허용. 파라미터(워드 임베딩 제외) ≈89.3M.
- 리소스 메모: 단일 32GB V100 기준, 한 에폭 시간·배치 제약(코드 최적화/혼합정밀·멀티GPU로 단축 가능).
10) 태스크/데이터 구성(멀티태스킹) — 언롤링 후 샘플 수
- IC: FLICKR30K(IM→EN 2.39M, IM→DE 2.48M), FLICKR8K-TASVIRET(IM→TR 263K, 누수 방지 위해 새 스플릿).
- MMT: MULTI30K EN↔DE/FR(예: EN→DE 582K).
- MT: IWSLT EN↔DE/FR, SETIMES EN↔TR(예: EN→TR 8.40M).
→ 언롤링 덕에 코퍼스가 수배로 증강됩니다(표 1).
11) 학습 절차(실전용 Step-by-Step)
- 샘플 준비: 태스크에 따라 {x, v, y}/{x, y}/{v, y}로 시퀀스를 구성하고 맨 앞에 **[LANG]**를 부착.
- 언롤링: 타깃 길이 n만큼 [MASK] 위치를 달리한 n개의 예시로 전개. 각 예시는 독립 샘플로 처리.
- Forward & Loss: 단일 Transformer+MLM 헤드로 양방향 self-attention 인코딩, 목표 토큰에 대해 **CE(로그 우도 합)**를 계산.
- Update: AdamW로 파라미터 업데이트(포지셔널 포함). 태스크를 섞어 멀티태스킹 학습.
- Decode: 추론 시 그리디—예측 토큰을 삽입하고 [MASK] 오른쪽 이동, **[STOP]**에서 종료.
12) 설계 선택의 의미(대안 대비 핵심 포인트)
- ED 분리 없음 → 파라미터 효율 & 단순화: 절반 수준 파라미터로 다태스크 처리.
- 언롤링 → 데이터 증강: 평균 타깃 길이만큼 에폭당 관측 증가.
- [LANG] 지정자 → 제로샷 일반화: 동일 규칙으로 언어 전환 제어.
- 하이브리드 초기화 → 유도편향 이식: 시각+다국어 초기 능력 장착.
한 장 짜리 방법론 요약표
구성요소 핵심| 본체 | 12-layer Transformer + MLM head(단일 스트림) |
| 입력 | {x,v,y} / {x,y} / {v,y} + 맨 앞 [LANG] 지정자 |
| 시각 | 2048-d RoI(10–100개) + 기하 임베딩, 감지기 고정 |
| 목적함수 | (\sum_t \log P(y_t |
| 어텐션 | 언롤 사례마다 양방향·재계산, 공유 표현 공간 유도 |
| 디코딩 | 그리디, [MASK] 오른쪽 이동, [STOP]에서 종료 |
| 초기화 | VL-BERT + M-BERT 하이브리드(임베딩/가중치/MLM 헤드) |
| 스케줄 | AdamW, lr 1.3e-5, warm-up 16k, linear decay, wd 1e-4 |
| 용량 | ≈89.3M(임베딩 제외), 포지션 학습 허용 |
| 데이터 | 언롤링 후: IM→EN 2.39M, EN→TR 8.40M 등(표 1) |
필요하시면 위 내용을 바로 **재현 체크리스트(학습 스크립트/데이터 준비/하이퍼파라미터)**로 변환해 드릴게요.
좋아요. “시퀀스 언롤링(sequence unrolling)”을 BERTGEN이 어떻게 쓰는지를, 수식 → 직관 → 예시 → 기존 seq2seq와의 차이 → 장단점 순서로 딱 정리해볼게요.
1) 한 줄 정의
하나의 (소스, 타깃[, 이미지]) 훈련 샘플에서 타깃 길이 (n) 만큼 **(n)개의 “미니 샘플”**을 만들어, 각 시점 (t)에 대해 (\log P(y_t \mid x;v;y_{<t}))를 독립적으로 관측하며 학습하는 방식이에요. 이렇게 하면 데이터가 타깃 평균 길이만큼 증강되고, BERTGEN은 인코더/디코더를 나누지 않은 단일 Transformer+MLM 헤드로 이 목표를 최적화합니다.
2) 수식으로 보면
BERTGEN은 (예: MMT)에서 다음의 최대우도 목적을 씁니다:
[
\mathcal{L}^{(i)}=\sum_{t=1}^{n}\log P\big(y^{(i)}{t}\mid x^{(i)};v^{(i)};y^{(i)}{<t}\big)
]
차이점은 이 합의 각 항을 한 샘플 안에서 한 번에 계산하는 대신, 샘플을 (n)번 “언롤”해서 (n)개의 독립 예시로 학습한다는 점입니다(각 (t)마다 [MASK]가 가리키는 목표가 다름). 그래서 한 에폭 동안 각 조건부 항이 독립적으로 관측되고, 결과적으로 데이터 증강 효과가 생깁니다.
3) 직관(왜 이런 일을 하나?)
- MLM 형식으로 오토리그레시브 학습을 흉내 내려면, “다음 토큰 예측”을 각 위치 (t)에 대해 별개 예시처럼 만들어 버리면 됩니다. 이렇게 하면 BERT류(양방향 self-attn)를 생성기로 쓸 수 있고(인코더/디코더 불필요), 데이터가 늘어나 학습이 안정·효율적으로 됩니다.
4) 한 눈에 예시(작은 토이)
타깃 문장 (y = [\text{ich},\ \text{liebe},\ \text{Katzen},\ \text{STOP}]) 이라고 해봅시다.
언롤 시점 (t) 모델이 보는 타깃 컨텍스트 (y_{<t}) [MASK] 위치 학습 손실(예시)| 1 | (없음) | y1 → ich | (-\log P(\text{ich}\mid x;v)) |
| 2 | ich | y2 → liebe | (-\log P(\text{liebe}\mid x;v;\text{ich})) |
| 3 | ich liebe | y3 → Katzen | (-\log P(\text{Katzen}\mid x;v;\text{ich liebe})) |
| 4 | ich liebe Katzen | y4 → STOP | (-\log P(\text{STOP}\mid x;v;\text{ich liebe Katzen})) |
즉, 원래 하나였던 샘플이 4개로 늘어나고, 각 언롤 예시는 “해당 [MASK] 위치 토큰”만 맞히도록 학습됩니다. 이게 곧 (\sum_t) 항을 “한 번에”가 아니라 “나눠서” 최적화하는 셈이죠. (BERTGEN의 공식 설명과 동일한 아이디어입니다.)
5) 추론 때는 어떻게?
테스트에선 그리디로 진행합니다: 현재 [MASK] 위치의 최빈 토큰을 시퀀스에 삽입하고 [MASK]를 오른쪽으로 한 칸 이동 → 이를 반복하다가 **[STOP]**이 나오면 종료. 빔 서치는 매 단계 표현을 재계산해야 해서 느려서 쓰지 않았다고 명시되어 있어요(언롤링 덕분에 캐시형 디코더와 달리 매번 재계산).
6) Self-Attention은 어떻게 달라지나?
- 양방향: 언롤된 각 예시 안에선 모든 위치가 서로를 본다(bi-directional).
- 재계산: 언롤 예시가 독립 샘플이므로, 이전 위치의 표현도 단계마다 다시 계산된다(전형적인 디코더 캐시와 대조적).
- 귀납편향: 입력/출력이 단일 스트림에서 공유 self-attn으로 처리돼 진짜 멀티모달·다국어 표현 공간으로 수렴하는 편향을 준다.
7) 기존 seq2seq와의 핵심 차이
- 전통 seq2seq: 하나의 훈련 샘플에서 디코더가 순차적으로 (t=1\to n)을 한 번의 포워드(또는 teacher forcing)로 처리.
- BERTGEN(언롤링): 그 한 샘플을 (n)개로 쪼개서 **각 (t)**를 독립 샘플로 최적화(= 데이터 증강). 이로 인해 단일 Transformer로 인코딩·생성 겸용이 가능하고, 파라미터 효율도 좋아집니다.
8) 장단점 요약
장점
- 데이터 증강: 코퍼스 (D)가 타깃 평균 길이 배로 늘어난 효과.
- 단일 모듈/파라미터 효율: 인코더·디코더를 나누지 않아 파라미터가 절반 수준.
- 멀티태스킹·제로샷에 유리한 공유 표현(단일 스트림 self-attn).
유의점
- 추론 속도: 매 단계 표현 재계산이 필요해 빔 서치가 비경제적(그래서 그리디 채택).
필요하시면, 당신의 Stage-1/2 임베딩·RAG 데이터를 이 포맷으로 변환해 **언롤링 학습 샘플(n-way)**을 자동 생성하는 파이썬 스니펫도 바로 만들어 드릴게요.
아래 정리는 업로드하신 원문(BERTGEN: Multi-task Generation through BERT)만을 근거로, 결과 → 결론 → 한계 → 기여 순으로 핵심 수치와 메시지를 정리한 것입니다.
결과(Result)
1) 이미지 캡셔닝 (IC)
- Flickr30k-EN: BERTGEN BLEU 27.0 / METEOR 23.2 / CIDEr 0.587로, 빔서치를 쓰는 SENTINEL/NBT와 대등~우위(그리디 디코딩임에도).
- COCO(카르파시 스플릿): COCO에 학습하지 않았음에도 점수는 “reasonable”; 다만 NBT 대비 METEOR −6.7.
- 제로샷 캡셔닝(FR/TR/DE): 정량 점수는 낮지만 유효한 기술을 생성(참조 수 및 번역 참조 사용 이슈로 점수 하한).
2) 멀티모달 번역(MMT, Multi30k 2016 test)
- EN→DE: BLEU 42.2 / METEOR 61.6 — FAIRSEQ NMT 및 RNN MMT 초과. EN→FR: 68.0 / 81.2, 강력.
- 제로샷 MMT(DE→FR, FR→DE)에서도 강력(표 4 회색 칸).
- 어드버서리얼(이미지-문장 매핑 셔플): EN→DE에서 BLEU −1.1 / METEOR −0.9, EN→FR에서 BLEU −3.1 / METEOR −2.3 하락 ⇒ 이미지 특징을 실제로 사용.
3) 텍스트 번역(MT, IWSLT/SETIMES)
- 단일태스크 FAIRSEQ NMT 대비: 전반적으로 동급~우위, 특히 METEOR 전쌍 우세(예: EN→DE 27.8/48.4 vs 27.4/47.1).
- 학습 효율: 여러 태스크를 합친 BERTGEN이 소수 패스 후 단일태스크 모델을 빠르게 추월(학습 곡선 비교).
- 제로샷 뉴스 번역(WMT’19 DE↔FR): DE→FR 19.6/40.5, FR→DE 13.1/36.7. 도메인 미스매치로 점수는 낮지만 질적/양적 결과가 고무적.
4) 어블레이션
- 초기화 전략: Hybrid(VL-BERT + M-BERT) > Visual-only > Random.
- 멀티태스킹의 이득: 멀티태스크 > 단일태스크, 카타스트로픽 포겟팅 징후 없음.
결론(Conclusion)
- 단일 생성기로 이미지 캡션·텍스트 번역·멀티모달 번역을 모두 수행하면서,
- 태스크·언어·모달리티 전반에 걸친 범용성,
- 제로샷 일반화(IC/MMT/WMT 뉴스)
- 파라미터 효율(ED 분리 없이 동등/우수 성능)
을 확인했다고 요약합니다.
한계(Limitations) — 논문 근거
- COCO 미학습 성능 격차: COCO에서 NBT 대비 METEOR −6.7.
- 디코딩 제약: 빔 서치 미사용(언롤링으로 매 스텝 재계산 필요 → 느림) ⇒ 그리디 채택.
- 리소스 요구: 단일 32GB V100에서 에폭당 약 2일(코드 최적화·혼합정밀·멀티GPU로 단축 가능).
- 비전 백본 고정: RoI 특징 사전추출 후 감지기 미세조정 안 함(표현력 상한 가능성).
- SOTA NMT와의 직접 비교 한계: 대규모 데이터/복잡한 구조의 최신 NMT 대비 SoTA를 필수적으로 목표로 하지는 않음.
- 토크나이저 차이: M-BERT의 강한 분절로 인해 타 연구와 수치 미세 차이 가능.
기여(Contributions)
- BERT 기반 단일 생성기: 인코더/디코더 분리 없이 다국어×멀티모달×다태스크 통합 생성 프레임.
- 하이브리드 초기화: VL-BERT + M-BERT 가중치/임베딩/MLM 헤드를 결합해 시각·다국어 유도편향 이식.
- 시퀀스 언롤링: (\sum_t \log P(y_t|x;v;y_{<t}))의 각 항을 독립 샘플로 관측해 데이터 증강(타깃 평균 길이 배)과 파라미터 효율(ED 대비 절반 수준)을 동시에 달성.
- 실증적 성과:
- IC: Flickr30k-EN에서 강력 베이스라인 초과.
- MMT: EN→DE/EN→FR에서 FAIRSEQ NMT·RNN MMT 초과, 제로샷 방향에서도 우수.
- MT: FAIRSEQ 단일태스크 대비 전반적으로 우세, 특히 METEOR 전쌍 리드.
- 멀티태스킹·초기화 설계의 효과를 어블레이션으로 검증(하이브리드 초기화 최상, 멀티태스킹 이득, 망각 없음).
- 시각 정보 활용성 검증: 이미지-문장 매핑 셔플 시 성능 유의 하락 → 이미지 특징을 무시하지 않음.
빠른 복습 표
구분 핵심 요약| IC | Flickr30k-EN 27.0/23.2/0.587, COCO는 미학습으로 NBT보다 METEOR −6.7. |
| MMT | EN→DE 42.2/61.6, EN→FR 68.0/81.2, 제로샷도 강함. |
| MT | FAIRSEQ 단일태스크 대비 METEOR 전쌍 우세, 소수 패스에 추월. |
| Ablation | Hybrid 초기화 최상, 멀티태스크 이득, 망각 없음. |
| 결론 | 범용성/제로샷/파라미터 효율을 단일 생성기로 입증. |
| 한계 | COCO 격차, 그리디 디코딩, 학습 시간 큼, RoI 백본 고정, SOTA NMT와 목표 다름. |
필요하시면 위 내용을 슬라이드용 1–2장 요약이나 재현 체크리스트(예: 어떤 표/지표를 반드시 보고, 어떤 ablation을 우선 돌릴지)로 바로 변환해 드릴게요.