https://arxiv.org/abs/2412.00447
ATP-LLaVA: Adaptive Token Pruning for Large Vision Language Models
Large Vision Language Models (LVLMs) have achieved significant success across multi-modal tasks. However, the computational cost of processing long visual tokens can be prohibitively expensive on resource-limited devices. Previous methods have identified r
arxiv.org
Pruning은 모델에 쓸모 없는 파라미터를 버리기 위해 하는 줄 알았는데 여기선 이미지 토큰을 버리는 것 같네요..
이전 방법들은 Vision token들의 중복성을 파악하고, 미리 정의한 고정된 비율로 토큰을 제거하여 계산 오버헤드를 줄여 이를 완화했다.
그러나 이렇게 고정된 비율은 악영향을 주기에 동적으로 제거하는 전략이 필요하다
-> ATP-LLaVA
중복성과 모델링 관점 모두 고려하여 토큰을 SAP 전략을 개발하여 사용!
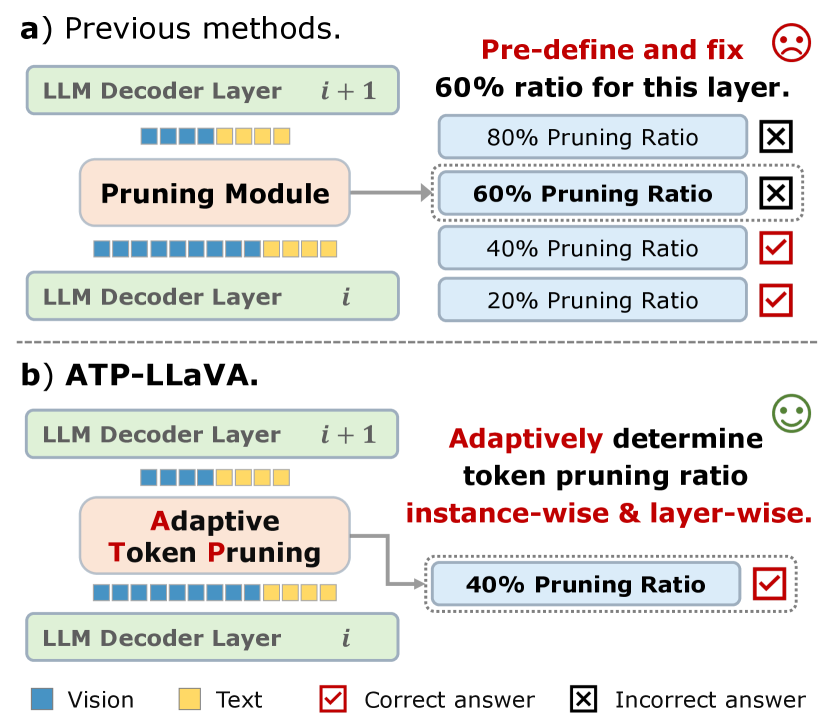
기존 모델들은 고정된 방법으로 프루닝을 진행했다. 그리하여 맞출 수 있는 문제도 틀려버리는 경우가 나와버린다.

레이엉의 초반부 역할이 강력하고, 후반부로 넘어갈 수록, 프루닝의 역할이 약해지는 것을 볼 수 있다.
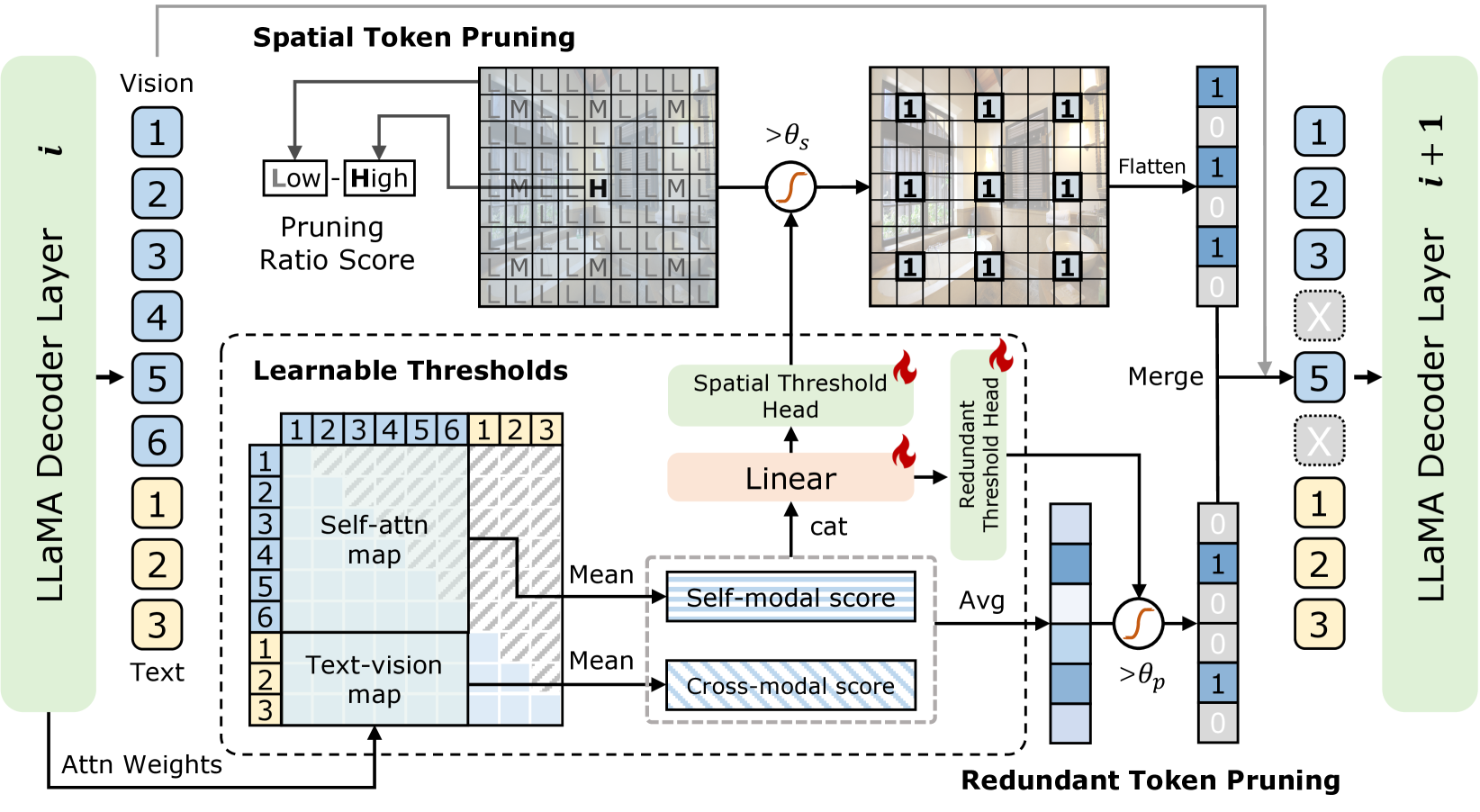
이 그림을 통해 ATP-LLaVA의 구조를 명확하게 볼 수 있다.

결과!
*은 평균이라는 뜻 이라네요

예시를 통해 ATP-LLaVA의 작동 방식을 이해할 수 있다.
얕은 층과 중간 층(4, 14)에서 대부분의 필요 없는 토큰은 사라져있는 것을 볼 수 있다.
| 📌 문제 정의 | LVLMs의 시각 토큰 수가 많아 연산량과 메모리 비용이 매우 큼 기존 프루닝은 고정 비율로 적용되어 인스턴스/레이어에 따라 비효율 발생 |
| 💡 핵심 아이디어 | Adaptive Token Pruning 모듈을 도입하여, 각 이미지/프롬프트에 따라 레이어별로 다른 프루닝 임계값을 학습해 적용 |
| 🧠 구성 요소 | ① Redundant Score: self-attn + cross-attn으로 의미 기반 중요도 계산 ② Spatial Score: 공간 균형 유지 위해 균등 샘플링 기반 점수 계산 ③ Learnable Thresholds: MLP로 θ_r, θ_s 동적 예측 (인스턴스별 다름) ④ Differentiable Masking: 학습 중 soft mask, 추론 시 하드 pruning ⑤ ATP Loss: 토큰 수를 제한하는 budget-aware loss 추가 |
| 🔁 동작 방식 요약 | 🔹 매 LLM 레이어 사이마다 ATP 모듈 삽입 🔹 각 시각 토큰에 대해 redundant/spatial 중요도 계산 🔹 학습된 threshold 기반으로 중요하지 않은 토큰 제거 🔹 인스턴스와 레이어마다 pruning 강도 다르게 작동 |
| 📊 실험 결과 | 🔸 기준 모델: LLaVA-1.5 (576 tokens) 🔸 ATP-LLaVA (평균 144 tokens): 98.1% 성능 유지 🔸 ATP-LLaVA (평균 88 tokens): 94.6% 성능 유지 🔸 FLOPs 78.1% 감소, 메모리 75% 감소, 성능 손실 < 2% |
| 📈 Ablation 결과 | Redundant or Spatial pruning 제거 시 각각 성능 약 1pt 하락 두 pruning 전략과 positional embedding이 모두 중요 |
| ✅ 기여점 | 🔹 Instance-wise + Layer-wise 동적 프루닝 최초 제안 🔹 의미와 공간을 모두 고려한 복합적 pruning 구조 🔹 End-to-end 학습 가능한 differentiable pruning 설계 🔹 LVLM 연산 최적화에 실용적 전환점 제공 |
| ⚠️ 한계 | 🔸 특정 모델 구조(LLaVA-1.5)에 특화됨 🔸 텍스트 토큰 pruning은 적용 안 됨 🔸 pruning 전략의 해석 가능성 부족 (black-box threshold) |
| 🧠 후속 연구 방향 | 🔸 Prompt-aware pruning / 텍스트 pruning 확장 🔸 Token revival, structured pruning 통합 🔸 다른 multimodal task (segmentation 등) 확장 가능성 |
🔍 1. 문제 정의: 왜 프루닝이 필요한가?
LVLM은 고성능 멀티모달 이해 능력을 보여주고 있지만, 특히 시각 정보(visual tokens)의 수가 많아 막대한 연산량과 메모리 사용량을 유발합니다. 이를 해결하기 위해 기존에는 고정 비율로 시각 토큰을 제거(prune)하는 방법을 사용했으나, 이는 다음과 같은 문제를 갖습니다:
- 모든 레이어에 동일한 비율 적용 → 비효율적
- 이미지-질문 쌍(instance)마다 요구되는 정보량이 다름 → 정보 손실 or 과잉 유지 발생
💡 2. 제안 방법: ATP-LLaVA의 구조
ATP-LLaVA는 각 레이어, 각 인스턴스에 따라 프루닝 비율을 동적으로 조절하는 프레임워크입니다.
🔧 (1) Adaptive Token Pruning (ATP) 모듈
- 모든 LLM 디코더 레이어 사이에 삽입 가능
- 각 시각 토큰의 중요도를 계산해 불필요한 토큰을 제거
- 두 가지 기준으로 토큰 중요도 평가:
- Redundant Pruning Score: 비전-비전 & 비전-텍스트 간 주의력(attention) 기반
- Spatial Pruning Score: 공간적 분포 기반 (공간적으로 균등한 샘플링)
🔎 (2) Learnable Thresholds
- 각 레이어, 각 인스턴스에 대해 프루닝 임계값을 MLP 기반으로 학습
- Self-attention 및 Cross-attention 점수를 입력으로 사용
🧊 (3) Differentiable Mask
- 학습 시에는 hard pruning 대신 soft mask를 적용해 미분 가능성 확보
- 추론 시에는 불필요한 토큰을 실제로 제거하여 연산 절약
📉 (4) ATP Loss
- 프루닝 후 남은 토큰 수를 기반으로 패널티 부여
- 목표 토큰 수(N_target)와의 차이를 최소화하며 효율과 성능 균형 유지
🧠 3. 주요 실험 결과
📊 실험 벤치마크
- GQA, MMBench, MME, POPE, SEED, ScienceQA, VQAv2 등 7개 벤치마크에서 성능 평가
🥇 주요 결과
| 모델 | 평균 토큰 수 | 성능 유지율 |
| LLaVA-1.5 (기준선) | 576 | 100% |
| ATP-LLaVA (144) | 144* | 98.1% |
| ATP-LLaVA (88) | 88* | 94.6% |
- 평균 토큰 수 75% 감소 + 성능 손실 < 2%
- 특히 MMBench, SEED-Bench 등에서 기준선 모델보다 성능이 향상됨
🧪 4. 상세 분석 및 Ablation Study
| 제거 항목 | 평균 성능 하락 |
| Redundant Pruning 제거 | -1.05 pt |
| Spatial Pruning 제거 | -1.0 pt |
| Positional Embedding 제거 | -0.9 pt |
| Self-attn or Cross-attn만 사용 | -0.4 ~ -0.5 pt |
- Redundant + Spatial pruning의 조합이 가장 효과적
- Self-attn + Cross-attn 조합이 중요도 계산에 모두 필수
🔧 5. 효율성 분석
| CUDA 시간 감소 | FLOPss 감소 | 성능 유지율 | |
| ATP-LLaVA (144) | 38.4% 감소 | 78.1% 감소 | 98.1% |
| FastV (기존법) | 40.1% 감소 | 75% 감소 | 81.7% |
- 약간의 오버헤드(MLP로 인한 1~2%)는 발생하나,
- 성능 향상으로 인해 전체 효율성은 ATP-LLaVA가 우수
🖼️ 6. 시각화 분석
- 쉬운 이미지일수록 shallow layer에서 많은 토큰 제거
- 복잡한 이미지에서는 token을 더 많이 유지
- 마지막 layer에서는 대부분 pruning되어 text로 정보가 흡수됨
🧩 7. 결론 및 연구 의의
ATP-LLaVA는 LVLM의 비전 토큰을 인스턴스 및 레이어 수준에서 적응적으로 제거하여, 최소한의 성능 손실로 최대한의 연산 효율을 달성할 수 있는 새로운 토큰 프루닝 패러다임을 제시합니다.
- 기존의 고정 비율 프루닝 한계를 극복
- 실시간 적용 가능한 경량 프루닝 모듈로서 실용성 높음
- LVLM 경량화 연구의 새로운 기준이 될 수 있음
📘 앞으로의 연구 제안
- ATP-LLaVA의 구조를 비전-텍스트 alignment 학습에도 적용 가능할지 검토
- 동적 instruction 길이 조절과의 결합 연구
- 초경량 디바이스 적용을 위한 pruning-aware 학습 최적화 기법 도입
필요하시면 코드 구조나 파라미터 튜닝 방식에 대해서도 추가 분석해드릴 수 있어요.
🧩 관련 주요 연구들과 비교
🔹 1. LLaVA-PruMerge
정적 프루닝 기반의 대표적 방법
- 핵심 아이디어:
Transformer 내부에서 중복되는 시각 토큰을 클러스터링하여 사전에 정해진 비율만 남기고 제거함
("토큰 병합 + 고정 비율 프루닝") - 특징:
- 프루닝 비율은 레이어와 인스턴스에 무관하게 고정됨
- spatial uniform sampling만 수행
- 한계점:
- 고정된 비율로 인해 복잡한 이미지에 필요한 정보까지 제거 가능성
- 프루닝 전략이 상황 적응적이지 않음
- ATP-LLaVA와의 차이점:
항목 PruMerge ATP-LLaVA 프루닝 비율 고정 인스턴스 및 레이어별로 동적 결정 고려 요소 spatial spatial + semantic (attention 기반 중요도) 학습 가능성 비학습 기반 학습 가능한 모듈(MLP 기반 threshold 학습)
🔹 2. FastV [9]
Layer 내에서의 Vision Token 내부 프루닝
- 핵심 아이디어:
LLM의 Transformer 레이어 내부에서 vision token redundancy를 줄이기 위해 사전 정의된 pruning 적용 - 특징:
- 빠른 추론 속도를 목표로 함
- 프루닝 위치는 고정되어 있으며, 각 인스턴스에 대해 개별 특성 반영 없음
- ATP-LLaVA와의 차이점:
항목 FastV ATP-LLaVA 프루닝 위치 Layer 고정 Layer별 유연하게 삽입 전략 비적응형 (fixed) 적응형 (learnable) 중요도 계산 없음 attention 기반 self/cross modality 중요도 활용 성능 저하 약 18% 성능 저하 <2% 성능 저하
🔹 3. SparseVLM [56]
시각 토큰 sparsification을 통한 효율적 처리
- 핵심 아이디어:
시각 토큰 중 중요도 높은 부분만 sparse하게 유지하여 전체 토큰 수 감소 - 특징:
- 일부 layer에서만 sparsification 적용
- attention weight 기반 importance 측정
- ATP-LLaVA와의 차이점:
SparseVLM ATP-LLaVA 프루닝 방식 sparsification (희소화) token masking 및 discard 적용 범위 일부 layer 모든 layer 가능 spatial 정보 유지 미약함 SAP 통해 spatial 보존 강화 학습 방식 고정된 sparsity layer & instance별 동적 threshold 학습
🔹 4. Matryoshka Multimodal Models [7]
모델 경량화에서 토큰 수 조절 가능한 모델
- 핵심 아이디어:
하나의 모델이 다양한 토큰 수 설정에 대응할 수 있도록 훈련 - 특징:
- 모델은 여러 pruning level을 지원하나, 인스턴스별로 동적 결정하지 않음
- 내부적으로 token masking만 지원하고 중요도 학습은 없음
- ATP-LLaVA와의 차이점:
Matryoshka ATP-LLaVA 목적 다양한 pruning 수준 지원 최적의 pruning 비율 동적 탐색 중요도 측정 없음 attention 기반 중요도 계산 학습 방식 일반적인 multi-pruning fine-tuning pruning-aware loss 포함한 end-to-end 학습
📘 요약 정리: ATP-LLaVA의 차별화 포인트
| 항목 | ATP-LLaVA의 강점 |
| 프루닝 결정 | 토큰 중요도 (self + cross modality attention)를 활용하여 레이어별 & 인스턴스별 동적으로 결정 |
| 공간 정보 유지 | Spatial Augmented Pruning (SAP)을 통해 프루닝 중에도 2D spatial 정보 유지 |
| 학습 가능성 | Learnable Thresholds + Soft Mask로 end-to-end 학습 가능 |
| 성능/효율 트레이드오프 | 75% 시각 토큰 제거에도 <2% 성능 손실로 고성능 유지 |
| 경량화 설계 | 기존 구조 변경 없이 디코더 사이에 모듈 삽입 가능 |
🧠 향후 연구에 줄 수 있는 인사이트
- Prompt-adaptive Pruning: Prompt의 형태에 따라 pruning 강도를 조절하는 방식 연구
- Multimodal Relevance Modeling: 단순 attention score 외에도 CLIP similarity나 다른 modality relevance 기반 중요도 측정 기법 도입
- Token Revival Mechanism: 프루닝 후 성능 저하가 생긴 경우 일부 토큰을 복원하는 동적 구조 연구 가능
더 심화된 주제나, 특정 모델 구조 기반으로 적용 전략을 탐색하고 싶으시면 이어서 알려주세요. 예: LLaMA-3, Qwen-VL, or Mobile Vision Transformer 등에의 응용 등.
🧠 ATP-LLaVA 방법론 정리 (Methodology)
ATP-LLaVA는 LLaVA(Large Vision-Language Model)를 더 효율적으로 만들기 위해, 인스턴스와 레이어별로 시각 토큰을 프루닝하는 모듈을 제안합니다.
핵심은 "얼마나 많은 시각 토큰을 남길 것인가?"를 똑똑하게 학습해서 결정하는 것입니다.
📌 전체 아키텍처 개요
[Input Image + Prompt Text]
↓
[Vision Encoder (CLIP ViT)]
↓
[Visual Tokens + Text Tokens]
↓
[LLM Decoder Layer 1]
↓ ↘
[ATP Module] ← 중요도 계산 후 프루닝
↓
[LLM Decoder Layer 2]
↓ ↘
[ATP Module]
...
↓
[LLM Decoder Layer N]
↓
[Output Text]
🧩 1. Adaptive Token Pruning (ATP) 모듈의 구성
ATP 모듈은 각 LLM 디코더 레이어 사이에 삽입됩니다. 이 모듈은 두 가지 단계를 거쳐 중요하지 않은 시각 토큰을 제거합니다.
💡 개념 예시
- 질문: "What color is the cat's collar?"
- 이미지: 고양이, 배경, 소파, 책, 창문 등 여러 시각 정보 존재
이 경우, "고양이의 목걸이" 주변 시각 정보만 중요합니다. ATP는 그 주변 토큰만 남기고 나머지를 제거하는 방식입니다.
🧱 2. 핵심 구성 요소 설명
🔶 (1) 중요도 점수 계산 (Token Importance Scoring)
✅ Self-Modality Score (S_self)
- 시각 토큰 간 자기 주의력(self-attention) 기반으로 중요도 측정
→ 다른 시각 토큰들이 얼마나 이 토큰에 집중하는가?
✅ Cross-Modality Score (S_cross)
- 텍스트 토큰들이 시각 토큰에 집중하는 정도 기반 중요도
→ 질문과 관련된 부분인가?
🎯 최종 중요도
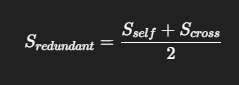
📌 예시:
- "cat", "collar"에 관련된 토큰은 높은 S_cross 점수를 받음
- 배경 토큰은 S_self, S_cross 모두 낮음 → 제거 후보
🔶 (2) Spatial Augmented Pruning (SAP)
프루닝 과정에서 공간 정보 손실을 방지하기 위한 전략
🔹 Uniform Spatial Sampling
- 이미지 상에서 균일하게 토큰을 샘플링
- 너무 많은 제거 시 spatial context 손실되므로 일부는 유지
🔹 Spatial Score (S_spatial)
- 균일 샘플링된 위치에 가중치 부여 (샘플링 밀도 기반)
🔶 (3) Learnable Threshold Prediction
토큰을 남길지 버릴지를 결정하는 임계값(threshold)을 학습합니다.
- MLP(Linear) Head를 통해 θ_r (redundant), θ_s (spatial) 두 임계값을 예측
- 임계값보다 낮은 중요도 점수를 가진 토큰은 제거됨
z = Linear(Concat(S_self, S_cross))
θ_r = Sigmoid(Linear_r(z))
θ_s = Sigmoid(Linear_s(z))
📌 예시:
- "cat" 관련 토큰은 중요도 점수가 높아 θ_r, θ_s를 넘음 → 유지
- 배경 토큰은 임계값보다 낮음 → 제거
🔶 (4) Differentiable Pruning via Soft Mask
학습 가능한 구조를 위해, 프루닝을 soft masking으로 처리

- 학습 중에는 softmax attention에 masking 적용
- 추론 시에는 아예 해당 토큰 제거 (연산 절약)
⚙️ 3. Budget-Constrained Training (ATP Loss)
🎯 목적:
성능은 유지하면서 토큰 수는 줄이도록 압력을 가함
🔸 Loss 구성:
- 원래 목적 (예: captioning loss, QA loss 등)
- LATP: 프루닝된 토큰 수에 비례해 패널티 부여
- Ltarget: 목표 토큰 수(N_target)와 실제 프루닝 수 차이 최소화
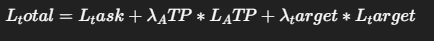
⏱️ 4. 연산 효율 향상
- 평균 75% 토큰 제거
- FLOPs 78% 감소
- CUDA 시간 38% 감소
- 성능 손실 < 2%
즉, "거의 동일한 성능을 훨씬 빠르고 효율적으로" 달성함.
📊 요약: 전체 단계 흐름
- CLIP으로 시각 정보를 추출
- ATP 모듈이 각 레이어마다 시각 토큰 중요도 평가
- 불필요한 토큰을 제거 (redundant + spatial 기준)
- 학습 가능한 임계값으로 동적 결정
- 성능과 연산량 균형을 맞추는 loss로 학습
🧠 추가 팁: 왜 이 구조가 중요한가?
- 기존에는 “모든 이미지에 대해 같은 비율”로 토큰을 제거했기 때문에, 과소/과잉 프루닝 문제가 심각
- ATP-LLaVA는 프롬프트, 이미지 내용, 레이어 깊이 등을 종합적으로 고려해 최적의 프루닝 비율을 학습함
- 고성능 LVLM을 모바일이나 Edge 디바이스에도 실용화할 수 있는 기반 기술임
필요하시면 이 구조를 다른 모델에 적용하거나, 개선 아이디어를 논의하는 방향으로도 확장해드릴 수 있어요!
좋은 질문입니다.
ATP-LLaVA에서 임계값(Threshold)을 학습할 때 예측하는 redundant와 spatial은 각각 프루닝을 위한 두 가지 기준이며, 이 두 기준은 서로 다른 관점에서 토큰의 중요도를 평가합니다.
🔹 개요: 왜 두 가지 기준이 필요한가?
시각 토큰을 제거할 때, 단순히 중요하지 않아 보이는 토큰을 없애는 것만으로는 부족합니다.
"내용상 덜 중요한 토큰"과 "공간 정보 보존을 위해 필요한 토큰"은 구분해서 다뤄야 하죠.
그래서 ATP-LLaVA는 아래 두 기준을 따로 평가하고, 각 기준에 대해 임계값을 학습합니다:
| 구분 | 의미 | 무엇을 평가하는가? | 주로 제거되는 토큰 |
| 🟥 redundant pruning | 의미 중복 기준 | 의미적으로 불필요한 토큰인가? (텍스트와 관계 없음) | 의미 없는 배경, 반복되는 패턴 |
| 🟦 spatial pruning | 공간 분포 기준 | 공간적으로 과도하게 밀집된 토큰인가? | 밀도 높은 영역의 토큰 |
🔸 1. redundant pruning (의미 기반 프루닝)
텍스트와 무관하거나, 시각 내에서 의미가 중복되는 토큰은 제거하자
📌 어떻게 계산하나?
두 가지 중요도 점수를 평균냅니다:
- S_self: 다른 시각 토큰들이 얼마나 이 토큰에 집중하는가?
- S_cross: 텍스트 토큰들이 이 토큰에 얼마나 집중하는가?
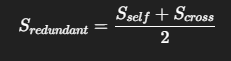
📌 예시
- 질문: "What color is the dog's leash?"
- 이미지: 개, 목줄, 나무, 풀, 하늘, 벤치…
→ 여기서 나무, 하늘, 벤치 같은 정보는 텍스트와 관련성이 없고, 시각 정보 간 중요도도 낮음
→ redundant score가 낮고, 제거 대상이 됩니다.
🔸 2. spatial pruning (공간 보존 관점 프루닝)
이미지의 전체 공간에서 골고루 시각 정보를 유지하도록 하자
📌 왜 필요한가?
- 의미상 중요하지 않더라도 공간 정보 보존은 시각 모델의 이해에 필수
- 예: 텍스트에는 없지만 “왼쪽 상단의 개체”가 필요한 경우가 있음
📌 어떻게 계산하나?
- Rs: 균등한 spatial sampling 비율
- S_spatial: 샘플링 비율에 따라 score 부여 (많이 뽑힐수록 더 중요)

→ S_spatial이 낮은 토큰은 과도하게 밀집되었거나 덜 중요한 공간 → 제거
🔧 임계값 학습은 어떻게?
각 기준에 대해 MLP head가 임계값을 예측합니다:
z = Linear(Concat(S_self, S_cross))
θ_r = Sigmoid(Linear_r(z)) # redundant threshold
θ_s = Sigmoid(Linear_s(z)) # spatial threshold
→ 이 θ_r, θ_s는 인스턴스와 레이어마다 다르게 예측됨
→ 즉, "이 이미지, 이 질문, 이 위치에서는 어디까지 제거해도 괜찮을까?"를 학습하는 구조
✅ 최종 프루닝 마스크는?
두 기준 중 하나라도 통과하면 토큰을 유지합니다:
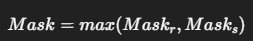
→ 의미 중요도(redundant)와 공간 보존(spatial) 중 하나라도 중요하면 살립니다.
💬 요약
| 항목 | 의미 |
| redundant | 텍스트와 관련성 없거나 시각적으로 중복된 토큰 제거 |
| spatial | 공간적으로 과도하게 밀집된 토큰 제거, 공간 분포 유지 |
| 두 기준을 왜 나누는가? | "의미적으로 불필요한 정보"와 "공간적으로 덜 중요한 정보"는 서로 다르기 때문 |
| 어떻게 학습하는가? | S_self, S_cross를 기반으로 두 개의 MLP가 각각 임계값(θ_r, θ_s) 예측 |
필요하다면 이 구조를 다른 task (예: Object Detection, Segmentation)에 응용하는 방법도 도와드릴 수 있습니다!
✅ ATP-LLaVA 논문 결과, 결론, 마무리 정리
📊 1. 결과 (Results)
ATP-LLaVA는 기존 LVLMs에서 시각 토큰을 효과적으로 줄이면서도 성능 손실을 최소화하는 데 성공했습니다.
🔹 실험 설정 요약
- 기준 모델: LLaVA-1.5 (CLIP-ViT-L + Vicuna-7B)
- 테스트 벤치마크:
GQA, MMBench, MME, POPE, SEED-Bench, ScienceQA (SQAI), VQAv2 등 7개 - 비교 방법:
- 고정 프루닝 기법: PruMerge, FastV, SparseVLM
- ATP-LLaVA (144 토큰 / 88 토큰 버전)
📌 주요 수치 결과
| 모델 | 평균 토큰 | 성능 유지율 | 정확도 |
| LLaVA-1.5 (기준선) | 576 | 100% | 최고 성능 |
| ATP-LLaVA (144*) | 144 | 98.1% | 준수한 수준 유지 |
| ATP-LLaVA (88*) | 88 | 94.6% | 소폭 성능 감소 |
| FastV (128) | 128 | 79.9% | 성능 급락 |
| SparseVLM (128) | 128 | 91.0% | 준수하지만 ATP보다 낮음 |
★ ATP-LLaVA는 평균 75% 이상의 토큰을 줄이고도 98% 이상 성능 유지
⚙️ 효율성 분석
| ATP-LLaVA (144) | 감소율 | |
| 토큰 메모리 | 75.6MB | 75% 감소 |
| FLOPs | 266.4 GFLOPs | 38.4% 감소 |
| CUDA 시간 | 2.1ms | 38.4% 감소 |
- FastV 대비 성능 +16.4% 향상 (FLOPs는 비슷)
- 거의 동일한 성능을 훨씬 더 빠르고 적은 메모리로 달성
🔬 Ablation Study 요약
| Ablation 항목 | 성능 영향 |
| redundant pruning 제거 | -1.05 pt |
| spatial pruning 제거 | -1.0 pt |
| positional embedding 제거 | -0.9 pt |
| self-attn만 사용 | -0.43 pt |
| cross-attn만 사용 | -0.55 pt |
→ 두 pruning 방식과 positional 정보를 모두 사용하는 조합이 가장 효과적
🧑🎨 시각화 결과
- 복잡한 이미지에서는 shallow/mid layer에서 토큰을 더 많이 유지
- 간단한 이미지에서는 early layer부터 적극적으로 pruning
- 마지막 레이어에서는 대부분의 시각 정보가 텍스트로 통합되어 pruning이 강하게 일어남
🧾 2. 결론 (Conclusion)
ATP-LLaVA는 인스턴스 및 레이어별로 적응형 토큰 프루닝을 수행하는 모듈로,
LVLM의 연산 비용을 줄이면서도 멀티모달 이해 성능을 거의 유지할 수 있습니다.
✨ 주요 기여 요약:
- Adaptive Token Pruning (ATP) 모듈 제안
- self-attn + cross-attn 기반 토큰 중요도 계산
- 임계값을 학습하여 유연한 pruning 가능
- Spatial Augmented Pruning (SAP) 전략 도입
- 의미 + 공간적 정보 동시에 고려
- 학습 가능한 프루닝 구조
- differentiable masking → end-to-end 학습 가능
- 성능 손실 거의 없이 75% 이상 토큰 절감
- 평균 98.1% 성능 유지
🧠 3. 마무리 및 시사점
📌 실질적 시사점
| 분야 | 기대 효과 |
| ✅ 모바일/Edge AI | LVLM 추론을 소형 디바이스에서도 실시간 실행 가능 |
| ✅ Visual QA / Captioning | 더 빠른 응답과 경량 추론 가능 |
| ✅ 프루닝 연구 확장 | 의미-공간 통합적 프루닝 방법론 제시 |
| ✅ Multimodal Adaptation | 인스턴스별 추론 최적화 가능성 열림 |
📘 후속 연구 방향 제안
- Prompt-aware pruning
→ 질문 유형에 따라 pruning threshold 동적으로 조정 - Cross-modal token revival
→ pruning 후 성능 저하를 복구하기 위한 selective token restoration 기법 - 지속 학습 시나리오
→ pruning 전략을 continual learning 구조에 적용해 학습 효율 최적화 - LLM 기반 Q-Former와의 통합 구조 설계
→ token 중요도 예측에 LLM 직접 참여하도록 확장 가능
필요하시면 이 논문을 기반으로 후속 논문 아이디어, 또는 실제 구현에 필요한 모듈 설계 전략도 도와드릴 수 있어요!
✅ 논문의 타당성, 한계, 기여점 평가
🧠 1. 타당성 검증 (Validity Analysis)
논문이 제안한 방법이 과연 신뢰할 수 있는지를 다음의 과학적 기준에 따라 평가해 봅니다.
✅ A. 문제 정의의 명확성
- ✅ 기존 LVLM 구조의 연산 비용 문제를 정확하게 진단
- ✅ 고정 프루닝 방식의 비효율성을 실험적으로 입증 (Fig. 2)
- ✅ Instance-wise & Layer-wise Pruning 필요성 논리 전개가 설득력 있음
✅ B. 방법론의 합리성
- Self-attention, Cross-attention 기반의 중요도 계산은 기존 VLM 연구들과 이론적으로 호환됨
- Spatial Pruning + Redundant Pruning을 분리해 다룬 것도 공간-의미 정보의 분리 개념에 부합
- Threshold를 학습하는 구조는 fully differentiable로 잘 설계됨
✅ C. 실험 설계의 타당성
- 벤치마크: GQA, MMBench, POPE 등 다양한 난이도/타입의 7개 벤치마크 사용
- 비교 모델: FastV, SparseVLM, PruMerge 등 최신 기법과의 공정한 비교
- Ablation Study에서 각 구성 요소의 기여도도 정량적으로 제시 → 모듈 신뢰성 검증
✅ D. 재현 가능성
- 공개된 링크 (https://yxxxb.github.io/ATP-LLaVA-page/) 통해 재현 가능성 확보
- LLaVA-1.5 및 CLIP-ViT-L 기반 구조 → 누구나 실험 구성 가능
⚠️ 2. 한계 (Limitations)
이 논문이 훌륭한 연구임에도 불구하고, 명확한 확장 가능성과 한계도 존재합니다.
⚠️ A. 전용 모델에 제한됨
- 구조는 LLaVA-1.5 + Vicuna에 맞춰 설계됨
→ 다른 구조(ex. Flamingo, Qwen-VL, GPT4V 등)에는 바로 적용 어려움
⚠️ B. Vision token만 pruning
- 텍스트 토큰에는 pruning 적용하지 않음
→ 사실 multimodal context를 고려하면 텍스트 pruning도 중요할 수 있음
⚠️ C. 임계값 학습 비용
- MLP 두 개가 들어간 threshold 예측은 매우 가볍지만, 여전히 inference-time latency에 미세한 영향 존재
⚠️ D. Fine-grained task에서는 여전히 제한
- 매우 세밀한 spatial 정보가 필요한 task (ex. Segmentation, VQA reasoning 등)에서는
88 token pruning의 경우 소폭 성능 하락 발생
⚠️ E. Dynamic Pruning 정책의 해석 가능성 부족
- ATP-LLaVA가 어떤 기준으로 pruning을 했는지 사람이 직관적으로 이해하긴 어려움
- Explainability 측면의 분석 부족
🌟 3. 기여한 점 (Key Contributions)
이 연구가 인공지능 커뮤니티에 미친 실질적 기여는 다음과 같습니다:
✅ 1. Instance-wise + Layer-wise 적응형 Vision Token Pruning 구조 제안
기존 fixed-ratio 방식에서 탈피 → 정확도와 연산 효율의 동시 확보
✅ 2. Redundant + Spatial 양측면에서의 중요도 평가
기존 연구 대부분이 한쪽만 고려
→ 공간/의미 통합적 중요도 기반 프루닝 최초 제안
✅ 3. Learnable Threshold + Soft Mask를 통한 end-to-end 학습 구조
프루닝 과정을 gradient 흐름 안으로 통합 → 학습 가능하고 미세 조정 가능한 pruning 구조
✅ 4. 최소 성능 손실로 최대 토큰 절감
평균 75% pruning, FLOPs 78% 감소, 성능 98.1% 유지
→ 실질적인 실용성 확보
✅ 5. VLM 프루닝 연구에 새로운 벤치마크 및 방법론 기준 제시
향후 연구들이 instance-adaptive한 방향으로 나아가는 기준점이 될 가능성 큼
🧾 요약 정리
| 📌 타당성 | 이론적, 실험적, 재현 가능성 모두 확보된 우수한 연구 |
| ⚠️ 한계 | 범용성 제한, 텍스트 pruning 없음, explainability 부족 |
| 🌟 기여 | 적응형 multi-기준 프루닝 전략, 학습 가능한 pruning 구조 제안, 실용성 입증 |
이 연구는 LVLM 경량화의 새로운 가능성을 열어준 실질적 기여를 했습니다.
후속 연구로 "pruning + compression + distillation"을 융합한 다단계 경량화 기법이나, "프롬프트 적응형 pruning" 같은 구조로 확장하면 더욱 강력한 모델을 만들 수 있습니다.
"Dynamic Pruning이라면서 왜 결과표에 144, 88처럼 정해진 토큰 수가 나와?"는 핵심적인 질문인데, 이건 ATP-LLaVA가 어떻게 작동하는지를 정확히 이해해야만 납득 가능한 부분입니다. 아래에서 전문가 관점으로 차근차근 설명드릴게요.
🔍 핵심 개념: ATP-LLaVA는 **"토큰 수를 정하는 것이 아니라, 임계값을 학습"**하는 방식입니다.
✅ 즉,
- 144, 88이라는 숫자는 사전에 정한 게 아니라,
- 학습이 완료된 후, 추론(inference) 단계에서 평균적으로 그 정도 토큰이 살아남는 것입니다.
🔁 학습 구조 복습: 왜 동적인가?
ATP-LLaVA는 학습 중에 다음 두 가지를 매 인스턴스, 매 레이어마다 동적으로 수행합니다:
- Redundant Score / Spatial Score 계산
- Learnable Threshold (θ_r, θ_s) 예측
→ 이 임계값은 MLP가 인스턴스마다 다르게 예측합니다.
# 토큰의 중요도와 이미지 특성을 보고
θ_r = MLP(S_self, S_cross) # redundant pruning threshold
θ_s = MLP(S_spatial) # spatial pruning threshold
- 그래서 pruning되는 토큰 수는 이미지, 프롬프트, 레이어에 따라 다릅니다.
- 하지만 전체 벤치마크 결과를 평균적으로 보면, 특정 수치(예: 144개, 88개)로 수렴하게 됩니다.
📊 결과표 속 수치는 무슨 의미인가?
👉 144, 88은 "평균적으로 남겨진 시각 토큰 수"
예: 144*
| 구성 | 의미 |
| 144* | 모든 이미지 + 32개 레이어 기준, 한 레이어당 남겨진 평균 시각 토큰 수가 약 144개라는 뜻 |
| 88* | 더 aggressive한 pruning을 한 버전으로, 평균 88개 토큰만 사용 |
📌 이 수치는 실제 추론 결과의 통계적 요약값이지, 고정값이 아닙니다.
💡 실례 예시
| Layer 4 | Layer 14 | Layer 24 | |
| 이미지 A (간단한 장면) | 106개 | 81개 | 19개 |
| 이미지 B (복잡한 장면) | 143개 | 109개 | 21개 |
➡ ATP-LLaVA는 매 인스턴스마다 다른 수의 토큰을 남깁니다.
➡ 그러나 전체 평균으로 보면 약 144개 수준이 유지된다는 뜻입니다.
⚖️ 왜 평균 토큰 수를 조절하는가?
학습 시에는 이 평균 토큰 수가 너무 높아지지 않도록 제한하는 추가적인 loss (L_target)이 들어갑니다.
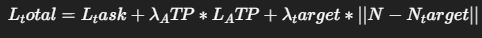
- N_target을 144, 88 등으로 설정하면
→ 학습 중 pruning 강도가 자동으로 조절되어
→ 평균적으로 그 정도 토큰만 남게 됩니다.
✅ 요약
| 질문 | 답변 |
| ATP-LLaVA가 동적이라면서 왜 144, 88로 고정돼 보이나요? | 실제로는 고정 아님. 인스턴스마다 다르며, 평균 토큰 수를 보고한 것일 뿐입니다. |
| 그럼 진짜 동적 pruning 맞나요? | 네, 매 이미지, 매 레이어에서 threshold를 동적으로 예측하고 pruning합니다. |
| 144, 88은 무슨 의미인가요? | 학습 시 설정한 목표 평균(N_target)에 따라, 최종적으로 평균적으로 남는 토큰 수를 의미합니다. |
궁금하시다면 L_target의 조절에 따라 얼마나 pruning 정도가 달라지는지도 분석해드릴 수 있어요!
또는 실제로 threshold를 시각화해 보는 연구 방향도 가능합니다.