✅ Collator 정리
인공지능 모델 학습에 사용되는 데이터는 일반적으로 하나의 샘플씩 불러오며, 리스트 형태로 되어 있고 문장 길이도 서로 다릅니다.
이때 Collator는 다음과 같은 역할을 합니다:
- 샘플 여러 개를 하나의 배치(batch) 로 묶고,
- 각 문장을 가장 긴 문장에 맞춰 패딩(padding) 한 뒤,
- 파이토치 텐서(torch.Tensor) 로 변환합니다.
보통 collator는 tokenizer 객체를 입력으로 받아, pad_token을 자동으로 사용하며, max_length, truncation 등도 설정할 수 있습니다.
HuggingFace의 Trainer나 DataLoader에서 collate_fn 파라미터로 전달되어, 모델에 적합한 형태로 데이터를 전처리해주는 핵심 컴포넌트로 사용됩니다.
🔎 핵심
| 항목 | 설명 |
|---|---|
| 목적 | 개별 샘플 → 텐서 배치로 변환 |
| 주요 역할 | padding, tensor 변환, mask 생성 |
| 필요한 입력 | tokenizer, optionally max_length 등 |
| 사용 위치 | DataLoader(..., collate_fn=collator) 또는 Trainer(data_collator=collator) |
| 결과 | 모델 입력에 바로 사용할 수 있는 batch 형태 |
📦 Collator란?
— 배치를 만들고 전처리까지 담당하는 데이터 가공의 핵심!
❓ Collator란 무엇인가요?
Collator는 PyTorch나 HuggingFace에서 여러 개의 개별 데이터를 하나의 배치(batch)로 변환하는 역할을 합니다.
데이터 길이가 서로 다르고, 리스트 형태로 반환되는 Dataset 객체에서
→ tensor 형태로 정리된 고정된 크기의 배치를 만들어주는 함수 또는 클래스입니다.
🔧 입력은 무엇인가요?
🔹 Collator가 받는 입력은?
batch = [sample1, sample2, sample3, ...]각 샘플은 일반적으로 dict 형식이며, 다음과 같은 키를 가질 수 있습니다:
sample = {
"input_ids": [101, 123, 456],
"attention_mask": [1, 1, 1],
"label": 1
}이런 여러 샘플을 리스트로 묶은 것이 batch이며, 이걸 Collator가 받아 처리합니다.
📤 출력은 어떤가요?
Collator는 이 리스트(batch)를 받아 아래처럼 모델이 바로 입력할 수 있는 텐서 형태의 딕셔너리로 바꿉니다:
{
"input_ids": Tensor[batch_size, max_seq_len],
"attention_mask": Tensor[batch_size, max_seq_len],
"labels": Tensor[batch_size]
}예를 들어 input_ids는 가장 긴 문장에 맞춰 padding된 2D 텐서로 변환됩니다.
⚙️ Collator로 무엇을 할 수 있나요?
| 기능 | 설명 |
|---|---|
| ✅ Padding | 서로 다른 길이의 시퀀스를 동일한 길이로 맞춰줌 |
| ✅ Tensor 변환 | 리스트 → PyTorch 텐서로 자동 변환 |
| ✅ Mask 생성 | 필요한 경우 attention mask 자동 생성 |
| ✅ Label 정리 | label, start_positions, end_positions 등도 텐서로 묶어줌 |
| ✅ 확장성 | MLM용 masking, span masking 등 고급 전처리도 가능 |
✨ 예제 (HuggingFace)
from transformers import AutoTokenizer, DataCollatorWithPadding
from datasets import load_dataset
from torch.utils.data import DataLoader
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
dataset = load_dataset("glue", "sst2", split="train")
def preprocess(example):
return tokenizer(example["sentence"], truncation=True)
dataset = dataset.map(preprocess, batched=True)
collator = DataCollatorWithPadding(tokenizer=tokenizer)
loader = DataLoader(dataset, batch_size=4, collate_fn=collator)
for batch in loader:
print(batch["input_ids"].shape) # torch.Size([4, max_seq_len])
break✅ 장점과 ❌ 단점
| 항목 | 설명 |
|---|---|
| ✅ 간편성 | 복잡한 전처리 없이 배치 자동 생성 |
| ✅ HuggingFace 통합성 | Trainer에서 바로 사용 가능 |
| ✅ 커스터마이징 | 직접 collate 함수 정의하여 자유롭게 변경 가능 |
| ❌ 복잡한 로직 한계 | 너무 복잡한 전처리는 Dataset 쪽에서 나눠야 할 수도 있음 |
| ❌ 버그 은닉 가능성 | 의도치 않은 패딩/마스킹으로 결과 이상 가능성 있음 |
🧪 직접 커스터마이징 하고 싶다면?
def my_collate_fn(batch):
input_ids = [x["input_ids"] for x in batch]
max_len = max(len(ids) for ids in input_ids)
padded_ids = [ids + [0] * (max_len - len(ids)) for ids in input_ids]
return {"input_ids": torch.tensor(padded_ids)}🎯 마무리 요약
| 항목 | 설명 |
|---|---|
| 정의 | 개별 샘플 리스트 → 모델 입력 배치로 변환 |
| 입력 | list of dict (샘플들) |
| 출력 | dict of tensors (모델 입력) |
| 기능 | 패딩, 텐서화, 마스킹, 정리 |
| 사용처 | DataLoader(..., collate_fn=collator), Trainer(data_collator=...) |
🔧 커스텀 Collator 분석
🧩 1. 무엇을 위한 Collator인가요?
이 DataCollator는 HuggingFace Trainer 또는 DataLoader와 함께 사용되며,
문장 임베딩 학습, 특히 SentenceTransformers 스타일의 pair-based 학습(ex: anchor–positive–negative)에서 사용됩니다.
예:
{
"query": "나는 오늘 기분이 어때?",
"pos": "기분이 어떤지 알려줘",
"neg": "날씨가 왜 이래",
"label": 1
}🔢 2. 입력: 어떤 데이터를 받나요?
__call__ 함수의 입력은 다음과 같은 샘플 리스트입니다:
features: List[Dict[str, Any]]예시:
[
{"query": "Q1", "pos": "P1", "neg": "N1", "label": 1},
{"query": "Q2", "pos": "P2", "neg": "N2", "label": 0}
]또는
[
{"question": "What is AI?", "answer": "Artificial Intelligence", "label": 1}
]📤 3. 출력: 어떤 형태로 반환되나요?
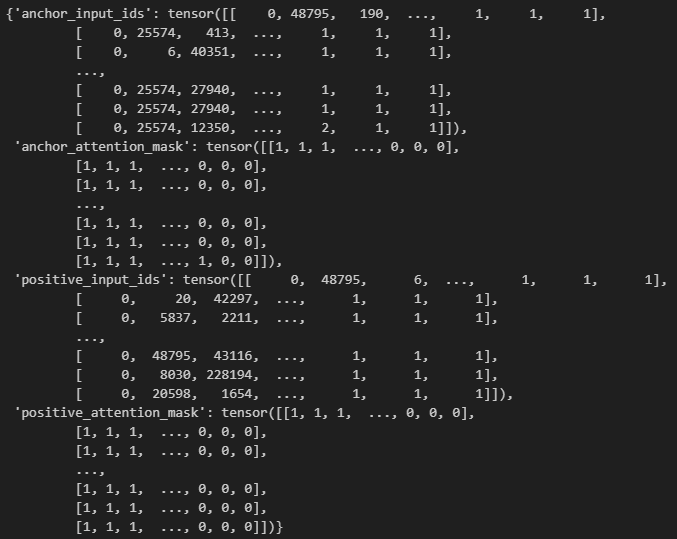
Collator는 입력된 여러 샘플을 받아 다음과 같이 반환합니다:
{
"query_input_ids": Tensor,
"query_attention_mask": Tensor,
"pos_input_ids": Tensor,
"pos_attention_mask": Tensor,
"neg_input_ids": Tensor,
"neg_attention_mask": Tensor,
"label": Tensor
}모든 문장열 컬럼에 대해 tokenizer를 적용하고, _{input_ids, attention_mask} 형태로 키가 붙습니다.
⚙️ 4. 이 Collator는 무엇을 하나요?
✅ 핵심 기능
| 기능 | 설명 |
|---|---|
| ✔️ 텍스트 필드 자동 토크나이징 | 각 컬럼(query, pos, neg, question, answer 등)에 대해 tokenizer 적용 |
| ✔️ padding/truncation | 길이에 맞춰 padding + max_seq_length 제한 |
| ✔️ 다중 텍스트 필드 처리 | anchor/positive/negative 구조를 지원 |
| ✔️ label 처리 | label, score 등의 정답 필드를 텐서로 변환 |
| ✔️ lang 인식 | "lang" 컬럼이 있으면 "en" → 0, "ko" → 1 등의 ID 부여 |
| ✔️ 컬럼 순서 체크 | anchor, positive, question, answer 등의 순서를 경고로 안내함 |
🧠 예외 처리 및 사용자 안내
maybe_warn_about_column_order()는 사용자가 입력한 컬럼 순서가 잘못된 경우 경고를 출력합니다.
예: MultipleNegativesRankingLoss를 사용하는데 "answer"가 첫 번째 컬럼이면 경고 발생
🚨 "anchor"는 항상 0번 컬럼이어야 한다는 규칙 등을 점검해줌
✅ 장점 요약
| 장점 | 설명 |
|---|---|
| 다양한 데이터셋 구조 지원 | "query–pos–neg", "question–answer", "anchor–positive" 등 |
| 자동 패딩 + truncation | tokenizer와 max length 기반으로 자동 처리 |
| column 이름 기반 유연한 설계 | 어떤 이름을 써도 자동 처리되며, 경고를 통해 알려줌 |
| 커스터마이징 가능성 | lang 처리, prompt_length 추가 등 자유로운 확장 가능 |
❌ 단점 또는 주의점
| 단점/주의점 | 설명 |
|---|---|
| 컬럼 순서 의존 | 특정 loss 함수는 순서에 따라 의미가 달라질 수 있음 (e.g., MNRankingLoss) |
| tokenizer가 전제로 깔려 있음 | PreTrainedTokenizer를 반드시 받아야 작동 |
"dataset_name"은 첫 샘플 기준으로만 들어감 |
전체 배치에서 다를 경우 예외가 발생할 수 있음 |
📌 사용 예시
collator = DataCollator(
tokenizer=AutoTokenizer.from_pretrained("bert-base-uncased"),
max_seq_length=128
)
dataloader = DataLoader(dataset, batch_size=8, collate_fn=collator)🧾 마무리 요약
| 항목 | 설명 |
|---|---|
| 이름 | DataCollator |
| 입력 | 샘플 리스트 (List[Dict[str, Any]]) |
| 출력 | Dict[str, Tensor] – 각 컬럼별 input_ids, attention_mask, label 등 |
| 주요 기능 | padding, 토크나이징, 컬럼 정렬 경고, lang 처리 |
| 사용처 | DataLoader 또는 HuggingFace Trainer(data_collator=...) |
| 강점 | 다양한 구조 대응 + 동적 패딩 지원 + 정제된 전처리 로직 |

'인공지능 > 공부' 카테고리의 다른 글
| Multi-GPU 기본 개념 DDP, Data Parallel, Model Parallel (4) | 2025.07.30 |
|---|---|
| 인공지능 기초 학습 코드 + 개념 (4) | 2025.07.29 |
| 딥러닝 총 정리 (2) | 2025.07.04 |
| 딥러닝 공부하기 3 (4) | 2025.07.03 |
| 딥러닝 공부하기 2 (1) | 2025.07.02 |