오늘날 추천 시스템은 데이터의 불균형을 신경 쓰지 않아 사용도가 높은 참여자의 데이터는 많이 학습되어 잘 작동하고, 적은 참여자는 임베딩이 잘 못 생성되어 무시되는 경우가 있다.
온도말고 학습률을 높여서 진행하면 안되나?
모델이 구분을 잘 하도록? 오토인코더 왜 쓰?
로라가 좋았던 이유 - 도메인이 너무 많아 파라미터가 너무 많았다.

논문 요약 (한글)
논문 제목
모든 임베딩이 동일하게 생성되지 않는다: 대비 학습을 통한 견고한 크로스 도메인 추천을 향하여
문제 정의
크로스 도메인 추천(Cross-Domain Recommendation, CDR)은 소스 도메인의 풍부한 정보를 활용하여 타겟 도메인의 추천 성능을 향상하는 것을 목표로 합니다. 그러나 각기 다른 도메인 간의 데이터 불균형 문제는 CDR 접근 방식의 효과를 저하시킵니다. 기존의 대부분의 CDR 방법론은 타깃 도메인을 위한 더 나은 사용자 임베딩을 생성하는 데 중점을 두지만, 데이터 불균형으로 인한 사용자 활동의 불일치를 간과하는 경우가 많습니다. 이로 인해 더 빈번하게 상호작용하는 사용자는 우선시 되고, 덜 활발한 사용자는 간과되어, 이들에 대한 정확한 추천을 제공하는 데 어려움이 있습니다. 이러한 임베딩 생성 과정의 편향은 "모든 임베딩이 동일하게 생성되지 않는다"는 사실을 드러냅니다.
해결 방법
이 연구는 대비 학습(Contrastive Learning)의 최근 발전에 영감을 받아, 사용자 인식 대비 학습(User-aware Contrastive Learning)을 통해 견고한 크로스 도메인 추천을 제공하는 UCLR(User-aware Contrastive Learning for Robust cross-domain recommendation) 방법을 제안합니다. 제안된 방법은 두 개의 서브 모듈로 구성됩니다:
- 사전 학습된 글로벌 임베딩: 모든 도메인에 걸쳐 사전 학습된 글로벌 사용자 임베딩을 생성합니다.
- 대비 듀얼 스트림 협업 오토인코더(Contrastive Dual-stream Collaborative Autoencoder): 개별화된 온도(Individualized Temperatures)로 대비 손실을 최적화하여 보다 균등한 사용자 임베딩을 생성합니다.
또한 각 도메인 내에서 성능을 더욱 향상시키기 위해 Low-Rank Adaptation (LoRA)을 기반으로 전체 프레임워크를 미세 조정합니다.
연구 방법
- 문제 정의: 여러 도메인에 걸쳐 사용자 집합과 도메인별 아이템 집합을 갖는 다중 타깃 크로스 도메인 추천(MTCDR) 문제를 다룹니다.
- 프레임워크 개요: BPRMF 모델을 사용하여 사용자-아이템 상호작용 기반 글로벌 사용자 및 아이템 임베딩 매트릭스를 사전 학습합니다.
- 대비 듀얼 스트림 협업 오토인코더: 하나의 스트림은 원래 글로벌 사용자 임베딩을 재구성하고, 다른 스트림은 사용자 인식 대비 손실을 최적화하여 사용자 임베딩을 생성합니다. 여기서 개별화된 온도를 사용하여 사용자 간의 페널티 강도를 다르게 조절합니다.
- LoRA 미세 조정: 각 도메인 내에서 성능을 향상시키기 위해 LoRA를 사용하여 전체 프레임워크를 미세 조정합니다.
실험 및 결과
실험은 Amazon과 Douban의 두 개의 실제 데이터셋에서 수행되었습니다. 세 가지 주요 연구 질문을 다루었습니다:
- RQ1: 제안된 UCLR 방법이 다른 기준 방법들과 비교하여 어떻게 성능을 발휘하는가?
- RQ2: 제안된 UCLR 방법이 "모든 임베딩이 동일하게 생성되지 않는다"는 문제를 해결하는가?
- RQ3: 제안된 서브 모듈들이 성능 향상에 어떻게 기여하는가?
실험 결과는 제안된 UCLR 방법이 대부분의 도메인에서 기존 방법들보다 우수한 성능을 발휘하며, 특히 사용자 상호작용이 적은 경우에도 뛰어난 견고성을 보여줌을 입증했습니다.
한계점
UCLR 방법은 대부분의 도메인에서 우수한 성능을 보였지만, 일부 도메인에서는 여전히 성능 향상의 여지가 남아있습니다. 예를 들어, Amazon 데이터셋의 Movies 도메인에서는 최상위 방법인 CAT-ART에 비해 성능이 다소 떨어지는 경향을 보였습니다. 이는 특정 도메인에서의 아이템 수나 상호작용 빈도에 따른 효과가 다를 수 있음을 시사합니다.
결론
이 논문은 크로스 도메인 추천에서 데이터 불균형 문제를 해결하기 위해 사용자 인식 대비 학습을 제안했습니다. 제안된 UCLR 방법은 다중 도메인에 걸친 사용자 선호도를 효과적으로 반영하여, 덜 활발한 사용자에 대해서도 높은 정확도의 추천을 제공할 수 있음을 입증했습니다. 이는 크로스 도메인 추천 분야에 가치 있는 기여를 했다고 할 수 있습니다.
사용자 임베딩?
사용자 임베딩(user embedding)을 생성한다는 것은 사용자의 특성과 행동을 수치화된 벡터로 표현하는 과정을 의미합니다. 이 벡터는 기계 학습 모델이 사용자의 선호도를 이해하고 예측하는 데 사용됩니다.
사용자 임베딩 생성의 의미
- 데이터 수집:
- 사용자 임베딩을 생성하기 위해 먼저 사용자와 아이템 간의 상호작용 데이터를 수집합니다. 예를 들어, 사용자가 어떤 영화를 보았는지, 어떤 책을 읽었는지 등의 정보가 포함됩니다.
- 특성 추출:
- 수집된 데이터를 바탕으로 각 사용자의 특성을 추출합니다. 이 특성들은 사용자가 어떤 종류의 아이템을 선호하는지, 어떤 패턴으로 상호작용하는지를 반영합니다.
- 벡터화:
- 추출된 특성들을 고정된 크기의 벡터로 변환합니다. 이 벡터는 임베딩 공간에서 사용자의 위치를 나타내며, 유사한 선호도를 가진 사용자들은 임베딩 공간에서 가깝게 위치하게 됩니다.
- 모델 학습:
- 사용자와 아이템 간의 상호작용을 예측할 수 있도록 모델을 학습시킵니다. 이 과정에서 사용자 임베딩은 지속적으로 조정되며, 최종적으로 사용자의 선호도를 가장 잘 반영하는 벡터로 수렴하게 됩니다.
사용자 임베딩의 중요성
- 추천 시스템 성능 향상:
- 정확한 사용자 임베딩은 추천 시스템의 성능을 크게 향상합니다. 사용자의 선호도를 잘 반영하는 임베딩은 더 정확한 추천을 가능하게 합니다.
- 데이터 불균형 문제 해결:
- 논문에서 다룬 것처럼, 데이터 불균형 문제는 추천 시스템의 성능을 저하시킬 수 있습니다. 임베딩 생성 과정에서 빈번하게 상호작용하는 사용자가 우선시 되면, 덜 활발한 사용자는 정확한 임베딩을 얻기 어렵습니다. 이를 해결하기 위해 논문에서는 대비 학습(Contrastive Learning)과 개별화된 온도 조절(individualized temperature adjustment)을 사용하여 더 균등한 임베딩을 생성하는 방법을 제안하고 있습니다.
예시
- 영화 추천 시스템:
- 사용자가 어떤 영화를 봤는지, 어떤 장르를 선호하는지 등의 정보를 기반으로 사용자 임베딩을 생성합니다. 임베딩 벡터는 사용자가 선호하는 영화의 특징을 반영하며, 이를 통해 새로운 영화를 추천할 수 있습니다.
- 쇼핑몰 추천 시스템:
- 사용자가 구매한 제품, 검색한 제품 등의 정보를 기반으로 사용자 임베딩을 생성합니다. 임베딩 벡터는 사용자가 선호하는 제품의 특징을 반영하며, 이를 통해 새로운 제품을 추천할 수 있습니다.
결론
사용자 임베딩 생성은 추천 시스템의 핵심 요소로, 사용자의 선호도를 수치화된 벡터로 표현하여 더 정확한 추천을 가능하게 합니다. 데이터 불균형 문제를 해결하기 위해 논문에서 제안된 방법은 대비 학습과 개별화된 온도 조절을 통해 더 균등한 임베딩을 생성하는 것을 목표로 합니다.
대비학습
대비 학습 (Contrastive Learning)
대비 학습은 머신러닝에서 데이터 포인트 간의 유사성을 학습하는 방법 중 하나입니다. 주로 자기 지도 학습(self-supervised learning)에서 사용되며, 데이터 포인트를 서로 대비시킴으로써 유사한 것끼리는 가깝게, 다른 것끼리는 멀어지도록 학습합니다.
핵심 개념
- 앵커 포인트 (Anchor Point):
- 대비 학습의 중심이 되는 데이터 포인트입니다.
- 양성 샘플 (Positive Sample):
- 앵커 포인트와 유사한 데이터 포인트입니다. 예를 들어, 같은 클래스에 속하는 데이터 포인트일 수 있습니다.
- 음성 샘플 (Negative Sample):
- 앵커 포인트와 다른 데이터 포인트입니다. 예를 들어, 다른 클래스에 속하는 데이터 포인트일 수 있습니다.
학습 과정
- 특징 추출:
- 앵커 포인트와 양성 샘플, 음성 샘플에서 특징 벡터를 추출합니다.
- 대비 손실 (Contrastive Loss):
- 대비 손실은 앵커 포인트와 양성 샘플 간의 거리를 줄이고, 앵커 포인트와 음성 샘플 간의 거리를 늘리도록 설계된 손실 함수입니다. 이는 보통 다음과 같이 정의됩니다:


- 대비 손실은 앵커 포인트와 양성 샘플 간의 거리를 줄이고, 앵커 포인트와 음성 샘플 간의 거리를 늘리도록 설계된 손실 함수입니다. 이는 보통 다음과 같이 정의됩니다:
개별화된 온도 (Individualized Temperatures)
개별화된 온도는 대비 손실 함수에서 각 데이터 포인트마다 다른 온도 매개변수를 사용하는 것을 의미합니다. 이는 데이터 포인트 간의 유사도 계산에서 패널티의 강도를 조절하는 데 사용됩니다.
왜 개별화된 온도가 필요한가?
- 다양한 사용자 행동: 데이터 포인트마다 상호작용 빈도가 다를 수 있습니다. 예를 들어, 어떤 사용자는 많은 상호작용을 가지고 있고, 다른 사용자는 적은 상호작용을 가질 수 있습니다.
- 맞춤형 학습: 개별화된 온도를 사용하면 각 데이터 포인트의 특성에 맞춰 패널티 강도를 조절할 수 있어, 모든 사용자를 공평하게 학습할 수 있습니다.
대비 손실 (Contrastive Loss)
대비 손실은 대비 학습에서 사용하는 손실 함수로, 주로 두 가지 목적을 가지고 있습니다:
- 양성 샘플의 유사도 극대화: 앵커 포인트와 양성 샘플 간의 유사도를 최대화합니다.
- 음성 샘플의 유사도 최소화: 앵커 포인트와 음성 샘플 간의 유사도를 최소화합니다.
공식
대비 손실 함수는 다음과 같은 형태로 정의됩니다:
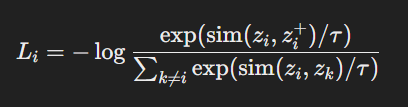
여기서:

결론
- 대비 학습은 유사한 데이터 포인트는 가깝게, 다른 데이터 포인트는 멀어지도록 학습하는 방법입니다.
- 개별화된 온도는 각 데이터 포인트마다 다른 온도 매개변수를 사용하여 학습의 맞춤형 조절을 가능하게 합니다.
- 대비 손실은 앵커 포인트와 양성 샘플 간의 거리를 줄이고, 앵커 포인트와 음성 샘플 간의 거리를 늘리는 손실 함수입니다.
이러한 개념들을 활용하면, 추천 시스템에서 데이터 불균형 문제를 해결하고, 보다 정확한 사용자 임베딩을 생성하여 추천 성능을 향상할 수 있습니다.
개별화된 온도?
개별화된 온도 (Individualized Temperatures) 상세 설명
기본 개념
대비 학습에서 온도 매개변수(temperature parameter) (\tau)는 손실 함수에서 데이터 포인트 간 유사도 계산 시 페널티의 강도를 조절합니다. 온도가 높을수록 데이터 포인트 간 차이를 덜 민감하게 평가하고, 온도가 낮을수록 더 민감하게 평가합니다. 개별화된 온도는 이 온도 매개변수를 사용자나 데이터 포인트마다 다르게 설정하는 것을 의미합니다.
왜 개별화된 온도가 필요한가?
- 다양한 사용자 행동:
- 데이터셋에서 사용자의 상호작용 빈도는 매우 다양할 수 있습니다. 일부 사용자는 매우 빈번하게 상호작용하지만, 다른 사용자는 드물게 상호작용할 수 있습니다. 이러한 차이는 임베딩 생성 시 불균형을 초래할 수 있습니다.
- 맞춤형 학습:
- 모든 사용자에게 동일한 온도를 적용하면 상호작용이 많은 사용자에게 최적화된 모델이 만들어질 수 있으며, 이는 상호작용이 적은 사용자에 대한 성능을 저하시킬 수 있습니다. 개별화된 온도를 사용하면 각 사용자의 상호작용 빈도에 맞춰 페널티 강도를 조절할 수 있습니다.
개별화된 온도 적용 방법
- 온도 매개변수의 설정:
- 각 사용자 (i)에 대해 온도 매개변수 (\tau_i)를 설정합니다. 이는 데이터 포인트의 특성, 즉 사용자의 상호작용 빈도에 따라 다르게 설정됩니다.
- 온도 매개변수의 최적화:
- 학습 과정에서 각 사용자의 온도 매개변수를 최적화합니다. 이는 손실 함수를 최소화하기 위해 각 사용자의 온도 매개변수를 조정하는 과정입니다.
대비 손실 함수와 개별화된 온도

개별화된 온도의 효과
- 패널티 강도 조절:
- 온도 매개변수가 낮을수록 손실 함수는 유사도 차이에 더 민감해지므로, 상호작용이 적은 사용자에 대해 더 강한 패널티를 적용할 수 있습니다.
- 온도 매개변수가 높을수록 손실 함수는 유사도 차이에 덜 민감해지므로, 상호작용이 많은 사용자에 대해 더 완화된 패널티를 적용할 수 있습니다.
- 유사도 공간에서의 분리:
- 개별화된 온도를 사용하면 각 사용자의 임베딩이 유사도 공간에서 더 적절하게 분리될 수 있어, 모든 사용자에 대해 공정하고 정확한 임베딩을 생성할 수 있습니다.
예시
사용자 A와 사용자 B가 있다고 가정해봅시다:

결론
개별화된 온도는 대비 학습에서 각 데이터 포인트나 사용자마다 온도 매개변수를 다르게 설정함으로써, 데이터 불균형 문제를 해결하고 모든 사용자에 대해 공정하고 정확한 임베딩을 생성할 수 있도록 도와줍니다. 이는 특히 상호작용 빈도가 다양한 사용자들이 존재하는 실제 추천 시스템에서 매우 유용합니다.
LoRA?
Low-Rank Adaptation (LoRA) 설명
LoRA(Low-Rank Adaptation)는 머신러닝 모델을 미세 조정(finetuning)하는 방법 중 하나로, 모델의 파라미터 수를 줄이고 효율적으로 학습할 수 있도록 합니다. 이는 주로 대규모 언어 모델(LLMs)에서 사용되며, 모델을 보다 효율적으로 적응시키기 위해 도입되었습니다.
기본 개념
- 기존의 미세 조정 방법:
- 모델 전체의 파라미터를 업데이트합니다. 이는 많은 계산 자원을 필요로 하며, 특히 대규모 모델에서는 비효율적일 수 있습니다.
- LoRA의 접근 방법:
- 모델 파라미터를 저 차원(low-rank) 공간으로 분해하여 업데이트합니다. 이는 모델의 파라미터 수를 줄이고, 필요한 계산량을 감소시킵니다.
LoRA의 구현 방법

논문에서의 LoRA 적용
목적
각 도메인 내에서 성능을 더욱 향상하기 위해, 논문에서는 Low-Rank Adaptation (LoRA)을 사용하여 전체 프레임워크를 미세 조정합니다. 이는 사전 학습된 글로벌 모델이 각 도메인에 대해 과적합(over-parameterized)되는 문제를 해결하고, 보다 효율적으로 모델을 적응시키기 위해 도입되었습니다.
구체적인 적용 방법
- 글로벌 모델 학습:
- 우선, BPRMF 모델을 사용하여 글로벌 사용자 및 아이템 임베딩을 사전 학습합니다.
- LoRA 기반 미세 조정:

- 손실 함수 구성:
- 기존의 BPR 손실과 대비 학습 손실을 결합하여 최종 손실 함수를 구성합니다. 이를 통해, 모델이 각 도메인에 대해 최적화될 수 있도록 합니다.
결론
LoRA는 모델의 파라미터를 저 차원 공간으로 분해하여 효율적으로 미세 조정하는 방법으로, 논문에서는 이를 통해 각 도메인 내에서의 성능을 향상하고자 했습니다. LoRA를 사용하면, 대규모 모델을 보다 효율적으로 학습할 수 있으며, 각 도메인의 특성에 맞춘 맞춤형 파라미터 업데이트가 가능합니다.
크로스 도메인?
크로스 도메인 추천(Cross-Domain Recommendation, CDR)
개념 설명
크로스 도메인 추천(Cross-Domain Recommendation, CDR)은 한 도메인(소스 도메인)의 데이터를 활용하여 다른 도메인(타겟 도메인)의 추천 성능을 향상시키는 것을 의미합니다. 이는 사용자가 여러 도메인에서 활동하는 경우, 한 도메인의 정보가 다른 도메인의 추천 정확도를 높이는 데 도움이 될 수 있다는 가정에 기반합니다.
예시
- 영화와 책 추천: 사용자가 주로 영화를 많이 본다면, 이 영화 데이터(소스 도메인)를 활용하여 사용자가 좋아할 만한 책(타겟 도메인)을 추천할 수 있습니다. 예를 들어, 사용자가 로맨틱 영화를 많이 본다면, 로맨틱 소설을 추천할 수 있습니다.
- 음악과 패션 추천: 사용자가 주로 듣는 음악 장르를 기반으로 그와 어울리는 패션 스타일을 추천할 수 있습니다. 예를 들어, 사용자가 힙합 음악을 많이 듣는다면, 힙합 스타일의 옷을 추천할 수 있습니다.
논문에서의 크로스 도메인 추천
논문에서는 다음과 같은 과정을 통해 크로스 도메인 추천을 구현하고 있습니다:
- 사전 학습된 글로벌 임베딩:
- 모든 도메인의 사용자 및 아이템 데이터를 통합하여 글로벌 임베딩을 학습합니다.
- 대비 듀얼 스트림 협업 오토인코더:
- 대비 학습을 통해 각 도메인의 데이터 불균형을 해결하고, 더 균등한 사용자 임베딩을 생성합니다.
- 도메인 인식 LoRA 미세 조정:
- 각 도메인에 맞춰 파라미터를 저차원 공간으로 분해하여 효율적으로 미세 조정합니다.
데이터 불균형 문제 해결
크로스 도메인 추천에서 중요한 문제는 데이터 불균형입니다. 각 도메인에서 사용자 활동 빈도가 다를 수 있으며, 이는 추천 정확도에 영향을 미칠 수 있습니다. 논문에서는 대비 학습과 개별화된 온도 매개변수를 통해 이 문제를 해결하고자 합니다.
- 대비 학습: 서로 다른 도메인의 사용자 임베딩을 비교하여, 유사한 사용자들 간의 유사도를 극대화하고, 다른 사용자들 간의 유사도를 최소화합니다.
- 개별화된 온도: 각 사용자의 상호작용 빈도에 따라 패널티 강도를 조절하여, 덜 활발한 사용자를 위한 임베딩을 더 정확하게 만듭니다.
결론
크로스 도메인 추천은 한 도메인의 데이터를 활용하여 다른 도메인의 추천 성능을 향상시키는 방법입니다. 이는 영화 데이터를 활용하여 책을 추천하는 것과 같은 다양한 응용이 가능합니다. 논문에서는 데이터 불균형 문제를 해결하기 위해 대비 학습과 개별화된 온도 매개변수를 사용하는 방법을 제안하고 있습니다.
MF? BPR?
행렬 분해 (Matrix Factorization, MF)
행렬 분해는 대규모 데이터셋을 더 작은 차원으로 분해하는 방법입니다. 추천 시스템에서 행렬 분해는 사용자-아이템 상호작용 행렬을 분해하여 사용자와 아이템의 잠재 요인(latent factors)을 찾는 데 사용됩니다.
예시:
- 사용자-아이템 상호작용 행렬은 사용자가 아이템을 평가한 점수를 나타냅니다.
- 이 행렬을 두 개의 저차원 행렬(사용자 행렬과 아이템 행렬)로 분해합니다.
- 이 두 행렬의 곱으로 원래의 상호작용 행렬을 근사할 수 있습니다.
베이즈 개인화 순위 손실 (Bayes Personalized Ranking, BPR)
BPR은 추천 시스템에서 순위를 학습하는 데 사용되는 손실 함수입니다. BPR의 목적은 사용자가 선호하는 아이템이 그렇지 않은 아이템보다 더 높은 순위에 위치하도록 학습하는 것입니다.
BPR 손실 함수의 특징:
- BPR은 아이템 간의 쌍(pairwise) 비교를 통해 순위를 학습합니다.
- 사용자 uu가 아이템 ii를 아이템 jj보다 더 선호한다고 가정합니다. 여기서 ii는 사용자가 상호작용한 아이템이고, jj는 상호작용하지 않은 아이템입니다.
- BPR 손실 함수는 다음과 같이 정의됩니다

결론적으로, 주어진 구문의 의미는 다음과 같습니다:
- 행렬 분해(MF) 모델을 채택:
- 여러 도메인에 걸친 사용자와 아이템의 상호작용 데이터를 바탕으로 행렬 분해를 사용하여 사용자 임베딩과 아이템 임베딩을 생성합니다.
- 베이즈 개인화 순위 손실(BPR) 사용:
- BPR 손실 함수를 사용하여, 사용자가 선호하는 아이템이 그렇지 않은 아이템보다 더 높은 순위에 위치하도록 모델을 학습합니다.
이를 통해, 여러 도메인에 걸쳐 사용자와 아이템 간의 상호작용을 반영한 임베딩을 생성하고, 이를 바탕으로 보다 정확한 추천을 제공할 수 있게 됩니다.
Dual-Stream Autoencoder?
듀얼 스트림 오토인코더(Dual-Stream Autoencoder)는 두 개의 입력 스트림을 사용하는 오토인코더입니다. 이 문장에서 듀얼 스트림 오토인코더는 사전 학습된 글로벌 사용자 임베딩을 원본 형태와 무작위 마스킹(random masking)된 형태로 입력받아 처리합니다. 이를 이해하기 위해 오토인코더와 듀얼 스트림 오토인코더의 개념을 자세히 설명하겠습니다.
오토인코더 (Autoencoder)
오토인코더는 입력 데이터를 압축된 표현으로 변환하고, 이를 다시 원래의 데이터로 복원하는 것을 목표로 하는 신경망입니다. 오토인코더는 일반적으로 두 부분으로 구성됩니다:
- 인코더 (Encoder):
- 입력 데이터를 저차원(latent space)으로 변환합니다.
- 디코더 (Decoder):
- 저차원 표현을 다시 원래의 고차원 데이터로 복원합니다.
듀얼 스트림 오토인코더 (Dual-Stream Autoencoder)
듀얼 스트림 오토인코더는 두 개의 입력 스트림을 사용하는 오토인코더입니다. 이 경우, 두 개의 입력 스트림은 사전 학습된 글로벌 사용자 임베딩의 원본 형태와 무작위 마스킹된 형태입니다. 듀얼 스트림 오토인코더는 두 개의 서로 다른 경로를 통해 입력 데이터를 처리하고, 이를 통해 보다 견고한 임베딩을 학습합니다.
구체적인 설명
- 입력 스트림:
- 원본 형태의 글로벌 사용자 임베딩: 사전 학습된 글로벌 사용자 임베딩을 그대로 입력으로 사용합니다.
- 무작위 마스킹된 글로벌 사용자 임베딩: 사전 학습된 글로벌 사용자 임베딩에서 일부 요소를 무작위로 마스킹하여 입력으로 사용합니다. 여기서 마스킹은 특정 요소를 0으로 설정하는 것을 의미합니다.
- 인코더:
- 두 개의 입력 스트림(원본 임베딩과 마스킹된 임베딩)을 각각 인코딩하여 저차원 표현으로 변환합니다.
- 대비 학습:
- 인코딩된 두 개의 저차원 표현을 비교하여, 같은 사용자의 임베딩은 더 가깝게, 다른 사용자의 임베딩은 더 멀어지도록 학습합니다.
- 개별화된 온도 매개변수를 사용하여 각 사용자의 임베딩을 최적화합니다.
- 디코더:
- 두 개의 인코딩된 표현을 다시 원래의 고차원 데이터로 복원합니다.
- 원본 임베딩을 재구성하고, 마스킹된 임베딩을 원본 형태로 복원합니다.
예시
- 원본 형태의 글로벌 사용자 임베딩:
- 예를 들어, 사용자가 좋아하는 영화 목록을 임베딩으로 표현합니다. 이 임베딩은 사용자의 선호도를 나타냅니다.
- 무작위 마스킹된 글로벌 사용자 임베딩:
- 동일한 사용자의 영화 목록 임베딩에서 일부 요소를 0으로 설정합니다. 이는 데이터의 일부가 누락된 상태를 시뮬레이션합니다.
- 인코더:
- 두 개의 임베딩을 각각 인코딩하여 저차원 표현으로 변환합니다.
- 대비 학습:
- 두 저차원 표현을 비교하여 같은 사용자의 임베딩은 더 가깝게, 다른 사용자의 임베딩은 더 멀어지도록 학습합니다.
- 디코더:
- 두 저차원 표현을 다시 원래의 고차원 데이터로 복원합니다. 원본 임베딩은 재구성되고, 마스킹된 임베딩은 원본 형태로 복원됩니다.
결론
듀얼 스트림 오토인코더는 사전 학습된 글로벌 사용자 임베딩을 두 가지 형태(원본과 무작위 마스킹)로 입력받아 처리합니다. 이를 통해 데이터의 일부가 누락된 상황에서도 견고한 임베딩을 학습할 수 있습니다. 이 과정에서 대비 학습과 개별화된 온도 매개변수를 사용하여 각 사용자의 임베딩을 최적화하고, 보다 정확한 추천 시스템을 구축할 수 있습니다.
Negative pairs?
대비 학습에서의 Positive Pair와 Negative Pair
대비 학습(Contrastive Learning)은 데이터 포인트 간의 유사성과 차이를 학습하는 방법입니다. 이 방법은 주로 자기 지도 학습(self-supervised learning)에서 사용되며, 데이터 포인트 간의 유사도 점수를 조정하여 모델을 학습시킵니다.
Positive Pair와 Negative Pair의 정의
- Positive Pair(양성 쌍):
- 서로 유사한 데이터 포인트의 쌍입니다. 예를 들어, 같은 클래스에 속하는 두 이미지 또는 동일한 사용자의 두 상호작용 기록이 positive pair가 될 수 있습니다.
- 대비 학습에서는 positive pair의 유사도 점수를 높이는 것을 목표로 합니다.
- Negative Pair(음성 쌍):
- 서로 다른 데이터 포인트의 쌍입니다. 예를 들어, 다른 클래스에 속하는 두 이미지 또는 다른 사용자의 상호작용 기록이 negative pair가 될 수 있습니다.
- 대비 학습에서는 negative pair의 유사도 점수를 낮추는 것을 목표로 합니다.
대비 손실 함수(Contrastive Loss)
대비 손실 함수는 positive pair와 negative pair 간의 유사도 점수를 조정하는 역할을 합니다. 목표는 positive pair의 유사도 점수를 높이고, negative pair의 유사도 점수를 낮추는 것입니다.
대비 학습의 목표
대비 학습의 주요 목표는 다음과 같습니다:
- Positive Pair의 유사도 증가:
- 앵커 포인트와 positive pair 간의 유사도를 높입니다. 이는 두 데이터 포인트가 더 가깝도록 만듭니다.
- Negative Pair의 유사도 감소:
- 앵커 포인트와 negative pair 간의 유사도를 낮춥니다. 이는 두 데이터 포인트가 더 멀어지도록 만듭니다.
이를 통해 모델은 데이터 포인트 간의 유사성과 차이를 학습하여, 새로운 데이터 포인트에 대해서도 올바른 유사도를 계산할 수 있게 됩니다.
예시
이미지 분류
- Positive Pair:
- 같은 종류의 두 이미지(예: 두 마리 고양이의 사진).
- Negative Pair:
- 다른 종류의 두 이미지(예: 고양이 사진과 개 사진).
대비 학습에서는 같은 종류의 이미지를 더 가깝게(유사도 증가), 다른 종류의 이미지를 더 멀게(유사도 감소) 학습합니다.
추천 시스템
- Positive Pair:
- 같은 사용자의 두 상호작용(예: 사용자가 좋아한 두 개의 영화).
- Negative Pair:
- 다른 사용자의 상호작용(예: 한 사용자가 좋아한 영화와 다른 사용자가 좋아한 영화).
대비 학습에서는 같은 사용자의 상호작용을 더 가깝게(유사도 증가), 다른 사용자의 상호작용을 더 멀게(유사도 감소) 학습합니다.
결론
대비 학습은 positive pair와 negative pair 간의 유사도 점수를 조정하여 데이터 포인트 간의 유사성과 차이를 학습합니다. 이를 통해 모델은 주어진 앵커 포인트에 대해 올바른 유사도를 계산할 수 있으며, 새로운 데이터 포인트에 대한 유사도도 정확하게 예측할 수 있게 됩니다.
contrastive dualstream collaborative autoencoder?
Contrastive Dual-Stream Collaborative Autoencoder
개요
Contrastive Dual-Stream Collaborative Autoencoder(대비 듀얼 스트림 협업 오토인코더)는 두 개의 스트림을 통해 사용자 임베딩을 학습하는 구조입니다. 이 구조는 각각의 스트림이 서로 다른 목적을 가지고 데이터를 처리하여, 최종적으로 더 나은 임베딩을 생성하는 데 기여합니다.
목적
이 접근 방식은 다음 두 가지 주요 목적을 가지고 있습니다:
- 원래의 글로벌 사용자 임베딩 재구성: 원본 임베딩을 복원하여 기존 정보의 보존을 목표로 합니다.
- 다른 사용자로 인한 효과 완화: 다른 사용자들의 영향을 줄여 보다 개인화된 임베딩을 생성합니다.
구조 및 작동 방식
- 입력 데이터:
- 사전 학습된 글로벌 사용자 임베딩: 모든 도메인에 걸쳐 사전 학습된 사용자 임베딩이 입력으로 사용됩니다.
- 무작위 마스킹된 글로벌 사용자 임베딩: 원래의 글로벌 사용자 임베딩을 무작위로 일부 요소를 마스킹한 형태로 사용합니다.
- 두 개의 스트림:
- 스트림 1: 원래 임베딩 재구성:
- 이 스트림의 목표는 원래의 글로벌 사용자 임베딩을 그대로 재구성하는 것입니다.
- 인코더와 디코더 구조를 통해 입력 임베딩을 압축된 표현으로 변환한 후, 다시 원래의 임베딩으로 복원합니다.
- 스트림 2: 다른 사용자의 효과 완화:
- 이 스트림의 목표는 다른 사용자들의 영향을 줄여 보다 개인화된 임베딩을 생성하는 것입니다.
- 무작위 마스킹된 임베딩을 입력으로 사용하여 인코딩하고, 이를 통해 얻어진 압축된 표현을 다른 사용자로 인한 노이즈를 줄인 임베딩으로 변환합니다.
- 스트림 1: 원래 임베딩 재구성:
- 대비 학습:
- 두 스트림에서 생성된 임베딩을 비교하여, 양성 쌍(positive pairs)의 유사도는 높이고 음성 쌍(negative pairs)의 유사도는 낮추는 방식으로 학습합니다.
- 개별화된 온도 매개변수를 사용하여 각 사용자의 임베딩을 최적화합니다.
- 최종 출력:
- 두 스트림의 출력은 최종적으로 결합되어 더 나은 사용자 임베딩을 생성합니다.
- 이 임베딩은 사용자 간의 유사성과 차이를 잘 반영하여 추천 시스템의 성능을 향상시킵니다.
구체적인 작동 방식 예시

결론
Contrastive Dual-Stream Collaborative Autoencoder는 두 개의 스트림을 통해 사용자 임베딩을 학습하여, 하나는 원래의 임베딩을 재구성하고, 다른 하나는 다른 사용자의 영향을 줄인 임베딩을 생성하는 구조입니다. 이를 통해 보다 개인화된 임베딩을 만들고, 추천 시스템의 성능을 향상시킬 수 있습니다.
스트림? 이게 임베딩?
스트림(Stream)이란?
스트림의 의미
스트림(Stream)은 데이터 처리의 경로를 의미합니다. Contrastive Dual-Stream Collaborative Autoencoder에서는 두 개의 독립적인 데이터 처리 경로(스트림)를 사용하여 임베딩을 학습합니다.
임베딩 생성 과정
사전 학습된 글로벌 사용자 임베딩
먼저, 사용자와 아이템의 상호작용 데이터를 바탕으로 사전 학습된 글로벌 사용자 임베딩이 생성됩니다. 이는 다른 모델(예: Matrix Factorization, BPR 등)을 통해 미리 학습된 임베딩 벡터입니다.
두 개의 스트림
스트림 1: 원래 임베딩 재구성

스트림 2: 다른 사용자의 효과 완화

대비 학습(Contrastive Learning)
양성 쌍(Positive Pair)과 음성 쌍(Negative Pair)

대비 손실 함수
대비 손실 함수는 양성 쌍의 유사도를 극대화하고 음성 쌍의 유사도를 최소화하는 역할을 합니다. 이를 통해 모델은 같은 사용자의 임베딩은 더 가깝게, 다른 사용자의 임베딩은 더 멀게 학습합니다.
최종 임베딩 생성
결합된 출력
두 스트림에서 생성된 임베딩을 결합하여 최종 사용자 임베딩을 생성합니다. 이 최종 임베딩은 사용자의 개인적 특성과 상호작용 패턴을 잘 반영하여 추천 시스템의 성능을 향상시킵니다.
결론
Contrastive Dual-Stream Collaborative Autoencoder는 두 개의 독립적인 스트림을 통해 사용자 임베딩을 학습합니다. 첫 번째 스트림은 원래의 임베딩을 재구성하여 기존 정보를 보존하고, 두 번째 스트림은 다른 사용자의 영향을 줄인 개인화된 임베딩을 생성합니다. 이를 통해 보다 정확하고 개인화된 추천을 가능하게 합니다.
Pretrained Global Embedding??
단계별 설명
1단계: 도입
이 부분에서는 여러 도메인에 걸쳐 사용자의 풍부한 정보를 활용하여, 모든 도메인의 사용자-아이템 상호작용을 통합한 글로벌 임베딩을 생성합니다.
2단계: 상호작용 행렬 정의
- 상호작용 행렬 R:

3단계: 임베딩 행렬 생성
- 사용자 임베딩 행렬 E:

- 아이템 임베딩 행렬 I:

4단계: 사용자와 아이템 임베딩 생성

5단계: 선호도 점수 계산

6단계: BPR 손실 함수 도입
- BPR 손실 함수:
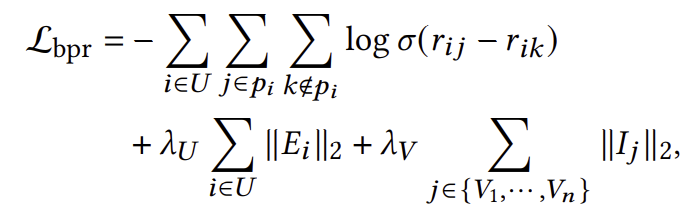

7단계: BPR 손실 함수의 작동 방식
- BPR 손실 함수는 양성 샘플과 음성 샘플 간의 차이를 학습합니다:
- 목표는 양성 샘플의 선호도 점수가 음성 샘플의 선호도 점수보다 높도록 하는 것입니다.

8단계: 정규화 항 추가
- 정규화 항을 추가하여 모델의 복잡도를 줄이고 과적합을 방지합니다.
9단계: 사전 학습 완료
- BPRMF(Bayesian Personalized Ranking Matrix Factorization) 모델을 사용하여 두 개의 임베딩 행렬 E와 I를 사전 학습합니다.
- 이를 통해 모든 도메인의 사용자 선호도를 포착한 글로벌 사용자 및 아이템 임베딩을 얻습니다.
요약
- 다양한 도메인의 사용자-아이템 상호작용 데이터를 통합하여 상호작용 행렬 을 정의합니다.
- 사용자와 아이템 임베딩 행렬 와 를 생성합니다.
- 각 사용자와 아이템에 대해 임베딩 벡터를 얻습니다.
- 사용자의 아이템에 대한 선호도 점수를 계산합니다.
- BPR 손실 함수를 사용하여 모델을 학습하고, 양성 샘플과 음성 샘플 간의 차이를 학습합니다.
- 정규화 항을 추가하여 과적합을 방지합니다.
- 사전 학습을 완료하여 글로벌 사용자 및 아이템 임베딩을 얻습니다.
이 과정을 통해 다양한 도메인의 정보를 통합한 글로벌 사용자 임베딩과 아이템 임베딩을 생성할 수 있습니다.
Contrastive Dual-Stream Collaborative
요약
- 사전 학습된 글로벌 사용자 임베딩 E 생성.
- 일부 사용자 임베딩을 마스킹하여 E′ 생성.
- 두 개의 입력 데이터 E와 E′를 사용하여 듀얼 스트림 오토인코더 구성.
- 두 스트림에서 각각 저차원 표현 e와 e′ 생성.
- 대비 손실 함수를 통해 양성 샘플의 유사도를 최대화하고 음성 샘플의 유사도를 최소화.
- 저차원 표현을 디코딩하여 원래의 임베딩 E와 마스킹된 임베딩 E′ 재구성.
- 재구성 손실 함수를 통해 모델의 안정성 확보.
- 결합 손실 함수를 최소화하여 모델 학습 및 최적화.
Domain-aware LoRA Finetune
단계 1: 각 도메인의 사용자-아이템 상호작용 정보 사용
- 목적: 각 도메인별로 사용자-아이템 상호작용 데이터를 사용하여 프레임워크를 미세 조정합니다.
단계 2: BPR 손실을 사용한 행렬 분해 모델
- 행렬 분해 모델:
- 각 도메인 d에서 사용자-아이템 상호작용 데이터를 사용하여 행렬 분해 모델을 학습합니다.
- BPR 손실을 사용하여 모델을 학습합니다:

단계 3: 결합 손실 함수 구성
- 결합 손실 함수:

단계 4: 과적합 문제 해결
- 과적합 문제:
- 사전 학습된 모델이 모든 도메인을 대상으로 학습되었기 때문에, 개별 도메인에서는 과적합(over-parameterization) 문제가 발생할 수 있습니다.
- 이를 해결하기 위해 Low-Rank Adaptation (LoRA)을 사용합니다.
단계 5: Low-Rank Adaptation (LoRA) 사용
- LoRA 개념:

단계 6: 최종 미세 조정
- 미세 조정 과정:
- 결합 손실 함수를 최소화하여 A와 B의 가중치를 최적화합니다.
- 최종적으로 도메인에 맞게 미세 조정된 임베딩 W를 얻습니다.
요약
- 각 도메인별 사용자-아이템 상호작용 데이터를 사용하여 행렬 분해 모델을 학습합니다.
- BPR 손실을 사용하여 모델을 학습하고, 정규화 항을 추가하여 과적합을 방지합니다.
- 대비 듀얼 스트림 협업 오토인코더의 결합 손실 함수와 각 도메인의 BPR 손실을 합쳐 최종 미세 조정 손실 함수를 구성합니다.
- 사전 학습된 모델이 과적합되는 문제를 해결하기 위해 Low-Rank Adaptation (LoRA)을 사용합니다.
- LoRA를 사용하여 저차원 행렬 A와 B를 학습하여 모델을 미세 조정합니다.
- 결합 손실 함수를 최소화하여 최종적으로 도메인에 맞게 미세 조정된 임베딩 W를 얻습니다.
이 과정을 통해 각 도메인에서의 성능을 향상시키고, 사용자의 상호작용 빈도에 따라 보다 개인화된 임베딩을 생성할 수 있습니다.
Algorithmm Procedure
단계 1: BPRMF 모델을 사용한 사전 학습
- 목적: 모든 도메인에서 사용자의 선호도를 포착하기 위해 BPRMF(Bayesian Personalized Ranking Matrix Factorization) 모델을 사용하여 글로벌 사용자 및 아이템 임베딩을 사전 학습합니다.
단계 2: 사용자 인식 대비 학습 적용
- 목적: 다양한 상호작용 빈도를 가진 사용자들 간의 부정적인 영향을 제거하기 위해 사용자 인식 대비 학습(User-aware Contrastive Learning)을 사용합니다.
단계 3: 글로벌 사용자 임베딩 무작위 마스킹
- 과정: 사전 학습된 글로벌 사용자 임베딩을 무작위로 일부 요소를 마스킹하여 새로운 임베딩을 생성합니다. 이는 사용자 임베딩의 일부분을 0 벡터로 대체합니다.
단계 4: 두 개의 사용자 임베딩 인코딩
- 과정: 원래의 글로벌 사용자 임베딩과 마스킹된 사용자 임베딩을 각각 인코딩하여 저차원 표현을 생성합니다.
단계 5: 사용자 인식 대비 손실 계산
- 과정: 두 임베딩의 저차원 표현을 사용하여 사용자 인식 대비 손실을 계산합니다.
- 목적: 동일한 사용자의 임베딩 간 유사도를 높이고, 다른 사용자의 임베딩 간 유사도를 낮춥니다.
단계 6: 개별화된 온도 최적화
- 과정: 사용자 인식 대비 손실의 그래디언트를 사용하여 각 사용자의 개별화된 온도 매개변수를 최적화합니다.
단계 7: 재구성 손실을 사용한 오토인코더 최적화
- 목적: 재구성 임베딩과 생성된 임베딩의 구조를 제어하기 위해 재구성 손실을 사용하여 오토인코더의 파라미터를 최적화합니다.
단계 8: 도메인 인식 LoRA 미세 조정
- 목적: 각 도메인 내에서 성능을 더욱 향상시키기 위해 도메인 인식 LoRA(Low-Rank Adaptation) 미세 조정 방법을 사용합니다.
- 과정: 사전 학습된 글로벌 사용자 임베딩의 가중치를 고정하고, 저차원 행렬 A와 B를 학습하여 모델을 미세 조정합니다.
요약
- BPRMF 모델로 글로벌 사용자 및 아이템 임베딩 사전 학습.
- 사용자 인식 대비 학습을 사용하여 상호작용 빈도의 부정적 영향 제거.
- 사전 학습된 글로벌 사용자 임베딩을 무작위로 마스킹.
- 원래와 마스킹된 사용자 임베딩을 각각 인코딩.
- 사용자 인식 대비 손실 계산.
- 개별화된 온도 매개변수를 최적화.
- 재구성 손실을 사용하여 오토인코더 최적화.
- 도메인 인식 LoRA 미세 조정 방법을 사용하여 각 도메인 내에서 성능 향상.
이론적 보장

주요 차이점 및 기여
- 개별화된 온도 매개변수: 글로벌 온도 대신 개별화된 온도를 사용하여 각 사용자의 임베딩이 동일하게 생성되지 않는 문제를 해결합니다.
- 결정론적 음성 샘플: 배치 샘플에서 독립적인 음성 샘플 대신 사용자 임베딩에 따라 결정되는 음성 샘플을 사용합니다.
이 알고리즘은 다양한 도메인의 데이터를 효과적으로 통합하고, 사용자 간의 불균형한 상호작용 빈도 문제를 해결하며, 최종적으로 보다 정확한 추천 시스템을 구현하는 데 기여합니다.
논문 후반부
1. 연구 질문 (RQs)
이 연구에서는 다음과 같은 중요한 질문을 탐구합니다:
- RQ1: 제안된 UCLR 방법이 다른 기준 방법들과 비교했을 때 성능이 어떠한가?
- RQ2: UCLR 방법이 "모든 임베딩이 동일하게 생성되지 않는다"는 문제를 해결하는가?
- RQ3: 제안된 서브 모듈들이 성능 향상에 어떻게 기여하는가?
2. 데이터셋
- 사용된 데이터셋: Amazon과 Douban 데이터셋
- 도메인: 각 데이터셋에서 세 개의 도메인(Books, Movies, Electronics; Books, Movies, Music)을 사용
- 데이터 불균형 문제: 실세계 데이터셋에서 사용자의 상호작용 빈도 불균형이 존재
3. 실험 설정
- 평가 방법: leave-one-out 방식 사용, 각 사용자에 대해 1개의 양성 항목과 99개의 음성 항목을 샘플링
- 성능 지표: Mean Reciprocal Rank (MRR), Hit Ratio (HR), Normalized Discounted Cumulative Gain (NDCG)
- 비교 방법: BPRMF, NeuMF, LightGCN (단일 도메인 추천), HeroGraph, GA-MTCDR, CAT-ART (크로스 도메인 추천)
4. 성능 비교 (RQ1)
- 결과 요약: UCLR 방법은 대부분의 도메인에서 우수한 성능을 보였으며, 특히 사용자의 상호작용이 적은 경우에도 효과적이었습니다.
- 특징: 각 도메인별로 성능 차이가 존재하지만, 전반적으로 크로스 도메인 추천 접근 방식이 단일 도메인 추천보다 우수함을 확인.
5. 세부 분석 (RQ2)
- 데이터 불균형 해결: UCLR 방법은 상호작용이 적은 사용자를 위한 추천 성능을 크게 향상시켰습니다.
- 개별화된 온도 매개변수 사용: 사용자 인식 대비 학습을 통해 각 사용자에 맞춘 온도 매개변수를 자동으로 최적화, 불균형 문제 해결
6. 세부 모듈 분석 (RQ3)
- 모듈 분석: 각 서브 모듈의 기여도를 평가
- PGE: 사전 학습된 글로벌 임베딩 모델
- PGE + AE: 단일 스트림 오토인코더 추가
- PGE + CL-AE: 대비 학습 기반 듀얼 스트림 오토인코더 추가
- PGE + UCL: 사용자 인식 대비 학습 추가
- UCLR: 도메인 인식 LoRA 미세 조정 추가
- 결론: 각 모듈이 성능 향상에 기여하며, 특히 도메인 인식 LoRA가 중요한 역할을 함.
7. 결론
- 연구 요약: UCLR 방법은 사용자 선호도를 포착하는 사전 학습된 글로벌 임베딩, 사용자 인식 대비 학습, 도메인 인식 LoRA 미세 조정을 결합하여 크로스 도메인 추천의 성능을 크게 향상시킵니다.
- 기여: 다양한 도메인의 데이터를 효과적으로 통합하고, 사용자 간의 불균형한 상호작용 빈도 문제를 해결하여 정확한 추천을 제공.
제목: 효과적인 크로스 도메인 추천을 위한 UCLR 방법
연구 질문
이 연구에서는 UCLR 방법의 성능, 불균형 문제 해결 여부, 서브 모듈들의 기여도를 탐구합니다.
데이터셋
Amazon과 Douban 데이터셋에서 Books, Movies, Electronics 도메인을 사용하여 실험을 진행했습니다.
실험 설정
평가 방법으로 leave-one-out 방식을 사용했고, MRR, HR, NDCG 지표를 통해 성능을 평가했습니다. 비교 방법으로 BPRMF, NeuMF, LightGCN, HeroGraph, GA-MTCDR, CAT-ART를 사용했습니다.
성능 비교
UCLR 방법은 대부분의 도메인에서 우수한 성능을 보였으며, 특히 사용자의 상호작용이 적은 경우에도 효과적이었습니다.
세부 분석
UCLR 방법은 상호작용이 적은 사용자를 위한 추천 성능을 크게 향상시켰습니다. 사용자 인식 대비 학습을 통해 각 사용자에 맞춘 온도 매개변수를 자동으로 최적화하여 불균형 문제를 해결했습니다.
세부 모듈 분석
각 서브 모듈이 성능 향상에 기여하며, 특히 도메인 인식 LoRA가 중요한 역할을 했습니다.
결론
UCLR 방법은 다양한 도메인의 데이터를 효과적으로 통합하고, 사용자 간의 불균형한 상호작용 빈도 문제를 해결하여 정확한 추천을 제공합니다. UCLR은 크로스 도메인 추천 분야에 중요한 기여를 했습니다.