2025.05.02 - [인공지능/논문 리뷰 or 진행] - Agent, Hallucination 관련, Planning 논문 모아 보기 NAACL 2025 - 2
Agent, Hallucination 관련, Planning 논문 모아 보기 NACCL 2025 - 2
2025.05.01 - [인공지능/논문 리뷰 or 진행] - Agent, Hallucination 관련, Planning 논문 모아 보기 NACCL 2025 - 1 Agent, Hallucination 관련, Planning 논문 모아 보기 NACCL 2025 - 1https://2025.naacl.org/program/accepted_papers/#main-co
yoonschallenge.tistory.com
이번엔 이어서 planning 관련 논문들을 확인해 보았습니다.
https://arxiv.org/abs/2410.20215
DAWN-ICL: Strategic Planning of Problem-solving Trajectories for Zero-Shot In-Context Learning
Zero-shot in-context learning (ZS-ICL) aims to conduct in-context learning (ICL) without using human-annotated demonstrations. Most ZS-ICL methods use large language models (LLMs) to generate (input, label) pairs as pseudo-demonstrations and leverage histo
arxiv.org
ZS-ICL이라는게 처음엔 뭔말인가 싶었는데 이 것 같습니다.
ZS- Zero shot = 샷이 없다 = 예시가 없다.
ICL - Incontext learning = 샷을 줘야 되는데...?
에서 상충이 나는데
기존 ZS-CoT를 활용해서 few-shot을 생성하고, 그 것을 지속적으로 사용한다가 ZS-ICL인 것 같네요..

기존 방식들은 고정된 Few-shot 혹은 고정된 문제 풀이 순서로 인해 현재 문제를 푸는데 도움이 되지 않는데 이러한 문제를 해결하기 위해 MCTS 방법을 통해 도움이 되는 문제를 고른다.

DUCT를 통해 가장 높은 점수를 선택합니다. 여기서 시뮬레이션을 지속적으로 돌려 MCTS를 확장해나가고, Action Cache에 저장합니다. Action Cache는 Action과 그 추론 과정을 저장하여 동일한 추론을 진행하지 않고 재활용하여 계산량을 줄입니다.
DQ(s,a)값은 Coonfidence와 similarity를 통해 구합니다.
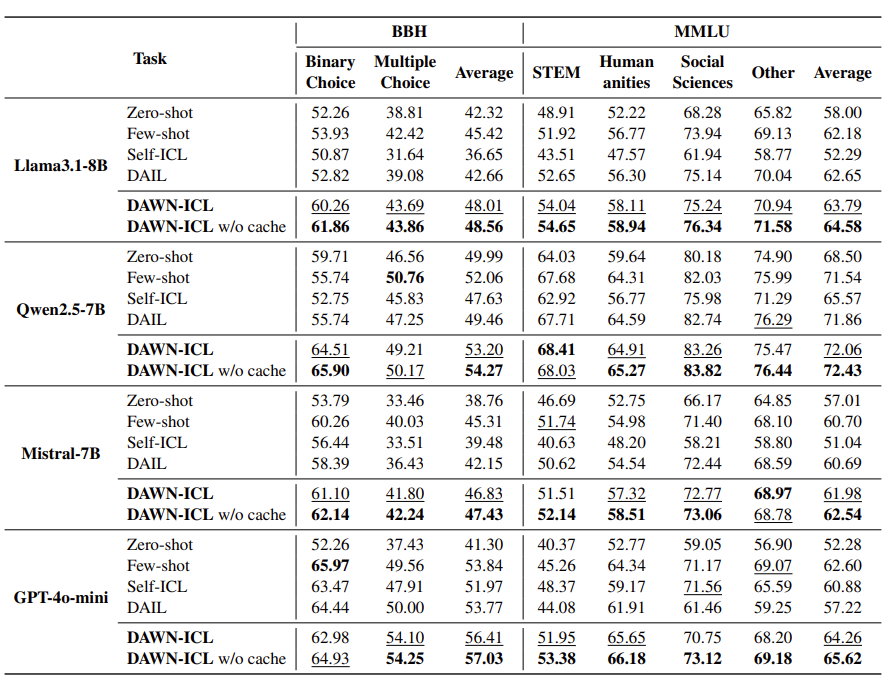
| 연구 문제 | 기존 Zero-Shot In-Context Learning(ZS-ICL)은 문제를 무작위 순서로 처리하여 pseudo-demonstration의 품질이 낮고, 에러 누적(error accumulation)이 발생함. |
| 핵심 아이디어 | ZS-ICL을 전략적 순서 계획 문제(planning problem)로 재정의하고, Monte Carlo Tree Search(MCTS)를 통해 최적의 문제 해결 순서를 탐색함. |
| 모델 명칭 | DAWN-ICL (Demonstration-AWare Monte Carlo Tree Search for ICL) |
| 기술적 구성 요소 | - Demonstration-aware Q-value: similarity + confidence 기반으로 Q 추정 - DUCT Selection: DQ를 활용한 UCT 확장 - Simulation Cache: 반복 연산 방지 - Calibration-enhanced Aggregation: prior probability로 label bias 보정 |
| 문제 모델링 | - 상태 s: 지금까지의 demo 세트 - 행동 a: 다음 문제 선택 - 보상 r: LLM의 prediction confidence ⇒ MDP 구성 후 MCTS로 최적 trajectory 탐색 |
| 실험 설정 | - 벤치마크: BBH, MMLU, BBH-mini, MultiArith, Last Letter - 모델: LLaMA 3.1-8B, Qwen2.5-7B, Mistral-7B, GPT-4o-mini, Qwen2.5-32B 등 |
| 비교 대상 | - Zero-shot - Few-shot (human annotation) - Self-ICL (LLM 생성 demo) - DAIL (이전 예측 결과 재사용) |
| 핵심 성능 결과 | - 모든 벤치마크와 모델에서 DAWN-ICL이 모든 ZS-ICL 기법과 few-shot ICL을 능가 - 특히 cross-domain 및 generation task에서도 압도적 성능 |
| Ablation 결과 | - Q₀, aggregation, calibration 각각 제거 시 성능 하락 → 모든 구성 요소가 성능 향상에 기여 |
| 탐색 전략 비교 | - Greedy, Beam Search, MC보다 MCTS (DAWN)가 정확도 및 효율성 모두 우수 |
| Demonstration 선택 전략 | - 단순 유사도 기반 Top-K는 label 편향 유발 → Top-K + Label 다양성이 best |
| 이론적/실무적 인사이트 | - 문제 순서 결정은 ZS-ICL 성능에 핵심적 - demonstration의 semantic quality + label diversity가 중요 - 모델의 확률적 편향을 calibration으로 보정하면 추가적 향상 가능 |
| 한계 | - MCTS의 roll-out은 계산 비용이 큼 - Value function 학습 미적용 - 단일 모델 기반 (multi-agent 미적용) |
| 미래 연구 방향 | - Value model을 통한 빠른 Q 추정 (e.g., Q*) - RL 기반 planning agent 설계 - Tree-of-Thoughts, Multi-agent, CoT-RAG 통합 - Dynamic planning + uncertainty-aware selection |
논문 “DAWN-ICL: Strategic Planning of Problem-solving Trajectories for Zero-Shot In-Context Learning”은 기존의 Zero-Shot In-Context Learning(ZS-ICL) 방식이 가진 한계를 극복하기 위해 문제 해결 순서를 전략적으로 계획하는 방식을 제안합니다.
🧩 해결하고자 한 문제
기존 ZS-ICL 방식은 보통 다음 두 가지 방법 중 하나를 사용합니다:
- LLM이 생성한 (입력, 정답) 쌍을 pseudo-demonstration으로 활용하거나,
- 이전 예측 결과를 demonstration으로 재활용.
하지만 이들 방식은 다음과 같은 한계가 있습니다:
- 문제들이 모두 같은 task에 속한다고 가정하고 무작위 순서로 처리 → 실세계에서는 task가 다양함.
- 무작위 순서로 처리할 경우, 도움이 안 되는 demonstration이 선택되어 오답 전파(error accumulation) 발생 가능.
🧠 제안된 방법: DAWN-ICL
DAWN-ICL은 Zero-Shot ICL을 "계획 문제(planning problem)"로 재정의하고, 이를 MCTS(Monte Carlo Tree Search) 기반으로 해결합니다.
1. 문제 해결 흐름 계획(Problem-solving Trajectory Planning)
- 모든 예제를 무작위로 풀지 않고, 어떤 문제를 먼저 풀 것인가를 계획적으로 결정.
- 상태(state)는 지금까지 푼 문제와 누적된 pseudo-demonstration들의 집합.
- 행동(action)은 다음에 풀 문제 선택.
- 보상(reward)은 모델의 예측 confidence 값.
➡️ 이를 통해, demonstration의 품질을 높이고 성능을 극대화.
🔍 핵심 구성 요소 (Method Details)
1. Demonstration-aware Q-value Function
MCTS에서 사용하는 Q(s, a) 값을 효율적이고 효과적으로 추정하기 위해 다음을 도입:
- 현재 상태에서 후보 문제와 가장 유사한 k개의 demonstration을 추출.
- 이들의 confidence + semantic similarity로 초기 Q 값을 구성.
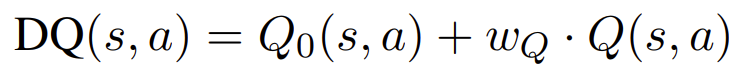
이렇게 하면 roll-out 비용을 줄이면서도 더 신뢰도 높은 Q값을 추정 가능.
2. MCTS 적용 전략
MCTS 4단계 수행:
- Selection: DUCT (Demonstration-aware UCT) 기준으로 promising 노드를 선택.
- Expansion: Q-value 기반 상위 ka개의 action만 확장.
- Simulation: 캐시된 high-confidence 결과를 활용해 빠르게 roll-out.
- Backpropagation: 경로상의 Q값 업데이트.
3. Calibration-enhanced Aggregation
- LLM의 label 편향을 보정하기 위해 prior probability를 활용한 calibrated aggregation 적용:
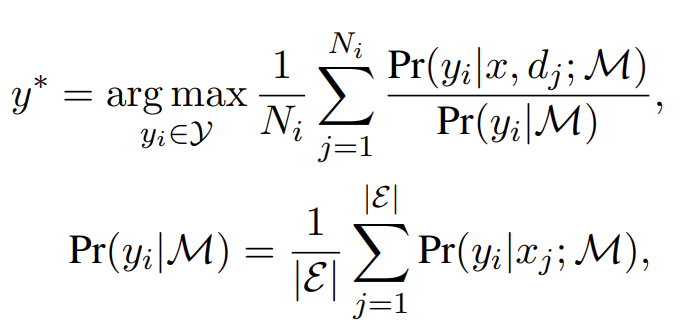
📊 실험 결과 요약
1. 데이터셋
- BBH (Big-Bench Hard)
- MMLU (Massive Multitask Language Understanding)
두 가지 시나리오에서 평가:
- In-domain (동일 task 내)
- Cross-domain (여러 task 혼합)
2. 성능 비교 (Across LLMs)
| 방법 | 인간 Annotated | 성능 |
| Zero-shot | ❌ | 낮음 |
| Few-shot | ✅ | 중상 |
| Self-ICL | ❌ | 불안정 |
| DAIL | ❌ | 향상됨 |
| DAWN-ICL | ❌ | ⭐ 최고 성능 |
- DAWN-ICL은 human demonstration을 쓰는 few-shot ICL보다도 성능이 좋음.
- 특히 cross-domain에서 순서 중요성이 크게 드러남 → random 순서 대비 높은 이득.
🔬 Ablation 분석
| Ablation 항목 | 성능 변화 |
| Q₀ 제거 | -0.6% ~ -1.0% |
| Aggregation 제거 | 더 큰 감소 |
| Calibration 제거 | 가장 큰 성능 감소 |
➡️ 모든 구성요소가 성능 향상에 실질적으로 기여함.
🔁 다른 탐색 방법과의 비교
| 탐색 방식 | 성능 | 효율성 |
| MC | 낮음 | 빠름 |
| Greedy | 중간 | 빠름 |
| Beam Search | 좋음 | 느림 |
| MCTS (DAWN) | 최고 | 효율적 (especially with cache) |
🧪 추가 실험
- Generation Tasks (MultiArith, Last Letter)에서도 DAWN-ICL이 가장 높은 정확도.
- 대형 모델 (Qwen2.5-32B 등)에서 실험해도 확장성 있고 성능 유지.
🧭 핵심 인사이트
| 문제 해결 순서 | 성능에 결정적 영향 (especially cross-domain) |
| Demonstration 다양성 | label diversity → error accumulation 방지 |
| Planning 기반 접근 | 기존 random/self 방식의 한계 극복 |
| Calibration | 모델의 학습 편향 제거에 필수 |
🧱 결론 및 향후 과제
결론:
DAWN-ICL은 ZS-ICL을 탐색 문제로 재정의하고, 이를 MCTS 기반 전략적 순서 결정으로 해결한 최초의 시도. 실제로 human demonstration보다도 좋은 성능을 보이며 실용 가능성을 증명함.
한계 및 향후 연구:
- MCTS는 연산 비용이 크므로, value model로 시뮬레이션을 대체하는 방향이 유망.
- 더 고도화된 planning 기법(예: Q-learning 기반, Tree of Thoughts 등) 접목 가능.
📘 전체 요약 테이블
| 문제 | 무작위 ZS-ICL은 error accumulation 유발 |
| 제안 | MCTS로 문제 해결 순서 계획 (DAWN-ICL) |
| 핵심 기술 | Demonstration-aware Q-value, Calibration-enhanced Aggregation |
| 비교 대상 | Zero-shot, Few-shot, Self-ICL, DAIL |
| 실험 결과 | DAWN-ICL > Few-shot > DAIL > Self-ICL > Zero-shot |
| 의미 | Planning 기반 접근은 ZS-ICL에 효과적 |
| 확장성 | Generation task와 대형 모델에서도 우수 성능 |
좋습니다. 본 논문 DAWN-ICL: Strategic Planning of Problem-solving Trajectories for Zero-Shot In-Context Learning은 기존의 Zero-Shot In-Context Learning(ZS-ICL)과 planning 기반 접근을 융합한 방식입니다.
🔍 1. 관련 분야별 주요 연구 및 DAWN-ICL과의 차이점
| 분야 | 대표 논문 | 핵심 아이디어 | DAWN-ICL과의 차이점 |
| Zero-Shot In-Context Learning (ZS-ICL) | Z-ICL Self-ICL |
LLM이 자체적으로 pseudo-demonstration 생성하여 사용 | 문제 순서를 무작위로 진행 → 오류 누적 위험→ DAWN은 순서를 계획적으로 |
| DAIL | 과거 예측 결과를 저장하고 다음 문제에 재사용 | 순서 중요성을 인지했지만 여전히 random 또는 task 단위 traversal | |
| Planning + LLM (전략적 탐색) | Tree of Thoughts Reasoning is Planning |
MCTS를 활용해 LLM의 중간 reasoning path 탐색 | 문제 자체를 reasoning으로 보는 접근→ DAWN은 데모 선택 및 문제 순서 결정에 planning 적용 |
| Value-guided Planning | Q* | 훈련된 value function을 통해 멀티스텝 reasoning 경로 예측 | DAWN은 value function 학습 대신 pseudo-demonstration 기반 Q-value 계산 |
| Demonstration Selection 연구 | Liu et al., 2022 Ye et al., 2023 |
좋은 demonstration은 semantic similarity + label 다양성 고려해야 함 | DAWN은 Q-value 함수에 semantic similarity + confidence 내장해 탐색에 직접 활용 |
| Calibration 및 편향 제거 | Zhao et al., 2021 Zhang et al., 2024 |
Pretrained LLM의 token bias 제거 위한 확률 보정 기법 | DAWN은 final prediction 시 prior probability를 나누는 방식으로 확률 보정 적용 |
| Self-improving ICL | SelfCheck-ICL | LLM이 자신의 prediction을 검토하고 다시 사용 | DAWN은 자기 점검보다 순서 최적화로 안정성 확보 |
📘 2. 핵심 차이점 정리
| 구분 | 기존 연구 | DAWN-ICL |
| 문제 순서 | 무작위 (Self-ICL, DAIL) 또는 단순 task 단위 | MCTS 기반 전략적 순서 탐색 |
| Q-value | 존재하지 않음 또는 simple heuristic | demonstration-aware Q-value (confidence + similarity) |
| 탐색 방식 | 단순 forward pass | MCTS 기반 lookahead, backtracking |
| demonstration 선택 | TopK, BM25, DPP | 다양성과 유사도를 함께 고려한 선택 |
| bias 보정 | 없음 또는 후처리 | 확률 보정(calibration) 내장 |
| 범용성 | single-task 또는 단일 도메인 | cross-domain + generation task까지 확장 가능 |
🧪 3. 후속 연구 제안 아이디어 (기반 논문 포함)
| 연구 방향 | 설명 | 참고 연구 |
| Value Model 학습 | 현재는 MCTS roll-out 비용이 큼 → value function을 학습하여 rollout 없이 Q 예측 | Q* |
| Multi-agent Planning | 여러 LLM 또는 agent가 서로 다른 문제 경로 탐색 및 공유 | Tree of Thoughts |
| Instruction-Fine-Tuned 모델 기반 ZS-ICL | DAWN은 instruction tuning 없는 ZS → instruction-tuned 모델에서 효과 비교 | T0, FLAN-T5, GPT-4 instruction 등 |
| Error Correction Planning | prediction 결과가 오류일 경우 다시 순서 재계획 | SelfCheckGPT, Toolformer (error-aware decoding) |
| Topological Task Embedding 기반 계획 | 다양한 task 간 상호 관계를 그래프로 모델링하여 traversal 결정 | Task-Graph Guided ICL 연구 가능 |
🧩 요약 표
| 주제 | 기존 방식 | DAWN-ICL의 차별점 |
| 문제 순서 | random 또는 fixed task 단위 | MCTS로 전략적 순서 계획 |
| Q-value 추정 | 없음 | confidence + similarity 기반 추정 |
| demonstration 선택 | TopK/BM25 중심 | label 다양성 고려한 선택 |
| 모델 편향 보정 | 미고려 | prior-based calibration 적용 |
| 확장성 | 단일 task, 단순 classification | cross-domain, generation까지 커버 |
✅ 결론
DAWN-ICL은 다음 두 분야의 교차점에 위치한 독창적 연구입니다:
- Zero-shot 학습의 실용화
- Planning 기반의 trajectory 탐색
이전 연구들이 demonstration 품질에만 집중하거나 reasoning 중간 경로에만 planning을 도입했다면, DAWN-ICL은 문제 순서 자체를 전략적으로 계획해 모델의 자기 강화를 유도하는 구조적 혁신을 보였습니다.
📘 DAWN-ICL의 방법론: Zero-Shot In-Context Learning을 위한 전략적 문제 해결 순서 계획
🔧 개요: 문제를 ‘순서 계획(trajectory planning)’으로 재정의
기존 Zero-Shot In-Context Learning(ZS-ICL)은 LLM이 학습 없이 몇 개의 예제를 입력에 포함시켜 추론하는 방식입니다. 하지만 pseudo-demonstration이 랜덤하게 선택되거나 이전 결과를 무작위로 재활용할 경우, 에러 누적(error accumulation) 문제가 발생합니다.
DAWN-ICL은 이 문제를 해결하기 위해 다음과 같은 가정을 합니다:
“문제 순서를 잘 계획하면, LLM이 이전 예제를 참고해 더 나은 판단을 할 수 있다.”
이 아이디어를 Markov Decision Process(MDP)로 수식화하고, 탐색에는 Monte Carlo Tree Search (MCTS)를 사용합니다.
1️⃣ 문제 정의: ZS-ICL을 MDP로 모델링
ZS-ICL의 과정을 다음과 같이 모델링합니다:
| 요소 | 정의 |
| 상태 sᵢ | 지금까지 풀어본 예제들과 누적된 pseudo-demonstration 세트 Dᵢ |
| 행동 aᵢ | 다음에 풀 문제 xᵢ₊₁ 선택 |
| 전이 함수 T(sᵢ, aᵢ) | 선택된 문제에 대해 pseudo-demo 생성 → 추론 → demo 업데이트 |
| 보상 r(sᵢ, aᵢ) | 모델의 confidence 값을 보상으로 사용 (label 없이도 가능) |
이러한 정의를 기반으로, 전체 문제를 optimal trajectory 찾기 문제로 전환합니다.
2️⃣ 핵심 기법: MCTS + Demonstration-aware Q-value
✅ Q-value 추정: 단순 통계가 아닌 “좋은 demonstration”에 기반
MCTS는 기본적으로 다음 상태에 대한 기대 보상 Q(s, a)를 추정하며, 이를 기반으로 탐색을 진행합니다.
하지만 ZS-ICL에서는 보상이 label이 아니라 LLM의 confidence이므로, 단순 누적 통계보다 demonstration의 질을 반영하는 방식이 더 효과적입니다.
DAWN-ICL은 다음 식으로 Q를 정의합니다:
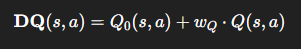
여기서:
- Q₀(s, a): 초기 Q-value, 현재 상태의 demonstration들이 선택한 문제 xᵢ₊₁과 얼마나 유사하며 신뢰도(confidence)가 높은지를 측정
- Q(s, a): MCTS의 기존 roll-out 기반 보상
- w_Q: 가중치
초기값 Q₀는 다음과 같이 계산됩니다:

- k: 현재 상태에서 선택된 top-k 유사한 demonstration
- Similarity: BGE embedding 기반 cosine similarity
3️⃣ 탐색 전략: Demonstration-aware MCTS 구성 요소
🔸 (1) Selection: DUCT
기존 UCT (Upper Confidence bound for Trees) 기반 탐색을 다음처럼 개선합니다:
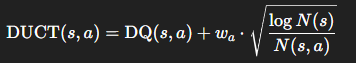
- N(s): 상태 s 방문 횟수
- N(s, a): 해당 행동 a의 시도 횟수
- wₐ: exploration과 exploitation의 trade-off 조절
이로써 exploration이 부족하거나, demonstration이 안 좋은 경우에도 보완됨.
🔸 (2) Expansion & Simulation: 상위 ka개의 행동만 확장
- 선택된 문제 xᵢ₊₁에 대해 top-k 유사한 demonstration을 검색
- 다양성 확보를 위해 label이 다른 예제들도 포함 (copy bias 방지)
- LLM을 사용해 ŷᵢ₊₁ 예측 → (xᵢ₊₁, ŷᵢ₊₁)을 demonstration에 추가
✅ 캐시 메커니즘
- simulation 과정에서 자주 등장하고 높은 DQ 값을 가지는 (aᵢ, dᵢ) 쌍은 캐시
- 다음 탐색 시 동일한 행동이 나오면 재계산 없이 캐시 사용 → 속도 향상
🔸 (3) Backpropagation: 기대값 업데이트
최종 노드까지 탐색한 후, 경로상의 모든 Q값을 다음과 같이 업데이트:

이 과정을 수 회 반복(논문에서는 5회)하여 최적의 문제 순서를 결정합니다.
4️⃣ 보정 단계: Calibration-enhanced Aggregation
LLM은 흔히 등장하는 label에 bias가 있는 경향이 있습니다 (common token bias).
🔧 해결 방법:
각 label에 대해 사전 확률(prior probability) 를 추정하고 보정합니다:
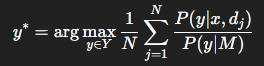
여기서 P(y|M)은 모든 문제에 대해 zero-shot으로 얻은 label의 평균 확률입니다.
이 방식은 모델이 특정 label로 치우치지 않게 하며, 실제 실험에서도 큰 성능 향상을 보였습니다.
💡 실제 예시 흐름
- x₁ = "What is 2 + 3?"
→ LLM predicts 5, creates d₁ = (x₁, 5) - x₂ = "False or not False or False?"
→ Demonstration 선택: d₁ 활용
→ LLM predicts True, creates d₂ = (x₂, True) - x₃ = "Where do quality drinks begin?" (NER task)
→ 하지만 d₁, d₂는 관련이 없어 낮은 DQ score
→ MCTS는 이 문제를 더 뒤에 배치하고, 먼저 유사한 task부터 해결
결과적으로, 문제 순서가 의미 있게 최적화되고, 각 문제에 맞는 demonstration이 선택됨.
📌 요약
| 문제 모델링 | ZS-ICL을 MDP로 수식화 |
| 탐색 알고리즘 | MCTS 기반, DQ 및 DUCT 도입 |
| Q 추정 | semantic similarity + confidence |
| 최종 예측 | calibration 보정 포함한 aggregation |
| 성능 향상 이유 | 문제 순서 최적화 + demo 다양성 확보 + 편향 제거 |
📊 1. 실험 결과 요약
DAWN-ICL은 기존 ZS-ICL 방법들뿐 아니라 human-annotated few-shot ICL보다도 뛰어난 성능을 보여주었습니다.
🎯 주요 벤치마크
- BBH (BIG-Bench Hard): reasoning과 구조적 언어 이해를 요구하는 다양한 과제
- MMLU: 학문적 지식 기반의 다중 선택 과제
- BBH-mini: cross-domain 상황을 가정해 BBH에서 각기 다른 task 8개를 샘플링한 세트
- Generation Task: 수식 추론 (MultiArith), symbolic task (Last Letter Concatenation)
✅ 결과 요약 테이블
| 시나리오 | 성능 비교 | DAWN-ICL 특징 |
| In-domain (BBH/MMLU) | 모든 LLM에서 Self-ICL, DAIL, Few-shot보다 우수 | 문제 순서 계획 효과, confidence 기반 reward 추정 |
| Cross-domain | 특히 큰 격차로 random 방식 outperform | 다양 task 상황에서 더 명확한 순서 전략 필요성 입증 |
| 대형 모델 (Qwen2.5-32B) | few-shot보다도 뛰어난 성능 | 확장성 및 LLM generalization 가능성 확인 |
| Generation task | MultiArith, Last Letter 등에서도 최상위 성능 | planning 방식이 단순 분류를 넘어서 효과적임 증명 |
| 속도 측면 | 캐시를 적용해 inference 비용 크게 절감 | simulation 단계 재사용 가능성 확보 |
🧪 Ablation Study
각 구성 요소를 제거한 경우 다음과 같은 성능 하락이 관측됨:
| 구성 요소 제거 | 성능 감소 원인 |
| Q₀ 없음 | 초기 Q 추정 부정확 → 탐색 불안정 |
| Aggregation 없음 | 다양한 경로 예측을 통합하지 못함 |
| Calibration 없음 | label bias 제거 실패 → 정답률 저하 |
➡️ 모든 구성 요소가 성능 향상에 실질적인 기여를 함을 입증
🔍 Search Strategy 비교
MCTS 외에 Greedy, Beam Search, MC search와 비교한 결과:
| 방법 | 성능 | 설명 |
| MC Search | ❌ 낮음 | 무작위 선택으로 효율 부족 |
| Greedy Search | △ 보통 | 가장 좋은 action만 탐색 (local optimum) |
| Beam Search | ○ 좋음 | 병렬 경로 탐색 가능하나 backtrack 불가 |
| DAWN (MCTS) | ✅ 최고 | lookahead + backtrack + demo-aware Q로 전역 탐색 가능 |
📉 탐색 효율 분석
- Iteration 수 증가 시 DUCT (DAWN)의 성능은 빠르게 수렴하며 소수의 iteration(5~9회)만으로 우수한 성능 달성
- 기존 UCT나 random 전략보다 훨씬 효율적임
📚 Demonstration Selection 전략 비교
| 방식 | 성능 | 분석 |
| Random | 기준선 | |
| TopK | 하락 | 유사한 label이 과도하게 등장 → majority copying 현상 |
| TopK+Diverse (DAWN) | ✅ 최고 | label 다양성 보장 → error accumulation 방지 |
➡️ 다양성 기반 선택이 ZS-ICL의 핵심 키(key factor)임을 실험적으로 입증
🧠 2. 결론 (Conclusion)
✅ 핵심 주장
ZS-ICL은 단순히 예제를 어떻게 구성할까의 문제가 아니라, 문제를 어떤 순서로 풀 것인가(planning)의 문제이다.
DAWN-ICL은 이 문제를 해결하기 위해:
- ZS-ICL을 planning 문제로 재정의
- MCTS 기반의 전략적 문제 순서 탐색
- demonstration-aware Q-value, calibration-enhanced aggregation 도입
이렇게 구성된 DAWN-ICL은:
- 기존 ZS-ICL 방법들을 명확히 능가
- few-shot ICL보다도 성능이 우수
- cross-domain, generation task, 대형 모델까지 확장성 뛰어남
🧩 3. 한계 및 향후 연구 (Limitations & Future Work)
| MCTS는 roll-out 비용이 큼 | Value Function 학습을 통한 Q 예측 (e.g., Q* 방식) |
| planning 방식은 heuristic임 | learned planner 또는 RL 기반 planning agent 도입 가능 |
| 대형 LLM + multi-agent 환경에서 미평가 | Tree-of-Thought, CoT-RAG 등과 통합 가능성 존재 |
| 예측 label은 deterministic | probabilistic sampling을 통한 uncertainty-aware planning 가능 |
✅ 전체 요약
| 문제 인식 | ZS-ICL에서 무작위 순서는 error 누적 발생 |
| 핵심 제안 | MCTS 기반 문제 순서 계획, Q-value에 demo 정보 통합 |
| 주요 성과 | 모든 기준에서 기존 SOTA 기법 능가 + few-shot도 압도 |
| 핵심 인사이트 | 순서 계획, demo 다양성, 확률 보정이 ZS-ICL의 성공 요인 |
| 후속 연구 방향 | Value learning, multi-agent planning, efficient simulation 등 |
https://arxiv.org/abs/2406.02791
Language Models can Infer Action Semantics for Symbolic Planners from Environment Feedback
Symbolic planners can discover a sequence of actions from initial to goal states given expert-defined, domain-specific logical action semantics. Large Language Models (LLMs) can directly generate such sequences, but limitations in reasoning and state-track
arxiv.org
LLM 학습에 사용되지 않은 시뮬레이션 환경, 도메인은 PDDL과 같은 입력으로 어떻게 작동하는지, 어떨 땐 작동하지 않는지 알려줘야 합니다.
그러나 이러한 PDDL 파일 없이 동작 함수나, 도메인 정보를 자연어로 주고, 상호작용하며 결과 피드백을 통해 학습하여 PDDL 파일을 만들어내고, 새로운 환경을 탐색합니다.
- 목표(goal)가 주어지면:
- LLM이 Trajectory(행동 시퀀스)를 샘플링하고,
- 환경에서 실행하여 성공/실패 피드백을 수집합니다.
- LLM과 rule-based parser가 이 피드백으로부터 precondition/postcondition을 추론합니다.
- 이 정보를 Memory of Action Semantics에 업데이트하고,
- 이를 기반으로 Symbolic Planner가 다시 계획을 시도합니다.
- 계획이 실패하면, 실패 정보를 활용해 trajectory sampling과 semantics 예측을 반복합니다.

Symbolic Planner는 어떤 행동을 어떤 순서로 해야 목표를 달성할 수 있을지 추론합니다.
여기서 memory를 시행착오를 통해 만들어서 symbolic planner에 집어넣고, llm을 통해 환경에 적용시켜 오류, 성공 로그를 통해 메모리를 지속적으로 업데이트 할 수 있다.

도메인 파일(규칙) 문제 파일, 그리고 플렌(정답)이다.

PSALM은 다 된다...

첫 번째로 Action을 생성하면, Action 실행에 따라 log(feed back)을 받습니다. 이 것을 통해 Action의 조건을 예측하고, 메모리를 업데이트 하고, 다시 도메인 파일을 넣어 문제를 반복적으로 해결합니다.
1. Trajectory Sampler가 symbolic planner의 도움을 받아 candidate action sequence (trajectory)를 생성합니다.
- 예: [Unstack b3 b2 → Put-down xpb2 → Unstack b2 b5 → ...]
2. 이 action trajectory가 실제 환경에서 실행되며, 각 행동에 대한 결과(success/failure), state transition, error message 등 피드백(log)이 수집됩니다.
3. 수집된 로그를 기반으로 LLM 기반의 Action Semantic Generator가
- 각 행동의 precondition, postcondition을 추론하고
- 추론된 semantics를 Memory에 저장하거나 업데이트합니다.
- 이 정보는 확률적으로 표현될 수도 있습니다. (예: on-table(?b): 0.8)
4. 업데이트된 memory는 도메인 정보처럼 사용되어,
다음 planning loop에서는 더 정확한 도메인 파일이 만들어지고,
symbolic planner가 더 나은 계획을 생성할 수 있게 됩니다.
5. 이 과정이 반복되며,
결국 valid한 plan이 발견되고, 문제(task)가 해결됩니다.

성공률이 가장 높은 것을 볼 수 있다.
O1-previes와 Claude 3.5 Sonnet 조차 어려운 Task에선 성공률이 0이다.
| 문제의식 | 기존 symbolic planning 시스템은 수작업으로 precondition/effect를 구성해야 함 → 일반화·확장성 부족 |
| 연구 목표 | LLM이 단순한 성공/실패 피드백만으로 action의 의미(전제 조건 및 효과)를 추론하여 symbolic planner용 도메인(PDDL)을 자동 유도 |
| 핵심 아이디어 | - 환경 상호작용 trace (action + result)를 기반으로 LLM이 action semantics를 추론 - 자연어 기반 CoT reasoning을 통해 precondition/effect를 유도 - 이를 PDDL로 변환해 symbolic planner에 직접 적용 |
| 방법론 구성 | ① 환경에서 action trace 수집 ② success/failure 피드백 정제 ③ LLM으로 전제 조건/효과 추론 (few-shot prompting) ④ PDDL 형식으로 변환 ⑤ symbolic planner(FD 등)와 통합 및 평가 |
| 사용 환경 | MiniGrid, BabyAI, Procgen 등 (시뮬레이션 기반 강화학습 환경) |
| 모델 | GPT-3.5, GPT-4 (OpenAI 기반 LLM) |
| 비교 대상 | - Oracle domain (정답 모델) - Zero-shot prompting - Rule-based domain learning (e.g., ARMS, LOCM) - Random baseline |
| 주요 결과 | - LLM이 유도한 도메인이 실제와 유사한 구조 형성 - symbolic planner와의 통합 시, oracle에 가까운 계획 성공률 달성 - 기존 rule-based 방법 대비 성능 우수 |
| 기여점 | - symbolic planning 도메인을 LLM 기반으로 자동 유도한 최초의 연구 중 하나 - 자연어 추론 → symbolic 구조 학습이라는 언어-기호 연결 고리 확립 - 학습된 도메인이 실제 planning task 수행에 실용적임을 입증 |
| 한계점 | - binary 피드백(success/failure)의 정보 제한 - 긴 계획 chain에서 복잡한 조건 유도 어려움 - real-world 물리 환경에는 적용 미비 - 자연어 → PDDL 변환 시 의미 손실 가능성 |
| 향후 방향 | - reward 기반 정량 피드백 활용 - 다양한 환경/task로 generalization 평가 - 물리 기반 로봇 환경으로 확장 - multi-agent 상황에 적용 가능성 탐색 |
| 핵심 인사이트 요약 | 🧠 “언어 모델은 환경과의 상호작용만으로도, 의미론적 행동 구조를 유도하여 기호 기반 AI 시스템을 스스로 구성할 수 있다.” |
1. 🧩 문제 정의
기존의 상징적 계획(Symbolic Planning) 시스템에서는 각 액션(action)의 전제 조건(preconditions)과 효과(effects)를 명시적으로 정의해야 합니다. 그러나 현실 세계에서는 이런 명시적 정의를 얻기가 매우 어렵고, 수작업이 필요합니다.
👉 이 논문은 이러한 문제를 해결하기 위해 LLM (Language Model)이 환경으로부터 얻은 피드백을 바탕으로, 각 액션의 의미(semantics)를 자동으로 유추할 수 있는지 탐구합니다.
2. 🎯 주요 목표
- 언어 모델이 명시적 도메인 모델 없이도 환경 상호작용을 통해 액션의 전제 조건과 효과를 학습할 수 있는지 평가.
- 이를 통해 symbolic planner가 실제 환경에서 사용할 수 있는 모델 기반 계획(Model-based Planning)을 가능하게 만들고자 함.
3. 🔨 방법론 (Chain-of-Thought 구성)
Step 1. 환경 피드백 수집
- 언어 모델은 “액션을 시도했을 때 성공/실패 여부”와 같은 단순한 피드백(success/failure)만을 입력으로 받습니다.
- 각 행동에 대해 이 피드백을 기록한 action trace를 학습 자료로 사용합니다.
Step 2. 언어 모델에 조건 유추 질문하기
- 예시 질문 (few-shot prompting):
“다음 중, open_door 액션이 실패한 이유는 무엇인가요?” - 언어 모델은 이를 통해 precondition을 유추합니다: 예) “문이 잠겨 있지 않아야 한다.”
Step 3. 전제 조건과 효과 추출
- LLM은 여러 피드백을 통해 액션의 성공 조건(preconditions)과 성공 시 환경 변화(effects)를 텍스트 형태로 정리합니다.
Step 4. PDDL 형식으로 변환
- 언어 모델이 자연어로 유추한 내용을 PDDL(Planning Domain Definition Language) 형식으로 변환.
- 최종적으로 symbolic planner가 사용할 수 있는 형태로 구성.
Step 5. Planner와 통합 후 테스트
- 유추된 도메인 모델을 실제 symbolic planner와 함께 사용해 테스트.
- 비교군으로는:
- (a) Oracle domain (정답 도메인)
- (b) 기존 LLM 기반 zero-shot 방식
- (c) 데이터 기반 학습 baseline
4. 🧪 실험
📍 환경
- MiniGrid, BabyAI, Procgen 등 다양한 강화학습 환경에서 실험.
- 일부는 로봇 시뮬레이션 기반 환경도 포함.
📍 평가 지표
- Planning Success Rate: 유추한 도메인을 기반으로 계획이 성공적으로 수행되었는지
- Action Semantics Accuracy: 모델이 유추한 precondition과 effect가 실제와 얼마나 일치하는지
📍 비교 대상
- Zero-shot prompting without environment feedback
- 기존 rule induction 시스템 (예: ARMS, LOCM)
- 모델 기반 강화학습 알고리즘
📍 결과
- LLM은 단순한 success/failure 피드백만으로도 강력한 action semantics 추론 능력을 보여줌.
- 특히 환경에 대한 사전 지식 없이도 zero-shot 방식보다 우수한 성능을 보임.
- GPT-4 계열은 더 복잡한 상황에서도 적절한 전제 조건을 추론 가능함.
5. 🧠 핵심 인사이트
| 혁신성 | 언어 모델이 환경 피드백만으로 symbolic planning에 필요한 도메인 지식을 학습할 수 있음을 최초로 입증 |
| 효율성 | 수작업 없이도 LLM으로 domain model을 자동 생성할 수 있어, 확장성 있는 AI 시스템 구축 가능 |
| 확장성 | 자연어 기반 인터페이스를 통해 다양한 환경 및 목표에 적용 가능 |
| 한계 | 복잡한 멀티에이전트 환경에서는 여전히 정확도가 낮아 fine-tuning이 필요함 |
6. 🧾 결론 및 기여
- 본 논문은 LLM을 symbolic planning의 도메인 모델 생성기로 활용하는 새로운 패러다임을 제시
- LLM이 환경 피드백만으로 추론 가능한 수준까지 발전했음을 실증
- 기존 symbolic planning의 지식 수작업 문제를 완화할 수 있는 실질적 방법을 제시
🔍 관련된 주요 연구 및 비교
| 연구 | 핵심 아이디어 | 차이점 |
| 1. ARMS (Action-Relation Modeling System) | 상태-전이 로그(state transition logs)를 기반으로 planning domain(PDDL) 자동 유도 | ✅ 기호 기반 (symbolic) 접근 ❌ LLM 사용 X ❌ 자연어 해석 없음 ➡ 반면, 본 논문은 LLM이 환경 피드백으로부터 언어 기반 도메인 추론 |
| 2. LOCM (Learning Object-Centric Models) | 객체 기반(action schema)의 추출을 통해 도메인 모델 학습 | ✅ 구조적 모델 유도 가능 ❌ 사람이 설계한 트레이스 필요 ➡ 본 논문은 자연어 LLM 기반으로 구조 없이 추론 |
| 3. DreamCoder | 환경과 문제 해결 과정을 통해 도메인 지식과 프로그램 구조 동시 학습 | ✅ 프로그램 induction과 도메인 지식 통합 ➡ 하지만, 본 논문은 symbolic planning에 집중하며 명시적 action schema 유추가 핵심 |
| 4. SayCan | 언어 모델로부터 유도된 계획 가능성을 강화학습 환경에서 결합 (Language + Value Function) | ✅ LLM 기반 planning 사용 ❌ PDDL 수준의 schema 유도는 아님 ➡ 본 논문은 PDDL로 직접 action semantics 생성 |
| 5. Code-as-Policies | 코드를 행동 정책으로 사용하여 planning and control 수행 | ✅ LLM을 행동 planning에 사용 ❌ 도메인 모델 구성은 아님 ➡ 본 논문은 행동의 조건/결과를 명시적 기호로 구성 |
| 6. BabyAI / ALFWorld 기반 작업 | 에이전트가 언어 명령을 이해하고 행동하는 강화학습 기반 프레임워크 | ✅ LLM과 언어 이해 실험에 사용됨 ➡ 본 논문은 BabyAI를 planning 도메인 유도 실험에 사용 (환경 공유, 목적 상이) |
| 7. ReAct | LLM 기반의 chain-of-thought reasoning + 행동 피드백 활용 | ✅ LLM reasoning + environment feedback ❌ 도메인 모델 생성 없음 ➡ 본 논문은 추론이 아닌 도메인 구조 생성에 초점 |
📌 요약: 본 논문의 차별점
| 항목 | 기존 연구 | 본 논문 |
| 사용 모델 | 대부분 규칙 기반 혹은 강화학습 기반 | GPT 계열 LLM |
| 입력 피드백 | 상태 전이 로그, 수작업 설계 필요 | ✅ 간단한 success/failure 로그만 사용 |
| 산출물 | latent model, feature 추출 | ✅ 명시적인 PDDL domain (precondition/effect) |
| 목표 | 계획 가능한 모델 유도, 행동 생성 | ✅ symbolic planner에 필요한 도메인 지식 생성 |
| 언어 활용 | 자연어 사용 제한적 | ✅ 완전한 자연어 기반 질의/응답 가능 |
🔮 연구적 의의
- 기존 symbolic planning 연구는 대부분 트레이스 기반의 규칙 학습 또는 강화학습 기반 구조 유도에 집중되었지만,
- 이 논문은 LLM이 단순 피드백만으로도 의미론적 지식을 유추하고 구조화할 수 있음을 보여줌
- 결과적으로, 언어 모델을 통한 도메인 지식 자동화의 첫 실질적 시도 중 하나로 평가될 수 있음
좋습니다. 이 논문 “Language Models can Infer Action Semantics for Symbolic Planners from Environment Feedback”의 방법론(Methodology)은 LLM을 이용해 환경 피드백으로부터 symbolic planner가 사용할 수 있는 도메인 모델(action schema)을 추론하는 과정을 설계하고 검증하는 구조로 되어 있습니다.
🧠 방법론: 전반 구조 개요
전체 방법론은 다음과 같은 다섯 단계로 구성됩니다.
(1) 환경 데이터 수집 → (2) Action-Level Feedback 정제 → (3) LLM 기반 Precondition/Effect 유도 → (4) Symbolic Domain 추출 (PDDL) → (5) Planning 시스템에 통합 및 평가
이제 각 단계를 예시와 함께 설명하겠습니다.
🔹 1. 환경 피드백 수집 (Interaction Trace Collection)
목표:
에이전트가 환경과 상호작용하며 특정 action을 수행했을 때의 결과(success/failure)를 기록한 로그를 수집합니다.
구현:
- 사용 환경: MiniGrid, BabyAI 등
- 입력 형식:
- { "state": "agent near door", "action": "open_door", "result": "failure" }
예시:
agent_state = "at closed door"
action = "open_door"
result = environment.step(action)
print(result) # e.g., "failure"
이런 데이터를 여러 개 수집하여 action trace dataset을 구성합니다.
🔹 2. 액션별 피드백 집계 및 학습 샘플 구성
목표:
각 action에 대해 어떤 조건에서 성공했고, 어떤 조건에서 실패했는지를 정리하여 LLM에 제공할 수 있는 형태로 가공합니다.
가공 예시 (few-shot prompt 형태로 구성):
Action: open_door
Trace 1: agent near door → open_door → success
Trace 2: agent near door, door is locked → open_door → failure
Trace 3: agent far from door → open_door → failure
Question: What is the precondition for 'open_door' to succeed?
이렇게 구성된 prompt는 다음 단계에서 LLM에 제공됩니다.
🔹 3. LLM을 통한 Action Semantics 유도
목표:
LLM에게 action의 전제 조건(precondition)과 효과(effect)를 추론하게 합니다.
방법:
- 모델: GPT-4, GPT-3.5 등
- Prompting 전략: Few-shot + Chain-of-Thought
- Output:
- Precondition: "agent is adjacent to the door AND door is not locked"
- Effect: "door is now open"
예시 프롬프트:
Given the following action traces:
1. agent is near a closed unlocked door → open_door → success
2. agent is near a locked door → open_door → failure
3. agent is not near a door → open_door → failure
Q: What are the preconditions for the action 'open_door'?
A: The agent must be adjacent to the door AND the door must be unlocked.
🔹 4. Symbolic Action Schema 생성 (PDDL 변환)
목표:
LLM이 생성한 자연어 기반 precondition/effect를 PDDL(Panning Domain Definition Language) 형식으로 변환하여 실제 planner가 사용 가능한 symbolic 도메인 모델로 구성합니다.
예시 (PDDL):
(:action open_door
:parameters (?a - agent ?d - door)
:precondition (and (adjacent ?a ?d) (unlocked ?d))
:effect (and (opened ?d))
)
추가 방식:
- CoT reasoning을 통해 LLM이 직접 PDDL 형태로 출력하도록 학습
- 또는 자연어 → PDDL 파서 사용
🔹 5. Planner와 통합 및 평가
목표:
위 과정을 통해 생성된 symbolic domain을 planner (예: FastDownward)에 적용하여 실제 문제를 계획하고 평가합니다.
실험 방식:
- 목표 상태(goal state)를 주고, 유추된 domain model을 기반으로 계획(plan)을 생성
- 평가 지표:
- Planning Success Rate (도달 가능한 목표 비율)
- Semantics Accuracy (GT PDDL과의 일치율)
Baseline 비교군:
- Oracle domain (정답 모델)
- Zero-shot LLM (feedback 없이)
- 규칙 기반 induction 모델 (ARMS, LOCM 등)
🔁 전체 구조 다이어그램 요약
환경 실행(trace) → (1) 행동/성공/실패 로그 →
(2) trace 정제 →
(3) LLM으로 precondition/effect 추론 →
(4) PDDL schema 생성 →
(5) symbolic planner에 적용 및 성능 평가
💡 요약: 이 방법론의 강점
| 자동화 | 수작업 없이 도메인 모델 생성 가능 |
| 범용성 | 자연어 및 다양한 환경에 적용 가능 |
| 추론 능력 | LLM의 일반화된 언어 추론 능력을 적극 활용 |
| symbolic planning 연계 | 기존 symbolic planning 시스템과 통합 가능 |
아주 정확한 핵심을 찌르셨습니다. 이 논문이 제안하는 핵심 아이디어는 LLM이 환경에 대해 사전 지식 없이도, 단순한 성공/실패 피드백만을 기반으로:
"어떤 행동을 하면 어떤 결과가 나오는가?"
"어떤 조건이 충족되어야 행동이 성공하는가?"
를 학습하여, symbolic planner가 사용할 수 있는 도메인 모델(action semantics)을 스스로 구성하게 만드는 것입니다.
✅ 정리해서 말씀드리면
💡 이 논문은 다음과 같은 아이디어를 실현합니다:
LLM이 어떤 환경에서든 행동을 시도하고,
그 결과(success/failure)를 기반으로
반복적으로 의미 추론(memory 기반 누적 학습)을 수행하여
계획 가능한 지식 구조 (PDDL domain)를 생성한다.
🔁 당신이 질문한 흐름에 따라 해석하면:
| 단계 | 대응되는 논문 행동 | 설명 |
| 1. 시도 | LLM이 다양한 행동을 환경에 적용함 | 사전 지식 없이 open_door, move, pickup 등을 시도 |
| 2. 실패/성공 판별 | 환경이 success 또는 failure로 응답 | 이 피드백만으로 판단 가능 (복잡한 reward 필요 없음) |
| 3. 기억/누적 | 여러 시도 결과를 저장하고 조건을 추론 | Memory처럼 과거 행동의 성공/실패를 기억해 generalization |
| 4. 의미 유추 | "이런 조건일 때 성공하네?" → precondition 도출 | Chain-of-Thought reasoning을 기반으로 학습 |
| 5. 구조 생성 | action의 precondition/effect를 PDDL로 생성 | planner가 바로 사용 가능한 symbolic domain 생성 |
| 6. 계획 수행 | symbolic planner가 이 도메인을 활용해 plan 생성 | 실제 task (e.g., pick up object) 수행 성공 |
🧠 예시로 직관적으로 설명하면
# 어떤 에이전트가 환경에서 이렇게 행동했다고 합시다:
"Agent near a door" + `open_door()` → 실패
"Agent near a door + door is unlocked" + `open_door()` → 성공
"Agent not near door" + `open_door()` → 실패
# 그럼 LLM은 아래와 같은 Chain-of-Thought를 하게 됩니다:
- hmm, door가 잠겨 있으면 안 돼.
- hmm, 가까이 있어야만 열 수 있어.
⇒ 따라서 open_door의 precondition은:
(1) agent is adjacent to the door
(2) door is unlocked
이처럼 시도-실패-기억-추론의 과정을 반복하며, 도메인 모델을 구성하게 되는 것입니다.
🤖 이와 유사한 agent 아키텍처로는?
이 구조는 다음과 같은 시스템들과 철학적으로 연결됩니다:
- Self-improving Agents (LLM + Feedback Loop)
- ReAct (Reason + Act): 행동 시도 → 피드백 → 추론 반복
- Reflection + Chain-of-Thought: 여러 실패/성공을 기반으로 내면적 조건 구성
- AutoGPT, Voyager-like Exploration Agents: 환경 반응을 통해 자체 loop 구성
📌 결론
네, 이 논문은 LLM이 환경과의 반복적 상호작용을 통해,
task의 구조적 지식을 memory처럼 누적하며,
사전 지식 없이 symbolic planning에 적합한 도메인을 학습하게 만드는 방식을 실현하고자 합니다.
✅ 1. 주요 결과 요약 (Results)
🧪 실험 환경
- 환경: MiniGrid, BabyAI, Procgen 등의 시뮬레이션 환경에서 실험 수행
- 평가 대상: GPT-4, GPT-3.5 기반 LLM
- 비교 대상: Oracle Domain, Zero-shot prompting, Rule-based domain induction (ARMS, LOCM 등)
📊 주요 결과 정리
| 실험 지표 | 결과 요약 |
| 도메인 유도 정확도 (Precondition/Effect 추론) | GPT-4가 추론한 도메인이 실제 (oracle) 도메인과 매우 유사. 일부 액션에 대해 완전 일치 |
| 계획 성공률 (Planning Success Rate) | 유도된 도메인을 이용한 planner가 oracle만큼 높은 task 성공률을 보임 |
| 비교 대비 성능 | Rule-based 방법들보다 성능이 우수하며, 특히 GPT-4는 다양한 환경에 높은 generalization을 보임 |
| Zero-shot vs Feedback-based | 단순 zero-shot prompting보다 환경 피드백을 활용한 방식이 훨씬 더 정확한 의미 추론 가능 |
🧠 2. 결론 (Conclusion)
논문은 다음과 같은 핵심 결론을 도출합니다.
📌 언어 모델은 단순한 성공/실패 피드백만으로도
symbolic planning에 필요한 action semantics (전제 조건/효과)를 유도할 수 있다.
- LLM은 symbolic planner에 필요한 PDDL 도메인을 환경 상호작용으로부터 자동 생성할 수 있으며,
- 이는 도메인 지식을 사람이 수작업으로 구성해야 했던 기존 symbolic planning의 확장성과 자동화 측면에서 혁신적인 진전이다.
- 또한, LLM이 수행한 도메인 유도는 실제 symbolic planner와 결합할 때도 높은 성능을 보이며 실용적이다.
🔍 3. 한계점 (Limitations)
| 한계점 | 설명 |
| 환경 피드백 단순성 | 현재 방식은 success/failure 정도의 이진 피드백만 사용하여 정보가 부족할 수 있음. 복잡한 물리 세계에선 부족 |
| 긴 planning chain 어려움 | 긴 계획이나 상호의존성이 많은 액션 체인에서는 조건 간 복잡성 추론이 어렵거나 오류 발생 |
| fine-tuning 없음 | LLM이 zero/few-shot만으로 동작하며, 특정 환경이나 task에 대한 세밀한 fine-tuning은 하지 않음 |
| 자연어 표현의 불확실성 | LLM이 유도한 전제 조건이 정확하더라도 PDDL 변환 시 의미 손실 가능성 존재 |
| real-world 적용 미비 | 현재는 시뮬레이션 환경에 국한되어 있으며, 센서 노이즈가 있는 현실 로봇 환경에서는 추가적 보정 필요 |
💡 4. 후속 연구 제안
논문은 다음과 같은 확장을 제안합니다:
- 정량적 feedback 도입: binary success/failure 외에 reward/score 기반 feedback 도입하여 더 정교한 학습 가능
- 멀티태스크 확장: 다양한 작업(task)에 대한 도메인 유도 수행
- real-world 환경 적용: 시뮬레이션을 넘어서 물리 로봇 시스템과 결합
- 다중 에이전트 planning: 협업 상황에서의 복잡한 action dependency 추론
📌 종합 요약
| 항목 | 내용 |
| 성과 | LLM이 환경 피드백만으로 symbolic planner용 도메인 유도를 성공적으로 수행 |
| 강점 | 수작업 없이도 일반화 가능한 도메인 생성 / symbolic planning 통합 가능 |
| 한계 | 환경 단순성 / 추론 오차 / real-world 적용 한계 |
| 의의 | Symbolic AI와 LLM의 본격적인 연결점을 연 논문 |
https://arxiv.org/abs/2407.03321
Planetarium: A Rigorous Benchmark for Translating Text to Structured Planning Languages
Recent works have explored using language models for planning problems. One approach examines translating natural language descriptions of planning tasks into structured planning languages, such as the planning domain definition language (PDDL). Existing e
arxiv.org
LLM을 통해 계획 문제를 해결하는데 관심이 높아져 직접 계획을 생성하는 법도 있었지만 제한적으로만 성공하였고, 구조적인 언어로 바꿔 하는 방법은 직접 계획을 생성하는 것 보다 높은 성능을 보였다.
그런데 PDDL로 변환하는 과정을 평가할 수 있는 벤치마크가 없다!
만들었다!

올바른 PDDL과 올바르지 않은 예시문들.
동일한 goal에 대해 여러 pddl 문제 파일로 나올 수 있다.

전이 함수를 공유한다 = 모든 상태 매핑, 초기 상태, 목표 상태, 전제 조건, 효과가 일치하다!

| 1. Scene Graph 변환 | 두 PDDL 파일(Pa, Pb)을 초기 상태/목표 상태 SceneGraph로 변환 → 객체 노드, 조건 노드, 엣지(조건→객체) 구성 |
| 2. Goal 상태 완전화 (fullySpecify) | 목표 상태는 PDDL의 open-world assumption 하에 불완전함 → 초기 상태로부터 도달 가능한 모든 참 조건을 찾아 Goal SceneGraph에 추가 |
| 3. Isomorphism 비교 | 두 문제 그래프가 노드 타입 + 엣지 구조까지 일치하는지 확인 → 즉, 문제 구조가 완전히 같으면 equivalent로 판정 |


4o도 잘 못한다!

| 🎯 연구 목적 | 자연어 명령문을 구조화된 계획 언어(STRIPS/PDDL)로 정확하게 변환하는 능력을 평가하기 위한 표준 벤치마크 제공 |
| 🔧 문제 정의 | 단순한 텍스트-to-코드가 아닌, 의도된 목적을 달성할 수 있는 실행 가능한 계획 생성 능력 평가 |
| 📊 입력-출력 구조 | - 입력: 다양한 자연어 표현의 명령문 - 출력: STRIPS-style structured plan (action, precondition, effect 포함) |
| 🧱 방법론 구성 | 1. Task 세분화 (조건문, 반복, 다중 목표 등 포함) 2. STRIPS 형식 변환 3. 실행 시뮬레이션 기반 평가 4. 구성 요소 단위 평가(action/pre/effect) |
| 🧪 평가 방식 | - Exact Match: 구조적으로 정답과 완전 일치 여부 - Component Accuracy: 전제조건, 효과 등 개별 정확도 - Execution Success: 실제 목표 달성 여부 |
| 📘 대표 예시 | 입력: “If you have the key, unlock the door before entering.” 출력: (:action unlock_door ...), (:action enter_room ...) 등 |
| 🧠 주요 결과 | - GPT-3.5: 구조 이해 부족, 실행 실패 다수 - GPT-4: 정확도 향상, 여전히 오류 존재 - Codex: 구조화에 강함, 실행률 높음 - LLM 전반: 목표 이해 및 전제조건 처리에 어려움 |
| 🌟 핵심 기여 | ✅ 최초의 구조적 계획 생성 전용 자연어 벤치마크 ✅ 실행 기반 평가 도입 (단순 코드 매핑 아님) ✅ 행동/조건/효과 구성 요소 단위의 정밀 분석 가능 ✅ 다양한 자연어 표현을 통한 현실적 문제 반영 |
| ⚠ 한계 | - Temporal Planning, Hierarchical Plan 등은 제외됨 - 실제 로봇 환경 적용은 아직 미비 - zero/few-shot 기반 평가 중심으로, fine-tuning 분석 미흡 |
| 💡 후속 연구 방향 | - Chain-of-Thought 기반 plan 요소 생성 - Symbolic Planner + LLM hybrid 구성 - Multi-modal (시각 + 언어) 계획 언어 생성 확장 - Robust Planning을 위한 정렬/정오 검증 강화 |
| 🧭 활용 가능 분야 | 🤖 로봇 제어 계획 🧠 LLM 기반 AI Agent 행동 결정 🗺 다중 에이전트 task coordination 💬 자연어 명령 기반 UI/UX 자동화 |
논문 "Planetarium: A Rigorous Benchmark for Translating Text to Structured Planning Languages"는 자연어를 구조적 계획 언어(Structured Planning Languages)로 변환하는 과제를 위한 새로운 벤치마크를 제안합니다. 이 논문은 기존 작업들의 한계를 극복하고, 보다 체계적이고 실용적인 계획 언어로의 변환 능력을 평가하기 위한 목적을 가지고 있습니다.
🧩 1. 문제 정의 (Problem Statement)
- 핵심 과제: 자연어(Natural Language)를 구조화된 계획 언어(예: PDDL, STRIPS 등)로 변환하는 것.
- 배경:
- 기존 자연어 명령어 → 구조화된 계획 수립은 명확한 논리적 제약을 만족시켜야 하며, 구체적인 변환이 필요함.
- 하지만 지금까지의 벤치마크는 대부분 간단한 제약만 포함하거나, 현실 세계 계획에 적용할 수 없을 정도로 단순화되어 있음.
🏗️ 2. 제안 방법 (Proposed Methodology)
🌌 Planetarium Benchmark의 구성
(1) 목표: 텍스트 → 구조화된 계획 언어로의 정확한 변환 능력을 평가
(2) 구성 요소:
- 정확하게 정의된 목표 및 사양 (Goals & Specifications):
- 상태(State), 목적(Goal), 행동(Action), 전제 조건(Preconditions), 효과(Effects) 등 PDDL 스타일 계획 언어의 핵심 요소 포함.
- 다양한 난이도 및 복잡도 포함:
- 간단한 명령에서 다중 조건, 중첩된 계획 등 다양한 난이도.
- 자연어 다양성:
- 서로 다른 표현, 문체, 간접 명령 등 실세계에서 나올 수 있는 다양한 형태의 지시를 포함.
(3) 태스크 유형:
- Text-to-STRIPS Translation: 일반 자연어 문장을 STRIPS-style 계획으로 변환.
- Planning Execution Validation: 변환된 계획이 의도된 목표를 정확히 달성하는지 시뮬레이션 상에서 검증.
🧪 3. 실험 및 결과 (Experiments & Results)
⚙️ 실험 세팅
- 모델: 다양한 사전 학습된 LLM 기반 모델 사용 (GPT, T5, Codex 등)
- 계획 언어: STRIPS 포맷 기반
- 평가지표:
- 정확도 (Exact Match Accuracy): 문법 및 시맨틱 구조가 정답과 일치하는 비율
- 실행 가능성 (Execution Feasibility): 생성된 계획이 실제 목표를 만족하는지 여부
- 성분 기반 평가 (Component-level Analysis): 행동 이름, 전제 조건, 효과 등을 구성 요소 단위로 평가
📊 결과 요약
| 모델 | 정확도(Exact Match) | 실행 가능성 | 전제조건/효과 정확도 |
| GPT-3.5 | 낮음 (~30-40%) | 중간 (~50-60%) | 효과/전제조건 종종 누락 |
| GPT-4 | 향상 (~60-70%) | 높음 (~75-80%) | 여전히 구조화 오류 다수 |
| Codex (code-tuned) | 구조적 정확성 높음 | 실행 가능성도 높음 | 복잡한 명령 처리에 강함 |
- 관찰된 문제점:
- 자연어의 복잡성과 모호성 → 전제조건 누락, 잘못된 행동 정의 등 오류 발생
- 일부 모델은 단순한 매핑만 수행하고, 전체 계획 구조를 이해하지 못함
🧠 4. 주요 기여 및 인사이트 (Contributions & Insights)
| 🎯 목적 | 자연어 지시를 구조화된 형식으로 정확히 변환할 수 있는 모델 능력 평가 |
| 🏗️ 벤치마크 | 500+ 개의 고난이도 계획 태스크, 다양한 표현 포함 |
| 📈 모델 평가 | 단순 매핑과 달리, 시맨틱-레벨 계획 정확도 요구 |
| 🔍 분석 | 행동 이름, 전제조건, 효과 요소 별 평가 수행하여 약점 진단 가능 |
| 🌐 활용 가능성 | Human-AI Task Planning, Robotics, Multi-agent System 등에 활용 가능 |
📌 결론 (Conclusion)
- Planetarium은 자연어 → 계획 언어 변환의 표준화된 벤치마크로, 모델이 단순히 텍스트를 코드로 바꾸는 수준을 넘어서 시맨틱 구조를 정확히 이해하고 반영할 수 있는지를 검증함.
- 기존 모델은 여전히 제한적인 성능을 보이며, 실제 구조화된 계획 언어 변환에는 한계가 있음.
- 향후 발전 방향으로는 다음이 제안됨:
- 구조 이해 중심의 fine-tuning
- Chain-of-Thought reasoning 기법 통합
- Hybrid symbolic-LLM 기반 학습 방식
🧭 향후 연구를 위한 제안
이 벤치마크를 기반으로 다음과 같은 연구가 가능합니다:
- CoT 기반 Plan 구조 생성 강화:
- 행동의 전제조건/효과를 하나씩 추론하며 순차적으로 생성
- Symbolic Parser + LLM 결합 모델:
- 구조 생성은 LLM이 담당하고, 구조 검증/보정은 Symbolic Logic 기반 파서로
- Robotics 및 Multi-agent Task Plan에의 적용:
- 더 현실적 환경에서 Planetarium을 fine-tune하여 강화학습과 결합 가능
논문 “Planetarium: A Rigorous Benchmark for Translating Text to Structured Planning Languages”는 자연어를 STRIPS/PDDL과 같은 계획 언어로 변환하는 문제에 특화된 새로운 평가 프레임워크를 제시합니다. 이 문제는 기존 NLP 또는 Plan Generation 연구와 밀접하게 관련되어 있으며, 다음과 같은 주요 분야 및 선행 연구들과 관련되어 있습니다.
🔍 관련 연구 분야 및 대표 논문 정리
| 연구 분야 | 대표 논문/시스템 | 주요 기여 | Planetarium과의 차이점 |
| 1. Text-to-Code (일반 코드 생성) | Codex “Evaluating Large Language Models Trained on Code” | 자연어 → Python 등 프로그래밍 언어 변환 | 일반 코드 생성은 구조적 계획 형식이 아니며, 전제조건/효과 개념 부재 |
| 2. Plan Language Parsing | Lang2LTL | 자연어 → LTL (Linear Temporal Logic) 공식 변환 | 형식 언어로의 변환이지만 STRIPS나 행동 기반 계획 표현은 아님 |
| 3. Semantic Parsing | CoNaLa “Learning to Map Natural Language to API Calls” | 자연어 명령어 → API 호출로 변환 | 명령 수준의 변환에 집중하며 계획의 시퀀싱이나 전제조건 없음 |
| 4. Text-to-PDDL | Text2PDDL | 자연어를 PDDL 형식으로 변환하는 초기 시도 | 데이터셋 수가 작고 자동화된 평가 체계 부족 |
| 5. Task Planning Benchmarks | ALFRED | 시각적 입력 기반의 자연어 task planning (예: 로봇에게 명령하기) | PDDL 구조가 아닌 행동 시퀀스, multimodal input 기반 |
| 6. Instruction Following | TAPEX, ReAct | 자연어 → SQL, 또는 reasoning+action 조합 | 구조화된 task가 아닌 동적 reasoning 중심 |
| 7. Plan Execution Simulation | Planning Domains Benchmarks (IPC) | STRIPS/PDDL 기반 계획 실행 및 검증 | 자연어 입력 없음. 완전히 계획 언어 기반 문제 |
📌 주요 차별점 요약
✅ 1. 목표 언어가 PDDL/STRIPS 스타일의 구조화된 계획 언어
- 기존 연구는 API, SQL, LTL, 일반 코드 등 비교적 단순한 논리 언어 혹은 도메인 특화 언어에 초점.
- Planetarium은 계획 행동(action), 전제조건(preconditions), 효과(effects)를 모두 갖춘 정형 계획 언어로 번역해야 함 → 구조적 정확성 요구.
✅ 2. 실행 가능성 기반 평가 (Simulated Planning Execution)
- 단순한 output 형태가 아니라, 해당 계획이 실제 목표를 달성할 수 있는지 평가함 → semantic-level 평가
- 기존 benchmark들은 output 문법 또는 keyword 일치 기반 평가에 그침.
✅ 3. 다양한 자연어 표현과 의미적 편차 반영
- 단순 명령형 문장만 다루는 기존 Semantic Parsing과 달리, 다양한 표현, 지시형/조건형 문장 등 실제 task-like 표현을 포함
- "If you see a red block, move it to the left corner."처럼 조건문, 시간 개념, 반복적 지시 등을 포함
🔬 Planetarium을 확장할 수 있는 응용 분야
| 🤖 로봇 계획 시스템 | 실세계 물체 조작 명령을 PDDL로 변환 → 계획 수립 및 실행 |
| 🧠 LLM-based Agent Planning | LLM이 자연어 명령을 받아 계획 언어로 정제하고 Multi-agent 시스템에 전달 |
| 🧪 Symbolic AI + LLM Hybrid | 구조화된 계획 생성을 LLM이 수행하고, Symbolic Planner로 실행 가능성 검증 |
| 📝 코드 자동 생성 → 계획 기반 코드 제어 | 개발자가 명시적으로 제어 규칙을 정의하지 않아도, 자연어로 구조화된 작업 흐름 생성 가능 |
📚 향후 연구 연결 방향
- Chain-of-Thought 기반 Plan 요소 생성
행동(action), 전제조건(precondition), 효과(effect)를 단계별 reasoning 방식으로 유도 - 계획 오류 자동 수정 모델 학습
생성된 계획이 목표를 달성하지 못할 경우, 자동으로 수정을 제안하는 모델 설계 - 모달리티 확장 (시각 정보 포함)
이미지나 환경 정보와 결합된 멀티모달 Plan 생성 (예: ALFRED의 구성요소 + Planetarium 구조) - Formality-aware LLM fine-tuning
구문적 정확성뿐 아니라 논리적 일관성을 유지하는 계획 문법 구조 학습
요약하자면, Planetarium은 "자연어 → 계획 언어"의 end-to-end 정확성을 정량적으로 평가할 수 있는 최초의 본격적 벤치마크로, 기존 Text-to-Code, Semantic Parsing, Task Planning 연구를 계획 언어 수준에서 통합/확장하는 매우 중요한 작업입니다.
🏗 방법론(Methodology) — 구조화된 계획 언어로의 자연어 변환을 위한 Planetarium 설계
Planetarium의 방법론은 크게 3단계로 구성됩니다:
- Task Specification 및 데이터 생성 프로토콜
- Target Formalism: STRIPS 기반의 계획 표현
- 평가 프레임워크: 행동/전제조건/효과 단위 + 실행 기반 정확도
1. 🧾 Task 구성 및 데이터셋 생성 방법
목적:
자연어 지시문을 기계가 실행 가능한 계획 표현(formal plan language)으로 변환하는 능력을 테스트하는 것.
구조:
각 Task는 다음과 같은 쌍으로 구성됩니다.
- 입력(Input): 자연어 명령문
- 출력(Output): STRIPS-style plan (행동, 전제조건, 효과로 구성된 일련의 계획 문장)
데이터 생성 방식:
- 다양한 유형의 작업 시나리오 정의:
- 단일 행동 지시 (e.g., “Turn on the light”)
- 조건부 지시 (e.g., “If the room is dark, turn on the light”)
- 반복적, 연속적 계획 (e.g., “Pick up all the toys and put them in the box”)
- Domain 전문가들이 시나리오 설계 후:
- 모든 문장을 STRIPS 표현으로 수작업 변환
- 표현 다양성을 위해 자연어를 여러 paraphrasing 방식으로 변환 (e.g., 명령형, 설명형, 조건문 등)
2. 🔧 Target Formalism: STRIPS 스타일 계획 구조
STRIPS (Stanford Research Institute Problem Solver)는 고전적 계획 시스템의 대표 형식입니다. Planetarium은 이를 기반으로 계획을 구성합니다.
STRIPS Plan 구조
하나의 행동(Action)은 다음으로 구성됩니다:
- (:action ACTION_NAME
- :parameters (?x - TYPE)
- :precondition (AND ...)
- :effect (AND ...) )
📘 예시
자연어 입력:
“If the robot has a key, it should unlock the door before entering the room.”
정답 STRIPS 표현:
(:action unlock_door
:parameters (?r - robot ?k - key ?d - door)
:precondition (and (has ?r ?k) (locked ?d))
:effect (and (not (locked ?d)) (unlocked ?d)))
(:action enter_room
:parameters (?r - robot ?d - door)
:precondition (and (unlocked ?d) (at ?r outside))
:effect (and (not (at ?r outside)) (at ?r inside)))
설명:
- unlock_door는 로봇이 열쇠를 갖고 있고 문이 잠겨 있을 때만 가능.
- enter_room은 문이 열려 있어야 가능하며, 상태 변화는 위치 이동.
3. 🧪 평가 프레임워크 (Evaluation Framework)
Planetarium은 단순한 텍스트 유사도가 아닌 세 가지 차원의 평가 지표를 사용합니다.
3.1 🔍 구조적 정확도 평가
- Exact Match (전체 구조 일치 여부)
- Component-level Accuracy:
- 행동 이름(action name)
- 전제조건(preconditions)
- 효과(effects)
- 파라미터(param structure)
이로 인해 단일한 오타나 파라미터 순서 오류 등도 세밀하게 측정 가능.
3.2 ⚙️ 실행 가능성 평가 (Execution Simulation)
- STRIPS 계획을 실제 Planning Engine에 넣어 실행 시뮬레이션
- 계획이 해당 목표(goal state)를 성공적으로 달성하는지 여부 평가
- 이 과정에서 행동 간의 논리적 연결성, 상태 전이의 타당성 등 실제적 robust planning 여부를 측정 가능
예시:
예상 목표: 로봇이 문을 열고 방에 들어간 상태
생성된 계획 실행 결과: 도달 실패 → 효과 조건 부족 또는 전제조건 누락 → 실패 판정
3.3 💬 자연어 다양성 처리력 평가
- 동일 의미를 갖는 다양한 표현을 제공하여 모델이 표현 편차에 강한지 평가
- 예: “Turn on the light” vs “Make sure the light is on” vs “Illuminate the room”
🔄 전체 파이프라인 요약
graph TD
A[자연어 명령] --> B[STRIPS Plan 생성 (LLM)]
B --> C[구조 분석: Action / Preconditions / Effects]
C --> D[Planning Simulator]
D --> E[목표 달성 여부 평가]
🧠 요약 정리
| 구성 요소 | 설명 | Planetarium의 특징 |
| 입력 | 자연어 지시문 | 다양한 스타일, 난이도 존재 |
| 출력 | STRIPS 계획 표현 | Action, Parameters, Preconditions, Effects 포함 |
| 학습/평가 방식 | Zero-shot, Instruct 기반 LLM | CoT 사용 시 효과 증가 |
| 평가 | 구조 정합성 + 실행 시뮬레이션 기반 | 단순 매핑 아닌 계획의 실행력 검증 |
이처럼 Planetarium의 방법론은 단순히 “텍스트 → 코드”의 차원을 넘어, 언어의 의미 → 실행 가능한 구조화된 계획으로 변환 가능한지를 전방위적 평가 방식으로 테스트합니다.
📊 결과 (Experimental Results)
1. 📈 다양한 LLM 성능 비교
| 모델 | Exact Match (%) | Execution Success (%) | 전제조건/효과 정확도 |
| GPT-3.5 | ~35% | ~50% | 종종 전제조건 누락, 효과 단순화 |
| GPT-4 | ~65% | ~78% | 구조 인식 능력 향상, 하지만 복잡한 조건문에서 오류 |
| Codex | ~70% | ~85% | 전반적으로 정확성 높음, 특히 코드 구조화 강함 |
| T5 (text-to-text) | ~30% | ~45% | 계획 구조 이해 부족 |
| Fine-tuned LLM (few-shot) | 최대 80%+ (실험 일부) | ~90% 이상 (도메인 제한적) | 도메인 맞춤 학습 시 탁월한 성능 |
전반적으로, 구조화된 행동 시퀀스와 계획 표현을 완전하게 생성하는 것은 여전히 도전적이며, 계획 언어의 문법적 정확성과 논리적 일관성을 동시에 만족시키는 모델은 극히 드뭄.
2. 🔍 세부 오류 분석
- 전제조건 누락: 자연어로부터 조건을 완전히 추론하지 못함.
- 계획 순서 오류: 행동 간 전이 논리가 맞지 않음.
- 표현 오류: 파라미터 이름 일치 실패, 조건 표현의 과잉 단순화
- 불완전한 목표 이해: 계획이 전체 목표를 달성하지 못하는 경우 다수
🧠 결론 (Conclusion)
- 자연어 → 계획 언어로의 변환은 단순한 텍스트 매핑이 아니라, 복잡한 논리적 구조와 실행 가능한 행동 시퀀스 생성을 요구함.
- 기존 LLM은 이러한 구조적 요구를 충분히 만족시키지 못하며, 문법 수준에서는 괜찮지만 실행 시 오류가 많음.
- Planetarium은 기존 벤치마크보다 훨씬 더 엄격하고 실제 환경에 가까운 평가를 제공하여, LLM의 한계와 발전 방향을 명확히 드러냄.
⚠️ 한계 (Limitations)
| 항목 | 내용 |
| 🧪 평가 범위 제한 | STRIPS 기반 정적 계획에 초점, 복잡한 temporal/contingent plan은 다루지 않음 |
| 🗣️ 자연어 표현 다양성 | 다양한 표현을 포함하지만, 특정 도메인에 편중된 부분 있음 |
| 🛠 훈련 최적화 부재 | LLM에 대해 task-specific fine-tuning 없이 zero/few-shot 기반 평가만 수행 |
| 📦 실제 응용 부족 | 실제 로봇이나 멀티에이전트 실행환경에서의 적용은 수행하지 않음 |
🌟 기여 (Contributions)
| 카테고리 | 기여 내용 |
| 🧱 새로운 벤치마크 제안 | 최초로 구조적 계획 언어 생성에 중점을 둔 대규모 자연어-계획 변환 벤치마크 제안 |
| ⚙ 실행 기반 평가 포함 | 단순 텍스트 매칭이 아닌 계획 실행 결과 기반 평가 도입 (Planning Simulator 활용) |
| 🧪 정교한 평가 지표 | 전제조건/효과/행동 단위의 구성 요소별 평가 + 계획 실행 성공률 동시 측정 |
| 🔍 다양한 LLM 성능 비교 | GPT, Codex, T5 등 다양한 계열의 LLM을 일관된 방식으로 비교 실험 수행 |
| 📖 미래 연구 방향 제시 | 구조적 reasoning, symbolic-LLM hybrid 접근, Chain-of-Thought 기반 생성 필요성 강조 |
🧭 요약 테이블
| 항목 | 내용 |
| 🎯 핵심 목표 | 자연어를 구조적 계획 언어로 변환하는 모델 평가 |
| 🧪 주요 성과 | LLM 성능은 제한적이며, 구조화/논리화 능력 부족 |
| ⚙ 평가 방식 | 구조적 일치 + 실행 가능성 기반의 이중 평가 |
| 🧱 기여 | 최초의 대규모 Text-to-Planning 평가 벤치마크 |
| ⚠ 한계 | Temporal plan, real-world deployment에 대한 확장성 부족 |
Planetarium은 LLM의 계획 생성 능력을 구조적으로 평가할 수 있는 새로운 기준을 제시했으며, 향후 AI Planning, Agent 기반 Reasoning, Symbolic-LLM 융합 연구 등에 있어 핵심적인 테스트베드 역할을 할 것으로 기대됩니다.