
기존 라마 1B의 출력입니다.
결론적으론 제 SAE를 못 쓰게 되었는데 파라미터 업데이트가 문제였네요....

8일전 업데이트해서 저 파라미터에 대한 SAE가 아니기 때문에 이전 Llama를 사용해야 해서.....
일단...
시작은 "yoonLM/sae_llama3.2org_1B_512_16_l1_100" 모델입니다.
1B 뒤부터 Contest_length, Latent_space_scale, l1_coefficient 입니다.
모델 부르는 방법은 아래와 같습니다.
import os
from setproctitle import setproctitle
setproctitle("")
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
import torch
from tqdm import tqdm
import plotly.express as px
import pandas as pd
# Imports for displaying vis in Colab / notebook
torch.set_grad_enabled(False)
# For the most part I'll try to import functions and classes near where they are used
# to make it clear where they come from.
if torch.backends.mps.is_available():
device = "mps"
else:
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Device: {device}")
from sae_lens.toolkit.pretrained_saes_directory import get_pretrained_saes_directory
from sae_lens import SAE, HookedSAETransformer
layer_sae_path = f"layer_{10}_sae"
model_name = "meta-llama/Llama-3.2-1B"
model = HookedSAETransformer.from_pretrained(model_name, device = device)
#`cfg` 딕셔너리는 SAE와 함께 반환되며, 이는 SAE를 분석하는 데 유용한 정보를 포함할 수 있기 때문입니다 (예: 활성화 저장소 인스턴스화).
#이는 SAE의 구성 딕셔너리와 동일하지 않으며, HF(Hugging Face) 저장소에 있던 내용을 의미하며, 여기서 SAE 구성 딕셔너리를 추출할 수 있습니다.
# 또한 편의상 HF에 저장된 특징 희소성도 반환됩니다.
sae_id = f"blocks.{10}.hook_resid_pre"
sae, cfg_dict, sparsity = SAE.from_pretrained(
release = "yoonLM/sae_llama3.2org_1B_512_16_l1_0.1", # <- Release name
sae_id = sae_id, # <- SAE id (not always a hook point!)
device = device
)
또 활성화 되는 것이 단 한개도 없네요
모델 완전히 고장날 예정입니다...

역시 SAE를 달기 전에는 멀쩡했지만 SAE를 달자마자 바로 고장이 났습니다.
이 모델은 넘기겠습니다.
이번엔 yoonLM/sae_llama3.2org_1B_512_16_l1_0.1 입니다.
가장 기대되는 모델 중 하나입니다.

이번엔 Apple에 활성화된 feature들이 상당히 많은 모습입니다..
l1 coefficient가 너무 낮긴 했습니다.
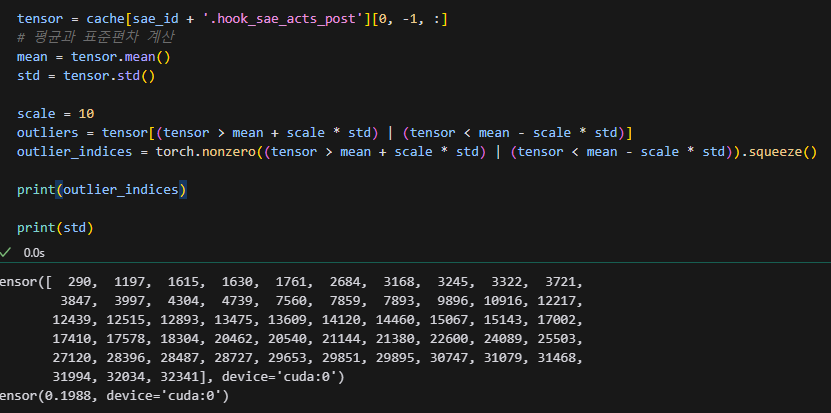
이상치가 너무 많네요....
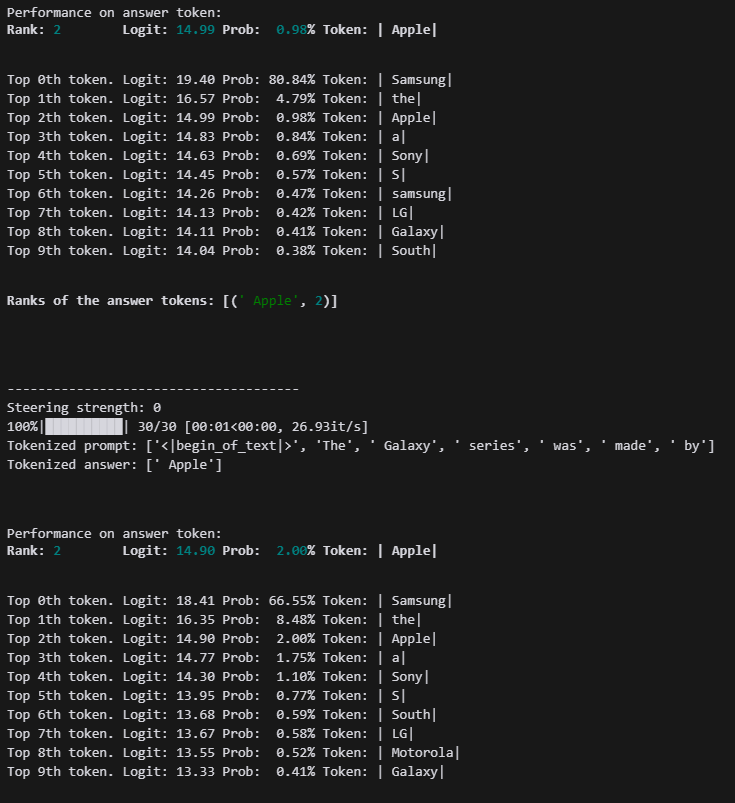
그래도 Apple의 확률이 많이 올라간 모습입니다.
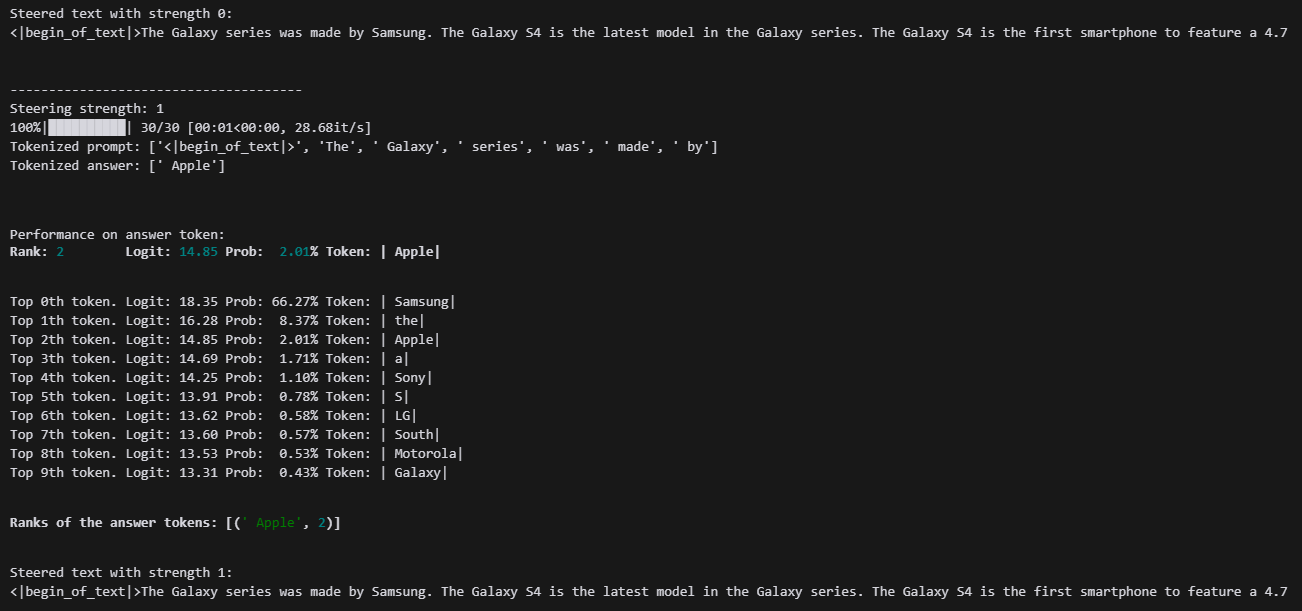
그래도 발화가 크게 변화지 않네요...

발화가 동어 반복 현상이 나오고, feature가 강해지진 않네요....
이번엔 yoonLM/sae_llama3.2org_1B_512_16_l1_1 입니다.

확실히 1보다는 활성화 되는 정도가 줄었습니다.

그래도 아직도 많네요...

모델 사이즈가 작아지니까 동어 반복현상이 너무 많이 생기네요....
학습이 부족한가 MSE를 좀 더 줄여야 하는 상황인 것 같습니다.
이번엔 yoonLM/sae_llama3.2org_1B_512_16_l1_10 입니다.

Feature는 확실히 sparse한데 문제는 MSE가 커서...

딱 이정도면 괜찮아 보이네요

역시 SAE 달자마자 고장나는 것을 볼 수 있습니다....
이번에는 yoonLM/sae_llama3.2org_1B_512_8_l1_0.01 모델입니다.
Coefficient가 낮은 만큼 mse는 엄청 작을 예정입니다.

역시 많이 활성화 되긴 하네요...

음...


Feature를 강화해준다고 출력이 바뀌지는 않았지만 Apple의 순위는 오히려 떨어졌습니다..

Feature를 더 강화시켰더니 고장나는 모습이 보이고, Apple는 점점 떨어지네요....
이번에는 yoonLM/sae_llama3.2org_1B_512_8_l1_0.05 모델입니다.

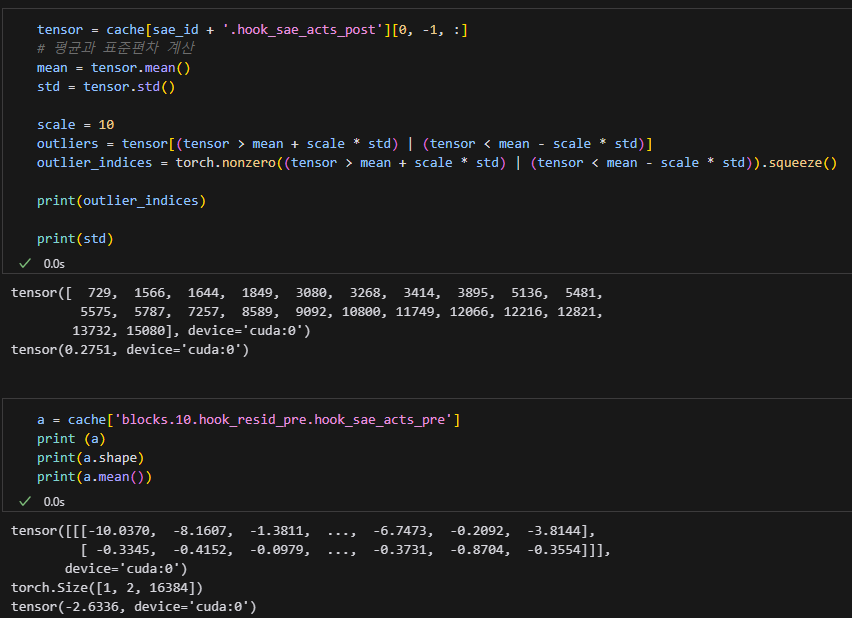
비슷하지만 조금 줄었네요

????
SAE만 달았을 뿐인데 모델이 완전히 망가졌습니다.
이건....????

MSE도 2점 대로 나름 준수한 편인데 왜인지는....????

일단..... 확인정도 하고 넘어가겠습니다...
이번에는 yoonLM/sae_llama3.2org_1B_512_8_l1_0.1 모델입니다.
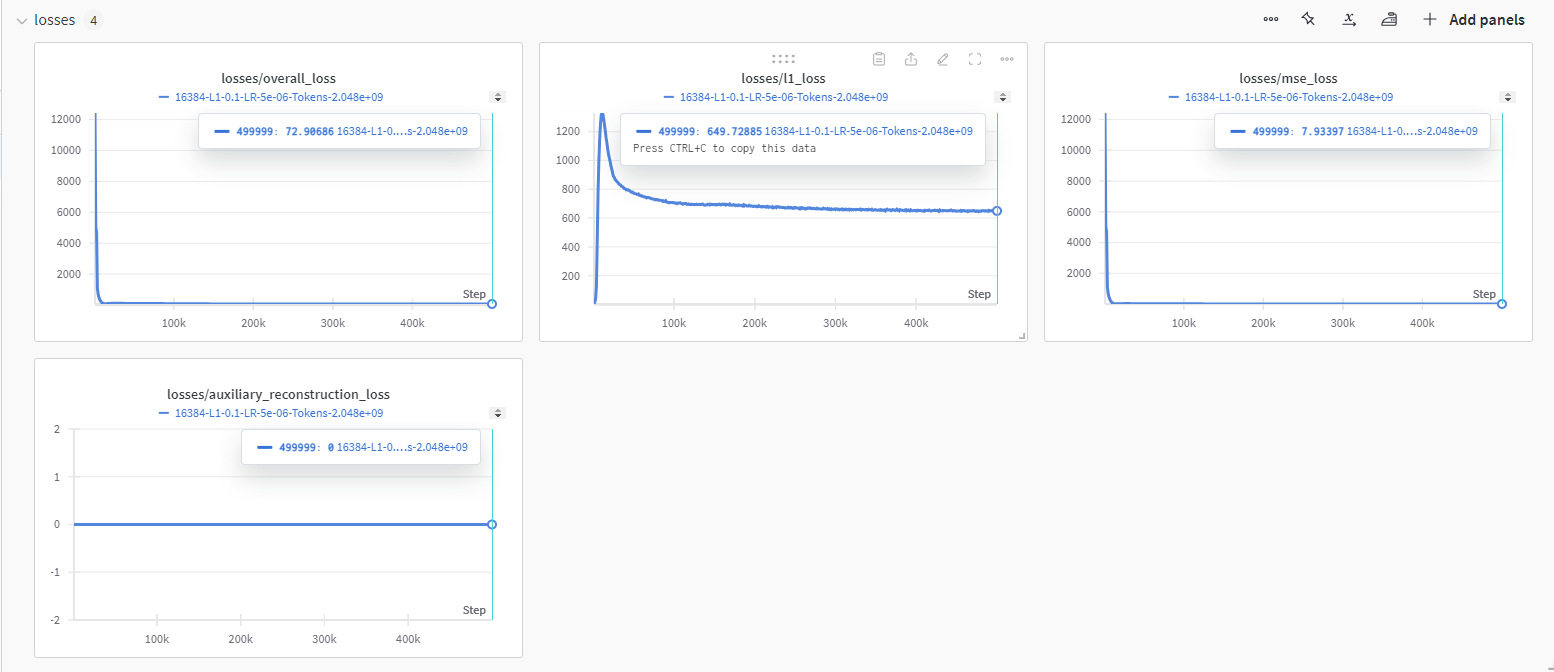

Sparsity가 오히려 감소하는 모습이 왜 보였는진 모르겠지만 한번 확인해보겠습니다.


느낌은 대충 비슷하네요

또 완전히 고장났습니다.......
이번에는 yoonLM/sae_llama3.2org_1B_256_4_l1_0.1 입니다.

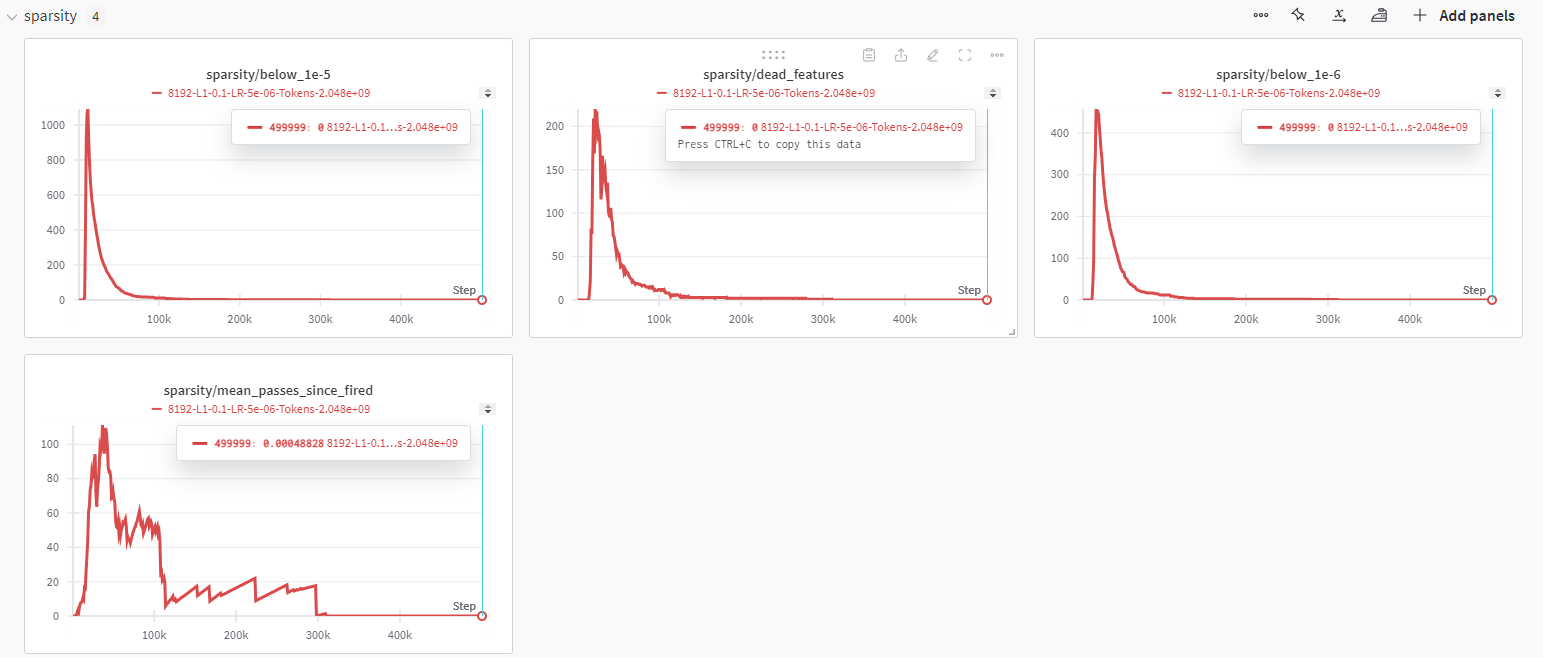
Loss가 박살난 것을 보니 기대도 못 하겠습니다...

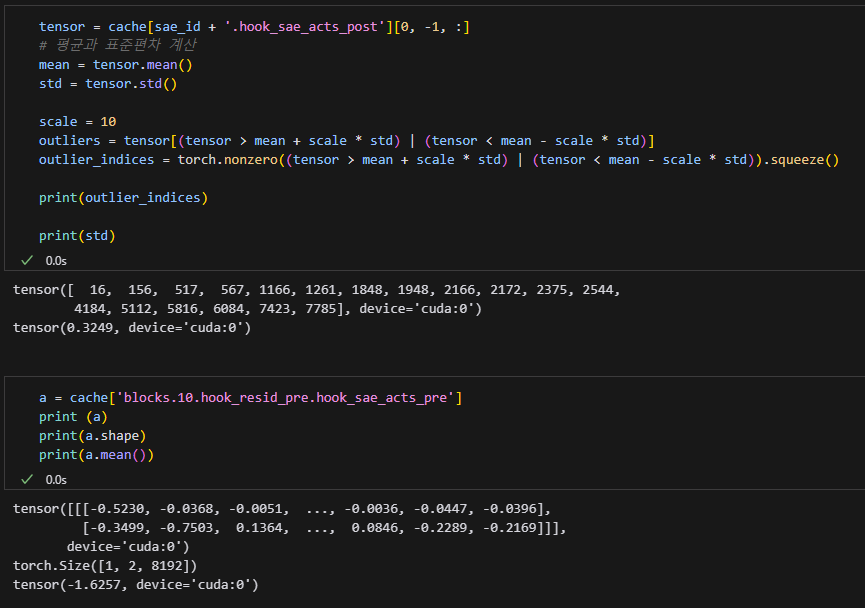

역시 MSE가 좀만 커도 모델이 바로 고장나버리네요...
이번에는 yoonLM/sae_llama3.2org_1B_256_4_l1_0.05 모델입니다.


Sparsity가 좀 많이 죽긴 했지만 mse가 그래도 좀 낮아서 기대해보고 있습니다...
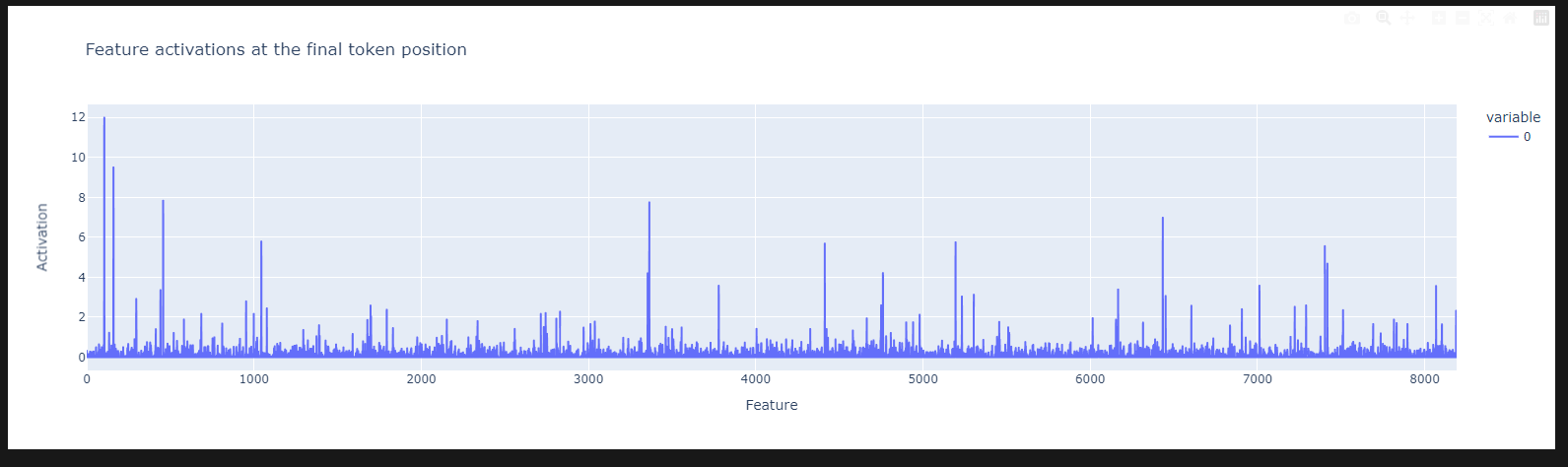

그래도 많이 걸리진 않았네요

모델이 많이 박살났네요 ㅎㅎ.....
마지막 모델이네요 이 것 조차 안되면... yoonLM/sae_llama3.2org_1B_256_4_l1_0.01

확실히 너무 살아있네요

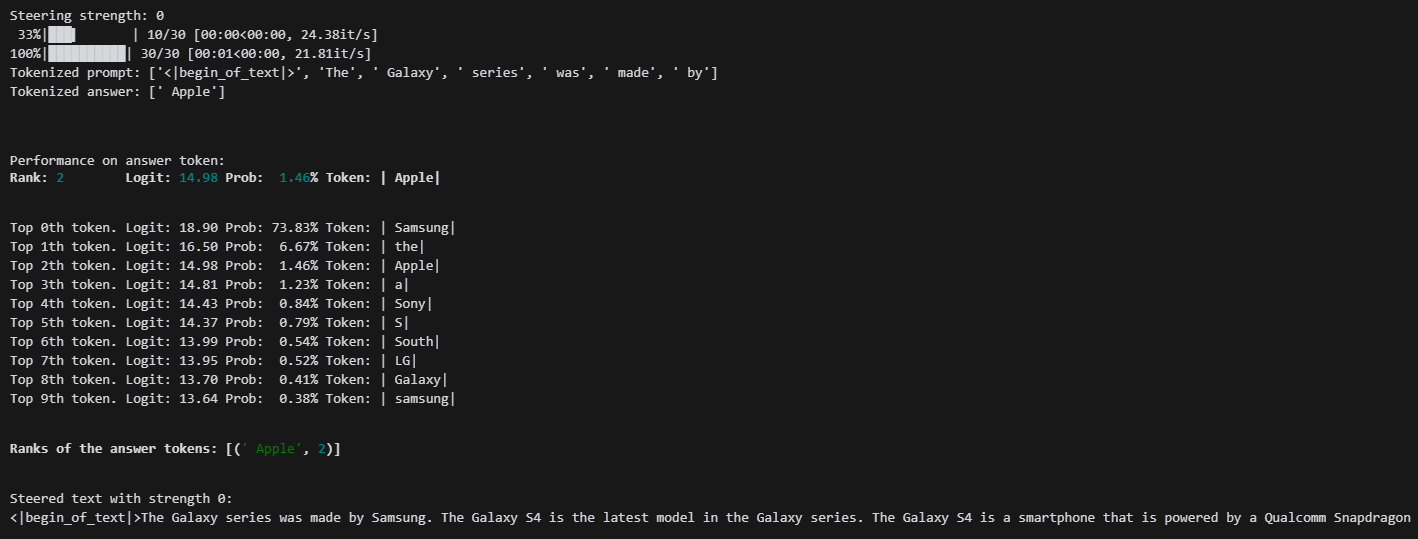
멀쩡한 모델이 되었씁니다!
그럼 가중치를 크게 줘가면서 Apple를 키워보겠습니다.

결국 고장나네요.......
'인공지능 > XAI' 카테고리의 다른 글
| SelfIE : 세미나 발표 준비 (1) | 2024.11.24 |
|---|---|
| 🤳SelfIE: Self-Interpretation of Large Language Model Embeddings - 세미나 준비 (1) | 2024.11.18 |
| sae-vis tutorial (3) | 2024.10.31 |
| latent space, l1 coefficient, context length에 따른 Sparse Autoencoder 학습 (0) | 2024.10.29 |
| l1 Coefficient에 따른 Sparse Autoencoder 학습, 출력 확인 (0) | 2024.10.15 |