https://aclanthology.org/2024.findings-acl.259.pdf
https://arxiv.org/abs/2401.17167
Planning, Creation, Usage: Benchmarking LLMs for Comprehensive Tool Utilization in Real-World Complex Scenarios
The recent trend of using Large Language Models (LLMs) as tool agents in real-world applications underscores the necessity for comprehensive evaluations of their capabilities, particularly in complex scenarios involving planning, creating, and using tools.
arxiv.org

기존 벤치마크들은 새로운 도구를 사용하지 않고, 제한된 차원에서 사용하며, 쿼리가 실제 작업의 복잡성을 반영하지 못한다!
1. 계획 - 목표를 도달하기 위해 단순한 하위 작업으로 분해하는지
2. 도구 인식 - 기존 도구가 충분한지 평가
3. 도구 생성 - 기준 tool이 부족하면 새로운 tool 개발
4. 도구 사용 여부 - 도구가 필요한 작업 판단
5. tool(도구) 선택 - 적절한 tool 선택
6. 도구 사용 - tool의 매개변수 지정!

대부분의 Tool 밴들은 이런 것이 없다고 하네요

Q, P, T로 구성되어 있다!
Q- 쿼리
P - planning으로 tool과 같이 작성되어 있음
T - Tool의 설명이 작성되어 있음
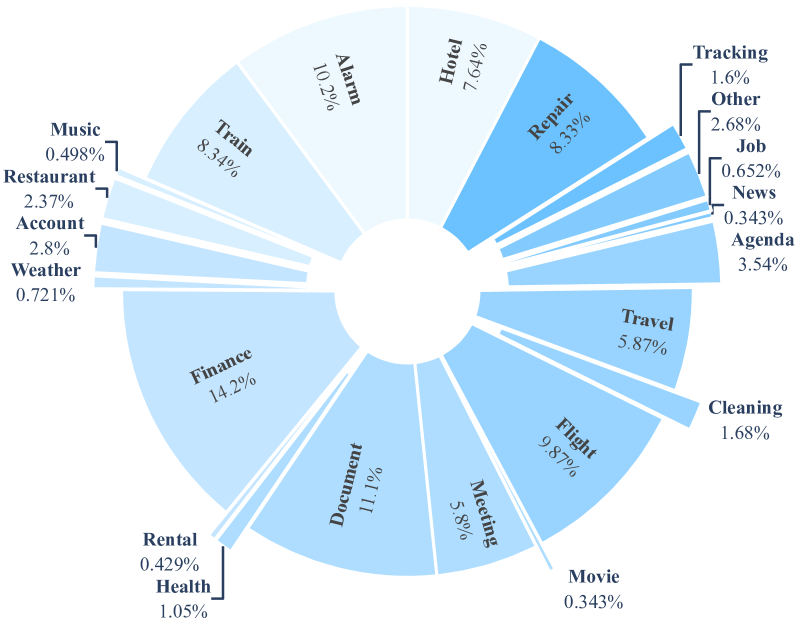
도메인 분포

쿼리를 변환하고, 주석을 다는 과정
계획 평가 방식
🎯 평가 목적:
- LLM이 문제를 얼마나 잘 분해하고, 단계별로 구조화했는가?
🛠 평가 방식:
- GPT-4 기반 다차원 평가 (LLM-as-Judge)
- 평가 항목 6가지:
- Accuracy: 원래 질문에 맞는 계획인가?
- Completeness: 필요한 하위 작업을 빠짐없이 포함했는가?
- Executability: 각 단계가 실제로 실행 가능한가?
- Syntactic Soundness: 문법과 언어 표현이 자연스러운가?
- Structural Rationality: 계획 구조(트리)가 논리적으로 조직됐는가?
- Efficiency: 불필요한 단계 없이 간결하게 구성됐는가?
이 평가 방식이 적절한 것인지는....
https://github.com/JoeYing1019/UltraTool
GitHub - JoeYing1019/UltraTool: [ACL2024] Planning, Creation, Usage: Benchmarking LLMs for Comprehensive Tool Utilization in Rea
[ACL2024] Planning, Creation, Usage: Benchmarking LLMs for Comprehensive Tool Utilization in Real-World Complex Scenarios - JoeYing1019/UltraTool
github.com
| 문제 정의 | 기존 벤치마크는 단순 도구 사용(툴 호출)에만 초점 → LLM의 실질적인 문제 해결 능력(계획, 툴 생성, 활용)을 평가할 수 없음 |
| 주요 목표 | LLM이 실세계 문제를 해결하기 위해 ①계획 → ②도구 생성 → ③도구 사용하는 능력을 종합적으로 평가할 수 있는 벤치마크 UltraTool 제안 |
| 벤치마크 이름 | UltraTool |
| 평가 대상 단계 | 총 6개 평가 항목 (3단계로 분류) ① Planning (계획 수립) ② Tool Creation: Awareness + Generation ③ Tool Usage: Awareness + Selection + Parameterization |
| 데이터 규모 | 총 5,824 샘플 22개 도메인 2,032개 도구 평균 12.27개 계획 단계, 평균 2.74개 툴 호출 중첩 호출 비율 39.6% |
| 쿼리 수집 방식 | 도메인 전문가가 현실 기반 쿼리 직접 수집 → GPT-4를 이용해 복잡화 및 다양화 진행 |
| 계획 (Planning) | 자연어 기반 계층 구조로 문제 분해 (tree 형태) 평가 항목: Accuracy, Completeness, Executability 등 6개 |
| 도구 생성 (Tool Creation) | 기존 도구가 부족할 경우, 도구 정의(JSON)를 스스로 생성 평가 항목: Format, Accuracy, Executability 등 5개 |
| 도구 사용 (Tool Usage) | 도구가 필요한지 판단 → 적절한 도구 선택 → 파라미터 구성 평가 항목: Awareness(Accuracy), Selection(Accuracy), Usage(Levenshtein) |
| 평가 방식 | 🧠 LLM-as-Judge: GPT-4 기반 다차원 자동 채점기 + Key-Value Accuracy / Levenshtein Distance |
| 실험 모델 | GPT-4, GPT-3.5, Qwen, Vicuna, Mistral, LLaMA2, Baichuan 등 |
| 결과 요약 | ✅ GPT-4: 전 영역에서 최고 성능 (76.04%, 74.58%) ✅ Qwen-72B: 오픈소스 중 최상 ✅ Mistral-7B: 소형 모델 중 높은 효율성 ❗ 대부분의 오픈소스 모델은 Tool Creation & Usage 단계에서 부족함 |
| 에러 유형 분석 | 지시 무시, 할루시네이션, JSON 오류, 불완전 출력 등 |
| 한계 | - 도구는 skeleton 형태 (실행 불가) - 정적 평가 기준 중심 (실행 결과 평가 아님) - 장기 의존 reasoning은 부족 |
| 의의 및 기여 | ✅ 최초의 전과정(tool reasoning pipeline) 기반 벤치마크 ✅ 현실 기반 멀티도메인 시나리오 ✅ Tool Creation 평가 최초 도입 ✅ LLM tool agent 연구 및 강화학습 튜닝 데이터로 활용 가능 |
| 향후 방향 | 🔧 실행 가능한 API 연결 / 동적 평가 🧠 Tool Creation 능력 강화 학습 🤖 End-to-End Self-Evolving Agent 연구 🧪 UltraTool 기반 fine-tuning / RLHF |
🔍 문제 정의: LLM의 진짜 도구 활용 능력은 평가되고 있는가?
최근 LLM이 외부 툴을 활용하며 복잡한 문제를 해결하는 능력이 주목받고 있습니다. 하지만 기존 벤치마크들은 단순한 시나리오(예: 단일 툴 호출)에만 초점을 맞췄고, 실제 세계의 계획-도구 생성-도구 사용이라는 복잡한 과정 전체를 다루지 못했습니다.
📌 이 논문은 UltraTool이라는 새로운 벤치마크를 통해, 도구 활용 전반 (기획, 생성, 사용)에 걸친 LLM의 능력을 실제 현실 문제를 기반으로 정량적 평가하는 체계를 제안합니다.
🧩 주요 기여 (Contribution)
- UltraTool 벤치마크 설계
- 총 22개 실세계 도메인 (예: 금융, 교통, 건강 등)에서 수집한 5,824개 복잡한 쿼리
- 도구 호출이 포함된 계층적 계획 구조
- 총 2,032개의 툴 스켈레톤(tool skeletons) 포함
- 도구 활용 능력의 6가지 평가 축
- Planning
- (①) 계획 능력: 문제를 하위 단계로 적절히 분해할 수 있는가?
- Tool Creation
- (②) 도구 필요성 인식: 기존 도구로 해결 가능한가?
- (③) 도구 생성: 새로운 도구를 생성할 수 있는가?
- Tool Usage
- (④) 도구 사용 필요성 인식
- (⑤) 적절한 도구 선택
- (⑥) 도구에 적절한 입력값 제공
- Planning
- LLM-as-Judge 기반 다차원 평가 지표
- GPT-4 기반의 다차원 채점자
- Accuracy, Completeness, Executability 등 다면 평가
- 도구 의존을 넘는 ‘자연어 계획’의 독립 평가
- 기존 도구 없이도 자연어로 먼저 계획을 수립하고, 그 계획에 따라 도구를 선택하거나 생성
⚙ UltraTool 구축 방법 (Step-by-Step)
1️⃣ 쿼리 수집
- 실제 사용자 시나리오 기반 쿼리 수집
- 도메인 전문가가 초기 툴셋 제안
- GPT-4로 다양화(Generalization) 및 복잡화(Complication) 수행
2️⃣ 자동 솔루션 주석화
- GPT-4 기반 자동 프로세스
- 계획 수립 → 툴 필요성 분석 → 툴 생성 → 툴 호출 인자 생성
3️⃣ 수동 검수 및 정제
- 총 6명의 전문가가 모든 샘플을 검토 및 수정
- JSON 포맷 오류, 중복, 누락, 불일치 등을 제거
🧪 실험 결과 및 분석
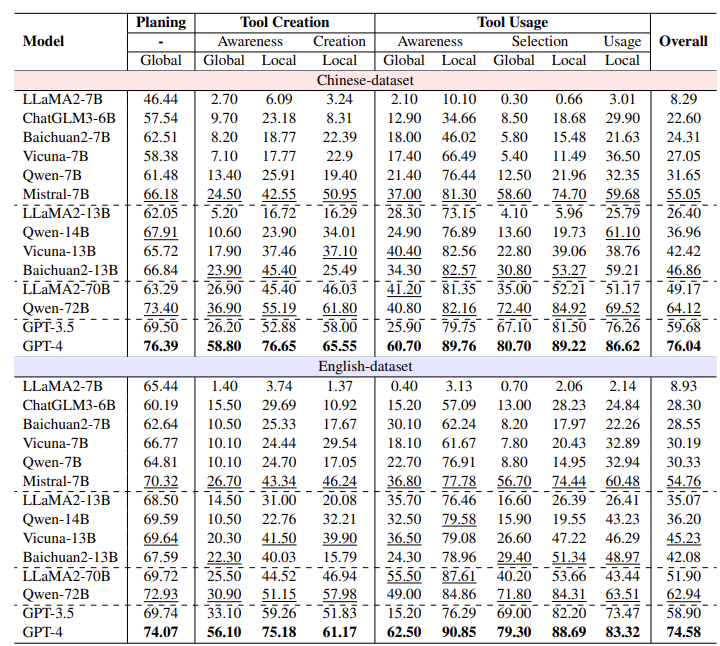
📊 성능 비교 (GPT-4 vs Open-Source)
- GPT-4: 전 영역에서 최고 성능 (종합점수: 중국어 76.04%, 영어 74.58%)
- Qwen-72B: 오픈소스 중 가장 우수 (중국어 73.40%)
- Mistral-7B: 모델 크기 대비 효율적인 성능
🔍 세부 분석
- 작은 모델일수록 문법(Syntactic)은 잘하지만 계획 논리성, 정보 충실성은 부족
- 툴 생성 시 JSON 포맷 오류, 정보 누락이 잦음
- 대형 모델일수록 툴 생성 및 파라미터 작성 능력 향상
📈 모델 크기와 성능 상관관계
- 모델 크기 증가 → 툴 활용 성능 증가
- 특히 툴 생성/사용에서 큰 차이 발생 (파라미터 조합 등 복잡한 논리 필요)
🧠 정성적 관찰 (Error 분석)
| 에러 유형 | 설명 |
| 지시 미준수 | 프롬프트를 무시하거나 부적절한 응답 생성 |
| 할루시네이션 | 존재하지 않는 도구/파라미터 생성 |
| 출력 중복 | 같은 내용 반복 또는 의미 없는 문장 포함 |
| 출력 누락 | 일부 단계 혹은 파라미터 생략 |
| JSON 형식 오류 | 형식 불일치로 평가 실패 |
🧪 평가 방법론 정리
📐 주요 평가 지표
| 평가 항목 | 사용 지표 |
| 계획 수립 능력 | GPT-4 기반 다차원 채점 (정확성, 구조성 등 6개 축) |
| 도구 생성 능력 | 도구 포맷 준수, 적절성, 풍부성 등 5개 축 |
| 도구 사용 능력 | 인식 여부(Accuracy), 선택(Accuracy), 사용(Levenshtein) |
🔚 결론 및 향후 과제
- UltraTool은 LLM의 툴 활용 능력을 계획부터 생성, 사용까지 종합적으로 평가할 수 있는 현실 기반 종합 벤치마크
- 현재 대부분 LLM은 도구 생성과 활용에 있어 여전히 취약
- 향후 연구는 툴 창의력, 파라미터 조합 최적화, 실제 툴 실행 환경과의 연계에 집중 필요
🧠 연구자 관점에서의 시사점
- Fine-grained task planning 능력을 향상시킬 수 있는 구조적 프롬프트 연구 필요
- LoRA, Adapter 등 경량화 모델도 Tool Creation-Usage로 실험해볼 가치 있음
- 사용자 목적 기반 "Plan → Tool Suggestion → Execution"의 Self-Evolving Agent Framework로 확장 가능
🔗 관련 연구 및 비교 분석
1. 🔧 기존 LLM 도구 활용 연구의 흐름
(1) Tool-Oriented Learning (도구 중심 학습)
- 대표 논문:
- Toolformer (Schick et al., 2023): LLM이 스스로 툴 호출을 학습하도록 사전 훈련 중 API 호출 삽입.
- CREATOR (Qian et al., 2023): 추상적 reasoning과 concrete reasoning을 분리하고, 도구 생성까지 수행.
- ToolkenGPT (Hao et al., 2023): 툴 임베딩을 통해 frozen LLM과 massive API 연동 가능하도록 설계.
- 한계:
- 툴을 사용하는 학습만 고려하고, 도구를 새로 만들거나 툴 사용 전의 계획 설계는 평가하지 않음.
(2) Tool-Augmented Learning (도구 증강형 인컨텍스트 학습)
- 대표 논문:
- Gorilla (Patil et al., 2023): 수천 개의 API 문서 기반 LLM 도구 호출 실험.
- HuggingGPT (Shen et al., 2023): ChatGPT를 중앙 조정자로 사용하여 여러 AI 툴 연결.
- 한계:
- 주로 “선택 및 사용”에 초점. 즉, 이미 주어진 도구 중 어떤 걸 선택하고 어떻게 쓸지를 평가.
(3) 기존 벤치마크의 한계
| 벤치마크 | 평가 범위 | 계획/도구 생성 평가 | 현실성 |
| ToolAlpaca (Tang et al., 2023) | 툴 사용만 (⑥) | ❌ | ❌ (시뮬레이션 기반 쿼리) |
| API-Bank (Li et al., 2023) | 툴 사용만 (⑥) | ❌ | ❌ |
| ToolBench (Qin et al., 2023b) | 툴 선택 + 사용 (④⑤⑥) | ❌ | ❌ |
| MetaTool (Huang et al., 2023) | 툴 인식 + 선택 | ❌ | ❌ |
➡️ 이들은 툴 사용 단계 (Tool Usage)에만 초점을 맞추고 있으며, 툴 생성 및 문제 해결 계획 수립(Planning)은 제외되어 있음.
2. 🆕 UltraTool의 차별점과 기술적 기여
✅ (1) 풀스택 도구 활용 평가 (Planning → Creation → Usage)
- 기존 연구가 다루지 않은 "툴 필요 인식 → 툴 생성 → 툴 호출"까지의 전체 경로를 벤치마크로 평가 가능.
- 특히 계획(Planning) 단계를 독립 평가하여, 도구가 없어도 자연어 기반 분해 능력을 측정 가능.
✅ (2) 툴 생성 능력 평가
- 기존 도구셋이 부족한 경우 LLM이 스스로 툴 스켈레톤을 생성해야 함.
- 이는 기존 벤치마크가 전혀 평가하지 않던 능력으로, LLM의 창의적 추론과 JSON 구조화 능력을 테스트.
✅ (3) 현실 기반 쿼리와 다도메인 설정
- 기존 벤치마크는 툴에 맞춰 쿼리를 생성했으나, UltraTool은 도메인 전문가가 실제 상황 기반으로 쿼리를 생성.
- 복잡한 조건, 다단계 의존성, 중첩된 툴 호출(nested tool call, 39.6%) 등 실제 시나리오와 매우 유사.
✅ (4) 평가 방식 자체의 혁신 (LLM-as-Judge)
- GPT-4 기반의 다차원 평가자(Multi-Dimensional Point-Wise Scoring)
- 기존 평가가 정답 대조(match/mismatch)에 의존했다면, UltraTool은 정확성, 구조성, 실행 가능성 등 총 6개 항목을 통해 정량 평가 수행.
📌 연구자가 주목해야 할 지점
| 기존 연구 | UltraTool | |
| 계획 능력 평가 | ❌ 없음 | ✅ NL 기반 계획 평가 (Accuracy, Completeness 등) |
| 도구 생성 능력 평가 | ❌ 없음 | ✅ JSON 기반 도구 정의 생성 및 평가 |
| 툴 사용 평가의 세분화 | 단일 단위 평가 | Awareness / Selection / Usage 분리 평가 |
| 쿼리 현실성 | 툴에 맞춰 생성된 시뮬레이션 쿼리 | 전문가가 수집한 실제 기반 쿼리 |
| 평가 방식 | 정답 매칭 / 단일 스코어 | GPT-4 기반 다차원 채점기(Metric + Structure) |
🔭 향후 연구 방향 제안 (from AI expert’s view)
- End-to-End Tool Agent 학습 프레임워크
- UltraTool 기반의 fine-tuning 및 RLHF를 통해 Tool Agent를 학습시키는 E2E 파이프라인 제안 가능.
- Tool Skeleton → 실제 툴 연동
- 현재는 도구 스켈레톤만 평가하지만, 이를 실제 API 또는 스크립트로 변환하여 실제 실행까지 이어지는 연구 확장 가능.
- Zero-shot 또는 Few-shot 도구 생성 능력 비교
- 다양한 LLM들이 처음 보는 도메인에서 툴을 얼마나 잘 생성하는지 비교 분석 가능.
- Open-source LLM 대상 구조적 Instruction Tuning
- Mistral이나 Qwen 같은 모델에 대해, 구조화된 계획 + 툴 생성 방식으로 instruction tuning을 적용할 수 있음.
🧠 방법론: 도구 활용 능력을 전방위로 평가하는 UltraTool 벤치마크
UltraTool은 LLM이 복잡한 실세계 문제를 해결하기 위해 어떻게 계획을 수립하고, 필요한 도구를 생성하고, 도구를 적절히 사용할 수 있는지를 종합적으로 평가하기 위한 다단계 벤치마크 시스템입니다.
📌 핵심 개념: 문제 해결의 3단계
LLM이 복잡한 문제를 푸는 과정은 다음 세 단계로 구성됩니다.
| 단계 | 설명 |
| ① Planning | 문제를 하위 단계로 나누고, 전체 해결 전략을 세움 (자연어 기반) |
| ② Tool Creation | 필요한 도구가 없을 경우, 도구의 이름, 설명, 입력/출력 등을 정의함 |
| ③ Tool Usage | 도구 사용이 필요한 경우, 적절한 도구를 선택하고, 파라미터를 설정해서 호출 |
🔧 UltraTool의 데이터 구조
하나의 샘플 구조:
(Q, P, T)
- Q: 사용자 쿼리
- P: 계획(Plan) – 계층 구조로 표현됨 (Tree 형태)
- T: 도구 집합 (Toolset) – JSON 형식으로 정의됨
예시:
Q: 500달러와 300유로를 위안화로 환전하려면 총 얼마인가요?
계획 (P):
1. 현재 환율 조회
1.1 USD → CNY 환율 조회 → tool: currency_exchange_rate
1.2 EUR → CNY 환율 조회 → tool: currency_exchange_rate
2. 금액 계산
2.1 USD 환전액 계산 → tool: foreign_currency_exchange
2.2 EUR 환전액 계산 → tool: foreign_currency_exchange
3. 합산
3.1 합계 계산 → tool: sum_amounts
3.2 결과 출력 → tool: 없음
🧩 각 단계별 평가 방법
① Planning: 계획 능력 평가
- LLM이 자연어로 문제를 어떻게 논리적으로 나누는지 평가
- 6개 세부 항목 평가:
- Accuracy, Completeness, Executability, Syntactic Soundness, Structural Rationality, Efficiency
예시 평가 기준:
- “환율 조회 → 환전 → 합산”이라는 논리가 순차적으로 잘 연결돼 있는가?
- 중복되거나 빠진 단계는 없는가?
- 문법적으로 정확하고 효율적인가?
② Tool Creation: 툴 생성 능력 평가
- 도구가 부족한 상황에서, LLM이 스스로 툴을 정의할 수 있는가?
- 포맷 예시 (JSON):
{
"name": "foreign_currency_exchange",
"description": "주어진 환율로 외화를 환전합니다.",
"arguments": {
"type": "object",
"properties": {
"amount": { "type": "number", "description": "환전할 금액" },
"sourceCurrency": { "type": "string" },
"targetCurrency": { "type": "string" },
"rate": { "type": "number" }
}
},
"results": {
"type": "object",
"properties": {
"converted_amount": { "type": "number" }
}
}
}
- 5개 평가 항목:
- Format Compliance, Accuracy, Content Reasonableness, Executability, Richness
③ Tool Usage: 도구 사용 능력 평가
총 3가지 세부 평가로 구성됩니다.
| 세부 평가 | 설명 | 예시 |
| Usage Awareness | 어떤 단계에 도구가 필요한지 인식 | “환율을 계산하려면 외부 도구가 필요하겠군” |
| Tool Selection | 적절한 도구를 선택 | currency_exchange_rate 도구 선택 |
| Parameter Usage | 도구에 적절한 인자를 설정 | amount=500, rate=<1 USD 환율> |
- 도구 이름 및 파라미터 명칭과 값은 정확한 맥락 기반으로 추출되어야 하며,
- Nested Tool Call (ex. A의 결과가 B의 인자로)도 고려해야 합니다.
🧪 평가 방식: LLM-as-Judge (GPT-4 기반 평가자)
기존 평가 방식은 단일 정답과 비교하는 “정답 기반 평가”였지만, UltraTool은 다차원적, 질적 평가를 자동화합니다.
| 방식 | 설명 |
| Multi-Dimensional Point-Wise 평가 | GPT-4가 항목별 점수 (1~10점)를 직접 채점 |
| Key-Value Accuracy | 단계별 도구 선택 또는 파라미터 매칭 정확도 |
| Levenshtein Distance | 생성된 인자 문자열과 정답 간 유사도 비교 |
💡 신뢰성 보장:
GPT-4 채점 결과와 인간 전문가의 채점 결과는 Pearson Correlation ≈ 0.85 이상 → 정량적 평가로 활용 가능.
📊 예시 실험 결과
- GPT-4: 종합 성능 최고 (Planning + Tool Creation + Usage 전반에서 강세)
- Qwen-72B: 오픈소스 중 최고 성능 (도구 생성까지 가능)
- Mistral-7B: 소형 모델 중 최적 효율성
주요 발견:
- 모델 사이즈가 클수록 도구 사용 성능 증가
- 도구 생성 성능은 여전히 GPT 계열이 압도적
✨ 요약
| 단계 | 평가 포인트 | 핵심 질문 |
| Planning | 계층적 논리와 계획 | 문제를 어떻게 쪼갤 것인가? |
| Tool Creation | 툴 정의 능력 | 새로운 툴을 만들 수 있는가? |
| Tool Usage | 도구 판단/선택/호출 | 어떤 도구를 어떻게 사용할 것인가? |
이러한 설계-생성-사용 전 과정을 벤치마크화한 UltraTool은 앞으로 LLM 기반 멀티모달 AI 에이전트, 자기진화형 에이전트, 실제 API 연동형 시스템을 설계하고 평가하는 데 매우 강력한 프레임워크가 됩니다.
추가적으로 이 구조를 실험 코드로 구현하거나, 오픈소스 LLM에 적용하는 튜토리얼도 설계해드릴 수 있습니다. 원하시나요?
✅ 결과 요약 (Results Summary)
UltraTool 벤치마크를 통해 GPT-4를 포함한 여러 LLM의 도구 활용 능력을 총 6개 평가 항목(3단계: 계획, 생성, 사용)에 대해 정량 평가했습니다.
🔍 주요 결과 정리
| 모델 | 종합 성능 (중국어) | 종합 성능 (영어) | 비고 |
| GPT-4 | 76.04% | 74.58% | 전체 최고 성능, 전 영역 우수 |
| GPT-3.5 | 69.50% | 58.90% | 도구 생성 및 사용에서 성능 저하 |
| Qwen-72B | 73.40% | 72.93% | 오픈소스 중 최고 |
| Mistral-7B | 66.18% | 54.76% | 경량 모델 중 최고의 효율 |
| 기타 모델 | 대부분 tool usage만 중간 수준 |
📈 주요 분석 포인트
1. 모델 크기 vs 성능
- 모델 규모가 클수록 도구 활용 능력이 향상됨
- 특히 Tool Creation과 Tool Usage 성능에서 큰 차이 발생
2. 언어별 성능 차이
- 영어와 중국어 데이터셋 모두에서 GPT-4가 가장 강력
- 다만 오픈소스 모델은 모델의 언어 특화 성향에 따라 성능이 달라짐
- 예: Qwen/Baichuan → 중국어에서 강세, LLaMA → 영어에서 상대적 강세
3. JSON 출력 정확도와 성능 상관관계
- 도구 사용 단계는 JSON 포맷이 필수 → JSON 생성 정확도는 전체 성능과 강한 양의 상관관계 보임
4. 오류 유형
- 주요 오류 유형:
- 지시 불이행 (Instruction Ignorance)
- 할루시네이션 (툴 이름, 인자 이름 허위 생성)
- 불완전 출력, JSON 형식 오류 등
🧾 결론 (Conclusion)
🎯 핵심 결론 요약
- UltraTool은 기존 벤치마크의 한계를 극복한 종합 평가 체계
- 단순 도구 사용에서 벗어나, 계획 → 생성 → 사용 전체를 아우르는 평가 가능
- 현실 기반의 다도메인 복합 쿼리를 통해 실질적인 도구 활용력 측정
- 도메인 전문가가 실제 시나리오 기반으로 문제 정의 → 평가의 신뢰성 및 실효성 높음
- GPT-4는 전 영역에서 강력한 성능을 보이며 tool agent로서의 잠재력 입증
- 특히 도구 생성 능력은 오픈소스 모델들과 큰 격차
- 오픈소스 모델은 문법적 구조 작성에는 능하지만 계획 논리성과 도구 활용에서는 여전히 취약
- 특히 도구 생성(JSON 작성 포함)에서 어려움이 큼
🧩 마무리: 시사점과 한계 (Discussion)
🌱 시사점 (What This Work Brings)
| 관점 | 내용 |
| 연구적 | LLM 도구 활용 능력에 대한 최초의 전체 프로세스 기반 평가 체계 확립 |
| 기술적 | 도구 호출뿐 아니라 도구 생성까지 포함한 tool-centric agent framework 평가 가능 |
| 실용적 | 다양한 실제 시나리오 기반 훈련/평가 데이터로 Agent 훈련용 fine-tuning/validation dataset으로 활용 가능 |
⚠ 한계 (Limitations)
- 툴은 skeleton 형태 (실제 실행 불가)
→ 실제 API 실행 여부를 반영하지 못함 (미래에 실동작 도구 연계 계획) - 도구 사용 평가가 정적 JSON 평가에 한정됨
→ 동적 실행 성공 여부 기반의 평가 아님 - 고도로 복잡한 reasoning이 필요한 장기 의존적 문제에 대한 평가 부족
→ UltraTool은 도구 중심 분해 문제에 최적화됨
🚀 향후 연구 방향 제안
- 실행 가능한 도구 연동 (Executable Tool Environment)
- OpenAPI, Web Automation 등으로 확장하여 실제로 LLM이 API를 호출하고 결과를 검증할 수 있도록 설계
- Tool Creation에 초점을 둔 Prompt Engineering 또는 Pretraining
- 스스로 적절한 툴을 정의하는 능력을 강화하는 학습 프레임워크 설계
- UltraTool 기반 Fine-tuning / RLHF
- UltraTool 데이터를 기반으로 tool-aware agent 모델을 사전 학습 → RLHF 또는 instruction tuning으로 성능 보완
- 자동 계획 + 도구 설계 + 호출까지 포함한 End-to-End Agent 연구
- Self-Evolving 또는 Self-Reflective Agent에 적용 가능
이로써 UltraTool은 LLM 기반 Tool Agent 시스템의 실질적 가능성과 한계를 모두 조명하며, 향후 AGI 시대의 지능적 도구 활용 능력을 평가하는 데 핵심적인 벤치마크로 자리매김할 수 있습니다.
🔨 UltraTool 구축 과정 요약: Q → (P, T)을 만드는 여정
UltraTool은 다음과 같은 4단계로 구성된 체계적인 데이터 생성 파이프라인을 통해 만들어집니다:
✅ 1단계: Query Collection (사용자 쿼리 수집)
목표: 현실에 존재할 법한, 복잡한 도구 사용이 필요한 질문을 모으자!
방법:
- 22개 실제 도메인 설정: 예) 알람, 항공권, 호텔, 금융, 건강 등
- 도메인 전문가에게 실제 사용자의 질문처럼 쿼리 작성 의뢰
- 각 질문에 대해 "이런 도구가 필요할 것 같다"는 초기 도구 후보(T 초기)도 함께 제시받음
🔧 예시:
Q = “나는 이번 주 월요일 오전 9시에 알람을 설정하고, 오후에는 회의를 예약하고 싶어.”
→ 전문가가 제안한 도구:
- alarm_set(time)
- calendar_schedule(title, time)
추가 작업:
- GPT-4로 질문을 일반화 / 복잡화하여 더 다양하고 어려운 쿼리도 생성
- 원본 + 확장된 쿼리를 통합 후 사람이 검수
✅ 2단계: Solution Annotation (해결 절차 구성)
목표: 질문 Q에 대해 LLM이 따라야 할 해결 절차 (P)와 사용할 도구들 (T)을 만들자!
자동화 + GPT-4 활용
🔹 (1) Plan Annotation
- GPT-4가 쿼리를 기반으로 여러 단계로 나누어진 계획(P) 생성 (트리 구조)
- 이 단계에서는 아직 도구를 고려하지 않음
🔄 예시:
1. 알람 설정 요청 파악
2. 오전 9시 알람 설정
3. 회의 일정 확인
4. 오후 회의 예약
🔹 (2) Tool Creation + Plan Refinement
- 위의 계획을 보면서, "기존 도구로는 부족하다면 새로운 도구 생성"
- 새 도구는 GPT-4가 JSON 포맷으로 정의
- 계획 P도 도구 호출을 고려해서 다시 다듬음
예시 Tool 생성:
{
"name": "set_alarm",
"arguments": {
"time": "string"
},
"results": {
"status": "boolean"
}
}
🔹 (3) Tool Calling Message Annotation
- 각 단계에 대해:
- 도구가 필요한지 판단
- 어떤 도구를 쓸지 선택
- 필요한 인자(argument) 채워 넣음
예시:
Step 2: 오전 9시 알람 설정 → tool: set_alarm(time="09:00")
Step 4: 회의 예약 → tool: calendar_schedule(title="회의", time="14:00")
→ 이 정보들이 바로 P의 (si, ti)에 해당함!
🔹 (4) Tool Merge
- 다양한 쿼리에서 비슷한 기능의 도구가 생성되었을 수 있음
- 중복 도구들을 수동으로 병합해서 최종 Toolset(T)을 정리
✅ 3단계: Manual Refinement (수동 정제)
목표: 계획(P)과 도구(T)의 정확도, 일관성, 완성도를 높인다
작업 내용:
- 누락된 단계 추가
- 잘못된 도구 선택 수정
- 인자 불일치/누락 수정
- JSON 형식 오류 수정
- 품질이 낮은 샘플 제거
검수자는 전문가 6명이며, 모든 샘플은 2번 검수함
✅ 4단계: 최종 데이터셋 구성
| 전체 샘플 수 | 5,824개 |
| 도메인 수 | 22개 |
| 최종 도구 수 | 2,032개 |
| 언어 | 중국어 원본 + GPT-4로 번역된 영어 버전 |
| 평균 계획 단계 수 | 12.27개 |
| 평균 도구 호출 수 | 2.74개 |
| 중첩 도구 호출 비율 | 39.61% (툴의 출력이 다른 툴의 입력이 되는 경우) |
📌 전체 프로세스 요약 그림
[사용자 질문 Q]
↓
도메인 전문가 + GPT-4 → 질문 다양화 (일반화 + 복잡화)
↓
GPT-4 → 계획 수립 (Plan P)
↓
GPT-4 → 필요한 도구 생성 (Tool Creation)
↓
GPT-4 → 도구 호출 메시지 작성 (tool calling in P)
↓
사람 → 중복 도구 병합 (Tool Merge)
↓
전문가 → 수동 검수 및 수정 (Manual Refinement)
↓
==> 최종 데이터셋 (Q, P, T)
🎯 핵심 요약 (Q, P, T 관련)
| Q | 사용자 질문 | 전문가 + GPT-4 |
| P | 해결 단계 계획 (with 도구 호출) | GPT-4 → 계획 수립 + 도구 호출 + 인자 생성 |
| T | 이 쿼리 해결에 필요한 도구 목록 (정의 포함) | 전문가 초기 제안 + GPT-4 도구 생성 + 수동 병합 |
이제 이해가 조금 더 되셨을까요? 필요하다면 이 과정을 코드로 시뮬레이션하는 구조를 같이 짜드릴 수도 있습니다. 계속 도와드릴까요?