https://arxiv.org/abs/2002.08909
REALM: Retrieval-Augmented Language Model Pre-Training
Language model pre-training has been shown to capture a surprising amount of world knowledge, crucial for NLP tasks such as question answering. However, this knowledge is stored implicitly in the parameters of a neural network, requiring ever-larger networ
arxiv.org
파라미터에 지식을 저장하는 lm의 비해석, 비 확장성 문제를 검색을 결합한 사전학습으로 완화한다.
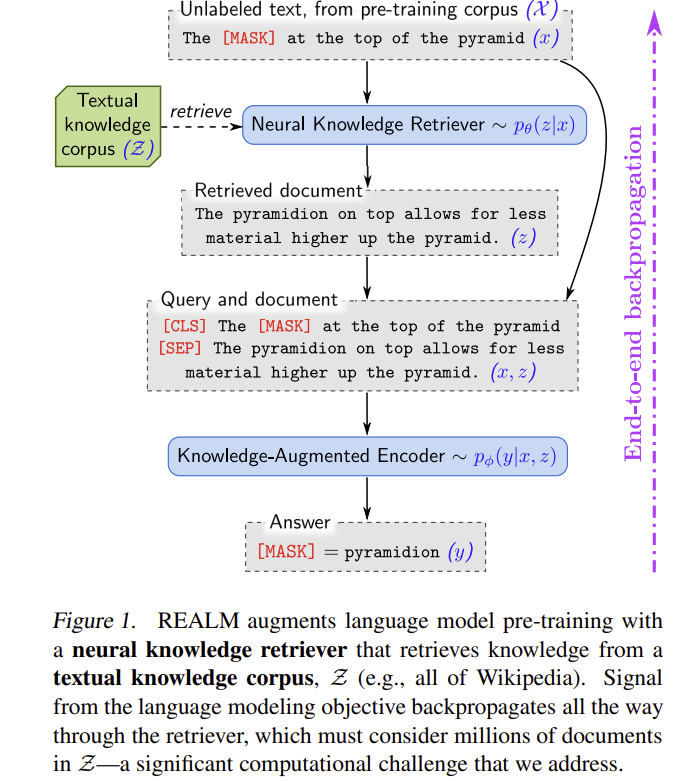
이렇게 Query를 통해 문서를 검색하고, 마스킹 된 단어를 맞추도록 학습한다.
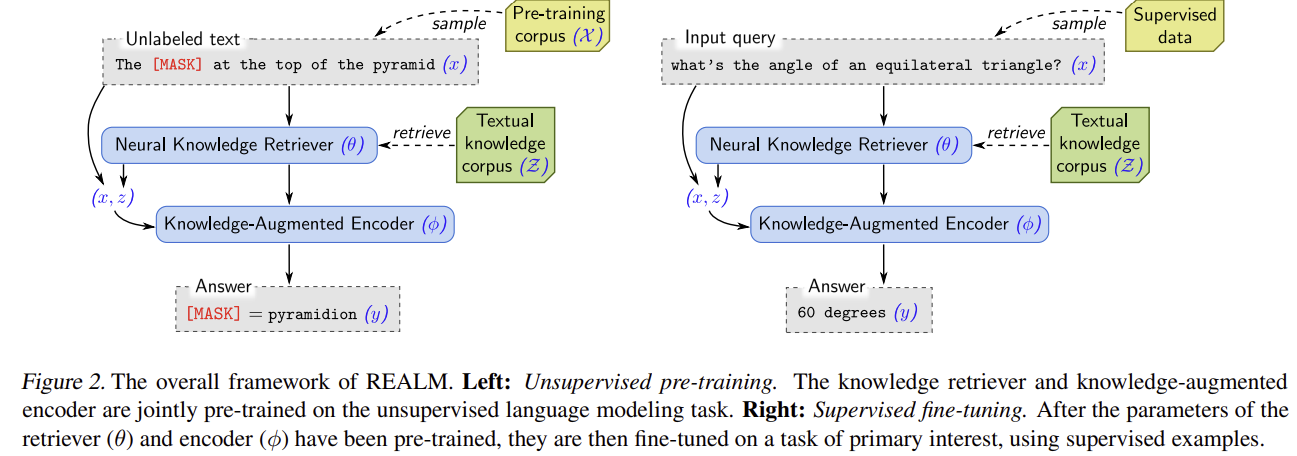
처음엔 마스킹 된 단어를 맞추도록 진행하고, 이 후엔 정답을 맞추도록 진행한다.

성능 야무지다....
T5는 크기에 비해 성능이 떨어지는 것을 볼 수 있다.
| 문제 상황 | LM이 세계 지식을 파라미터 내부에만 저장하면 해석·업데이트가 어렵고, 규모 확장 비용이 큼. Open-domain QA로 “외부 코퍼스의 지식 접근”을 평가 대상으로 채택. |
| 방법론 | 입력 (x)에 대해 문서 (z) 를 확률분포 (p(z | x))에서 검색 후, (p(y | z,x))로 정답 (y)를 예측. 잠재변수 주변화로 (p(y | x)= _{z}p(y | z,x)p(z | x)). 두 모듈: (1) Neural Retriever (p(z | x)), (2) Knowledge-augmented Encoder (p(y | z,x)). |
| Retriever | 덴스 내적 점수 (f(x,z)=<Embed_{input}(x),Embed_{doc}(z)> 를 softmax 정규화해 (p(z | x)) 구성. BERT-style로 [CLS]/[SEP] 규약 사용(제목·본문 분리), [CLS] 풀링 후 선형 투영. |
| Encoder | (x)와 (z)를 단일 시퀀스로 결합, cross-attention으로 상호조건화 후 MLM/QA 목적 계산(파인튜닝에선 span 시작/끝). |
| 계산 전략 | ∑_{z∈Z}를 top-k 근사. (p(z | x))의 순위 = 내적 점수의 순위 → MIPS로 근사 top-k 탐색(시간·메모리 준선형). 학습 중 인덱스가 stale해지므로 수백 스텝마다 비동기 재색인(Trainer/Index-builder 2잡). 선택된 top-k에 대해서만 최신 θ 로 (p(z | x))·기울기 재계산. |
| 유도 편향(핵심 기법) | Salient span masking(개체·날짜 등 세계지식 의존 스팬만 마스킹) → 성능에 결정적. Null 문서(∅) 를 항상 후보에 포함해 “검색 불필요”도 학습. Trivial retrieval 금지(원문 문서 자체 후보 제외). ICT 초기화로 냉시동 방지(입력·문서 임베딩 워밍업). |
| 학습 데이터·학습법 (사전학습) | 코퍼스 X: (1) Wikipedia, (2) CC-News. 스텝/자원: 200k steps, 64 TPU, batch 512, lr 3e-5(BERT 옵티마이저). 문서 임베딩: 16 TPU 병렬. 주변화: 예제당 8 후보(∅ 포함). 인덱스 새로고침: 약 500 스텝/회. |
| 학습 데이터·학습법 (파인튜닝) | 지식 코퍼스 Z: 2018-12-20 위키 스냅샷. 문서를 최대 288 wordpiece로 청크 → 약 1,300만 후보. 추론: top-5만 사용. HP: ORQA와 동일(공정 비교). |
| 실험(벤치마크) | NQ-Open, WebQuestions, CuratedTREC(정확 일치 기준). WQ·CT의 데이터 특성과 평가 세부는 원문에 기술. |
| 결과(핵심 수치) | SOTA: NQ/WQ/CT에서 39.2/40.2/46.8(X=Wiki), 40.4/40.7/42.9(X=CC-News). T5-11B보다 30× 작지만 상회. 다른 검색기반(보통 20–80문서) 대비 top-5만으로 최고 성능. |
| 어블레이션(무엇이 중요한가) | Retriever/Encoder 각각만 바꿔도↑, 둘 다 REALM일 때 최고. Salient masking > 랜덤. 인덱스 새로고침 30× 지연 시 EM 28.7, Recall@5 15.1로 급락(= stale 악영향). |
| 기여(요지) | (1) 사전학습 단계에 검색을 내재화한 잠재변수 LM, (2) MIPS+비동기 재색인으로 대규모 코퍼스에서도 안정 최적화, (3) 근거 문서 노출로 해석·프로버넌스 강화, (4) 작은 모델+top-5로 SOTA. |
| 한계·주의 | (1) 시스템 복잡성: 임베딩·MIPS·비동기 재색인 파이프라인 운영 필요, (2) 신선도 민감: 새로고침 빈도 낮으면 학습 저해, (3) 자원비용: 64 TPU 등 대규모 사전학습 필요(문서 임베딩 16 TPU 병렬). |
REALM (Retrieval-Augmented Language Model Pre-Training) 논문 요약
한눈에 보기 (TL;DR)
- 문제: 세상 지식을 LM 파라미터에 “암묵적으로” 저장하면 모델이 커지고 해석/업데이트가 어렵다. 문서를 검색해 명시적으로 활용하도록 LM 사전학습을 바꾼 것이 REALM의 핵심 동기다.
- 아이디어: 입력 (x)에 대해 문서 (z)를 먼저 검색하고( (p(z\mid x)) ), 그 문서를 활용해 정답 (y) 를 예측( (p(y\mid z,x)) )하는 잠재변수 모델로 사전학습을 수행한다. 목적함수는 (\sum_{z} p(y\mid z,x)p(z\mid x)).
- 핵심 기술: (1) MIPS로 수백만 문서에서 top-k 근사 검색, (2) 검색 인덱스 비동기 새로고침, (3) Salient span masking, Null 문서, 문자열 일치 방지, ICT 초기화 등 편향 유도.
- 결과: Open-QA(NQ-Open, WebQuestions, CuratedTREC)에서 SOTA 달성. T5-11B보다 작고(30× smaller) 더 정확했다. (예: NQ-Open 39.2/40.4, WQ 40.2/40.7, CT 46.8)
- 해석 가능성: 정답에 기여한 근거 문서가 노출되어 모듈성/해석성이 좋아진다.
1) 문제 설정과 동기
- 거대 LM은 학습 말뭉치에서 세계 지식을 습득하지만, 지식을 파라미터 속에 암묵적으로 저장하기 때문에 무엇을 아는지 파악/업데이트가 어렵고, 더 많은 지식을 담으려면 모델 규모가 비효율적으로 커진다.
- 평가 과제로 Open-domain QA를 선택: 질문만 주어지고 정답이 있을 만한 문서가 사전에 주어지지 않기 때문에 지식 접근 능력을 명확히 본다.
2) 방법론 개요 (Retrieve → Predict; 잠재변수 언어모델)
- 생성 과정:
[
p(y\mid x) ;=; \sum_{z\in\mathcal Z} ; p(y\mid z,x); p(z\mid x)
]
① 입력 (x)로부터 지식 문서 (z) 를 샘플(검색)하고, ② (x,z)를 함께 인코딩해 정답 (y) 를 산출한다. - Retriever (p(z\mid x)): BERT 계열 인코더로 만든 입력/문서 임베딩의 내적 점수 (f(x,z)=\langle \mathrm{Embed}{\text{input}}(x),\mathrm{Embed}{\text{doc}}(z)\rangle) 를 소프트맥스로 정규화. 문서 제목/본문을 [CLS]/[SEP] 규약으로 인코딩.
- Knowledge-augmented encoder (p(y\mid z,x)): (x)와 (z)를 결합해 Transformer에 넣어 (a) MLM 사전학습, (b) Open-QA 파인튜닝을 수행. QA에선 span 시작/끝을 점수화해 정답 문자열을 추출한다(전통 RC와 유사).
3) 학습의 계산상 핵심 (MIPS & 비동기 인덱스 갱신)
- (\sum_z)는 거대하므로 top-k 근사 합산으로 근사. top-k 탐색을 MIPS(Maximum Inner Product Search)로 처리한다.
- 인덱스의 ‘staleness’: 학습 중 (\theta)가 변해 문서 임베딩이 구식이 되므로, 수백 스텝마다 문서 재임베딩/재색인을 비동기로 돌려 최신화한다(Trainer ↔ Index builder 2잡 구조).
- 실제로 비동기 새로고침 빈도를 낮추면 성능이 저하된다(30× stale MIPS).
4) 학습 신호가 Retriever를 어떻게 가르치는가 (직관)
- 로그 우도 기울기 전개 시, 각 문서의 점수 업데이트는
(r(z)=\big[\frac{p(y\mid z,x)}{p(y\mid x)}-1\big]p(z\mid x)) 비례.
즉, 해당 문서가 평균보다 잘 맞추면( (p(y\mid z,x)>p(y\mid x)) ) 점수를 올려 더 자주 검색되도록 학습된다.
5) 효과적인 사전학습을 위한 편향(Inductive Bias)
- Salient span masking: 고유명사/날짜 등 세계지식이 필요한 스팬을 우선 마스킹 → REALM에서는 결정적으로 중요.
- Null document: 어떤 경우엔 검색이 불필요하므로 공집합 문서(∅) 를 후보에 포함해 “검색이 이득 없음”을 모델이 학습.
- 문자열 일치 금지: 학습 코퍼스 (X)와 지식 코퍼스 (Z)가 같을 때 원문 문서 자체를 검색 후보에서 제외해 트리비얼 해법 방지.
- 초기화(ICT): Inverse Cloze Task로 Retriever를 웜스타트해서 초기 부정합(검색 무의미 → 인코더가 문서를 무시 → 신호 소실) 악순환을 방지.
6) 실험 설정 (요약)
- 파인튜닝: 2018-12-20 위키 스냅샷을 288 wordpiece로 청크(약 1,300만 후보) 후 top-5로 추론. ORQA와 동일 하이퍼파라미터 재사용.
- 사전학습: 64 TPU, 200k steps, batch 512, lr (3\times10^{-5}). 매 예제마다 8개 후보(∅ 포함)로 주변화. Wikipedia/CC-News 두 코퍼스 실험.
7) 결과 (정량/정성)
- 메인 성능(정확 일치, EM):
NQ-Open 39.2/40.4, WQ 40.2/40.7, CuratedTREC 46.8. T5-11B보다 정확하고 30× 작음. - ORQA 대비: 파인튜닝 설정 동일(공정 비교). 향상은 전적으로 사전학습 개선 효과. 또한 top-5 문서만으로도 SOTA.
- 어블레이션:
- Retriever/Encoder 각각만 바꿔도 개선, 둘 다 REALM일 때 최고.
- 랜덤 마스킹(uniform/span) < salient 마스킹.
- 인덱스 stale 심할수록 악화.
- 정성 사례: “정삼각형… 3은 소수이므로 [MASK]”에서 Fermat를 올바르게 복원(BERT 대비 현저한 확률 향상), 관련 문서 검색 덕분.
8) 실제 적용을 위한 Step-by-Step 가이드
- 지식 코퍼스 구축: 위키 등 대규모 텍스트를 문서/패시지 단위로 청크(예: 288 wp). 인덱스 구축을 염두에 둔 고정 전처리.
- Retriever 초기화: ICT로 입력/문서 쌍 임베딩을 대략 정렬. (초기 검색 무의미 방지)
- 사전학습(MLM):
- Salient span masking 적용.
- 각 배치에서 top-k 문서를 MIPS로 근사 검색 후 ( \sum_{z\in\text{top-k}} p(y\mid z,x)p(z\mid x) ) 를 최대화.
- Null 문서 포함.
- 비동기 재색인: 수백 스텝마다 문서 임베딩/인덱스 갱신.
- 파인튜닝(Open-QA): Retriever/Encoder를 함께 미세조정. 추론 시 top-5 문서만 결합해 span 추출.
- 점검/해석: 정답 기여 문서를 확인해 근거 제시와 오류 분석을 수행.
9) 기여와 한계
- 주요 기여
- LM 사전학습에 검색을 내재화: 지식 접근을 명시적/모듈화/해석 가능하게 함.
- 완전 비지도 사전학습으로 Retriever 공동학습: MLM 신호를 검색까지 역전파.
- 대규모 검색의 실용화: MIPS + 비동기 인덱스 새로고침으로 확장성 확보.
- SOTA Open-QA: 거대 생성 모델보다 작고 정확.
- 한계/주의
- 인덱스 신선도에 민감: 새로고침을 게을리하면 성능 저하.
- 파이프라인 복잡도: 문서 전처리/임베딩/색인/동시 작업 관리가 필요. (구조상 암묵적)
- QA는 추출 기반 설정에 우호적(연속 span 가정). 생성형 답변이 필요한 응용에는 추가 설계가 필요.
10) 한 장 요약 표 (실험 재현/적용용)
항목 내용| 문제 | 세계 지식을 파라미터에만 저장하는 LM의 비해석성/비확장성 문제를, 검색 결합 사전학습으로 완화. |
| 핵심 아이디어 | 잠재 문서 (z) 를 검색( (p(z\mid x)) )→ 문서와 입력을 함께 인코딩해 예측( (p(y\mid z,x)) )→ (\sum_z) 주변화. |
| 모델 구성 | Dense retriever(BERT 임베딩 내적) + Knowledge-augmented encoder(MLM/RC head). |
| 학습 테크닉 | MIPS top-k 근사, 비동기 인덱스 새로고침, salient masking, Null 문서, 문자열 일치 금지, ICT 초기화. |
| 사전학습 설정 | 64 TPU, 200k steps, batch 512, lr 3e-5, 후보 8(∅ 포함), 코퍼스: Wikipedia/CC-News. |
| 파인튜닝 설정 | 위키 2018-12-20 스냅샷, 288 wp 청크(약 1.3천만 후보), 추론 top-5. ORQA와 동일 HP. |
| 주요 성능 | NQ-Open 39.2/40.4, WQ 40.2/40.7, CT 46.8. T5-11B보다 작고 정확(≈30× smaller). |
| 어블레이션 | Retriever/Encoder 각각의 개선, salient masking > 랜덤, stale 인덱스 성능 악화. |
| 정성 사례 | 관련 문서 검색으로 Fermat 복원 확률 급상승(BERT 대비). |
| 장점 | 지식의 모듈성/해석성, 효율적 업데이트 가능성, 작은 모델로 높은 정확도. |
| 한계 | 인덱스 관리/동시화의 시스템 복잡도, 추출 기반 QA 가정. |
11) 연구 확장 아이디어 (당신의 실험 적용 관점)
- Retriever 공동학습을 최신 코퍼스/도메인(의료/법률/한국어 위키+뉴스)로 전개하고, Null 문서 비중과 인덱스 새로고침 주기를 어블레이션. (30× stale 악화 참고)
- 한국어/다국어에서 salient masking(개체/날짜 룰) 품질을 높여 학습 신호의 일관성을 확보.
- 장문 생성/추론에는 추출+생성 혼합(예: 추출 근거를 조건으로 생성)으로 확장.
아래 정리는 업로드하신 REALM 논문 본문과 표/토의를 “직접 근거”로 삼아, 동시대·이전 계열 방법(스파스/덴스 검색기반, 생성기반)을 차이점·장점·단점 중심으로 압축 비교한 것입니다.
REALM과 관련 연구 비교
큰 흐름 한 장 요약
- 검색기반(Open-QA) – 스파스 계열: TF-IDF/BM25 같은 휴리스틱 1차 검색 + 독해기(Reader). DrQA, HardEM, Graph/PathRetriever 등이 여기에 해당. 초기 검색 단계가 커버리지를 제한할 수 있음.
- 검색기반 – 덴스 계열: MIPS 기반 학습형 검색기를 사용. ORQA는 REALM과 유사한 잠재변수 주변화를 쓰지만, 사전학습 없이(혹은 ICT로만) 고정 인덱스로 미세조정하는 점이 핵심 차이. REALM은 사전학습 단계부터 검색을 내재화하고, MIPS 인덱스까지 역전파하며 비동기 재색인을 수행함.
- 생성기반(Closed-book/Seq2Seq): 질문만 인코딩해 정답을 직접 생성. T5-11B 등 대규모 모델이 강력하지만, 지식이 전부 파라미터에 내장되어 대규모화를 요구. REALM은 30× 더 작으면서 T5-11B를 능가함.
방법별 차이·장단점 표
방법 핵심 아이디어 / 지식 저장 학습 신호 검색기 업데이트 대표 수치/특징 장점 단점| DrQA (Chen+ 2017) 등 스파스 계열 | 명시적 지식(코퍼스) + TF-IDF/BM25 1차 검색 → 독해기 | 감독(Extractive QA) 위주 | 검색은 비학습/휴리스틱 중심 | WebQ/CuratedTREC 결과 표기, 스파스 계열로 구분 | 구현 단순, 빠른 1차 필터 | 초기 검색의 커버리지 한계, 파이프라인 이원화 |
| HardEM / Graph / PathRetriever | 스파스/경로/그래프 신호로 후보 축소 후 랭킹 | 감독 | 비학습 1차 검색 + 학습형 재랭크 | 표 1에 성능/아키텍처 제시 | 구조적 단서(경로/그래프) 활용 | 여전히 초기 휴리스틱 단계 병목 |
| ORQA (Lee+ 2019) | 덴스 검색기 + 잠재문서 주변화(Open-QA) | ICT 초기화 + 미세조정 | 고정 인덱스(역전파 X) | 표 1에 덴스(MIPS)로 표기, 성능 비교 기준선 | 덴스 검색으로 커버리지/정확도↑ | 사전학습 내 내재화 부족, 인덱스 갱신·공동학습 부재 |
| T5(Generative) (Roberts+ 2020) | 파라미터 내부 지식(closed-book)로 직접 생성 | 대규모 멀티태스크 사전학습 | 해당 없음 | Base→Large→11B로 커질수록 개선. 11B가 당시 SOTA에 근접/상회 | 문서 불필요, 단순 인퍼런스 경로 | 초대형 모델 필요, 추가 RC 데이터 사용 등 비용↑ |
| REALM | 사전학습부터 ‘검색’을 내재화: (p(y | x)=\sum_z p(y | z,x)p(z | x)). MIPS 인덱스에 역전파, 비동기 재색인 | MLM 신호로 검색기까지 공동학습, Salient Span Masking, Null 문서 | 수백 스텝마다 재임베딩/재색인(≈500 step) |
주: REALM은 salient span masking이 성능에 결정적이며, 인덱스 새로고침 빈도가 낮아지면 성능이 악화됨을 어블레이션으로 확인합니다.
핵심 “차이점” 5가지 (REALM vs. 대표 계열)
- 지식 저장 위치
- T5류: 파라미터 내부(암묵적·폐쇄형) → 크기 확대가 성능과 직결.
- REALM/ORQA: **코퍼스 외부 메모리(문서)**를 명시적으로 참조 → 해석/출처 제시 가능.
- 사전학습에서의 검색 내재화
- ORQA: 잠재변수 모델이지만 사전학습 내 검색 업데이트가 제한적(고정 인덱스 경향).
- REALM: MLM 신호가 검색기까지 역전파, MIPS 인덱스도 공동 최적화.
- 인덱스/임베딩 신선도 관리
- REALM은 ≈500 스텝마다 비동기 재색인; 느리면 성능 하락(“stale MIPS”).
- 스파스/고정형 파이프라인은 이런 공동 최적화 루프가 없음.
- 최소 후보 문서 수 대비 성능
- 여타 검색기반은 20–80문서까지 모으는 경우가 많음.
- REALM은 top-5만으로 전반 최고 성능 보고.
- 규모-성능 트레이드오프
- T5는 모델 50× 확대 → 약 +5pt 개선.
- REALM은 T5-11B보다 30× 작으면서 더 정확.
연구자 관점 실전 코멘트 (장/단점의 실질적 의미)
- REALM의 장점
- 재현·분석 친화적: 예측 근거 문서를 그대로 제시 → 오류 분석과 프로버넌스 제공.
- 지식 업데이트 용이: 파라미터 재학습 없이 코퍼스 교체/증분으로 최신화 여지.
- 효율적 검색: 소수(top-k) 문서로도 높은 정확도(시스템 지연·메모리 부담 완화).
- REALM의 단점/리스크
- 엔지니어링 복잡도: 문서 임베딩/인덱싱/비동기 파이프라인 운영 필요(학습·서빙 모두).
- 인덱스 신선도 의존성: 재색인 주기가 느려지면 학습 신호 왜곡으로 성능 하락.
- 학습 자원 요구: 논문 기준 64 TPU 등 대규모 계산으로 사전학습.
확장 관점(논문 내 토의 연결)
REALM은 “코퍼스를 컨텍스트로 하는 언어모델링”을 한 단계 확장해 전체 코퍼스까지 보는 일반화로 해석 가능하고, 제품키 메모리/메모리 네트워크류의 “대규모 신경 메모리” 연구와도 맞닿아 있습니다. 차이는 REALM의 메모리는 **문서에 ‘구체적’으로 연결(grounded)**되어 해석 가능성을 보장한다는 점입니다.
한 줄 결론
REALM = 검색을 ‘사전학습’에 내재화해, 작은 모델로도 대형 생성형을 능가하는 명시적 지식 접근 프레임 — 단, 인덱스 신선도와 시스템 복잡도를 관리해야 합니다.
아래는 업로드하신 REALM(“Retrieval-Augmented Language Model Pre-Training”) 논문의 방법론을, 수식–구조–학습 절차–계산 이슈–유도 편향–파인튜닝까지 step-by-step으로 정리하고, 이해를 돕는 작은 예시를 곁들인 설명입니다.
1) 문제를 확률모형으로 정의: “가져온 뒤 예측”(retrieve → predict)
REALM은 입력 (x)에 대해 먼저 지식 문서 (z) 를 검색하고, 그 문서를 조건으로 출력 (y)를 예측하는 잠재변수 생성 과정으로 (p(y\mid x))를 모델링합니다:
[
p(y\mid x)=\sum_{z\in\mathcal Z} p(y\mid z,x),p(z\mid x).
]
즉, (i) (p(z\mid x))로 문서 분포에서 후보를 뽑고, (ii) (p(y\mid z,x))로 정답을 내는 2단계입니다.
2) 모델 아키텍처: Retriever + Knowledge-augmented Encoder
2.1 Retriever (p(z\mid x))
- 덴스 내적 모델: (f(x,z)=\langle \text{Embed}{\text{input}}(x),\text{Embed}{\text{doc}}(z)\rangle),
(p(z\mid x)=\text{softmax}_z, f(x,z)). 임베딩은 BERT-style Transformer의 [CLS] 표현을 선형투영하여 사용합니다(문서는 title; body로 인코딩).
2.2 Knowledge-augmented encoder (p(y\mid z,x))
- (x)와 (z)를 하나의 시퀀스로 결합해 Transformer에 넣어 교차 주의(cross-attention) 로 상호조건화를 수행합니다.
- **사전학습(MLM)**일 때: [MASK] 토큰별 로짓을 산출해 표준 MLM 우도를 최대화합니다.
- Open-QA 파인튜닝일 때: 정답 (y)가 문서 (z)의 연속 span에 존재한다고 가정하고, 시작/끝 위치 점수로 span 확률을 정의합니다.
3) 학습 목적함수와 Retriever로의 기울기(직관)
로그우도 (\log p(y\mid x))의 retriever 파라미터에 대한 기울기는
[
\nabla \log p(y\mid x)=\sum_z r(z),\nabla f(x,z),\quad
r(z)=\Big[\frac{p(y\mid z,x)}{p(y\mid x)}-1\Big],p(z\mid x).
]
즉, 해당 문서가 평균보다 예측에 더 도움이 되면( (p(y\mid z,x)>p(y\mid x)) ) 그 문서의 점수를 올려 더 자주 검색되도록 학습됩니다.
4) 계산 이슈와 해결책
4.1 Top-k 근사 + MIPS
전체 코퍼스 (\mathcal Z)에 대한 합은 거대하므로, 확률이 큰 상위 (k)개만 합해 근사합니다. 이때 순서는 내적 (f(x,z))와 동일하므로, MIPS(Maximum Inner Product Search) 로 sub-linear한 근사 검색을 수행합니다.
4.2 “Stale index”와 비동기 재색인
문서 임베딩이 학습 중 갱신되면 인덱스가 금세 낡아(stale) 집니다. REALM은 수백 스텝마다 문서를 재임베딩/재색인하는 비동기 루프(Trainer + Index-builder) 로 신선도를 유지합니다(논문 실험에선 대략 ~500 step 주기). 검색은 약간 낡은 인덱스로 top-k만 고른 뒤, 선택된 문서에 대해서는 최신 파라미터로 확률과 기울기를 재계산합니다. 주기가 느려지면 성능이 실제로 하락함을 어블레이션으로 보입니다.
5) 사전학습을 잘 되게 만드는 유도 편향(Inductive Bias)
- Salient span masking: “United Kingdom”, “July 1969” 같은 세계지식 의존 스팬만 골라 마스킹(NE 태거·정규식 활용). REALM에선 이 편향이 성능에 결정적입니다.
- Null document(∅): 어떤 예제는 검색이 불필요하므로 빈 문서를 항상 후보에 포함해 “검색 안 함”으로도 학습 신호를 보냅니다.
- Trivial retrieval 금지: 사전학습 코퍼스 (X)와 지식 코퍼스 (Z)가 같을 때 원문 문서 그 자체를 후보에서 제외(문자열 매치 편향 방지).
- 초기화(ICT): 초기에 검색이 엉뚱하면 인코더가 문서를 무시하게 되고, 그러면 retriever가 기울기를 못 받아 악순환이 생깁니다. 이를 막기 위해 Inverse Cloze Task(ICT) 로 (\text{Embed}{\text{input}},\text{Embed}{\text{doc}})를 웜스타트합니다.
6) 파인튜닝(Open-QA) 설정 요약
- 지식 코퍼스: 2018-12-20 영어 위키를 문서 청크(최대 288 wordpiece)로 분할 → 약 1,300만 후보.
- 추론: top-5 문서만 결합해 span 추출. (ORQA와 동일 하이퍼파라미터로 공정 비교)
7) “한 눈에” 학습 루프 (사전학습; 의사코드 느낌)
- 입력 생성: 문장에서 salient span을 [MASK]로 바꿔 (x)·정답 (y)를 만듭니다. (∅도 후보에 포함)
- 빠른 검색: 현재 (\theta)로 (p(z\mid x)) 상위 (k) 개를 MIPS로 찾습니다.
- 주변화 우도: 상위 (k)개에 대해 (\sum_{z\in\text{top-}k} p(y\mid z,x),p(z\mid x)) 를 계산(MLM).
- 역전파: (i) 인코더 (\phi) 업데이트, (ii) retriever (\theta)는 (r(z)) 비례로 각 문서 점수 (f(x,z))를 올리거나 내립니다.
- 비동기 재색인: 수백 스텝마다 문서 전체를 재임베딩/재색인(스냅샷 (\theta')로 별도 잡에서 수행)하고 주기적으로 교체합니다.
8) 작동 예시 (직관)
8.1 논문 속 예시(정확 사례)
문장: “An equilateral triangle is easily constructed … because 3 is a prime.” 에서 [MASK]가 “Fermat”일 때,
- BERT는 (p(\text{Fermat}\mid x)\approx 1.1\times10^{-14})
- REALM은 관련 문서 (z:) “257 is … a Fermat prime …” 를 가져오면 (p(\text{Fermat}\mid x,z)=1.0) 에 가깝고, top-8 주변화로 (p(\text{Fermat}\mid x)=0.129)까지 상승합니다(실제 표).
8.2 직관적 장난감 예시(설명용)
- 입력 (x): “The capital of [MASK] is Paris.”
- Retriever (p(z\mid x)): “France의 수도는 파리”가 적힌 위키 문서를 상위로 올립니다.
- Encoder (p(y\mid z,x)): (z)와 (x)를 함께 보며 [MASK]에 “France”를 복원.
- 학습: 이 조합이 평균보다 잘 맞추면( (p(y\mid z,x)>p(y\mid x)) ) 그 (z)의 점수 (f(x,z))를 올리도록 (\theta)가 업데이트됩니다(식의 (r(z)) 항).
9) REALM의 방법론적 포인트 요약
- 사전학습과 검색의 동시 최적화: MLM 신호가 retriever까지 직접 역전파, 인덱스도 주기적 새로고침.
- 선별적 마스킹으로 세계지식 신호 집중 + Null 문서로 “검색 안 해도 됨”을 학습.
- 파인튜닝은 간결: 거대한 후보(≈1,300만) 중 top-5만 결합해 span 예측.
좋은 질문이에요! 핵심은 REALM이 잠재변수(latent document) 모델이기 때문에, 문서 (z)에 대한 확률분포 (p(z\mid x)) 가 꼭 필요하다는 점입니다. 그 분포를 만드는 가장 간단하고 미분가능한 방법이 내적 점수 (f(x,z)) 를 소프트맥스(softmax) 로 정규화하는 방식이에요. 논문은 아래처럼 정의합니다:
(p(z\mid x)=\dfrac{\exp f(x,z)}{\sum_{z'}\exp f(x,z')}), (f(x,z)=\langle \text{Embed}{\text{input}}(x),\text{Embed}{\text{doc}}(z)\rangle) (BERT 기반 임베딩의 내적). 또한 문서는 [CLS] 제목 [SEP] 본문 [SEP] 규약으로 인코딩해 [CLS] 벡터를 문서 표현으로 씁니다.
왜 softmax 정규화인가?
1) REALM의 목표식이 ‘분포’를 요구
REALM은 출력 (y)의 가능도를
[
p(y\mid x)=\sum_{z\in\mathcal{Z}} p(y\mid z,x),p(z\mid x)
]
처럼 문서 분포 (p(z\mid x)) 로 주변화(marginalize)합니다. 즉, (p(z\mid x))는 합이 1인 확률분포여야 하고, 그 위에서 기댓값을 취해야 해요. Softmax는 임의의 실수 점수 (f(x,z))를 이런 분포로 만드는 표준 방식입니다.
만약 정규화하지 않고 “점수만” 사용하면? → (\sum_z p(y\mid z,x),p(z\mid x)) 형태의 올바른 기대를 정의할 수 없고, 잠재변수 최대우도학습의 안정적 기울기(아래 #2)가 사라집니다.
2) 깔끔한 기울기(“이득-기반” 업데이트)가 나오기 때문
softmax를 쓰면 로그우도 (\log p(y\mid x))의 retriever 쪽 기울기가
[
\nabla \log p(y\mid x)=\sum_{z} r(z),\nabla f(x,z),\qquad
r(z)=\Big[\frac{p(y\mid z,x)}{p(y\mid x)}-1\Big],p(z\mid x)
]
처럼 **“평균보다 잘 맞춘 문서는 올리고, 못한 문서는 내린다”**는 이득(advantage) 형태로 떨어집니다. 이 예쁜 형태는 softmax 정규화에서 오는 (\nabla\log p(z\mid x)) 전개 덕분이에요.
또, 이상적인 상황(정답 문서 (z^*) 하나만 100% 맞춤)에서는 이 기울기가 그 문서를 정답으로 두고 분류를 학습하는 전형적인 MLE(최대우도) 목적과 같아집니다. 즉, REALM의 비지도 사전학습이 감독학습적 검색학습과 연결돼요.
반대로, 문서마다 독립 시그모이드(=정규화 없는 “여럿 긍정”)를 쓰면, “모두 올려버리기”가 가능해져 선택-경쟁 구조가 약해지고, 위의 기대-기반 기울기 형태도 무너집니다.
3) 최적화·탐색에 유리한 “경쟁(competition)” 구조
softmax는 확률 질량 보존(합=1)을 강제해 문서 간 경쟁을 유도합니다. 덕분에 상위 문서에 확률을 재할당하는 식으로 빠르게 랭킹을 정제할 수 있어요. 실제로 REALM은 학습 중 top-(k)만 주변화하면서 문서 순서가 (p(z\mid x))와 (f(x,z))에서 동일하다는 성질을 이용해 MIPS로 효율적으로 탐색합니다.
4) 대규모 검색과 궁합(내적→MIPS)
점수를 내적으로 둔 이유는, 대규모 코퍼스에서 MIPS(Maximum Inner Product Search) 를 쓸 수 있기 때문입니다. softmax는 이 내적 점수의 상대 순위만 보존하면 되므로, 근사 top-(k)를 빠르게 찾고(소요 시간·메모리 준선형 이하), 그 후에만 정확한 (p(z\mid x))와 기울기를 다시 계산합니다(인덱스는 수백 스텝마다 비동기 갱신).
[CLS]/[SEP]로 제목·본문을 나누는 이유
- BERT 규약: [CLS] x [SEP] 또는 [CLS] x1 [SEP] x2 [SEP] 를 넣으면, [CLS] 토큰 벡터가 시퀀스의 풀링 표현(BERT(_\text{CLS}))으로 나오며, 여기에 선형투영 (W)을 걸어 고정길이 임베딩을 얻습니다. 문서는 제목(title)과 본문(body) 를 구분해 인코딩합니다(정보 밀도가 높은 제목을 별도 표식으로).
- 이 방식은 문서 경계/구조 정보를 명시해 주고, retriever/encoder가 제목 신호를 활용해 빠르게 유사 문서를 올리는 데 도움을 줍니다(실험 파이프라인의 기본 구현).
작은 수치 예시(직관)
질문 (x)에 대해 세 문서의 내적 점수가 (f=[2.0,,1.0,,0.0]) 라면
- softmax (p(z\mid x)=\text{softmax}(f)=[0.665,,0.245,,0.090]).
- 만약 첫 번째 문서로 정답 예측 확률이 (p(y\mid z_1,x)=0.6), 평균 (p(y\mid x)=0.5) 라면
(r(z_1)=\big(\frac{0.6}{0.5}-1\big)\times 0.665=0.133) → 점수 상승,
반대로 (p(y\mid z_3,x)=0.3)이면 (r(z_3)<0) → 점수 하향.
즉 softmax 분포 덕분에 평균 대비 성능(advantage) 에 비례해 확률 질량이 재분배됩니다. 이 업데이트 공식은 논문의 유도 그대로입니다.
요약 한 줄
- 왜 softmax? 잠재문서 주변화를 위한 정규화된 분포가 필요하고, 그로부터 안정적·해석적 기울기(advantage 형태)가 유도되며, MIPS와 결합해 대규모 검색을 효율적으로 돌릴 수 있기 때문입니다.
- Open-QA SOTA 달성: NQ-Open / WebQuestions / CuratedTREC에서 각각 39.2, 40.2, 46.8(사전학습 X=Wikipedia, Z=Wikipedia) 및 40.4, 40.7, 42.9(X=CC-News, Z=Wikipedia)로 기존 방법을 상회. 동일 세팅의 ORQA 대비 이득은 전적으로 더 나은 사전학습에서 기인한다고 명시. 또한 **상위 5개 문서(top-5)**만으로 최고 성능을 달성.
- 초대형 생성형(T5-11B) 대비 우위: T5는 크기 증가로 점진적 향상이 있으나 비용이 큼(베이스→11B 약 50×). REALM은 30× 더 작으면서 T5-11B를 능가. T5는 사전학습 시 SQuAD 추가 사용(>10만 예제), REALM은 미사용.
- 어블레이션(핵심 구성요소의 효과):
- Retriever/Encoder 각각만 바꿔도 개선, 둘 모두 REALM일 때 최고.
- Salient span masking이 랜덤(uniform/span) 마스킹보다 우수 → REALM에서 결정적.
- 인덱스 신선도: 새로고침을 30× 느리게 하면 성능 급락(EM 28.7, Recall@5 15.1).
- 사전학습 중 약 500 스텝마다 비동기 재색인이 효과적임을 실증.
- 정성 사례: “Fermat” 복원 예시처럼, 적절 문서 검색으로 MLM 정확도가 극적으로 상승(BERT 대비).
결론 (Conclusions)
- 사전학습 단계에서 ‘검색’을 내재화한 잠재변수 LM이, 대규모 파라미터에 지식을 내장하는 방식(예: T5)보다 작은 모델로도 더 정확할 수 있음을 입증.
- 검색기와 인코더의 공동 최적화(MLM 신호가 retriever까지 전달) + MIPS 기반 확장성 + 비동기 인덱스 새로고침으로 현실적 규모의 코퍼스에서 안정적으로 최적화됨.
- 접근 자체를 “코퍼스를 컨텍스트로 하는 언어모델링”의 다음 단계로 해석 가능(문단·문서 범위를 넘어 전체 코퍼스까지).
한계 (Limitations)
- 시스템 복잡도·신선도 의존성: 문서 전임베딩, MIPS 인덱싱, 주기적(≈500 step) 비동기 재색인 등 엔지니어링 오버헤드가 크며, 인덱스가 stale해지면 성능 손상.
- 학습 자원 비용: 논문 기준 사전학습은 64 TPU / 200k step, 문서 임베딩은 16 TPU 병렬 등 대규모 연산이 필요. (파인튜닝 자체는 상대적으로 경량화 가능)
- 검색 품질 편향: 마스킹/코퍼스 품질·시기(스냅샷)에 성능이 민감. (예: 위키 2018→2020 업데이트 시 정답 회복)
기여 (Contributions)
- REALM 프레임 제안: LM 사전학습에 학습형 지식 검색기를 결합, 주변화 우도 최대화로 retriever까지 성능 기반 신호(advantage)로 학습.
- 대규모 검색 최적화: MIPS + 비동기 재색인으로 대규모 코퍼스에서도 안정적 최적화 달성(상위 k만 재계산).
- 효율적 추론: top-5 문서만으로도 타 방법(20–80 문서 검색) 대비 전반 최고 성능.
- 모듈성·해석성·업데이트 용이성: 지식을 문서로 명시적 저장하므로 근거 제시가 가능하고, 코퍼스 갱신만으로 지식 최신화가 가능(“grounded memory”).
- 경쟁적 베이스라인 초월: ORQA 대비 동일 파인튜닝 세팅에서 사전학습의 개선만으로 유의미 향상, T5-11B보다 작고 정확.
한 장 표 (실험 재현·응용용)
항목 핵심 정리 근거| 메인 성능 | NQ 39.2/40.4, WQ 40.2/40.7, CT 46.8/42.9 | |
| T5-11B 비교 | 30× 더 작지만 T5-11B 상회 | |
| top-k | top-5만으로 최고 성능(타 방법 20–80+) | |
| 어블레이션 | Salient masking 필수, stale index 악영향 | |
| 계산 전략 | MIPS + 비동기 재색인(≈500 step) | |
| 프레이밍 | “코퍼스를 컨텍스트로” LM로 일반화 |
필요하시면 위 표를 LaTeX/HTML 버전으로 바로 붙여 쓰도록 변환해 드릴게요.
'인공지능 > 논문 리뷰 or 진행' 카테고리의 다른 글
| WOUAF: Weight Modulation for User Attribution and Fingerprinting in Text-to-Image Diffusion Models (0) | 2025.10.21 |
|---|---|
| BERTGEN: Multi-task Generation through BERT (0) | 2025.10.21 |
| RELAM: LEARNING ANTICIPATION MODEL FOR REWARDING VISUAL ROBOTIC MANIPULATION (0) | 2025.10.19 |
| REFRAG: Rethinking RAG based Decoding (0) | 2025.10.16 |
| 인공지능 저작권 보호 (Copyright protection in AI) - 1 (1) | 2025.09.24 |