https://arxiv.org/abs/2503.15272
MAMM-Refine: A Recipe for Improving Faithfulness in Generation with Multi-Agent Collaboration
Multi-agent collaboration among models has shown promise in reasoning tasks but is underexplored in long-form generation tasks like summarization and question-answering. We extend multi-agent multi-model reasoning to generation, specifically to improving f
arxiv.org
일단 여기서 Agent가 장문 생성 작업에서 충분히 연구되지 않았다고 하여 Multi-Agent를 활용하여 Hallucination을 잡아나갔습니다.
이제 여기선 Multi-Agent(n 개 이상의 페르소나 or 역할 활용)와 Multi-Model(서로 다른 모델 활용)을 통해 성능을 올렸습니다.

과정은 단순합니다.
원문과 요약문을 주고, 한 문장마다 LLM이 사실인지, 거짓인지 확인합니다. - Detect
이제 이 Detect된 문장을 LLM을 통해 어디가 잘 못 되었고, 어떻게 해야 하는지 생성합니다. - Critique
마지막으로 이 원문, 요약문, Critique된 생성물을 같이 넣어 최종 출력물을 뽑아냅니다. - Refine
이 과정에서 LLM이 여러개 확용되면 이제 토론이라는 과정이 추가되어 하나의 결론이 나올 때 까지 서로 지속적으로 대화합니다.
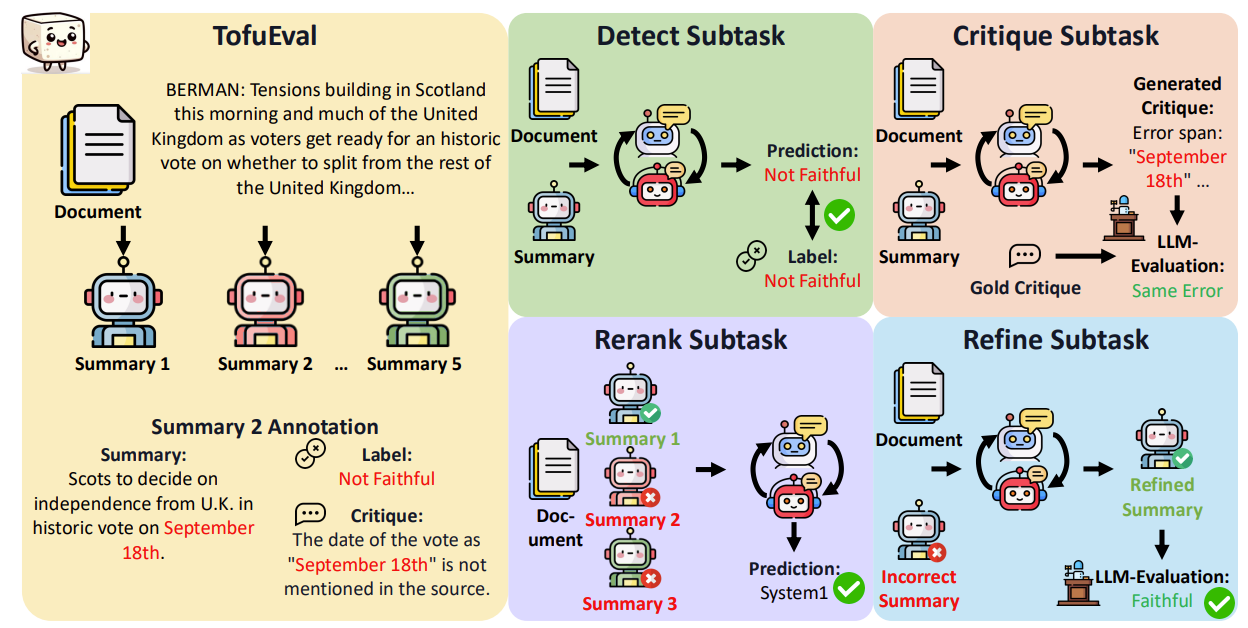
Data Set에 이게 다 있네요
TofuEval이란 데이터 셋에 생성되어 있는 Summary가 진짠지 가짠지 Label이 다 붙어있고, Critique도 얼마나 심각한 것인지, Rerank, Refine까지 잘 나오는 모습을 보입니다.
이 데이터 셋이 활용하기 편할 것 같습니다.

이 결과를 통해 Multi-Agent, Multi-Model이 가장 높은 성능을 내는 것을 볼 수 있다.
Multi-Agent만 활용한다고 했을 때 약간의 성능 향상만 있다.

MAMM-Refine 방식이 통계적으로 유의미한 개선을 보인다는 것을 알 수 있다.
| 문제의식 | LLM은 종종 입력 정보와 불일치하는 hallucination 문제를 유발하여 사실성(faithfulness)이 저하됨 |
| 기존 한계 | Self-refinement 기법은 대부분 단일 모델 기반이며, 외부 피드백 부족으로 정제 효과가 제한적 |
| 핵심 아이디어 | LLM 정제 과정에 Multi-Agent 및 Multi-Model 협업을 도입하고, 생성(generate) 대신 선택(rerank) 방식으로 안정성 향상 |
| 방법론 구조 | 🔹 3단계 파이프라인 ① DETECT: 문장별 사실성 이진 판단 ② CRITIQUE: 오류 위치 및 수정 제안 ③ REFINE: 피드백을 반영해 최소 수정 🔹 각 단계에 Multi-Agent Debate 적용 (최대 10라운드) 🔹 RERANK로 후보 중 최적 선택 (discriminative framing) |
| 사용 모델 | GPT-4o, Claude 3.5 Sonnet → 단일(MASM) vs 조합(MAMM) 비교 실험 |
| 주요 실험 | 📊 TofuEval (MediaSum, MeetingBank) 📚 UltraChat (요약), ELI5 (Long-form QA) |
| 평가 지표 | ✅ MiniCheck (Factuality) ✅ GPT-4 Likert (주관적 일관성 평가) ✅ VeriScore (QA 실험) |
| RERANK 효과 | GENERATE 대비 성능 향상 + 비용 절감 Especially when n=2 (2 candidates) → LLM이 Pairwise 판단에 강함 |
| 최적 조합 (MAMM-REFINE) | 🔹 DETECT: GPT-4o + Claude (G+C) 🔹 CRITIQUE: 2x Claude + RERANK 🔹 REFINE: 2x GPT-4o + RERANK |
| 성능 향상 | MiniCheck 기준 📌 MediaSum +2.4% 📌 MeetingBank +1.3% 📌 UltraChat +1.5% 📌 ELI5 QA +5.3% |
| 핵심 인사이트 | 🔸 Multi-Agent는 reasoning 기반 task에 특히 효과적 🔸 Multi-Model 조합은 서로 다른 오류 보완 가능 🔸 Generate보다 Rerank가 성능·비용 모두에서 우수 |
| 한계점 | ✖ Coherence, Fluency 등 비사실성 지표 미고려 ✖ 비용 이슈 (multi-agent inference) ✖ human 평가 보완 필요 |
| 발전 가능성 | 🔹 Coherence 등 멀티 기준 정제로 확장 🔹 RL 기반 agent 조합 최적화 🔹 비용 절감 위한 selective debate 전략 개발 |
| 연구 기여 | ✅ Long-form generation에도 Multi-Agent 적용 가능성 입증 ✅ Generate → Rerank framing 일반화 ✅ 다양한 LLM 협업 설계의 실용적 기반 마련 |
논문 “MAMM-Refine: A Recipe for Improving Faithfulness in Generation with Multi-Agent Collaboration”는 LLM의 사실성 향상(Faithfulness)을 위해 Multi-Agent / Multi-Model 협력 기반의 정제(Refinement) 방식을 제안하고, 체계적인 실험을 통해 이를 검증한 연구입니다. 아래는 논문 내용을 기반으로 한 체계적이고 단계적인 요약입니다.
🔍 1. 문제 정의 (Problem Definition)
LLMs는 종종 Hallucination을 유발하여 생성된 문장이 입력 정보와 사실적으로 불일치하는 문제가 있음.
→ 기존에는 단일 모델 기반의 Self-Refinement가 주로 연구되었으나, 외부 정보 부족으로 성능에 한계가 있음.
→ 이 논문은 ‘협력적 정제 과정’을 통해 사실성을 높이는 방법을 제안.
🧠 2. 핵심 기여 (Main Contributions)
- Refinement Task를 3단계로 분할:
- DETECT: 사실 오류 탐지
- CRITIQUE: 오류 원인 분석 및 비판
- REFINE: 오류를 반영하여 수정
- 각 단계에 대해 Multi-Agent와 Multi-Model 전략을 적용:
- 같은 모델 여러 개 (예: 2x GPT-4o)
- 서로 다른 모델 (예: GPT-4o + Claude 3.5)
- GENERATE vs RERANK 비교:
- 자유 생성(Generate)보다 후보 중 선택(Rerank)이 더 효과적임을 실험적으로 증명
- 종합적인 성능 향상 조합(MAMM-REFINE)을 레시피로 정리하여 Summarization 및 Long-Form QA에 적용
🧪 3. 실험 구조 (Experimental Design)
🔹 Subtask 별 실험 설계
| Subtask | 실험 목적 | 방식 |
| DETECT | 문장 단위의 사실 오류 탐지 | Binary classification |
| CRITIQUE | 오류 이유 설명 및 수정 제안 | Generative / Rerank 방식 비교 |
| REFINE | 오류를 반영하여 문장을 재작성 | Generate / Rerank 방식 비교 |
- 데이터: TofuEval (MediaSum, MeetingBank)
- 모델: GPT-4o, Claude-3.5-Sonnet
- 평가: MiniCheck, GPT-4 Likert, Veriscore
📊 4. 주요 결과 (Step-by-Step Result Analysis)
🔸 1) DETECT 결과
- Multi-Model (GPT-4o + Claude) > 단일 모델 > Multi-Agent 단일 모델
- 다양한 모델 조합이 오류 탐지에 가장 유리함
🔸 2) RERANK 결과
- Multi-Agent + Multi-Model 조합이 최고 성능
- 특히 후보가 2개일 때 가장 큰 효과 (LLMs가 pairwise 판단에 강함)
🔸 3) CRITIQUE 결과
- RERANK 방식이 GENERATE보다 확실히 우수
- 2x Claude가 가장 정확한 오류 판단 가능
- Detect 결과를 기반으로 한 CRITIQUE의 경우 GPT-4o 기반 멀티에이전트가 우수
🔸 4) REFINE 결과
- 2x GPT-4o + RERANK가 최종 성능 가장 좋음
- 좋은 CRITIQUE가 있다면, REFINE은 강한 모델 하나만으로도 우수한 성능 가능
🧩 5. 최종 조합(MAMM-REFINE Recipe)
| Subtask | 최적 모델 조합 | 방식 |
| DETECT | GPT-4o + Claude (G+C) | Binary |
| CRITIQUE | 2x Claude (2xC) | RERANK |
| REFINE | 2x GPT-4o (2xG) | RERANK |
이 구조는 MediaSum, MeetingBank, UltraChat 요약뿐 아니라, Long-form QA (e.g., ELI5)에도 효과적으로 일반화됨.
🧪 6. Long-Form QA 확장 실험
- ELI5 + WebGPT 데이터로 실험
- VeriScore 및 MiniCheck 기반 정량 평가
- 결과: faithfulness 5.3% 상승, Likert score 0.6 상승
- Multi-Model이 특히 큰 역할을 함
📌 7. 인사이트 (Insights & Takeaways)
- Multi-Agent는 단순 반복보다 서로 다른 모델 간 협업일 때 더 강력한 효과
- GENERATE는 불안정, RERANK는 안정적이며 계산 비용도 낮음
- 중간 성능 모델을 섞는 것은 성능을 떨어뜨릴 수 있음 → 유사 성능 모델끼리 협업 필요
- 더 많은 Agent 사용 시(3개): Diversity가 증가하여 추가 개선 가능
🧠 결론 (Conclusion)
- MAMM-REFINE는 사실성 향상을 위한 실질적이며 일반화 가능한 솔루션을 제시
- 다양한 모델 조합과 RERANK 전략의 중요성 부각
- 향후 coherence, relevance 등 다른 지표에 대한 refinement framework 확장 가능성 있음
이 논문은 특히 당신처럼 LLM의 신뢰성 향상 및 정제 파이프라인을 다루는 연구자에게 유의미한 기반을 제공합니다.
본 논문 “MAMM-Refine: A Recipe for Improving Faithfulness in Generation with Multi-Agent Collaboration”은 사실성(faithfulness)을 높이기 위한 세분화된 정제 파이프라인을 설계하고, 이를 Multi-Agent + Multi-Model 방식으로 구성해 성능을 개선하는 방법론을 제시합니다.
다음은 이 방법론을 구성요소별로 분해하고, 각각을 예시와 함께 전문가 관점에서 설명한 정리입니다.
🔧 전체 방법론 구조 (Overview)
논문은 LLM이 생성한 문장(Y)를 입력으로 받아, 3단계(Subtasks) 정제 절차를 수행하여 사실성이 높은 출력(Yᵣ)을 생성합니다:
[입력 문서 X] + [초기 요약 Y] → DETECT → CRITIQUE → REFINE → 정제된 요약 Yᵣ
또한, 각 단계는 Multi-Agent Debate 형식으로 구성되어, 여러 모델(또는 인스턴스)이 협력/토론을 통해 더 나은 결론에 도달하도록 설계되었습니다.
🧩 1. DETECT: 사실 오류 탐지 (Error Detection)
🎯 목적:
요약(Y)의 각 문장이 입력 문서(X)와 일치하는지 판단하는 이진 분류 작업
🧠 방법:
- 각 문장을 단위로 쪼갬: Y = {y₀, y₁, ..., yₙ}
- 각 문장에 대해 모델에게 "이 문장은 사실적인가?"를 물음
- JSON 포맷으로 { "reasoning": "...", "answer": "yes/no" } 형식의 응답을 받음
💡 Multi-Agent 방식:
- GPT-4o, Claude 3.5 등 2개 모델이 각자 판단
- 서로의 판단과 근거(reasoning)를 공유하며 최대 10라운드까지 합의에 도달
📌 예시:
입력 문서:
"The Scottish independence vote will be held soon."
요약 문장 y₁:
"Scots will vote for independence on September 18th."
DETECT 결과:
{ "reasoning": "The date 'September 18th' does not appear in the source.", "answer": "no" }
🧩 2. CRITIQUE: 오류 근거 분석 (Error Span Identification & Explanation)
🎯 목적:
오류의 원인과 수정 방향 제시
🧠 방법:
- 오류가 있는 문장에 대해 LLM에게 "왜 이 문장이 틀렸는지"를 묻고
- 문장 내 오류 span과 함께 수정 제안을 작성하도록 지시
🔄 구성:
- CRITIQUE는 DETECT 단계의 결과(불일치 문장)를 입력으로 사용
- GENERATE 방식과 RERANK 방식 비교
💡 Multi-Agent 구성:
- 각 모델이 critique를 생성하거나, 후보 중 가장 설득력 있는 critique를 선택 (RERANK)
📌 예시:
입력 문장 y₁:
"Scots will vote for independence on September 18th."
CRITIQUE 출력:
The error span: <September 18th>.
The date is not mentioned in the source. Suggested fix: remove the date.
🧩 3. REFINE: 정제된 문장 생성 (Faithful Summary Generation)
🎯 목적:
이전 단계의 피드백(Critique)을 기반으로 문장을 수정
🧠 방법:
- (X, Y, C)를 입력으로 받아 → Yᵣ (정제된 요약) 생성
- C: 각 문장에 대한 critique
- 수정은 최소한만 적용 (minimal edit principle)
🔄 구성:
- GENERATE: 모델이 새 문장을 생성
- RERANK: 여러 수정안 중 가장 적절한 것을 선택
💡 Multi-Agent 구성:
- 각 Agent가 수정안 생성 → 가장 적절한 결과를 RERANK로 선택
📌 예시:
기존 요약:
"Scots will vote for independence on September 18th."
Critique:
"The date is not in the document."
정제된 요약 Yᵣ:
"Scots will vote for independence."
🤖 Multi-Agent Debate 구조 (Core Mechanism)
모든 Subtask에 적용되는 핵심 구조는 다음과 같습니다:
| 구성 | 설명 |
| Agents | GPT-4o, Claude, Gemini 등 |
| Round | 각 라운드마다 agent들이 서로의 응답을 보고 다시 응답 |
| Stop Condition | 합의 도달 or 최대 10 라운드 |
RERANK가 선호되는 이유:
- 선택형 문제로 바꾸면 응답을 비교하기 쉬움
- 각 Agent가 답안을 생성하는 대신, 후보 중 최적 선택
🧪 방법론의 실험적 효과 (실제 적용 결과)
| Subtask | Multi-Agent 단일 모델 | Multi-Agent + Multi-Model | 최적 방식 |
| DETECT | ❌ 향상 없음 | ✅ 정확도 상승 | G+C |
| CRITIQUE | ✅ 개선 (2xClaude) | ✅ 유사한 수준 | 2xC + RERANK |
| REFINE | ❌ 제한적 | ❌ 효과 미미 | 2xG + RERANK |
📦 전체 파이프라인 예시 (MAMM-REFINE 조합)
사용된 구성:
- DETECT: GPT-4o + Claude
- CRITIQUE: 2xClaude
- REFINE: 2xGPT-4o
이 조합은:
- MediaSum, MeetingBank, UltraChat 요약에서 사실성 향상
- Long-form QA에서도 MiniCheck 기준 +5.3% 향상
🧠 전문가적 해석
이 논문은 각 Subtask의 성격에 따라 최적의 협력 전략을 분리 적용했다는 점에서 매우 의미 있습니다.
- DETECT: 정답이 명확 → Multi-Model의 시각 다양성이 이점을 줌
- CRITIQUE: 창의적 reasoning 필요 → 같은 모델의 조합이 더 정확
- REFINE: 강력한 단일 모델이 있고 critique가 적절하면 Multi-Agent 도움 제한적
또한, Generate vs Rerank 실험은 다음과 같은 현실적 시사점을 줍니다:
- OPEN-ENDED task는 Generative, CLOSED-SET은 Rerank가 더 효과적
정확한 이해를 하셨습니다! MAMM-Refine 프레임워크에서의 RERANK는 생성된 후보 중에서 “가장 사실적인 요약 또는 비판”을 선택하는 선택(classification) 문제로 바꾸는 방식입니다. 이는 LLM의 pairwise 판단 능력을 활용하며, 실제로 GENERATE보다 더 안정적이고 비용 효율적인 방식으로 밝혀졌습니다.
🔁 RERANK 방식이란?
원래의 오픈엔디드 생성(GENERATE) 문제를 폐쇄형 분류 문제로 바꿔, 여러 후보 중 가장 사실적인 것을 선택(selection)하게 만드는 방식입니다.
📐 구조적 구성
1. 입력
- 📄 문서 (X)
- 🧾 기존 요약 또는 문장 (Y)
- 🧾 여러 개의 수정안 또는 비판 후보 {C₁, C₂, ..., Cₙ}
2. 작동 방식
- 각 Agent에게 후보들을 보여주고,
- 각 Agent는 “가장 사실적인 것”을 선택
- 반복적으로 서로의 선택 이유(reasoning)를 공유하면서 합의된 결과로 수렴
3. 출력
- 선택된 1개의 후보 (e.g., 수정안, critique, 정제된 요약)
🔍 실제 예시로 보는 RERANK (CRITIQUE 단계 예시)
문장 (요약 Y의 일부)
"Scots will vote for independence on September 18th."
입력 문서
"The Scottish independence vote is approaching."
비판 후보(Critique Candidates):
| Candidate | 내용 |
| C1 | "The phrase 'September 18th' is not mentioned in the document." |
| C2 | "Scots are indeed voting; thus this sentence is accurate." |
| C3 | "This sentence contains accurate info and needs no correction." |
RERANK 과정:
- GPT-4o와 Claude가 각각 가장 적절한 critique를 선택하고 그 이유를 설명
- 서로의 reasoning을 확인한 후, 다음 라운드에서 판단을 수정
- 두 모델 모두 C1을 선택한 후 합의
→ 최종 critique로 C1이 선택됨: "The phrase 'September 18th' is not mentioned..."
💬 RERANK을 사용하는 이유
| GENERATE 방식 문제점 | RERANK 방식 장점 |
| 일관성 부족 (agent마다 결과 달라짐) | 후보 중 고르는 방식은 비교적 안정적 |
| 반복 생성 비용 큼 (모든 agent가 생성) | 후보들만 보여주고 선택하므로 계산량 ↓ |
| 평가 어려움 (무엇이 더 나은지 불명확) | 후보 간 pairwise 비교 → 더 쉬운 평가 가능 |
🧠 Multi-Agent RERANK 구조 요약 (Figure 1 참고)
[입력 문서 X] + [초기 요약 Y]
↓
여러 개 수정안 후보 생성
(e.g. Claude가 3개 생성)
↓
[Agent 1: GPT-4o] [Agent 2: Claude]
→ C1 선택 → C1 선택
↓
🗣️ RERANK debate (토론 & reasoning 공유)
↓
🏁 Consensus: C1
📊 실험 결과 요약 (Table 1 & 2 기준)
| 비교 대상 | 성능 (Acc@1 또는 EM↑) |
| MiniCheck baseline | ~70% 이하 |
| RERANK 2xClaude (2 후보) | 99.2% (거의 완벽한 선택) |
| RERANK 2xGPT-4o (2 후보) | 96.8% |
| GENERATE 2xClaude | ~67.5% (성능 하락) |
→ RERANK 방식이 모든 경우에서 GENERATE보다 낫고, 특히 후보가 2개일 때 가장 강력한 성능을 발휘함.
✍️ 정리된 개념 흐름
[문장 단위로 요약 분할]
↓
[사실 여부 DETECT]
↓
[비사실적 문장 → 여러 비판(Critique) 생성]
↓
[RERANK로 가장 적절한 비판 선택]
↓
[비판을 반영해 여러 정제 후보 생성]
↓
[RERANK로 최종 요약 선택]
🔑 연구자 관점의 핵심 Insight
- RERANK는 LLM의 분류적 능력(discriminative capacity)을 활용해 안정성과 효율성을 모두 확보
- Generative 방식보다 실행 비용 낮고, 성능 일관성도 높음
- 특히 pairwise comparison에 특화된 LLM 특성을 최대한 활용한 전략
🏆 1. 논문의 결과 (Results)
🔹 세부 실험 결과 요약
| Subtask | 최적 방법 | 주요 결과 요약 |
| DETECT | G+C (GPT-4o + Claude) | Multi-Model 조합이 단일 모델 대비 정확도 상승 (BACC +2.5% 향상) |
| CRITIQUE | 2xC (Claude 2개) + RERANK | RERANK가 GENERATE보다 오류 식별 능력 12% 향상 |
| REFINE | 2xG (GPT-4o 2개) + RERANK | Faithfulness (MiniCheck) 0.3% 추가 향상, 비용 대비 효율성 높음 |
🔹 Summarization & QA 데이터셋 결과
- MediaSum, MeetingBank, UltraChat 모두에서 기존 방법 대비 MiniCheck 점수 및 GPT Likert 평가 개선
- 특히 MeetingBank, UltraChat에서는 사실성(MiniCheck 기준) 향상이 통계적으로 유의미(p<0.05)
| Dataset 개선된 | Faithfulness 점수 |
| MediaSum | +2.4% |
| MeetingBank | +1.3% |
| UltraChat | +1.5% |
🔹 Long-Form QA (ELI5, WebGPT) 실험
- MAMM-Refine 적용 시
- MiniCheck +5.3% 상승
- Likert 점수 +0.6 상승
- 요약이 아닌 추론 중심 과제에서도 일반화 가능성 입증
🧠 2. 논문의 결론 (Conclusion)
핵심 결론:
Multi-Agent + Multi-Model 협력, 그리고 RERANK 기반 구조는 LLM 생성 결과의 사실성을 효과적으로 향상시킬 수 있다.
구체적 요약:
- Multi-Agent (같은 모델 여러 개)만으로는 일부 성능 향상에 한정적
- Multi-Model (서로 다른 모델 조합)은 서로 다른 오류 패턴을 보완해주는 강력한 효과를 보임
- RERANK 방식이 GENERATE 방식보다:
- 더 높은 안정성
- 더 낮은 계산 비용
- 더 빠른 수렴 을 가져옴
- 최적화된 조합 (MAMM-Refine):
- Summarization, Long-form QA 모두에서 성능 향상
- 특히, 오류 탐지(Detect)와 오류 분석(Critique) 단계에서 큰 이득
🎯 3. 마무리 (Final Remarks)
🔵 연구의 의의
- 생성 기반 과제에서도 Multi-Agent 협력 방식이 유효함을 실증적으로 보여줌
- 특히 오픈엔디드 생성(Open-ended generation) 과제에 폐쇄형 RERANK 변환을 통해 안정성을 확보한 첫 시도
- Summarization → Question Answering → 그 이상으로 확장 가능한 보편적 레시피(recipe)를 제공
🟠 한계와 향후 과제
- 현재는 사실성(faithfulness)만 초점
- Coherence(일관성), Relevance(적합성) 같은 다른 품질 지표까지 확장할 필요 있음
- 평가에 자동화된 점수(GPT 평가, MiniCheck 등)를 사용했지만, Human Evaluation과의 완벽한 일치는 아님
- Multi-Agent 사용으로 인해 계산 비용 증가
→ 하지만 이는 시간이 지나면서 더 최적화될 여지가 있음
🟢 기대 효과
- 안전하고 신뢰할 수 있는 LLM 개발에 필수적인 기반 기술 제공
- Fine-grained feedback 기반 refinement 연구를 넘어, 멀티-모델 협력형 AI 시스템 설계에도 영감을 줄 수 있음
📋 요약 테이블
| 항목 | 내용 |
| 핵심 목표 | LLM 생성의 사실성 향상 |
| 핵심 방법 | DETECT → CRITIQUE → REFINE의 3단계에 Multi-Agent + Multi-Model 적용, RERANK 사용 |
| 핵심 결과 | Summarization 및 Long-form QA 모두에서 Faithfulness 향상 |
| 핵심 결론 | Multi-Model + Rerank가 Generative 방식보다 더 강력하고 일반화 가능함 |
| 한계 | 아직 Coherence, Relevance까지는 다루지 않음 |
| 확장성 | 요약 외에도 다양한 생성 과제에 적용 가능 |
이제 이 논문의 결과를 기반으로
"Multi-Agent 기반 생성 결과 개선 연구" 또는
"Rerank를 통한 LLM 신뢰성 강화 연구"를 후속 과제로 확장할 수도 있을 것 같습니다.
✅ 1. 방법론의 타당성 검토
🔹 (1) 문제 정의의 명확성
- LLM의 대표적인 문제인 hallucination → faithfulness 저하 문제를 명확히 타겟으로 삼음
- 기존 단일 모델 self-refinement 기법의 한계를 정확히 짚고, 협업 기반 정제(collaborative refinement)의 필요성을 잘 논리화
🔹 (2) 3단계 정제 파이프라인 구조
| 단계 | 구성 | 타당성 |
| DETECT | 문장 단위 사실성 판단 | 이진 분류 → 명확한 평가 가능 |
| CRITIQUE | 오류 설명 및 수정 제안 | 인간과 유사한 피드백 생성 가능 |
| REFINE | 최종 문장 수정 | 평가 메트릭으로 성능 확인 가능 |
→ 각 단계가 분리되어 있어 모듈 단위 평가 가능, fine-grained 실험 설계에 적합
🔹 (3) RERANK 도입의 설계 논리
- Generative task를 discriminative task로 변환함으로써:
- 안정성 향상
- 비교 기반 선택 가능
- agent 간 합의 수렴이 명확
→ 특히 LLM이 pairwise 비교에 강하다는 기존 연구(Huang et al., 2024b)와 일치하는 설계
🔹 (4) Multi-Agent + Multi-Model 적용
- 단순히 agent를 늘리는 것이 아니라, 다양한 모델 (GPT-4o, Claude)을 조합
- hallucination 유형이 서로 다른 모델을 함께 사용할 때 오류 상호보완 효과 기대
🔹 (5) 프롬프트 설계
- 각 subtask마다 명확한 구조의 prompt를 사용 (JSON 형태, 오류 span 명시 등)
- 실제 서비스에 적용 가능한 수준의 제어 가능한 정제 과정 설계
🧪 2. 실험 설계와 검증의 타당성
🔸 데이터셋
- TofuEval: 문장 단위로 human-annotated fact label + critique 포함 → 적합한 벤치마크
- MediaSum, MeetingBank, UltraChat, ELI5(WebGPT) 등으로 실험 확장
→ 요약 + QA task 모두에서 일반화 가능성 입증
🔸 평가 지표
- MiniCheck: 최신 fact consistency 평가 모델
- GPT-4 Likert score: 자연언어 기반 평가, 사람 평가와 높은 상관성 확보
- VeriScore (QA에서 사용): 문장 수준 fact 확인 평가
→ 자동 + GPT 기반 + 사람 기반 평가 지표를 적절히 혼합하여 신뢰성 확보
🔸 실험 구성
- 각 subtask별로:
- Single Agent / Multi-Agent / Multi-Model 비교
- Generate vs Rerank 비교
- 전체 시스템으로는 여러 파이프라인 조합 비교 (e.g., DETECT-REFINE vs DETECT-CRITIQUE-REFINE)
→ 실험 설계가 계층적이고 정교하게 짜여 있음, 논문 주장의 정당성 확보에 기여
⚠️ 3. 논문의 한계점 (Limitations)
| 구분 | 내용 |
| 1. 평가 지표 편중 | Faithfulness에 집중. Coherence, fluency, coverage 등은 미고려 |
| 2. 인간 평가 보조적 | 사람 평가(Likert)는 소규모에 한정. 대부분 자동지표에 의존 |
| 3. 모델 조합 제한 | GPT-4o와 Claude에 집중됨. 다양한 중소형 모델 포함 실험 부족 |
| 4. 비용 문제 | Multi-Agent 구성이 계산 비용 증가 (10라운드 debate + 여러 모델) |
| 5. 실시간 사용 한계 | 현재 구조는 실시간 서비스에 쓰기에는 복잡. 응답 시간 우려 |
🚀 4. 발전 가능성 (Future Directions)
| 방향 | 구체 제안 |
| 1. 다중 지표 통합 평가 | 사실성 외에도 일관성(coherence), 정보성(informativeness)까지 통합한 multi-metric 평가 체계 구축 |
| 2. 적응형 Agent 조합 학습 | task 또는 예측 난이도에 따라 적절한 agent 조합을 선택하는 meta-controller 설계 |
| 3. 비용 최적화된 Debate 전략 | 불일치 케이스에서만 debate를 수행하고 나머지는 skip하는 adaptive RERANK 방식 도입 |
| 4. 미드사이즈 모델 활용 | Mistral-7B, LLaMA-3-8B 등 효율적인 모델로 agent 구성해 비용-성능 균형 맞추기 |
| 5. RL 기반 최적 조합 학습 | 각 단계의 agent 조합을 강화학습 기반으로 최적화 (AutoMAMM 등 가능) |
🌟 5. 논문의 기여 (Key Contributions)
| 항목 | 기여 내용 |
| 🧱 정제 프로세스 분할 구조화 | Detect → Critique → Refine 세분화된 구조로 각 구성의 효과를 실험적으로 검증 |
| 🧠 Multi-Agent Debate 적용 확장 | 기존 reasoning task 위주에서 → long-form generation task로 성공적 확장 |
| 🧩 RERANK 전략의 일반화 가능성 | critique, refine 모두에 discriminative 방식 적용 → 성능, 효율성 동시 확보 |
| 🔬 다양한 데이터셋/도메인 적용성 | 요약(Summarization), 질의응답(QA) 모두에서 적용 가능 → 범용 정제 프레임워크 |
| 📈 성능 개선 실증 | MiniCheck 기준 최대 +5.3%, GPT Likert 기준 +0.6 이상 개선 → 통계적으로 유의미한 향상 확보 |
🧠 총평
MAMM-Refine 논문은 LLM의 hallucination 문제를 실제적이고 구조적으로 해결하려는 정제 파이프라인을
Multi-Agent + Multi-Model + RERANK 구조로 성공적으로 확장한 실용적 연구 사례입니다.
모듈화된 구성, 구조적 실험 설계, 다양한 적용 실험을 통해 정제 시스템 설계의 새로운 기준점을 제시했다고 볼 수 있습니다.
📚 1. 사용한 데이터셋 (Evaluation Datasets)
| 데이터셋 |
유형 | 목적 | 특징 |
| TofuEval | Intrinsic 요약 평가용 | DETECT / CRITIQUE / RERANK 등 세부 태스크 평가 | 문장 단위 human label 및 critique 포함 |
| MediaSum | 요약 (뉴스/인터뷰) | Summarization 태스크 전반적인 faithfulness 평가 | 비교적 짧은 뉴스 대화 기반 |
| MeetingBank | 요약 (회의) | 보다 긴 회의 문서 기반 정제 실험 | 복잡한 맥락 이해와 fact alignment 필요 |
| UltraChat | 요약 (대화 기반 대형 모델 응답) |
Out-of-domain generalization 평가 | Multi-turn Chat 형식 요약, 원문 다양성 높음 |
| ELI5 (WebGPT) | Long-form QA | Summarization 외 task에서의 generalization 검증 | 질의응답 형식, supporting document 포함 |
🔍 2. 각 데이터셋의 활용 방식
📌 A. TofuEval
- 핵심 사용처: Intrinsic Evaluation (DETECT / CRITIQUE / RERANK)
- 구성: 150개의 document-topic pair (50 docs × 3 topic)
- 각 document에 대해 5개의 summary system outputs
- 문장 단위로 human label (faithful / unfaithful), 오류 설명 포함
- 사용 방식:
- 각 문장을 input으로 넣고, DETECT에서 예측 정확도 평가
- unfaithful 문장에 대해 CRITIQUE 생성 → human critique와 비교
- 다양한 system summary들을 모아 RERANK task 구성
📌 B. MediaSum & MeetingBank
- 사용처: Extrinsic Evaluation
- 목적: 정제된 요약이 실제 문서와 얼마나 일치하는지 평가
- MediaSum: 짧은 뉴스 인터뷰 기반 요약
- MeetingBank: 회의록 기반, 긴 컨텍스트 → 더 어려운 평가 대상
📌 C. UltraChat
- 사용처: Generalization 평가
- 목적: Summarization 모델이 다양한 문장 유형에도 정제 효과 있는지 확인
- 대화 기반 응답 요약 → hallucination 발생 가능성 높은 도메인
📌 D. ELI5 (WebGPT) – Long-form QA
- 사용처: 세대(generation) 전이 능력 평가
- 구조: 질문 + 문서 + 정답 형식
- 방법: WebGPT에서 수집된 evidence 기반 long-form 응답을 정제
- 정제 전후의 사실성 변화 측정
🧪 3. 평가 방식 (Evaluation Methodology)
① DETECT 평가
- 문장 단위로 “이 문장은 사실인가?” → 이진 분류
- 정답 라벨은 TofuEval의 human annotation 사용
- 지표: Balanced Accuracy (BACC)
- 이유: class imbalance (unfaithful 문장이 적음) 고려
② CRITIQUE 평가
- unfaithful 문장에 대해 생성된 critique가 human critique와 일치하는가?
- GPT-4o에게 세 가지 중 선택하게 함:
- ✅ Error Match: 정확한 오류 지적
- ❌ Error, No Match: 다른 오류 지적
- ❌ No Error: 오류를 놓침
- 지표:
- EM (Error Match) ↑: 성능 지표
- EMM (Error Mismatch) ↓: 부정확 critique
- NE (No Error Detected) ↓: 오류를 놓친 비율
③ RERANK 평가
- 여러 개의 요약 후보 중, 가장 사실적인 것을 선택할 수 있는가?
- Ground-truth로 faithful summary 1개, unfaithful 2~4개로 구성
- 순서를 섞어 제시
- 지표: Acc@1 — 올바른 요약을 1순위로 뽑은 비율
④ REFINE 평가
- 전체 요약(Yr)이 얼마나 더 사실적인가?
- 지표:
- MiniCheck: 문장 단위 factual consistency (SOTA 평가 모델)
- GPT-4 Likert Score (1~5점 척도): GPT-4 기반 사람 평가 대체
⑤ Long-form QA (ELI5) 평가
- 정제된 QA 응답이 얼마나 사실에 기반했는지 측정
- 지표:
- MiniCheck
- VeriScore: 생성된 응답이 문서 기반인지 평가하는 QA 정합성 지표
- GPT-4 Likert
📌 총괄 요약 테이블
| 평가 항목 | 데이터셋 | 평가 목적 | 주요 지표 |
| DETECT | TofuEval | 문장 단위 사실성 판단 | Balanced Accuracy (BACC) |
| CRITIQUE | TofuEval | 오류 분석 및 수정 근거 | Error Match / Mismatch / No Error |
| RERANK | TofuEval | 여러 요약 중 best 선택 | Accuracy@1 |
| REFINE | MediaSum, MeetingBank, UltraChat | 정제된 전체 요약 평가 | MiniCheck, GPT Likert |
| QA 확장 | ELI5 (WebGPT) | 정제된 QA 응답의 사실성 | VeriScore, MiniCheck, GPT Likert |
이처럼 MAMM-Refine은 세부 단계별로 정제된 실험 설계를 갖추고, Human-labeled 데이터셋과 자동 평가 지표를 복합적으로 활용하여 신뢰성 있는 검증 프레임워크를 제시했습니다.