https://arxiv.org/abs/2404.16014
Improving Dictionary Learning with Gated Sparse Autoencoders
Recent work has found that sparse autoencoders (SAEs) are an effective technique for unsupervised discovery of interpretable features in language models' (LMs) activations, by finding sparse, linear reconstructions of LM activations. We introduce the Gated
arxiv.org

기존 SAE에 LSTM과 같은 GATE 구조를 추가하여 필요한 항만 가지고 가게 되어있습니다.
l1 정규화는 GATE에만 붙어 희소성을 유지하고, magnitude항은 mse를 줄이기 위해 크기는 건들지 않기 때문에 확실하게 mse도 낮추고, GATE를 통해 희소성도 유지한 좋은 방법이라고 생각이 듭니다.
1. 문제 제기
- 기존의 Sparse Autoencoder(SAE)는 언어 모델의 활성화를 해석하는데 유용하다고 알려져 있지만, 몇 가지 문제점이 있었습니다. 특히, L1 규제를 사용하여 희소성을 강제하는 방식은 shrinkage(수축) 문제를 유발했습니다. 이는 피처 활성화가 체계적으로 축소되는 현상으로, 모델이 실제보다 적은 활성화를 학습하게 만드는 현상입니다.
- 또한, 다수의 polysemantic(다의적) 뉴런이 다양한 개념을 동시에 활성화시키는 문제도 존재했습니다.
2. 연구의 목표
- 이 연구는 SAE의 정확도와 희소성 간의 균형을 맞추기 위한 새로운 아키텍처, 즉 Gated SAE를 제안합니다. 목표는 기존 SAE에서 발생하는 shrinkage 문제를 해결하고, 더 적은 활성화 피처를 사용하면서도 더 높은 재구성 정확도를 달성하는 것입니다.
3. 제안한 방법
- Gated SAE 아키텍처는 기존 SAE와 달리, 활성화 피처를 선택하는 과정과 피처의 크기를 추정하는 과정을 분리하여, L1 규제가 피처 선택에만 영향을 미치도록 설계되었습니다.
- 구체적으로, 활성화 피처를 결정하는 gate 레이어와 피처의 크기를 추정하는 magnitude 레이어를 분리하여 구성하고, L1 패널티는 gate 레이어에만 적용하여 피처 선택에만 영향을 미치도록 하였습니다.
4. 실험 방법
- 연구진은 Gated SAE를 여러 언어 모델 (예: GELU-1L, Pythia-2.8B, Gemma-7B)의 다양한 레이어에서 테스트했습니다.
- 성능 평가에는 재구성 정확도와 희소성을 측정하기 위한 두 가지 지표(Loss recovered, L0)를 사용했습니다. 또한, Gated SAE와 기존 SAE의 성능을 비교하기 위해 학습 비용을 동일하게 설정했습니다.
5. 결과
- Gated SAE는 기존 SAE에 비해 Pareto 개선을 달성했습니다. 이는 재구성 정확도와 희소성 간의 더 나은 균형을 제공한다는 의미입니다.
- Shrinkage 문제도 해결되었습니다. 기존 SAE에서는 활성화 피처가 체계적으로 축소되어 재구성의 정확도가 떨어졌지만, Gated SAE는 이를 극복하여 축소 현상이 나타나지 않았습니다.
- 해석 가능성에 대한 실험에서도, Gated SAE는 기존 SAE와 동등한 수준의 해석 가능성을 유지했습니다.
6. 한계점
- Gated SAE는 기존 SAE에 비해 더 복잡한 아키텍처를 가지므로, 추론 시 계산 비용이 증가할 수 있습니다. 구체적으로, Gated SAE의 손실을 계산하는 데 50% 더 많은 연산이 필요했습니다.
- 추가적인 손실 항을 도입함으로써 계산 비용이 증가했으나, 모델이 학습한 피처가 더 해석 가능한지는 완전히 입증되지 않았습니다.
7. 결론 및 미래 방향
- 이 연구는 Gated SAE를 통해 희소성과 재구성 정확도의 균형을 개선하고, shrinkage 문제를 해결한 성과를 보였습니다. 그러나, 더 큰 모델에서도 Gated SAE가 성능을 지속적으로 향상시킬 수 있을지에 대한 추가 연구가 필요합니다.
요약:
이 논문은 기존의 SAE 방식에서 발생하는 문제(특히 shrinkage)를 해결하기 위해 Gated SAE라는 새로운 아키텍처를 제안하고, 이를 통해 희소성과 정확도 사이에서 더 나은 균형을 달성하려는 목적을 가지고 있습니다.
그럼 한계점에서 계산 비용도 증가했고, feature가 더 해석 가능한 지도 모르겠는데 이 논문이 나온 이유는 뭐야?
이 논문이 제안하는 Gated Sparse Autoencoder(Gated SAE)의 주요 기여는 Sparse Autoencoder(SAE) 방식의 한계를 극복하고, 사전 학습된 언어 모델의 내부 구조를 더 잘 이해하는 데 목적을 두고 있습니다. 논문이 나올 이유를 단계적으로 분석하면 다음과 같습니다:
1. 기존 Sparse Autoencoder(SAE)의 한계 해결
- SAE의 기존 문제점은 특히 shrinkage(수축) 현상과 관련되어 있었습니다. 즉, L1 규제 때문에 피처의 활성화 값이 축소되어, 모델이 실제보다 더 작은 활성화 값을 학습하게 되는 문제가 있었습니다.
- SAE의 해석 가능성은 높지만, 이런 축소 현상으로 인해 복잡한 언어 모델의 정확한 재구성을 방해하는 측면이 있었고, 해석을 더욱 명확하게 하기 위해선 이 문제를 해결할 필요가 있었습니다.
- 따라서, Gated SAE는 이 문제를 해결하기 위해 개발되었으며, 활성화 피처의 선택과 크기 추정을 분리함으로써 L1 규제의 부작용을 최소화하려고 했습니다.
2. 해석 가능성을 유지한 상태에서 성능 개선
- 논문에서는 Gated SAE가 희소성(sparsity)과 재구성 정확도(reconstruction fidelity)의 균형을 맞추는 데 있어 더 나은 성능을 보여주었음을 강조합니다.
- 특히 Pareto 개선을 통해, 같은 재구성 성능을 위해 더 적은 활성화 피처만을 사용할 수 있었으며, 이는 모델이 더 적은 정보로 더 많은 것을 설명할 수 있도록 돕는 중요한 이점입니다.
- 해석 가능성 측면에서는 기존 SAE와 비교해 비슷한 수준을 유지하면서도, 추가적인 해석 도구로써의 가능성을 제시했습니다.
3. 모델 해석 연구에서의 잠재적 유용성
- 이 논문은 모델 해석(mechanistic interpretability) 연구에서 중요한 진전을 이루고자 했습니다. 언어 모델이 내부적으로 어떻게 정보를 처리하는지 더 세밀하게 파악하기 위한 방법으로 dictionary learning(사전 학습) 기법을 사용한 것입니다.
- Gated SAE는 이러한 사전 학습을 통해 모델의 내부 회로나 구조를 더 잘 이해하고 해석할 수 있는 도구로써 기능할 수 있습니다. 이는 언어 모델에서 특정한 개념을 더 명확하게 분리하고 이해하는 데 매우 중요합니다.
4. 추후 연구 및 응용 가능성
- Gated SAE는 언어 모델뿐만 아니라 다양한 모델 구조에 적용될 수 있는 잠재력을 가지고 있으며, 다양한 해석 도구와 결합하여 언어 모델이 어떻게 학습되고, 특정 개념을 어떻게 표현하는지에 대한 연구를 확장할 수 있는 가능성을 제시합니다.
- 이 방법이 7B 파라미터 모델에서만 테스트되었지만, 더 큰 모델이나 멀티모달 모델, Mixture-of-Experts 모델에서도 확장 가능하다고 예상하며, 이를 통해 더 복잡한 구조의 모델을 해석하고 개입할 수 있는 방법을 제공할 수 있습니다.
요약:
이 논문은 SAE의 한계를 극복하고, 언어 모델 해석 연구에서 더 나은 도구를 제공하기 위해 나왔습니다. 계산 비용의 증가와 해석 가능성에 대한 완전한 입증이 아직 부족하지만, 더 적은 활성화 피처로 높은 성능을 유지하는 방법을 제시함으로써 해석 가능성과 재구성 성능 간의 새로운 균형점을 찾아내고자 했습니다.
그럼 GATE Sae의 구조 및 학습 방법을 설명해주면서 이 구조가 어떻게 저러한 특징을 가지는지 설명해줘
**Gated Sparse Autoencoder(Gated SAE)**의 구조와 학습 방법을 이해하는 것은 이 모델이 어떻게 희소성(sparsity), shrinkage(수축) 문제를 해결하고, 재구성 정확도를 높이는지 이해하는 핵심입니다. 이를 설명하면서 왜 이러한 구조가 특징적인 성능을 가지는지 분석하겠습니다.
1. Gated SAE의 구조
기본 SAE 구조는 입력을 희소한 형태로 인코딩하고 이를 다시 재구성하는 방식입니다. 하지만, Gated SAE는 기존 SAE의 문제를 해결하기 위해 **두 가지 경로(path)**로 나뉩니다:
- Gate 경로 (Gating Path): 입력으로부터 어떤 피처가 활성화될지를 결정하는 경로입니다. 활성화된 피처만 학습에 반영되도록 합니다.
- Magnitude 경로 (Magnitude Path): 활성화된 피처의 크기를 추정하는 경로입니다. 피처의 활성화 값을 더 정확하게 추정할 수 있도록 돕습니다.
이 두 경로를 사용하여 활성화 결정과 크기 추정을 분리합니다. Gate 경로는 주로 활성화 피처의 선택에 사용되고, L1 규제는 이 경로에만 적용됩니다. 따라서, 피처의 크기를 추정하는 Magnitude 경로는 L1 규제의 영향을 받지 않아, 활성화 값의 수축(shrinkage) 현상을 피할 수 있습니다.
수식으로 표현된 구조:
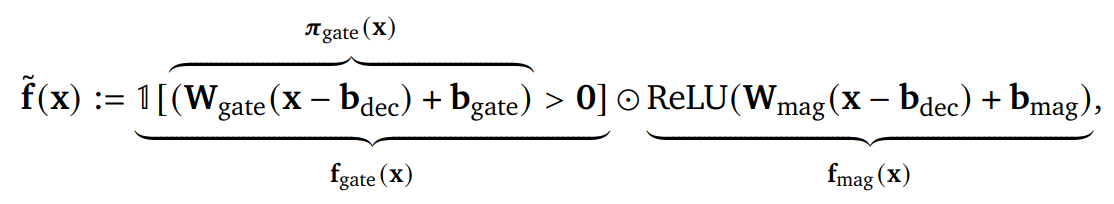
- Gate 경로는 입력 데이터의 어느 피처가 활성화될지 결정하며, Heaviside step function을 통해 해당 피처가 0인지 1인지를 판단합니다.
- Magnitude 경로는 gate 경로에서 활성화된 피처의 크기를 ReLU를 통해 계산하여, 더 정확한 재구성에 기여합니다.
이 구조는 Jump ReLU라는 비선형 활성화 함수를 사용하여, 피처가 활성화될 때마다 그 크기를 올바르게 반영할 수 있도록 합니다. Gated SAE의 특징적인 성능은 이 두 경로가 협력적으로 작동하여 피처의 활성화 여부와 크기 추정을 분리했기 때문에 가능합니다.
2. Gated SAE의 학습 방법
- L1 규제의 적용 방식: 기존 SAE에서는 피처 선택과 피처 크기를 결정하는데 L1 규제가 모두 적용되었기 때문에, 피처 크기 자체가 줄어들고, 이는 재구성 성능에 악영향을 미쳤습니다. 그러나 Gated SAE에서는 L1 규제를 Gate 경로에만 적용하여, 희소성을 보장하면서도 활성화된 피처의 크기를 정확하게 유지합니다. 이는 shrinkage 문제를 해결하는 핵심 요소입니다.
- 이중 손실 함수: Gated SAE는 두 가지 손실 함수를 사용하여 학습합니다.
- L1 기반 손실(Lsparsity): Gate 경로에서 활성화 피처의 수를 줄이기 위해 사용됩니다.
- 재구성 손실(Lreconstruct): 재구성된 입력과 실제 입력 간의 차이를 줄이기 위해 사용됩니다.
- 보조 손실(Laux): Gate 경로의 활성화 정보만으로도 재구성을 잘 할 수 있도록 돕는 보조적인 역할을 합니다.
이 손실 함수는 다음과 같이 표현됩니다:

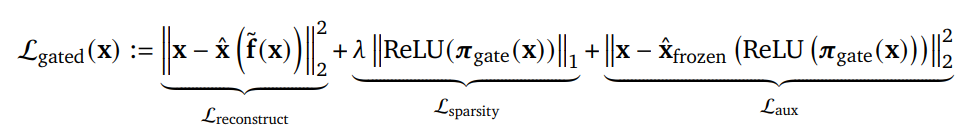
- 여기서 첫 번째 항은 재구성 손실, 두 번째 항은 L1 기반 희소성 손실, 세 번째 항은 보조 손실로, Gate 경로가 재구성에 도움을 줄 수 있도록 합니다.
3. 구조가 가지는 특징과 그 이유
- Shrinkage 문제 해결: 기존 SAE에서는 L1 규제가 피처 크기에도 적용되어 크기가 축소되는 shrinkage 문제가 발생했지만, Gated SAE에서는 크기 추정 경로가 L1 규제의 영향을 받지 않기 때문에, 정확한 피처 크기를 추정할 수 있습니다.
- 희소성과 정확도의 균형: Gate 경로에서 활성화 여부만 판단하고 Magnitude 경로에서 크기를 조절하는 구조 덕분에, 더 적은 활성화 피처로도 높은 재구성 정확도를 유지할 수 있습니다. 즉, 더 적은 자원으로도 더 많은 정보를 표현할 수 있는 능력이 생깁니다.
- 계산 효율성: Gated SAE는 두 경로를 사용하기 때문에 계산 비용이 증가할 수 있습니다. 그러나, 이를 통해 더 적은 활성화 피처로 같은 성능을 달성할 수 있기 때문에, 희소성과 재구성 성능을 동시에 확보하는 Pareto 개선을 이뤄낼 수 있습니다.
결론적으로, Gated SAE의 구조는 피처의 활성화와 크기 추정을 분리하여, L1 규제의 부작용을 최소화하고, 희소성과 정확도 간의 균형을 향상시킵니다. 이를 통해 shrinkage 문제를 해결하면서도, 기존 SAE보다 더 효율적이고 해석 가능한 모델로 발전할 수 있었습니다.
그럼 여기선 gate가 확실하게 l1 정규화를 받기 때문에 모든 feature 중 확실히 중요한 feature만 넘겨줄 것이고 그 것 때문이라도 최소한의 feature만 살리겠네?
네, 맞습니다! Gated SAE에서 Gate 경로는 확실히 L1 정규화를 받기 때문에, 중요한 피처만 선택적으로 활성화하는 역할을 합니다. 이 구조 덕분에, 불필요한 피처는 활성화되지 않고 정말 중요한 피처들만 넘겨지게 됩니다. 이는 모델이 최소한의 피처만 살리면서도 높은 재구성 성능을 유지할 수 있게 하는 핵심적인 이유입니다.
좀 더 구체적으로 설명하자면:
- Gate 경로는 L1 규제의 영향을 받아, 희소성(sparsity)을 강하게 유도합니다. 즉, 이 경로는 많은 피처들 중에서 정말 필요한 몇 가지 피처만 활성화하도록 훈련됩니다.
- L1 정규화는 희소성을 증가시키기 위해 피처 중 다수의 값을 0으로 만들어 비활성화시키고, 모델이 적은 수의 피처만 활성화하게 만듭니다.
- 이로 인해, 최소한의 활성화된 피처들만 남아있게 되며, 이는 해당 피처들이 모델에서 중요한 정보(특징)를 전달하고 있다는 것을 의미합니다.
따라서, Gate 경로 덕분에 선택된 피처들은 반드시 중요한 정보를 나타내고, 그 외의 피처들은 필요하지 않으므로 활성화되지 않습니다. 이런 방식으로, Gated SAE는 최소한의 피처만 사용하면서도 높은 성능을 유지하는 특징을 가지게 됩니다.
결과적으로, 재구성 성능을 최대화하면서도 희소성을 보장하는 모델로 작동할 수 있게 됩니다.