Data Parallelism - GPU 마다 모델을 넣어서 각각의 연산에 따라 훈련시킨다
Model Parallelism - Model을 쪼개서 GPU에 넣는다.
Tensor Parallelism - 모델을 수평으로 나눈다.
Pipeline Parallelism - 레이어 별로 다른 GPU에 넣는다.
Data Parallelism
배치가 작을 수록 한 iteration을 빠르게 돌릴 수 있다. -> GPU에 잘 넣을 수 있도록 적당한 size를 가져온다. - GPU가 많을 수록 많은 배치 사이즈로 가져갈 수 있다.
GPU가 3개라면 3개의 Loss를 가지게 된다. -> 평균 Gradient를 구해서 Back Propagation을 진행한다.
Ring all reduce - 양 옆의 GPU의 Loss만 전달한다. => 이게 최적한 알고리즘은 아니다!
이 방식은 모델이 매우 크면 활용할 수 없다.
Tensor Parallelism - 모델을 수평으로 나눈다.

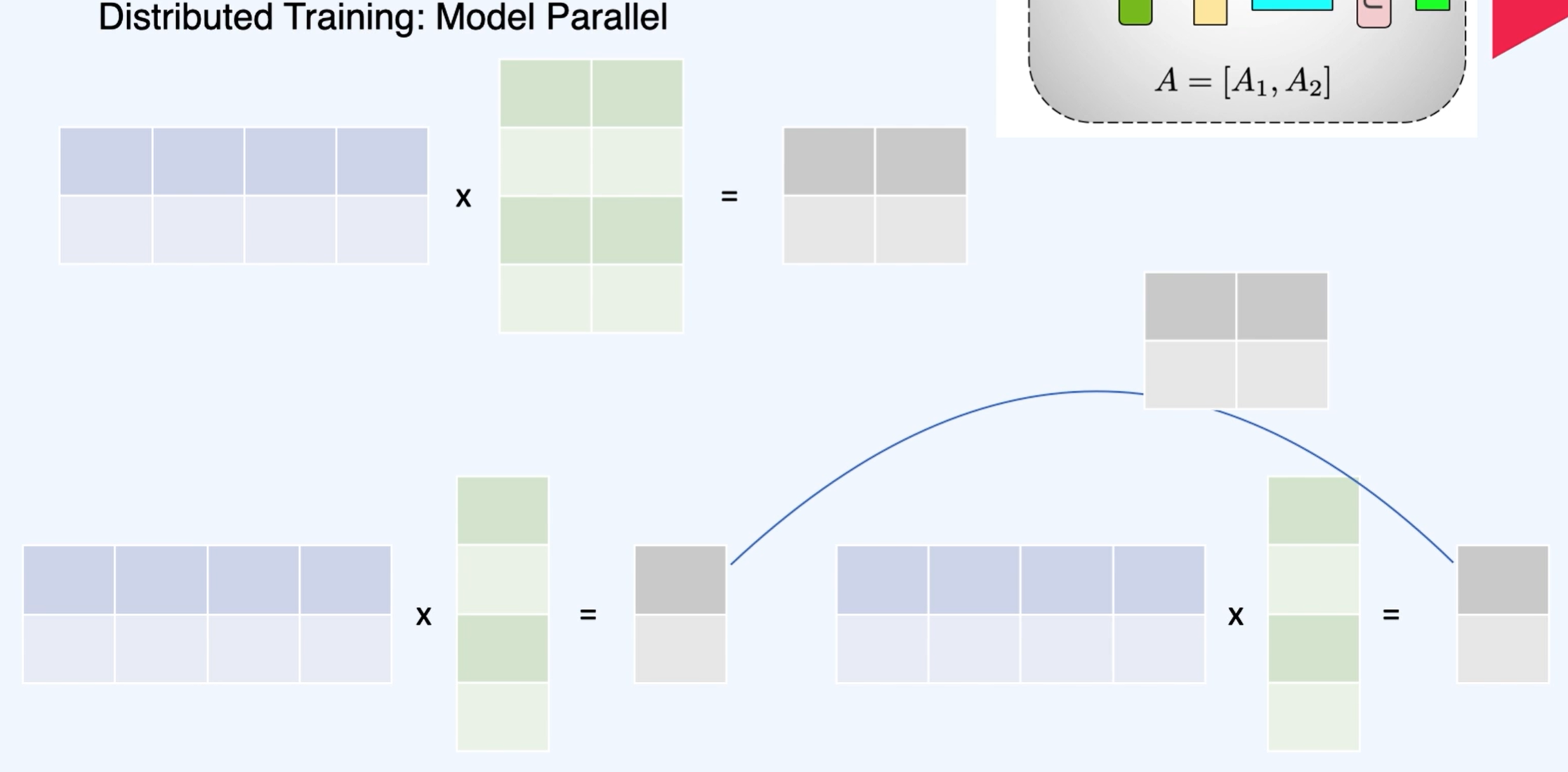
이런 방식으로 병렬 연산을 진행할 수 있다.
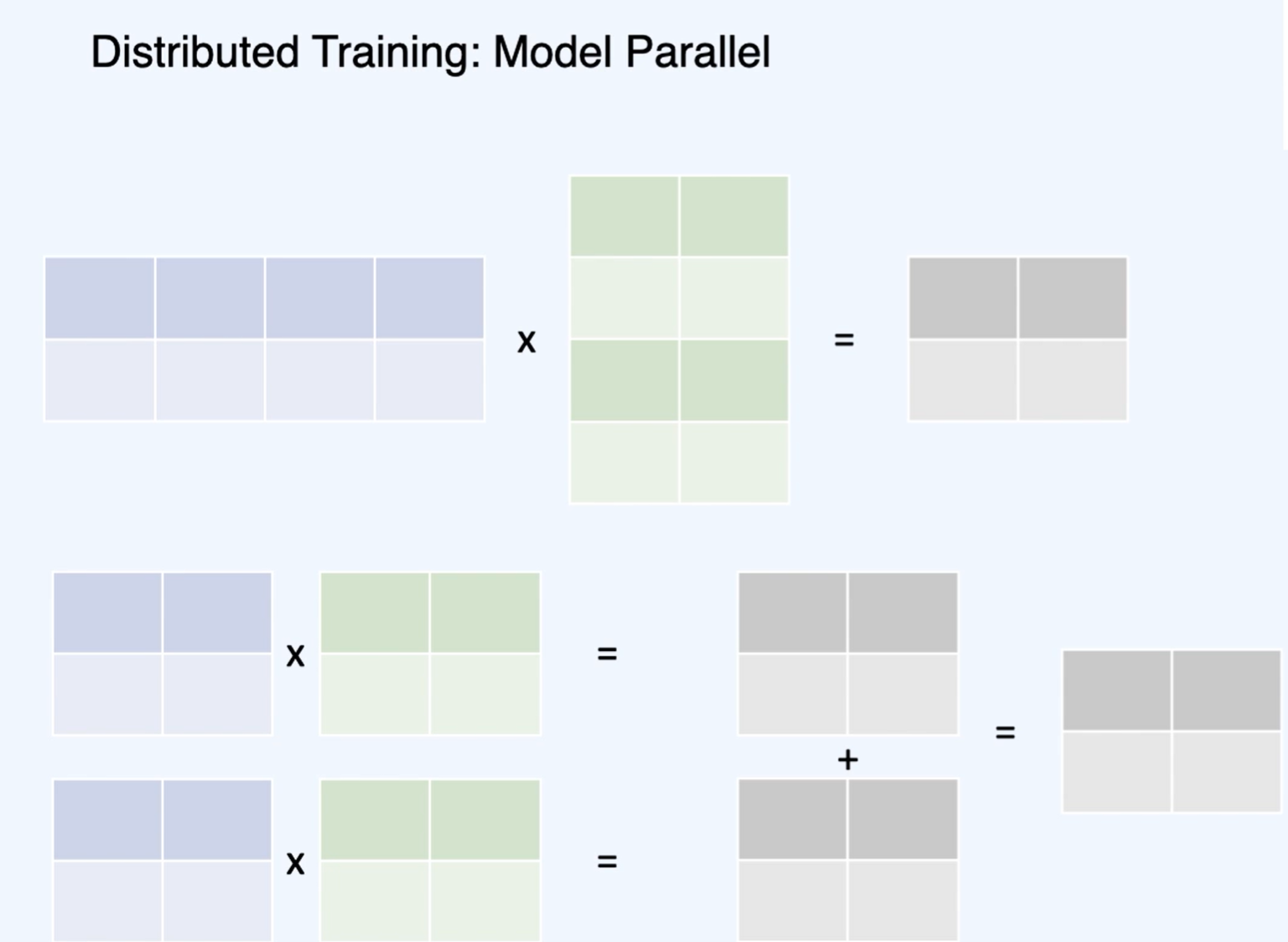
이 결과들을 더해주면 같아진다!
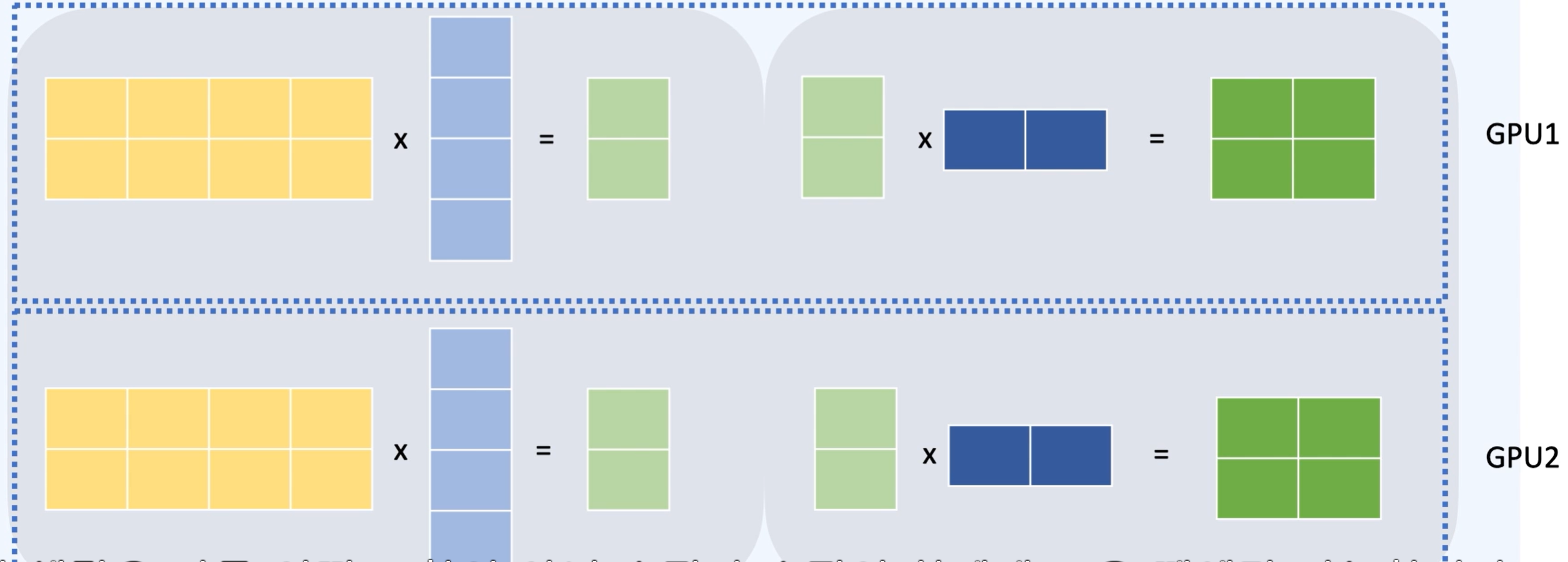
실제 연산은 아래와 같이 진행한다.
Pipeline Parallelism - 레이어 별로 다른 GPU에 넣는다.
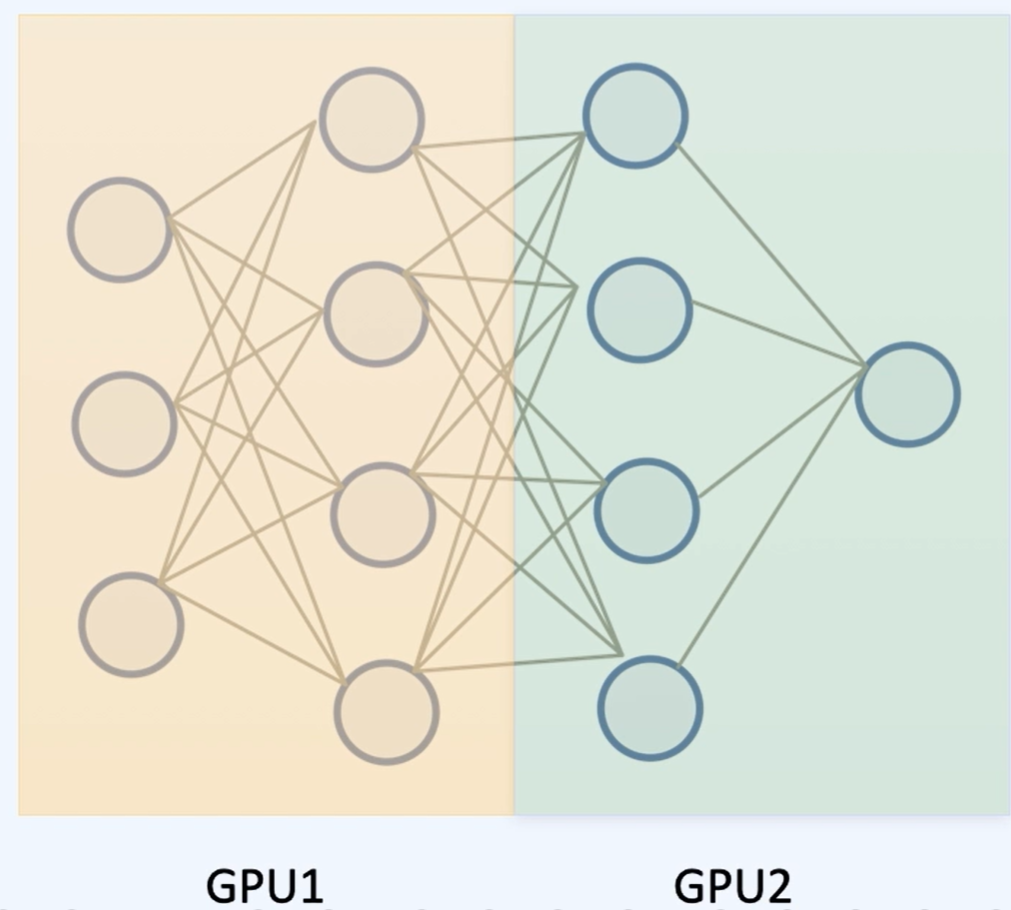
연산 속도에 대한 장점은 없어 보이네요
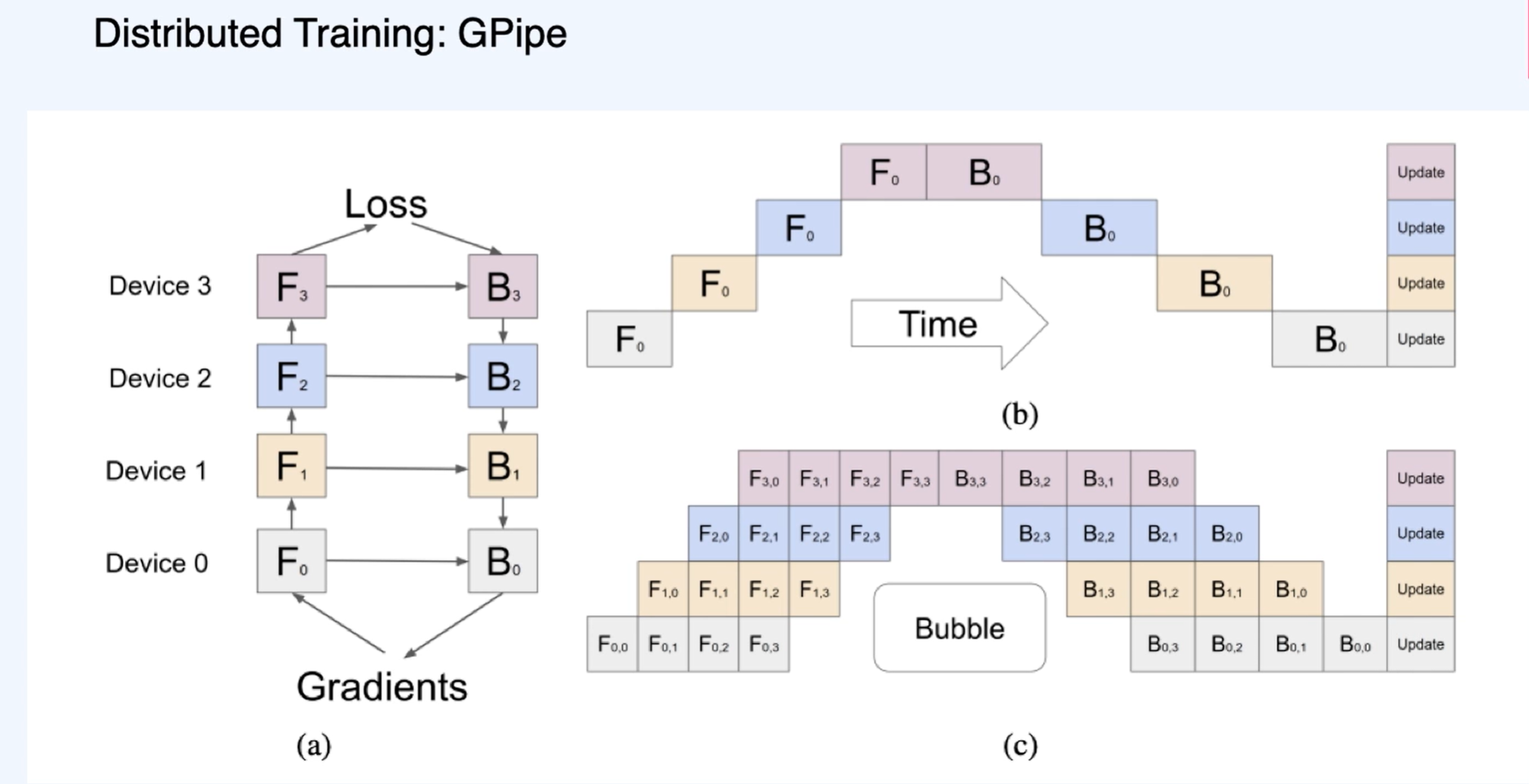
배치를 한 번 더 나눈 마이크로 배치를 활용하여 C와 같은 방식으로 시간을 단축시켰다!
Deep speed ZeRO : 파라미터와 Gradient, optimizer states을 따로 GPU에 저장해서 각각 사용한다.
from datasets import load_dataset
nsmc_dataset = load_dataset('nsmc')데이터 다운받기!
nsmc_dataset['train'][0]{'id': '9976970', 'document': '아 더빙.. 진짜 짜증나네요 목소리', 'label': 0}
확인해 보면 이전 실습에서도 많이 사용했던 데이터 들이다.
nsmc_df = nsmc_dataset['train'].to_pandas()
nsmc_df판다스로 변형시켜서 데이터 처리를 좀 더 쉽게 해준다.
from transformers import AutoTokenizer
tok = AutoTokenizer.from_pretrained('bert-base-multilingual-cased')허깅 페이스에서 토크나이저 가져오기
tok.tokenize('청춘 영화의 최고봉.')['청', '##춘', '영화', '##의', '최고', '##봉', '.']
다양한 단어로 학습된 토크나이저므로 완벽하게 나누진 못했지만 그래도 잘 나뉜 것을 볼 수 있다.
tok('청춘 영화의 최고봉.'){'input_ids': [101, 9751, 97707, 42428, 10459, 83491, 118989, 119, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1]}
토큰화 되었다!
tok(['청춘 영화의 최고봉.', '청춘'], padding=True){'input_ids': [[101, 9751, 97707, 42428, 10459, 83491, 118989, 119, 102], [101, 9751, 97707, 102, 0, 0, 0, 0, 0]], 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 0, 0, 0, 0, 0]]}
단어 길이를 맞추는 것을 볼 수 있다.
def tokenizer(data):
return tok(data['document'], max_length=32, padding='max_length', truncation=True)최대 길이를 맞추는 함수를 만들었다.
BERT는 동일한 길이로 맞춰줘야 하기 때문에...
nsmc_dataset_tokenized = nsmc_dataset.map(tokenizer)데이터에 토크나이저를 적용한다.
nsmc_dataset_tokenized['train'][0]{'id': '9976970',
'document': '아 더빙.. 진짜 짜증나네요 목소리',
'label': 0,
'input_ids': [101,
9519,
9074,
119005,
119,
119,
9708,
119235,
9715,
119230,
16439,
77884,
48549,
9284,
22333,
12692,
102,
0,
0,
0,
0,
0,
...
0,
0,
0,
0,
0]}
잘 된 것을 확인했다!
import torch
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
deviceGPU 확인하기!
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained('bert-base-multilingual-cased',
num_labels=2)학습된 모델을 불러온다
num_train_epochs = 2
learning_rate = 2e-7
batch_size = 128학습 파라미터들 정해주기!
from torch.utils.data import DataLoader데이터 로더 불러오기
tr_ds = nsmc_dataset_tokenized['train'].remove_columns(['id', 'document'])
tr_ds.set_format(type='torch')필요 없는 열들 제거해주기
tr_dl = DataLoader(tr_ds, batch_size=batch_size)
tr_dl데이터 로더에 데이터 넣어주기
val_ds = nsmc_dataset_tokenized['test'].remove_columns(['id', 'document'])
val_ds.set_format(type='torch')
val_dl = DataLoader(tr_ds, batch_size=batch_size)
val_dlvalidation도 만들어주기
그런데 이렇게 만들면 동일한 데이터에서 뽑아오니까 이러면 안되는거 아닌가...?
next(iter(tr_dl)){'label': tensor([0, 1, 0, 0, 1, 0, 0, 0, 1, 1, 1, 1, 0, 1, 0, 1, 1, 0, 1, 1, 1, 1, 0, 1,
0, 0, 1, 0, 1, 1, 1, 0, 1, 0, 1, 1, 0, 1, 0, 1, 1, 0, 1, 1, 1, 0, 0, 0,
0, 1, 1, 0, 1, 0, 1, 1, 0, 1, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, 1, 0, 0, 1,
0, 1, 0, 0, 1, 0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1,
1, 0, 1, 1, 1, 0, 1, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 1, 1, 0, 1, 0, 0, 0,
0, 0, 1, 1, 0, 1, 0, 1]),
'input_ids': tensor([[ 101, 9519, 9074, ..., 0, 0, 0],
[ 101, 100, 119, ..., 16439, 102, 0],
[ 101, 100, 102, ..., 0, 0, 0],
...,
[ 101, 9358, 12508, ..., 0, 0, 0],
[ 101, 9519, 25503, ..., 0, 0, 0],
[ 101, 10150, 10954, ..., 9568, 12310, 102]]),
'token_type_ids': tensor([[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]]),
'attention_mask': tensor([[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 1, 1, 0],
[1, 1, 1, ..., 0, 0, 0],
...,
[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 1, 1, 1]])}
tensor 형태로 잘 들어가 있는 것을 볼 수 있다.
import numpy as np
from tqdm import tqdm
from torch.nn import CrossEntropyLoss
from torch.optim import Adam
def acc(pred,label):
pred = torch.round(pred.squeeze())
return torch.sum(pred == label.squeeze()).item()
model.to(device)
criterion = CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=learning_rate)정답의 개수를 리턴하는 acc 함수!
for epoch in range(num_train_epochs):
train_losses = []
train_acc = 0.0
model.train()
for step, batch in enumerate(tqdm(tr_dl)):
label = batch['label'].to(device)
input_id, token_type_ids, attention_mask = batch['input_ids'].to(device), batch['token_type_ids'].to(device), batch['attention_mask'].to(device)
model.zero_grad()
pred = model(input_id, token_type_ids, attention_mask)
loss = criterion(torch.sigmoid(pred.logits.t()[1]), label.float())
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_losses.append(loss.item())
train_acc += acc(pred.logits.argmax(dim=1), label)
# if (step+1)%100==0:
# print("train loss: ", np.mean(train_losses))
# print("train acc: ", train_acc/(step*batch_size))
print("train loss: ", np.mean(train_losses))
print("train acc: ", train_acc/len(tr_dl.dataset))
val_losses = []
val_acc = 0
model.eval()
# validation 데이터를 통한 확인
for step, batch in enumerate(tqdm(val_dl)):
label = batch['label'].to(device)
input_id, token_type_ids, attention_mask = batch['input_ids'].to(device), batch['token_type_ids'].to(device), batch['attention_mask'].to(device)
pred = model(input_id, token_type_ids, attention_mask)
loss = criterion(torch.sigmoid(pred.logits.t()[1]), label.float())
val_losses.append(loss.item())
val_acc += acc(pred.logits.argmax(dim=1), label)
print("val loss: ", np.mean(val_losses))
print("val acc: ", val_acc/len(val_dl.dataset))
허깅페이스의 트레이너를 활용한 학습!
from transformers import TrainingArguments
logging_steps = len(nsmc_dataset['train']) // batch_size
output_dir = 'trainer_test'
training_args = TrainingArguments(output_dir=output_dir,
num_train_epochs=num_train_epochs,
learning_rate = learning_rate,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
evaluation_strategy='epoch',
logging_steps=logging_steps,
fp16=True,
push_to_hub=False)
from sklearn.metrics import precision_recall_fscore_support, accuracy_score
def compute_metrics(pred):
labels = pred.label_ids
preds = pred.predictions.argmax(-1)
precision, recall, f1, _ = precision_recall_fscore_support(labels, preds, average='binary')
acc = accuracy_score(labels, preds)
return {
'accuracy': acc,
'f1': f1,
'precision': precision,
'recall': recall
}다양한 평가 방법들을 넣어줬다.
from transformers import Trainer
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained('bert-base-multilingual-cased',
num_labels=2)
trainer = Trainer(model=model,
args=training_args,
compute_metrics=compute_metrics,
train_dataset=nsmc_dataset_tokenized['train'],
eval_dataset=nsmc_dataset_tokenized['test'],
tokenizer=tok)모델의 학습이 진행되었으므로 다시 불러온다!
평가 방식도 다시 넣어준다.
trainer.train()
학습하는 법!
'인공지능 > 자연어 처리' 카테고리의 다른 글
| 자연어 처리 : LLaMa Pretrain하기 - python 실습 (1) | 2024.07.21 |
|---|---|
| 자연어 처리 LLaMa 모델 분석하기 (0) | 2024.07.21 |
| Gen AI LM - GPT (1) | 2024.07.20 |
| Generative AI - LM Baseline (1) | 2024.07.20 |
| Python NLP - BERT Binary Classification (hugging Face Transformer library) (0) | 2024.06.19 |