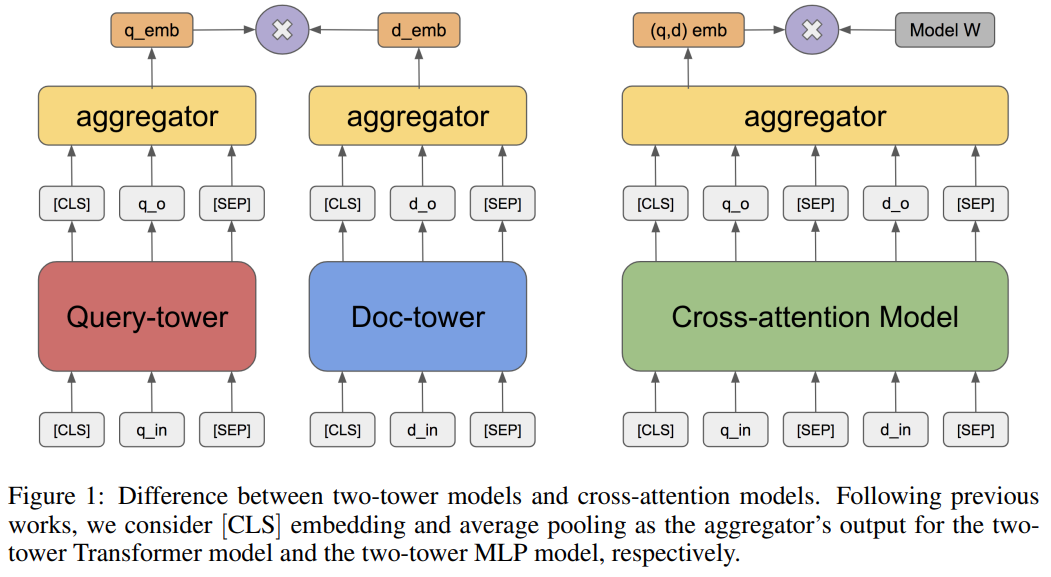
https://arxiv.org/abs/2002.03932 Pre-training Tasks for Embedding-based Large-scale RetrievalWe consider the large-scale query-document retrieval problem: given a query (e.g., a question), return the set of relevant documents (e.g., paragraphs containing the answer) from a large document corpus. This problem is often solved in two steps. The retriarxiv.org문서 검색에 시초인 논문인가 봅니다?기존에는 Doc와 Query 모두 넣..