SAE-VIS 데모
참고: 이것이 최종 버전 데모입니다. (첫 번째 및 두 번째 이전 버전은 최신 버전의 라이브러리를 나타내지 않습니다.)
이 Colab 파일은 제가 만든 오픈소스 희소 오토인코더 시각화 도구(sparse autoencoder visualizer)를 시연하기 위해 생성되었습니다. 자세한 내용은 여기에서 확인할 수 있습니다. 추가적으로 참고할 링크들은 다음과 같습니다:
- GitHub 저장소
- 개발자 가이드: 코드베이스를 이해하고 기여하고자 하는 분들을 위한 자료
- 사용자 가이드: 코드베이스의 모든 기능을 이해하고자 하는 분들을 위한 자료 (이 Colab을 따라 읽는 것도 또 다른 방법이며, 대부분 자가 설명적입니다)
이 Colab에서는 두 가지 종류의 시각화 방법을 시연합니다:
- 특징 중심 시각화: 단일 특징을 대상으로 해당 특징이 대규모 데이터셋의 어느 시퀀스에서 가장 강하게 활성화되는지 확인하는 방식입니다.
-
- 프롬프트 중심 시각화: 사용자 정의 프롬프트를 입력하고, 다양한 메트릭을 사용해 해당 프롬프트에서 가장 높은 점수를 기록한 특징들을 확인하는 방식입니다.
-
이 데모는 희소 오토인코더(sparse autoencoder)의 결과 해석을 위한 시각화 도구입니다. 첫 번째 방법에서는 특정 특징이 데이터셋의 다양한 시퀀스에서 어떻게 활성화되는지 볼 수 있으며, 두 번째 방법에서는 특정 프롬프트에 대한 특징들의 반응을 파악할 수 있습니다.
COLAB = False
from IPython import get_ipython # type: ignore
ipython = get_ipython(); assert ipython is not None
ipython.run_line_magic("load_ext", "autoreload")
ipython.run_line_magic("autoreload", "2")
import torch
from datasets import load_dataset
import webbrowser
import os
from transformer_lens import utils, HookedTransformer
from datasets.arrow_dataset import Dataset
from huggingface_hub import hf_hub_download
import time
# Library imports
from sae_vis.utils_fns import get_device
from sae_vis.model_fns import AutoEncoder
from sae_vis.data_storing_fns import SaeVisData
from sae_vis.data_config_classes import SaeVisConfig
# from sae_lens.training.sparse_autoencoder import SparseAutoencoder
# Imports for displaying vis in Colab / notebook
import webbrowser
import http.server
import socketserver
import threading
PORT = 8000
device = get_device()
torch.set_grad_enabled(False);def display_vis_inline(filename: str, height: int = 850):
'''
Displays the HTML files in Colab. Uses global `PORT` variable defined in prev cell, so that each
vis has a unique port without having to define a port within the function.
'''
if not(COLAB):
webbrowser.open(filename);
else:
global PORT
def serve(directory):
os.chdir(directory)
# Create a handler for serving files
handler = http.server.SimpleHTTPRequestHandler
# Create a socket server with the handler
with socketserver.TCPServer(("", PORT), handler) as httpd:
print(f"Serving files from {directory} on port {PORT}")
httpd.serve_forever()
thread = threading.Thread(target=serve, args=("/content",))
thread.start()
output.serve_kernel_port_as_iframe(PORT, path=f"/{filename}", height=height, cache_in_notebook=True)
PORT += 1
설정
오토인코더
여기서 오토인코더를 설정합니다. W_enc, W_dec, b_enc, b_dec와 같은 파라미터를 동일한 방식으로 사용하는 한, 사용자는 자신이 보유한 오토인코더를 사용할 수 있습니다. 또한 cfg 속성이 있어야 하며, 이 속성은 d_mlp와 dict_mult 속성을 가진 데이터 클래스입니다. 이 코드베이스에서는 가중치만 직접 사용하기 때문에 순전파(forward pass) 방식은 중요하지 않습니다.
설명하자면, 이 설정은 메모리 문제를 줄이기 위해 전체 특징을 다루지 않고 오토인코더의 일부 특징만 사용하는 방법입니다. W_enc, W_dec, b_enc, b_dec와 같은 가중치 및 편향 파라미터가 중요하며, 이 코드에서는 이러한 파라미터들만 사용됩니다.
encoder = AutoEncoder.load_from_hf(version="run1").to(device)
encoder_B = AutoEncoder.load_from_hf(version="run2").to(device)
for k, v in encoder.named_parameters():
print(f"{k}: {tuple(v.shape)}")
W_enc: (2048, 16384)
W_dec: (16384, 2048)
b_enc: (16384,)
b_dec: (2048,)
모델
이 라이브러리는 궁극적으로 TransformerLens가 아닌 모델도 지원할 예정이지만, 현재는 해당 기능이 구현되지 않았습니다. 관심이 있다면 연락해 주세요!
현재는 TransformerLens 모델만을 지원하고 있지만, 나중에는 다른 모델도 사용 가능하도록 확장될 예정입니다. 만약 다른 모델을 사용하려 한다면 forward 메서드를 수정해 특정 요구사항에 맞추어주는 것이 좋습니다. 이 Colab에서는 최소한의 요구사항만을 만족하는 DemoTransformer 모델을 예시로 사용하여, 다른 복잡한 기능이 없어도 가능하다는 점을 보여줍니다.
model = HookedTransformer.from_pretrained("gelu-1l")
model.to(device);Loaded pretrained model gelu-1l into HookedTransformer
Moving model to device: cuda
데이터
물론, 이 코드는 사용자의 데이터 로딩 코드로 교체할 수 있습니다. 최종적으로는 토큰 ID로 구성된 2D 텐서가 준비되어 있어야 합니다.
설명하자면, 이 부분에서는 원하는 데이터를 사용할 수 있으며, 코드가 요구하는 것은 토큰 ID로 이루어진 2차원 텐서 형태의 데이터입니다. 이를 통해 모델이 텍스트를 입력으로 받아 처리할 수 있게 됩니다.
SEQ_LEN = 128
# Load in the data (it's a Dataset object)
data = load_dataset("NeelNanda/c4-code-20k", split="train")
assert isinstance(data, Dataset)
# Tokenize the data (using a utils function) and shuffle it
tokenized_data = utils.tokenize_and_concatenate(data, model.tokenizer, max_length=SEQ_LEN) # type: ignore
tokenized_data = tokenized_data.shuffle(42)
# Get the tokens as a tensor
all_tokens = tokenized_data["tokens"]
assert isinstance(all_tokens, torch.Tensor)
print(all_tokens.shape)
torch.Size([215402, 128])
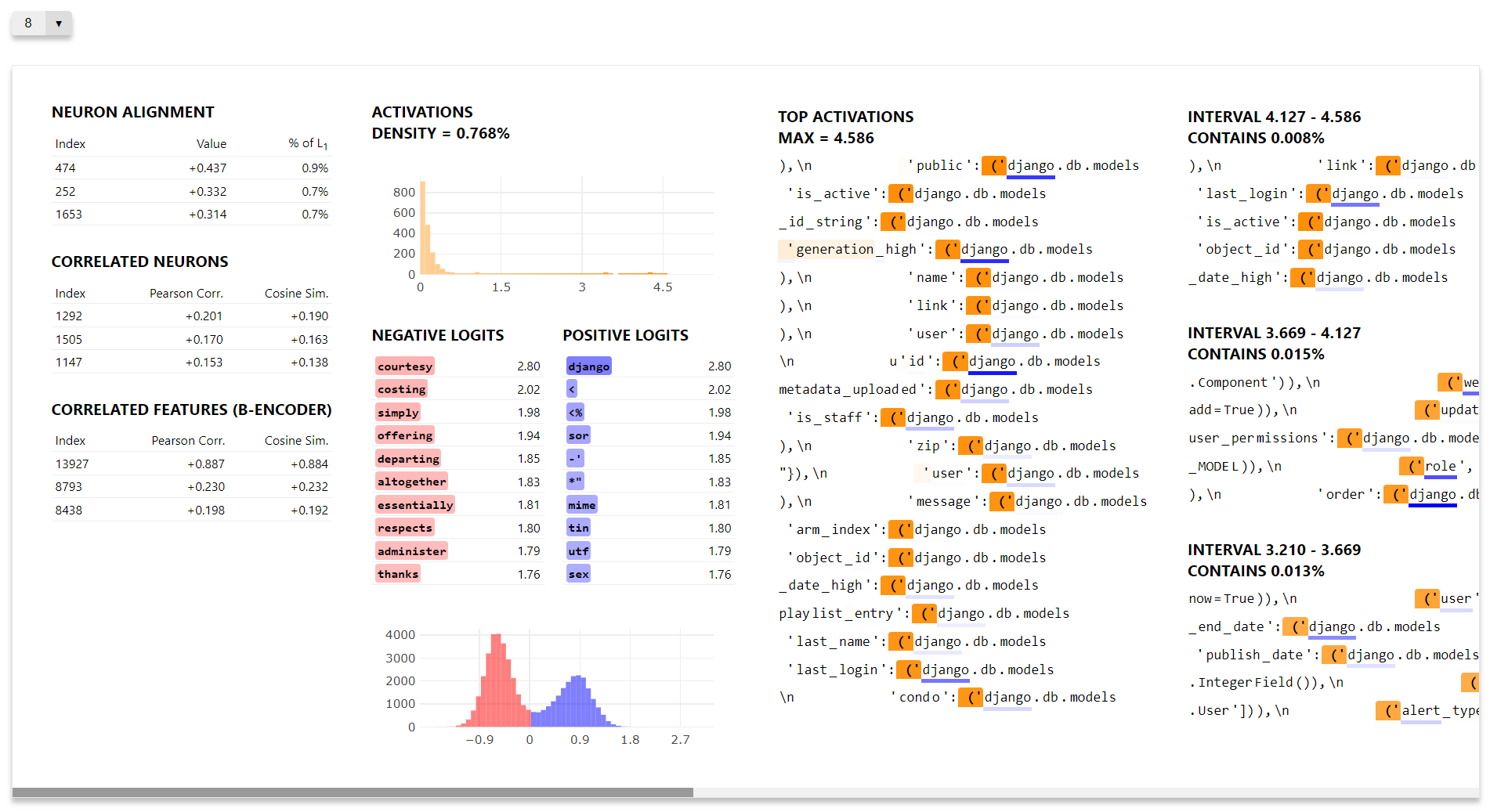
특징 중심 시각화
여기서는 첫 64개의 특징에 대한 데이터를 생성하고, 해당 특징들을 시각화하는 간단한 예시를 제공합니다.
이 시각화를 열면, 토큰 위에 마우스를 올려 각 특징의 활성화 크기 또는 가장 크게 활성화된 토큰을 확인할 수 있습니다. 또한, 왼쪽 상단의 드롭다운 메뉴를 통해 다양한 특징 간에 쉽게 이동할 수 있습니다.
설명하자면, 이 시각화 방식은 각 특징이 데이터셋의 어떤 부분에서 강하게 활성화되는지를 직관적으로 확인할 수 있게 해줍니다. 드롭다운을 사용하면 특정 특징을 선택해 상세하게 분석할 수 있으며, 이를 통해 오토인코더의 각 특징이 데이터에 어떻게 반응하는지 파악할 수 있습니다.
# Specify the hook point you're using, and the features you're analyzing
sae_vis_config = SaeVisConfig(
hook_point = utils.get_act_name("post", 0),
features = range(64),
verbose = True,
)
# Gather the feature data
sae_vis_data = SaeVisData.create(
encoder = encoder,
encoder_B = encoder_B,
model = model,
tokens = all_tokens[:2048],
cfg = sae_vis_config,
)
# Save as HTML file & display vis
filename = "_feature_vis_demo.html"
sae_vis_data.save_feature_centric_vis(filename, feature_idx=8)
display_vis_inline(filename)
특징 중심 시각화: 레이아웃 사용자 정의
시각화 레이아웃을 사용자 정의하기 위해, 메인 SaeVisConfig에 SaeVisLayoutConfig 객체를 전달합니다. 이 객체는 각 열에 들어갈 구성 요소의 목록을 지정하여 작동하며, 각 구성 요소는 관련된 설정 객체를 통해 세부적으로 설정할 수 있습니다.
help 메서드를 사용하여 이러한 매개변수들에 대해 설명을 볼 수 있습니다. 아래 셀을 실행하면 기본 레이아웃에 대한 출력 결과를 확인할 수 있습니다 (즉, 위 셀에서 시각화를 생성한 레이아웃입니다).
요약하자면, SaeVisLayoutConfig를 통해 각 열의 구성을 세밀하게 조정할 수 있습니다. 예를 들어, 특정 특징을 강조하거나 다양한 구성 요소를 추가하여 원하는 방식으로 시각화 레이아웃을 맞춤 설정할 수 있습니다. help 메서드를 사용하면 각 매개변수의 역할을 쉽게 이해할 수 있어 설정을 좀 더 직관적으로 다룰 수 있습니다.
from sae_vis.data_config_classes import (
SaeVisLayoutConfig,
Column,
FeatureTablesConfig,
ActsHistogramConfig,
LogitsTableConfig,
LogitsHistogramConfig,
SequencesConfig,
PromptConfig, # this one is only used for the prompt-centric vis
)
layout = SaeVisLayoutConfig(
columns = [
Column(FeatureTablesConfig()),
Column(ActsHistogramConfig(), LogitsTableConfig(), LogitsHistogramConfig()),
Column(SequencesConfig()),
]
)
layout.help()다음은 몇 가지 구성 요소를 변경하고 그 모양을 수정하여 레이아웃을 사용자 정의하는 예시입니다. 여기서 중요한 점은 layout 객체를 SaeVisData.create 메서드에 전달해야 한다는 것입니다. 그 이유는 일부 매개변수가 어떤 데이터를 수집할지 결정하기 때문입니다.
요약하면, layout 객체는 시각화의 구성을 조정하며 SaeVisData.create 메서드에서 사용하는 데이터의 양과 형식을 결정합니다. 예를 들어, 시각화에서 더 많은 데이터를 보여주기 위해 열의 수를 늘리거나 특정 구성 요소의 모양을 조정할 수 있습니다. 에러 메시지는 필요한 데이터가 누락될 때 경고를 표시하여 사용자에게 명확한 피드백을 제공합니다.
# Create custom layout
layout = SaeVisLayoutConfig(
columns = [
Column(SequencesConfig(stack_mode='stack-all', buffer=None, n_quantiles=0, top_acts_group_size=30), width=1000),
Column(ActsHistogramConfig(), FeatureTablesConfig(n_rows=5), width=500),
],
height = 1000,
)
# Set all config parameter
feature_vis_config_custom_layout = SaeVisConfig(
hook_point = utils.get_act_name("post", 0),
features = range(16),
feature_centric_layout = layout,
)
# Generate data
sae_vis_data_custom = SaeVisData.create(
encoder = encoder,
encoder_B = encoder_B,
model = model,
tokens = all_tokens[:1024, :64], # type: ignore
cfg = feature_vis_config_custom_layout,
)
# Save & display vis
filename = "_feature_vis_demo_custom.html"
sae_vis_data_custom.save_feature_centric_vis(filename, feature_idx=8)
display_vis_inline(filename)

현재까지는 단일 레이어 모델만 다뤘습니다. 이제 다층 모델을 사용할 때 어떤 결과가 나오는지 확인해 보겠습니다. 다행히 Joseph Bloom이 GPT2-small 모델에 대해 우수한 희소 오토인코더(SAE)를 학습시켰으므로, 이를 활용할 수 있습니다.
먼저, 모델과 오토인코더를 로드합니다.
설명하자면, 단일 레이어에서 다층 모델로 전환함으로써 각 레이어가 입력을 어떻게 변형하는지 살펴볼 수 있습니다. 다층 모델은 복잡한 특징을 학습할 가능성이 높기 때문에, 더 깊은 구조에서 특징이 어떤 방식으로 활성화되는지 이해하는 데 유용할 것입니다.
print("Code currently doesn't run, because of dependency issue in SAELens. Will be fixed soon!")
# Get gpt2 model
gpt2 = HookedTransformer.from_pretrained("gpt2-small")
gpt2.to(device);
# Get autoencoder
hook_point = "blocks.0.hook_resid_pre"
sae_path = hf_hub_download(
repo_id = "jbloom/GPT2-Small-SAEs-Reformatted",
filename = f"{hook_point}/sae_weights.safetensors"
)
gpt2_sae = SparseAutoencoder.load_from_pretrained(os.path.dirname(sae_path))
gpt2_sae.to(device);이제 시각화를 생성해 보겠습니다. 힘을 느껴보세요!
여기서 주의할 점은 시간 복잡도가 순전파(forward pass)에 의해 지배된다는 것입니다. 이는 하나의 특징만을 가져오기 때문입니다. 또한, 이번 시각화에는 드롭다운 메뉴가 없는데, 그 이유는 단일 특징만을 시각화하기 때문입니다.
설명하자면, 다층 모델을 사용하는 경우, 순전파 과정이 복잡해질 수 있지만, 하나의 특징만을 시각화할 때는 계산 부담이 줄어듭니다. 따라서 다층 구조에서 특정 특징이 어떻게 활성화되는지 확인할 수 있으며, 여기서는 단일 특징을 더 깊이 분석하는 데 중점을 둡니다.
torch.cuda.empty_cache()
import gc
gc.collect()
test_feature_idx_gpt = 14057
feature_vis_config_gpt = SaeVisConfig(
hook_point = hook_point,
features = test_feature_idx_gpt,
verbose = True,
)
sae_vis_data_gpt = SaeVisData.create(
encoder = gpt2_sae,
model = gpt2,
tokens = all_tokens[:8192],
cfg = feature_vis_config_gpt,
)
filename = "_feature_vis_demo_gpt.html"
sae_vis_data_gpt.save_feature_centric_vis(filename)
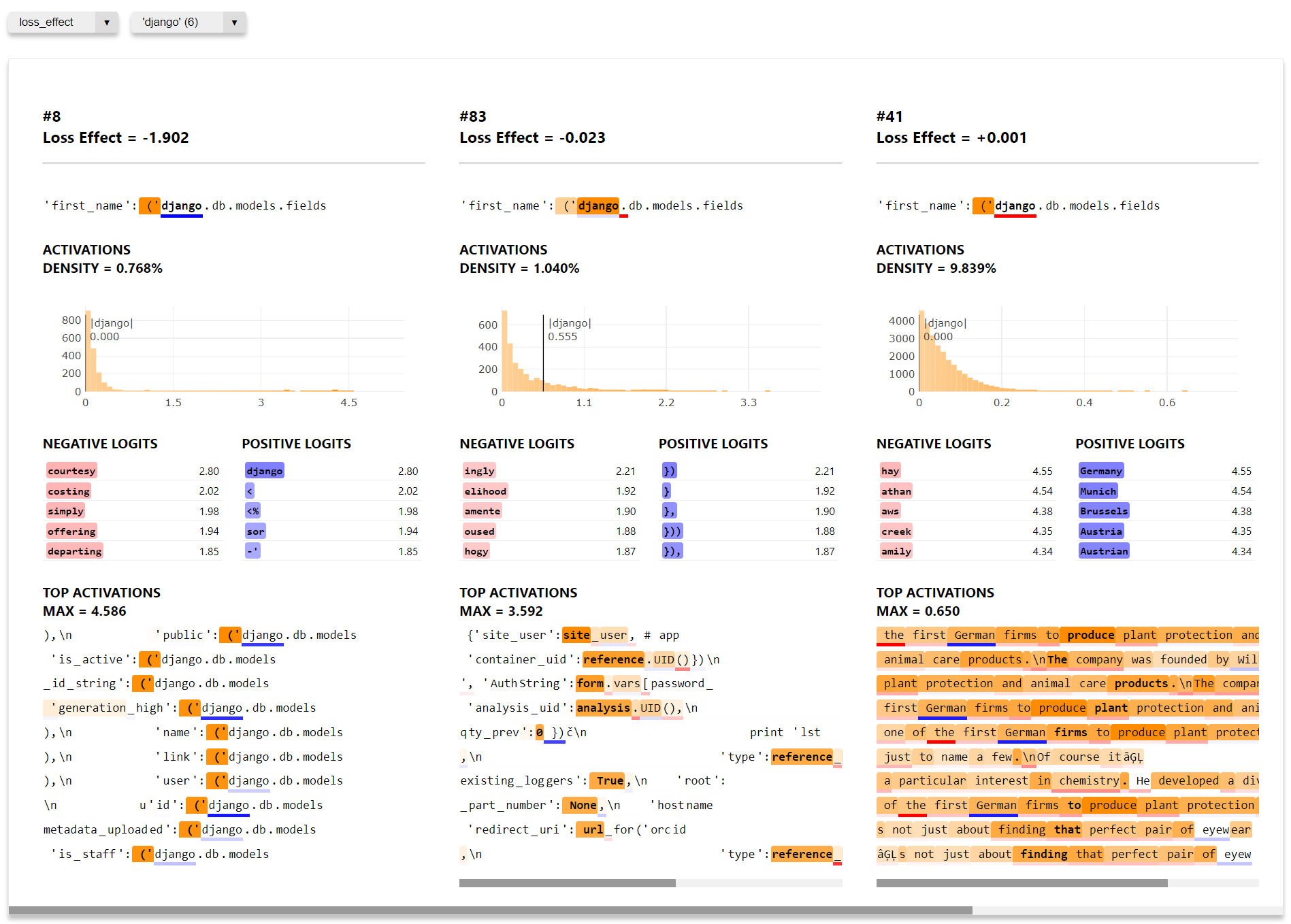
display_vis_inline(filename)프롬프트 중심 시각화
이 시각화에서는 프롬프트를 선택한 후, 다양한 메트릭을 기준으로 해당 프롬프트에서 가장 높은 점수를 기록한 특징들을 확인합니다.
먼저, 위에서와 동일한 단계를 수행하되, 이번에는 sae_vis_data 객체에 대해 save_prompt_centric_vis 메서드를 호출합니다. 또한 프롬프트를 전달해야 하며, 옵션으로 seq_pos와 metric 인수를 추가할 수 있습니다. 이들은 페이지가 로드될 때 기본적으로 선택되는 드롭다운 옵션을 설정합니다.
설명하자면, 프롬프트 중심 시각화는 특정 문장(프롬프트)에 대해 오토인코더의 특징들이 얼마나 활성화되는지 확인할 수 있는 방법입니다. 이 과정에서 다양한 메트릭을 사용해 프롬프트에 가장 강하게 반응하는 특징을 분석할 수 있으며, 이는 모델이 특정 입력에 대해 어떤 식으로 반응하는지 깊이 있게 이해하는 데 도움이 됩니다.
torch.cuda.empty_cache()
import gc
gc.collect()
# Specify the hook point you're using, and the features you're analyzing
sae_vis_config = SaeVisConfig(
hook_point = utils.get_act_name("post", 0),
features = range(256),
verbose = True,
)
# Gather the feature data
sae_vis_data = SaeVisData.create(
encoder = encoder,
encoder_B = encoder_B,
model = model,
tokens = all_tokens[:2048],
cfg = sae_vis_config,
)prompt = "'first_name': ('django.db.models.fields"
seq_pos = model.tokenizer.tokenize(prompt).index("Ġ('") # type: ignore
metric = 'act-quantiles'
filename = "_prompt_vis_demo.html"
sae_vis_data.save_prompt_centric_vis(
prompt = prompt,
filename = filename,
seq_pos = seq_pos, # optional argument, to determine the default option when the page loads
metric = metric, # optional argument, to determine the default option when the page loads
)
display_vis_inline(filename, height=1200)특징 중심 시각화와 마찬가지로, 프롬프트 중심 시각화에서도 보기를 사용자 정의할 수 있습니다. 특징 중심 보기는 기본적으로 sae_vis_data.feature_centric_layout 객체를 통해 다음과 같이 설정되었습니다:
SaeVisLayoutConfig(
columns = [
Column(FeatureTablesConfig()),
Column(ActsHistogramConfig(), LogitsTableConfig(), LogitsHistogramConfig()),
Column(SequencesConfig()),
]
)반면, 프롬프트 중심 보기는 기본적으로 sae_vis_data.prompt_centric_layout 객체를 통해 설정됩니다:
SaeVisLayoutConfig(
columns = [
Column(PromptConfig(), ActsHistogramConfig(), LogitsTableConfig(n_rows=5), SequencesConfig(n_quantiles=0), width=450),
],
)특징 중심 보기와 동일한 방식으로 사용자 정의할 수 있지만, 두 가지 조건을 추가로 고려해야 합니다:
- 열은 하나만 있어야 합니다 (이 시각화에서는 각 상위 특징에 한 개의 열을 할당하기 때문입니다).
- 프롬프트 중심 시각화가 특징 중심 시각화보다 더 많은 데이터를 요구해서는 안 됩니다. 이는
sae_vis_data에 포함된 데이터가 프롬프트 중심 레이아웃에 의해 결정되기 때문입니다. 예를 들어, 특징 중심 설정에서LogitsTableConfig(n_rows=10)을 사용했다면, 프롬프트 중심 시각화 생성 시LogitsTableConfig(n_rows=15)을 사용할 수 없습니다.
이 두 조건은 구성 객체를 초기화할 때, 데이터를 수집하기 전에 확인됩니다.
아래는 예시로 제공하는 프롬프트 중심 레이아웃의 사용자 정의 예시입니다. 참고로, 이미 수집한 데이터보다 더 많은 데이터를 사용하려고 하지 않는 한, 데이터를 새로 생성하지 않고도 sae_vis_data.cfg.prompt_centric_layout을 수동으로 변경할 수 있습니다 (특징 데이터에도 동일하게 적용됩니다).
설명하자면, 프롬프트 중심 시각화에서 필요한 열 수와 데이터 제한 사항을 준수하면, 원하는 대로 구성 요소를 추가하여 보기를 조정할 수 있습니다. 이 방식을 통해 모델의 특정 프롬프트에 대한 반응을 좀 더 세밀하게 분석할 수 있습니다.
sae_vis_data.cfg.prompt_centric_layout = SaeVisLayoutConfig(
columns = [
Column(PromptConfig(), LogitsTableConfig(), LogitsHistogramConfig(), ActsHistogramConfig(), SequencesConfig(n_quantiles=10), width=550),
],
height = 1200,
)
filename = "_prompt_vis_demo_custom.html"
sae_vis_data.save_prompt_centric_vis(
prompt = prompt,
filename = filename,
seq_pos = seq_pos,
metric = metric,
)
display_vis_inline(filename, height=1200)데이터를 JSON 파일로 저장하기
다음과 같이 데이터를 JSON 파일로 저장할 수 있습니다. 하지만 이를 통해 실제로 저장 공간을 많이 절약할 수 있는 것은 아닙니다. HTML은 이미 매우 간결하게 저장되며, JSON 데이터는 HTML 페이지 내에 직접 삽입됩니다. 추가로 필요한 대부분의 공간은 빈 HTML 요소에 데이터를 채우기 위해 사용되는 JavaScript 함수들 때문입니다.
설명하자면, 데이터를 JSON 형식으로 저장하면 다른 프로그램이나 환경에서도 쉽게 활용할 수 있습니다. 그러나 이 경우 HTML 파일 크기에서 JavaScript 함수들이 차지하는 비율이 높기 때문에 JSON을 별도로 저장한다고 해서 큰 용량 절약을 기대하기는 어렵습니다.
json_filepath = "_feature_vis_demo.json"
html_filepath = "_feature_vis_demo.html"
# Save
t0 = time.time()
sae_vis_data.save_json(filename=json_filepath)
print(f"Saved in {time.time() - t0:.2f} seconds")
# Load back in (supplying our config, model & encoders which aren't saved)
t0 = time.time()
sae_vis_data_loaded = SaeVisData.load_json(
filename=json_filepath,
cfg=sae_vis_data.cfg,
model=model,
encoder=encoder,
encoder_B=encoder_B,
)
assert isinstance(sae_vis_data_loaded, SaeVisData)
print(f"Loaded in {time.time() - t0:.2f} seconds\n")
# Check we can still use it
sae_vis_data_loaded.save_feature_centric_vis(html_filepath, feature_idx=8)
display_vis_inline(html_filepath)
# Print out sizes, to see how much we save using json (answer = not much, because the HTML is already quite efficient!)
print(f"Size of JSON: {os.path.getsize(json_filepath) / 1e6:.3f} MB")
print(f"Size of HTML: {os.path.getsize(html_filepath) / 1e6:.3f} MB")