
Encoder - wartermark를 이미지에 넣어줌
Decoder - 워터마킹된 이미지에서 추출함
사람 눈에는 워터마킹이 눈에 띄지 않는다.

이 화면은 뉴럴 워터마킹 강건성(복원 정확도) 실험 결과를 모아 놓은 그래프입니다. (HiDDeN 스타일)
무엇을 보여주나
- y축: Accuracy (bits %) — 삽입한 워터마크 비트가 얼마나 정확히 복원되었는지(비트 정확도).
- x축: 공격 강도
- Dropout (p): 픽셀을 무작위로 지우는 비율(또는 생존 확률) 변화.
- Cropout (p): 이미지 일부를 잘라내고 빈 영역을 채우는 유형의 크롭형 손상.
- Crop (p): 단순 크롭 비율 변화.
- Gaussian Blur (σ): 블러 강도(표준편차).
- JPEG (Q): JPEG 품질(Quality). 낮을수록 압축 손상 큼.
- 세 가지 학습 설정(곡선)
- Identity (파란색): 노이즈/공격 없이 학습 → 공격이 생기면 급격히 성능 하락.
- Specialized (주황색): 한 가지 특정 공격 강도에 맞춰 학습 → 그 지점(★) 부근에서 최고 성능, 다른 공격이나 강도엔 일반화 한계.
- Combined (초록색): 여러 공격을 섞어 학습 → 최고점은 양보하지만 넓은 범위에서 안정적(실전 친화).
그래프 해석 포인트
- **파란색(Identity)**가 모든 패널에서 가장 빨리 무너지는 이유: 학습 시 공격을 보지 못했기 때문.
- **주황색(Specialized)**는 ★ 근처에서 100%에 가까운 복원률을 보이나, 강도가 달라지면 급락 가능.
- **초록색(Combined)**는 전 구간 평균적으로 가장 견고—실제 배포 환경의 변동성에 강함.
실무 시사점
- 배포 경로에서 예상되는 왜곡(JPEG Q, 리사이즈/크롭, 약블러)을 학습 중 노이즈 레이어로 주입하라.
- 한 공격만 대비하면 운영 중 다른 변형에서 깨질 수 있으니, 기본값은 Combined 학습.
- **ECC(에러정정)**와 **임계값 튜닝(ROC 기반)**을 함께 쓰면 오탐/미탐을 더 잘 통제 가능.
마지막 한 줄(핵심 저장)
“노이즈 없이 학습하면 공격에 취약, 한 가지에 특화하면 범용성이 약하다—여러 공격을 섞어 학습(Combined)해야 실제 환경에서 워터마크 복원률이 안정적으로 유지된다.”
Dropout - 픽셀을 무작위로 지우는 비율
Cropout - 이미지 일부를 잘라내고, 빈 영역을 채우는 유형
Crop - 단순 크롭 비율 변화
Gaussian Blur - 블러 강도(표준 편차)
JPEG - JPEG 품질로 낮을 수록 압축 손상 큼
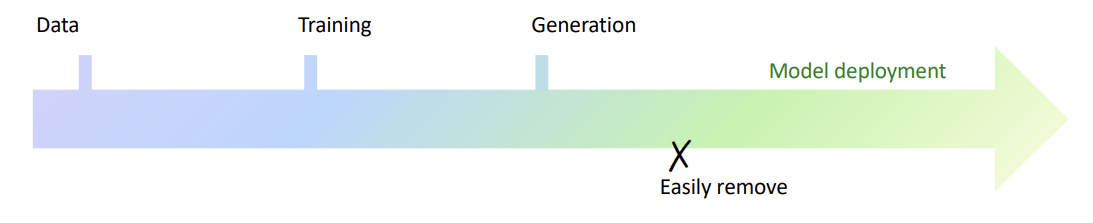
기존의 워터마킹 방법은 사후 마킹 방법으로 지우기 쉬웠음
-> 새로운 워터마킹 방법 개발!!
Stable Diffusion은 오픈 소스로, 사후(post-hoc) 워터마킹이 되는 방법이다. -> 지우기 쉬움. 주석 처리 하나로 사라져버림
Generation 단계에서 워터마킹이 되면 지우기 어렵고, 또 다른 과정이 필요하지 않다.
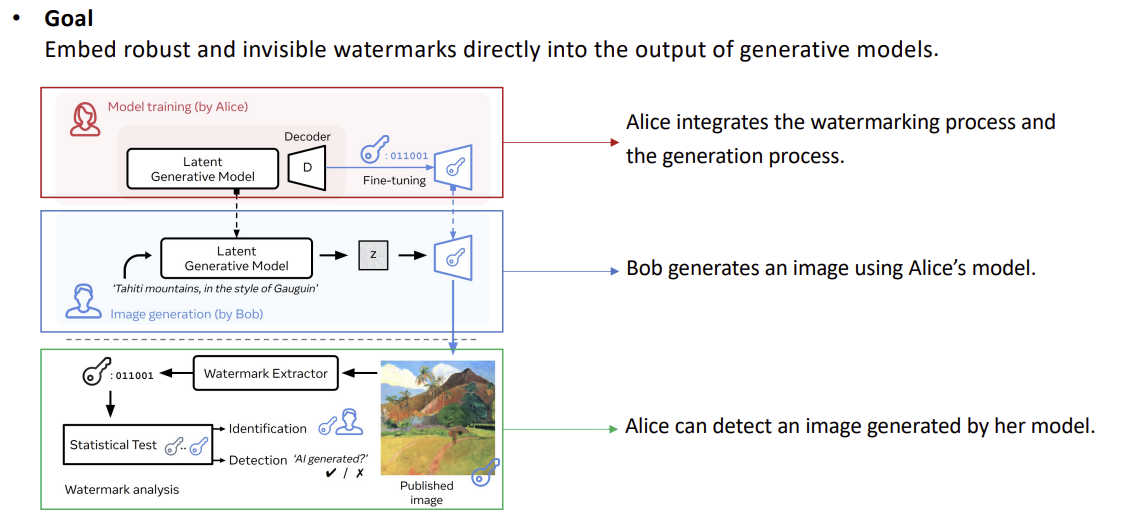
이 도식은 **“생성 과정에 워터마킹을 내재화(anchoring)해 배포 후에도 검출·식별하는 전체 파이프라인”**을 단계별로 보여줍니다.
1) 모델 학습(위, Alice)
- 목표: 모델이 이미지를 만들 때마다 **보이지 않는 비트열(워터마크)**이 자동으로 출력에 섞이도록 함.
- 방법
- 페이로드(예: 모델/사용자 ID)를 ECC로 인코딩 → 비트열 b.
- 비밀 키 k로 삽입 위치/패턴을 결정.
- VAE 디코더 등 생성 경로를 미세조정하며 다음 손실을 동시 최적화:
- 워터마크 복원 손실(CE/BCE): 추출기 출력 (\hat b) ≈ (b)
- 지각 손실(LPIPS/SSIM): 비가시성 유지
- 노이즈 레이어(JPEG/리사이즈/크롭/블러): 강건성 학습
- 결과: “워터마크 삽입기 + 생성기”가 하나의 모델로 통합.
2) 생성(가운데, Bob)
- Bob은 평소처럼 텍스트 프롬프트와 시드 z로 이미지를 생성.
- 추가 단계 없이 워터마크가 내재된 결과가 나온다(사용자는 표식을 인지하지 못함).
3) 검증(아래, Alice/검증기관)
- 공개 이미지 → 워터마크 추출기(+ 키 k) → 복원 비트열 (\hat b).
- 통계적 검정/임계값으로 두 가지를 판정:
- Detection: “이건 해당 AI가 생성했는가?”(존재 여부)
- Identification: “어느 모델/사용자 키로 생성됐는가?”(귀속/지문)
- 오탐 제어: ROC 기반 임계값, p-value 보고. ECC로 비트 오류 보정.
왜 이렇게 설계하나(포스트-혹 대비 이점)
- 제거 난이도↑: 생성 파이프라인 내에 고정 → 후처리 코드 삭제만으론 제거 어려움.
- 운영 단순화: 사용자 입장에선 일반 생성 절차와 동일.
- 확장성: 사용자별 키/페이로드로 지문화(fingerprinting) 가능.
실무 체크리스트
- 배포 경로의 우세 왜곡(예: JPEG Q 30–75, 소폭 리사이즈/크롭)을 노이즈 레이어로 학습.
- 버전 관리: (모델, 추출기, 키, ECC) 쌍을 기록.
- 프라이버시/법무: 오탐률 목표를 명시하고(예: 1e-6), 감사 로그에 검정 통계량 저장.
마지막 한 줄(핵심 저장)
“학습 단계에서 생성기(특히 VAE 디코더)에 키 기반 비트를 내재화 → 생성 시 자동 삽입 → 추출기+통계검정으로 ‘AI 생성/소유자’를 강건하게 판별한다.”

이 도식은 잠재 노이즈(latent noise) 워터마킹의 전체 파이프라인(삽입→생성→검출)을 압축한 그림입니다. Tree-Ring류 방식의 일반화된 형태로 보면 이해가 쉽습니다.
위: Watermarking (삽입 단계)
- Latent Noise
- 확산 모델이 샘플링을 시작할 때 쓰는 초기 잠재 노이즈 (z_0)입니다.
- Distribution Modification
- 비밀 키 (k)로 결정된 패턴(예: 푸리에 공간의 고리(ring) 마스크, 위상/크기 편이, 다중밴드 등)을 이용해 (z_0)의 분포를 미세 변형합니다.
- 예: ( \tilde z_0 = z_0 + \alpha, M_k ) 또는 주파수 도메인에서 ( \mathcal{F}(\tilde z_0)[\Omega_k] \leftarrow \mathcal{F}(z_0)[\Omega_k] + s_k ).
- 여기서 (M_k) 또는 (\Omega_k)는 키로 선택된 위치/대역, (\alpha)는 삽입 강도, (s_k)는 시드 기반 PN 시퀀스입니다. (보통 ECC로 페이로드를 보호)
- VAE Decoder(및 확산 생성기)
- 변형된 (\tilde z_0)로부터 확산 샘플링을 수행하고, 최종 잠재를 VAE 디코더가 RGB 이미지로 복원합니다.
- 결과 이미지는 육안으로 거의 동일하지만, (\tilde z_0)에 남긴 신호가 생성 과정에 전파됩니다.
아래: Extracting watermark (검출 단계)
- Diffusion Inversion
- 공개된 이미지를 **역확산(DDIM inversion 등)**으로 되돌려 초기 잠재의 추정치 (\hat z_0)를 얻습니다.
- 파이프라인(스케줄러, 가이던스 스케일, VAE 버전)이 학습/생성 때와 일치할수록 (\hat z_0)의 오차가 작아집니다.
- Calculate Distance to Watermark & Statistical Test
- 키 (k)로 정의된 템플릿 (M_k) 또는 스펙트럼 마스크 (\Omega_k)에 대해, 상관/거리 통계를 계산합니다.
- 예: 정규화 상관 ( T=\frac{\langle \hat z_0, M_k\rangle}{|\hat z_0|,|M_k|} ) 또는 마스크 에너지 비율.
- 가설검정으로 임계값을 정해 탐지(있다/없다), 필요 시 **식별(어느 키/사용자인가)**을 판정합니다. (오탐률을 ROC로 관리)
장점과 한계 (그림이 암시하는 바)
- 장점: 모델 가중치를 수정하지 않아도 되므로 간편하고 도입 비용이 낮습니다. 사용자별 키로 지문화도 가능합니다.
- 한계/주의:
- 검출이 역확산 정확도에 의존 → 모델/스케줄러 불일치, 강한 크롭/리사이즈/재합성에서 신호가 약화될 수 있습니다.
- 재노이즈-재샘플링 공격(이미지를 다시 노이즈화해 다시 생성)으로 표식이 희석될 수 있습니다.
- 보완책: 다중 대역/다중 링, 회전·스케일 불변 템플릿, ECC, 혼합 왜곡 조건에서 임계값 튜닝.
실무 체크리스트
- 배포 경로(JPEG Q, 리사이즈, 약블러)에 맞춰 **패턴 강도 (\alpha)**와 검정 임계값을 교정.
- 버전 고정: VAE/스케줄러/가이던스가 바뀌면 역확산 오차↑ → 검출력 저하.
- 로그/감사: 검정 통계량, p-value, 키 버전, ECC 파라미터를 기록.
마지막 한 줄(핵심 저장)
“초기 잠재 노이즈를 키로 미세 변형해 생성물에 흔적을 남기고, 역확산으로 그 잠재를 복원해 ‘키 템플릿과의 상관’을 통계적으로 검정해 워터마크를 판별한다.”

이렇게 결과물 자체에는 큰 차이가 없다.

이렇게 학습하는 방법도 있다.
두 방식의 핵심 차이는 워터마크를 어디서/어떻게 심고, 어떻게 읽느냐입니다.
방금 전 방식은 잠재 노이즈 수정(예: Tree-Ring), 지금 슬라이드는 **VAE 디코더만 미세조정(Stable-Signature 계열)**입니다.
| 삽입 위치/타이밍 | 생성 시작 노이즈 (z_0) 를 키로 미세 변형(주파수 링 등) | VAE 디코더가 이미지를 복원할 때 비트가 자동 섞이도록 가중치 미세조정 |
| 추가 학습 | 불필요(모델 가중치 그대로) | 필요(디코더만 학습, 추출기는 보통 사전학습 고정) |
| 검출 방식 | 결과 이미지를 역확산해 (\hat z_0) 추정 → 키 템플릿과 상관/검정 | 결과 이미지를 워터마크 디코더에 넣어 비트 복원(블라인드) |
| 강건성(일반적) | 역확산 오차·강한 편집(크롭/리사이즈/재합성)에 민감 | 혼합 노이즈로 학습하면 상대적으로 강건 |
| 제거 난이도 | 재노이즈-재샘플링 등으로 희석 가능 | 모델 내부 경로라 후처리만으론 제거 어려움 |
| 버전 의존성 | 모델/스케줄러가 바뀌면 검출 약화 | 탐지기–디코더 쌍 버전 관리가 필요 |
| 지문화/식별 | 키만 바꿔도 가능(가볍게 운영) | 페이로드/키 관리로 가능, 표현력은 추출기 품질에 좌우 |
| 도입/운영 비용 | 낮음(코드 추가만) | 중간(추가 학습·배포 필요) |
| 실패 모드 | 역확산 불일치, 강한 기하/재합성 | 학습 미스매치, 탐지기 과적합/버전 드리프트 |
언제 무엇을 쓸까
- 빠른 도입·저비용·모델 수정 불가 환경 → 잠재 노이즈 삽입.
- 실전 강건성·후처리 제거 저항·서비스형 배포 → VAE-디코더 미세조정 (혼합 노이즈+ECC 추천).
마지막 한 줄(핵심 저장)
“잠재 노이즈 삽입은 ‘무학습·역확산 검출’, VAE-디코더 미세조정은 ‘학습으로 출력에 내재·추출기로 복원’—전자는 간편, 후자는 강건.”
여기선 차이가 거의 없다.

이렇게 검출기를 사용하거나 차이를 줘야 보인다.

요점만 딱 정리해 드릴게요.
슬라이드의 방식은 **“VAE 디코더와 워터마크 디코더(추출기)를 함께 학습”**하는 케이스이고, 비교 대상은 **“VAE 디코더만 미세조정(추출기는 고정/사전학습)”**입니다.
핵심 차이
구분 VAE만 미세조정 (Stable-Signature 계열) VAE+추출기 공동학습 (예: WOUAF 계열)| 학습 대상 | VAE 디코더만 업데이트, 추출기는 고정 | VAE 디코더+추출기 모두 업데이트(공적응) |
| 그래디언트 흐름 | 추출기 출력 → CE/BCE 손실이 VAE로만 역전파 | 같은 손실이 VAE와 추출기 모두에 역전파 |
| 강건성(혼합 왜곡) | 추출기 표현력 한계에 성능 상한 | 추출기가 공격 분포에 함께 적응 → BER↓/ROC↑ 기대 |
| 용량/지문화 | 페이로드 용량·사용자 분리력은 고정 추출기 한계 | 가중치/특징 변조로 용량↑·사용자 식별력↑ 설계 용이 |
| 배포/운영 | 단순: 추출기 버전 1개로 여러 모델 커버 가능 | 모델–추출기 쌍을 동일 버전으로 관리·배포 필요 |
| 호환성/검증 | 제3자 검증에 비교적 쉽게 공유(표준 추출기) | 해당 추출기 없으면 검출 불가(의존성↑) |
| 비용/위험 | 학습 비용↓, 과적합 위험↓ | 학습 비용↑, 공적응 과적합/버전 드리프트 위험 |
| 실패 모드 | 강한/미학습 왜곡에서 급락 가능 | 추출기 교체/업데이트 누락 시 검출 실패 가능 |
실무 선택 가이드
- 운영 단순성·낮은 비용·검증 호환성이 우선 → VAE만 미세조정 + 표준(고정) 추출기.
- 최대 강건성·사용자 지문화(식별)·용량 확대가 목표 → VAE+추출기 공동학습(혼합 노이즈 학습 + ECC 권장).
- 공동학습을 쓸 때는 반드시 모델–추출기 버전 페어링과 ROC/임계값 재보정(배포 채널별)을 운영 절차에 포함하세요.
한 줄 결론
“고정 추출기 + VAE만 튜닝은 간단하고 보편적, VAE+추출기 공동학습은 공적응으로 강건성과 지문화가 더 세지만 ‘버전 결합’ 비용을 치러야 합니다.”
학습 데이터에 워터마크가 있더라도 모델은 그 워터마크를 학습 하지 않기 때문에 상관 없다.

1) 한눈에 핵심
- 목표: 생성 단계에서 자동으로 삽입되고 쉽게 지워지지 않는 보이지 않는 워터마크를 구현한다. 전통적 “사후(post-hoc) 삽입”은 제거가 쉬우므로, 모델/훈련 단계에 내재화하는 접근이 중요하다.
2) 뉴럴 워터마킹 기본 아키텍처 (Encoder–Noise–Decoder)
- Encoder: 원본에 비가시적 표식을 삽입하는 신경망(CNN 등).
- Noise layer: 학습 중 JPEG/리사이즈/크롭/블러 등 공격을 시뮬레이션하여 강건성↑.
- Decoder: 결과물에서 표식을 복원/검출.
→ 대표 예: HiDDeN (ECCV’18). 이 구조는 현대 뉴럴 워터마킹의 기본 레시피다.
3) “사후(post-hoc) 삽입”의 한계와 내재화(anchoring)
- 공개 모델(예: Stable Diffusion)의 생성 후 워터마킹 코드는 사용자/공격자가 간단히 비활성화 가능.
- 해결: 워터마크를 생성 파이프라인 내부(모델/훈련 단계)로 가져와 삭제 난이도와 운영 편의성을 동시에 높인다.
4) 확산(디퓨전) 모델에서의 워터마킹 방법
A. 잠재 노이즈(latent noise) 삽입 — 학습 불필요
- 생성 시작 노이즈의 주파수/위상 영역에 키 기반 패턴을 삽입.
- 검출 시 역확산(inversion)으로 시작 노이즈를 추정해 상관 검정.
- 장점: 모델 가중치 수정 無, 배포 용이. 단점: 역확산/강한 편집·재합성에 민감.
- 예: Tree-Ring (NeurIPS’23).
B. 미세조정(fine-tuning) 기반 내재화
- Stable Signature (ICCV’23)
- VAE 디코더만 미세조정 + 사전학습(고정) 탐지기로 비트 복원.
- 장점: 구현/배포 단순. 한계: 탐지기의 표현력에 성능이 좌우.
- WOUAF (CVPR’24)
- VAE 디코더 + 탐지기 동시 학습(co-adaptation).
- 장점: 강건성·지문화(사용자 식별)↑, 단점: 학습/버전 관리 비용↑.
5) 데이터셋 워터마킹(Training-time watermarking)
- 단순히 워터마크가 박힌 이미지들로만 학습한다고 해서, 생성물이 그대로 표식을 내보내는 것은 아님(모델이 그 패턴을 “학습”하도록 설계가 필요).
- 목표: 훈련 데이터의 표식 → 모델 → 생성물로 전이되게 설계.
- 관련 연구: DIAGNOSIS (ICLR’24)—무단 데이터 사용 여부를 식별/검출하는 프레임워크.
6) 평가·운영 체크리스트
- 비가시성: PSNR/SSIM·LPIPS로 품질 저하 최소화.
- 강건성: JPEG(Q), 리사이즈, 크롭, 블러 등 공격 강도별 BER/정확도 곡선 보고.
- 검출 설정: 블라인드(원본 無, 키/탐지기만) vs 논블라인드(원본 비교).
- 보안/운영: 키 관리(시드·버전 회전), ECC(에러정정), 모델–탐지기 버전 동기화(특히 WOUAF) 필수.
용어 정리(쉬운 정의)
- Post-hoc 워터마킹: 생성 후 결과물에 표식 부착. 삭제가 쉬움.
- Anchoring(내재화): 표식을 모델/훈련 단계에 통합해 생성과 동시에 삽입되게 하는 것.
- Encoder/Decoder(워터마킹): 삽입기/추출기 역할의 신경망. Encoder가 넣고, Decoder가 읽는다.
- Noise layer: 학습 중 공격을 흉내 내는 레이어(JPEG, 리사이즈, 크롭, 블러 등)로 강건성을 키움.
- Latent noise: 확산 모델의 생성 시작 노이즈(잠재공간의 초기 상태). 여기에 패턴을 심는 방식이 Tree-Ring.
- Inversion(역확산): 결과 이미지로부터 시작 노이즈를 추정해내는 과정(검출용).
- VAE 디코더: 잠재 표현을 RGB 이미지로 복원하는 모듈. 여기만 미세조정해도 표식을 내보내게 만들 수 있음.
- Pre-trained vs Trained(워터마크 디코더): 사전학습 후 고정한 탐지기 vs 동시에 재학습해 공적응을 유도한 탐지기.
- ECC(에러정정코드): 전송/저장 중 오류(비트 뒤집힘)를 복구하기 위한 코드(리드-솔로몬, BCH 등).
- BER(비트 오류율): 복원된 비트 중 틀린 비트 비율—워터마킹 검출의 핵심 지표.
- ROC-AUC: 임계값을 바꾸며 탐지 성능 곡선(민감도/특이도)을 통합한 값.
마지막 한 줄(핵심 저장)
“사후 삽입은 취약—따라서 확산 모델에선 (i) 잠재 노이즈 삽입(Tree-Ring), (ii) VAE-only 미세조정(Stable Signature), (iii) VAE+탐지기 공동학습(WOUAF), (iv) 데이터셋 워터마킹으로 ‘모델/훈련 단계에 내재화’하고, 혼합 공격을 가정해 BER·ROC로 강건성을 검증하라.”
'인공지능 > 공부' 카테고리의 다른 글
| 딥러닝 응용 시험 정리 - 1 CTC Loss, LoRA (1) | 2025.12.07 |
|---|---|
| 허깅페이스 2 기초 - Transformers 모듈, 모델 추가 (0) | 2025.11.12 |
| 딥러닝 응용 9- 정리2 (0) | 2025.10.13 |
| 딥러닝 응용 8- 정리1 (0) | 2025.10.12 |
| 딥러닝 응용 7 - Large Language Models (0) | 2025.10.11 |