import torch
import torch.nn as nn
# Comparison of number of parameters, LSTM vs GRU
lstm_layer = nn.LSTM(3, 5) #3 is input size,which is input number's embedding vector;5 is hidden_size,which shows network's ability and memory.
gru_layer = nn.GRU(3, 5)
print(sum(p.numel() for p in lstm_layer.parameters()))
print(sum(p.numel() for p in gru_layer.parameters()))200
150
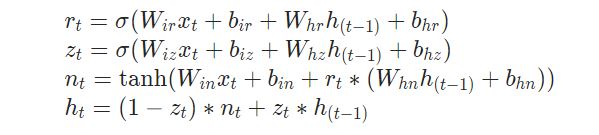
# complete GRU network
def gru_forward(input, initial_state, w_ih, w_hh, b_ih, b_hh):
prev_h = initial_state
bs, T, i_size = input.shape
h_size = w_ih.shape[0] // 3 # GPU has 3 groups
# For weight expansion, copy batch_size times
batch_w_ih = w_ih.unsqueeze(0).tile(bs, 1, 1)
batch_w_hh = w_hh.unsqueeze(0).tile(bs, 1, 1)
output = torch.zeros(bs, T, h_size) # GRU network output sequence
for t in range(T):
x = input[:, t, :] # t time GRU cell input vector, [bs, i_size]
w_times_x = torch.bmm(batch_w_ih, x.unsqueeze(-1)) # [bs, 3*h_size, 1]
w_times_x = w_times_x.squeeze(-1) # [bs, 3*h_size]
w_times_h_prev = torch.bmm(batch_w_hh, prev_h.unsqueeze(-1)) # [bs, 3*h_size, 1]
w_times_h_prev = w_times_h_prev.squeeze(-1) # [bs, 3*h_size]
r_t = torch.sigmoid(w_times_x[:, :h_size] + w_times_h_prev[:, :h_size] + \
b_ih[:h_size] + b_hh[:h_size]) # reset gates
z_t = torch.sigmoid(w_times_x[:, h_size:h_size*2] + w_times_h_prev[:, h_size:h_size*2] + \
b_ih[h_size:h_size*2] + b_hh[h_size:h_size*2]) # update gates
n_t = torch.tanh(w_times_x[:, h_size*2:h_size*3] + b_ih[h_size*2:h_size*3] + \
r_t*(w_times_h_prev[:, h_size*2:h_size*3] + b_hh[h_size*2:h_size*3])) # new gates
prev_h = (1-z_t)*n_t + z_t*prev_h # Update the implied state incrementally
output[:, t, :] = prev_h
return output, prev_h
# fisrt testing the correctness of a function
bs, T, i_size, h_size = 2, 3, 4, 5
input = torch.randn(bs, T, i_size) # input sequence
h_0 = torch.randn(bs, h_size) # proj is a compression of h
# Using the official GRU API
gru_layer = nn.GRU(i_size, h_size, batch_first=True)
# input has batch, h_0 also need increse one dimension
output, h_final = gru_layer(input, h_0.unsqueeze(0))
print(f'[Info] output: \n{output}')
for k, v in gru_layer.named_parameters():
print(k, v.shape)
output_custom, h_final_custom = gru_forward(input, h_0, gru_layer.weight_ih_l0, gru_layer.weight_hh_l0, \
gru_layer.bias_ih_l0, gru_layer.bias_hh_l0)
print(f'[Info] output_custom: \n{output_custom}')[Info] output:
tensor([[[-0.6685, -0.0647, -0.7804, 0.3492, -0.2578],
[ 0.2485, -0.0994, -0.1951, -0.1328, -0.0540],
[ 0.1673, 0.1734, -0.4363, 0.0931, 0.1852]],
[[ 0.0554, 0.0910, -0.1709, 0.4527, 0.4302],
[ 0.3979, 0.0780, 0.3177, 0.1780, 0.3212],
[ 0.4039, 0.1357, 0.3363, -0.4384, 0.4896]]],
grad_fn=<TransposeBackward1>)
weight_ih_l0 torch.Size([15, 4])
weight_hh_l0 torch.Size([15, 5])
bias_ih_l0 torch.Size([15])
bias_hh_l0 torch.Size([15])
[Info] output_custom:
tensor([[[-0.6685, -0.0647, -0.7804, 0.3492, -0.2578],
[ 0.2485, -0.0994, -0.1951, -0.1328, -0.0540],
[ 0.1673, 0.1734, -0.4363, 0.0931, 0.1852]],
[[ 0.0554, 0.0910, -0.1709, 0.4527, 0.4302],
[ 0.3979, 0.0780, 0.3177, 0.1780, 0.3212],
[ 0.4039, 0.1357, 0.3363, -0.4384, 0.4896]]], grad_fn=<CopySlices>)
GRU(Gated Recurrent Unit)는 순환신경망(RNN)의 일종으로, 시퀀스 데이터를 처리할 때 이전 상태의 정보를 효과적으로 보존하면서 문제의 장기 의존성을 다루기 위해 고안된 구조입니다. 다음은 GRU 네트워크에 대한 설명입니다:
r_t (리셋 게이트): 이전 상태를 얼마나 잊어버릴지 결정합니다. 값이 0에 가까우면 과거 정보를 더 많이 잊고, 1에 가까우면 더 많이 기억합니다.
z_t (업데이트 게이트): 현재 상태와 새로운 정보를 얼마나 혼합할지 결정합니다. 값이 0이면 새 정보만, 1이면 이전 상태만 반영합니다.
n_t (새 게이트): 새로운 후보 상태를 계산합니다. 현재 입력과 리셋 게이트에 의해 조정된 이전 상태를 기반으로 새로운 정보를 만들어냅니다.
gru_forward 함수는 이러한 게이트들을 사용하여 시퀀스의 각 시점마다 숨겨진 상태를 업데이트합니다. for 루프를 통해 시퀀스의 각 시점에 대해 순차적으로 연산을 수행하고, 마지막으로 모든 시퀀스의 출력과 최종 상태를 반환합니다.
h_0는 GRU 네트워크의 초기 상태로, 첫 번째 숨겨진 상태를 정의합니다. 테스트 코드는 이 함수가 공식적인 PyTorch GRU 레이어와 동일한 결과를 생성하는지 확인하기 위해 작성되었습니다.
코드의 끝에 gru_forward 함수를 호출하여 사용자 정의 GRU 네트워크의 결과를 출력하고 공식 nn.GRU 레이어의 결과와 비교합니다. 이를 통해 사용자 정의 함수가 올바르게 작동하는지 검증합니다.
GRU를 처음 사용하신다면, PyTorch의 공식 nn.GRU 레이어를 사용하는 것이 좋습니다. 공식 레이어는 최적화가 잘 되어 있고, 사용하기도 더 쉽습니다. 사용자 정의 함수는 GRU의 작동 원리를 더 깊게 이해하고 싶을 때 유용합니다.
'인공지능 > 공부' 카테고리의 다른 글
| 생성형 인공지능 2주차 4 - Attention 2 (0) | 2024.03.11 |
|---|---|
| 생성형 인공지능 2주차 3 - Attention 1 (0) | 2024.03.11 |
| 생성형 인공지능 2주차 2 - 재귀 신경망 2 RNN (0) | 2024.03.11 |
| 생성형 인공지능 2주차 1 - 재귀 신경망 1 RNN (0) | 2024.03.11 |
| 인공지능과 빅 데이터 2주차 3 - 표현 학습과 딥러닝 (0) | 2024.03.11 |