2025.09.02 - [인공지능/논문 리뷰 or 진행] - Language Model 파라미터 감소(Pruning) 논문 4
Language Model 파라미터 감소(Pruning) 논문 4
2025.09.02 - [인공지능/논문 리뷰 or 진행] - Language Model 파라미터 감소(Pruning) 논문 3 Language Model 파라미터 감소(Pruning) 논문 32025.09.02 - [인공지능/논문 리뷰 or 진행] - Language Model 파라미터 감소(Pruning)
yoonschallenge.tistory.com
https://arxiv.org/abs/2409.14168
Towards Building Efficient Sentence BERT Models using Layer Pruning
This study examines the effectiveness of layer pruning in creating efficient Sentence BERT (SBERT) models. Our goal is to create smaller sentence embedding models that reduce complexity while maintaining strong embedding similarity. We assess BERT models l
arxiv.org
이 논문은 똑같은 곳에서 다른 방법으로 해서 낸 논문이네요 ㅎㅎ
https://arxiv.org/abs/2501.00733
On Importance of Layer Pruning for Smaller BERT Models and Low Resource Languages
This study explores the effectiveness of layer pruning for developing more efficient BERT models tailored to specific downstream tasks in low-resource languages. Our primary objective is to evaluate whether pruned BERT models can maintain high performance
arxiv.org
여기 비슷한 내용으로 또 있습니다.
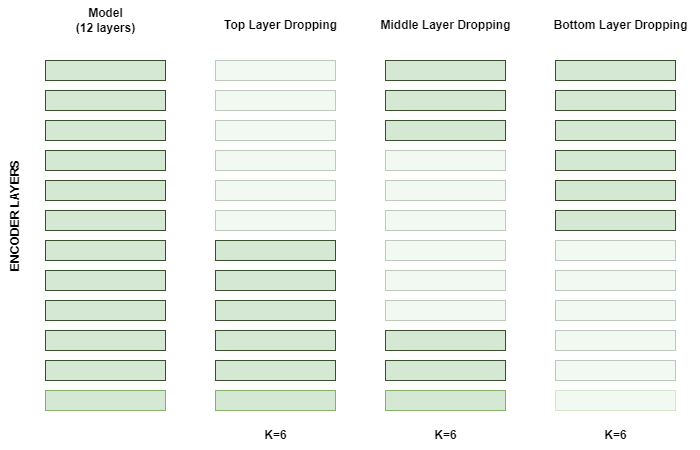

| 문제 상황 | SBERT는 문장 임베딩 품질은 우수하지만 레이어 수·파라미터가 많아 저자원 환경에서 배포가 어렵다. 본 논문 목표는 레이어 프루닝으로 모델을 작게 만들면서 임베딩 유사도 성능을 유지하는 것. |
| 방법론(요약) | (1) 레이어 프루닝으로 12층 모델을 6/2층 등으로 축소 → (2) 2단계 SBERT 파인튜닝: ① NLI(문장쌍 논리관계 분류) ② STS(문장쌍 유사도 회귀) → (3) 임베딩 유사도 평가(STSb). |
| 프루닝 전략 | 12층 기준 상단(1–6), 중단(4–9), 하단(7–12) 세 조합을 MahaBERT-v2 검증으로 비교해 상단(1–6) 유지가 최선이라 채택. 또한 Muril/MahaBERT(12L) 등에 대해 2/6/12층 조합으로 폭넓게 실험. |
| 데이터셋 | IndicXNLI(마라티): train 392,702 / val 2,490 / test 5,010 → 1단계 NLI 학습에 사용. STSb multi-mt(마라티 번역) → 2단계 STS 학습/테스트. Indic-NLP News(마라티): 3,823/479/477(학습/테스트/검증) → 분류 검증용. |
| 학습법(절차) | 프루닝 → NLI → STS 순으로 2단계 파인튜닝: ① 마라티 IndicXNLI로 NLI 학습 ② 번역된 STSb train으로 STS 학습. 이후 STSb test(마라티) 임베딩을 만들어 KNN으로 유사도 점수 산출(분류 평가는 Indic-NLP News 사용). |
| 실험 설정 | 비교 모델: Muril, MahaBERT-v2, MahaBERT-Small, MahaBERT-Smaller. 프루닝 전/후를 모두 평가. |
| 주요 결과(정량) | - 상/중/하 프루닝 비교(NLI 기준): 상단 0.7098 > 중단 0.6912 > 하단 0.6954. - 임베딩 유사도 범위(STS): 다양한 조합에서 0.72–0.83. 2층/6층도 2단계 학습 후 12층에 근접. |
| 핵심 발견 | (i) 레이어 수를 크게 줄여도(2‒6층) NLI→STS를 거치면 임베딩 품질을 상당 부분 회복/유지. (ii) 프루닝 모델이 동급 파라미터의 스크래치 소형 모델(MahaBERT-Small/Smaller)보다 일관되게 우수. |
| 기여 | 저자원 언어(마라티)에서 SBERT 레이어 프루닝+2단계 학습의 실효성을 체계적으로 검증했고, “큰 모델을 프루닝해 재학습하는 전략이 처음부터 작은 모델을 학습하는 것보다 낫다”는 실증을 제시. |
| 한계/주의 | - 지연시간/FLOPs/메모리 절감의 정량 수치 보고 부재(임베딩 점수 중심). - 평가 절차 간략: STSb에서 KNN으로 유사도 점수 산출이라고만 서술(세부 설정 미기재). - 언어·도메인 편중: 마라티 중심 실증 → 다언어(MTEB 등) 검증 필요. |
좋아, 업로드한 논문 **“Towards Building Efficient Sentence-BERT Models using Layer Pruning”**를 바탕으로, 문제 설정 → 방법론(스텝-바이-스텝) → 데이터/학습 → 실험/결과 → 기여/한계까지 한 번에 재현 가능한 형식으로 정리했어. (모든 사실은 논문 본문 인용 기반)
한 줄 핵심
SBERT를 **레이어 프루닝 + 2단계 파인튜닝(NLI→STS)**으로 경량화했을 때, 적은 레이어(2/6) 만으로도 기존 12-레이어에 준하는 문장 유사도 성능을 달성하며, 동일 규모의 스몰 모델을 처음부터 학습하는 것보다 우수하다는 것을 보였다.
핵심 표 (한 장으로 다시 떠올릴 수 있게)
구분 내용| 문제 상황 | BERT/SBERT는 파라미터가 커서 저자원 환경·지연 시간 제약에서 배치가 어려움 → 압축/경량화 필요. |
| 기본 아이디어 | 레이어 프루닝(상·중·하단 레이어 후보) 후 NLI→STS 2단계 SBERT 학습으로 임베딩 품질 유지/복원. |
| 모델 | MahaBERT-v2, Muril, MahaBERT-Small/Smaller 등 SBERT 기반 비교. |
| 프루닝 전략 비교 | 12-레이어 기준 상단(1-6), 중단(4-9), 하단(7-12) 중 상단 프루닝이 가장 우수 → 이후 실험에 채택. |
| 학습 단계 | (1) NLI: IndicXNLI(마라티) (392,702 train/2,490 val/5,010 test; 영→인도계 11개 언어 번역), (2) STS: STSb Multi-MT(마라티 번역)로 유사도 회귀. |
| 평가 | STSb(마라티)로 임베딩 유사도 산출(저자들은 KNN을 이용해 점수 계산), 분류는 Indic-NLP News Articles(마라티 3,823/479/477) 사용. |
| 대표 수치 | 레이어 조합 전반에서 유사도 0.72–0.83 범위. 상단(1-6) NLI 점수 0.7098 vs 중단 0.6912, 하단 0.6954. 2-레이어 프루닝도 6-레이어에 근접. |
| 주요 결론 | 큰 모델을 스크래치로 축소 설계·학습하기보다, 큰 모델을 프루닝 후 SBERT식 NLI→STS로 후학습하는 편이 더 효율적/성능 우수. |
| 기여 | (i) SBERT에 레이어 프루닝+2단계 파인튜닝을 체계 적용, (ii) **저자원 언어(마라티)**에서 실증, (iii) 동일 크기 스크래치 모델 대비 우수함을 보임. |
| 한계 | (i) 언어/도메인 편중(마라티 중심), (ii) 지연시간·파라미터/연산량 절감치의 정량 리포트 부재, (iii) STS 유사도 산출에 KNN 절차 설명이 간략. (평가 파트 인용 참조) |
방법론 — Step by Step (재현용)
- 프루닝 후보 레이어 선택
- 12-레이어 SBERT에서 상단/중단/하단 조합을 검토(예: 1–6, 4–9, 7–12). 검증 셋으로 비교했을 때 상단 프루닝이 최고 정확도 → 최종 채택.
- 레이어 프루닝 적용
- Muril, MahaBERT-v2, MahaBERT-Small/Smaller에 대해 2/6/12 레이어 조합을 구성해 성능/복잡도 변화를 관찰.
- 2단계 SBERT 파인튜닝
- 1단계 NLI: IndicXNLI(마라티)로 entailment/contradiction/neutral 판별 능력 학습.
- 2단계 STS: STSb Multi-MT(마라티 번역)로 문장 간 연속적 유사도 학습.
- 평가
- STSb(마라티) 테스트로 임베딩 유사도 평가(저자들은 임베딩에 KNN을 적용해 유사도 점수 산출).
- 분류 태스크는 Indic-NLP News Articles(마라티)로 성능 확인.
데이터·학습 세부
- IndicXNLI (마라티): train 392,702 / val 2,490 / test 5,010 (영→11개 인도계 언어 번역). 본 논문에서는 마라티 서브셋 사용.
- STS benchmark (stsb_multi_mt, 마라티 번역): STS 회귀 학습 및 테스트에 사용(논문 내 STSb 파트 서술이 XNLI 소개 문장과 일부 혼재되어 있어 재현 시 데이터 경로/스플릿을 명확히 잡는 것을 권장).
- Indic-NLP News Articles (마라티): 3,823(train)/479(test)/477(val), 3개 카테고리(스포츠/엔터/라이프스타일).
실험 결과(요지)
- 프루닝 전략 비교(NLI): 상단(1-6) 0.7098 > 중단 0.6912 > 하단 0.6954.
- 전체 범위: 다양한 조합에서 0.72–0.83 유사도 점수.
- 프루닝 효과: 2-레이어만 남긴 경우도 6-레이어 베이스에 근접(NLI→STS 두 단계 후).
- 핵심 비교: 동급 파라미터의 스크래치 스몰 모델보다, 대형 모델 프루닝→SBERT식 파인튜닝이 일관되게 우수.
타당성 체크
- SBERT의 문장 의미 파악 능력은 NLI(논리 관계)로 전처리하고 STS(연속 유사도)로 미세조정할 때 강화된다는 기존 관찰과 합치(본 논문도 같은 2-스테이지 설계를 채택).
- 프루닝 직후 성능 하락 가능성은 STS 단계로 복원·보정(논문 실험 수치로 뒷받침).
한계 및 개선 포인트
- 일반화 범위: 마라티 중심 실증 → **다언어/도메인(MTEB 등)**으로 확장 필요. (저자도 저자원 언어 접근성을 강조)
- 효율 지표 부재: 지연시간, FLOPs/파라미터 수, 메모리 절감량의 정량 보고가 없음(결과는 유사도 점수 중심).
- 평가 절차 간략: STS 유사도 산출에 KNN을 활용했다고만 명시 → 스코어 산출/정규화 세부가 더 필요.
- 데이터 서술 혼재: STSb 섹션 일부 문장에 XNLI 설명이 섞여 있어(편집상 오류로 보임) 재현 시 정확한 데이터셋 경로와 스플릿 확인 권장.
재현 체크리스트 (실험 적용용)
- 베이스: MahaBERT-v2(12L) 혹은 유사 구조 SBERT. 상단 1–6 레이어만 유지하는 프루닝 스크립트 적용.
- NLI(IndicXNLI-Marathi) → STS(stsb_multi_mt-Marathi) 순으로 2-단계 파인튜닝.
- STSb(마라티) 테스트로 임베딩 생성 후 유사도 계산(KNN). 필요 시 코사인 유사도/스피어만/피어슨 등도 병행.
- 분류: Indic-NLP News(마라티)로 추가 확인.
- 보고: 유사도 성능(0.72–0.83 범위 기대) + 파라미터/FLOPs/지연시간 절감치까지 함께 기재(논문 보강 포인트).
연구자 메모 (당신의 실험과 비교)
“처음/중간/끝 제거 후 FT했더니 중간이 약간 높았고 비등비등했다”는 관찰과 달리, 본 논문은 상단(1–6) 프루닝 우세를 보고. 차이는 (i) SBERT 2-스테이지 학습 유무, (ii) 데이터셋/언어, (iii) 프루닝 레이어 수·정의(예: ‘상단’의 기준), (iv) 평가지표에서 기인했을 가능성이 높아. 같은 파이프라인(NLI→STS, 동일 마라티 STSb)으로 맞춘 뒤 다시 비교하면 결론이 수렴하는지 확인할 수 있어.
원하면, 위 체크리스트를 바탕으로 당신의 Qwen/Ko 데이터셋 파이프라인에 맞춘 실험 스크립트/로그 포맷(예: MTEB-Ko, cosine/R@1/NDCG 포함)으로 바로 포팅해줄게.
좋아, 두 논문의 “핵심 차이”만 콕 집어 비교해줄게. (모든 항목은 업로드한 원문에서 따옴)
한눈에 비교 (SBERT 임베딩 vs BERT 분류)
구분 SBERT 논문 BERT 분류 논문| 목표/태스크 | SBERT를 레이어 프루닝한 뒤 문장 임베딩 품질(유사도) 유지 | (프루닝한) BERT로 마라티 뉴스 분류 정확도 유지 |
| 학습 파이프라인 | 2단계 SBERT 파인튜닝: NLI → STS 로 임베딩 복원/강화 | 각 모델을 SHC/LPC/LDC 분류 데이터로 파인튜닝 |
| 평가 지표/셋 | STSb(마라티) 임베딩 유사도; 임베딩에 KNN 적용해 점수 산출 | 정확도(Accuracy); SHC/LPC/LDC 세 가지 길이의 뉴스 분류 |
| 프루닝 탐색 | 12L 기준 Top(1–6), Middle(4–9), Bottom(7–12) 비교 후, Top이 최고라 결론 내리고 채택 | Top/Middle/Bottom 모두 실험, 6-층/10-층 제거 조합으로 폭넓게 비교 |
| 핵심 발견 | 프루닝 후 2·6 레이어 모델도 NLI→STS 거치면 12레이어에 근접(0.72–0.83) | **전반적 ‘우열 없음’**이지만 Middle 프루닝이 자주 유리, 데이터·모델 조합별로 달라짐 |
| 대표 수치 | NLI→STS 후 유사도: 예) MahaBERT-v2 6L 0.7878 / 12L 0.8320 | 테스트 정확도 예) MahaBERT-v2 Top-6: 92.18(SHC), Bottom-6: 91.05(LPC) 등 |
| 스몰 모델 대비 | 프루닝 모델이 동일 크기 스크래치 스몰 모델보다 일관되게 우수 (임베딩) | 프루닝 모델이 MahaBERT-Small/Smaller 등 스크래치 스몰 모델보다 우수 (분류) |
| 문제 설정 한줄 | “임베딩 모델을 작게 만들되 문장 유사도 성능 유지” | “분류 모델을 작게 만들되 정확도 유지” |
차이, 핵심만 5줄 요약
- 태스크가 다름: SBERT 논문은 문장 임베딩/유사도(STS), 다른 논문은 문서 분류 정확도(SHC/LPC/LDC).
- 학습법이 다름: SBERT는 NLI→STS 2단계로 임베딩을 복원, BERT 분류 논문은 분류 데이터로 직접 FT.
- 평가가 다름: SBERT는 STS 유사도(KNN 기반), BERT는 Accuracy.
- 프루닝 결론이 다름: SBERT는 Top 레이어 프루닝이 최상이라 채택, BERT 분류는 일괄 최적 없음·Middle 우세 경향.
- 숫자 지표도 다름: SBERT는 0.72–0.83 유사도 범위, BERT 분류는 SHC/LPC/LDC 각 정확도 표로 제시.
당신 실험에 적용 포인트
- 임베딩/RAG 쪽이 목적이면 SBERT 논문식으로 NLI→STS 2-스테이지 세팅에서 프루닝을 비교하세요(Top/Middle/Bottom 모두). SBERT 논문은 Top이 유리하다고 보고했으나, 이는 임베딩 과제·NLI 검증 기준에 맞춘 결론임을 명심.
- 분류 목적이면 BERT 분류 논문처럼 데이터셋 길이(헤드라인/문단/문서) 별로 6층/10층 제거 조합을 폭넓게 스윕하고 Middle를 포함한 다변량 비교가 필요. “일괄 정답 없음”이 실험적 결론.
필요하면, 당신의 **Ko 세트(MTEB-Ko, KorQuAD 계열 등)**에 맞춰 두 파이프라인(SBERT 임베딩 vs 분류) 실험 스크립트/로그 포맷을 바로 만들어줄게.
좋아. 업로드한 **“Towards Building Efficient Sentence-BERT Models using Layer Pruning”**를 그대로 따라갈 수 있게, 문제 설정 → 방법론(스텝-바이-스텝) → 데이터/학습 → 결과 → 타당성/한계까지 정리했어.
한 장 요약표
항목 핵심| 문제 | SBERT는 좋은 임베딩을 주지만 레이어 수가 많아 저자원·지연시간 제약에서 쓰기 어려움 → 레이어 프루닝으로 작게 만들되 임베딩 품질 유지가 목표. |
| 아이디어 | (1) 레이어 프루닝으로 12→6/2층 등 축소, (2) NLI→STS 2단계 SBERT 학습으로 임베딩 품질 복원/강화. |
| 프루닝 전략 | 첫 6층(1–6), 중간 6층(4–9), 마지막 6층(7–12) 비교 → **첫 6층 유지(=Top-layer pruning)**가 가장 좋았음(NLI 0.7098 vs 0.6912/0.6954). |
| 데이터 | IndicXNLI(마라티): train 392,702 / val 2,490 / test 5,010 → 1단계 NLI. STSb multi-mt(마라티 번역) → 2단계 STS. **Indic-NLP News(마라티 3,823/479/477)**로 분류도 확인. |
| 평가 | STSb(마라티) 임베딩 유사도 산출(임베딩에 KNN 적용해 스코어 계산). |
| 대표 결과 | 유사도 0.72–0.83 범위. 2층/6층도 12층에 근접. 스크래치 소형(MahaBERT-Small/Smaller)보다 프루닝+SBERT가 일관 우세. |
| 결론 | 큰 모델을 자른 뒤 NLI→STS로 재학습하는 게, 같은 크기의 소형 모델을 처음부터 학습하는 것보다 효율·성능 모두 유리. |
방법론 — Step-by-Step (재현용)
- 프루닝 후보 선정(탐색 단계)
12-층 SBERT에서 첫 6층 / 중간 6층 / 마지막 6층 조합을 만들어 NLI 검증 점수로 비교. 가장 높은 정확도는 **첫 6층 유지(Top-layer pruning)**였고, 이후 실험에서 이를 채택. - 레이어 프루닝 적용(모델 축소)
Muril, MahaBERT-v2 등 12-층 모델을 6층 / 2층 등으로 축소해 성능-복잡도 트레이드오프를 관찰(프루닝 대상/잔존 레이어만 바꾸고 SBERT 헤드는 동일하게 둠). - 2단계 SBERT 학습(임베딩 품질 복원/강화)
- 1단계 NLI: IndicXNLI(마라티)로 entail/contra/neutral 관계를 학습.
- 2단계 STS: STSb(마라티 번역)로 연속 유사도 회귀를 학습.
이 NLI→STS 조합이 SBERT 임베딩을 견고하게 만든다는 것이 본 논문 파이프라인의 핵심.
- 평가(임베딩 기반)
STSb(마라티) 테스트에서 문장 임베딩을 뽑고, KNN으로 유사도 스코어를 계산(분류 검증은 Indic-NLP News 사용).
작은 예시(개념): 12층 SBERT에서 1–6층만 남김 → NLI로 관계 판단 학습 → STS로 연속 유사도 보정. “영화가 정말 재미있었다”와 “정말 즐거운 영화였다”의 임베딩 코사인 유사도가 STS 단계 이후 더 높아지며, 6층·2층 모델도 12층에 근접한 유사도를 회복. (실험 수치 경향은 아래 결과 참고)
실험·결과(핵심 수치)
- 전략 비교(NLI): 첫 6층이 중간/마지막 6층보다 높음(0.7098 > 0.6912/0.6954).
- 유사도 범위: 다양한 조합에서 0.72–0.83. 2층/6층 모델도 NLI→STS 후 12층에 근접.
- 모델별 표(발췌): 예) MahaBERT-v2 6층: 0.7878 / 12층: 0.8320, Muril 6층: 0.7742 / 12층: 0.8165(NLI→STS).
- 소형 스크래치 대비: 프루닝+SBERT가 MahaBERT-Small/Smaller보다 일관 우세.
- 크기 절감: 프루닝 후 50–80% 더 작아져도 대형 모델에 경쟁적.
왜 타당한가? (검증 포인트)
- 레이어 드롭의 유지력: 선행연구에서 레이어 40% 제거해도 원 성능의 ~98% 유지 보고(대형 PLM) → 레이어 축소가 근본적으로 가능함. 본 논문은 이를 SBERT 임베딩에 맞게 적용/검증.
- NLI→STS 2단계의 효과: NLI로 문장 관계를, STS로 연속 유사도를 학습해 임베딩 품질을 복원·상향. 실제로 2층/6층도 STS까지 거치면 12층에 근접.
- 경쟁 실험 설계: 동일 파라미터급 스크래치 소형과 정면 비교 → 프루닝+SBERT 우위로 귀결.
한계와 주의점
- 언어·도메인 범위: 실증이 마라티 중심. 다언어/다도메인(MTEB 등) 일반화 검증이 필요.
- 효율 지표 부재: 파라미터/FLOPs/지연시간 절감치의 정량 보고가 없음(임베딩 점수 중심).
- 평가 절차의 간략성: STSb에서 KNN으로 유사도 산출이라고만 기술되어 상세 설정이 부족(거리척도/상규모/정규화 등).
- 데이터 설명 혼선: STS 섹션에 XNLI 설명이 반복되는 편집적 오류가 있어, 재현 시 데이터 경로/스플릿 명확화 필요.
실험 적용 팁(당신 워크플로우용)
- 프루닝 후보: 12층 기준 [1–6], [4–9], [7–12] 세트로 NLI 검증 → 최적 세트 선택 후 6층/2층까지 스윕.
- 학습: IndicXNLI(혹은 Ko-XNLI 대체) → **STS(ko-STS 등)**로 동일한 2-스테이지 적용.
- 리포트: 유사도(스피어만/피어슨 + R@1/NDCG), 그리고 파라미터/FLOPs/latency를 함께 보고하면 이 논문의 한계를 보완 가능.
'인공지능 > 논문 리뷰 or 진행' 카테고리의 다른 글
| An Empirical Study of Clinical Note Generation from Doctor-Patient Encounters (2) | 2025.09.11 |
|---|---|
| LLM의 중간 계층 표현 능력 논문 리뷰 - LLM middle layer representation ability (0) | 2025.09.05 |
| Language Model 파라미터 감소(Pruning) 논문 4 (0) | 2025.09.02 |
| Language Model 파라미터 감소(Pruning) 논문 3 (6) | 2025.09.02 |
| Language Model 파라미터 감소(Pruning) 논문 2 (0) | 2025.09.02 |