728x90
728x90

문제점이라면 정보 소실이랑 양이 너무 많아지면 엄청난 메모리 필요한 것?
슈미드 밀러 - LSTM 장단기 메모리
조경현 - GRU
마지막엔 결국 Transformer

문장이 길어지면서 학습할 때 error가 손실하게 된다.
긴 문장이 들어오면 학습이 안되거나 Gradient가 폭팔해버린다.

clip = 집는다. Gradient의 최소, 최대 한계를 정해놓는다.

GRU : LSTM의 복잡함을 줄였다.

3가지 게이트로 이루어져 있다.
forget gate
input gate
output gate

히든 스테이트가 셀 스테이트 역할을 한다.

리셋 게이트 : 그냥 이전과 지금 값 가중치 해서 더하기
포겟 게이트 : 리셋이랑 비슷하다.
인풋 게이트 : 1 - 포


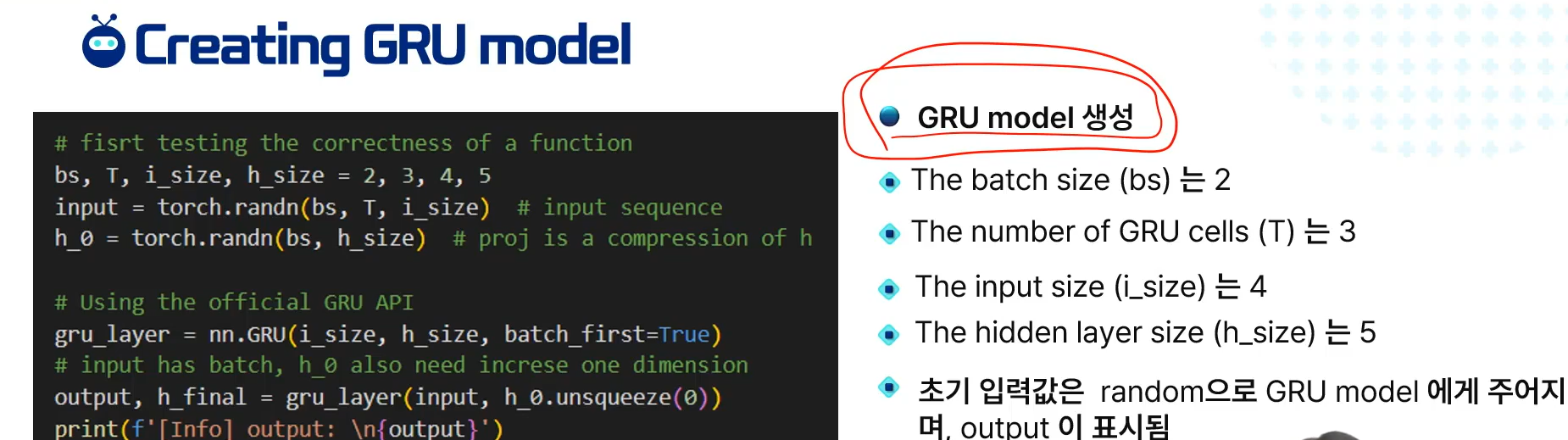
이전 페이지를 그대로 계산을 구현한 것




728x90
'인공지능 > 공부' 카테고리의 다른 글
| 생성형 인공지능 2주차 3 - Attention 1 (0) | 2024.03.11 |
|---|---|
| GRU 실습 - python (0) | 2024.03.11 |
| 생성형 인공지능 2주차 1 - 재귀 신경망 1 RNN (0) | 2024.03.11 |
| 인공지능과 빅 데이터 2주차 3 - 표현 학습과 딥러닝 (0) | 2024.03.11 |
| 인공지능과 빅 데이터 2주차 2 - 규칙 기반 시스템과 머신 러닝 (0) | 2024.03.11 |