여태까지 FCN, CNN, CAM 모두 supervised learning였다. 즉 지도학습으로 input(data)와 정답(label)이 주어지는 학습이었다.
그러나 오늘 다룰 Autoencoder는 label이 없는 즉 정답이 input인 unsupervised learning이다. 나중에 나오겠지만 차원을 축소시켜 피쳐의 개수를 줄이고, 정보의 loss는 최대한 줄인다.
우린 encoder(z = f(x))와 decoder(x = g(z))로 나눌 수 있따. ( x = g(f(x)))
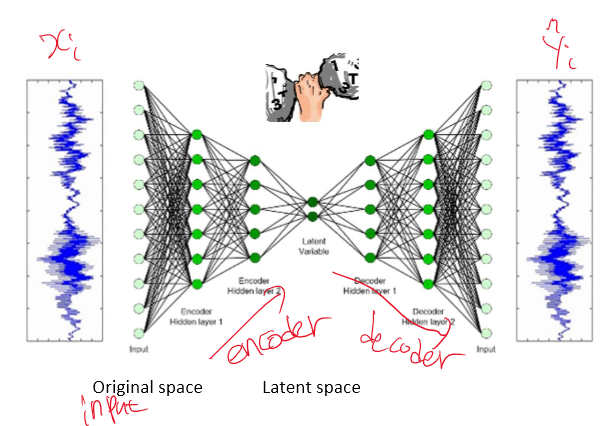
로스는 결과와 입력값의 차이를 제곱하는 mse와 비슷한 성격을 가지고 있다.
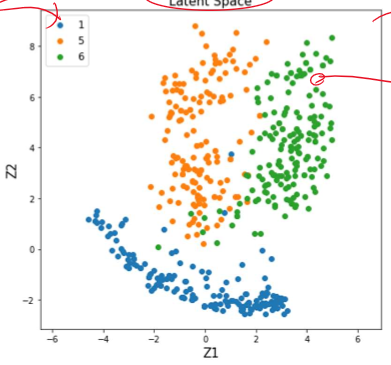
latent space를 그래프로 표시하면 위와 같다. 여기서 점이 없는 부분을 decoder로 돌리면 없는 data를 생산할 수 있다. 그러나 여기서 만드는 data의 성능은 그렇게 좋지 않다. 그건 나중에 GAN이나 VAE에서 다뤄보고, 여기선 일단 MNIST만 활용해 본다.
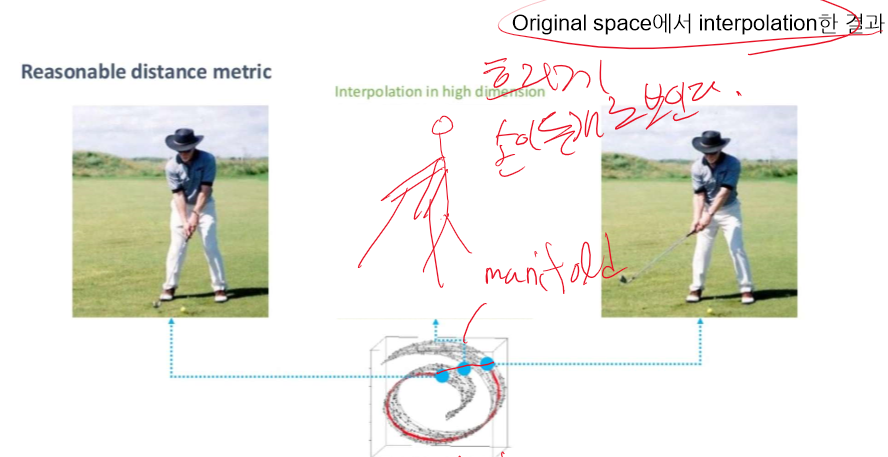
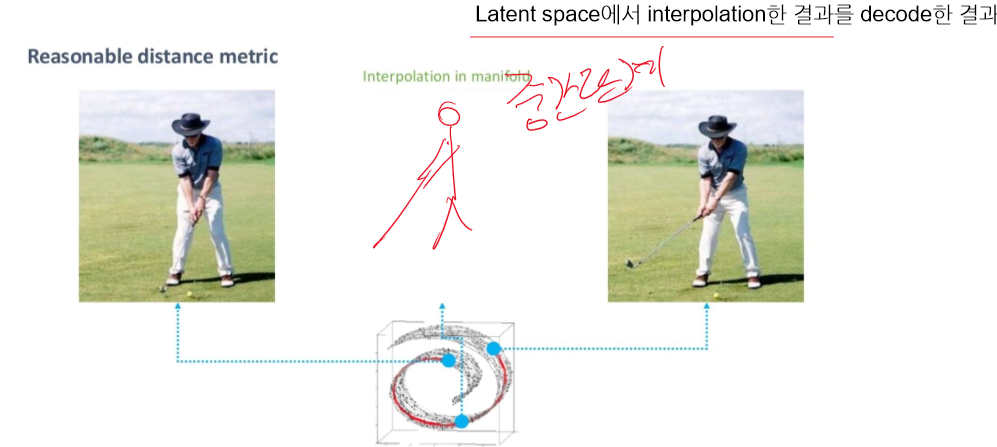
mnist에서 더 쉽게 보여줄 수 있다.
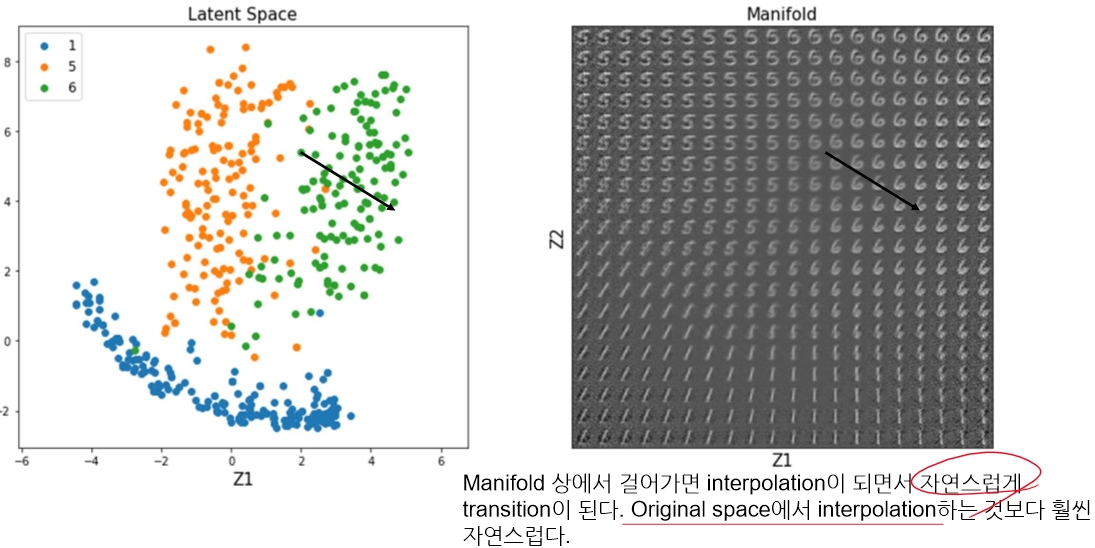
근데 FCN은 층을 줄이든 늘리든 자연스럽지만, convolution을 사용하면 층이 늘고, 크기는 작아지는데 크기를 어떻게 키울까?
여기선 transposed convolution layers를 사용한다.
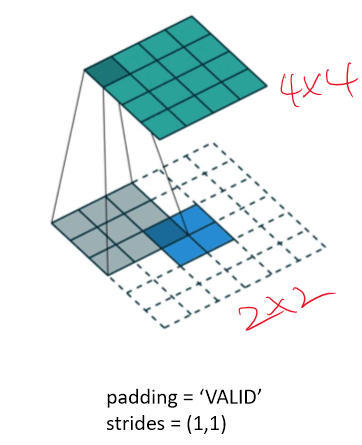
여기선 stride = 1, filter = 3, padding = 0으로 upsampling하는 과정이다.

위와는 stride=2로 변해진 것만 같다.
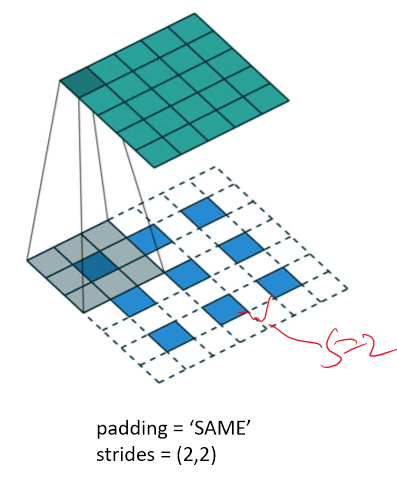
여기선 s = 2 , p = 1, f =3으로 원래는 (5*5 - > 3*3)이 되는 과정이 transposed된 것이다.
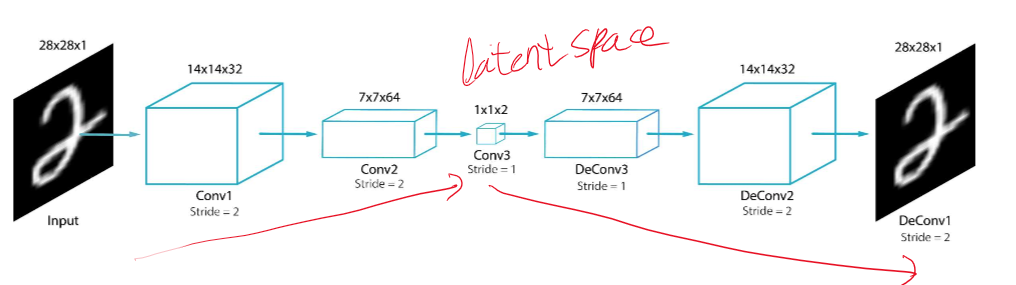
위 사진을 정리하면 이렇게 된다. 아래는 코드로 보여주겠다.
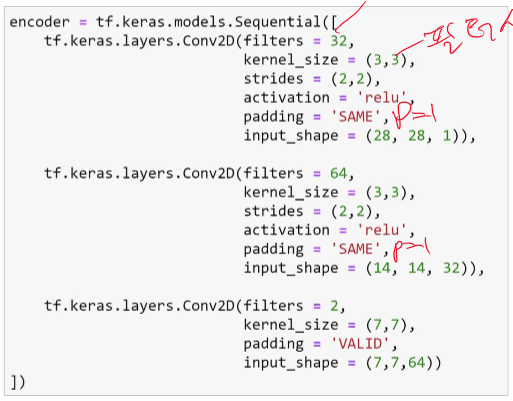
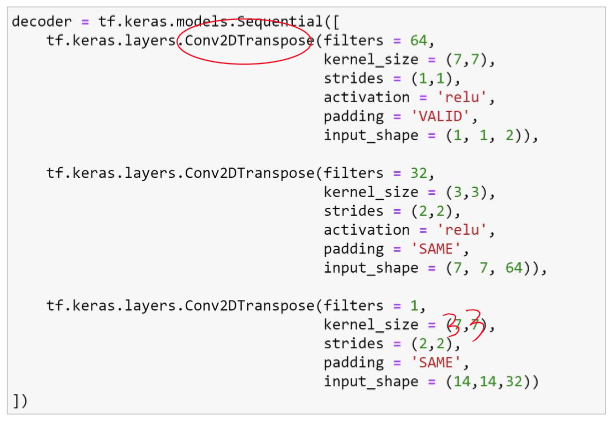
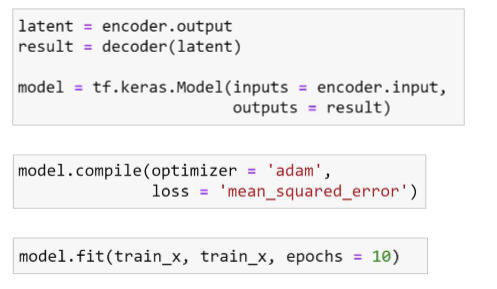
위와 같은 코드를 쭉 따라해보면

이런 결과를 얻을 수 있다.
차원 축소, 이상치 제거(noise reduction), 중복인자를 제거하는 효과적인 방법이다.
2023.12.15 - [인공지능/공부] - 물체의 위치까지 구분하는 인공지능 -segmentation, odject detection
물체의 위치까지 구분하는 인공지능 -segmentation, odject detection
여태까지 CNN으로 물체가 있다, 없다 정도만 알았다면 이번에 해볼 것은 어디 위치에 물체가 있는지 알려주는 segmentation이다. classification은 전체 input에 대해 오직 한개의 결과만 나오고, 한가지 cl
yoonschallenge.tistory.com
'인공지능 > 공부' 카테고리의 다른 글
| 생성형 인공지능 GAN 개념 - autoencoder의 업그레이드 버전 (45) | 2023.12.15 |
|---|---|
| 물체의 위치까지 구분하는 인공지능 -segmentation, odject detection (45) | 2023.12.15 |
| CAM 실습 - MNIST, TensorFlow (0) | 2023.12.14 |
| 설명 가능한 인공지능 CAM - 개념 (0) | 2023.12.14 |
| CNN - 기본 개념 (32) | 2023.12.13 |