2024.09.27 - [인공지능/자연어 처리] - LLama3 학습 데이터 변환하여 LLama3.2 Sparse Autoencoder 학습하기
LLama3 학습 데이터 변환하여 LLama3.2 Sparse Autoencoder 학습하기
기존에 공개된 학습 데이터를 통해 3.2에 사용할 수 있는 학습 데이터를 만들어 보겠습니다.import csvfrom datasets import load_datasetfrom transformers import AutoTokenizerfrom tqdm import tqdm # 진행 상태 표시를 위한
yoonschallenge.tistory.com
학습 하는 방법은 위의 글을 확인하면 볼 수 있습니다.
그리고 아래 글에서 학습 도중에 나타났던 문제점을 확인할 수 있습니다.
2024.10.04 - [인공지능/자연어 처리] - Sae 학습에 따른 dead_features
Sae 학습에 따른 dead_features
context_length128128128expansion_factor163264latent_size49,15298,304196,608below_1e-5(sparsity)42,60291,309171,941head_features42,25788,793169,247죽은 feature 비율 85.97%90.32%86.08%sparsity한 것 중 죽은 feature 비율 99.19%97.24%98.43%학습
yoonschallenge.tistory.com
Sparse Autoencoder를 학습할 수록 dead featrue가 과하게 증가했고, 이 것이 혹시 Sparse Autoencoder 학습에 악 영향을 끼치는 것 같았습니다.
일단 여기서 부터는 128 context length에 latent space는 16 * 3072 입니다.

l1 loss가 상당히 작은 것을 볼 수 있습니다.
context length가 짧아서 그럴 수도 있겠다는 생각이 들고, l1에 가중치를 너무 큰 게 준 것이 아닌가 싶었습니다. (10 줬었습니다.)
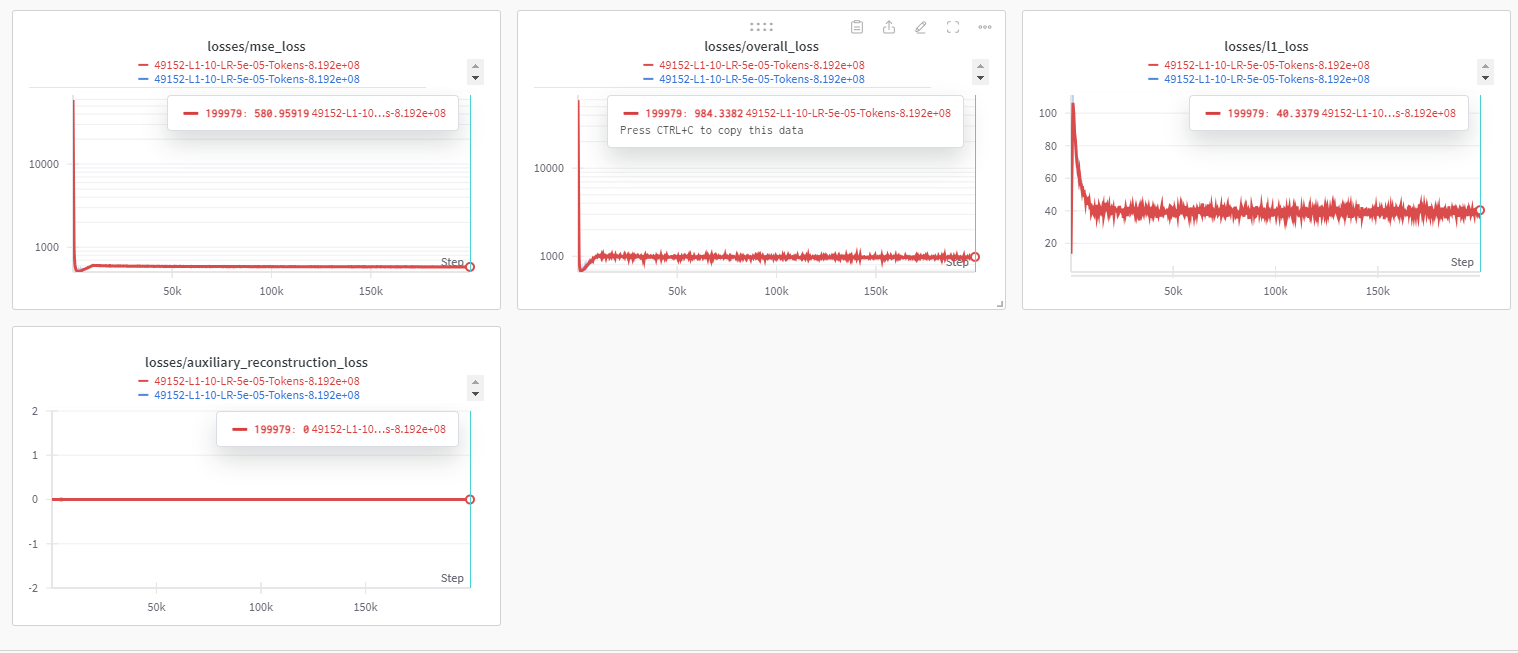

위에서 토큰 수, 학습률과 l1 계수 확인 가능합니다.

feature의 상당 부분이 죽은 것을 확인할 수 있었씁니다.
학습 중반 부분에 많은 feature가 죽은 것을 볼 수 있었는데 우려하던 부분이 여기서 그대로 나왔네요......
일단 여기서 부터는 128 context length에 latent space는 32 * 3072 입니다.

여기서도 l1의 계수를 10을 줬던 것이 문제였던 것 같네요 ㅎㅎ,,,,

여기서도 진짜 몇개 빼고 다 죽은 것을 확인할 수 있습니다.........
여기부턴 학습 도중에 종료된 것이긴 한데 일단 정리 용으로...
일단 여기서 부터는 512 context length에 latent space는 16 * 3072 , l1 coefficent = 5 입니다.
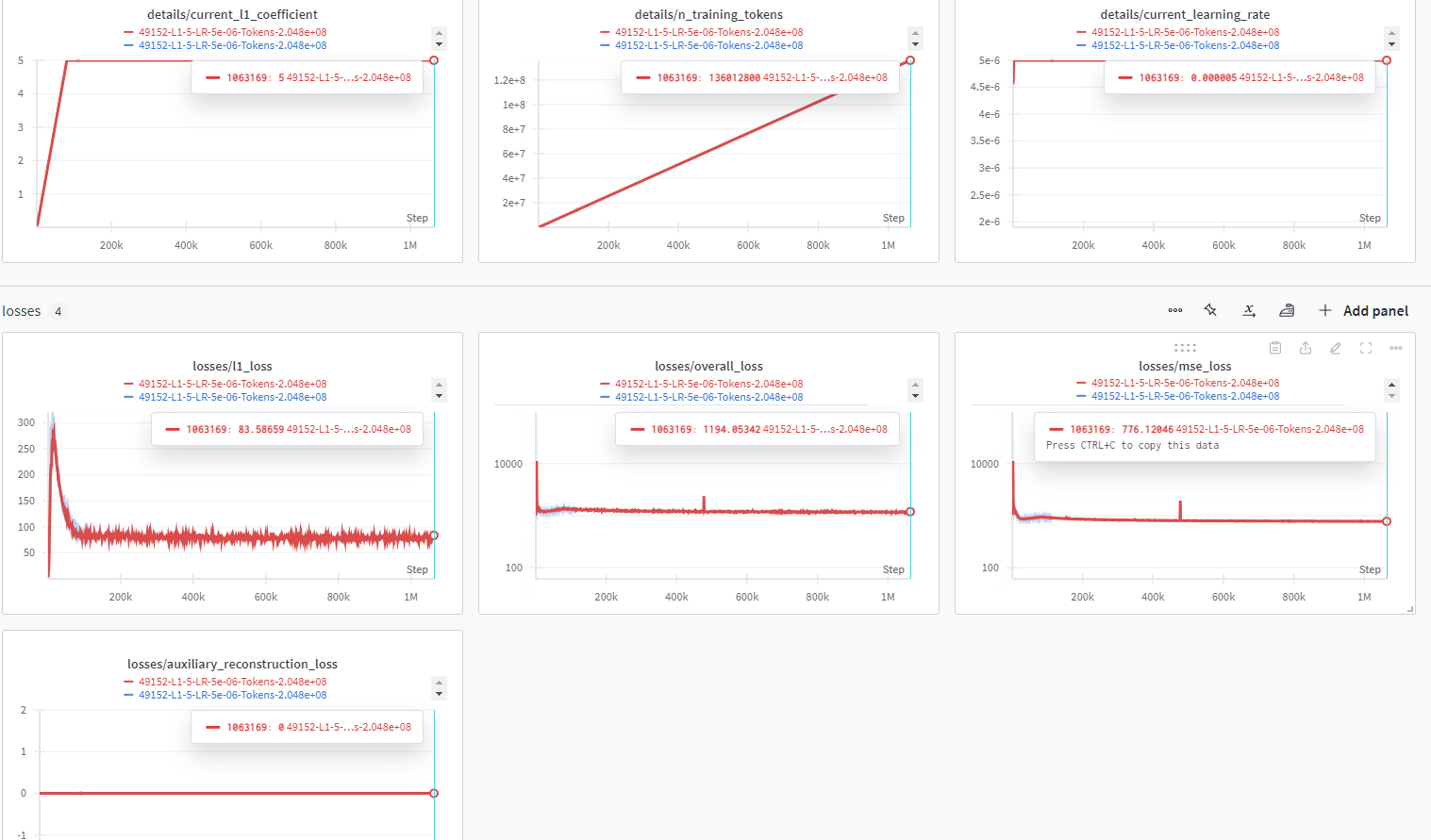

일단 여기서 부터는 512 context length에 latent space는 32 * 3072 , l1 coefficent = 5 입니다.


context length가 길어질 수록 batch size가 급격하게 줄어서 step 수는 엄청나게 느는 것을 볼 수 있습니다.
일단 여기서 부터는 1024 context length에 latent space는 16 * 3072 , l1 coefficent = 5 입니다.
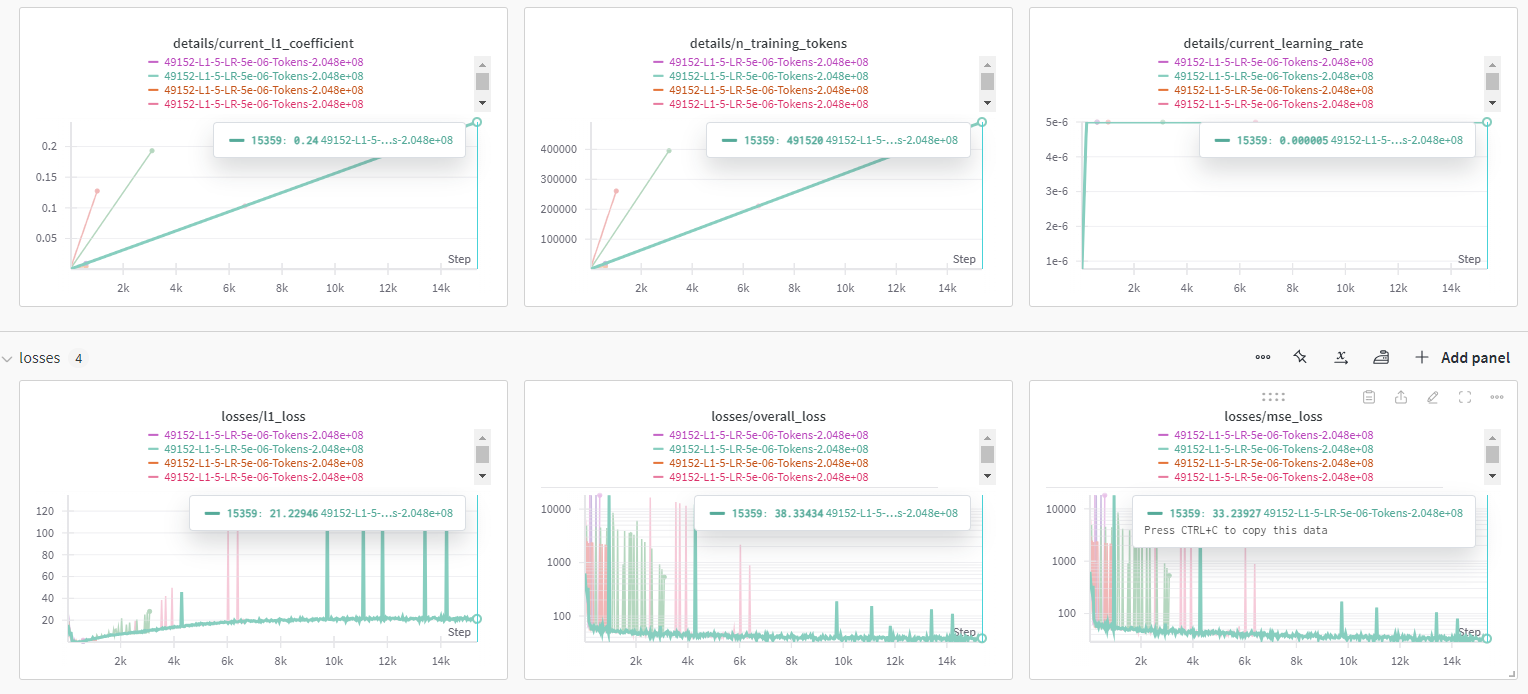
loss가 굉장히 낮은데 이 이유는 명확히 모르겠씁니다.
진짜 모르는게 많네요...
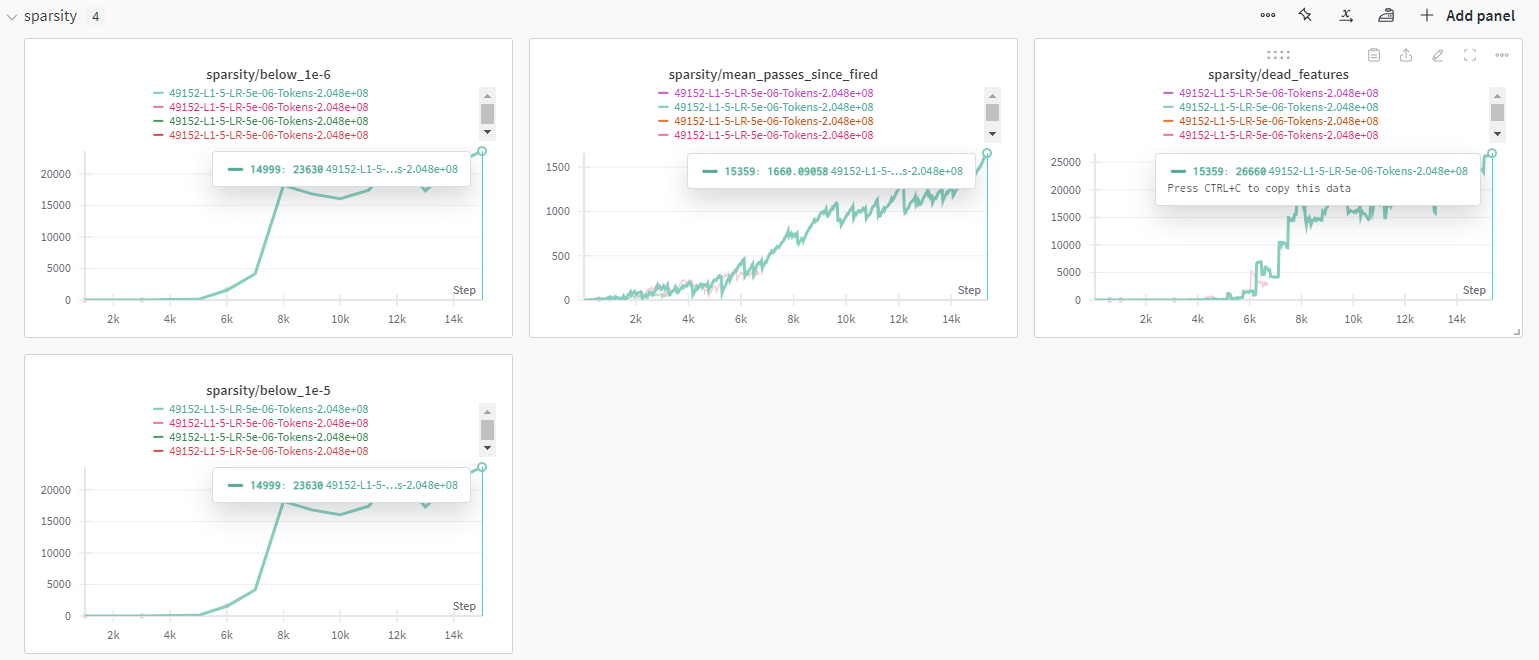
dead feature는 아마 파라미터를 제가 잘 못 설정해서 이렇게 나왔을 겁니다...
일단 엄청 많이 죽었습니다...ㅠ
'인공지능 > XAI' 카테고리의 다른 글
| l1 Coefficient에 따른 Sparse Autoencoder 학습, 출력 확인 (0) | 2024.10.15 |
|---|---|
| Sparse Autoencoder 학습 - l1 regularization coefficient에 따른 학습 변화 (0) | 2024.10.13 |
| Sae 학습에 따른 dead_features (2) | 2024.10.04 |
| LLama3 학습 데이터 변환하여 LLama3.2 Sparse Autoencoder 학습하기 (3) | 2024.09.27 |
| SAE 통해 특정 feature를 강화시켜 LLM 출력 변형하기 - 미스트랄 mistral 7b (2) | 2024.09.26 |