
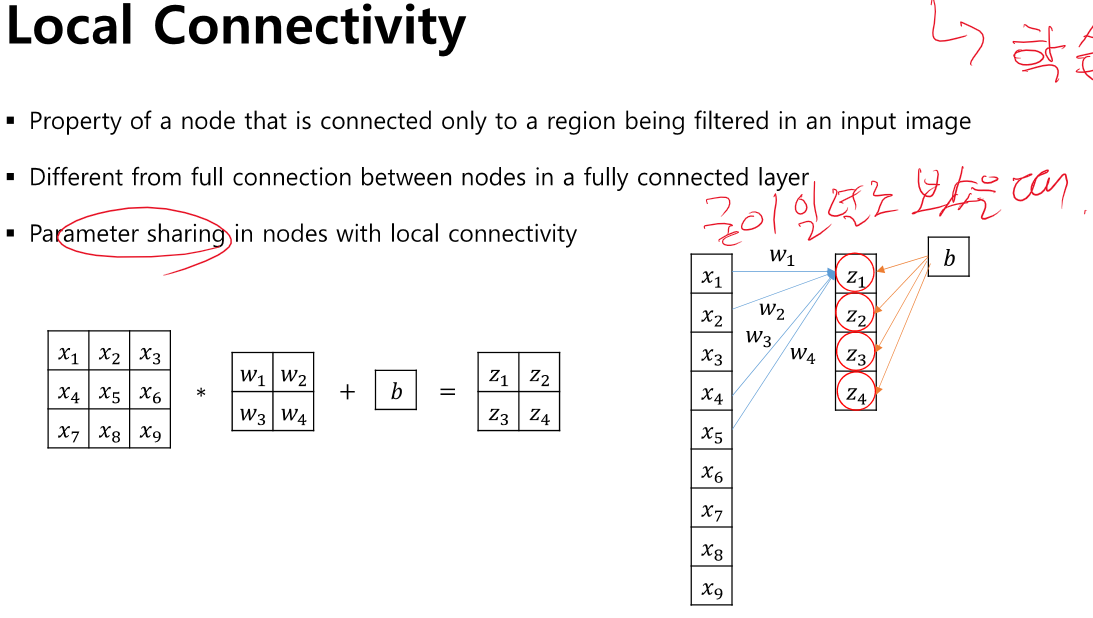
우리는 여태까지 FCN으로 tensorflow에서 Dense만 사용해왔다. 그러나 사진과 같은 경우엔 해상도가 만만치 않아 대충 1000*1000이라고 하면 일렬로 나열하면 1000000이 된다. 이게 Dense layer 하나만 거쳐서 100개로 줄어든다해도 100,000,000 1억개의 파라미터가 존재하게 된다. 이 것은 확실한 컴퓨터소스를 잘 활용하지 못하는 것이다.
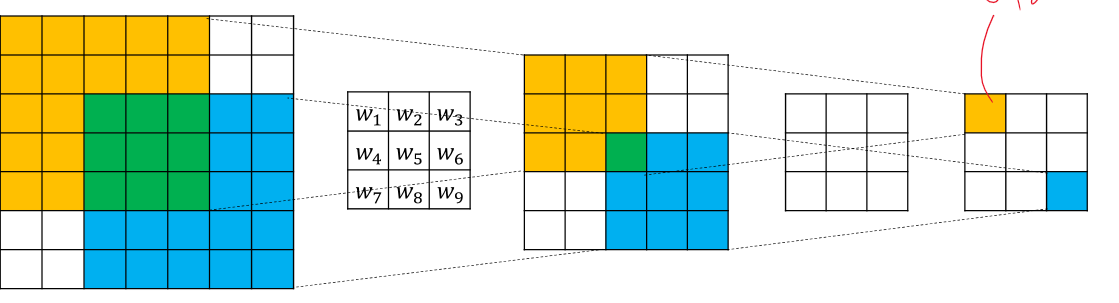
그래서 위와 같이 필터를 사용하여 파라미터 9개만 사용하여 피쳐수도 줄이고, 중요한 정보만 가져오는 방식을 만들었다.

피쳐 수를 줄이고 싶지 않을 때 padding을 사용하게 된다. 그럼 0으로 padding 수 만큼 겹겹히 쌓아서 필터를 거쳐도 피쳐 수가 줄지 않게 해준다. 필터 크기가 3이면 패딩은 1, 필터 크기가 5이면 패딩은 2... 이렇게 나아간다.
패딩 적용 후 다음 피쳐의 크기는 (n + 2p - f + 1)* (n + 2p - f + 1) 이다.

stride는 피쳐의 수를 확 줄여준다. 중복해서 봐주는 분이 사라지고, 결과의 크기를 줄여서 계산 량을 확실하게 줄이는 것이다. 결과의 크기는 ((n + 2p - f)/s +1)* ((n + 2p - f)/s +1) 이고 연산 결과는 항상 내림이다. s=1일 땐 이전과 같은 결과이고 stride가 커질수록 결과는 점점 작아지게 된다.
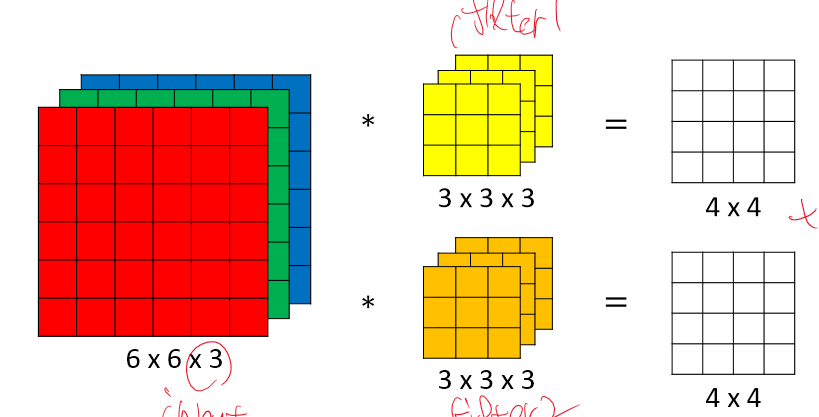
input이 n*n*3이라면 filter는 항상 f*f*3이어야 한다. 그 후 그 필터의 개수가 다음 레이어에서 쓰일 input의 층 수이다. 그리고 여기서 파라미터의 수는 (3*3*3(filter)+1(bias)) * 2(층수) = 56이다. 그 후 sigmoid든 ReLU든 activation function을 사용한다.

위 사진은 MAX POOLING으로 보통 s=2로 해서 크기를 절반으로 줄여준다. 중요한 값들만 뽑아서 액기스를 뽑는다 라고도 한다.
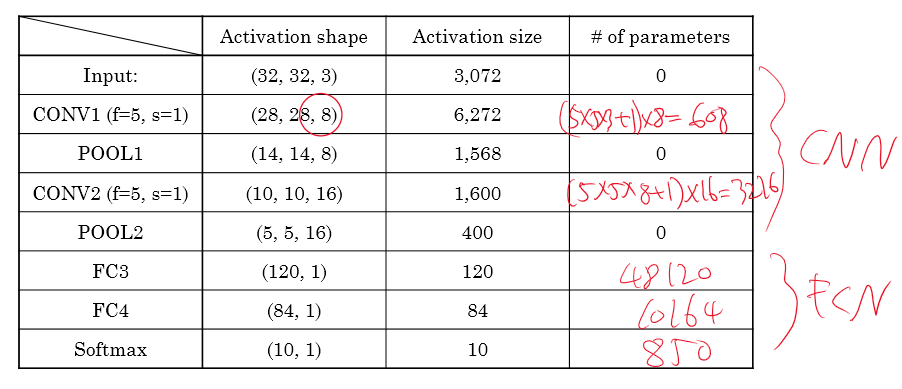
이건 표만으로도 확인이 가능해서 그대로 두었다.
정리하고 넘어가자면 CNN을 사용하는 이유는
1. Less number of parameters than FCN (FCN에 비해 파라미터 개수가 적다)
2. Parameter sharing : A feature detector(such as a vertical edge detector) that's useful in one part of the image is probably useful in another part of image (filter만 잘 학습하면 어디에 있더라도 잘 찾아낸다.)
밑에는 CNN을 활용하여 잘 만든 네트워크 3개정도 보여주겠다.
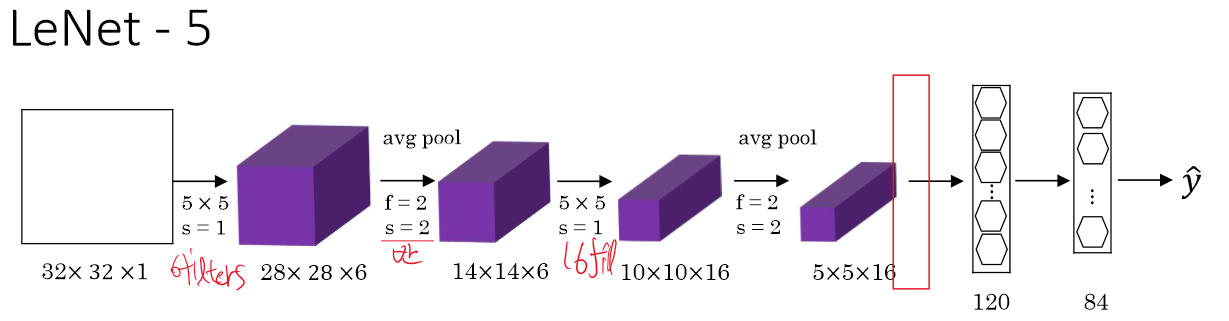



layer가 많아지면 backpropagation을 진행할 수록 0에 수렴하여 처음 layer들은 학습이 되지 않는다. 이러한 이유 때문에 ResNet의 short cut을 사용하여 vanishing gradient를 막아준다.
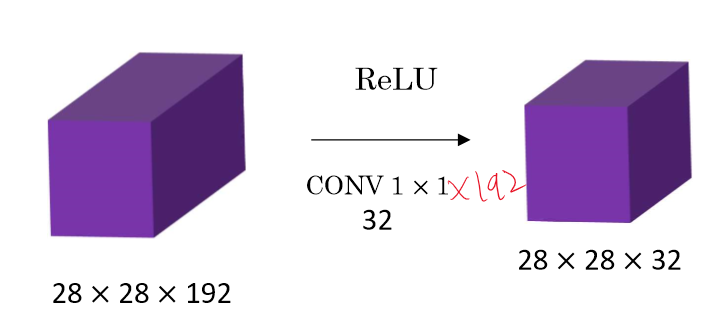
1. 채널 수를 줄이거나 늘릴 때 사용
2. 채널 수를 유지하면서 비선형성을 늘릴 때

총 연산 횟수는 5*5*192* 28*28*32 = 120M으로 어마무시한 숫자가 나온다.
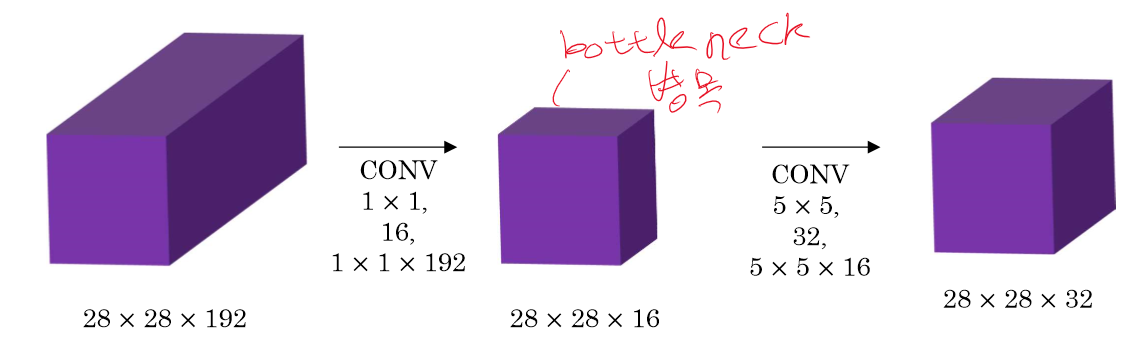
총 연산 횟수가 1*1*192 * 28*28*16 + 5*5*16 * 28*28*32 = 12.4로 거의 10%로 감소하는 연산 수를 볼 수 있다.

이 건 왜 쓰는지 확실하겐 모르겠지만 다양한 정보를 한 피쳐에 담을 수 있게 된다.
데이터 늘리기
1. Rotation 돌리기
2. shearing 찌그러뜨리기
3. Local warping 비틀기
4. mirroring 좌우 반전
5. Random Cropping 랜덤으로 자르기
6. Color shifiting R,G,B값 각각 조금씩 변동주기
...
데이터가 적을 경우
NN의 구조 잘 만들기, trial and error 계속 시행(hand engineering 필요), DNN 오버피팅 우려
데이터가 많을 경우
NN의 구조 걱정할 필요 X
마지막 추가!


이 convolution은 필터가 더 넓은 영역을 수용할 수 있어 이미지 내의 더 큰 패턴을 잘 찾아낸다. 그러나 파라미터가 추가적으로 필요한 것이 아니라 효율적이다.

input의 채널을 반으로 나눠서 각각 convolution을 한 형태이다. 이렇게 진행하게 되면 파라미터의 수가 절반으로 줄게 된다.
2023.12.14 - [인공지능/공부] - 설명 가능한 인공지능 CAM - 개념
설명 가능한 인공지능 CAM - 개념
기존 CNN, FCN은 설명이 불가능하다.(출력만 나온다. API) CNN에서 중요한 부분은 높은 가중치를 받는다. -> 이걸 확인하면 우린 네트워크를 설명할 수 있다. CLASS ACTIVATION MAP - CAM 우린 이러한 이유로 C
yoonschallenge.tistory.com
2023.12.14 - [인공지능/공부] - 생성형 인공지능 Autoencoder - 개념
생성형 인공지능 Autoencoder - 개념
여태까지 FCN, CNN, CAM 모두 supervised learning였다. 즉 지도학습으로 input(data)와 정답(label)이 주어지는 학습이었다. 그러나 오늘 다룰 Autoencoder는 label이 없는 즉 정답이 input인 unsupervised learning이다. 나
yoonschallenge.tistory.com
'인공지능 > 공부' 카테고리의 다른 글
| CAM 실습 - MNIST, TensorFlow (0) | 2023.12.14 |
|---|---|
| 설명 가능한 인공지능 CAM - 개념 (0) | 2023.12.14 |
| 인공지능 기말 자료 (0) | 2023.12.13 |
| 인공지능 중간고사 개념 정리 (0) | 2023.12.13 |
| TensorFlow - LSTM을 사용하여 apple 주식 예측하기 (42) | 2023.12.07 |