2024.04.15 - [인공지능/자연어 처리] - 자연어 처리 중간 정리 1
자연어 처리 중간 정리 1
2강 - Text mining 자연어 처리 - 사람의 언어를 컴퓨터가 이해할 수 있는 체계인 숫자로 변환하여 번역, 감성분석, 정보 요약 등 다양한 TASK를 처리하는 것 컴퓨터가 이해할 수 있는 체계로의 변환 ==
yoonschallenge.tistory.com
언어의 특성 - 동음이의어, 사회적 지식, 모호성
단어 -> 형태 -> 문법 -> 의미 -> 대화
품사, 이름, 문법
통계에 기반한 embedding 방식
onehot encoding - 그저 index. 차원이 너무 많다.
TD - 통계에 기반한 단어 등장 횟수로 표현한 임베딩.
TF- IDF : 이것도 통계에 기반한 임베딩으로 차원이 아직도 너무 많아 효율이 떨어진다.

유사도 계산 - Cos 유사도
유사도가 높은 단어는 1에 가깝게 나온다.
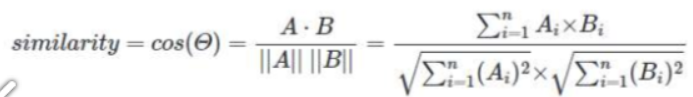
Word2Vec - 뉴럴 넷을 활용하여 주변 단어 맞추기로 학습하여 파라미터를 임베딩으로 사용한다.
-> 벡터로 표현됨 : 문맥의 정보를 포함하고, 비슷한 문맥에서 나타나는 단어는 비슷한 백터 표현을 가진다.
BUT 순서 정보가 없다. 그리고 미리 학습한 단어에 대해 효과가 좋지만 모르는 단어에 대해선 기본형으로 변환해야 한다.
Subword 모델은 텍스트 데이터를 처리할 때, 단어를 더 작은 단위인 subwords나 morphemes로 분해하여 사용하는 방법입니다. 이 접근 방식은 언어의 모르는 단어(out-of-vocabulary, OOV) 문제를 줄이고, 언어의 구조적인 세부사항을 더 잘 반영할 수 있도록 합니다. 예를 들어, "unhappiness"라는 단어를 "un-", "happy", "-ness"와 같은 의미 있는 조각으로 분할하여 학습에 활용할 수 있습니다. 이러한 모델은 BERT나 GPT와 같은 현대의 NLP 시스템에서 널리 사용됩니다.
FastText는 Facebook에서 개발한 자연어 처리 라이브러리로, Word2Vec의 아이디어를 기반으로 합니다. 하지만 FastText는 각 단어를 개별적인 단위로만 처리하는 대신에, 단어를 여러 개의 n-gram(subwords)으로 분해하여 각 n-gram의 임베딩을 학습하고, 최종 단어의 표현을 이들 n-gram 벡터의 합으로 계산합니다. 이 접근법은 단어 내에 내재된 형태학적 정보를 활용할 수 있게 하며, 특히 희귀 단어나 신조어 처리에 유리하고, 다양한 언어의 복잡한 형태학을 가진 단어들에 대해서도 더 강력한 표현력을 제공합니다.



data size
SGD - 샘플마다 업데이트 == 학습속도는 빠르지만 진동이 크다.
batch Learning - 모든 데이터 셋을 다 사용하여 업데이트 == 학습은 느리고, Local min에 빠질 수 있지만 진동이 거의 없다.
mini batch - 두 가지를 적절히 섞어서 batch 사이즈 마다 학습하고 총 epoch만큼 데이터셋 반복
Optimizer
Momentum - 기울기 누적
Adagrad - lr이 점점 작아진다
adam = Momentum + Adagrad
overfitting - training 데이터에 지나치게 과적합
해결 : early stopping, Dropout, Weight decay, Weight Restriction(가중치 제한), Data Augmentation
batch normalization - 분포를 변화시켜 레이어 기능 활성화
weight initalization - Xavier(Sigmoid), He(ReLU)
ensemble - 히든레이어가 많아 오버피팅이 났다 -> 다양한 모델을 만들어 평균하자 => 오버피팅 방지 및 다양성 증가
정확도 : 예측 중 정답을 얼마나 맞췄는지
정밀도(Precision) : 예측한 Positive 중 True인 것 (암이라고 예측했는데 암인 경우)
재현율(recall) : True인데 Positive로 예측한 것(암인데 암이라고 예측하는 경우)
1종오류 : False인데 Positive로 예측 (남자한테 임신했습니다.)
2종오류 : True인데 Negative로 예측 (임신한 여자한테 임신 아닙니다.)
F1 score (조화평균) : 1/{(1/Precision) + (1/recall)}
언어 모델에서 CNN 사용 이유 - 문장의 가변적 길이, n-gram feature 확인
embedding -> convolution -> activation -> pooling -> FCN
자연어 - 순서가 있는 데이터들의 연속 == RNN 사용가능
RNN의 파라미터는 공유된다.
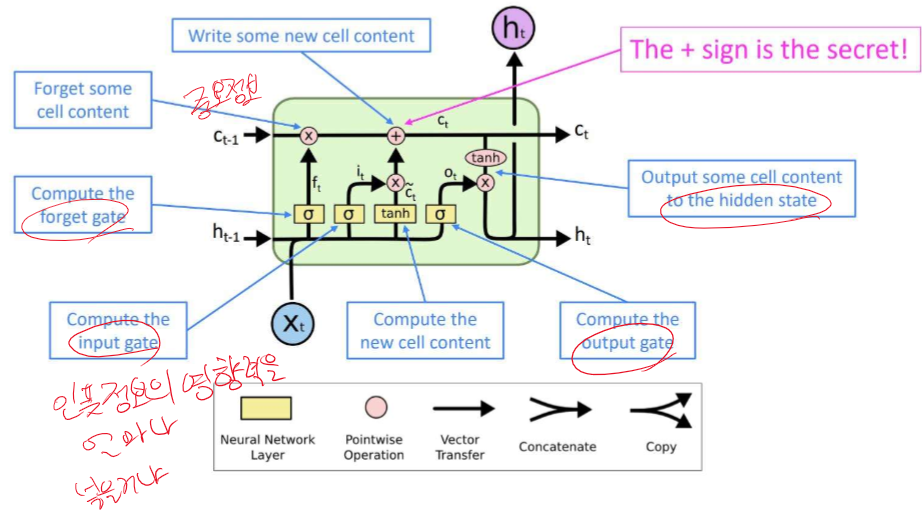
한계 : 길어질수록 정보 손실이 일어난다. -> LSTM 사용 - 다양한 GATE를 통해 정보 전달에 효과적
Seq2Seq - LSTM을 통해 Encoder + Decoder 구조 - Greedy Decoding으로 가장 높은 확률을 가지는 단어를 선택
가장 높은 확률만 선택하면 되돌아 갈 수 없다!
-> Beam Search Decoding : n개의 단어에게서 n개의 단어를 추출하고 n개만 남겨둬서 계속 진행하기
Seq2Seq의 한계 : 병목현상 -> 어텐션의 등장
attention
1. 디코더 시작값과 인코더의 모든 값 각각 내적 == attention score
2, attention score Softmax 하면 가중치가 나온다
3. key값을 가중치와 곱하여 Decoder와 concat
Encoder의 어느 값이 중요한지 알 수 있게 된다.
BLUE 평가 - n-gram씩 사람과 컴퓨터의 번역을 비교하면서 진행
Extractive summerization == 중요한 문장 찾기
Abstractive summerization == 중요한 문장 만들기
Transformer - attention으로만 이루어진 네트워크
Self-attention : 자기 자신으로 attention을 진행하여 맥락, 순서 정보를 모두 가진 벡터를 만든다.
Multi-Head attention : 임베딩 차원을 나눠서 각각 다른 feature를 뽑는다.
Masked attention : 학습할 때 문장 전체를 넣게 되는데 아직 예측하지 않은 뒷 부분을 사용하면 안되기 때문에 가리는 것

'인공지능 > 자연어 처리' 카테고리의 다른 글
| GPT로 자연어 처리 퀴즈 만들기 2 - embedding, transformer, text mining (0) | 2024.04.17 |
|---|---|
| 자연어 처리 중간고사 애매한 것 정리하기 (0) | 2024.04.17 |
| 자연어 처리 중간고사 대비 Chat GPT 퀴즈 (0) | 2024.04.16 |
| Chat GPT 통한 자연어 처리 중간고사 OX, 빈칸 퀴즈 문제 (0) | 2024.04.16 |
| 자연어 처리 중간 정리 1 (0) | 2024.04.15 |