https://arxiv.org/abs/2309.01918
RoboAgent: Generalization and Efficiency in Robot Manipulation via Semantic Augmentations and Action Chunking
The grand aim of having a single robot that can manipulate arbitrary objects in diverse settings is at odds with the paucity of robotics datasets. Acquiring and growing such datasets is strenuous due to manual efforts, operational costs, and safety challen
arxiv.org
논문을 잘 못 찾아버렸네요 ㅎㅎ......
이 논문은 RoboAgent라는 로봇 조작 에이전트를 제안하며, Semantic Augmentation과 MT-ACT를 활용해 소규모 데이터로도 강력한 일반화 성능을 달성
Semantic Augmentation은 데이터 증강을 자동화하여 배경, 오브젝트를 다양화하고, 로봇의 새로운 환경 적응 능력을 강화
MT-ACT는 CVAE와 Transformer 구조를 통해 다중 작업을 처리하며, Action Chunking으로 시간적 연속성을 개선
실험 결과, RoboAgent는 조명, 물체 위치(L1), 배경 텍스처 및 방해 요소(L2), 새로운 작업 및 기술(L3)에서 기존 모델 대비 최대 400% 향상된 성능을 기록했
특히, 학습되지 않은 새로운 환경에서도 뛰어난 적응력을 보이며 현실 응용 가능성을 입증
이 연구는 로봇 조작 학습의 효율성을 극대화하고, 복잡한 환경에서의 범용 로봇 설계에 기여
| 연구 목표 | 제한된 데이터로 다양한 조작 작업을 수행할 수 있는 범용 로봇 에이전트 개발. |
| 주요 문제 | - 로봇 학습 데이터 확보의 높은 비용과 안전성 문제 - 현실 세계에서 새로운 작업/환경에 대한 일반화 부족 |
| 제안 방법 | 1. Semantic Augmentation: - 데이터셋을 증강해 다양성을 강화. - 자동화된 장면 변경(오브젝트 및 배경 변형). 2. MT-ACT: - 다중 작업 처리 가능한 Transformer 기반 정책 구조. - Action Chunking으로 시간적 연속성 강화. - CVAE로 다중 모달 데이터 학습. |
| 데이터셋 (RoboSet) | - 7,500개의 경로. - 12가지 기술과 38개의 작업. - 주방 환경에서 수집된 다양한 오브젝트와 장면 포함. - 예: 물체 잡기, 서랍 열기, 오븐 문 닫기. |
| 핵심 기법 | - Semantic Augmentation: 텍스트 기반 자동 장면 증강 (SegmentAnything 활용). - MT-ACT 구조: 1. CVAE: 행동 데이터의 잠재 패턴 학습. 2. FiLM 기반 언어 조건화: 언어 명령과 이미지 데이터 통합. 3. Action Chunking: 행동 조각 단위로 예측해 오류 완화. |
| 실험 설정 | - 일반화 축: 1. L1 (효율성): 물체 위치 및 조명 변화. 2. L2 (강건성): 새로운 배경, 방해 요소. 3. L3 (새로운 작업): 학습 데이터에 없는 작업. 4. L4 (강한 일반화): 새로운 주방 환경. - 다양한 환경과 작업에서 모델 성능 평가. |
| 주요 결과 | - MT-ACT는 기존 방법보다 모든 축에서 뛰어난 성능 발휘. - 성능 향상: L1: 30%, L2: 100%, L3: 400%. L4(새로운 환경): 성공률 25% (기존 모델은 0%). - 데이터 증강으로 일반화 성능 크게 향상. |
| 결론 | - 제한된 데이터로도 다중 작업을 수행할 수 있는 효율적이고 일반화 가능한 로봇 조작 에이전트 설계. - 데이터 수집 비용 절감과 높은 실용성 제공. |
| 한계 및 미래 연구 | - 한계: 1. 긴 작업 시퀀스 처리 미흡. 2. 언어 명령의 유연성 부족. - 미래 연구 방향: 1. 기술 조합을 통한 복잡한 장기 작업 수행. 2. 언어 조건화 개선으로 유연성 확보. |

이 Figure는 RoboAgent의 MT-ACT 모델이 수행할 수 있는 다양한 조작 기술과 작업들을 시각적으로 보여줍니다. 아래는 이 그림에 대한 상세 설명입니다.
1. Figure의 전체 구성
- 중심에 MT-ACT 로고가 위치하며, 이를 중심으로 모델이 수행하는 12가지 기술과 38가지 작업이 6개의 주요 활동으로 구분되어 배치되어 있습니다.
- 각 활동(activity)은 특정 작업(task)들로 이루어져 있으며, 작업 과정이 여러 프레임의 이미지로 시각화되어 있습니다.
2. RoboAgent의 주요 활동과 기술
활동별 작업
- Making Tea (차 만들기):
- 기술: 물체 잡기(Pick), 뚜껑 열기(Uncap), 뚜껑 닫기(Cap), 물체 놓기(Place).
- 작업 예: 찻잎 캔의 뚜껑 열기, 찻잎 담기, 찻잔 준비.
- Baking Prep (베이킹 준비):
- 기술: 서랍 열기(Slide-Open), 서랍 닫기(Slide-Close), 물체 놓기(Place).
- 작업 예: 버터 꺼내기, 서랍 닫기, 베이킹 재료 배치.
- Stowing Bowl (볼 정리):
- 기술: 물체 잡기(Pick), 물체 놓기(Place), 서랍 닫기(Slide-Close).
- 작업 예: 볼 집기, 서랍에 정리하기.
- Cleaning Up (정리):
- 기술: 닦기(Wipe), 물체 잡기(Pick).
- 작업 예: 카운터 닦기, 수건 정리.
- Heat Soup (수프 데우기):
- 기술: 오븐 문 열기(Flap-Open), 오븐 문 닫기(Flap-Close), 볼 밀어 넣기(Slide-In), 볼 꺼내기(Slide-Out).
- 작업 예: 오븐 사용을 통해 수프 데우기.
- Serve Soup (수프 서빙):
- 기술: 볼 꺼내기(Slide-Out), 오븐 닫기(Flap-Close).
- 작업 예: 데운 수프를 오븐에서 꺼내기.
3. 기술 요약
이 그림에서 12가지 조작 기술이 시각적으로 나타나 있으며, 각 작업이 단계적으로 표현됩니다:
- Slide-Open: 서랍 열기.
- Slide-Close: 서랍 닫기.
- Pick: 물체 잡기.
- Place: 물체 놓기.
- Flap-Open: 오븐 문 열기.
- Flap-Close: 오븐 문 닫기.
- Cap: 뚜껑 닫기.
- Uncap: 뚜껑 열기.
- Slide-In: 볼을 밀어넣기.
- Slide-Out: 볼을 꺼내기.
- Wipe: 표면 닦기.
- Press: 물체 누르기.
4. Figure의 핵심 메시지
- 다양성: RoboAgent는 12가지 기술을 기반으로 다양한 작업을 수행할 수 있으며, 이는 실제 가정, 주방 등 복잡한 환경에서도 작동 가능함을 보여줍니다.
- 작업 분할: 각 작업은 세부 기술로 나뉘며, 여러 단계의 행동이 매끄럽게 이어지는 것을 강조합니다.
- 일반화 가능성: RoboAgent가 다양한 환경과 오브젝트(예: 버터, 볼, 찻잎 캔 등)에 적용 가능함을 시각적으로 입증합니다.
5. 예시 분석
- 왼쪽 위의 "Cleaning Up" 활동:
- 수건을 사용하여 주방 카운터를 닦는 작업이 여러 단계로 나뉘어 진행.
- 기술: Wipe.
- 중앙의 "Baking Prep" 활동:
- 서랍을 열고(Slide-Open), 버터를 집어(Pick), 다시 서랍을 닫는(Slide-Close) 일련의 작업.
- 기술: Slide-Open, Pick, Slide-Close.
- 오른쪽 아래의 "Serve Soup" 활동:
- 오븐에서 볼을 꺼내는(Slide-Out) 작업.
- 기술: Slide-Out, Flap-Close.
6. 결론
이 Figure는 RoboAgent가 얼마나 다양한 조작 기술을 통합하여 실제 작업을 수행할 수 있는지를 직관적으로 보여줍니다. 특히, MT-ACT의 강점(다중 작업 수행, 기술의 매끄러운 연계성, 환경 일반화 능력)이 효과적으로 드러나 있습니다.
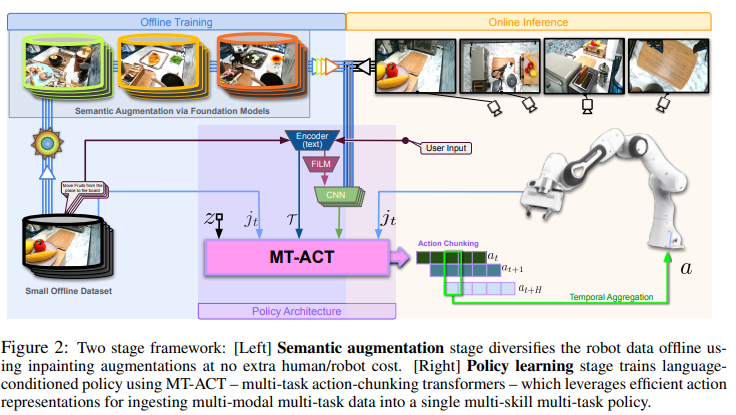
Figure 2: RoboAgent의 Two-Stage Framework
이 그림은 RoboAgent의 학습 및 추론 과정에 대한 두 단계 (Two-Stage) 프레임워크를 시각적으로 나타냅니다. 단계별로 아래와 같이 설명할 수 있습니다.
1. 첫 번째 단계: 오프라인 학습 (Offline Training)
목적:
- 제한된 데이터를 Semantic Augmentation으로 증강하여 데이터 다양성을 확대.
- 증강된 데이터를 기반으로 MT-ACT 정책 모델을 학습.
과정:
- Small Offline Dataset:
- 소규모 초기 데이터셋(7,500개의 경로)이 입력으로 사용됩니다.
- 예: 로봇이 서랍을 여는 작업, 물체를 집는 작업 등.
- Semantic Augmentation via Foundation Models:
- Semantic Augmentation:
- SegmentAnything 같은 분할(segmentation) 모델을 사용해 데이터의 객체와 배경을 탐지.
- 객체 및 배경의 다양한 변형(예: 다른 오브젝트로 대체, 새로운 배경 추가)을 통해 데이터를 증강.
- 이 과정은 사람/로봇의 추가 작업 없이 완전 자동화되어 진행.
- 결과: 증강된 데이터셋 생성 → MT-ACT 학습에 사용.
- Semantic Augmentation:
- MT-ACT 정책 구조:
- 증강된 데이터는 다중 작업, 다중 모달 데이터로 구성됩니다.
- 이 데이터를 기반으로 Transformer 기반의 MT-ACT 모델이 학습됩니다.
- Input to MT-ACT:
- 모델은 다양한 입력을 처리:
- zᵢ: 행동 데이터의 잠재 표현(학습된 CVAE에서 생성).
- jₜ: 로봇의 관절 위치와 속도.
- T: 사용자 명령(언어 조건화).
- 이미지: 다양한 카메라 시점에서 캡처된 영상.
- 모델은 다양한 입력을 처리:
2. 두 번째 단계: 온라인 추론 (Online Inference)
목적:
- 학습된 정책을 사용해 로봇이 실시간으로 다양한 작업을 수행.
과정:
- 사용자 입력 (User Input):
- 사용자는 언어 명령으로 작업을 지정합니다.
- 예: "오븐 문을 열어라", "컵을 집어서 놓아라."
- MT-ACT의 역할:
- Action Chunking: 로봇이 한 번에 여러 행동 단위를 예측(예: 손을 이동 → 물체 잡기 → 이동 후 놓기).
- Temporal Aggregation: 예측된 행동 조각을 시간적 연속성에 따라 조정하여 부드럽게 실행.
- 로봇의 동작:
- 로봇은 학습된 정책을 기반으로 작업을 수행.
- 예: 서랍 열기, 물체 집기, 오븐 문 닫기 등.
Figure에서 강조된 주요 포인트
- 자동화된 증강:
- 증강 과정의 자동화를 통해 추가적인 작업 비용 없이 데이터 다양성을 확보.
- 새로운 물체, 배경, 장면을 생성하여 로봇이 다양한 상황에서 적응 가능.
- MT-ACT의 학습 구조:
- CVAE를 사용해 행동 데이터의 패턴을 학습하고 잠재 표현(z)을 생성.
- FiLM (Feature-wise Linear Modulation) 기반 조건화로 언어 명령을 이미지와 통합.
- Action Chunking과 Temporal Aggregation:
- 행동 단위를 묶어서 예측하여 시간적 연속성과 행동의 안정성을 강화.
- 예측된 행동이 부드럽게 이어지도록 조정.
결론
이 Figure는 RoboAgent의 두 단계 프레임워크를 체계적으로 보여줍니다. 첫 번째 단계에서는 데이터 증강과 학습이 이루어지고, 두 번째 단계에서는 실시간으로 학습된 정책이 실행됩니다. 이러한 접근법은 효율적인 데이터 활용과 높은 일반화 성능을 가능하게 합니다.


Figure 4: Semantic Augmentation의 시각적 예시
이 그림은 RoboAgent가 데이터 증강(Semantic Augmentation)을 통해 다양한 장면과 오브젝트를 생성하는 방식을 보여줍니다.
(a) Augmenting Background (배경 증강)
설명:
- 배경(Scene) 요소를 변경하여 동일한 작업에서도 다양한 시나리오를 생성합니다.
- 주변 배경 텍스처(예: 타일, 나무 바닥, 주방 설정 등)를 변경하며, 로봇의 주요 작업 영역은 유지됩니다.
의미:
- 목적: 배경 변화를 통해 로봇이 다양한 환경에서 학습하도록 유도.
- 예시:
- 같은 주방 장면에서 타일 텍스처를 나무 바닥으로 바꾸거나, 주변 물체 배치를 변경.
- 작업 예: "볼을 집어 올리기"를 다양한 배경에서 실행.
(b) Augmenting Interaction Object (상호작용 오브젝트 증강)
설명:
- 로봇이 조작하는 물체(Interaction Object)를 변경합니다.
- 예를 들어, 물체가 버터 → 바나나 → 토마토로 바뀌며, 로봇의 동작은 동일하게 유지됩니다.
의미:
- 목적: 로봇이 다양한 오브젝트를 다룰 수 있도록 일반화 성능을 강화.
- 예시:
- 로봇이 동일한 작업("물체 집기")을 다른 오브젝트에 적용.
- 작업 예: "버터를 잡기" → "바나나를 잡기."
Figure 5: MT-ACT의 정책 아키텍처
이 그림은 RoboAgent의 학습 구조인 MT-ACT의 세부 아키텍처를 보여줍니다.
구조 개요
- 입력 데이터:
- 이미지 관찰: 4개의 카메라 시점에서 캡처된 이미지 입력.
- 언어 임베딩: 작업 설명을 위한 언어 임베딩(예: "서랍 열기").
- 잠재 코드 z: CVAE를 통해 생성된 행동 데이터의 잠재 표현.
- 로봇 상태 j_t: 로봇 관절의 위치 및 속도.
- 처리 흐름:
- Transformer Encoder:
- 입력 데이터를 처리해 시간적 연속성과 행동의 패턴을 학습.
- FiLM 기반 언어 조건화:
- 언어 명령(작업 설명)을 이미지와 통합.
- FiLM 레이어가 작업 명령을 이미지 토큰에 명시적으로 연결해 혼란을 방지.
- Transformer Decoder:
- 다음 행동 시퀀스(예: a_{t:t+H})를 Chunk 단위로 예측.
- Transformer Encoder:
- 출력:
- Action Queries:
- Transformer Decoder에서 생성된 행동 조각(Chunk)을 기반으로 로봇이 실행.
- Action Queries:
FiLM Layer의 역할
- FiLM(Feature-wise Linear Modulation) 레이어는 언어 명령을 이미지 관찰에 반영하도록 설계되었습니다.
- 구조:
- Batch Normalization(BN)과 Convolution(Conv) 레이어를 통해 언어 명령과 이미지를 효율적으로 통합.
- 효과:
- 다중 작업에서 로봇이 명확한 작업 명령을 이해하고 수행.
Figure 4 & 5의 요약
- Figure 4 (데이터 증강):
- 배경 증강: 로봇의 작업 영역 이외의 환경을 다양화.
- 오브젝트 증강: 로봇이 조작하는 물체를 변형.
- Figure 5 (MT-ACT 구조):
- Transformer 기반의 정책 모델로, 행동 시퀀스를 Chunk 단위로 예측.
- FiLM 레이어를 사용해 언어와 이미지 데이터를 통합.
이 두 그림은 데이터 증강을 통한 다양성 확보와 MT-ACT의 정책 학습 구조가 어떻게 로봇 조작의 효율성과 일반화 성능을 극대화하는지 설명하고 있습니다.

Figure 6 & Figure 7: RoboAgent의 환경과 일반화 성능 분석
Figure 6: 로봇 환경과 데이터셋 개요
이 그림은 RoboAgent의 학습 및 실험 환경과 사용된 데이터셋의 다양성을 시각적으로 보여줍니다.
1. Robot Setup (로봇 환경)
- 구성:
- 로봇은 실험실 주방 환경에서 작업하며, 4개의 카메라로 장면을 관찰합니다.
- 카메라 위치:
- 상단 시점 (Top-Down View): 전체 장면을 포괄적으로 관찰.
- 좌우 시점 (Side Views): 로봇과 물체의 상호작용 세부 정보를 수집.
- 손목 시점 (Wrist View): 로봇 손목 근처의 세부 장면 확인.
- 목적:
- 다양한 시각적 정보를 활용하여 로봇이 환경을 더 정확히 이해하고, 작업을 수행하도록 돕습니다.
2. Glimpse of Objects in RoboSet
- 데이터셋의 다양성:
- RoboSet 데이터셋은 다양한 오브젝트와 작업을 포함.
- Articulated Objects (관절형 오브젝트): 서랍, 오븐 문 등 움직일 수 있는 오브젝트.
- Rigid Objects (강체 오브젝트): 볼, 컵, 프렌치 프레스 등 고정된 형태의 물체.
- Deformable Objects (변형 가능한 오브젝트): 수건과 같은 유연한 물체.
- RoboSet 데이터셋은 다양한 오브젝트와 작업을 포함.
- 의의:
- RoboSet의 오브젝트 다양성은 로봇이 복잡한 조작 작업을 학습하고 일반화할 수 있도록 지원.
Figure 7: 일반화 성능 분석
이 그림은 RoboAgent의 일반화 성능(L1, L2, L3 축에서)을 기존 방법들과 비교하여 분석한 결과를 보여줍니다.
1. 일반화 축
- L1 (Object Poses, Lighting):
- 물체의 위치와 조명 조건 변화를 포함.
- 예: 동일한 작업(볼 집기)을 다양한 각도와 조명에서 수행.
- L2 (Textures, New Distractors):
- 배경 텍스처 변화 및 새로운 방해 요소를 포함.
- 예: 주방 타일 텍스처 변경, 배경에 새로운 물체 추가.
- L3 (New Tasks, New Object-Skills):
- 새로운 작업과 기술에 대한 일반화.
- 예: 학습되지 않은 새로운 오브젝트(예: 주전자)로 작업 수행.
2. 성능 비교
- Bottom-Left (L1-Generalization):
- 조명 조건과 물체 위치 변화에 대한 성능 평가.
- MT-ACT (증강 포함):
- 약 90%의 성공률로 가장 높은 성능을 기록.
- MT-ACT (증강 미포함):
- 약 60%로 증강이 없는 경우 성능 저하.
- 다른 기법(VIL, RT-1, BeT 등)은 30% 이하로 낮은 성능.
- Bottom-Right (L2 & L3-Generalization):
- L2 (배경 텍스처 및 방해 요소):
- MT-ACT(증강 포함): 65.17%로 가장 뛰어난 성능.
- MT-ACT(증강 미포함): 39.13%로 성능 감소.
- 다른 기법은 20% 이하로 성능이 저조.
- L3 (새로운 작업 및 기술):
- MT-ACT(증강 포함): 31.33%로 우수한 성능.
- MT-ACT(증강 미포함): 7.50%로 일반화 성능 크게 감소.
- 다른 기법은 3% 이하로 새로운 작업에서 거의 실패.
- L2 (배경 텍스처 및 방해 요소):
결론
- Figure 6 (환경 및 데이터셋):
- RoboAgent는 다양한 카메라 시점과 오브젝트 종류를 활용하여 실험 환경의 복잡성과 데이터를 확장.
- 이는 로봇의 일반화 능력을 강화하는 데 기여.
- Figure 7 (일반화 성능):
- MT-ACT는 데이터 증강(Semantic Augmentation)의 효과로, L1, L2, L3 축 모두에서 기존 방법을 크게 상회.
- 특히, 새로운 작업(L3)과 환경(L2)에 대한 적응 능력이 돋보임.
이 결과는 RoboAgent가 현실적인 환경 변화와 새로운 작업에 대해 강력한 적응 능력을 가지고 있음을 입증합니다.
문제 정의
로봇 조작 기술은 다양한 환경에서 여러 작업을 수행할 수 있는 범용 에이전트를 개발하는 것을 목표로 합니다. 하지만 로봇 학습에 필요한 대규모 데이터셋 확보는 높은 비용, 안전 문제, 그리고 작업의 복잡성으로 인해 어려움을 겪습니다. 본 연구는 제한된 데이터 환경에서도 강력한 일반화 성능을 가진 다중 작업(manipulation tasks) 에이전트를 설계하는 방법을 제안합니다.
연구 방법
- 데이터 증강 및 학습 구조 설계
- Semantic Augmentation: 기존 데이터셋을 기반으로 오브젝트와 환경을 변화시키는 증강 기술을 적용해 데이터를 다각적으로 증가시킴.
- MT-ACT (Multi-Task Action Chunking Transformer):
- Action Chunking: 행동 단위를 일괄 예측해 시간 상관성을 강화하고, 데이터 부족으로 인한 오류 축적 문제를 완화.
- CVAE (Conditional Variational Autoencoder): 다중 모달 데이터에서 패턴을 학습하고, 다양한 상황에 적응할 수 있도록 설계.
- FiLM 기반 조건화: 언어 명령을 이미지 토큰에 연결하여 다중 작업에서의 혼란을 방지.
- 데이터셋 구성
- RoboSet 데이터셋: 총 7,500개의 조작 경로를 포함, 12가지 기술과 38가지 작업으로 구성.
- 데이터는 인간 원격 조작(Teleoperation)을 통해 수집되었으며, 주방과 같은 실제 환경에서 다양한 장면 변화를 포함.
- 실험 설계
- 네 가지 일반화 축으로 평가:
- L1 (효율성): 오브젝트 위치 및 조명 조건 변화.
- L2 (강건성): 새로운 배경 및 방해 요소 추가.
- L3 (일반화): 학습 데이터에 없던 새로운 작업.
- L4 (강한 일반화): 완전히 새로운 환경(예: 주방)에서의 작업 수행.
- 네 가지 일반화 축으로 평가:
결과
- 성능 비교
- MT-ACT는 기존 방법(VIL, RT1 등) 대비 L1에서 약 30%, L2에서 100%, L3에서 400% 이상의 성능 향상을 보임.
- 특히, 데이터 증강이 L2 및 L3에서 큰 효과를 발휘.
- 강한 일반화(L4)
- MT-ACT는 새로운 주방 환경에서도 성공률 25%를 달성. 다른 기법은 모두 실패(0%).
- 추가 실험
- Semantic Augmentation이 없는 MT-ACT와 비교했을 때 성능이 현저히 높음.
- 작업 조건(예: FiLM)과 Chunk 크기(최적: 20)가 성능에 큰 영향을 미침.
한계 및 미래 연구
- 한계
- 모든 작업은 단일 기술로 분류되며, 긴 시간 축에서 여러 기술을 조합하는 문제는 탐구되지 않음.
- 언어 일반화는 고정된 사전 학습 임베딩을 사용, 유연성이 부족.
- 미래 연구 방향
- 기술 조합을 통한 복잡한 장기 작업 수행.
- 보다 유연한 언어 조건화 기술 개발.
결론
본 연구는 제한된 데이터 환경에서도 다중 작업을 효율적으로 수행하고 일반화 성능을 극대화할 수 있는 로봇 조작 에이전트(RoboAgent)를 설계했습니다. 제안된 MT-ACT와 Semantic Augmentation은 로봇 학습의 데이터 효율성을 크게 향상시켰으며, 실제 환경에서 강력한 일반화 성능을 입증했습니다. 이는 로봇 조작 연구와 실질적 응용 가능성 측면에서 중요한 발전을 의미합니다.
방법론: RoboAgent를 통한 효율적이고 일반화 가능한 로봇 조작 학습
1. 데이터 증강 (Semantic Augmentation)
문제: 실제 환경에서의 데이터 수집은 비용이 높고, 물리적 제약으로 데이터 다양성이 부족함.
해결 방법:
- 기존에 수집된 데이터를 오프라인에서 증강하여 새로운 데이터셋 생성.
- 자동화된 방법으로 데이터를 증강하여 로봇의 다양한 상황 적응력을 강화.
구체적인 방법:
- 오브젝트 증강:
- 로봇이 조작 중인 물체를 자동으로 탐지(SegmentAnything 모델 사용).
- 해당 물체를 다른 물체(예: 버터 → 바나나)로 대체하여 새로운 시나리오 생성.
- 예시: "버터를 잡아 서랍에서 꺼내기" → "바나나를 잡아 서랍에서 꺼내기"로 변환.
- 배경 증강:
- 로봇이 조작하지 않는 배경 요소(예: 테이블, 벽지)를 선택.
- 다양한 텍스처와 패턴을 추가해 환경 다양성 확보.
- 예시: 주방의 흰색 타일 → 나무 패턴 타일로 변경.
특징:
- 완전 자동화: 수작업 없이 데이터 증강 가능.
- 로봇이 다양한 배경 및 오브젝트 변형에 적응하도록 학습.
2. MT-ACT (Multi-Task Action Chunking Transformer)
목표: 다중 작업 환경에서 하나의 정책으로 다양한 기술을 수행하도록 설계.
핵심 아이디어:
- Action Chunking: 행동 단위를 묶어서 예측함으로써 시간 상관성을 강화하고 오류 축적 문제 완화.
- CVAE (Conditional Variational Autoencoder):
- 행동 데이터를 잠재 공간(latent space)에 매핑해 데이터의 패턴을 학습.
- 로봇이 학습하지 않은 작업에서도 일반화된 행동 생성 가능.
- FiLM 기반 조건화:
- 언어 명령과 이미지 데이터를 통합해 로봇의 작업 혼란 방지.
구조:
- 입력 데이터:
- 4개의 카메라(위, 오른쪽, 왼쪽, 손목)에서 캡처된 이미지.
- 로봇의 관절 위치 및 속도.
- 언어로 주어진 작업 설명(예: "오븐 문 열기").
- 처리 단계:
- CVAE: 입력 데이터를 잠재 공간으로 변환.
- Transformer:
- CVAE의 잠재 코드, 언어 임베딩, 이미지 토큰을 입력으로 사용.
- FiLM 조건화로 언어 명령을 이미지 토큰에 명시적으로 연결.
- Chunk Prediction:
- 한 번에 여러 동작(예: 오븐 문 열기 → 손을 오븐 손잡이로 이동 → 열기)을 예측.
- 행동의 시간적 연속성과 안정성 강화.
- 결과:
- 예측된 행동 조각(chunk)을 실행.
- 예를 들어, "오븐 문 열기" 작업에서 로봇이 연속적으로 손을 이동하고 문을 여는 동작을 수행.
3. 데이터셋 설계 (RoboSet)
특징:
- 7,500개의 경로를 포함한 소규모 데이터셋.
- 12가지 기술과 38개의 작업으로 구성.
- 다양성: 각 기술은 여러 오브젝트와 장면에서 실행.
예시 작업:
- 기술: 물체 잡기, 문 열기, 서랍 닫기.
- 작업: "버터를 서랍에서 꺼내기", "오븐 문 열기".
예시를 통한 정리
- 데이터 증강:
- 기존 작업: "테이블 위에서 컵을 집어 올리기."
- 증강 후:
- 컵 → 접시로 변경.
- 테이블 → 나무 바닥으로 변경.
- 조명 → 어두운 환경으로 변경.
- MT-ACT 처리:
- 입력: "접시를 테이블에서 집어 올려라" (언어 명령).
- 출력:
- 단계 1: 로봇 손을 접시 방향으로 이동.
- 단계 2: 접시를 집음.
- 단계 3: 접시를 들어 올림.
장점
- 효율성: 기존 데이터에서 다각적인 증강을 통해 비용 없이 학습 데이터 증가.
- 강력한 일반화 성능: 새로운 환경과 작업에서도 높은 성공률.
예시 결과:
- 새로운 주방 환경에서 "오븐 문 열기" 작업 수행 성공률 25% (기존 기법은 0%).
이 방법론은 데이터 부족 문제를 극복하고 로봇 조작 에이전트의 일반화와 학습 효율성을 극대화하는 데 기여했습니다.
그럼 이 논문은 단순하게 학습데이터를 조금씩 변형해서 데이터의 양을 늘린거야...?
이 논문의 데이터 증강(Semantic Augmentation)은 단순히 학습 데이터를 조금 변형하는 수준을 넘어, 로봇이 다양한 실제 환경에서 적응할 수 있는 일반화 능력을 키우기 위한 체계적인 방법론입니다. 핵심은 데이터의 "양"을 늘리는 것뿐 아니라, 데이터의 "다양성"을 크게 향상시키는 데 있습니다. 아래에서 이 점을 자세히 설명하겠습니다.
1. 단순한 변형과의 차이점
일반적인 데이터 증강 기법은 다음과 같은 간단한 변형을 포함합니다:
- 이미지 회전, 크기 조절, 색상 변경.
- 데이터의 노이즈 추가.
하지만, 이 논문에서 사용한 Semantic Augmentation은 단순 변형이 아닌, **장면의 맥락(Context)**과 로봇 조작의 의미를 유지하며 데이터를 증강합니다.
예시
- 단순 변형: "로봇이 컵을 집는다"라는 데이터에서 컵의 위치를 조금 변경하거나, 배경 색상을 조정.
- Semantic Augmentation:
- 오브젝트 변경: 컵 대신 접시로 대체.
- 배경 변경: 주방 타일을 나무 바닥으로 변경.
- 작업 맥락 유지: 컵이나 접시를 "집는다"라는 동작의 본질은 유지.
2. Semantic Augmentation의 핵심
- 다양한 시나리오 생성
- 로봇이 여러 물체(예: 컵, 접시, 버터)와 환경(예: 다른 배경, 조명 조건)에서 동일한 기술을 수행하도록 데이터 생성.
- 목적: 로봇이 학습하지 않은 새로운 상황에서도 적응 가능하도록 준비.
- Fully Automatic Process
- 사람의 개입 없이 SegmentAnything 모델을 활용해 장면을 자동으로 분석하고 증강.
- 텍스트 기반 명령을 통해 증강된 오브젝트나 배경의 변경 사항을 반영.
- Out-of-Distribution Generalization
- 학습 데이터에 없는 장면과 작업에도 로봇이 대응할 수 있는 일반화 성능 확보.
3. 이 논문의 목표
단순히 데이터를 많이 모으거나 변형하는 것이 아닌, 제한된 데이터 환경에서도 로봇이 다양한 작업과 환경에서 잘 작동하도록 만드는 것이 목표입니다.
데이터 증강의 전략적 역할
- 비용 절감: 새로운 데이터를 직접 수집하지 않아도 다양한 데이터를 생성.
- 성능 향상: 기존 데이터를 기반으로 환경적 다양성과 물체적 다양성을 추가해 테스트 시 높은 일반화 성능 확보.
성능 비교
- 기존의 단순 변형 기법을 사용하는 모델(VIL, RT1)들은 제한된 데이터로 학습했을 때, 새로운 환경에서 거의 실패.
- 이 논문에서 제안한 RoboAgent는 새로운 환경(L3, L4)에서도 평균 25% 성공률을 달성.
4. 결론
이 논문은 단순히 데이터의 양을 늘리는 것이 아니라, 데이터의 다양성과 의미적 맥락을 강화하여 로봇이 더 일반화된 학습을 할 수 있도록 설계되었습니다. 이는 데이터 증강을 효율적으로 활용한 사례로, 적은 데이터로도 강력한 로봇 조작 성능을 얻는 데 성공했습니다.
이 접근법은 특히 현실 세계에서의 로봇 조작 문제를 해결하는 데 유용하며, 데이터 수집 비용이 높은 상황에서 중요한 실용적 가치를 가집니다.
결과, 결론, 마무리
1. 논문의 주요 결과
- 성능 비교
- 제안된 RoboAgent는 기존 모델(VIL, RT1 등)보다 모든 일반화 수준에서 뛰어난 성능을 보였습니다.
- L1 (효율성): 기존 기법 대비 약 30% 향상.
- L2 (강건성): 약 100% 성능 개선.
- L3 (새로운 작업 일반화): 약 400% 향상.
- L4 (강한 일반화): 새로운 주방 환경에서 유일하게 성공률 25%를 기록(다른 기법은 0%).
- 제안된 RoboAgent는 기존 모델(VIL, RT1 등)보다 모든 일반화 수준에서 뛰어난 성능을 보였습니다.
- 데이터 증강 효과
- Semantic Augmentation은 기존 데이터의 다양성을 강화해, 새로운 환경에서의 일반화 성능을 크게 높였습니다.
- 증강이 없을 경우, L2와 L3 성능이 크게 감소.
- MT-ACT의 효과
- Action Chunking과 CVAE 기반 정책이 기존 기법보다 더 안정적이고 매끄러운 로봇 행동을 생성.
- Chunk Prediction을 통해 행동의 시간적 연속성과 오류 복구 능력을 강화.
- 활용 가능성
- Plasticity: 이미 학습된 모델을 소량의 데이터로 추가 작업에 빠르게 적응 가능.
- 새로운 작업(예: "토스터 오븐에 토스트 넣기") 추가 시, 기존 성능 유지하면서 높은 학습 효율성 달성.
- Plasticity: 이미 학습된 모델을 소량의 데이터로 추가 작업에 빠르게 적응 가능.
2. 논문의 결론
- 제안된 방법의 의의
- 효율성: 소규모 데이터(7,500 경로)로 강력한 다중 작업 수행 에이전트를 학습.
- 일반화 성능: 다양한 환경과 작업에서 뛰어난 적응 능력을 입증.
- 로봇 조작의 실용성 향상: 로봇이 복잡하고 실제적인 환경에서 안정적으로 작동.
- 주요 기여
- MT-ACT: 다중 작업, 다중 모달 데이터를 효과적으로 학습할 수 있는 정책 구조 제안.
- RoboSet: 다양한 기술과 작업을 포함한 대규모 오픈소스 로봇 조작 데이터셋 공개.
- Semantic Augmentation: 새로운 장면과 작업에 일반화할 수 있는 효과적인 데이터 증강 기법 제안.
- 성공 요인
- 기존 데이터를 효율적으로 활용한 증강 기법.
- Transformer 기반 정책으로 다중 작업 처리 능력을 강화.
- CVAE와 Chunk Prediction으로 행동의 연속성과 정확도를 높임.
3. 마무리 및 한계
- 한계
- 긴 작업 시퀀스 처리:
- 본 논문은 단일 기술(예: 문 열기, 물체 잡기)을 중심으로 작업을 정의.
- 복잡한 장기 작업(예: 차 만들기)을 자동으로 조합하는 방식은 다루지 않음.
- 언어 일반화 부족:
- 언어 명령은 고정된 사전 학습된 임베딩을 사용.
- 작업 설명의 변화에 더 유연하게 적응하는 방법은 향후 연구가 필요.
- 긴 작업 시퀀스 처리:
- 미래 연구 방향
- 기술 조합을 통한 장기 작업 수행 에이전트 개발.
- 언어 조건화 개선: 작업 설명의 다양한 변형에도 적응할 수 있는 언어 처리 기법 개발.
- 확장성 연구: 다른 작업 영역(예: 공장, 병원)으로 적용 가능성 검토.
4. 논문의 최종 메시지
본 연구는 제한된 데이터 환경에서 효율적이고 일반화 가능한 로봇 조작 에이전트를 설계하는 데 성공했습니다. 특히, Semantic Augmentation과 MT-ACT는 데이터 수집 비용을 줄이면서도 높은 성능을 달성하는 데 중요한 기여를 했습니다.
이 방법론은 로봇 조작 연구와 실제 응용 가능성을 크게 확장할 수 있는 중요한 출발점을 제공합니다. 앞으로 이 기술은 로봇이 더 다양한 환경과 작업에서 성공적으로 작동하는 데 기여할 것으로 기대됩니다.