728x90
728x90

요즘은 이제 이전 입력을 다 넣어서 다음 출력을 추정한다.
n-gram은 이제 컴퓨팅 파워가 딸릴 때...





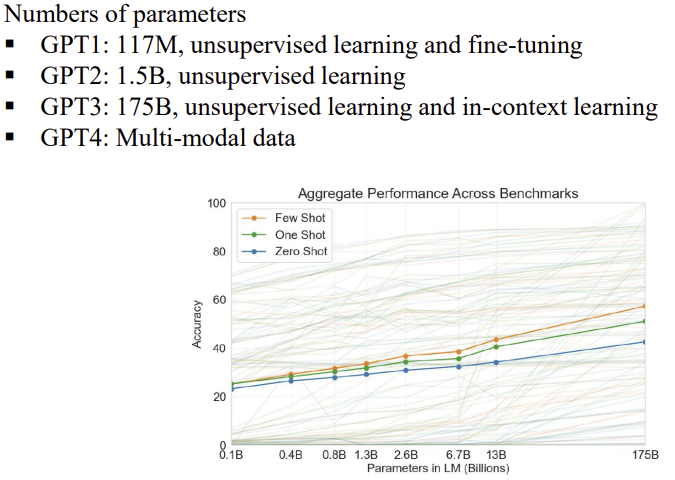
데이터, 파라미터, 정확도가 지속적으로 증가한다.
더보기
다음은 “LLM” 강의 자료 핵심 요약입니다.
한 줄 요약
언어모델의 역사(통계 → 신경망)에서 Transformer 기반 GPT 계열이 대규모 비지도 사전학습과 텍스트-to-텍스트 문제정의로 범용 능력을 얻고, GPT-1→2→3→4로 규모·능력이 확장되었다.
1) 언어모델의 흐름
- 통계적 LM (n-gram): (P(w_t|w_{t-n+1:t-1}))로 근사. 긴 의존성·가변 길이 문맥을 다루기 어렵고 데이터 희소성 문제가 큼. (슬라이드의 bigram/trigram 예시)
- 신경망 LM
- RNN/LSTM LM: “다음 단어 예측”을 최대우도((\sum_t \log P(w_t|w_{<t})))로 학습. 고정 창 제약은 줄지만 장기 의존·병렬화 한계 존재.
2) LLM: GPT 패러다임
- Generative Pre-Training
- 대규모 말뭉치로 비지도 다음토큰 예측((\mathcal{L}_1)) 사전학습. 입력을 임베딩 후 Transformer blocks를 통과해 Softmax로 확률 산출.
- Supervised Fine-Tuning
- 작업별 데이터 ((x_{1:m}, y))로 조건부 확률 (P(y|x_{1:m}))을 최대화((\mathcal{L}_2)). 필요 시 (\mathcal{L}_3=\mathcal{L}_2+\lambda\mathcal{L}_1)로 LM 성질 유지.
- GPT-2: Unsupervised Multitask
- “지시문·입력·출력”을 하나의 토큰 시퀀스로 통일(예: “answer the question”, 문서, 질문, 답). WebText(약 40 GB)로 (\sum_t \log P(w_t|w_{<t})) 학습. 프롬프트로 요약(TL;DR:), 번역(=) 등을 수행.
3) 규모 확장과 능력
- 파라미터 수: GPT-1 117M → GPT-2 1.5B → GPT-3 175B(in-context learning) → GPT-4(멀티모달). 모델·데이터·컴퓨팅 스케일업이 성능과 범용성을 견인.
4) 응용 스펙트럼
- 텍스트 생성/완성, 맞춤법·문법 교정, 질의응답, 요약, 번역 등. 생성은 확률샘플링/탑-k/확률가중 등으로 제어.
5) 연구 관점 핵심 포인트
- 문제 정형화: 다양한 작업을 “텍스트 조건 → 다음토큰 예측”으로 통일하면 단일 목적함수로 광범위한 능력이 나타난다.
- 사전학습 + 미세조정 분리: 대규모 비지도 사전학습이 언어적·세계 지식을 축적, 소량의 지도 데이터로 작업 특화 가능.
- 프롬프트 설계: 지시문/예시로 in-context 수행(특히 GPT-3 이후).
6) 빠른 점검 체크리스트
- (개념) n-gram의 한계와 RNN의 개선점, Transformer의 장점 설명 가능?
- (학습) (\mathcal{L}_1)/(\mathcal{L}_2)/(\mathcal{L}_3)의 역할과 차이 이해?
- (추론) 프롬프트만으로 요약·번역·QA를 호출하는 시퀀스 포맷을 재현 가능?
필요하면, 이 슬라이드를 바탕으로 사전학습 데이터 구성, 토크나이저 선택, 프롬프트 설계 지침, 스케일링 법칙까지 실무 노트를 추가로 정리해 드리겠습니다.
Medical References
- None
DOI: file_000000006aa861f9b41f0a1bc238ed1f
728x90
'인공지능 > 공부' 카테고리의 다른 글
| 딥러닝 응용 9- 정리2 (0) | 2025.10.13 |
|---|---|
| 딥러닝 응용 8- 정리1 (0) | 2025.10.12 |
| 딥러닝 응용 6 - Deep Generative Models (0) | 2025.10.11 |
| 딥러닝 응용 5 - Sequence to Sequence Model (0) | 2025.10.10 |
| 딥러닝 응용 4 - Architecture of DNNs (0) | 2025.10.10 |