https://arxiv.org/abs/2212.04088
LLM-Planner: Few-Shot Grounded Planning for Embodied Agents with Large Language Models
This study focuses on using large language models (LLMs) as a planner for embodied agents that can follow natural language instructions to complete complex tasks in a visually-perceived environment. The high data cost and poor sample efficiency of existing
arxiv.org
https://dki-lab.github.io/LLM-Planner/
LLM-Planner: Few-Shot Grounded Planning with Large Language Models
The prompt includes an explanation of the task, a list of possible high-level actions, 9 in-context examples selected by the kNN retriever from 100 training examples, and a current test example. For dynamic grounded re-planning, we add the subgoals that ha
dki-lab.github.io
이 논문은 22년도에 나온 논문으로 굉장히 초창기 논문입니다.
Prompt를 통해 Few-shot으로 SFT모델을 이길 수 있음을 보여줍니다.
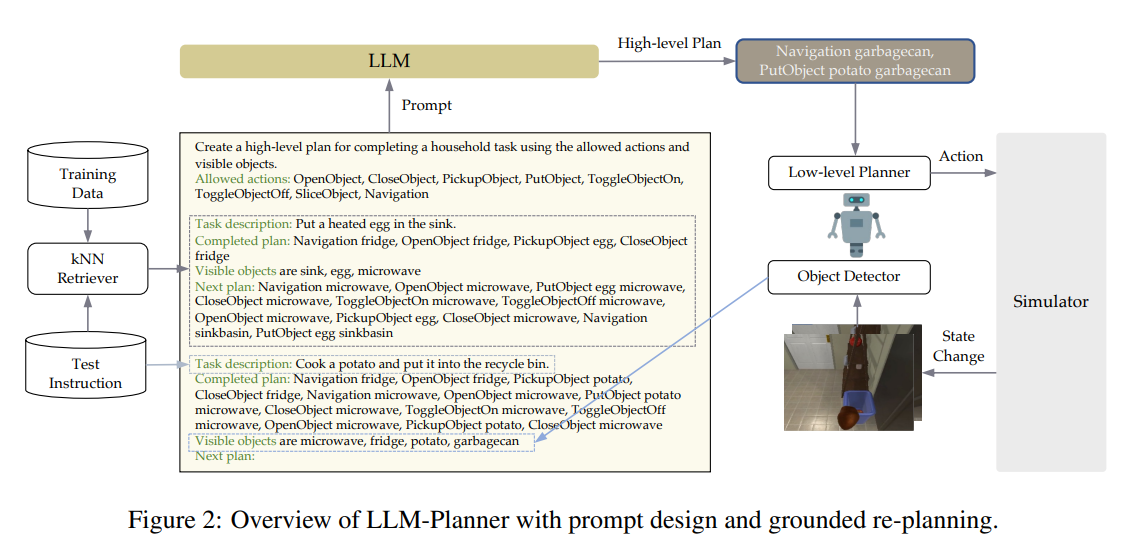
사진을 보면 알 수 있듯 Retriever을 통해 가장 근접한 Few-shot을 찾아 효과적으로 Few-Shot을 사용할 수 있도록 전달해줍니다.
또한 동적으로 계획을 수정하며 환경 변화에 좀 더 잘 적응하기도 합니다.

기존의 Full SFT 방식은 많은 데이터를 필요로 하기에 이러한 단점을 없애 버린 LLM-Planner은 적은 데이터 만으로도 준수한 성적을 가지고 간다.
그리고 동적 Planning과정이 꼭 필요한 것을 볼 수 있다.

Ablation Studty를 통해 각 과정이 모두 필요한 것을 볼 수 있다.
| 연구 목표 | - 대형 언어 모델(LLM)을 활용하여 최소한의 학습 데이터로도 실체화된 에이전트(Embodied Agent)가 플래닝을 수행할 수 있도록 함. - 환경 변화에 대응하는 동적 재계획(Grounded Re-Planning) 기능을 추가하여 기존 플래너의 한계를 극복. |
| 문제 정의 | - 기존 AI 플래너는 대량의 레이블링된 학습 데이터가 필요하여 확장성이 낮음. - 대부분의 방법이 정적 플래닝(Static Planning)만 가능하여, 환경 변화에 대응하지 못함. - Few-Shot 학습으로 다양한 작업을 수행할 수 있는 플래너가 필요. |
| 핵심 기여 | 1. Few-Shot 학습이 가능한 플래너 개발 → 100개 미만의 학습 데이터로도 효과적인 플래닝 가능. 2. 계층적 플래닝(Hierarchical Planning) 구조 활용 → 고수준(High-Level)과 저수준(Low-Level) 플래닝을 분리하여 효율성 증가. 3. 환경 정보를 반영한 동적 재계획(Grounded Re-Planning) → 에이전트가 실행 도중 실패할 경우 실시간으로 계획을 업데이트 가능. 4. 기존 모델 대비 적은 LLM 호출 횟수로 효율적 플래닝 가능. |
| 사용한 방법론 | 1. 계층적 플래닝 (Hierarchical Planning) - 고수준 계획(HLP): LLM이 자연어 명령을 받아 하위 목표(Subgoal) 리스트를 생성. - 저수준 계획(LLP): 생성된 하위 목표를 실제 실행 가능한 원자적 행동(Primitive Action)으로 변환. 2. Few-Shot 학습 (In-Context Learning) - kNN 기반 검색으로 가장 적절한 예제 샘플을 선택하여 LLM에게 제공. - 소량의 데이터만으로 학습이 가능하도록 구성. 3. 동적 재계획 (Grounded Re-Planning) - 에이전트가 특정 목표를 수행하는 도중 실패하면, 환경에서 인식된 객체 정보를 활용해 LLM이 실시간으로 플래닝을 수정. |
| 실험 데이터셋 | ALFRED 데이터셋 - 실내 환경에서 시각 및 언어를 활용한 장기 플래닝을 평가하기 위한 벤치마크 데이터셋. |
| 평가 지표 | 1. Success Rate (SR, %) - 주어진 작업을 완전히 성공한 비율. 2. Goal-Condition Success Rate (GC, %) - 목표 조건을 얼마나 정확하게 충족했는지 측정. 3. High-Level Planning Accuracy (HLP ACC, %) - 생성된 고수준 계획이 정답과 얼마나 일치하는지 평가. |
| 실험 결과 (Few-Shot 설정, 100개 학습 데이터 사용) | 1. 기존 모델 대비 경쟁력 있는 성능 달성 - HLSM, FILM과 같은 기존 모델은 100개 데이터로 학습할 경우 거의 작업 수행이 불가능했으나, LLM-Planner는 일정 수준 이상의 성능을 유지. - 전체 데이터를 학습한 HLSM과 비교해도 LLM-Planner는 경쟁력 있는 성능을 발휘. 2. 동적 재계획(Grounded Re-Planning)이 성능 향상에 기여 - 정적 플래닝보다 동적 플래닝을 사용할 경우 성능이 1.83% 향상. 3. SayCan과 비교 시 높은 효율성 - SayCan은 환경 내 가능한 모든 행동 리스트를 미리 알아야 하지만, LLM-Planner는 이를 필요로 하지 않음. - LLM 호출 횟수도 LLM-Planner(7회) < SayCan(22회)으로 더 적음. |
| LLM-Planner vs 기존 모델 비교 | |
| 연구 한계 | 1. 객체 탐지(Object Detection) 오류 발생 가능성 → 객체를 인식하지 못하면 플래닝이 실패할 가능성이 있음. 2. 장기 플래닝(Long-Horizon Tasks)에 대한 성능 저하 → 액션 수가 많아질수록 오류가 누적될 가능성이 있음. 3. LLM API 비용 문제 → LLM 호출 비용이 높은 모델(GPT-3 등)보다 가벼운 모델 사용이 필요. |
| 향후 연구 방향 | 1. Mixture of Experts (MoE) 기반 플래닝 연구 - 환경 및 작업 유형에 따라 적절한 LLM 전문가 모델을 선택하는 MoE 구조 적용. 2. 강화학습(RL)과 결합 - Few-Shot 학습을 강화학습과 결합하면 더 강력한 적응력을 가질 가능성 있음. 3. 다양한 LLM 비교 연구 - GPT-3뿐만 아니라 GPT-4, Claude, LLaMA, Mistral 등 다양한 모델과 비교 연구 진행 필요. 4. 객체 탐지 성능 향상 - YOLO, DETR 등 최신 객체 탐지 모델을 활용하여 정확도를 높이는 방향 검토. |
| 최종 결론 | LLM-Planner는 소량의 학습 데이터만으로도 효과적인 플래닝이 가능하며, 환경의 변화를 반영하여 동적으로 재계획할 수 있는 강력한 AI 플래너이다. |
1. 연구 배경 및 문제 정의
최근 로봇과 같은 실체화된 에이전트(Embodied Agents)가 자연어 명령을 이해하고 복잡한 작업을 수행하는 연구가 활발하다. 그러나 기존 방법들은 다음과 같은 한계를 가진다:
- 대량의 레이블링된 데이터(언어 지침-경로 쌍)가 필요하여 데이터 비용이 높고 확장성이 낮음.
- 샘플 효율성이 낮아 새로운 작업을 학습하는 속도가 느림.
- 기존의 LLM 기반 플래너는 단일 정적 계획을 생성하며 환경의 변화에 동적으로 대응하지 못함.
본 연구는 LLM-Planner를 제안하여 위 문제를 해결하고, 소수의 예시 데이터만으로도 효과적인 플래닝이 가능한 방법을 탐색한다.
2. 제안 방법: LLM-Planner
LLM-Planner는 대형 언어 모델(LLM)을 활용한 소수 예제(Few-shot) 기반의 플래닝 시스템으로, 환경의 변화에 따라 동적으로 계획을 수정할 수 있도록 설계되었다. 핵심 아이디어는 다음과 같다:
- 계층적 계획 (Hierarchical Planning)
- 고수준 계획(High-Level Planning, HLP): LLM을 활용하여 "하위 목표(예: 감자를 전자레인지에 넣기)" 시퀀스를 생성.
- 저수준 계획(Low-Level Planning, LLP): 하위 목표를 실제 환경에서 실행 가능한 원자적 액션(예: 이동, 집기 등)으로 변환.
- Few-Shot 학습을 활용한 플래닝
- 기존 접근법은 대량의 레이블링된 데이터를 필요로 하지만, LLM-Planner는 소수의 예시만으로도 효과적인 계획을 생성.
- K-최근접 이웃(kNN) 기반의 예제 검색을 활용하여 상황에 적절한 few-shot 학습을 수행.
- 환경 기반 동적 재계획 (Grounded Re-Planning)
- 에이전트가 특정 하위 목표를 달성하지 못할 경우(예: 감자를 찾을 수 없음) LLM에 새로운 환경 정보를 제공하고 계획을 수정.
- 객체 탐지(Object Detection) 정보를 활용하여 환경의 현재 상태를 기반으로 재계획을 수행.
- 예: 감자를 찾을 수 없을 경우, 냉장고가 보인다면 "냉장고 문을 열어 감자를 찾기"로 계획을 업데이트.
3. 실험 및 성능 평가
LLM-Planner는 ALFRED 데이터셋을 활용하여 평가되었다. 주요 실험 결과는 다음과 같다:
- 소수 데이터 학습에서도 경쟁력 있는 성능
- 전체 학습 데이터의 0.5%만 사용하면서도 기존 SOTA 모델(HLSM, FILM)과 비교해 유사한 성능을 보임.
- 기존 모델(HLSM, FILM)은 소수 데이터 학습 시 거의 작업을 수행하지 못하는 반면, LLM-Planner는 일정 수준의 성능 유지.
- 동적 재계획이 성능 향상에 기여
- 정적 계획(Static Planning) 대비 동적 재계획(Dynamic Re-Planning)을 추가하면 성공률이 1.83% 향상됨.
- SayCan과의 비교
- SayCan은 환경 내 "허용 가능한 행동 리스트"를 미리 알고 있어야 하지만, LLM-Planner는 이를 필요로 하지 않음.
- LLM-Planner는 적은 LLM 호출(평균 7회)로 플래닝이 가능하지만, SayCan은 평균 22회 호출이 필요하여 비효율적임.
- 작업 유형별 성능 분석
- “물체를 집어 특정 위치에 놓기”와 같은 단순한 작업에서는 높은 정확도를 보이지만, “물체를 요리한 후 특정 위치에 놓기”와 같은 복잡한 작업에서는 객체 탐지 오류로 인해 성능이 저하됨.
4. 결론 및 향후 연구 방향
LLM-Planner는 다음과 같은 기여점을 가진다:
- 대량의 학습 데이터를 필요로 하지 않는 샘플 효율적인 플래너를 개발.
- 환경 변화를 반영하여 동적으로 재계획이 가능한 플래닝 프레임워크 구축.
- 기존 SOTA 모델들과 경쟁력 있는 성능을 보이며, 적은 데이터로도 효과적인 학습 가능성 입증.
향후 연구 방향:
- 보다 강력한 객체 탐지 모델과 통합하여 환경 인식을 향상.
- 다양한 LLM(Codex 등)을 활용하여 성능 개선.
- 프롬프트 엔지니어링 최적화를 통해 플래닝 정확도를 더욱 향상.
연구 활용 방안 및 시사점
본 연구는 로봇, 자율 주행, AI 기반 작업 자동화 등 다양한 분야에 적용될 수 있다. 특히, 소수 데이터만으로도 높은 효율을 발휘할 수 있는 LLM 기반 플래너로서, 샘플 효율적인 학습이 필수적인 도메인에서 중요한 역할을 할 수 있다.
이 연구를 기반으로, 강건한 플래닝 시스템을 위한 Mixture of Experts(MoE) 기반 플래닝 구조를 고려할 수도 있을 것이다. MoE를 활용해 플래닝 성능을 더욱 최적화하는 연구를 진행하면 흥미로운 결과를 얻을 수 있을 것이다.
LLM-Planner는 대형 언어 모델(LLM)을 활용한 Few-Shot 기반 실체화 에이전트(Embodied Agent) 플래닝 기법으로, 환경의 물리적 정보를 고려하여 동적으로 계획을 수정할 수 있는 방식으로 설계되었다. 이를 보다 명확히 이해하기 위해 핵심 방법론을 세부적으로 분석하고, 구체적인 예시를 포함하여 설명하겠다.
1. 계층적 계획(Hierarchical Planning)
본 연구에서는 계층적 계획(Hierarchical Planning) 접근법을 사용하여 플래닝을 수행한다. 기존의 단순한 계획 접근법과 달리, LLM-Planner는 고수준 계획(High-Level Plan, HLP)과 저수준 계획(Low-Level Plan, LLP)을 분리하여 더욱 효과적인 의사결정을 수행한다.
1.1 고수준 계획(High-Level Planning, HLP)
- 역할: LLM을 사용하여 사용자의 언어 명령을 여러 개의 "하위 목표(Subgoal)"로 변환.
- 출력 형식: [고수준 행동, 객체] 쌍의 리스트
- 예시:
- 입력: "감자를 요리한 후 재활용통에 버려라"
- 출력: [(이동, 냉장고), (열기, 냉장고), (집기, 감자), (닫기, 냉장고), (이동, 전자레인지), (열기, 전자레인지), (놓기, 감자), (닫기, 전자레인지), (켜기, 전자레인지), (끄기, 전자레인지), (열기, 전자레인지), (집기, 감자), (닫기, 전자레인지), (이동, 재활용통), (놓기, 감자)]
- 즉, 고수준 목표를 달성하기 위한*구체적인 중간 단계(하위 목표)를 생성하는 과정.
1.2 저수준 계획(Low-Level Planning, LLP)
- 역할: HLP에서 생성된 하위 목표를 실제 실행 가능한 행동(Primitive Action)으로 변환.
- 출력 형식: 시뮬레이터가 실행할 수 있는 구체적 행동 시퀀스
- 예시:
- HLP 입력: (이동, 냉장고)
- LLP 출력: [앞으로 이동, 왼쪽으로 30도 회전, 앞으로 이동, 멈춤]
- 실제 환경에서 객체를 탐지하고 위치를 이동하는 단계를 포함함.
즉, LLM-Planner는 LLM을 활용하여 HLP를 생성한 후, 이를 LLP로 변환하는 방식으로 동작하며, 고수준 목표와 저수준 행동을 명확히 구분하여 플래닝 효율을 높인다.
2. Few-Shot 기반 학습과 플래닝
LLM-Planner는 소수의 학습 예시(Few-Shot Learning)를 활용하여 플래닝을 수행하는 점이 핵심 특징이다. 기존의 강화학습 기반 접근법과 달리, 대량의 데이터 없이도 효과적인 플래닝이 가능하도록 설계되었다.
2.1 In-Context Learning 기반 Few-Shot 학습
- 기존 모델들은 수천~수만 개의 레이블링된 데이터를 학습해야 하지만, LLM-Planner는 수십~수백 개의 예시만으로도 학습이 가능함.
- 이를 위해 kNN 기반의 예제 검색을 활용하여 가장 적절한 예제를 선택하여 LLM에게 제공.
예시: Few-Shot 학습 방식
- 사용자가 "뜨거운 컵을 캐비닛에 놓아라"라고 입력.
- LLM에 제공할 few-shot 예제를 검색(kNN 기반)하여 예시를 제공:
Task description: "계란을 요리한 후 싱크대에 놓아라." High-Level Plan: [이동: 냉장고, 열기: 냉장고, 집기: 계란, 닫기: 냉장고, 이동: 전자레인지, 열기: 전자레인지, 놓기: 계란] - LLM이 패턴을 학습하여 새로운 계획을 생성:
High-Level Plan: [이동: 컵보드, 열기: 컵보드, 이동: 테이블, 집기: 컵, 이동: 컵보드, 놓기: 컵] - LLP를 통해 저수준 행동 시퀀스 변환 후 실행.
이러한 Few-Shot 기반 접근법 덕분에 LLM-Planner는 데이터가 부족한 상황에서도 학습이 가능하며, 다양한 환경에서도 빠르게 적응할 수 있다.
3. 동적 재계획 (Grounded Re-Planning)
기존의 LLM 기반 플래닝 방법들은 정적 계획(Static Planning)을 수행하며, 환경 변화에 대한 고려가 부족했다. 하지만 LLM-Planner는 환경 변화를 반영하여 동적으로 계획을 수정할 수 있는 Grounded Re-Planning을 적용하였다.
3.1 동적 재계획의 핵심 원리
- LLM-Planner는 에이전트가 하위 목표를 실행하는 과정에서 실패하거나 예상치 못한 변수를 만나면 재계획을 수행.
- 환경에서 감지된 객체 리스트(Object List)를 기반으로 새로운 계획을 생성.
3.2 동적 재계획 예시
초기 계획
- 사용자가 "감자를 요리한 후 재활용통에 버려라"라고 입력.
- LLM-Planner가 초기 계획을 생성:
[(이동, 냉장고), (열기, 냉장고), (집기, 감자), (닫기, 냉장고), (이동, 전자레인지), (열기, 전자레인지), (놓기, 감자)]
실행 중 실패 발생
- 에이전트가 감자를 찾지 못함 → 환경에서 "냉장고"라는 객체가 탐지됨.
- 새로운 계획 생성:
[(이동, 냉장고), (열기, 냉장고), (집기, 감자)]
재활용통이 없는 경우
- 감자를 요리한 후 재활용통을 찾지 못함, 대신 "쓰레기통(garbage can)"이 보임.
- 재계획 수행:
[(이동, 쓰레기통), (놓기, 감자)]
즉, LLM이 직접 새로운 환경 정보를 고려하여 즉각적으로 플래닝을 업데이트하는 구조이며, 이를 통해 보다 현실적인 실행이 가능하다.
4. LLM-Planner와 기존 접근법 비교
| 모델 | 계획 방식 | 학습 방식 | 동적 재계획 | 데이터 요구량 |
| SayCan | 정적 계획 | 대량의 데이터 필요 | ❌ 불가능 | 높음 |
| HLSM | 정적 계획 | 대량의 데이터 필요 | ❌ 불가능 | 높음 |
| FILM | 정적 계획 | 대량의 데이터 필요 | ❌ 불가능 | 높음 |
| LLM-Planner | 동적 재계획 가능 | Few-Shot 학습 | ✅ 가능 | 낮음 |
LLM-Planner의 차별점
- 기존 모델은 정적 계획만 가능하지만, LLM-Planner는 환경 변화를 반영하여 재계획 가능.
- 소수의 학습 예시만으로도 플래닝 가능하여 데이터 비용 절감.
- 객체 탐지 결과를 즉각 반영하여 실시간 환경 적응이 가능.
결론
LLM-Planner는 대형 언어 모델을 활용한 Few-Shot 기반의 실체화 에이전트 플래닝 방법으로, 기존 모델 대비 더 적은 데이터로 학습 가능하면서도 동적으로 재계획이 가능한 점이 강점이다.
LLM-Planner는 Few-Shot 학습을 기반으로 한 동적 플래닝 기법을 적용하여 기존 모델들이 필요로 했던 대량의 데이터 없이도 강력한 성능을 발휘할 수 있음을 실험적으로 증명했다. 특히, 정적 플래닝이 아닌 환경 인식을 기반으로 동적 재계획이 가능한 점이 차별화된 특징으로 작용했다. 아래에서 논문의 실험 결과, 결론, 한계점 및 향후 연구 방향을 체계적으로 정리하겠다.
1. 실험 설정
본 연구는 LLM-Planner의 성능을 평가하기 위해 ALFRED 데이터셋에서 다양한 실험을 수행했다.
1.1. 데이터셋: ALFRED
- ALFRED는 실내 환경에서 시각과 언어를 활용한 작업 수행을 위한 대규모 데이터셋으로, 7가지 주요 작업 유형을 포함.
- 작업 예시: 물건을 집고 이동하기, 가열 또는 냉각 후 특정 위치에 놓기 등.
- 환경이 부분적으로 가려져 있고(Partially Observable), 장기적인 플래닝(Long-Horizon)이 필요한 도전적인 데이터셋임.
1.2. 평가 지표
LLM-Planner의 성능을 기존 모델들과 비교하기 위해 아래의 평가 지표를 사용했다.
| 평가 지표 | 설명 |
| Success Rate (SR) | 작업을 완전히 성공적으로 수행한 비율 |
| Goal-Condition Success Rate (GC) | 개별 목표 조건을 얼마나 정확하게 충족했는지 측정 |
| High-Level Planning Accuracy (HLP ACC) | 생성된 고수준 계획이 정답과 얼마나 일치하는지 평가 |
2. 주요 실험 결과
LLM-Planner는 소수의 예제(100개)만 학습하면서도 기존 모델들과 경쟁력 있는 성능을 발휘했다. 주요 결과를 정리하면 다음과 같다.
2.1. Few-Shot 설정에서도 높은 성능 달성
| 모델 | Few-Shot or 학습 데이터 | 성공률 | GC성공률 | HLP ACC |
| HLSM (Full Data) | 21,023개 | 20.27 | 27.24 | 70.17 |
| LLM-Planner (Few-Shot) | 100개 | 13.41 | 22.89 | 55.85 |
| HLSM (Few-Shot) | 100개 | 0.61 | 3.72 | 2.82 |
- 기존 모델(HLSM)이 100개 데이터로 학습하면 거의 성능이 나오지 않는 반면, LLM-Planner는 소수 데이터에서도 강력한 플래닝 성능을 발휘함.
- 전체 데이터를 사용한 HLSM과 비교해도 LLM-Planner의 성능은 경쟁력 있음.
2.2. 동적 재계획(Grounded Re-Planning)의 효과
LLM-Planner는 정적 플래닝(Static Planning)보다 동적 재계획(Grounded Re-Planning)을 수행할 때 성능이 향상됨.
| 모델 | Static Planning | Grounded Re-Planning |
| SR (Unseen) | 11.58% | 13.41% (+1.83%) |
| GC (Unseen) | 18.47% | 22.89% (+4.42%) |
- 정적 계획에서 동적 계획으로 전환할 경우 성능이 향상됨.
- 동적 재계획을 통해 환경의 변화에 맞춰 계획을 업데이트할 수 있는 점이 성능 개선의 핵심 요인.
2.3. SayCan과 비교
| 모델 | Success Rate | LLM 호출 횟수 |
| LLM-Planner | 13.41% | 7회 |
| SayCan | 9.88% | 22회 |
- SayCan은 환경 내 가능한 모든 행동 리스트를 미리 알아야 하지만, LLM-Planner는 이를 필요로 하지 않음.
- LLM 호출 횟수가 LLM-Planner가 더 적으며, 효율적임.
3. 결론
3.1. 연구 기여
LLM-Planner는 기존의 플래닝 모델들이 가지던 한계를 극복하면서도 적은 데이터만으로 효과적인 플래닝이 가능함을 증명했다. 주요 기여는 다음과 같다:
- Few-Shot 기반 플래닝 모델
- 기존 모델은 대량의 레이블링된 데이터를 필요로 했지만, LLM-Planner는 100개 정도의 데이터만으로도 충분한 성능을 발휘.
- 이는 실제 로봇 시스템에서 데이터 수집 비용을 획기적으로 줄일 수 있는 방법을 제공.
- 동적 재계획(Grounded Re-Planning) 기능
- 환경에서 인식한 객체 정보를 활용하여 플래닝을 수정할 수 있음.
- 부분 관찰 환경에서도 안정적인 작업 수행 가능.
- 샘플 효율성이 뛰어난 구조
- 기존 HLSM, FILM 등의 모델은 Few-Shot 학습 시 성능이 급격히 하락하는 반면, LLM-Planner는 데이터가 적어도 높은 성능 유지.
4. 연구 한계 및 향후 연구 방향
4.1. 연구 한계
- 객체 탐지 오류의 영향
- 예를 들어, "감자를 요리한 후 재활용통에 버리기" 작업을 수행할 때 객체 탐지(Object Detection) 모델이 감자를 탐지하지 못하면 플래닝이 실패할 가능성이 있음.
- 객체 탐지 성능 향상이 필요.
- 길이가 긴 작업(장기 플래닝)에서는 성능 저하
- 평균적으로 50개 이상의 액션이 필요한 **장기적인 작업(Long-Horizon Tasks)**에서는 여전히 개선이 필요.
- LLM 비용 문제
- GPT-3 기반 모델을 사용할 경우 API 호출 비용이 증가할 가능성이 있음.
- 더 경량화된 모델(GPT-4-Turbo, LLaMA 등)과의 비교가 필요.
4.2. 향후 연구 방향
- Mixture of Experts (MoE) 기반 플래닝 연구
- LLM을 활용한 플래닝을 더욱 최적화하기 위해 Mixture of Experts(MoE) 기반 모델을 활용할 수 있음.
- 환경 및 작업 유형에 따라 적절한 전문가 모델을 선택하는 방식이 가능.
- 강화학습(RL)과의 결합
- 현재 LLM-Planner는 Few-Shot 학습이지만, 이를 강화학습(Reinforcement Learning)과 결합하면 더욱 강력한 적응력이 가능할 것임.
- 다양한 LLM과 비교 연구
- GPT-3뿐만 아니라 GPT-4, Claude, LLaMA, Mistral 등 다양한 LLM과 비교하여 최적 모델을 선정할 필요가 있음.
5. 최종 요약
LLM-Planner는 소량의 학습 데이터만으로도 효과적인 플래닝이 가능하며, 환경의 변화를 반영하여 동적으로 재계획할 수 있는 점에서 기존 방법들보다 강력한 성능을 발휘했다.
이 연구는 데이터 효율적인 AI 플래닝 시스템 개발의 가능성을 열었으며, 향후 다양한 응용 분야에서 활용될 수 있을 것이다. 🚀