10강 - Language Modeling with GPT
Masked LM - encoder에서 진행되는 과정으로 마스킹된 단어를 맞춘다.
BERT가 Transformer의 Encoder를 사용하여 양방향 Self attention을 진행하여 마스킹된 단어 예측을 진행한다.
LM - Decoder에서 진행되는 과정으로 다음 단어를 예측한다.
input으로 이전 단어를 넣고 가장 높은 확률을 가지는 단어를 가지고 오는 것을 반복한다. == auto aggressive
GPT가 Transformer를 사용해 단방향 Self attention을 진행하고, 이전 컨택스트만 가지고 예측한다.
n-gram : n개 단어까지만 확인해서 그 확률이 어떻게 되는지 보고, 높은 단어를 가지고 온다 - 통계적 방법
앞의 문맥을 버리고, 임베딩을 고려하지 않아 단어 간 연관성을 확인하지 않는다.
RNN : 이전의 모든 input을 고려할 수 있고, 파라미터를 공유한다. 이전 정보를 가져올 수 있고, 패딩 하면 input이 다 같다.
Perplexity(복잡도)는 낮아야 성능이 좋다 == 모델이 예측한 단어의 확률이 높다.
네, 맞습니다. Perplexity는 언어 모델의 예측 능력을 평가하는 지표로, 낮을수록 모델의 성능이 좋음을 의미합니다. Perplexity가 낮다는 것은 모델이 테스트 데이터에 있는 단어들을 잘 예측한다는 것을 의미합니다. 즉, 모델이 예측한 확률이 높을수록, Perplexity가 낮아집니다. 이를 좀 더 자세히 설명하겠습니다.
Perplexity와 모델의 성능
- Perplexity의 의미:
- Perplexity는 테스트 데이터에 대해 모델이 얼마나 "놀라는지"를 나타내는 지표입니다.
- Perplexity는 주어진 단어 시퀀스에 대해 모델이 얼마나 잘 예측하는지를 측정합니다.
- Perplexity가 낮을수록 모델이 해당 시퀀스의 단어를 잘 예측하고 있다는 의미입니다.
- 확률과 Perplexity:
- 모델이 단어 (w_i)가 주어진 문맥 ((w_1, w_2, \ldots, w_{i-1}))에서 나올 확률 (P(w_i | w_1, w_2, \ldots, w_{i-1}))을 높게 예측할수록 Perplexity는 낮아집니다.
- Perplexity는 확률의 기하 평균의 역수이므로, 예측 확률이 높을수록 기하 평균이 커지고, 그 역수인 Perplexity는 작아집니다.
Perplexity 계산의 예
예를 들어, 테스트 문장이 "the cat sat on the mat"이라고 가정해 봅시다. 모델이 다음과 같은 확률을 예측한다고 가정하겠습니다:
- ( P(\text{"the"} | \text{}) = 0.2 )
- ( P(\text{"cat"} | \text{"the"}) = 0.1 )
- ( P(\text{"sat"} | \text{"the cat"}) = 0.4 )
- ( P(\text{"on"} | \text{"the cat sat"}) = 0.3 )
- ( P(\text{"the"} | \text{"the cat sat on"}) = 0.25 )
- ( P(\text{"mat"} | \text{"the cat sat on the"}) = 0.35 )
Perplexity를 계산하기 위해 다음 단계를 따릅니다:
- 로그 확률 계산:
[\log P(\text{"the"}) + \log P(\text{"cat"}) + \log P(\text{"sat"}) + \log P(\text{"on"}) + \log P(\text{"the"}) + \log P(\text{"mat"})] - 로그 확률의 평균 계산:
[\frac{1}{6} (\log 0.2 + \log 0.1 + \log 0.4 + \log 0.3 + \log 0.25 + \log 0.35)] - Perplexity 계산:
[\text{Perplexity} = 2^{-\frac{1}{6} (\log 0.2 + \log 0.1 + \log 0.4 + \log 0.3 + \log 0.25 + \log 0.35)}]
Perplexity가 낮아지려면 각 단어의 예측 확률 (P(w_i | w_1, w_2, \ldots, w_{i-1}))이 높아져야 합니다. 이는 모델이 테스트 데이터에 대해 잘 예측하고 있다는 것을 의미합니다.
결론
- Perplexity는 언어 모델의 성능을 평가하는 중요한 지표로, 값이 낮을수록 모델이 주어진 데이터를 잘 예측하고 있음을 나타냅니다.
- 모델이 각 단어의 예측 확률을 높게 계산할수록 Perplexity는 낮아집니다.
- 따라서, 좋은 언어 모델은 테스트 데이터에 있는 단어들의 확률을 높게 예측할 수 있어야 합니다.
이 전의 언어 모델들은 각각 다른 task에 특화되었지만 이젠 전부 잘한다.
GPT는 대량의 코퍼스를 통해 pre-training 하였고, fine-tune(분류, 유츄, Q&A)를 진행할 수 있다.
11강 - Named Entity Recognition (NER) + BERT
NER - 이 단어가 어디에 속하는지 맞춘다. 이름, 시설, 나라, 회사, 기관 등 다양한 tag 중에서 맞춘다.
BIO 태그로 구분한다. B - NER 시작, I - NER 도중, O - NER 아님
NER 사전이 완벽한 것이 아니고, 문맥에 의해 결정되기도 해서 어렵다.
규칙 기반 NER
높은 정밀도(Precision) rule을 통해 애매하지 않은 mentions를 라벨(라벨링 된 entitiy 수가 적을 수 있지만 높은 정확도) -> 감지된 entities의 label 전파(주변 단어가 이어질 경우 전파) -> list를 활용하여 더 식별(특정 목록을 통해 더 식별) -> 순차적 라벨링(텍스트 전체를 고려하여 엔티티를 라벨링)
평가지표로는 recall과 Precision을 모두 고려한 F1 score가 평가 지표로 사용된다.
ELMo는 일반적인 RNN 모델로 pretraning을 처음 적용하였고, 양방향 LSRM이다.
Pretrain이 생기기 전에는 SOTA가 모두 각각 모델이었으나 Pretrain 이후 fine tuning에 따라 SOTA가 변경
BERT 양방향 모델로 Pretraning 진행 = MLM + NSP == semi-supervised
MLM : input의 일정 부분을 [MASK] 토큰으로 바꾸거나, 랜덤 단어로 바꿔서 맞추기를 진행한다.
NSP : Classification과 같은 느낌으로 두 문장이 이어지나를 판단. CLS 토큰에서 classification이 진행된다.
토큰화 방법엔 Word Piece model, Byte-pair Encoding 등이 있다.
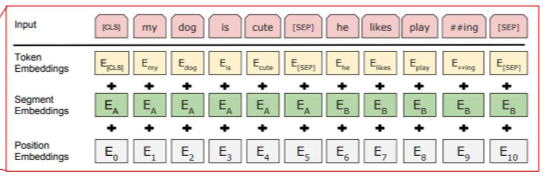
포지션 임베딩, 분류 작업에 사용되든 [CLS] 토큰, 문장 구분 임베딩[sep]이 있다.
즉 토큰 + segment + position을 한다.
BERT 또한 다양한 파인 튜닝을 통해 여러 분야에 특화
근데 왜 BERT에서 SEP 토큰이 있는데 Segment Embedding을 또 진행할까?
좋은 질문입니다. BERT에서 SEP 토큰과 segment embeddings는 서로 보완적인 역할을 합니다. 이 두 가지 요소는 함께 사용되어 문장 간의 관계를 명확히 구분하고 모델이 문장 구조를 이해할 수 있도록 돕습니다.
BERT의 입력 구성 요소
- [CLS] 토큰:
- 입력 시퀀스의 맨 앞에 추가되는 특별한 토큰입니다.
- 분류 작업의 경우 이 토큰의 출력이 최종 예측에 사용됩니다.
- [SEP] 토큰:
- 문장 간의 경계를 나타내는 특별한 토큰입니다.
- 두 문장 간의 구분을 명확히 하기 위해 사용됩니다.
- 예를 들어, 입력이 두 문장으로 구성되어 있을 때 첫 번째 문장이 끝난 후, 두 번째 문장이 시작되기 전에 [SEP] 토큰이 삽입됩니다.
- segment embeddings:
- 문장 구분을 위한 또 다른 방법입니다.
- segment embeddings는 문장의 위치 정보를 추가로 제공합니다.
- 입력 시퀀스의 각 토큰에 대해 문장이 속한 그룹을 나타내는 임베딩을 추가합니다. 예를 들어:
- 첫 번째 문장의 토큰들은 segment A(일반적으로 0으로 표현)로 표시됩니다.
- 두 번째 문장의 토큰들은 segment B(일반적으로 1으로 표현)로 표시됩니다.
SEP 토큰과 segment embeddings의 역할
[SEP] 토큰:
- 문장 간의 경계를 명확히 구분합니다.
- 모델이 두 문장의 경계를 쉽게 인식할 수 있도록 돕습니다.
segment embeddings:
- 문장 간의 관계를 명확히 하기 위해 각 문장에 다른 임베딩을 제공합니다.
- 모델이 입력 시퀀스 내에서 어떤 토큰이 어떤 문장에 속하는지 추가적인 정보를 제공합니다.
- 예를 들어, 두 문장이 "문장 A"와 "문장 B"로 구분될 때, 각 토큰에 대한 segment embedding을 통해 모델은 토큰이 "문장 A"에 속하는지 "문장 B"에 속하는지를 알 수 있습니다.
왜 둘 다 사용하는가?
SEP 토큰과 segment embeddings는 문장 간의 경계를 명확히 하고 문장의 위치 정보를 제공함으로써 서로 보완적인 역할을 합니다.
- 경계 구분: [SEP] 토큰은 명확한 경계를 제공하여 문장이 어디에서 끝나고 시작되는지를 명확히 합니다.
- 위치 정보: segment embeddings는 각 토큰이 어느 문장에 속하는지를 추가적인 벡터 정보를 통해 제공합니다. 이는 문장 간의 관계를 더 명확히 구분하고, 모델이 문맥을 더 잘 이해할 수 있게 합니다.
이 두 가지 요소는 함께 사용되어 모델이 문장 간의 관계를 명확히 이해하고, 더 나은 성능을 발휘할 수 있도록 돕습니다. SEP 토큰만으로는 문장 경계는 구분할 수 있지만, 각 토큰이 속한 문장을 명확히 구분하는 데 있어 segment embeddings가 추가적인 도움을 주는 것입니다.
요약
- SEP 토큰: 문장 경계를 구분합니다.
- segment embeddings: 각 토큰이 속한 문장을 구분합니다.
- 둘 다 사용하여 문장 간의 관계를 명확히 하고 모델이 문맥을 더 잘 이해할 수 있게 합니다.
12강 - Question Answering + BERT
QA 모델에는 의도파악, NER, 문서 검색, 정답 생성 등 다양한 기능이 필요하고, 의도 파악이 중요
QA SOTA 모델은 대부분 Pre-Trained BERT다
지식 그래프를 통해 knowedge based QA가 가능하다.
Visual QA에서는 사진의 물체를 탐지 후 태그 하여 알려주는 방식으로 Youtube에서 사용된다.
질문을 인코더에 넣고, 지문을 디코더에 넣어 가장 높은 확률인 위치가 정답이다.
이 과정으로 컴퓨터가 인간의 언어를 얼마나 잘 이해하고 있는지 평가한다.
SQuAD는 벤치마크 테스트 셋으로 Answer가 여러 단어로 되어있다. - span
평가 지표로는 정확히 매치되었나 확인과 f1 score가 있다.
Pre-trained BERT로 파인튜닝하면 QA에 대해 시작과 마지막 위치를 뱉어준다.
Tokenizing방식엔 문자(Character) 단위, 단어(Word) 단위, 의미(Subword) 단위가 있다.
그중 BPE는 Subword 방식으로, 캐릭터 단위로 쪼갠 뒤 가장 많이 붙어 있는 단어들을 계속 합치는 방식으로 진행된다.
WordPiece도 Subword 방식이지만 빈도와 가능도?를 생각해서 병합한다고 하네요...
BPE(Byte Pair Encoding)와 WordPiece는 둘 다 서브워드 분할(subword tokenization) 기법으로, 언어 모델에서 단어를 더 작은 단위로 분할하여 처리하는 방법입니다. 이 두 기법은 특히 희귀 단어의 문제를 해결하고, 모델의 어휘집 크기를 줄이며, 학습 효율성을 높이기 위해 사용됩니다. 하지만 이 두 기법은 약간 다른 방식으로 동작합니다.
Byte Pair Encoding (BPE)
BPE의 동작 방식:
- 초기화:
- 모든 단어를 문자(character) 단위로 분할합니다. 예를 들어, "hello"는 ["h", "e", "l", "l", "o"]로 분할됩니다.
- 빈도 계산:
- 텍스트 코퍼스에서 가장 자주 등장하는 문자 쌍을 찾습니다. 예를 들어, "l"과 "l"이 가장 자주 함께 등장할 수 있습니다.
- 쌍 병합:
- 가장 자주 등장하는 문자 쌍을 하나의 새로운 서브워드로 병합합니다. 예를 들어, "l"과 "l"을 병합하여 "ll"로 만듭니다.
- 반복:
- 병합된 서브워드가 포함된 새로운 단어 목록을 생성하고, 이 과정을 반복하여 자주 등장하는 서브워드 쌍을 계속 병합합니다.
- 예를 들어, 다음 단계에서는 "ll"과 "o"가 병합되어 "llo"가 될 수 있습니다.
- 어휘집 생성:
- 정해진 횟수만큼 병합을 반복하여 최종 서브워드 어휘집을 생성합니다. 이 어휘집에는 자주 등장하는 서브워드들이 포함됩니다.
장점:
- BPE는 희귀 단어를 더 작은 서브워드 단위로 분할하여 처리할 수 있습니다.
- 어휘집 크기를 효과적으로 줄일 수 있습니다.
WordPiece
WordPiece의 동작 방식:
- 초기화:
- 모든 단어를 문자 단위로 분할합니다. BPE와 동일하게, 예를 들어 "hello"는 ["h", "e", "l", "l", "o"]로 분할됩니다.
- 빈도 계산:
- 텍스트 코퍼스에서 가장 자주 등장하는 서브워드를 찾습니다. 서브워드는 문자뿐만 아니라 이미 병합된 문자 쌍도 포함될 수 있습니다.
- 최대 가능도:
- BPE와 달리, WordPiece는 서브워드 병합을 통해 생성된 새로운 서브워드의 빈도와 가능도를 계산합니다.
- 각 병합 단계에서, 가능도를 최대로 만드는 서브워드 쌍을 병합합니다.
- 반복:
- 가장 가능도가 높은 서브워드 쌍을 병합하고, 이 과정을 반복합니다.
- 어휘집 생성:
- 정해진 횟수만큼 병합을 반복하여 최종 서브워드 어휘집을 생성합니다. 이 어휘집은 자주 등장하는 서브워드와 가능도를 고려한 병합 결과로 구성됩니다.
장점:
- WordPiece는 가능도를 고려하여 병합을 진행하므로, 더 최적화된 서브워드 어휘집을 생성할 수 있습니다.
- 특히 BERT와 같은 모델에서 잘 동작하며, 희귀 단어와의 대응이 효과적입니다.
요약
- BPE:
- 문자 쌍의 빈도에 기반하여 병합합니다.
- 가장 자주 등장하는 문자 쌍을 반복적으로 병합하여 서브워드를 생성합니다.
- 비교적 단순한 방법으로 서브워드 어휘집을 만듭니다.
- WordPiece:
- 서브워드 쌍의 가능도를 고려하여 병합합니다.
- 가능도를 최대화하는 서브워드 쌍을 선택하여 병합합니다.
- BERT와 같은 모델에서 사용되며, 더 최적화된 서브워드 어휘집을 생성합니다.
두 기법 모두 서브워드 단위로 단어를 분할하여 처리하는 공통점을 가지지만, 병합 과정에서의 기준과 방법에 차이가 있습니다.
WordPiece 방식은 서브워드 단위로 병합을 진행하는 과정에서 단순한 빈도 기반이 아니라, 가능도(likelihood)를 고려하여 병합을 진행합니다. 하지만 이 가능도는 의미 단위와는 직접적으로 연관이 있는 것이 아니라, 주어진 코퍼스에서 얼마나 자주 등장하는지를 기반으로 최적의 서브워드를 선택하는 방식입니다. 따라서 의미 단위로 병합된다고 생각하기보다는, 코퍼스에서의 등장 빈도와 확률을 최대화하는 방식으로 병합된다고 보는 것이 더 정확합니다.
WordPiece의 병합 과정
- 초기화:
- 모든 단어를 문자 단위로 분할합니다.
- 빈도 계산:
- 텍스트 코퍼스에서 각 문자와 문자 쌍의 빈도를 계산합니다.
- 최대 가능도:
- 각 병합 단계에서, 서브워드 쌍의 가능도를 계산합니다. 가능도는 해당 서브워드 쌍이 코퍼스에서 얼마나 자주 등장하는지를 반영합니다.
- BPE와 달리, WordPiece는 서브워드 병합을 통해 생성된 새로운 서브워드의 빈도와 함께 가능도를 고려합니다.
- 가능도를 최대화하는 서브워드 쌍을 선택하여 병합합니다.
- 반복:
- 이 과정을 반복하여 서브워드 어휘집을 생성합니다. 각 단계에서 가장 가능도가 높은 서브워드 쌍을 병합합니다.
예시
예를 들어, "playing"이라는 단어를 서브워드로 분할한다고 가정해 봅시다.
- 초기 분할: ["p", "l", "a", "y", "i", "n", "g"]
- 첫 번째 병합: ["pl", "a", "y", "i", "n", "g"]
- 두 번째 병합: ["pl", "ay", "i", "n", "g"]
- 세 번째 병합: ["pl", "ay", "ing"]
이 과정에서 "playing"이라는 단어는 서브워드 "pl", "ay", "ing"로 병합될 수 있습니다. 이 병합은 단순히 문자 쌍의 빈도뿐만 아니라, 해당 서브워드가 전체 코퍼스에서 자주 나타나는지를 고려한 결과입니다.
요약
- WordPiece 방식은 서브워드 단위로 병합을 진행하며, 각 단계에서 서브워드 쌍의 가능도를 최대화하는 방식으로 병합됩니다.
- 이 과정은 의미 단위와 직접적인 연관이 있다기보다는, 주어진 코퍼스에서 서브워드 쌍이 얼마나 자주 등장하는지를 반영합니다.
- 결과적으로, WordPiece는 BPE보다 더 최적화된 서브워드 어휘집을 생성할 수 있습니다.
따라서 WordPiece 방식은 의미 단위로 병합된다고 생각하기보다는, 가능도 기반의 최적화된 서브워드 병합 방식이라고 이해하는 것이 더 정확합니다.
확실히 BPE와 WordPiece의 차이점을 명확히 구분하여 설명드리겠습니다. 이 두 기법은 서브워드 단위로 단어를 분할하여 언어 모델을 효율적으로 학습시키기 위한 방법입니다. 각각의 기법이 어떻게 작동하는지, 그리고 어떤 차이점이 있는지 자세히 설명하겠습니다.
BPE (Byte Pair Encoding)
동작 방식:
- 초기화:
- 모든 단어를 문자(character) 단위로 분할합니다.
- 예: "playing" → ["p", "l", "a", "y", "i", "n", "g"]
- 빈도 계산:
- 텍스트 코퍼스에서 가장 자주 등장하는 문자 쌍을 찾습니다.
- 예: "l"과 "a"가 가장 자주 함께 등장할 수 있습니다.
- 쌍 병합:
- 가장 자주 등장하는 문자 쌍을 병합하여 새로운 서브워드를 만듭니다.
- 예: "pl", "ay", "ing" 등
- 반복:
- 병합된 서브워드가 포함된 새로운 단어 목록을 생성하고, 이 과정을 반복하여 자주 등장하는 서브워드 쌍을 계속 병합합니다.
- 예: "playing" → ["pl", "ay", "ing"]
- 어휘집 생성:
- 정해진 횟수만큼 병합을 반복하여 최종 서브워드 어휘집을 생성합니다. 이 어휘집에는 자주 등장하는 서브워드들이 포함됩니다.
특징:
- 빈도 기반 병합: 가장 자주 등장하는 문자 쌍을 반복적으로 병합.
- 간단한 알고리즘: 빈도 계산과 병합을 반복하여 서브워드 어휘집 생성.
WordPiece
동작 방식:
- 초기화:
- 모든 단어를 문자 단위로 분할합니다.
- 예: "playing" → ["p", "l", "a", "y", "i", "n", "g"]
- 빈도 및 가능도 계산:
- 텍스트 코퍼스에서 각 서브워드의 빈도를 계산합니다.
- 서브워드 쌍의 가능도(likelihood)를 계산하여, 각 병합 단계에서 가능도를 최대화하는 서브워드 쌍을 선택합니다.
- 최대 가능도 병합:
- 가능도를 최대화하는 서브워드 쌍을 병합합니다.
- 예: "pl", "ay", "ing" 등
- 반복:
- 가능도가 높은 서브워드 쌍을 반복적으로 병합하여 최적화된 서브워드 어휘집을 생성합니다.
- 예: "playing" → ["pl", "ay", "ing"]
- 어휘집 생성:
- 정해진 횟수만큼 병합을 반복하여 최종 서브워드 어휘집을 생성합니다. 이 어휘집은 자주 등장하는 서브워드와 가능도를 고려한 병합 결과로 구성됩니다.
특징:
- 가능도 기반 병합: 빈도뿐만 아니라 가능도를 고려하여 서브워드 쌍을 병합.
- 최적화된 알고리즘: 서브워드 쌍의 가능도를 계산하여 더 최적화된 서브워드 어휘집 생성.
요약
BPE (Byte Pair Encoding):
- 병합 기준: 가장 자주 등장하는 문자 쌍을 반복적으로 병합.
- 장점: 구현이 간단하고, 빈도 기반으로 서브워드 어휘집을 쉽게 생성할 수 있음.
- 사용 예: 대부분의 경우 빈도 기반 서브워드 분할을 적용할 때 사용.
WordPiece:
- 병합 기준: 빈도와 가능도를 고려하여 서브워드 쌍을 병합.
- 장점: 가능도를 최대화하여 더 최적화된 서브워드 어휘집을 생성할 수 있음.
- 사용 예: BERT와 같은 모델에서 사용되며, 특히 희귀 단어 처리에서 효과적.
결론
BPE와 WordPiece 모두 서브워드 단위로 단어를 분할하는 기법이지만, 병합 기준과 알고리즘의 최적화 방식에서 차이가 있습니다. BPE는 단순히 빈도 기반으로 병합을 진행하는 반면, WordPiece는 빈도와 함께 가능도를 고려하여 더 최적화된 서브워드 어휘집을 생성합니다.
이 페이지는 다양한 토큰화 기법들인 Byte-level BPE, SentencePiece (unigram), 그리고 WordPiece의 특징들을 비교한 표입니다. 각 기법의 세부 사항을 설명하고 있습니다.
표의 구성 요소
- Lossless?:
- Byte-level BPE:
- Partial (non-GPT): 부분적으로 무손실
- Full (GPT): 완전 무손실
- SentencePiece (unigram):
- Partial (e.g., English): 부분적으로 무손실
- Full (e.g., Chinese): 완전 무손실
- WordPiece:
- N: 무손실이 아님
- Byte-level BPE:
- Pre-tokenization?:
- Byte-level BPE:
- Y (non-GPT): 사전 토큰화 필요
- N (GPT): 사전 토큰화 불필요
- SentencePiece (unigram):
- Y (e.g., English): 사전 토큰화 필요
- N (e.g., Chinese): 사전 토큰화 불필요
- WordPiece:
- Y: 사전 토큰화 필요
- Byte-level BPE:
- Base Vocab:
- Byte-level BPE: 256 (기본적으로 256개의 바이트 단위)
- SentencePiece (unigram): Large, all characters and most frequent substrings (모든 문자와 가장 빈번한 서브스트링)
- WordPiece: Unicode characters in the training data (훈련 데이터의 유니코드 문자)
- Rules:
- Byte-level BPE: "Merge" by frequency (빈도에 따라 병합)
- SentencePiece (unigram): "Trim" by minimizing likelihood loss (가능도 손실 최소화를 위한 잘라내기)
- WordPiece: "Merge" by maximizing likelihood (가능도 최대화를 위한 병합)
- Used by:
- Byte-level BPE: GPT, Roberta
- SentencePiece (unigram): T5, XLNet, Reformer
- WordPiece: BERT, DistilBERT
- Proposed in:
- Byte-level BPE: (Sennrich et al., 2016) - Initially proposed to translate rare words through subword units (희귀 단어를 서브워드 단위로 번역하기 위해 제안됨)
- SentencePiece (unigram): (Kudo & Richardson, 2018) - Proposed to sample different tokenizations for the same string, which are used as "subword regularizers" for the model (같은 문자열에 대해 다양한 토큰화를 샘플링하여 모델의 "서브워드 정규화"로 사용)
- WordPiece: (Schuster & Nakajima, 2012) - First subword tokenization model (최초의 서브워드 토큰화 모델)
각 토큰화 기법의 주요 특징
- Byte-level BPE:
- 빈도 기반 병합: 가장 자주 등장하는 문자 쌍을 반복적으로 병합.
- 사전 토큰화 필요 여부: GPT를 제외한 경우에 사전 토큰화가 필요.
- 사용 예시: GPT, Roberta.
- 제안 배경: 희귀 단어를 서브워드 단위로 번역하기 위해 제안됨.
- SentencePiece (unigram):
- 가능도 손실 최소화: 서브워드 빈도와 가능도를 고려하여 가장 가능도 손실이 적은 서브워드를 선택하여 병합.
- 사전 토큰화 필요 여부: 언어에 따라 다름 (영어의 경우 필요, 중국어의 경우 불필요).
- 사용 예시: T5, XLNet, Reformer.
- 제안 배경: 같은 문자열에 대해 다양한 토큰화를 샘플링하여 서브워드 정규화로 사용.
- WordPiece:
- 가능도 최대화 병합: 빈도와 함께 가능도를 고려하여 서브워드 쌍을 병합.
- 사전 토큰화 필요: 사전 토큰화가 필요.
- 사용 예시: BERT, DistilBERT.
- 제안 배경: 최초의 서브워드 토큰화 모델로 제안됨.
결론
- Byte-level BPE는 빈도 기반 병합을 통해 서브워드 단위를 생성하며, GPT와 Roberta와 같은 모델에서 사용됩니다.
- SentencePiece (unigram)는 가능도 손실 최소화를 통해 서브워드를 선택하며, T5, XLNet, Reformer와 같은 모델에서 사용됩니다.
- WordPiece는 가능도 최대화를 통해 서브워드 쌍을 병합하며, BERT와 DistilBERT와 같은 모델에서 사용됩니다.
이 표는 각 토큰화 기법의 특징과 차이점을 명확하게 비교하여 보여줍니다.
13강 - Self Supervised Learning 1
fine-tuning시 data의 양과, 데이터의 유사성을 보고 model의 weight를 업데이트할지 고를 수 있다.
데이터 많고, 유사성 크다 - 레이어를 70% 남기고 업데이트한다.
데이터 많고, 유사성 작다 - 전체 업데이트
데이터 적고, 유사도 크다 - pre-trained 부분은 얼리고, 새로 만든 layer만 업데이트
데이터 적고, 유사도 작다 - 최대한 많은 부분을 업데이트한다.
Self supervised learning은 unsupervised learning으로 Pretext task를 가지고 진행하고, fine tuning은 downstream task를 가지고 진행한다.
RoBERTa는 Dynamic Masking으로 마스킹 위치가 변하게 만들고, NSP의 Loss를 없애 downstream task를 향상
배치사이즈와 데이터 양도 증가했다.
ALBERT는 파라미터 수를 줄이고 효율성을 향상했다.
Factorized Embedding Parameterization을 통해 임베딩을 2개로 나눠 메모리와 계산량을 줄이고, 일반화 성능을 늘렸다.
또한 stacked transformer를 통한 파라미터 공유로 효율성을 늘렸고, 문장의 순서 맞추기도 진행하였다.(SOP)
근데 왜 RoBERTa에서 NSP Loss를 없앴는데 downstream task의 효율이 증가하지?
네, 질문에서 지적한 부분이 맞습니다. NSP(Next Sentence Prediction)는 BERT의 사전 학습(pre-training) 단계에서 사용하는 작업입니다. RoBERTa는 BERT와 유사한 구조를 가지고 있지만, 몇 가지 중요한 차이점이 있습니다. 그중 하나가 NSP를 사전 학습 단계에서 제거한 것입니다. 이 결정은 모델의 사전 학습 단계와 관련이 있으며, 결과적으로 다운스트림 작업의 성능에 영향을 미칠 수 있습니다.
BERT와 RoBERTa의 차이점
- BERT의 사전 학습:
- BERT는 두 가지 주요 사전 학습 목표를 사용합니다: 마스킹 언어 모델(Masked Language Model, MLM)과 다음 문장 예측(Next Sentence Prediction, NSP).
- MLM: 입력 문장의 일부 토큰을 [MASK] 토큰으로 대체하고, 모델이 이 마스크된 토큰을 예측하도록 합니다.
- NSP: 두 개의 문장이 주어졌을 때, 두 번째 문장이 첫 번째 문장의 다음 문장인지 아닌지를 예측합니다.
- RoBERTa의 사전 학습:
- RoBERTa는 BERT와 유사한 MLM 목표를 사용하지만, NSP 목표를 제거했습니다.
- RoBERTa는 대규모 데이터셋에서 더 긴 시간 동안, 더 큰 배치 크기를 사용하여 사전 학습을 진행합니다.
- 여러 입력 문장의 순서를 무작위로 섞어(Shuffling) 다양한 문맥을 제공하여 모델이 더 일반화된 문맥을 학습할 수 있도록 합니다.
NSP 제거의 영향
- 사전 학습: NSP를 제거함으로써, RoBERTa는 문장 간의 관계를 학습하는 대신에 단일 문장의 문맥을 더 잘 학습하게 됩니다.
- 다운스트림 작업: NSP가 제거되었지만, RoBERTa는 더 많은 데이터와 더 긴 사전 학습 시간 덕분에 문장 간의 관계를 잘 처리할 수 있습니다. NSP 없이도 모델이 강력한 문맥 이해력을 가질 수 있게 됩니다.
- 모델 성능: RoBERTa는 다양한 NLP 다운스트림 작업에서 BERT보다 더 높은 성능을 보여줍니다. 이는 사전 학습 데이터와 시간의 증가, 그리고 NSP 제거로 인한 단순화 덕분입니다.
결론
질문에서 제기한 내용은 맞습니다. NSP는 사전 학습 단계에서 사용되며, 직접적으로 다운스트림 작업과 관련이 없어 보일 수 있습니다. 하지만, NSP를 제거하고 대신 더 많은 데이터를 사용하여 모델을 학습한 RoBERTa는 결과적으로 다운스트림 작업에서도 더 나은 성능을 발휘합니다.
따라서, RoBERTa의 개선된 성능은 NSP를 제거한 것뿐만 아니라, 전체적인 사전 학습 전략의 변화(더 많은 데이터, 더 긴 학습 시간, 더 큰 배치 크기) 덕분입니다. NSP의 제거는 모델을 단순화하고, 더 많은 데이터를 통해 학습할 수 있도록 하여, 결과적으로 다운스트림 작업 성능에 긍정적인 영향을 미쳤습니다.
14강 - Self supervised Learning 2
SpanBERT에선 NSP가 빠졌고, 마스킹을 span레벨로 진행하여 문맥 파악을 더 잘한다. NSP도 제거되었다.
Longformer : BERT의 변형으로 긴 doc를 처리한다.
긴 doc에서 전체적으로 self-attention 하면 연산량이 늘어나므로 특정 패턴을 주고 진행한다.
1. Sliding window - 주변 단여 n개
2. Dilated sliding window - 주변 단어 n개를 한 개씩 뛰면서 attention
3. Global + Sliding Window - 일정 단어만 전체 적으러 attention
NLU - 자연어 이해 : GLUE, SQuAD
NLG - 자연어 생성 : Text Summarization, Machine Translation, ChatBot
BART는 Transformer의 Encoder와 Decoder를 모두 사용하며 다양한 방식으로 self supervised learning을 진행하여 원본 문장을 생성하게 만든다. (중간중간 비우기, 마스킹 토큰 사용하기, 섞기, span 맞추기, 문장 순서 바꾸기 등등,,)
ELECTRA는 GAN의 판별자와 같은 역할이며 원본인지 판단하여 생성자가 원본과 같이 생성하게 만든다.
VisualBERT는 vision + NLP로 텍스트와 이미지를 동시에 집어넣어 MASK 된 단어를 맞춘다. 혹은 문장과 사진이 일치하는지 예측하여 이미지 기반 택스트 이해, 택스트 기반 이미지 이해를 확인할 수 있다.
한계 : 이미지의 특징과 시각적 세부 사항을 무시하여 정보를 충분히 활용하지 못할 수 있고, 시각적 토큰이 언어 모델링의 능력을 저하시킬 수 있다.
이미지 토큰이란?
네, VisualBERT에서 이미지 토큰을 생성하는 과정은 다음과 같은 방식으로 진행됩니다. 이미지를 뉴럴 네트워크를 통해 처리하여 특징을 추출한 후, 이 특징들을 토큰으로 변환하여 텍스트 토큰과 함께 BERT 모델에 입력으로 사용합니다.
VisualBERT에서 이미지 토큰 생성 과정
- 이미지 처리:
- 이미지는 CNN(Convolutional Neural Network)과 같은 모델을 사용하여 처리됩니다. 주로 사전 학습된 모델인 ResNet, Faster R-CNN 등을 사용하여 이미지에서 중요한 특징(feature)을 추출합니다.
- 예를 들어, Faster R-CNN은 이미지에서 객체를 탐지하고, 각 객체의 영역(proposals)과 해당 특징 벡터를 추출합니다.
- 특징 벡터 추출:
- CNN을 통해 추출된 각 객체 또는 영역의 특징 벡터가 이미지 토큰으로 사용됩니다.
- 각 특징 벡터는 고차원 벡터로, 이미지의 시각적 정보를 압축하여 표현합니다.
- 이미지 토큰 생성:
- 추출된 특징 벡터는 "이미지 토큰"으로 변환됩니다. 이 토큰들은 텍스트 토큰과 동일하게 처리될 수 있도록 변환됩니다.
- 각 이미지 토큰은 특정 객체나 이미지의 일부분을 나타냅니다.
- 텍스트 토큰과 결합:
- 이미지 토큰과 텍스트 토큰은 함께 결합되어 BERT 모델의 입력으로 사용됩니다.
- 예를 들어, 입력 시퀀스는 다음과 같이 구성될 수 있습니다: [CLS] 텍스트 토큰들 [SEP] 이미지 토큰들 [SEP].
예시
- 이미지 입력:
- 입력 이미지: 사람과 테니스 라켓이 있는 이미지.
- 이미지 처리:
- Faster R-CNN을 사용하여 이미지에서 사람과 테니스 라켓을 탐지하고, 각 객체의 특징 벡터를 추출합니다.
- 이미지 토큰 생성:
- 추출된 특징 벡터를 이미지 토큰으로 변환합니다.
- 텍스트 토큰과 결합:
- "Man in black shirt is playing guitar"라는 텍스트와 함께 이미지 토큰을 결합합니다.
- 최종 입력 시퀀스: [CLS] Man in black shirt is playing guitar [SEP] 이미지 토큰들 [SEP].
VisualBERT의 입력 처리
VisualBERT는 이러한 이미지 토큰과 텍스트 토큰을 결합하여 입력으로 사용하고, 이를 통해 텍스트와 이미지 간의 관계를 학습합니다. 이는 BERT의 입력 구조를 확장한 형태로, 텍스트와 이미지 정보를 동시에 처리할 수 있도록 합니다.
요약
VisualBERT에서 이미지 토큰은 이미지에서 추출된 특징 벡터입니다. 이 벡터는 CNN과 같은 뉴럴 네트워크를 통해 추출되며, 텍스트 토큰과 함께 모델의 입력으로 사용됩니다. 이를 통해 VisualBERT는 텍스트와 이미지 간의 관계를 학습할 수 있습니다.
ViLBERT는 텍스트는 BERT가 처리하고 이미지는 Fast R-CNN으로 진행하다가 둘이 섞어서 진행한다.
UNITER은 fast R-CNN과 BERT를 섞은 뒤 다양한 task를 처리한다.
VisualBERT와 ViLBERT가 애매해서...
VisualBERT는 하나의 모델이고, ViLBERT는 두 개의 모델이 스까스까해서 진행하네요
ViLBERT(Vision-and-Language BERT)와 VisualBERT는 둘 다 시각적 정보와 언어적 정보를 결합하여 다양한 비전-언어 작업을 수행하는 모델입니다. 하지만 이 두 모델은 아키텍처와 정보 결합 방식에서 차이가 있습니다. 다음은 ViLBERT와 VisualBERT의 주요 차이점입니다.
VisualBERT
주요 특징:
- 단일 스트림 아키텍처:
- VisualBERT는 텍스트와 이미지 정보를 단일 스트림에서 처리합니다. 텍스트 토큰과 이미지 토큰을 결합하여 BERT 모델에 입력으로 사용합니다.
- 예: [CLS] 텍스트 토큰들 [SEP] 이미지 토큰들 [SEP]
- 이미지 토큰:
- 이미지를 CNN(예: Faster R-CNN)으로 처리하여 객체 특징 벡터를 추출하고, 이를 이미지 토큰으로 사용합니다.
- 텍스트 토큰과 이미지 토큰은 BERT의 입력으로 결합되어 처리됩니다.
- 훈련 목표:
- VisualBERT는 BERT의 마스크드 언어 모델(Masked Language Model, MLM)과 유사한 방식으로 훈련됩니다. 또한, 이미지-텍스트 일치 여부를 예측하는 목표도 포함될 수 있습니다.
- 예: 이미지와 텍스트가 일치하는지 여부를 예측하는 pretext task.
ViLBERT
주요 특징:
- 이중 스트림 아키텍처:
- ViLBERT는 텍스트 스트림과 이미지 스트림을 별도로 처리합니다. 각 스트림은 개별적인 BERT 인코더로 구성되며, 중간에 상호 주의(attention) 메커니즘을 통해 정보를 교환합니다.
- 스트림 구조:
- 텍스트 스트림과 이미지 스트림이 별도로 존재하며, 각 스트림은 자신의 BERT 인코더를 통해 처리됩니다.
- 텍스트 스트림: [CLS] 텍스트 토큰들 [SEP]
- 이미지 스트림: [CLS] 이미지 토큰들 [SEP]
- 상호 주의 메커니즘:
- 텍스트 스트림과 이미지 스트림은 중간 단계에서 상호 주의 메커니즘을 통해 정보를 교환합니다. 이를 통해 텍스트와 이미지 간의 상호 작용을 학습합니다.
- 훈련 목표:
- ViLBERT는 VisualBERT와 유사한 목표를 포함할 수 있지만, 이중 스트림 아키텍처로 인해 텍스트와 이미지 간의 상호 작용을 더 명확하게 학습할 수 있습니다.
- 예: 텍스트와 이미지 간의 상호 연관성을 학습하는 pretext task.
요약
VisualBERT:
- 단일 스트림 아키텍처: 텍스트와 이미지 정보를 단일 스트림에서 처리.
- 이미지 토큰: CNN으로 추출된 객체 특징 벡터를 이미지 토큰으로 사용.
- 훈련 목표: MLM과 이미지-텍스트 일치 여부 예측.
ViLBERT:
- 이중 스트림 아키텍처: 텍스트와 이미지 스트림을 별도로 처리.
- 스트림 구조: 텍스트 스트림과 이미지 스트림이 개별적인 BERT 인코더를 사용.
- 상호 주의 메커니즘: 텍스트와 이미지 간의 정보를 교환하는 메커니즘 포함.
- 훈련 목표: 텍스트와 이미지 간의 상호 연관성을 학습.
두 모델 모두 시각적 정보와 언어적 정보를 결합하여 다양한 비전-언어 작업을 수행하는 데 사용되지만, 정보 처리 방식과 아키텍처에서 차이가 있습니다. VisualBERT는 단일 스트림 접근 방식을 사용하고, ViLBERT는 이중 스트림 접근 방식을 사용하여 텍스트와 이미지 간의 상호 작용을 더 명확하게 학습할 수 있습니다.
15강 - Large Language Model
생성형 인공지능은 대부분 Decoder 모델로 PreTrain 때 input이 들어가면 차례대로 결과가 나오고, 질문에 대한 답을 생성하도록 하는다.
fine-tuning으로 말이 되는지 안 되는지 supervised learning도 진행한다.
그러나 fine-tuning 없이 모든 task를 잘하길 원해서 사이즈도 키우고, 데이터 양과 질도 늘려 좋은 모델을 만들려고 시도하였다.
GPT2는 웹 텍스트를 가져오면서 양도 늘렸고, Transformer layer도 48층으로 늘리며 토큰수도 늘렸다.
파라미터가 엄청나게 증가하였고, normalization이 attention전과 FCN 전으로 이동하였다.
Vocab 사이즈가 커진 것은 인코딩 방식을 세분화했다는 것이다.
일반적, 범용 모델이라면 fine tuning 하지 않은 Zero shot에서도 잘 되어야 한다 -> 파라미터를 업데이트하지 않고 얼려서 inference만 진행하였다. 아직은 fine tuning을 이기진 못했지만 따라잡고 있다.
input에서 무슨 task를 할지 넣어주면 조금 해결한다.
GPT3는 학습데이터가 10배 늘면서 파라미터가 110배 정도가 늘었다.
그러면서 파인튜닝하는데 리소스가 많이 들어가므로 input으로만 해결해야 되었다.
input에 각종 예시와 task를 주는 Few-shot이 나왔다. == Natural Language Prompt
FLAN - 명령어를 주면서 task를 시키면 다양한 작업을 잘 수행한다.
RLHF : 사람의 평가에 의한 강화학습으로 사람들이 답변을 평가하고, 그중 제일 높은 점수의 답이 나오도록 학습된다.
일정 파라미터가 넘어가면서 instruction tuning의 효과가 커졌다.
16강 - Prompt Engineering
Prompt는 instruction과 context, input data로 되어있으며 모델에 들어가 output으로 나오게 된다.
Chat GPT는 오픈 도메인이므로 instructions를 잘 작성해야 좋은 결과가 나온다.
상황을 가정해 주고, 무슨 일을 할지 명령해 주며, 원하는 대답의 형태 등 다양하게 넣어준다.
Temperature를 통해 precision을 조정할 수 있다.
Zero shot COT : "Lets think step by step"를 활용하여 순차적으로 대응할 수 있도록 한다. 문제도 순차적으로 줘야 한다.
Self-Consistency : 순차적으로 해결하는 예시를 보여줘서 CoT와 비슷한 과정으로 푼다. 예시를 계속 넣으며 일관적으로 만든다.
Generate Knowledge Prompting : 좋은 사전 지식을 prompt에 넣어서 결과를 좋게 만든다.
Program-Aided Language Model(PAL) : 코드 형식으로 명확하게 전달한다.
ReAct : 근거와 상황을 미리 전달한다.
LLM의 단점 보안을 위해 RAG 등 다양한 Appliation과 협업을 통해 수식이나 수학의 약점 커버
명확하고, 문맥을 제공하며, 길이를 정해주고, 응답을 제한하며, 여러 실험을 통해 프롬프트를 설계할 수 있다.
모델의 안전성도 프롬프트 주입, 누출, 탈옥을 통해 공격받고 있다.
17강 - Parameter efficient tuning
현재 LLM은 사이즈가 너무 크기 때문에 각각 task마다 fine-tuning을 진행하기엔 리소스가 너무 많이 든다.
Adapter - attention과 normalization, FCN과 normalization사이에 추가하여 그 부분만 fine tuning 하여도 전체를 파인튜닝한 것과 큰 차이가 나지 않고, 적은 숫자로도 빠른 수렴이 가능하게 해 준다.
p-tuning은 prefix + prompt로 학습가능한 파라미터 2개를 추가시킨다. prefix는 특정 task마다 갈아 끼울 수 있도록 되어있고, input 앞에 붙어서 task에 최적화되도록 만들어준다. prompt는 입력 끝에 추가시켜서 task에 최적화시킨다.
모델의 표현을 극대화하고, 다양한 작업에서 더 나은 성능을 발휘할 수 있으며, 더 정교하고 효율적인 방식이다.
LoRA는 adapter와 비슷하게 사용되며 파라미터를 Low Rank Adaptation을 통해 효율적으로 사용한다.
네, LoRA (Low-Rank Adaptation)와 Adapters는 둘 다 사전 학습된 모델을 다양한 다운스트림 작업에 효율적으로 적용하기 위한 방법입니다. 이 두 방법은 파라미터 효율성을 강조하지만, 그 접근 방식에는 몇 가지 중요한 차이점이 있습니다.
LoRA와 Adapters의 비교
1. 기본 개념
Adapters:
- 어댑터 레이어: 기존의 사전 학습된 모델의 레이어 사이에 작은 네트워크(어댑터 레이어)를 삽입하여, 이를 통해 모델의 성능을 조정합니다.
- 파라미터 효율성: 어댑터 레이어만 학습하고, 원래 모델의 파라미터는 고정된 상태로 유지합니다. 따라서 전체 모델의 학습 파라미터 수가 줄어들어 효율적입니다.
LoRA:
- 저 랭크 매트릭스: 사전 학습된 모델의 파라미터를 저랭크 근사(low-rank approximation)로 분해하여, 새로운 저랭크 매트릭스만 학습합니다.
- 파라미터 효율성: 저 랭크 매트릭스의 파라미터만 학습하고, 원래 모델의 파라미터는 고정된 상태로 유지합니다. 이는 전체 파라미터 수를 줄이면서도 성능을 유지하거나 향상시킬 수 있습니다.
2. 작동 방식
Adapters:
- 구조적 변화: 어댑터 레이어를 기존 모델 레이어 사이에 삽입합니다. 이 레이어는 작은 병목 네트워크(bottleneck network) 형태로, 입력을 압축한 후 다시 확장합니다.
- 주요 아이디어: 어댑터 레이어가 입력 특징을 학습하고 조정함으로써, 모델이 다양한 다운스트림 작업에 적응할 수 있게 합니다.
LoRA:
- 저랭크 근사: 기존 모델의 가중치 행렬을 저랭크 근사로 분해합니다. 즉, 원래의 큰 가중치 행렬을 두 개의 작은 저랭크 행렬의 곱으로 표현합니다.
- 주요 아이디어: 저랭크 행렬만 학습하여 모델의 효율성을 높이고, 기존의 가중치 행렬은 고정된 상태로 유지합니다.
3. 장단점
Adapters:
- 장점:
- 구현이 비교적 간단하며, 기존 모델의 아키텍처에 큰 변화를 주지 않습니다.
- 다양한 다운스트림 작업에 쉽게 적용할 수 있습니다.
- 단점:
- 어댑터 레이어의 추가로 인해 약간의 계산 오버헤드가 발생할 수 있습니다.
LoRA:
- 장점:
- 저랭크 근사로 인해 파라미터 수가 크게 줄어들어 매우 효율적입니다.
- 학습할 파라미터가 적기 때문에 학습 속도가 빠르고, 메모리 사용량이 적습니다.
- 단점:
- 저랭크 근사로 인한 성능 저하 가능성이 있습니다. 하지만 대부분의 경우 성능을 유지하거나 향상시킬 수 있습니다.
결론
LoRA와 Adapters는 모두 사전 학습된 모델을 다양한 다운스트림 작업에 효율적으로 적용하기 위한 방법이지만, 그 접근 방식에는 차이가 있습니다. Adapters는 어댑터 레이어를 추가하여 모델의 성능을 조정하고, LoRA는 저랭크 매트릭스 근사를 통해 파라미터 효율성을 극대화합니다.
두 방법 모두 파라미터 효율성을 강조하지만, LoRA는 특히 파라미터 수를 크게 줄이면서도 성능을 유지하거나 향상시킬 수 있는 점에서 차별화됩니다. 어댑터 레이어를 사용하는 방법과 저랭크 근사를 사용하는 방법의 차이를 이해하고, 각각의 장단점을 고려하여 적절한 방법을 선택할 수 있습니다.
'인공지능 > 자연어 처리' 카테고리의 다른 글
| Python NLP - BERT Binary Classification (hugging Face Transformer library) (0) | 2024.06.19 |
|---|---|
| 자연어 처리 기말고사 대비 문제 만들기 (2) | 2024.06.12 |
| 자연어 처리 17강 - Parameter efficient Tuning (1) | 2024.06.05 |
| 자연어 처리 16강 - Prompt Engineering (0) | 2024.06.05 |
| 자연어 처리 15강 - Large Language Model (0) | 2024.06.05 |