https://dl.acm.org/doi/10.1145/3626772.3657801
Content-based Graph Reconstruction for Cold-start Item Recommendation | Proceedings of the 47th International ACM SIGIR Conferen
The reasoning and generalization capabilities of LLMs can help us better understand user preferences and item characteristics, offering exciting prospects to enhance recommendation systems. Though effective while user-item interactions are abundant, ...
dl.acm.org
추천 시스템 - 다양하게 사용되고 있다.
협업 필터링 - 유저나 아이탬 간 비슷한 패턴을 찾아내는 방식
유저 기반 협업 필터링 - 나와 비슷한 성향의 사람들 아이템 추천
아이템 기반 협업 필터링 - 아이템 기반 추천
콜드 스타트 : 데이터가 없을 때의 추천 어려움
사용자 아이템 그래프가 중요!
멀티 모달 데이터를 어떻게 처리했는가?
이전 연구에 사용되던 전처리 된 데이터를 사용

1. 문제 정의
본 논문에서는 추천 시스템의 주요 문제 중 하나인 '콜드 스타트 문제'를 다룹니다. 콜드 스타트 문제는 새로운 사용자나 항목에 대해 기존의 사용자-항목 상호작용 데이터가 부족해 추천 품질이 저하되는 문제를 의미합니다 . 특히, 기존의 그래프 신경망(GNN) 기반 추천 시스템은 사용자-항목 상호작용을 기반으로 하여 콜드 스타트 상황에서는 정보 교환이 불가능해져서 추천이 어렵습니다.
2. 시도된 방법
기존 방법들은 보조 정보를 활용하여 콜드 스타트 항목이나 사용자를 설명하는 방식으로 문제를 해결하려고 했습니다. 그러나 이들 대부분은 고차원적인 협업 신호를 항목 특징에 명시적으로 반영하지 못했습니다. 이러한 문제를 해결하기 위해 본 논문에서는 콘텐츠 기반 그래프 재구성(Content-based Graph Reconstruction, CGRC)을 제안합니다. CGRC는 멀티모달 데이터를 활용하고, 그래프 마스크드 오토인코더 구조를 사용하여 사용자-항목 간의 상호작용을 재구성합니다.
3. 방법론
CGRC 모델은 세 가지 주요 구성 요소로 구성됩니다: 노드 인코더, 그래프 재구성기, 콜드 스타트 추천기입니다. 먼저, 사용자의 멀티모달 특징을 인코딩하고, 임의로 선택된 항목과의 연결을 마스킹하여 콜드 스타트 시나리오를 시뮬레이션합니다. 그런 다음, 이 마스킹된 연결을 복구하는 방식으로 모델을 학습시켜 콜드 스타트 항목에 대해 잠재적인 연결을 예측합니다. 이를 통해 사용자는 멀티홉 이웃으로부터의 정보를 통합해 사용자의 선호도를 반영할 수 있습니다.
4. 결과
실험 결과, CGRC 모델은 TikTok, MovieLens, Yahoo Movie 등 여러 데이터셋에서 높은 성능을 보였습니다. 특히, 다른 기존 모델들보다 높은 정확도와 재현율, NDCG 점수를 기록했습니다. 이는 CGRC가 콜드 스타트 문제를 효과적으로 해결할 수 있음을 시사합니다.
5. 한계점
CGRC는 주로 콜드 스타트 항목 추천에 초점을 맞추고 있으며, 사용자에 대한 보조 정보가 제한적이거나 없는 경우의 콜드 스타트 사용자 문제를 다루는 데에는 제한이 있을 수 있습니다. 또한, 특정 데이터셋에서만 평가되었기 때문에 다른 도메인에서도 동일한 성능을 발휘할지는 추가적인 검증이 필요합니다.
본 논문은 콜드 스타트 문제 해결을 위한 혁신적인 접근 방식을 제시하며, 향후 연구에서는 CGRC 모델의 응용 범위를 확장하여 다양한 상황에서의 유효성을 평가할 필요가 있습니다.
여기서 멀티모달 특징 무엇 무엇이 있고, 어떻게 인코딩하는거야?
몰티홉 이웃은 또 뭐고, 정보는 어떻게 통합해?
1. 멀티모달 특징과 인코딩 방법
논문에서는 멀티모달 특징을 사용하여 항목을 표현합니다. 멀티모달 특징은 항목의 시각적(Visual), 텍스트(Textual), 오디오(Acoustic) 정보를 포함합니다. 각 특징은 다음과 같은 방식으로 인코딩됩니다:
- 시각적 특징(Visual): ViT (Vision Transformer) 모델을 사용하여 인코딩.
- 텍스트 특징(Textual): BERT (Bidirectional Encoder Representations from Transformers) 모델을 사용하여 인코딩.
- 오디오 특징(Acoustic): AST (Audio Spectrogram Transformer) 모델을 사용하여 인코딩.
각 특징은 모달리티별 인코더를 통해 처리된 후, 학습 가능한 선형 투영(Linear Projection)을 거쳐 최종 임베딩으로 변환됩니다. 예를 들어, 각 모달리티의 특징은 f(𝑐)𝑖로 나타내어지며, 최종적으로 모든 특징을 결합하고, 완전 연결 계층(FC Layer)을 거쳐 최종 콘텐츠 기반 항목 임베딩 x𝑖를 생성합니다.
2. 멀티홉 이웃과 정보 통합 방법
멀티홉 이웃은 그래프 상에서 여러 단계 떨어진 노드를 의미합니다. 본 논문에서 사용된 그래프 신경망(GNN) 구조에서는 노드 간의 정보 교환이 발생하며, 이는 고차원 연결성을 통해 사용자의 선호도를 더욱 정확하게 반영할 수 있게 합니다. 특히, 사용자가 직접적으로 연결되지 않은 항목들과의 간접적 상호작용을 통해 더 넓은 범위의 정보가 통합됩니다.
구체적으로, 모델은 재구성된 그래프 Ĝ에서 메시지 패싱을 수행하여 최종 사용자와 항목 임베딩을 생성합니다. 이 과정에서 멀티홉 이웃으로부터 정보를 수집하고, 이를 통해 사용자의 선호도를 더욱 정확하게 예측합니다. 이는 복수의 그래프 컨볼루션 계층을 거쳐 각 노드의 임베딩을 학습하고, 이를 평균하거나 합치는 방식으로 최종 임베딩을 생성하여 사용자-항목 간의 연결성을 극대화합니다.
이와 같은 접근 방식은 고차원 연결성을 활용하여 더 정밀한 추천을 가능하게 하며, 콜드 스타트 항목에 대한 추천의 정확성을 높이는 데 기여합니다.
그래프 컨볼루션은 추천 시스템에 성공적으로 적용되어 사용자-항목 상호작용 그래프에서 고차원 협업 신호를 활용하고 있습니다. 그러나 이 개념은 콜드 스타트 항목에는 적용되지 않았는데, 이는 콜드 노드가 그래프에서 고립되어 있어 이웃 노드와의 정보 교환이 불가능하기 때문입니다. 최근에는 아이템-아이템 또는 사용자-사용자 속성 그래프에서 그래프 컨볼루션을 사용하여 콜드 스타트 상황에서도 고차원 협업 신호를 캡처하려는 몇 가지 시도가 있었습니다. 그러나 이러한 접근 방식은 아이템-아이템 또는 사용자-사용자 그래프의 엣지가 임의적이고 직관적인 속성 유사성에 따라 구성되므로 사용자-항목 상호작용의 동적 특성을 포착하는 데 한계가 있습니다.
이 논문에서는 콜드 스타트 항목 추천을 위한 콘텐츠 기반 그래프 재구성(Content-based Graph Reconstruction for Cold-start item recommendation, CGRC)을 소개합니다. 우리는 마스크드 그래프 오토인코더 구조와 멀티모달 콘텐츠를 사용하여 상호작용 기반 고차원 연결성을 직접 통합하여, 콜드 스타트 상황에서도 적용 가능한 모델을 제안합니다. 콜드 스타트 항목을 직접 다루기 위해, 우리의 접근 방식은 임의로 선택된 콜드 항목의 마스크된 엣지에서 그럴듯한 사용자-항목 상호작용을 재구성하도록 모델을 훈련시킵니다. 이는 사용자와 연결되지 않은 새 항목을 시뮬레이션하여 모델이 보이지 않는 콜드 스타트 노드에 대한 잠재적 엣지를 추론할 수 있도록 합니다. 실세계 데이터셋에 대한 광범위한 실험을 통해 우리의 모델이 우수함을 입증합니다.
1. 도입
추천 시스템은 정보 과부하가 중요한 과제로 대두되는 온라인 소매 및 비디오 공유 플랫폼과 같은 실제 응용 프로그램에서 필수적인 역할을 합니다. 개인화된 추천 시스템을 위한 가장 성공적인 기술인 협업 필터링(Collaborative Filtering, CF)은 사용자-항목 상호작용에서 일반적으로 관찰되는 선호 패턴을 포착하여 특정 사용자에게 맞춘 항목을 예측합니다. CF 접근법에는 행렬 분해(Matrix Factorization, MF) [26, 40, 43], 신경망 기반 모델 [22], 그리고 그래프 신경망(GNN) [21, 57, 65]이 포함됩니다.
CF 접근법의 효과에도 불구하고, 새로운 사용자나 새로운 콘텐츠를 다룰 때 콜드 스타트 문제라는 지속적인 어려움에 직면하게 됩니다. 특히, GNN 기반 방법은 보통 사용자-항목 상호작용으로 구성된 이분 그래프에 의존하여 추천을 수행합니다. 그러나 상호작용이 없는 새로운 사용자나 항목이 도입되면 연결성의 부재로 인해 이웃 노드와의 정보 교환이 불가능해지고, 결과적으로 이러한 콜드 엔티티에 대한 추천이 어려워집니다.
콜드 스타트 문제를 해결하기 위해 보조 정보가 사용되었습니다 [4, 25, 28, 44, 51]. 이 방법들은 상세한 방법은 다르지만, 공통적으로 사용자와 항목을 공통 잠재 의미 공간에서 나타내는 것을 학습합니다. 대부분의 모델은 먼저 사전 학습된 모델이나 엔드 투 엔드 방식으로 주어진 보조 정보에서 특징을 추출합니다. 이후, 다양한 방법들이 모달리티별 콘텐츠 특징을 공통 사용자-항목 임베딩 공간에 매핑하기 위해 사용되었습니다. 기존 방법들은 다층 퍼셉트론(MLP) [38], 오토인코더 [67], 생성적 적대 신경망(GANs) [8]을 사용했으며, 이 방법들은 항목 특징에 고차원 협업 신호를 명시적으로 반영할 수 없었습니다.
고차원 관계를 명확히 포착하기 위해, 최근에는 GNN이 도입되었습니다. AGNN [44]과 HERS [25]는 그래프 컨볼루션 연산을 사용하여 인접 노드로 메시지를 전달하고 항목을 표현하는 방법을 학습합니다. 아이템-아이템 속성 그래프에서 노드 표현을 학습하여 항목 콘텐츠의 고유한 특징을 효과적으로 캡처할 수 있습니다. 이러한 GNN 기반 접근법은 그래프 컨볼루션 레이어의 수만큼 멀리 떨어진 정보에 접근할 수 있게 합니다.
GNN을 추천에 사용하는 주된 이유는 고차원 연결성을 활용하여 모델이 다중 홉 이웃을 고려할 수 있도록 하는 것입니다. 사용자-항목 상호작용 그래프는 추천에서 가장 기본적인 선호 관계를 인코딩합니다. 즉, 사용자가 특정 항목과 상호작용했다는 명백한 사실을 전달합니다. 따라서 이 그래프에서 메시지 전달을 수행하는 것이 가장 자연스러울 것입니다.
그러나 기존 연구들은 정보 교환을 사용자-항목 상호작용이 아닌 아이템-아이템 그래프에서 수행합니다. 사실, 아이템-아이템 그래프는 사용자-항목 상호작용의 동적 특성을 충분히 반영하지 못합니다. 이는 엣지가 종종 임의적이고 직관적으로 정의된 속성 유사성에 기반해 구성되기 때문입니다. 반면, 사용자-항목 상호작용 그래프는 특정 사용자가 특정 항목을 소비했다는 명백한 사실을 전달합니다. 결과적으로, 이 그래프에서 직접 메시지 전달을 수행하는 것이 인간의 직관에 의해 덜 편향될 것입니다.
그렇다면 왜 우리는 아이템-아이템 그래프를 사용해왔을까요? 이는 그래프 컨볼루션이 콜드 스타트 설정에서 사용자-항목 상호작용 그래프에 직접적으로 적용되지 않기 때문입니다. 콜드 스타트 사용자나 항목 노드는 완전히 고립되어 있어 정보 교환이 발생하지 않습니다. 이러한 이유로 기존 방법들은 속성 유사성을 기반으로 고립된 항목을 연결하기 위해 아이템-아이템 그래프를 채택했습니다.
그러면 콜드 스타트 추천에 대해 사용자-항목 상호작용 그래프에 그래프 컨볼루션을 직접 적용하는 것이 불가능할까요? 만약 가능하다면, 항목 속성의 임의적 유사성 측정에 의존하지 않고 콜드 스타트 추천을 수행할 수 있을 것입니다. 이 연구에서는 콜드 스타트 상황에서 사용자-항목 상호작용 신호를 직접 슈퍼바이징하는 GNN 기반 추천 모델을 제안합니다. 이 목표를 달성하기 위해, 우리는 콜드 스타트 아이템 추천을 위한 콘텐츠 기반 그래프 재구성(CGRC)이라는 새로운 프레임워크를 개발했습니다. 우리는 최근 다양한 분야에서 성공을 거둔 마스크드 오토인코더 모델에 영감을 받아, 격리된 콜드 스타트 사용자와 항목을 연결하기 위해 새로운 마스크드 그래프 오토인코더 모델을 제안합니다. 구체적으로, 우리의 방법은 훈련 데이터의 기존 사용자-항목 상호작용 엣지의 일부를 마스킹하고 이러한 숨겨진 엣지를 복구하도록 모델을 훈련하여 그럴듯한 사용자-항목 상호작용을 재구성하는 것을 학습합니다. 이러한 시뮬레이션된 학습을 통해 모델은 보이지 않는 콜드 스타트 노드에 대해 그럴듯한 엣지를 추론할 수 있습니다. 우리의 마스크드 그래프 오토인코더 접근법을 통해, 모델은 잠재적인 사용자-항목 관계(엣지)를 자가 감독 방식으로 재구성하는 것을 학습합니다.
우리의 제안된 방법은 다음과 같이 요약될 수 있습니다:
- CGRC는 상호작용 기반 고차원 연결성을 직접 활용하여 콜드 스타트 문제를 해결할 수 있는 첫 번째 모델입니다.
- 우리는 멀티모달 콘텐츠와 콜드 스타트 아이템 추천을 위한 그래프 마스크드 오토인코더 구조를 활용하여 적응적으로 유익한 신호를 추출하고 사용자-항목 엣지의 자가 감독 재구성을 촉진합니다.
- 실세계 데이터셋에 대한 광범위한 실험을 통해 CGRC의 뛰어난 성능을 입증합니다.
3. 제안된 방법: CGRC
이 연구에서는 어떤 상호작용도 없는 완전히 새로운 항목을 추천하는 데 초점을 맞춥니다. 제안된 모델 아키텍처는 노드 인코더, 그래프 재구성기, 그리고 콜드 스타트 추천기로 구성됩니다(그림 2 참조). 사용자와 항목이 멀티모달 특징으로 인코딩되면, 일부 항목을 무작위로 선택하여 연결된 모든 엣지를 마스킹하여 콜드 스타트 시나리오를 시뮬레이션합니다. 모델은 이러한 엣지를 재구성하는 법을 학습하여 테스트 시 보이지 않는 콜드 스타트 항목에도 일반화할 수 있습니다. 이후, 콜드 스타트 추천기 내에서 사용자와 항목 그래프 임베딩은 재구성된 그래프를 통해 얻어지며, 상호작용 기반의 고차원 연결성을 활용합니다.
3.1 문제 정의
U와 I를 각각 n명의 사용자와 m개의 항목 집합이라고 합시다. R ∈ {0, 1}ⁿ×ᵐ은 n명의 사용자와 m개의 항목의 이진 상호작용 행렬이며, 사용자가 항목과 상호작용한 경우 R𝑢𝑖 = 1이고, 그렇지 않은 경우 R𝑢𝑖 = 0입니다. 각 항목 𝑖는 비디오, 이미지, 오디오, 텍스트와 같은 원시 콘텐츠 특징이나 장르, 제작자, 연도 등과 같은 메타데이터를 포함한 C개의 콘텐츠 요소를 가지고 있습니다. 우리는 사용자-항목 상호작용의 이분 그래프 G = (V, E)를 구성하며, 여기서 V = U ∪ I이고, E는 사용자-항목 상호작용 R입니다. 우리는 N𝑢를 사용자가 상호작용한 항목의 집합으로 나타냅니다. 마찬가지로, N𝑖는 항목 𝑖와 상호작용한 사용자의 집합입니다.
우리는 사용자가 항목 𝑖'에 대해 가질 것으로 예상되는 선호 점수 Rˆ𝑢𝑖'를 추정하여 콜드 스타트 항목 추천 작업을 해결하고자 합니다. 여기서 𝑖'는 I에 속하지 않는 항목입니다(즉, 사용자가 콜드 스타트가 아닌 경우, 목표 항목만 콜드 스타트). 제안된 아이디어는 사용자에 대한 유용한 보조 정보가 제공되는 경우 콜드 스타트 사용자에도 동일하게 적용될 수 있습니다. 이 논문에서는 주로 사용자의 프라이버시 문제로 인해 공개적으로 의미 있는 사용자의 보조 정보가 부족하기 때문에 콜드 스타트 항목 사례만을 다룹니다.
3.2 노드 인코더
3.2.1 사용자 및 멀티모달 항목 인코딩 레이어
사용자 인코딩 레이어에서는 전통적인 협업 필터링 모델을 따르며, 사용자를 임베딩 레이어를 통해 표현하여 e𝑢 ∈ R 𝑑 를 생성합니다. 여기서 는 임베딩 크기입니다.
콜드 스타트 항목을 다루기 위해 항목 인코딩 레이어는 C개의 콘텐츠 신호(또는 보조 정보)를 활용하여 항목 i를 나타냅니다. 이러한 신호는 ViT(시각적), BERT(텍스트), AST(오디오)와 같은 모달리티별 인코더에 의해 처리된 후 학습 가능한 선형 투영을 거칩니다. 각 모달리티 표현은 f (𝑐 ) 𝑖 ∈ R 𝑑𝑐 로 나타내어지며, 여기서 c=1,...,C는 각 콘텐츠 특징을 식별하고 dc는 모달리티 c의 임베딩 차원입니다.
그 후, 이러한 콘텐츠 특징을 집계하여(즉, 연결하고 완전 연결(FC) 레이어를 거쳐) 최종 콘텐츠 기반 항목 임베딩 x𝑖 ∈ R 𝑑 ,를 생성합니다. 여기서 dd는 최종 임베딩의 차원입니다:
xi=W(fi(1);fi(2);...;fi(C))+b,
여기서 W∈Rd×∑cdc이며 b∈Rd입니다.
3.2.2 멀티모달 정렬 손실
간단한 접근 방식으로, Eq. (1)에 나와 있는 투영 레이어는 다양한 멀티모달 콘텐츠 특징을 통합하여 동일 항목 내에서 멀티모달 관계를 자동으로 학습할 것으로 예상됩니다. 이 간단한 접근 방식은 멀티모달 신호를 적절히 결합하지만, 우리는 자기 감독을 통해 멀티모달 관계를 더욱 깊이 활용합니다. 구체적으로, 각 미니배치의 모든 항목 임베딩에 대조 손실을 적용하여 동일한 항목에 대한 다른 모달리티 간의 임베딩 유사성을 높이고, 다른 모든 조합 간의 유사성은 최소화합니다. 공식적으로, 동일 항목 i에 대해 모달리티 와 b 간의 멀티모달 손실 은 다음과 같이 주어집니다:
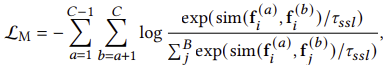
여기서 sim(⋅)은 두 벡터 표현의 유사성을 내적을 사용하여 계산하며, τssl은 온도 하이퍼파라미터를 나타내며, B는 배치 내의 예제 수를 나타냅니다.
3.3 그래프 재구성기
이 연구의 주요 혁신은 이 그래프 재구성 단계에 있습니다. 컴퓨터 비전(CV) [19], 자연어 처리(NLP) [12], 그리고 그래프 신경망(GNN) [24] 분야에서 마스크드 오토인코딩의 성공을 바탕으로, 우리의 접근법은 주어진 사용자-항목 상호작용 그래프 G에서 무작위로 선택된 일부 항목 노드의 모든 엣지를 마스킹하여 콜드 스타트 상황을 시뮬레이션하면서 콜드 스타트 항목에 대해 잠재적으로 관련 있는 사용자를 예측합니다. 모델은 노드의 콘텐츠 신호를 기반으로 다른 남아 있는 노드로의 누락된 엣지의 존재를 추정하도록 훈련됩니다. 이를 통해, 모델은 추천 시스템에서 협업 신호에 해당하는 그래프 내의 연결성과 콘텐츠 신호 간의 기본 관계를 학습할 것으로 기대됩니다.
3.3.1 마스킹된 그래프 G'
사용자-항목 이분 그래프 G에서 우리는 콜드 스타트 시나리오를 시뮬레이션하기 위해 마스킹된 그래프 G'를 구성합니다. 구체적으로, 먼저 G에서 일부 항목 노드를 무작위로 선택하여 콜드 항목 Icold ⊂ I로 선택하고, 확률 𝜌로 이 항목들에 연결된 모든 엣지를 마스킹합니다:
Emasked = {(𝑢,𝑖) ∈ E | 𝑢 ∈ U,𝑖 ∈ Icold}.
마스킹된 그래프는 G' = (V, E - Emasked)로 구성됩니다. (마스킹된 항목 Icold는 여전히 그래프 G'에 존재하지만, 다른 노드와 연결이 끊겨 콜드 스타트를 시뮬레이션합니다.) 추천의 관점에서, 이러한 마스킹된 엣지는 콜드 항목과 사용자 간의 숨겨진 관련성을 나타내며, 우리는 이러한 숨겨진 관련성을 콜드 항목에 사용할 수 있는 콘텐츠 신호를 사용하여 모델을 학습시킵니다. 훈련이 완료되면, 모델은 보이지 않는 콜드 스타트 항목에 대해 잠재적으로 관련 있는 사용자를 발견할 것으로 기대됩니다.
3.3.2 그래프 컨볼루션 레이어
마스킹된 그래프 G'이 구성된 후, 우리는 그래프 컨볼루션 레이어(예: LightGCN [21], NGCF [57])를 적용하여 사용자와 항목의 표현을 학습합니다. 이를 통해 사용자 선호도를 다중 홉 이웃에서 포착할 수 있습니다. 예를 들어, 사용자 표현을 생성하기 위해, 첫 번째 레이어는 사용자가 선호하는 모든 항목을 집계하고(user-item), 두 번째 레이어는 공통으로 선호된 항목에 대해 선호도를 공유한 다른 사용자를 통합합니다(user-item-user). 레이어 수를 확장함으로써, 더 먼 이웃으로부터의 통찰을 얻어 사용자 선호도를 더 포괄적으로 이해할 수 있습니다.
각 레이어에서, LightGCN [21]을 따르며, 그래프 컨볼루션 레이어는 다음과 같이 노드 임베딩을 업데이트합니다:
H (ℓ) = (D ′^(−1/2) A ′D ′&(−1/2) )H^(ℓ−1) ,
여기서 A'는 그래프 G'의 인접 행렬이며 D'는 대각선 차수 행렬입니다. 여기서 R'은 마스킹된 그래프 G'에 해당하는 사용자-항목 상호작용 행렬입니다. 우리의 방법은 LightGCN에 국한되지 않으며, NGCF [57]와 같은 다른 GCN 변형도 적용할 수 있습니다. 여러 개의 그래프 컨볼루션 레이어를 쌓아 𝐿개의 노드 표현 {H(1), H(2), ... , H(𝐿)}을 생성합니다.
기존의 GNN 인코더와 유사하게, 각 사용자 노드 u ∈ U는 h(0)_u = e_u로 초기화되고 각 항목 노드 i ∈ I는 h(0)_i = x_i로 초기화됩니다. 그러나 우리는 원래의 그래프 G가 아닌 마스킹된 그래프 G'에서 그래프 컨볼루션 연산을 수행하므로, 콜드 항목 노드(Icold)는 다른 노드와의 연결이 끊겨 G'에서 초기 값으로 고정됩니다. 다른 따뜻한 노드(사용자와 따뜻한 항목(I - Icold))는 기존 방식대로 그래프 컨볼루션 연산을 수행하여 업데이트됩니다. 각 레이어 ℓ에서, 사용자 u와 항목 i의 노드 임베딩은 각각 h(ℓ)_u와 h(ℓ)_i로 나타내며, 최종적으로 GNN 인코더는 모든 u ∈ U와 i ∈ I에 대해 {h(ℓ)_u, h(ℓ)_i}을 생성하지만, 콜드 항목 Icold는 초기값 x_i를 유지합니다.
3.3.3 엣지 예측기
엣지 예측기는 그림 2에 묘사된 대로 사용자 u ∈ U와 각 콜드 항목 i ∈ Icold 간의 연결 가능성을 추정하여 연결 여부를 결정합니다. 엣지 예측기는 여러 가지 옵션으로 구축할 수 있습니다. 이 예측기의 입력으로, 우리는 ℓ = 1, ..., 𝐿의 ℓ에 대한 임베딩 h(ℓ)_u와 h(ℓ)_i을 가져와 평균을 내어 집계합니다:
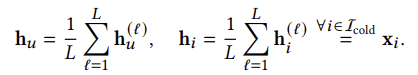
여기서 h_u와 h_i는 최종 사용자 u와 항목 i의 임베딩을 나타냅니다. 우리는 단순한 내적이나 MLP를 사용하여 사용자와 항목 임베딩의 연결 가능성을 예측할 수 있습니다. 실험을 통해 이 디자인 선택의 유효성을 검증합니다.
3.3.4 재구성 손실
훈련 중, 우리는 모든 u ∈ U와 i ∈ Icold에 대해 p(u, i)을 예측하고, 각 콜드 항목에 대해 예측된 점수가 가장 높은 상위-K 사용자 노드와 연결합니다. 이로써 콜드 항목과 사용자를 연결하는 재구성된 엣지를 포함하는 재구성된 그래프 Gˆ = (V, E' )가 만들어집니다. 마스킹된 엣지를 재구성하기 위한 훈련 손실은 다음과 같습니다:
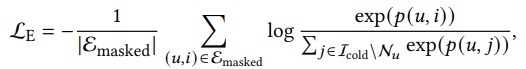
여기서 p(u, i)은 사용자 u와 콜드 항목 i 사이의 링크 점수를 추정하며, p(u, j)은 사용자 u와 부정 샘플링된 콜드 항목 j 사이의 점수입니다. 기존의 그래프 오토인코더는 일반적으로 동질적인 노드의 엣지를 재구성하는 데 초점을 맞추지만, 제안된 모델은 마스킹된 사용자-항목 상호작용 엣지를 재구성하도록 설계되었습니다.
3.4 콜드 스타트 추천기
3.4.1 재구성된 그래프 Gˆ에서의 그래프 컨볼루션 레이어
시뮬레이션된 콜드 항목에 대한 엣지를 재구성한 후, 우리는 재구성된 그래프 Gˆ에서 최종 사용자와 항목 임베딩을 얻기 위해 Sec. 3.3.2에서 사용된 것과 유사한 또 다른 그래프 컨볼루션 레이어 세트를 사용합니다.
구체적으로, 우리는 Eq. (4)를 사용하여 그래프 Gˆ에서 𝐿회 반복적으로 메시지 전달을 수행합니다. 이 과정은 각 레이어에서 사용자와 항목 임베딩을 생성하며, 이를 각각 z(ℓ)𝑢와 z(ℓ)𝑖로 나타냅니다(ℓ = 0, ..., 𝐿). 이후, 최종 사용자와 항목 표현 z𝑢, z𝑖는 모든 𝐿 + 1 임베딩을 연결하거나(NGCF [57]), 이들의 평균을 내는 방식으로(LightGCN [21]) 생성됩니다.
이후, 우리는 다음과 같이 선호도 점수 Rˆ𝑢𝑖를 예측합니다:
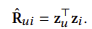
재구성된 그래프 Gˆ에서 GNN을 사용하는 이유는 콜드 항목 임베딩에서 다중 홉 이웃으로의 정보 흐름을 강화하기 위함입니다. 이는 추천 시스템에서 GNN의 가장 큰 장점인 상호작용 기반 고차원 연결성을 효과적으로 활용합니다 [21, 57]. 이 과정의 자세한 설명은 그림 2에서 볼 수 있습니다. 이 접근 방식은 콜드 항목을 사용한 고품질 추천을 가능하게 하는 더 정교한 최종 사용자와 항목 임베딩을 생성할 수 있게 합니다. 재구성된 그래프에 GNN을 적용한 효과에 대한 실험적 검증은 우리의 분석 연구 섹션 4.3.3에서 제시됩니다.
이 단계는 테스트 시에만 재구성된 그래프 Gˆ에서 수행됩니다. 이 메시지 전달 단계는 재구성 단계의 불안정성 때문에 훈련 시 원래의 완전한 그래프 G에서 훈련됩니다. 초기 훈련 단계에서 재구성된 엣지가 실제로 관련 있는 사용자-항목 상호작용을 나타내는 것은 아니기 때문에, 이 불안정한 재구성된 그래프에서 메시지 전달을 수행하면 상당히 노이즈가 많은 노드 임베딩으로 이어질 수 있습니다. 따라서, 교사 강제(teacher forcing) [33]와 유사하게, 훈련 중 그래프 컨볼루션 자체는 원래 그래프에서 훈련됩니다.
3.4.2 평점 순위 손실
사용자 z𝑢와 항목 z𝑖 임베딩을 활용하여, 우리는 모델이 선호하는 항목에는 더 높은 점수를, 선호하지 않는 항목에는 더 낮은 점수를 부여하도록 훈련시킵니다. 우리는 표현 학습에서 널리 사용되는 대조 손실 [20, 34]을 사용합니다. 구체적으로, 각 사용자에 대해 선호하는 항목은 긍정으로 식별되고, 반대로 미니배치의 다른 모든 항목은 부정으로 간주됩니다. 모델은 긍정 쌍을 최대화하고 부정 쌍을 최소화하도록 최적화됩니다. 각 미니배치에 대한 평점 순위 손실 LR은 다음과 같이 정의됩니다:
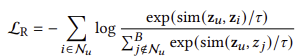
여기서 sim(a, b)는 a와 b 간의 내적을 나타내며, 𝜏는 온도 하이퍼파라미터, 𝐵는 미니배치 내의 예제 수를 나타냅니다.
3.5 전체 손실 함수
전체 손실 함수는 앞서 제시한 세 가지 손실을 선형으로 결합합니다:
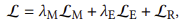
여기서 LM은 노드 인코더 내의 멀티모달 정렬 손실(3.2절), LE는 그래프 재구성기 내의 재구성 손실(3.3절), 그리고 LR은 추천기(3.4절)에서의 추천 손실을 의미합니다. λ{M, E}는 손실 간의 상대적 중요성을 조절하는 하이퍼파라미터입니다.
실험 요약
이 연구에서는 CGRC(Content-based Graph Reconstruction for Cold-start item recommendation)의 효과를 검증하기 위해 다양한 콜드 스타트 추천 데이터셋에서 광범위한 실험을 수행했습니다. 실험은 다음 네 가지 연구 질문에 답하고자 했습니다:
- RQ1: CGRC의 성능 비교
- CGRC는 최신 콜드 스타트 추천 모델들과 비교하여 세 가지 데이터셋에서 대부분의 지표에서 우수한 성능을 보여줍니다. 특히 TikTok과 Yahoo Movie와 같은 희소한 데이터셋에서 더 강력한 성능을 발휘했습니다.
- RQ2: 각 구성 요소의 기여도
- 그래프 인코더와 MLP 디코더를 결합한 경우가 가장 높은 성능을 보였습니다. 이는 MGAE(마스크드 그래프 오토인코더) 구조가 콜드 스타트 추천에서 효과적임을 시사합니다.
- RQ3: 하이퍼파라미터의 영향
- 다양한 하이퍼파라미터(임베딩 차원, 마스킹 비율, 손실 가중치, 재구성할 엣지 수)의 조정 결과, 최적의 값들이 발견되었습니다. 예를 들어, TikTok 데이터셋에서는 256 차원의 임베딩이 가장 좋은 성능을 보였습니다.
- RQ4: CGRC의 질적 성능
- CGRC는 사용자의 상세한 선호도를 고려하여 콘텐츠와 직접적으로 일치하지 않더라도 관련된 영화를 추천할 수 있는 능력을 보여줍니다.
결론
이 연구는 CGRC 모델을 통해 콜드 스타트 문제를 효과적으로 해결하는 방법을 제시했습니다. CGRC는 멀티모달 표현과 그래프 마스크드 오토인코더 구조를 활용하여 콜드 스타트 상황에서 풍부한 콘텐츠 정보를 완전히 활용하고, 자가 지도 학습을 통해 사용자-항목 엣지를 재구성합니다. 실험을 통해 CGRC의 우수성이 입증되었으며, 향후 연구에서는 워밍 스타트(warm-start) 설정에서의 효과를 탐구하는 것이 유망할 것입니다.