https://arxiv.org/abs/2002.03932
Pre-training Tasks for Embedding-based Large-scale Retrieval
We consider the large-scale query-document retrieval problem: given a query (e.g., a question), return the set of relevant documents (e.g., paragraphs containing the answer) from a large document corpus. This problem is often solved in two steps. The retri
arxiv.org
문서 검색에 시초인 논문인가 봅니다?
기존에는 Doc와 Query 모두 넣고, 거기서 가장 높은 점수를 골랐다면, 이젠 각각 독립적으로 넣어, Emb sim만 계산하는 형식으로 문서를 가져오네요
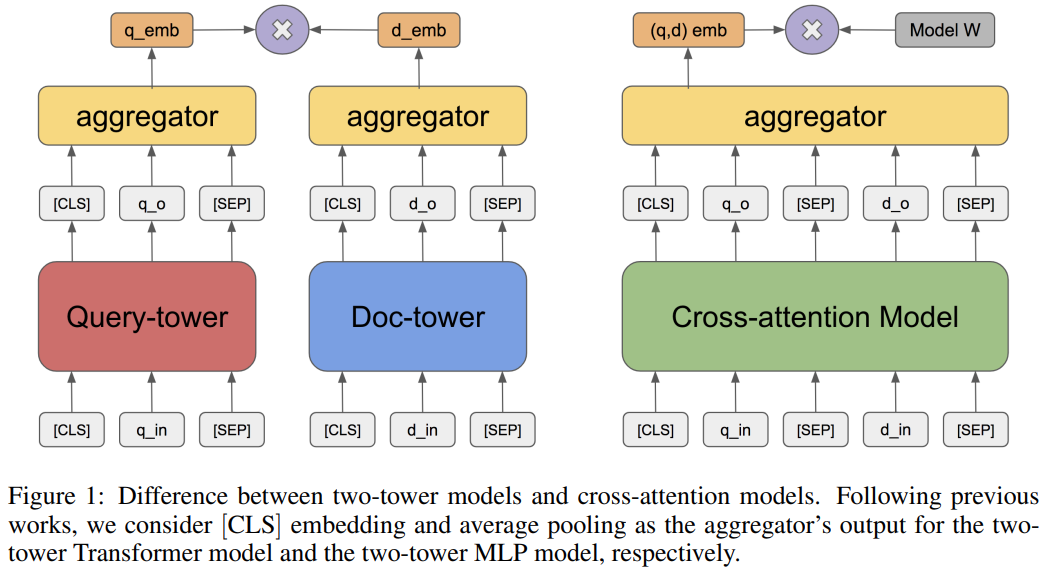
| 문제 상황 (Problem) | - 대규모 retrieval 시스템에서 효율적인 질의-문서 매칭이 필요함 - 기존의 BERT cross-attention 기반 방식은 정확하지만 속도가 느려 실용적이지 않음 - Retrieval 단계는 여전히 sparse 기반 BM25에 의존함 - Embedding 기반 Two-tower 모델은 효율적이지만, 효과적인 pre-training task가 부재 |
| 연구 목표 (Objective) | - 대규모 검색에 적합한 Transformer 기반 임베딩 모델을 만들기 위해 paragraph-level 사전학습 과제(pretraining task)를 정의하고 비교 - 기존 BM25보다 더 높은 Recall과 효율을 달성하는 retrieval 모델 개발 |
| 방법론 (Method) | 🔸 Retrieval 모델 구조: Two-tower Transformer - φ(q): query encoder / ψ(d): doc encoder - score = ⟨φ(q), ψ(d)⟩ (inner product) 🔸 학습 방식: - positive (q, d) 쌍 기반 cross-entropy loss - Sampled Softmax로 negative 샘플 처리 🔸 Pre-training Task 3종 제안: 1. ICT (Inverse Cloze Task): 문장-문단 관계 2. BFS (Body First Selection): 문서 요약부 ↔ 본문 관계 3. WLP (Wiki Link Prediction): 하이퍼링크 기반 문서 간 관계 + 기존 MLM과 비교 실험 🔸 Final: ICT+BFS+WLP 조합으로 pretraining 후 downstream QA fine-tuning |
| 실험 (Experiment) | 🔸 Benchmarks: - SQuAD, Natural Questions (sentence-level retrieval) - Open-domain QA: Wikipedia 1M 문서 추가 🔸 모델 비교: - BM25 (sparse baseline) - BoW-MLP (shallow embedding) - Transformer (with / without pretraining) 🔸 실험 구성: - Fine-tuning split: 1%, 5%, 80% - Metric: Recall@k (k = 1, 5, 10, 50, 100) |
| 결과 (Result) | ✅ Transformer+ICT+BFS+WLP는 모든 조건에서 BM25보다 우수 ✅ MLM은 효과 미미, paragraph-level task가 핵심 ✅ 특히 low-resource 조건 (1%, 5%)에서 pretraining의 효과 큼 ✅ Ablation: ICT > BFS > WLP (task 개별 성능), 조합이 최고 ✅ Open-domain 1M 문서 실험에서도 BM25 대비 크게 향상 |
| 기여 (Contribution) | 🔹 처음으로 paragraph-level pretraining task를 체계적으로 비교 🔹 ICT, BFS, WLP라는 retrieval에 특화된 사전학습 과제 제안 🔹 MLM이 retrieval에 부적합함을 실증적으로 증명 🔹 BM25를 대체 가능한 효율적이고 강력한 retrieval 모델 설계 |
| 한계 (Limitation) | ⚠️ 사전학습 데이터가 Wikipedia에 한정됨 (다른 도메인 일반화 미확인) ⚠️ 실험은 sentence-level QA에 집중, full passage-level이나 multi-hop QA는 미포함 ⚠️ Inference에서 ANN 등의 서브리니어 검색 기법의 정확도 변화는 직접적으로 다루지 않음 |
https://arxiv.org/abs/2004.04906
Dense Passage Retrieval for Open-Domain Question Answering
Open-domain question answering relies on efficient passage retrieval to select candidate contexts, where traditional sparse vector space models, such as TF-IDF or BM25, are the de facto method. In this work, we show that retrieval can be practically implem
arxiv.org
| 문제 상황 | Open-domain QA에서는 수백만 개의 문서에서 질문에 답할 수 있는 문서를 빠르고 정확하게 찾는 것이 핵심. 기존 BM25 같은 sparse retriever는 단어 기반이라 동의어/의미 유사성을 잘 반영하지 못해 retrieval 실패 → QA 성능 저하 초래. Dense retrieval은 잠재 의미 공간에서 유사성을 잘 포착하지만, 기존에는 복잡한 pretraining, joint learning이 필요해 적용이 어려웠음. |
| 제안 방법 (DPR) | Dense vector 기반의 dual encoder 모델. – 질문 인코더 EQ(q)와 문서 인코더 EP(p)를 독립적으로 BERT 기반으로 구성 – sim(q, p) = dot(EQ(q), EP(p)) – 학습은 question–positive passage pair만 사용하며, + in-batch negatives + BM25 hard negatives 조합으로 contrastive loss 최적화 – 문서 벡터는 사전 계산 및 FAISS index 구성, 질문만 실시간 인코딩하여 검색 |
| 실험 설정 | – 전체 문서: Wikipedia 21M passage (100단어 블록, title 포함) – QA 데이터셋: NQ, TriviaQA, WebQuestions, TREC, SQuAD – 훈련: batch size 128, BERT-base, 40 epoch, Adam optimizer, dropout 0.1 – 하이브리드 실험: BM25 점수 + DPR 점수 조합도 수행 (BM25+DPR) |
| 결과 (Retrieval) | ✅ BM25 대비 Top-20 기준 +9~19%p 향상 – NQ: 59.1 → 78.4 – TriviaQA: 66.9 → 79.4 – WebQ: 55.0 → 73.2 – TREC: 70.9 → 79.8 → SQuAD만은 예외 (BM25가 더 강함, 이유는 질문-문서 간 단어 중복 때문) |
| 결과 (End-to-End QA) | ✅ 정확도(Exact Match 기준)에서도 기존 ORQA 대비 SOTA 달성 – NQ: ORQA 33.3 → DPR 41.5 – TriviaQA: ORQA 45.0 → DPR 56.8 – WebQ/TREC도 multi-dataset 학습 시 성능 우수 – SQuAD 제외하고 대부분에서 기존 방법 대비 향상 |
| 기여 | ① Pretraining 없이 QA pair만으로 dense retriever 훈련 가능함을 실증 ② 기존 BM25보다 retrieval 및 QA 성능 모두 우수 ③ Dual encoder 구조만으로도 높은 효율성과 성능 달성 가능 ④ QA 데이터만으로 학습한 모델이 다른 도메인에도 generalization 가능 ⑤ Dense vector 기반이지만 FAISS로 실시간 검색 가능 (995 qps) |
| 한계 및 논의 | – FAISS index 구축 시간 및 문서 벡터 embedding 연산 비용 높음 (약 17시간) – passage retrieval precision은 높지만, salient rare phrase에는 약할 수 있음 (e.g., named entities) – SQuAD와 같은 좁은 도메인/높은 단어 중복 데이터에선 BM25가 더 나을 수 있음 – 문장 내부 구조나 multi-hop reasoning은 반영하지 않음 |
https://arxiv.org/abs/2004.12832
ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT
Recent progress in Natural Language Understanding (NLU) is driving fast-paced advances in Information Retrieval (IR), largely owed to fine-tuning deep language models (LMs) for document ranking. While remarkably effective, the ranking models based on these
arxiv.org


| 문제 상황 (Problem) | - BERT 기반 랭킹 모델은 정확도는 높지만, 쿼리–문서 쌍마다 BERT를 통과시켜야 해 계산량이 매우 큼 - 실시간 검색에서 지연(latency) 과 FLOPs 부담이 심각함 |
| 기존 한계 (Limitations) | - Dense Retriever는 query-doc 쌍을 각각 한 벡터로만 표현하여 세밀한 매칭 부족 - Interaction 모델(BERT cross encoder)은 매 쿼리마다 모든 문서를 인코딩해야 하므로 비효율적 |
| 제안 방법 (Method) | ✅ Late Interaction 기반 ColBERT 구조 제안 → 쿼리와 문서를 각각 BERT로 인코딩 (token-level) → 각 쿼리 토큰과 문서 토큰의 MaxSim 연산을 통해 relevance 계산 → 문서 임베딩은 오프라인 인코딩하여 저장 가능 |
| 구조 상세 (Architecture) | - f_Q(q) → 쿼리 token embeddings (L2 normalized) - f_D(d) → 문서 token embeddings (filtered + normalized) - Score(q, d) = Σᵢ maxⱼ cos(qᵢ, dⱼ) (MaxSim + sum) - 학습: pairwise softmax loss on triplets (q, d+, d−) |
| 실험 데이터셋 (Dataset) | 📚 MS MARCO Passage Ranking (8.8M 문서) 📚 TREC CAR (위키 기반 복잡 질의) → re-ranking 및 full retrieval 모두 평가 |
| 결과 요약 (Results) | - Re-ranking (top-1000 BM25): MRR@10 = 34.9 (BERT-base 수준) Latency = 61ms (BERT 대비 170× 빠름) - End-to-End Retrieval (전체 8.8M): MRR@10 = 36.0 Recall@1000 = 96.8% |
| 기여 (Contributions) | ⭐️ Late Interaction 구조 제안으로 fine-grained matching + 효율성 확보 ⭐️ 문서 임베딩 오프라인 처리로 실시간 대응 가능 ⭐️ Re-ranking뿐 아니라 full retrieval까지 적용 가능 ⭐️ MaxSim 연산은 pruning-friendly 하여 FAISS 등 vector index 활용 가능 |
| 한계점 (Limitations) | ❗ 문서 임베딩 저장 공간(수십 GB) 필요 ❗ MaxSim 연산을 위한 document vector loading 및 GPU transfer 비용 존재 ❗ 쿼리 토큰 수에 따라 계산량 증가 (비례적) |
| 활용 포인트 (Applications) | - Token-level semantic matching이 필요한 QA, IR 시스템 - 빠르면서도 정확한 retrieval-backend를 구성하고자 할 때 - End-to-end dense retriever가 필요한 경우: ColBERT + FAISS |
| 후속 연구 방향 (Ideas) | - Query augmentation 방식 다양화 - Embedding 차원 축소 or quantization (ex. 24 dim, 2 byte → 27 GiB) - Adapter/LoRA 등으로 경량화 BERT와 결합 |
https://arxiv.org/abs/2007.00808
Approximate Nearest Neighbor Negative Contrastive Learning for Dense Text Retrieval
Conducting text retrieval in a dense learned representation space has many intriguing advantages over sparse retrieval. Yet the effectiveness of dense retrieval (DR) often requires combination with sparse retrieval. In this paper, we identify that the main
arxiv.org

| 문제 상황 | - Dense Retriever(DR)는 embedding 기반으로 효율적이지만, 성능이 BM25 같은 sparse retriever보다 낮은 경우가 많음 - 그 이유는 in-batch negative가 대부분 informative하지 않아 gradient norm이 작고, 학습 수렴이 느리며 generalization도 약하기 때문 |
| 기존 방식 한계 | - Random negative, BM25 top-k negative, in-batch negative 등은 실제 테스트 시 분포(D⁻*)와 차이가 큼 - 특히 in-batch는 informative한 negative가 거의 포함되지 않음 (P ≈ 0) - Gradient norm도 작아 수렴 속도 저하 |
| 제안 방법 (ANCE) | Approximate Nearest Neighbor Contrastive Estimation → 학습 중인 모델로 전체 corpus를 ANN 탐색하여 Hard Negative를 구성 → Negative를 global하게 선정하여 학습 시 실제 D⁻와 분포 일치 → ANN Index는 비동기적으로 최신 모델로 갱신하여 학습 효율 유지 |
| 학습 구조 | - BERT-Siamese 구조 (query/doc encoder 공유) - Dot-product similarity - Loss: Negative Log-Likelihood (NLL) - ANN index는 Faiss 사용, 10k step마다 인덱스 갱신 - Positive당 Hard Negative 1개 sampling (top 200 ANN 중) |
| 학습 데이터 | - TREC DL 2019 (문서/패시지 검색, MS MARCO 기반) - Natural Questions (NQ), TriviaQA (TQA) for OpenQA - MS MARCO Passage labels (warm-up) - 상용 검색 시스템에서 실제 대규모 corpus (250M ~ 8B scale) 사용 |
| 실험 설정 | - RoBERTa-base fine-tuning - FirstP (문서 앞 512토큰), MaxP (최대 4개의 512 패시지 후 MaxPool) - Optimizer: LAMB, LR: 1e-6~5e-6 - Batch size 8, Accumulation 2, GPU 4개 (Trainer:Inferencer = 1:1) |
| 실험 결과 | ✅ TREC DL (Document NDCG@10): BM25: 0.549 → ANCE(MaxP): 0.628 ✅ OpenQA (Top-20/100 Passage): DPR: 78.4/85.4 → ANCE: 81.9/87.5 ✅ 상용 시스템 개선률: +15~18% |
| 이론적 분석 기여 | - In-batch negative는 gradient가 작아 variance는 크고 수렴 속도는 느림 - Gradient norm ∝ training 효과 → Hard Negative sampling이 중요 - ANCE는 gradient norm이 큰 sample을 효과적으로 구성함으로써 oracle importance sampling을 근사 |
| 실험적 기여 | - DR 성능을 sparse reranker 수준까지 끌어올림 (BERT-reranker와 근접) - ANN을 활용하여 효율성 (100배 빠름) + 성능 동시 확보 - 실제 상용 환경에도 성공적으로 적용 |
| 한계 및 향후 과제 | - ANN index를 주기적으로 업데이트해야 하므로 inference 비용 존재 - DR과 sparse retriever 간 overlap 적음 → TREC style 평가에서 hole rate 존재 - domain knowledge 부족 시 오탐 가능 (예: "active margin") - Query term miss match 상황에서 여전히 약함 |
https://arxiv.org/abs/2106.07345
Self-Guided Contrastive Learning for BERT Sentence Representations
Although BERT and its variants have reshaped the NLP landscape, it still remains unclear how best to derive sentence embeddings from such pre-trained Transformers. In this work, we propose a contrastive learning method that utilizes self-guidance for impro
arxiv.org

| 🔍 문제 상황 | - BERT의 [CLS] 벡터를 그대로 문장 임베딩으로 사용할 경우 성능이 매우 낮음 - Supervised fine-tuning 없이 robust하고 효과적인 sentence embedding 방법이 부족함 - 기존 contrastive learning 방식들은 데이터 증강(예: back-translation) 또는 라벨/도메인 정보에 의존함 |
| 🎯 연구 목표 | - Unsupervised 방식으로 [CLS] 벡터를 고품질 sentence representation으로 개선 - 데이터 증강 없이, 내부 표현을 활용한 효율적 contrastive 학습 프레임워크 제안 |
| 🧠 핵심 방법론 (SG / SG-OPT) |
✅ Self-guided contrastive learning (SG) - 동일 문장의 다른 layer hidden vector와 [CLS] 벡터 간을 positive pair로 활용 - BERT를 두 개로 복제: BERT<sub>F</sub> (fixed), BERT<sub>T</sub> (trainable) - [CLS] 벡터 c_i ↔ 내부 표현 h_{i,k} 간 cosine 유사도를 높이며 contrastive 학습 수행 ✅ SG-OPT (최적화 버전) - 기존 NT-Xent loss에서 불필요한 항 제거 ∙ 만 집중, , 등 제거 - 다양한 layer의 hidden state로부터 얻은 view를 통해 multi-positive 학습 |
| 🧪 학습 데이터 | - 라벨 없이, STS-B 데이터의 문장들만 사용 (문장 쌍 유사도 레이블 제거) - Multilingual 실험에서는 MBERT를 영어 문장으로 fine-tuning 후 Spanish, Arabic, English test 수행 (zero-shot transfer) - SentEval에서는 SNLI + MNLI 문장을 사용 |
| ⚙️ 실험 설정 | - Encoder: BERT-base, BERT-large, RoBERTa, SBERT - 벤치마크: ∙ STS-B, STS12–STS16, SICK-R (STS 벤치마크) ∙ SemEval-2014/2017 (Spanish/Arabic) (Multilingual STS) ∙ SentEval (MR, CR, SST2, TREC 등 분류 태스크) - 평가 지표: Spearman / Pearson correlation, SentEval accuracy |
| 📊 주요 결과 | - STS-B 기준, BERT-base [CLS]: 기존 20.30 → SG-OPT로 77.23 (56.9pt 향상) - 모든 STS task에서 기존 방식들 대비 최고 성능 달성 - Back-translation 방식보다 성능과 효율 모두 우수 - Multilingual zero-shot 평가에서도 우수 성능 (Spanish 82.74, Arabic 58.52) - SentEval에서도 mean pooling, WK pooling 대비 높은 정확도 달성 |
| ⚡ 효율성 | - 추론 시 별도 pooling 불필요 (그대로 [CLS] 벡터 사용) - SG-OPT inference time: 10.5초 (가장 빠름) - Flow 방식 등은 post-processing 필요, 느림 |
| 🔍 분석 | - Ablation 실험 통해 SG-OPT 구성의 타당성 검증 (NT-Xent 구조 변화 + projection head 사용이 핵심) - Domain shift (NLI 학습 → STS 평가) 실험에서도 성능 하락폭 가장 적음 (SG-OPT: -1.6, Flow: -4.2 ~ -12.1) - t-SNE 시각화로 embedding 품질 향상 확인 |
| 🧬 기여 | - 데이터 증강 불필요한 contrastive learning 방식 제안 - [CLS] 임베딩 자체의 성능을 회복시켜 효율적인 문장 표현 가능 - 다양한 layer를 self-guided signal로 활용한 contrastive 학습 프레임워크 제시 - multilingual zero-shot 및 SentEval 등에서도 일반화 능력 확인 |
| ⚠️ 한계 및 향후 방향 | - 모든 layer를 동일하게 sampling하는 단순 접근: task-specific 조정 여지 있음 - pooling 방식, layer 선택 등 적응형 구성 요소 최적화는 future work - back-translation과 hybrid 구조 시 더 높은 성능 달성 가능성 있음 |
https://arxiv.org/abs/2112.09118
Unsupervised Dense Information Retrieval with Contrastive Learning
Recently, information retrieval has seen the emergence of dense retrievers, using neural networks, as an alternative to classical sparse methods based on term-frequency. These models have obtained state-of-the-art results on datasets and tasks where large
arxiv.org
| 🔍 문제 상황 | - Dense retriever는 supervised 학습에서는 강력하지만, zero-shot/unsupervised 환경에서는 BM25보다 성능이 낮음 - 특히 도메인 이동(domain shift), 다국어(multi-lingual) 환경에서 일반화 어려움 - 기존 unsupervised pretraining 방식(예: ICT)은 성능 한계 존재 |
| 💡 방법론 (Contriever) | ❶ Bi-encoder 구조 (BERT base) ❷ Random Cropping 기반 contrastive learning (MoCo 적용) • Query와 Document는 같은 문서에서 랜덤하게 두 span 추출 • Positive pair는 같은 문서, Negative는 queue에서 샘플링 • InfoNCE Loss 사용 (dot product 유사도) ❸ Pretraining 데이터: Wikipedia + CCNet (50:50) ❹ 학습 안정성 향상: token deletion (10%) 등 data augmentation 적용 |
| 🧪 실험 설정 | • Datasets: BEIR (15개 도메인), NQ, TriviaQA, Mr.TyDi, MKQA • 평가 지표: Recall@100 (ML 시스템용), nDCG@10 (ranking 품질) • 비교 모델: BM25, ICT, REALM, SimCSE, DPR, ANCE, TAS-B, ColBERT 등 • 추가 실험: few-shot setting, multilingual/cross-lingual retrieval, ablation |
| 📈 주요 결과 | ✅ Zero-shot 성능: • BEIR 15개 중 11개에서 BM25보다 Recall@100 성능 우위 • NQ/TriviaQA에서도 ICT, BM25보다 높은 성능 ✅ Few-shot 학습: • 729~5,500 쿼리에서도 BM25, BERT 대비 nDCG@10 우수 ✅ Cross-lingual Retrieval: • mContriever는 MS MARCO(영어) fine-tuning만으로 타언어 질의 대응 가능 |
| 🧠 기여 | - Unsupervised 방식으로도 BM25를 뛰어넘는 Dense Retriever 제안 - Random Crop + MoCo 구조가 ICT보다 효과적임을 실험으로 입증 - Multilingual, Cross-lingual 환경에서도 높은 성능 유지 - 간단한 학습 방식으로 MS MARCO fine-tuning에도 강력함 |
| ⚠️ 한계 | - TREC-COVID, Touche-2020처럼 도메인 불일치 (시계열, 긴 문서)에선 BM25에 비해 낮은 성능 - 학습된 시점 이후 등장한 주제(예: 코로나)에 대해 학습 데이터 부족 - nDCG@10 기준 상위 문서 ranking에서는 여전히 BM25가 더 우수한 경우 존재 |
https://arxiv.org/abs/2205.12035
RetroMAE: Pre-Training Retrieval-oriented Language Models Via Masked Auto-Encoder
Despite pre-training's progress in many important NLP tasks, it remains to explore effective pre-training strategies for dense retrieval. In this paper, we propose RetroMAE, a new retrieval oriented pre-training paradigm based on Masked Auto-Encoder (MAE).
arxiv.org

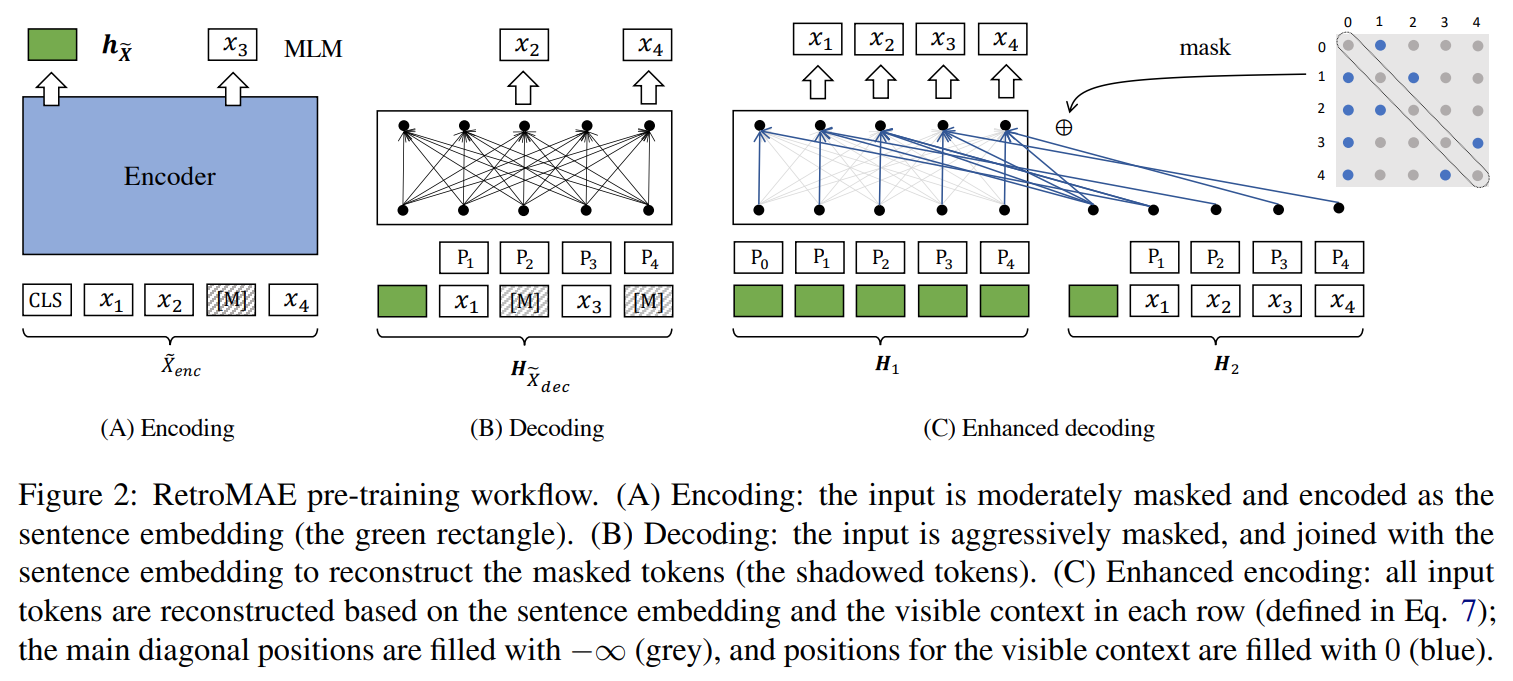
| 🔍 문제 상황 | 기존 BERT/RoBERTa 등 token-level pretraining 방식은 문장 수준 표현력(sentence-level embedding)이 부족하여 dense retrieval 성능이 제한됨. Contrastive 학습 기반 방법들은 augmentation 품질과 negative sampling 수에 의존. |
| 💡 핵심 아이디어 (방법론) | Masked Auto-Encoding 기반의 retrieval 전용 사전학습 구조: ① Encoder는 적당히 마스킹된 문장을 통해 문장 임베딩 생성 ② Decoder는 심하게 마스킹된 문장과 encoder의 문장 임베딩을 입력으로 받아 원문 복원 학습 ③ 모든 복원이 문장 임베딩에 의존하도록 설계하여 encoder의 표현력 강화 ④ Enhanced Decoding: 각 토큰을 고유한 context로 복원하도록 mask matrix 조절 |
| ⚙️ 모델 구조 | - Encoder: BERT-base (12-layer, 768-dim) - Decoder: 1-layer Transformer - Asymmetric Masking: • Encoder: 15 ~ 30% • Decoder: 50 ~ 70% (복원 난이도 높임) |
| 🧪 학습 데이터 | - Wikipedia - BookCorpus - MS MARCO (in-domain pretraining 용도) |
| 🧪 평가 데이터셋 | - Zero-shot: BEIR benchmark (18개 retrieval task: QA, Fact checking, Bio 등) - Supervised: MS MARCO, Natural Questions |
| 🧪 실험 설정 | - BEIR: zero-shot transfer 성능 측정 (MS MARCO로 finetune 후 전이) - MS MARCO/NQ: DPR 및 ANCE 기반 supervised fine-tuning - baseline: BERT, RoBERTa, DeBERTa, SimCSE, Condenser, SEED 등과 비교 |
| 📈 주요 결과 | ✅ Zero-shot (BEIR 평균 NDCG@10): - RetroMAE: 0.452 (기존 최고 대비 +4.5%p 향상) ✅ Supervised (MS MARCO, MRR@10): - DPR 기준: 0.3553 - ANCE 기준: 0.3822 (Condenser 대비 +1.8%p) ✅ Knowledge distillation 후 SOTA 달성: - MRR@10: 0.416 (ERNIE-Search, ColBERTv2 상회) |
| 🔍 Ablation 결과 요약 | - Enhanced Decoding 사용 시 성능 명확히 향상됨 - Decoder는 1-layer가 best - Decoder Masking 0.5, Encoder Masking 0.3이 가장 우수 |
| 🌟 기여 | - 문장 임베딩에 기반한 고품질 복원을 강제하는 pretraining 구조 제안 - Self-contrastive 학습 없이도 SOTA 성능 확보 - 간단한 구조 (1-layer decoder)로 효율적 구현 가능 |
| ⚠️ 한계 | - 실험은 BERT-base scale에 한정됨 - Pretraining 데이터량 제한적 (대규모 실험 미수행) - 확장성 (더 큰 모델, 더 큰 데이터)에 대한 검증 부족 |
https://aclanthology.org/2021.repl4nlp-1.17/
In-Batch Negatives for Knowledge Distillation with Tightly-Coupled Teachers for Dense Retrieval
Sheng-Chieh Lin, Jheng-Hong Yang, Jimmy Lin. Proceedings of the 6th Workshop on Representation Learning for NLP (RepL4NLP-2021). 2021.
aclanthology.org

| 문제 상황 | - 단일 벡터 Bi-Encoder는 효율적이지만 쿼리–문서 간 rich interaction 부족으로 성능이 낮음 - Cross-Encoder 기반 KD는 효과적이나 계산 비용이 매우 큼 - Hard Negative를 잘 쓰려면 자원이 많이 드는 비동기 인덱스 리프레시가 필요함 |
| 목표 | - 효율성과 성능을 모두 만족하는 Dense Retriever 학습 방법 제안 - 적은 계산 비용으로 정교한 표현을 학습하는 In-Batch Knowledge Distillation 방식 개발 |
| 방법론 | ✅ TCT-ColBERT 구조 제안 - Teacher: ColBERT (multi-vector, MaxSim) - Student: 단일 벡터 Bi-Encoder (AvgPool) ✅ In-Batch Knowledge Distillation - 동일 배치 내 모든 쿼리–문서 조합에 대해 teacher의 soft label 분포 (softmax over MaxSim) 학습 - KL divergence로 student가 분포를 모방하도록 학습 ✅ Hard Negative 활용 전략 1. HN: Hard Negative만 사용 (Teacher 없이) 2. TCT HN: Hard Negative + In-Batch KD 3. TCT HN+: Hard Negative로 teacher도 fine-tune 후 student에 distill |
| 학습 데이터 | 📚 MS MARCO - Passage ranking: 8.8M passages, 약 50만 (query, passage) 쌍 - Document ranking: 3.2M 웹 문서 - 평가셋: MS MARCO Dev, TREC-DL 2019 |
| 학습법 | 🔧 Warm-up 단계: BM25 negative로 ColBERT teacher 학습 🔧 KD 학습 단계: 동일 teacher로 In-Batch KD 수행 (τ=0.25, KL loss) 🔧 Hard Negative 단계: - ColBERT로 전체 코퍼스 인코딩 - Top-200에서 Hard Negative 샘플링 - 다시 teacher–student KD 수행 (TCT HN or TCT HN+) 💡 학습 세부 - 모델: BERT-base - batch size=96 (Doc는 64) - lr=7e-6, step=500K (BM25), 100K (HN) - Token 길이: query 32, passage 150 |
| 실험 구성 | - Passage Retrieval: MS MARCO Dev / TREC-DL’19 평가 - Document Retrieval: MS MARCO 문서 / TREC-DL’19 - Dense–Sparse Hybrid: BM25, doc2query-T5와 결합하여 효율–성능 비교 |
| 결과 요약 | ✅ Passage Retrieval (TCT-ColBERT) - MRR@10 = 0.344 → TCT HN+ = 0.359 - NDCG@10 = 0.685 → TCT HN+ = 0.719 - Recall@1K = 0.967 → TCT HN+ = 0.970 ✅ Document Retrieval - MRR@100 = 0.339 → TCT HN+ = 0.392 - NDCG@10 = 0.573 → TCT HN+ = 0.613 ✅ Hybrid (TCT-ColBERT + doc2query-T5) - MRR@10 = 0.375, NDCG@10 = 0.741 → BM25 + BERT reranker 수준 달성하면서 훨씬 빠름 (110ms vs 3500ms) |
| 기여 (Contributions) | - In-Batch KD 방식 제안: batch 내 모든 q–d 조합을 활용하여 rich한 학습 - Teacher로 ColBERT 사용: 연산 효율성과 표현력 균형 확보 - Hard Negative + KD 결합 전략 제시: 추가 index refresh 없이 성능 향상 - 실용적인 단일 벡터 Retriever 설계: 성능/속도/저장 효율 균형 달성 |
| 한계 (Limitations) | - 최종 성능은 RocketQA(reranker 포함)보다 낮음 - ColBERT 기반 teacher 학습 과정이 여전히 추가 학습 필요 - TCT HN+는 teacher 추가 fine-tune이 필요하므로 학습 파이프라인이 복잡해질 수 있음 |
https://arxiv.org/abs/2304.14233
Large Language Models are Strong Zero-Shot Retriever
In this work, we propose a simple method that applies a large language model (LLM) to large-scale retrieval in zero-shot scenarios. Our method, the Language language model as Retriever (LameR), is built upon no other neural models but an LLM, while breakin
arxiv.org
이건 너무 비효율적 아닌가 생각이 들어서,..

| 문제 상황 | - 기존 zero-shot dense retriever (e.g., Contriever)는 성능이 낮고 BM25보다도 못함 - LLM을 이용한 query augmentation (예: HyDE)도 self-supervised retriever의 성능 bottleneck 때문에 한계 존재 - LLM이 intent-모호하고 domain-unaware한 답변을 생성할 위험 있음 |
| 방법론: LameR | 🧠 LLM + BM25만으로 구성된 Zero-shot Retrieval Framework 1️⃣ Query 를 BM25에 입력 → Top-k candidates C^q 추출 2️⃣ q + C^q를 QA prompt로 LLM에 입력 → 정답 문장 A^q 생성 3️⃣ Augmented Query qˉ = q + A^q생성 4️⃣ qˉ를 BM25에 입력하여 최종 문서 검색 |
| 학습 방식 | - 완전 Zero-shot: Query-document annotation 사용하지 않음 - Self-supervised retriever도 사용하지 않음 - 모든 구성요소는 고정된 BM25 + LLM inference만으로 구성됨 |
| 사용 데이터 | - 평가만 공개 데이터 사용 ① MS MARCO: DL19, DL20 ② BEIR (Low-resource): SciFact, FiQA, TREC-COVID, TREC-NEWS, ArguAna, DBPedia |
| 실험 결과 | ✅ DL19 (nDCG@10): - BM25: 50.6 → HyDE: 61.3 → LameR: 69.1 ✅ DL20 (nDCG@10): - BM25: 48.0 → HyDE: 57.9 → LameR: 64.8 ✅ BEIR 일부 task 최고 성능 (TREC-COVID, TREC-NEWS) ✅ GPT-4 사용 시 DL20 nDCG@10 = 65.9 |
| Ablation 분석 | - Demo passage 수 10개, answer 생성 수 5개가 최적 - Hard negative 포함 시 성능 하락 가능 - Gold demo passage 사용 시 성능 상한 84.0까지 도달 가능 |
| 효율성 분석 | - BM25 사용으로 retrieval latency 빠르고 index size 작음 - HyDE 대비 속도 ↑, 비용 ↓ - LLM inference 비용만 고려 필요 (미래에는 경량 LLM 대체 가능성 제시) |
| 기여 | ✅ Self-supervised retriever 없이도 최고 성능 달성 ✅ LLM의 능력을 QA generation이 아닌 retrieval에 직접 활용 ✅ 모든 연산이 자연어 기반이라 end-to-end 해석 가능 ✅ dense retriever보다 효율적이며 더 강한 성능을 보임 |
| 한계 | ❗ LLM prompt에 민감함 → instruction tuning 필요 ❗ LLM inference 비용 큼 (GPT-3.5/4) ❗ 긴 문서 (e.g., ArguAna) 처리에 약함 (128 token truncation) ❗ LLM이 생성한 query에 오류 포함될 경우 2단계 retrieval 오염 가능 |