728x90
728x90

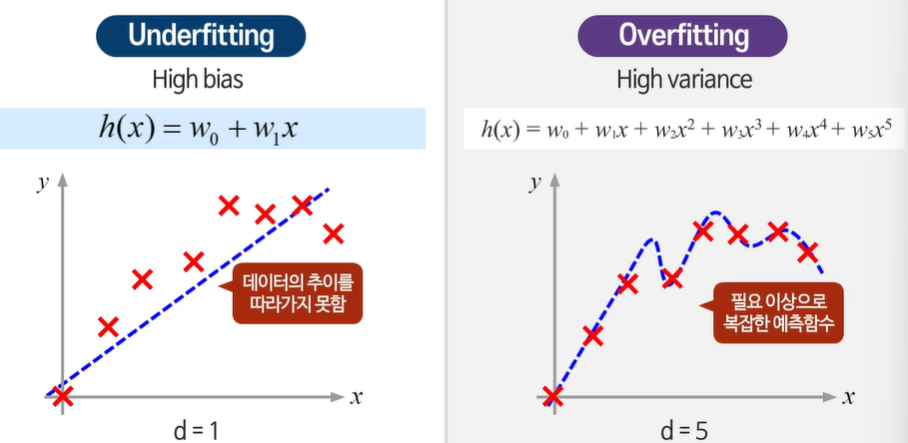
언더 피팅 - 지나치게 단순해서 데이터의 추이를 따라가지 못한다.
오버 피팅 - 지나치게 복잡하다( 지나치게 높은 차수)

적당히 따라가서 트랜드를 잘 따라간다 == 일반화 성능이 우수하다.
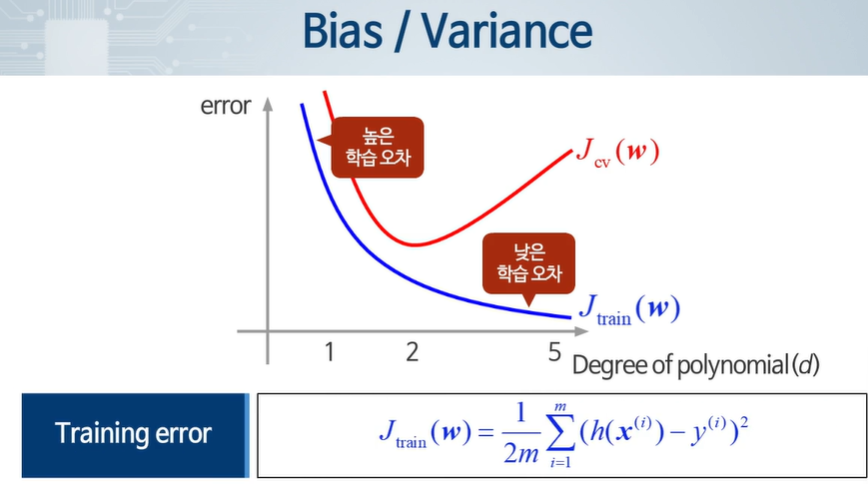
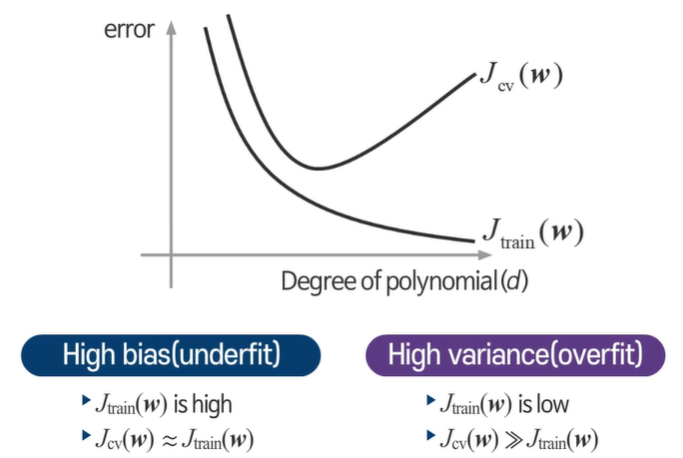
차수가 증가함에 따라 학습 오차는 점점 준다
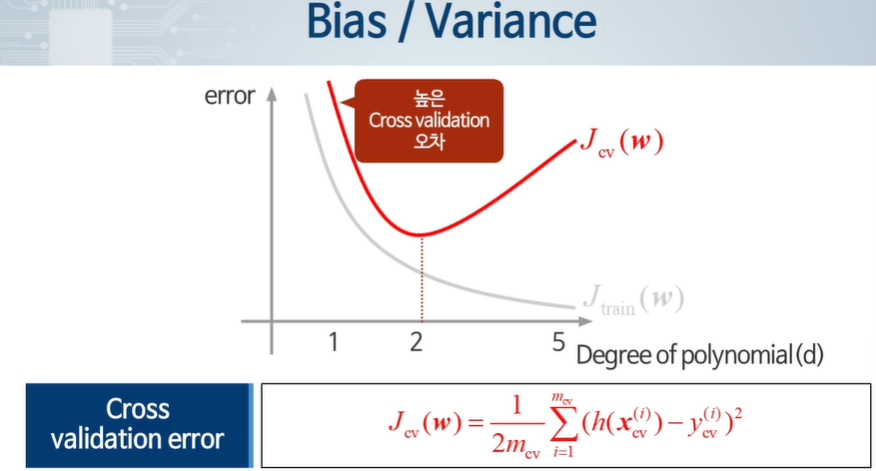
validation은 일정 이상이 되면 오차가 늘어난다.

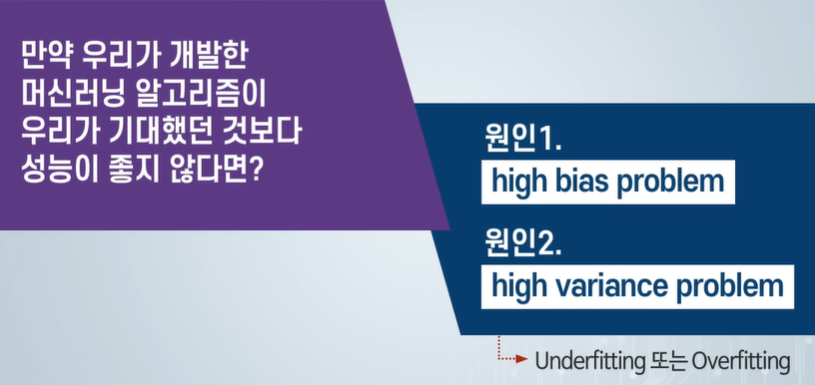
둘다 크면 언더피팅이죠! == 높은 편향!



y 만 관측 가능하고, 입실론 때문에 오차가 발생하게 되낟.
y의 평균은 h, 분산은 시그마의 제곱이 된다.


노이즈의 평균값은 0이므로 사라지는 값이 생긴다.

시그마 제곱 - 원래 데이터를 생성하는 모델에 포함되어 있는 노이즈의 분산
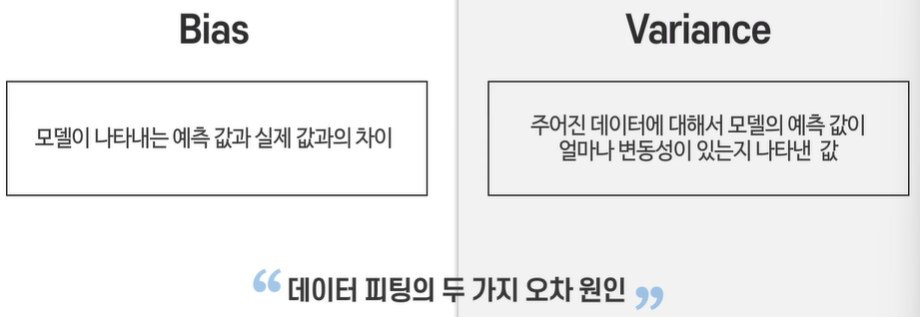
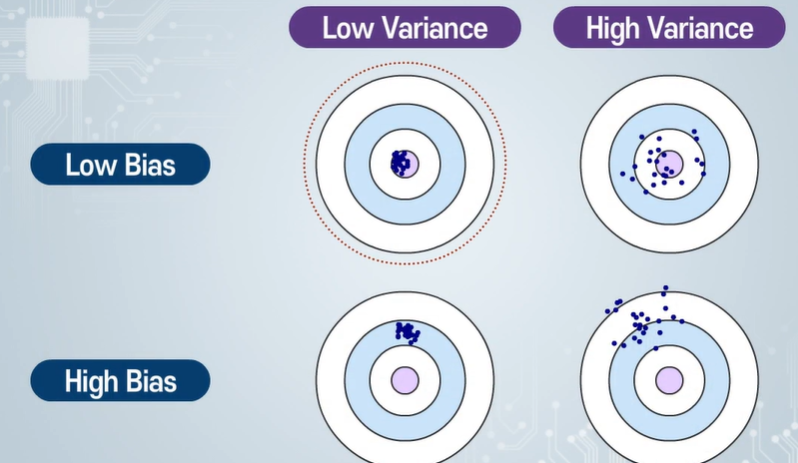
Variance - 파라미터를 완벽하게 예측할 수 없기 때문에 생기는 오차
bias - 단순화하였기 때문에 생긴 오차


정규화 항이 있다면?
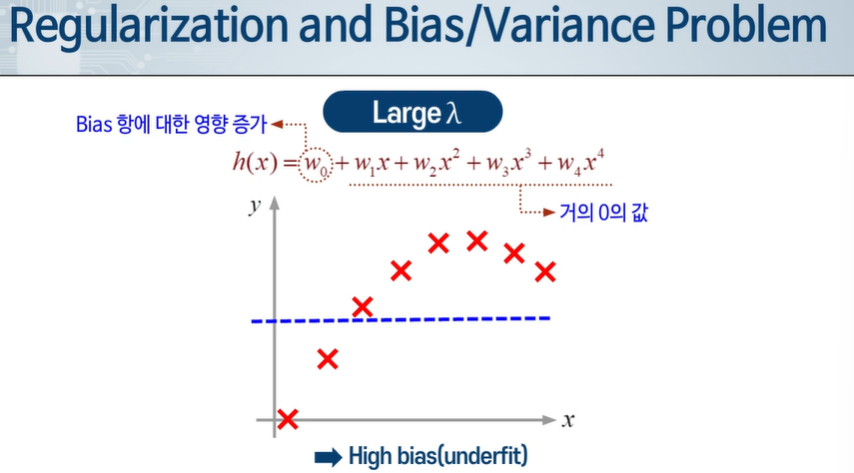
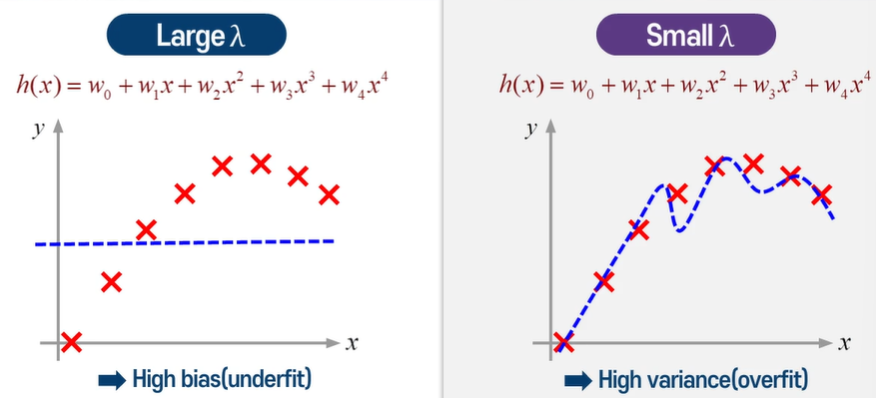
람다 값을 어떻게 잘 선택할까?
적당히 작은 값.....

정규화 항이 없다면 다 똑같이 정의된다.

가장 낮은 값이 5였다면?
뭐야 람다 없다면서 람다 왜 있어. 이제보니까?????????????

test와 validation엔 정규화 항이 없다.
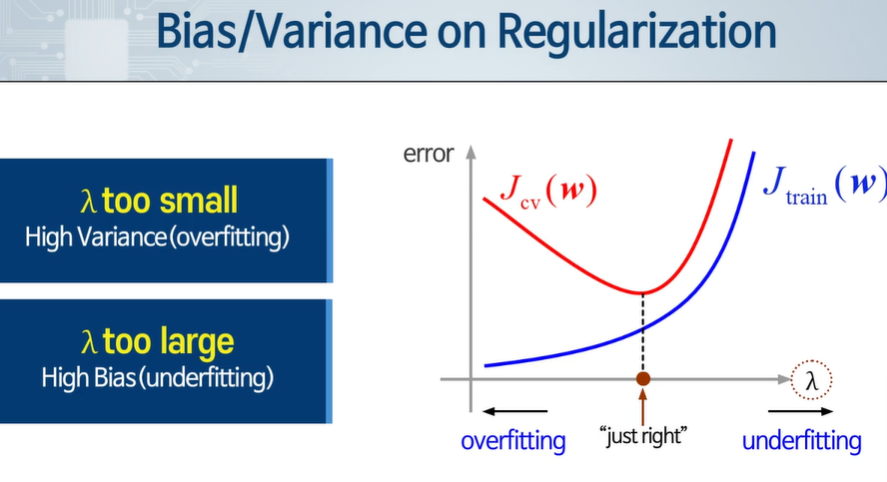
정규화 파라미터 값에 따라 오버피팅, 언더 피팅이 나뉘게 된다.

bias - 올바른 해답을 얼마나 잘 표현한지 기대할 수 있나.
variance - 모델이 얼마나 민감하게 변동성을 보여주냐


728x90
'인공지능 > 공부' 카테고리의 다른 글
| 모두를 위한 머신러닝 9주차 5차시 - 학습 알고리즘의 성능 향상 (1) | 2024.05.02 |
|---|---|
| 모두를 위한 머신러닝 9주차 4차시 - 학습 곡선 (0) | 2024.05.02 |
| 머신러닝 9주차 2차시 - 최적 모델의 선택(데이터 셋 나누기) (0) | 2024.05.01 |
| 머신러닝 9주차 1차시 - 예측 함수 성능 평가(데이터 셋 분류) (1) | 2024.05.01 |
| 인공지능과 빅데이터 9주차 3차시 - 빅데이터와 데이터 마이닝 (0) | 2024.04.29 |