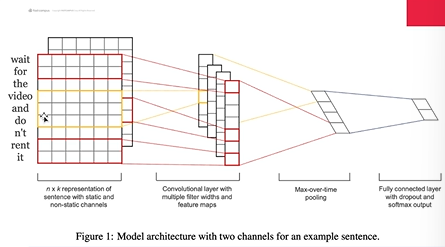
자연어 처리 -CNN을 사용한 실습, self- attention 실습
import matplotlib.pyplot as plt plt.rc('font', family='NanumBarunGothic') from google.colab import drive drive.mount('/content/drive') base_path = "./drive/MyDrive/fastcampus/practice" import pandas as pd df = pd.read_csv(f"{base_path}/data/nsmc/ratings_train.txt", sep='\t') # pos, neg 비율 df['label'].value_counts() # missing doc sum(df['document'].isnull()) df = df[~df['document'].isnull()] sum(..