https://arxiv.org/abs/2501.19393
s1: Simple test-time scaling
Test-time scaling is a promising new approach to language modeling that uses extra test-time compute to improve performance. Recently, OpenAI's o1 model showed this capability but did not publicly share its methodology, leading to many replication efforts.
arxiv.org
이 논문은 RL 없이도 1000개의 reasoning trace로 sft하고, 추론 시 모델의 생각 길이를 강제로 조절하는 budget forcing을 적용하여 작은 비용으로도 test-time scaling이 가능한 reasoning model을 만들 수 있음을 보였습니다.

token이 늘어날수록 정답률이 오르는 것을 볼 수 있다.
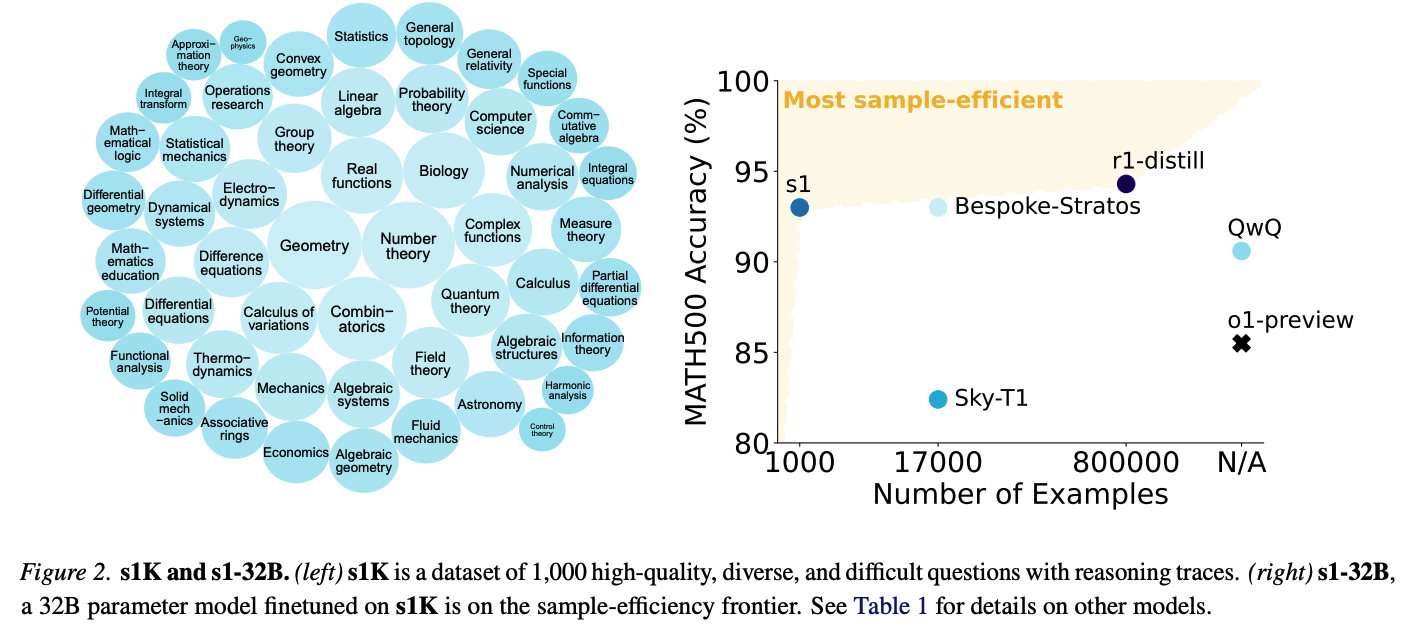
16개의 소스에서 퀄리티, 난이도, 분포를 조절하여 1000개의 문제를 골라냄
그 데이터를 통해 Qwen 2.5 32B instruct model에 sft를 진ㄷ행함

thinking을 짧게 만들기 위해서는 일정 버짓을 넘어가면 엔드 띵크 토큰을 넣고, 길게 만들기 위해서는 엔드 토큰이 나올 때 wait를 통해 reasoning trace를 늘림.

AIME24, MATH500, GPQA Diamond 벤치마크에서 평가하고, 성능이 크게 오름.

r1distill보다는 성능이 낮은데 데이터의 차이를 말함.

고품질 데이터의 중요성을 말함.

토큰수 제한을 거는 것은 컨트롤이 어려웠음.

| 핵심 질문 | OpenAI o1처럼 test-time compute를 늘릴수록 reasoning 성능이 좋아지는 모델을 대규모 RL 없이 단순한 방식으로 만들 수 있는가? |
| 문제의식 | 기존 o1/R1-style reasoning model은 강력하지만, 방법론이 비공개이거나 대규모 RL·대량 데이터·복잡한 multi-stage training에 의존함. 저자들은 가장 단순한 recipe로 test-time scaling을 재현하려 함. |
| 핵심 아이디어 | 잘 선별한 1,000개 reasoning trace로 SFT하고, 추론 시 budget forcing으로 thinking token 길이를 강제로 조절하면 강한 reasoning 성능과 test-time scaling이 가능함. |
| 데이터셋 | s1K: 59,029개 후보 문제에서 최종 1,000개만 선별. Gemini Flash Thinking으로 reasoning trace와 solution을 생성함. |
| 데이터 선별 기준 | Quality, Difficulty, Diversity 세 기준 사용. ① 포맷 오류·저품질 샘플 제거, ② Qwen2.5-7B/32B가 맞힌 쉬운 문제 제거, ③ Claude로 domain 분류 후 다양한 분야에서 sampling. |
| 학습 모델 | Qwen2.5-32B-Instruct를 base model로 사용하여 s1K에 대해 supervised fine-tuning 수행. 결과 모델은 s1-32B. |
| 학습 방식 | Next-token prediction 기반 SFT. 질문에는 loss를 주지 않고, reasoning trace와 final answer에만 loss 적용. |
| 학습 비용 | 16 NVIDIA H100 GPU에서 약 26분. 총 5 epochs, 315 gradient steps. |
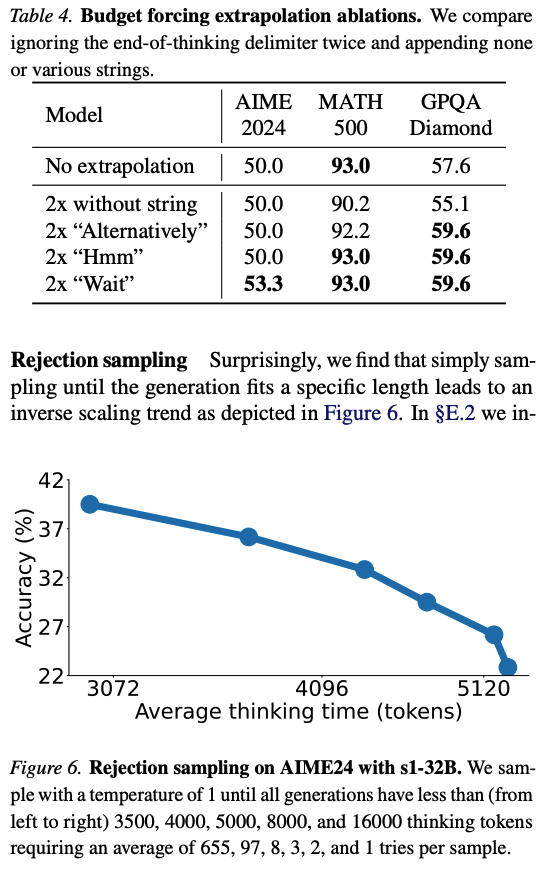
| 핵심 기법: Budget Forcing | 모델의 thinking 길이를 decoding 단계에서 강제 조절하는 방법. 너무 길면 end-of-thinking delimiter를 삽입해 종료시키고, 더 생각하게 만들고 싶으면 end-of-thinking을 막은 뒤 "Wait"를 삽입함. |
| Budget Forcing의 효과 | 모델이 답을 끝내려 할 때 "Wait"를 넣으면 스스로 검토하거나 오류를 수정하는 경우가 생김. 즉, 단순한 intervention으로 self-correction을 유도함. |
| 평가 벤치마크 | AIME24, MATH500, GPQA Diamond. 수학 경시, competition math, PhD-level 과학 reasoning 능력을 평가함. |
| 주요 성능 | s1-32B는 AIME24 56.7, MATH500 93.0, GPQA Diamond 59.6을 달성. Base model Qwen2.5-32B-Instruct의 AIME24 26.7보다 크게 향상됨. |
| 비교 결과 | 1K 데이터만 사용했음에도 Sky-T1보다 강하고, 일부 benchmark에서 o1-preview와 경쟁 가능함. 다만 DeepSeek-R1 계열보다는 낮음. |
| Sample efficiency | s1-32B는 1,000개 샘플만으로 강한 reasoning 성능을 얻었다는 점에서 sample-efficient reasoning model임. r1-distill은 약 800K 샘플을 사용한 반면 s1은 1K만 사용함. |
| Ablation: 데이터 | random 1K, diverse-only 1K, longest-only 1K보다 s1K가 전반적으로 우수함. 즉, 단순히 많이 또는 길게 고르는 것이 아니라 품질·난이도·다양성의 결합이 중요함. |
| Ablation: 59K 전체 학습 | 59K 전체를 학습해도 s1K 대비 큰 이득이 없음. 이는 reasoning SFT에서 데이터 양보다 선별 품질이 중요함을 시사함. |
| Ablation: test-time scaling | Token control, step control, class control, rejection sampling과 비교했을 때 budget forcing이 control, scaling, performance 측면에서 가장 안정적임. |
| 주요 한계 | Budget forcing을 과도하게 적용하면 반복 루프나 plateau가 발생함. Context window 한계가 있으며, 데이터가 Gemini distillation에 의존함. 평가도 수학·과학 reasoning 중심이라 일반 task로의 확장성은 추가 검증 필요. |
| 논문의 의의 | 대규모 RL 없이도 소량의 고품질 reasoning trace + 간단한 추론 제어만으로 test-time scaling behavior를 만들 수 있음을 보임. |
| 연구적 해석 | 이 논문은 reasoning 능력이 base model 내부에 이미 어느 정도 잠재되어 있고, SFT는 이를 새로 학습한다기보다 reasoning mode를 활성화하는 역할을 할 수 있음을 시사함. |
| 후속 연구 방향 | 더 좋은 reasoning trace selection, RL 없이 가능한 reasoning activation의 한계, budget forcing보다 안정적인 compute controller, SFT 기반 reasoning과 RL 기반 reasoning의 차이 분석이 중요함. |
'인공지능 > 논문 리뷰 or 진행' 카테고리의 다른 글
| Recursive Multi-Agent Systems (0) | 2026.05.15 |
|---|---|
| LIMO: Less is More for Reasoning (0) | 2026.05.14 |
| Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes (0) | 2026.05.12 |
| Associative Recurrent Memory Transformer (0) | 2026.05.12 |
| Adapting Language Models to Compress Contexts (0) | 2026.05.10 |